Создание веб‑приложения для управления соответствием и аудиторских следов
Практический план создания веб‑приложения для управления соответствием с надёжными аудиторскими следами: требования, модель данных, логирование, контроль доступа, хранение и отчётность.
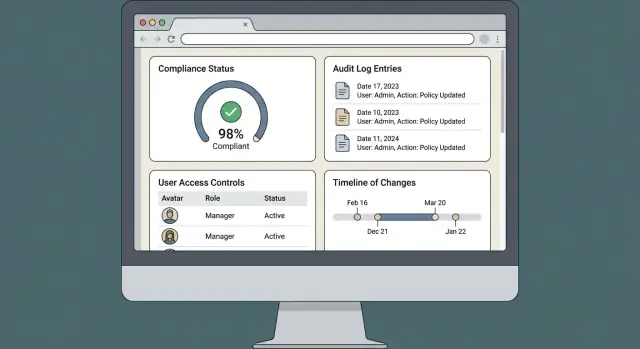
Создание веб‑приложения для управления соответствием — это не столько про «экраны и формы», сколько про то, чтобы аудиты были повторяемыми. Продукт успешен, когда он помогает быстро и последовательно доказать намерение, полномочия и прослеживаемость — без ручной сверки.
Начните с целей соответствия и пользовательских историй
Прежде чем выбирать базу данных или рисовать экраны, зафиксируйте, что в вашей организации означает «управление соответствием». Для одних команд это структурированный способ отслеживать контроли и доказательства; для других — прежде всего движок процессов для утверждений, исключений и периодических проверок. Определение важно, потому что оно определяет, что именно вам нужно будет доказать при аудите — и что ваше приложение должно упростить.
Определите цель простым языком
Хорошая отправная фраза:
«Нужно показать, кто что сделал, когда, почему и по чьему приказу — и быстро извлекать доказательства.»
Это сохраняет фокус на результате, а не на функциях.
Определите роли (и что каждой нужно)
Перечислите людей, которые будут работать с системой, и решения, которые они принимают:
- Администраторы: настраивают политики, пользователей, интеграции, параметры хранения.
- Менеджеры / владельцы контролей: утверждают изменения, проверяют доказательства, подписывают исключения.
- Пользователи: загружают доказательства, запрашивают исключения, выполняют назначенные задачи.
- Аудиторы (внутренние/внешние): доступ только для чтения, экспорты и ясная прослеживаемость.
Зафиксируйте основные рабочие процессы
Опишите «идеальный сценарий» и типичные отклонения:
- Утверждения (обновления политик, изменения контролей, запросы доступа)
- Исключения (временные отклонения с датой истечения и обоснованием)
- Сбор доказательств (загрузки, ссылки, аттестации, системные логи)
- Отчётность (статус контролей, просроченные элементы, история изменений)
Критерии успеха для v1
Для приложения по соответствию v1 обычно означает:
- Прослеживаемость: полная история изменений и ответственные лица
- Поисковость: находить решение или доказательство за секунды
- Противодействие подмене: обнаружение несанкционированных правок и сохранение оригиналов
Оставьте v1 узким: роли, базовые рабочие процессы, аудиторский след и отчётность. «Приятные» фичи (продвинутая аналитика, кастомные дашборды, широкие интеграции) отложите до тех пор, пока аудиторы и владельцы контролей не подтвердят базу.
Сопряжение регуляций и стандартов с конкретными требованиями приложения
Работа по соответствию идёт не туда, когда регуляции остаются абстрактными. Цель этого шага — превратить «соответствовать SOC 2 / ISO 27001 / SOX / HIPAA / GDPR» в понятный бэклог функций и доказательств, которые приложение должно выдавать.
Начните с выбора того, что применимо (и что нет)
Перечислите фреймворки, важные для вашей организации, и почему. SOC 2 часто движется из опросов клиентов, ISO 27001 — из плана сертификации, SOX — из финансовой отчётности, HIPAA — при работе с PHI, GDPR — при наличии пользователей из ЕС.
Затем определите границы: какие продукты, среды, бизнес‑единицы и типы данных попадают в зону охвата. Это предотвратит создание контролей для систем, которые аудиторы даже не будут смотреть.
Переведите требования в функции системы
Для каждого требования фреймворка опишите «требование приложения» простым языком. Частые переводы включают:
- Логирование и аудиторский след: доказать, кто что сделал, когда и откуда.
- Контроль доступа: ролевой доступ, принцип наименьших привилегий, разделение обязанностей для чувствительных действий.
- Хранение и жизненный цикл: сохранять записи требуемый период, затем архивировать или безопасно удалять.
- Утверждения и проверки: поддержка подписей, периодических ревизий доступа и аттестаций контролей.
- Сбор доказательств: хранение экспортов, скриншотов, вложений и «доказательств выполнения».
Практический приём — создать в требованиях таблицу соответствия:
Фреймворк → функция приложения → данные, которые нужно фиксировать → отчёт/экспорт, доказывающий это
Определите аудируемые события и сроки их хранения
Аудиторы обычно просят «полную историю изменений», но вам нужно конкретизировать. Решите, какие события считаются аудируемыми (например: логин, изменения прав, правки контролей, загрузки доказательств, утверждения, экспорты, действия по хранению) и минимальный набор полей для каждого события.
Также укажите ожидания по хранению для каждого типа события. Например, изменения доступа могут требовать более длительного хранения, чем простые просмотры, а GDPR может ограничивать хранение персональных данных дольше необходимого.
Ранняя ясность по требованиям к доказательствам
Рассматривайте доказательства как первоклассное требование продукта, а не как приклеенную фичу вложений. Укажите, какие доказательства поддерживают каждый контроль: скриншоты, ссылки на тикеты, экспортированные отчёты, подписанные утверждения и файлы.
Определите метаданные для аудита — кто загрузил, к чему относится, версионирование, метки времени и было ли это проверено и принято.
Согласуйте ожидания с аудиторами до разработки
Назначьте короткую рабочую сессию с внутренним или внешним аудитором, чтобы подтвердить ожидания: как выглядит «хорошо», какие выборки будут использоваться и какие отчёты ожидаются.
Такое согласование заранее может сэкономить месяцы переделок и поможет строить только то, что действительно поддерживает аудит.
Проектирование модели данных для контролей, доказательств и проверок
Приложение для соответствия живёт и умирает за счёт модели данных. Если контролы, доказательства и проверки плохо структурированы, отчётность становится болезненной, и аудит превращается в охоту за скриншотами.
Основные сущности
Начните с небольшого набора таблиц/коллекций:
- Пользователи и роли (плюс таблица соединений для many-to-many)
- Политики (документы верхнего уровня, например «Политика контроля доступа»)
- Контроли (операционные требования, которые вы тестируете и по которым собираете доказательства)
- Задачи (работы типа «Загрузить доказательства квартального ревью доступа»)
- Доказательства (файлы, ссылки, записи, скриншоты, тикеты)
- Проверки/тесты (экземпляр оценки контрола: кто проверял, когда, результат)
Отношения, которые упрощают аудит
Явно моделируйте связи, чтобы одним запросом ответить «покажите, почему этот контроль работает»:
- Контроль ↔ Доказательства: обычно many‑to‑many (одно доказательство может подкреплять несколько контролей)
- Контроль ↔ Проверки: one‑to‑many (каждый период даёт новую запись проверки)
- Владелец ↔ Контроль: пользователи могут владеть несколькими контролями; у контроля может быть основной и запасной владелец
- Политика ↔ Контроли: one‑to‑many (контроли сгруппированы по политике)
Идентификаторы и версионирование
Используйте стабильные, удобочитаемые ID для ключевых записей (например, CTRL-AC-001) наряду с внутренними UUID.
Версионируйте всё, что аудиторы ожидают видеть неизменным со временем:
- версии политик (даты публикации, даты вступления в силу)
- версии определений контролей (формулировка, частота, область)
- изменения метаданных доказательств (храните указатель на историю изменений, а не перезаписывайте)
Вложения: храните файлы, а не блобы в БД
Храните вложения в объектном хранилище (например, S3‑совместимом) и держите метаданные в БД: имя файла, MIME‑тип, хеш, размер, загрузивший, uploaded_at и метка хранения. Доказательство также может быть URL (тикет, отчёт, вики‑страница).
Поля, которые упрощают отчётность и фильтрацию
Проектируйте под фильтры, которыми будут пользоваться аудиторы и менеджеры: соответствие фреймворку, система/продукт в зоне охвата, статус контроля, частота, владелец, дата последней проверки, дата следующей проверки, результат теста, исключения и возраст доказательства. Такая структура упростит /reports и экспорт.
Определите аудиторский след, который отвечает на вопросы аудитора
Первые вопросы аудитора предсказуемы: Кто что сделал, когда и по чьему разрешению — и можно ли это доказать? Прежде чем внедрять логирование, определите, что такое «аудиторское событие» в вашем продукте, чтобы все команды (разработка, комплаенс, саппорт) записывали одну и ту же историю.
Минимум «кто/что/когда/где/почему»
Для каждого события аудита фиксируйте единый набор полей:
- Кто: ID пользователя, роль на момент действия и (если уместно) acting‑on‑behalf‑of / сервисный аккаунт
- Что: действие и объект (например, «обновление Контроля #184»)
- Когда: серверная метка времени (UTC) и, при необходимости, локальное время пользователя для отображения
- Где: тенант/организация, окружение и источник запроса (IP)
- Почему: текст обоснования для чувствительных действий (изменения прав, утверждения, удаления)
Стандартизируйте типы событий для отчётов
Аудиторы ожидают чётких категорий, а не свободного текста. Минимум — определить типы событий для:
- Создание / обновление / удаление ключевых записей (контроли, доказательства, политики, находки)
- Аутентификация: успех/неудача логина, выход, настройка MFA/сброс
- Изменения авторизации: смена ролей, выдача/отзыв прав, членство в группах
- Действия в рабочих процессах: утверждения, отклонения, подписи проверки, «готово к аудиту»
Фиксируйте «до/после» значения (с безопасной редакцией)
Для важных полей храните до и после, чтобы изменения можно было объяснить без догадок. Редактируйте или хешируйте чувствительные значения (например, сохраняйте «изменено с X на [REDACTED]») и фокусируйтесь на полях, влияющих на решения по соответствию.
Добавьте контекст запроса для расследований
Включите метаданные запроса, чтобы связать события с реальными сессиями:
- IP‑адрес, user‑agent
- Session ID (или device ID)
- Correlation ID / request ID (чтобы саппорт мог проследить транзакцию)
Будьте явными в том, что никогда не логируется
Запишите это правило заранее и соблюдайте в code review:
- Пароли, seed‑фразы MFA, секретные ключи, токены доступа
- Полные данные платёжных карт, CVV и подобные регулируемые данные
Пример простой формы события для согласования:
{
"event_type": "permission.change",
"actor_user_id": "u_123",
"target_user_id": "u_456",
"resource": {"type": "user", "id": "u_456"},
"occurred_at": "2026-01-01T12:34:56Z",
"before": {"role": "viewer"},
"after": {"role": "admin"},
"context": {"ip": "203.0.113.10", "user_agent": "...", "session_id": "s_789", "correlation_id": "c_abc"},
"reason": "Granted admin for quarterly access review"
}
Реализуйте добавляемое, устойчивое к подмене логирование аудита
Аудиторскому логу можно доверять, только если люди уверены в его целостности. Это значит обращаться с ним как с записью «write‑once»: добавлять записи можно, а старые нельзя «исправлять». Если что‑то было неверно, записывайте новое событие с пояснением.
Начните с хранилища событий append‑only
Используйте таблицу аудита с режимом append‑only (или поток событий), где каждая запись неизменяема. Избегайте UPDATE/DELETE аудиторских строк из кода приложения и при возможности обеспечьте неизменяемость на уровне БД (права, триггеры или отдельное хранилище).
Каждая запись должна содержать: кто/что совершил действие, что произошло, какой объект затронут, указатели до/после (или ссылку на diff), когда это произошло и откуда пришёл запрос (request ID, IP/устройство при необходимости).
Добавьте механизмы целостности, чтобы подделка была обнаружима
Чтобы правки были заметны, добавьте меры целостности:
- Хеширование и цепочка: храните хеш записи плюс хеш предыдущей записи, создавая цепочку.
- Подпись (где уместно): подписывайте партии/записи логов ключом, хранящимся вне рантайма приложения.
- Write‑once хранилище для экспортов/архивов: периодически «запечатывайте» сегменты логов в иммутабельном хранилище.
Цель не в криптографии ради криптографии, а в том, чтобы показать аудитору: отсутствующие или изменённые события будут очевидны.
Разграничивайте действия пользователя и системы
Логируйте системные действия (фоновые джобы, импорты, автоматические утверждения) отдельно от пользовательских. Используйте явный «тип актёра» (user/service), чтобы «кто сделал» никогда не было неоднозначным.
Сделайте время и повторы предсказуемыми
Используйте UTC‑метки повсеместно и опирайтесь на надёжный источник времени (метки БД или синхронизированные серверы). Планируйте идемпотентность: присваивайте уникальный ключ события (request ID / idempotency key), чтобы повторы не создавали путаницу, но при этом фиксировали повторные реальные действия.
Постройте контроль доступа и разделение обязанностей
Контроль доступа — это место, где ожидания соответствия становятся повседневным поведением. Если приложение упрощает делать неправильно или затрудняет доказать, кто и почему сделал действие, аудиты превратятся в споры. Стремитесь к простым правилам, отражающим реальную работу организации, и строго их применяйте.
Начните с RBAC и принципа наименьших привилегий
Используйте ролевой контроль доступа (RBAC) с понятными ролями: Viewer, Contributor, Control Owner, Approver, Admin. Давайте каждой роли только необходимые права. Например, Viewer может читать контролы и доказательства, но не загружать и не редактировать ничего.
Избегайте «одной супервкладки» с правами у всех. Вместо этого применяйте временное повышение полномочий (time‑boxed admin), и делайте это аудируемым.
Определяйте права по действию и по области применения
Права должны быть явными по операциям — view / create / edit / export / delete / approve — и ограничены по области. Область может быть:
- бизнес‑юнит или департамент
- система/приложение
- конкретный фреймворк (например, SOX vs. internal controls)
- проект или аудитный период
Это предотвращает типичную ошибку: у кого‑то есть право, но оно распространяется слишком широко.
Делайте разделение обязанностей исполняемым кодом
Разделение обязанностей не должно быть политикой на бумаге — это правило в коде.
Примеры:
- Запросивший изменение не может его утверждать.
- Загружавший доказательство не может сам отметить его как просмотренное для того же контроля.
- Админы могут управлять доступом, но без второго утверждения не редактируют записи соответствия.
Если правило блокирует действие, показывайте пользователю понятное сообщение («Вы можете запросить изменение, но утверждение должен выполнить Approver.»), чтобы не стимулировать обходные пути.
Рассматривайте смены ролей/прав как важные аудиторские события
Любое изменение ролей, членств, областей прав или цепочек утверждения должно генерировать заметную запись аудита с кто/что/когда/почему. Включайте предыдущие и новые значения и, по возможности, ссылку на тикет или причину.
Добавьте step‑up аутентификацию для чувствительных действий
Для операций высокого риска (экспорт полного набора доказательств, изменение настроек хранения, выдача админ‑прав) требуйте повторной аутентификации — введите пароль повторно, запросите MFA или SSO‑реаутентификацию. Это снижает риск ошибок и усиливает аудиторскую историю.
Управляйте хранением, архивированием и удалением безопасно
Управление хранением — то место, где инструменты соответствия часто проваливаются: записи есть, но вы не можете доказать, что они хранились нужный срок, защищены от преждевременного удаления и утилизируются предсказуемо.
Определяйте хранение по типам записей (не для «всей БД»)
Создайте явные сроки хранения для каждой категории записи и храните применённую политику вместе с записью (чтобы политика была аудируемой позже). Обычные корзины:
- Аудиторские логи (часто дольше всех): безопасность, доступ, административные действия
- Доказательства и вложения: скриншоты, PDF, экспорты, утверждения
- Проверки и подписи: тестирование контролей, исключения, аттестации менеджмента
- Учётные записи пользователей и роли: даты приёма/увольнения, история ролей
Делайте политику видимой в UI (например, «хранится 7 лет после закрытия») и неизменяемой после финализации записи.
Сделайте legal hold первоклассной функцией
Legal hold должен отменять автоматические удаления. Рассматривайте его как состояние с понятной причиной, областью и метками времени:
- кто наложил холд, когда и почему
- что охватывает (тенант, проект, набор контролей, конкретные записи)
- кто может снять (обычно узкая роль)
Если приложение поддерживает запросы на удаление, legal hold должен ясно объяснять, почему удаление приостановлено.
Автоматизируйте графики хранения (архив, экспорт, удаление)
Хранение проще защищать, когда оно последовательное:
- Автоархивация: перенос старых записей в более дешёвое хранилище при сохранении возможности поиска
- Экспорт перед удалением (когда требуется): генерируйте подписанный пакет экспорта и логируйте передачу
- Правила очистки, которые запускаются по расписанию, создают отчёт и пишут аудиторские события для каждой партии
Резервные копии и тесты восстановления — часть хранения
Документируйте, где живут бэкапы, как долго хранятся и как защищены. Планируйте тесты восстановления и фиксируйте результаты (дата, набор данных, критерии успеха). Аудиторы часто просят доказательства, что «мы можем восстановить» — это должно быть не обещание.
Удаление vs редактирование ради приватности
Для обязательств по приватности определите, когда вы удаляете, когда редактируете и что должно остаться для целостности (например, оставлять аудиторское событие, но редактировать персональные поля). Редакции должны логироваться как изменения с указанием причины и проверки.
Реализуйте отчёты, поиск и экспорт, которых ожидают аудиторы
Аудиторы редко хотят прогулку по UI — им нужны быстрые ответы, которые можно верифицировать. Отчёты и поиск должны сокращать переписку: «Покажите все изменения этого контроля», «Кто утвердил это исключение», «Что просрочено» и «Как вы доказали, что это доказательство проверено?»
Просматриваемые журналы аудита с возможностью расследования
Предоставьте представление аудита с фильтрацией по пользователю, диапазону дат/времени, объекту (контроль, политика, элемент доказательства, учётная запись) и действию (create/update/approve/export/login/permission change). Добавьте полнотекстовый поиск по ключевым полям (например, ID контроля, имя доказательства, номер тикета).
Делайте фильтры ссылками (копируемый URL), чтобы аудитор мог ссылаться на точный вид. Рассмотрите «сохранённые представления» для частых запросов, например «Изменения доступа за 90 дней».
Отчёты, которые отвечают на реальные вопросы аудита
Создайте небольшой набор высокоинформативных отчётов:
- Статус контролей (внедрён / в процессе / неприменимо) с владельцем и датой последней проверки
- Просроченные проверки по команде и степени важности
- Полнота доказательств (требуемые доказательства vs предоставленные), включая состояние проверки/утверждения
Каждый отчёт должен ясно показывать определения (что считается «полным» или «просроченным») и дату‑снимок набора данных.
Экспорт, которому можно доверять (и который вы сможете защитить)
Поддерживайте экспорт в CSV и PDF, но рассматривайте экспорт как регулируемое действие. Каждый экспорт должен генерировать аудиторское событие с: кто экспортировал, когда, какой отчёт/вид, какие фильтры, количество записей и формат файла. По возможности включайте контрольную сумму для экспортированного файла.
Чтобы данные отчёта были воспроизводимыми, обеспечьте, чтобы одинаковые фильтры возвращали одинаковый результат:
- Стабильная сортировка (например, по ID + времени обновления)
- Фиксация «as‑of» времени и параметров запроса
- Избегайте смешения живо обновляемых данных в одном экспорте без явного указания
«Объясните эту запись»
Для любого контроля, элемента доказательства или разрешения пользователя добавьте панель «Объясните эту запись», которая переводит историю изменений в понятный язык: что изменилось, кто изменил, когда и почему (с полями комментариев/обоснования). Это сокращает недопонимание и предотвращает ситуации, когда аудит превращается в угадывание.
Добавьте меры безопасности, которые поддерживают соответствие
Меры безопасности делают ваши функции соответствия правдоподобными. Если приложение можно редактировать без надлежащих проверок или данные доступны не тем людям — аудиторский след не удовлетворит SOX, GxP или внутренние проверки.
Считайте каждый запрос недоверенным
Проводите валидацию на каждом эндпойнте, а не только в UI. Используйте серверную валидацию типов, диапазонов и допустимых значений, отклоняйте неизвестные поля. Сопровождайте валидацию строгими проверками авторизации на каждую операцию (просмотр, создание, обновление, экспорт). Простое правило: «Если это изменяет данные соответствия, требуются явные права».
Чтобы снизить ошибки доступа, избегайте «безопасности через скрытие UI». Правила доступа должны выполняться на бэкенде, включая загрузки и фильтры API (например, экспорт доказательств для одного контроля не должен утекать для другого).
Защититесь от распространённых веб‑угроз
Последовательно закрывайте базовые уязвимости:
- Инъекции: параметризованные запросы, безопасный ORM и строгая валидация входа.
- XSS: кодирование вывода, очистка HTML для rich‑text и Content Security Policy.
- CSRF: анти‑CSRF токены для cookie‑сессий и sameSite настройки cookie.
- Безопасность сессий: короткоживущие сессии для админов, повторная аутентификация для чувствительных действий.
Шифруйте, изолируйте и управляйте секретами
Используйте TLS везде (включая внутренние S2S вызовы). Шифруйте чувствительные данные в покое (база данных и бэкапы) и рассмотрите шифрование на уровне полей для ключей API и идентификаторов. Храните секреты в выделенном менеджере секретов (не в исходниках или логах сборки). Регулярно ротация ключей и немедленная смена при уходе сотрудников.
Мониторьте и сигнализируйте о подозрительной активности
Командам комплаенса нужна видимость. Создавайте алерты на всплески неудачных логинов, повторные 403/404, изменения привилегий, создание новых API‑токенов и необычную активность экспортов. Делайте алерты конкретными: кто, что, когда и какие объекты затронуты.
Ограничения и правила блокировки
Применяйте rate‑лимиты для логина, сброса пароля и экспортных эндпойнтов. Добавляйте блокировку аккаунта или step‑up проверки в зависимости от риска (например, блокировать после повторных неудач, но предоставить безопасный способ восстановления для легитимных пользователей).
Тестируйте прослеживаемость, права и готовность к аудиту
Тестирование приложения соответствия — это не просто «работает ли оно», а «можем ли мы доказать, что произошло, кто это сделал и имел ли он право». Рассматривайте готовность к аудиту как первоклассный критерий приёмки.
Проверьте логирование с точностью до до/после
Пишите автоматические тесты, которые проверяют:
- Создаётся нужное событие (например,
CONTROL_UPDATED,EVIDENCE_ATTACHED,APPROVAL_REVOKED). - В событии всегда присутствуют актёр, метка времени, тенант/организация и ID объекта.
- Фиксируются значения до/после для изменений (включая очищенные поля).
- Чувствительные поля обрабатываются корректно (маскирование или исключение по политике).
Также тестируйте негативные случаи: неуспешные попытки (отказ в правах, ошибки валидации) должны либо создавать отдельное событие «доступ отклонён», либо намеренно исключаться — в соответствии с вашей политикой.
Тестируйте права как «не может», а не только «может»
Тестирование прав должно фокусироваться на предотвращении доступа за пределы области:
- Пользователь не может смотреть, экспортировать или искать данные вне своей организации, программы или назначенной системы.
- Потоки утверждений соблюдают разделение обязанностей (никакое самоустройство, если правила это запрещают).
- Изменения ролей вступают в силу немедленно и отражаются в событиях аудита.
Включайте тесты на уровне API, а не только UI, так как аудиторы часто проверяют точку истинного исполнения.
Драйлы прослеживаемости: восстановите историю
Проводите проверки прослеживаемости, начиная с результата (например, контроль помечен «Эффективен») и подтверждая, что можно восстановить:
- какие доказательства его поддерживают,
- кто проверял,
- какая версия политики действовала,
- и что менялось со временем.
Тесты производительности при росте логов
Логи и отчёты быстро растут. Нагрузочные тесты должны покрывать:
- приём событий в пиковые нагрузки,
- поиск/отчёты по большим временным диапазонам,
- и экспорт (CSV/PDF) для реалистичных объёмов данных.
Поддерживайте чек‑лист «готовности к аудиту» и пакет доказательств
Ведите повторяемый чек‑лист (ссылка в runbook, например /docs/audit-readiness) и генерируйте пример пакета доказательств: ключевые отчёты, списки доступа, примеры истории изменений и шаги проверки целостности логов. Это превращает аудит из паники в рутину.
Развёртывание, мониторинг и эксплуатация под контролем
Выпустить приложение соответствия — это не «релиз и забыть». Эксплуатация — то место, где добрые намерения либо становятся повторяемыми контролями, либо превращаются в пробелы, которые вы не сможете объяснить аудитору.
Защищайте историю через безопасное управление изменениями
Схемы и API‑изменения могут тихо нарушить прослеживаемость, если перезаписывают или по‑новому интерпретируют старые записи.
Используйте миграции БД как контролируемые, проверяемые единицы изменений и отдавайте предпочтение аддитивным изменениям (новые колонки, таблицы, типы событий) перед разрушительными. Когда приходится менять поведение — сохраняйте обратную совместимость API достаточно долго, чтобы поддержать старые клиенты и реплей/отчётные задачи. Цель проста: исторические события и доказательства должны оставаться читаемыми и согласованными между версиями.
Разделяйте окружения и контролируйте развёртывания
Держите отдельные окружения (dev/stage/prod) с раздельными БД, ключами и политиками доступа. Стейджинг должен имитировать прод, чтобы проверять правила прав, логирование и экспорты — но не копируйте прод‑данные, если нет одобренной санитизации.
Делайте развёртывания контролируемыми и повторяемыми (CI/CD с утверждениями). Рассматривайте каждое развёртывание как аудируемое событие: фиксируйте, кто утвердил, какая версия ушла и когда.
Логируйте развёртывания и изменения конфигурации
Аудиторы часто спрашивают: «Что поменялось и кто это разрешил?» Трекьте релизы, переключения feature‑флагов, изменения модели прав и конфигурации интеграций как первоклассные записи аудита.
Хороший паттерн — событие “system change”:
SYSTEM_CHANGE: {
actor, timestamp, environment, change_type,
version, config_key, old_value_hash, new_value_hash, ticket_id
}
Мониторьте угрозы соответствию
Настройте мониторинг, ориентированный на риски: уровни ошибок (особенно ошибки записи), задержки, бэклоги очередей (обработка доказательств, уведомлений) и рост хранилища (таблицы логов, бакеты файлов). Алертьте об отсутствии логов, неожиданном падении объёма событий и всплесках отказов доступа — это может указывать на неправильную настройку или злоупотребление.
Готовьте план реагирования на инциденты для целостности и доступа
Задокументируйте «первые часы» при подозрении на нарушение целостности или несанкционированный доступ: заморозьте рискованные записи, сохраните логи, ротируйте креды, проверьте непрерывность аудиторского лога и соберите таймлайн. Держите runbook коротким, выполнимым и ссылочным в операционных документах (например, /docs/incident-response).
Поддерживайте постоянное управление и улучшение
Приложение для соответствия не «готово» после релиза. Аудиторы будут спрашивать, как вы поддерживаете актуальность контролей, как утверждаются изменения и как пользователи соблюдают процесс. Встраивайте функции управления в продукт, чтобы непрерывное улучшение стало нормой, а не паникой перед аудитом.
Делайте управление изменениями видимым и аудируемым
Относитесь к изменениям приложения и контролей как к первоклассным записям. Для каждого изменения фиксируйте тикет/запрос, утверждающего(их), release notes и план отката. Связывайте это с затронутыми контролями, чтобы аудитор мог проследить:
почему изменили → кто утвердил → что изменилось → когда это вступило в силу
Если вы используете тикетинг‑систему, храните ссылки (ID/URL) и зеркалируйте ключевые метаданные в приложении, чтобы доказательства оставались целостными, даже если внешние инструменты меняются.
Версионируйте политики и контролы (не перезаписывайте историю)
Не редактируйте контроль «на месте». Создавайте версии с датами вступления в силу и явными diff‑ами (что и почему изменилось). Когда пользователи загружают доказательства или проходят проверку, привязывайте их к конкретной версии контрола.
Это предотвращает распространённую проблему аудита: доказательства, собранные под старое требование, кажутся несовместимыми с текущей формулировкой.
Сделайте обучение и подачу доказательств простыми
Большинство пробелов в соответствии — это процессные ошибки. Добавьте лаконичные подсказки прямо там, где люди действуют:
- Примеры хороших доказательств (форматы, образцы)
- Конвенции именования и обязательные поля
- Частые причины отклонений
Отслеживайте подтверждения обучения (кто, какой модуль, когда) и показывайте напоминания в момент назначения контрола или проверки.
Документируйте систему как продукт, а не как папку
Поддерживайте живую документацию в приложении (или ссылку через /help) с описанием:
- потоков данных (откуда приходят доказательства, где хранятся, кто может смотреть/экспортировать)
- модели прав и описаний ролей
- каталога событий аудита (что логируется и какие поля фиксируются)
Это сокращает переписку с аудиторами и ускоряет онбординг админов.
Встраивайте периодические проверки в рабочие процессы
Регулярные задачи:
- Ревью доступа: сертификация пользователей/ролей с записями утверждений и исключений.
- Ревью контролей: подтверждение владельцев контролей, частоты и ожиданий по доказательствам; документированное исключение при удалении контроля.
Когда эти ревью ведутся в приложении, непрерывное улучшение становится измеримым и легко демонстрируемым.
Быстрый прототип без компромисса на историю аудита
Инструменты соответствия часто начинают как внутренний workflow‑app — и самый быстрый путь к ценности — тонкий, аудируемый v1, который команды реально используют. Если нужно ускорить первый билд (UI + бэкенд + БД), подход типа vibe‑coding может быть практичным.
Например, Koder.ai позволяет командам создавать веб‑приложения через чат‑ориентированный рабочий процесс, при этом генерируя реальную кодовую базу (React на фронтенде, Go + PostgreSQL на бэкенде). Это может подойти для приложений соответствия, где нужны:
- чёткая RBAC‑модель и разделение обязанностей, реализованное на бэкенде,
- структурированные сущности для контролей, доказательств и проверок,
- шаблоны append‑only для аудита с самого начала,
- возможность экспортировать исходники или деплоить/хостить в контролируемых окружениях.
Ключ — трактовать требования соответствия (каталог событий, правила хранения, утверждения и экспорты) как явные критерии приёмки, независимо от того, как быстро вы получили первый прототип. Подходы «vibe‑coding» или генерация кода ускоряют кодинг, но не снимают обязанностей по дизайну аудита и безопасности.
FAQ
What’s the best way to define “compliance management” before building the app?
Start with a plain-language statement like: “We need to show who did what, when, why, and under whose authority—and retrieve proof quickly.”
Then turn that into user stories per role (admins, control owners, end users, auditors) and a short v1 scope: roles + core workflows + audit trail + basic reporting.
What should be in v1 of a compliance web application?
A practical v1 usually includes:
- Controls + ownership (who is responsible for what)
- Evidence collection (files/links + required metadata)
- Reviews/attestations (who reviewed, when, outcome)
- Approvals/exceptions (with justification and expiry)
- Audit trail (who/what/when/where/why)
- Search + a few core reports (status, overdue, evidence completeness)
Defer advanced dashboards and broad integrations until auditors and control owners confirm the fundamentals work.
How do I translate SOC 2 / ISO 27001 / SOX / HIPAA / GDPR into app requirements?
Create a mapping table that converts abstract controls into buildable requirements:
- Framework control → app feature → data captured → report/export that proves it
Do this per in-scope product, environment, and data type so you don’t build controls for systems auditors won’t examine.
What data model works well for controls, evidence, and periodic reviews?
Model a small set of core entities and make relationships explicit:
- Users, Roles (often many-to-many)
- Policies → Controls (one-to-many)
- Controls ↔ Evidence (often many-to-many)
- Controls → Reviews/Tests (one-to-many per period)
- Tasks for recurring work (e.g., quarterly reviews)
Use stable human-readable IDs (e.g., CTRL-AC-001) and version policy/control definitions so old evidence stays tied to the requirement that existed at the time.
What should an audit trail capture to satisfy auditors?
Define an “audit event” schema and keep it consistent:
- Who: actor ID + role at the time (and service identity if automated)
- What: action + resource type/ID
- When: server timestamp (UTC)
- Where: tenant/org + request origin (IP) + correlation/request ID
- Why: justification for sensitive actions
Standardize event types (auth, permission changes, workflow approvals, CRUD of key records) and capture before/after values with safe redaction.
How do I implement append-only, tamper-evident audit logging?
Treat audit logs as immutable:
- Use an append-only event store (no UPDATE/DELETE from app code)
- Add tamper detection (e.g., hash + previous-hash chaining)
- Optionally sign/seal batches and store archives in immutable/WORM storage
- Log system actions separately from user actions (actor type: user/service)
If something needs “correction,” write a new event that explains it rather than changing history.
How should access control and separation of duties be enforced?
Start with RBAC and least privilege (e.g., Viewer, Contributor, Control Owner, Approver, Admin). Then enforce scope:
- Business unit / system / framework / audit period
Make separation of duties a code rule, not a guideline:
- Requester ≠ approver
- Evidence uploader ≠ evidence reviewer (for the same control)
Treat role/scope changes and exports as high-priority audit events, and use step-up auth for sensitive actions.
How do I handle retention, archiving, legal hold, and deletion safely?
Define retention by record type and store the applied policy with each record so it’s auditable later.
Common needs:
- Long retention: audit logs, access/admin changes
- Medium: reviews/sign-offs, exceptions
- Variable: evidence/attachments (depends on framework and contracts)
Add legal hold to override purges, and log retention actions (archive/export/purge) with batch reports. For privacy, decide when to delete vs. redact while keeping integrity (e.g., retain the audit event but redact personal fields).
What reporting, search, and export features do auditors typically expect?
Build investigation-style search and a small set of “audit questions” reports:
- Filter audit logs by user/date/object/action, plus free-text search
- Reports: control status, overdue reviews, evidence completeness
For exports (CSV/PDF), log:
- who exported, when, which report/view, filters, record count, format
Include an “as-of” timestamp and stable sorting so exports are reproducible.
How do I test and operate the app so it stays audit-ready over time?
Test audit readiness as a product requirement:
- Automated checks that the right event types fire with required fields
- Before/after logging correctness (including cleared fields)
- Negative tests for forbidden actions (and whether denials are logged, per policy)
- API-level authorization tests to prevent cross-scope access
Operationally, treat deployments/config changes as auditable events, keep environments separated, and maintain runbooks (e.g., /docs/incident-response, /docs/audit-readiness) that show how you preserve integrity during incidents.