03 апр. 2025 г.·8 мин
Управление состоянием между фронтендом и бэкендом в AI‑приложениях
Узнайте, как состояние UI, сессий и данных перемещается между фронтендом и бэкендом в AI‑приложениях: паттерны синхронизации, персистентности, кеширования и безопасности.
Что означает «состояние» в приложении с ИИ
«Состояние» — это всё, что приложению нужно запомнить, чтобы корректно вести себя в следующий момент.
Если пользователь нажимает Отправить в чат-интерфейсе, приложение не должно забыть, что он написал, что ассистент уже ответил, выполняется ли ещё запрос и какие настройки (тон, модель, инструменты) включены. Всё это — состояние.
Состояние, простыми словами
Полезный способ думать о состоянии: текущая правда приложения — значения, которые влияют на то, что видит пользователь и что система делает дальше. Это включает очевидные вещи, такие как поля формы, но и «невидимые» факты, например:
- В каком разговоре находится пользователь
- Ответ ещё стримится или уже завершён
- Список сообщений и их порядок
- Вызовы инструментов и их результаты (результаты поиска, запросы в БД, извлечения из файлов)
- Ошибки, повторы и отступления при превышении лимитов
Почему в приложениях с ИИ больше взаимосвязей
Традиционные приложения часто читают данные, показывают их и сохраняют обновления. В приложениях с ИИ добавляются дополнительные шаги и промежуточные результаты:
- Одно действие пользователя может вызвать несколько операций на бэкенде (запрос в LLM, вызов инструмента, ещё один запрос в LLM).
- Ответы могут приходить инкрементально (стриминг токенов), поэтому интерфейс должен управлять частичным состоянием.
- Контекст важен: системе может потребоваться хранить память диалога, результаты инструментов и настройки модели согласованно между запросами.
Именно из‑за этой дополнительной динамики управление состоянием часто становится скрытой сложностью в AI-приложениях.
Что охватит это руководство
В следующих разделах мы разобьём состояние на практические категории (состояние UI, сессии, данные и модель/рантайм) и покажем, где должна находиться каждая из них (фронтенд или бэкенд). Мы также рассмотрим синхронизацию, кеширование, долгие задачи, стриминг-обновления и безопасность — потому что состояние полезно только тогда, когда оно корректно и защищено.
Короткий пример сценария
Представьте чат-приложение, где пользователь просит: «Суммируй счета за прошлый месяц и пометь необычные позиции». Бэкенд может (1) получить счета, (2) запустить анализатор, (3) стримить сводку в UI и (4) сохранить итоговый отчёт.
Чтобы это выглядело плавно, приложение должно отслеживать сообщения, результаты инструментов, прогресс и сохранённый вывод — не перепутывая разговоры и не допуская утечки данных между пользователями.
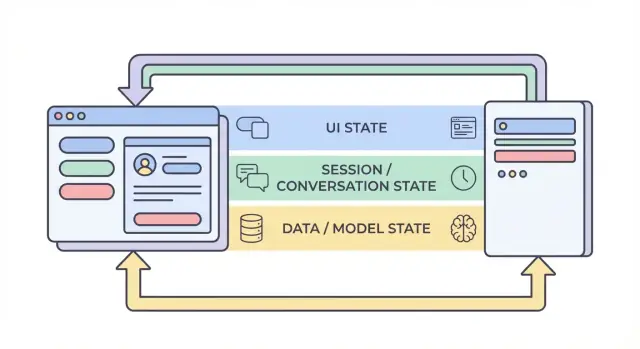
Четыре слоя состояния: UI, сессия, данные и модель
Когда говорят «состояние» в AI-приложении, часто смешивают очень разные вещи. Разделение состояния на четыре слоя — UI, сессия, данные и модель/рантайм — помогает решить, где что должно жить, кто может это менять и как это хранить.
1) Состояние UI (что пользователь делает прямо сейчас)
Состояние UI — это живое, моментальное состояние в браузере или мобильном приложении: текст в полях, переключатели, выбранные элементы, какая вкладка открыта и заблокирована ли кнопка.
AI-приложения добавляют несколько особенностей UI:
- Индикаторы загрузки и состояния «думает»
- Стриминг токенов (частичный текст, появляющийся по мере генерации)
- Локальные черновики сообщений (пока их не отправили)
Состояние UI должно легко сбрасываться и быть безопасным для утраты. Если пользователь обновит страницу, вы можете потерять это состояние — и это обычно нормально.
2) Состояние сессии / разговора (общий контекст для потока)
Состояние сессии связывает пользователя с текущим взаимодействием: идентичность пользователя, conversation_id и согласованный вид истории сообщений.
В AI-приложениях это часто включает:
- Историю сообщений (или ссылки на неё)
- Трейсы вызовов инструментов (какие функции/инструменты вызывались и с какими результатами)
- «Рабочий набор» — текущий проект/документ, выбранная модель, рабочее пространство
Этот слой часто охватывает фронтенд и бэкенд: фронтенд держит лёгкие идентификаторы, а бэкенд — авторитет за непрерывность сессии и контроль доступа.
3) Состояние данных (долговечные записи в хранилище)
Состояние данных — то, что вы специально храните в базе данных: проекты, документы, эмбеддинги, настройки, логи аудита, события биллинга и сохранённые транскрипты бесед.
В отличие от UI и сессий, состояние данных должно быть:
- Долговечным (выживать после перезапусков)
- Доступным для запросов (можно искать/фильтровать)
- Аудируемым (можно понять, что происходило позже)
4) Состояние модели / рантайма (как сейчас настроен ИИ)
Состояние модели/рантайма — это операционная настройка, используемая для генерации ответа: системные подсказки, включённые инструменты, temperature/max tokens, настройки безопасности, лимиты и временные кеши.
Часть из этого — конфигурация (стабильные значения), а часть — эфемерная (краткоживущие кеши или бюджеты токенов на запрос). Большая часть таких данных должна храниться на бэкенде, чтобы её можно было контролировать последовательно и не раскрывать лишнего.
Почему разделение снижает количество багов
Когда слои смешиваются, возникают классические ошибки: UI показывает текст, который не был сохранён, бэкенд использует другие prompt-настройки, чем ожидает фронтенд, или память разговора «протекает» между пользователями. Чёткие границы создают ясные источники правды — и облегчают понимание того, что нужно хранить, что можно пересчитывать и что защищать.
Что живёт на фронтенде и что — на бэкенде (и почему)
Надёжный способ уменьшить количество ошибок в AI-приложениях — решать для каждой части состояния, где ей быть: в браузере, на сервере или в обоих. Этот выбор влияет на надёжность, безопасность и на то, насколько неожиданно приложение ведёт себя при обновлении страницы, открытии вкладки или потере сети.
Состояние фронтенда: быстрое, временное и управляемое пользователем
Фронтенд лучше подходит для вещей, которые быстро меняются и не обязаны пережить обновление. Хранение локально делает UI отзывчивым и уменьшает ненужные API‑вызовы.
Обычные примеры только для фронтенда:
- Текст черновика сообщения
- Локальные фильтры и порядок сортировки в таблице
- Состояние модальных окон, выбранная вкладка, hover-стейты
Если вы потеряете это состояние при обновлении, это обычно приемлемо.
Состояние бэкенда: авторитетное, чувствительное и общее
На бэкенде должно храниться всё, чему нужно доверять, что нужно аудировать или последовательно применять. Это включает состояние, которое должны видеть другие устройства/вкладки, или которое должно оставаться корректным, даже если клиент модифицирован.
Обычные примеры только для бэкенда:
- Права и роли (что пользователю разрешено делать)
- Статус подписки и лимиты использования
- Долгие задания (индексация документов, большие экспорты, fine-tune) и их статус
Полезный принцип: если некорректное состояние может стоить денег, привести к утечке данных или нарушить доступ, оно должно быть на бэкенде.
Общие данные: согласование, но с одним источником правды
Некоторые элементы естественно разделяются:
- Заголовок разговора
- Выбранные источники знаний для чата
- Поля профиля пользователя, используемые на разных устройствах
Даже в таких случаях выберите «источник правды». Обычно это бэкенд, а фронтенд кэширует копию для скорости.
Правило большого пальца (и частая анти‑шаблонная ошибка)
Храните состояние ближе к месту, где оно нужно, но сохраняйте то, что должно пережить обновление, смену устройства или прерывание.
Избегайте анти‑паттерна хранения чувствительного или авторитетного состояния только в браузере (например, хранить на клиенте флаг isAdmin, уровень плана или статус завершения задания как истину). UI может отображать эти значения, но бэкенд должен их проверять.
Типичный цикл запроса AI: от клика до завершения
Функция AI ощущается как «одно действие», но на деле это цепочка переходов состояния между браузером и сервером. Понимание жизненного цикла помогает избежать рассинхрона UI, потери контекста и дублируемых расходов.
1) Действие пользователя → фронтенд готовит намерение
Пользователь нажимает Отправить. UI сразу обновляет локальное состояние: может добавить «в ожидании» пузырь сообщения, заблокировать кнопку отправки и зафиксировать текущие вводы (текст, вложения, выбранные инструменты).
В этот момент фронтенд должен генерировать или прикреплять корреляционные идентификаторы:
conversation_id: в каком потоке это происходитmessage_id: клиентский ID для нового сообщенияrequest_id: уникален для каждой попытки (полезно при повторах)
Эти идентификаторы позволяют обеим сторонам ссылаться на одно и то же событие, даже если ответы приходят поздно или дважды.
2) Вызов API → сервер валидирует и сохраняет
Фронтенд посылает API-запрос с сообщением пользователя и идентификаторами. Сервер проверяет права, лимиты и форму полезной нагрузки, затем сохраняет сообщение (или по крайней мере неизменяемую запись журнала), индексированную по conversation_id и message_id.
Этот шаг с персистентностью предотвращает «фантомную» историю, если пользователь обновит страницу во время запроса.
3) Сервер реконструирует контекст
Чтобы вызвать модель, сервер восстанавливает контекст из своего источника правды:
- Получает последние сообщения для
conversation_id - Подтягивает связанные записи (документы, настройки, результаты инструментов)
- Применяет политики разговора (системные подсказки, правила памяти, усечение)
Ключевая идея: не полагайтесь на клиент, чтобы он предоставил полную историю. Клиент может быть устаревшим.
4) Выполнение модели/инструментов → промежуточное состояние
Сервер может вызывать инструменты (поиск, запросы в БД) до или во время генерации модели. Каждый вызов инструмента создаёт промежуточное состояние, которое следует отслеживать против request_id, чтобы его можно было аудировать и безопасно повторить.
5) Ответ (стриминг или целиком) → завершение в UI
При стриминге сервер отправляет частичные токены/события. UI постепенно обновляет ожидающее сообщение ассистента, но считает его «в процессе» до получения финального события о завершении.
6) Точки отказа, о которых нужно задуматься
Повторы, двойные отправки и реакции вне порядка происходят. Используйте request_id для дедупликации на сервере и message_id для согласования в UI (игнорируйте поздние куски, которые не соответствуют активному запросу). Всегда показывайте ясный статус «не удалось» с безопасным повтором, который не создаёт дублирующих сообщений.
Сессии и память диалога: как держать контекст без хаоса
Держите состояние в безопасности
Генерируйте серверные проверки авторизации и безопасные шаблоны валидации для операций записи состояния.
Сессия — это «поток», который связывает действия пользователя: какое рабочее пространство открыто, что он недавно искал, над каким черновиком работал и к какому разговору должен продолжиться ответ ИИ. Хорошее состояние сессии делает приложение непрерывным между страницами — и, возможно, между устройствами — не превращая бэкенд в свалку всего, что пользователь когда‑либо говорил.
Цели состояния сессии
Стремитесь к: (1) непрерывности (пользователь может уйти и вернуться), (2) корректности (ИИ использует правильный контекст для нужного разговора) и (3) изоляции (одна сессия не должна протекать в другую). Если вы поддерживаете несколько устройств, рассматривайте сессии как scoped по пользователю и по устройству: «один аккаунт» не всегда значит «одни и те же открытые рабочие сессии».
Cookies vs. токены vs. серверные сессии
Обычно вы выбираете один из способов идентификации сессии:
- Cookies: самый простой вариант для веб‑приложений, потому что браузер отправляет их автоматически. Отлично подходит для традиционных сессий, но нужно ставить secure‑флаги (
HttpOnly,Secure,SameSite) и корректно обрабатывать CSRF. - Токены (например, JWT): хороши для API и мобильных приложений, потому что клиент прикрепляет их явно. Масштабируются хорошо, но отзыв и ротация требуют дополнительного дизайна (и не стоит класть в токен чувствительное состояние).
- Серверные сессии: сервер хранит данные сессии (часто в Redis), а клиент держит только непрозрачный session ID. Проще отзывать и обновлять, но нужно обеспечить запуск и масштабирование хранилища сессий.
Стратегии памяти разговора
«Память» — это просто состояние, которое вы решаете подать обратно в модель.
- Полная история: максимально точна, но дорогая и может раскрыть старые чувствительные данные.
- Суммарная история: поддерживайте текущую сводку плюс несколько последних ходов; дешевле и чаще «достаточно хорошо».
- Оконный контекст: только последние N сообщений; самый простой, но можно потерять важные ранние решения.
Практичный паттерн — сводка + окно: предсказуемо и помогает избежать неожиданных действий модели.
Вызовы инструментов: повторяемость и аудит
Если ИИ использует инструменты (поиск, запросы в БД, чтение файлов), сохраняйте каждый вызов инструмента с: входными данными, временными метками, версией инструмента и возвращённым результатом (или ссылкой на него). Это позволяет объяснить «почему ИИ это сказал», воспроизвести прогон для отладки и обнаружить, когда результаты изменились из‑за обновления инструмента или набора данных.
Ограждения конфиденциальности
Не храните долговременную память по умолчанию. Храните только необходимое для непрерывности (ID разговоров, сводки и логи инструментов), задавайте лимиты хранения и избегайте записи сырых пользовательских текстов без явной продуктовой причины и согласия пользователя.
Безопасная синхронизация состояния: источники правды и конфликтные ситуации
Состояние становится рискованным, когда один и тот же «объект» могут редактировать в разных местах — ваш UI, вторая вкладка или фоновая задача. Решение менее про хитрый код и больше про чёткое владение.
Определите источники правды
Решите, какая система авторитетна для каждого фрагмента состояния. В большинстве AI‑приложений бэкенд должен владеть канонической записью для всего, что должно быть корректным: настройки разговора, права на инструменты, история сообщений, биллинговые лимиты и статус задач. Фронтенд может кэшировать и выводить ради скорости (выбранная вкладка, черновик, индикаторы «печатает»), но при рассинхроне он должен считать бэкенд правильным.
Практическое правило: если вы расстроитесь, потеряв это при обновлении, вероятно, оно должно храниться на бэкенде.
Оптимистичные обновления UI (используйте с осторожностью)
Оптимистичные обновления делают интерфейс мгновенным: переключили настройку, сразу обновили UI, потом подтвердили на сервере. Это хорошо для низкорискованных, обратимых действий (например, отметка звёздочкой).
Они вводят в заблуждение, когда сервер может отклонить или трансформировать изменение (проверки прав, лимиты квот, валидация или серверные дефолты). В таких случаях показывайте состояние «сохранение…» и обновляйте UI только после подтверждения.
Обработка конфликтов (две вкладки, один разговор)
Конфликты возникают, когда два клиента пытаются обновить одну запись, исходя из разных версий. Частый пример: вкладка A и вкладка B изменяют температуру модели.
Используйте лёгкое версионирование, чтобы бэкенд мог обнаружить устаревшие записи:
updated_attimestamps (просто и удобно для отладки)- ETags /
If-Matchзаголовки (нативно для HTTP) - Инкрементные номера ревизий (явная детекция конфликтов)
Если версия не совпадает, возвращайте ответ о конфликте (обычно HTTP 409) и присылайте последний серверный объект.
Проектируйте API, чтобы уменьшить рассинхрон
После любой записи API должен возвращать сохранённый объект как он хранится (включая серверные дефолты, нормализованные поля и новую версию). Это позволяет фронтенду сразу заменить кэшированную копию — один апдейт источника правды вместо догадок.
Кеширование и производительность: ускоряем без устаревшего состояния
Кеширование — один из быстрых способов сделать AI‑приложение отзывчивым, но оно также создаёт вторую копию состояния. Если кэшиовать не то или не там, вы получите быстрый, но сбивающий с толку UI.
Что кешировать на клиенте
Клиентские кэши должны фокусироваться на опыте, а не на авторитете. Хорошие кандидаты:
- Недавние превью разговоров (заголовки, фрагменты последнего сообщения)
- UI‑предпочтения (тема, выбранная модель, состояние сайдбара)
- Оптимистичное состояние UI (сообщения в статусе «отправляется»)
Держите клиентский кэш маленьким и сменяемым: если он очистится, приложение должно работать, заново подтянув данные с сервера.
Что кешировать на сервере
Серверные кэши должны ускорять дорогое или часто повторяющееся вычисление:
- Результаты инструментов, безопасные для повторного использования (например, прогноз погоды для одного города в течение 5 минут)
- Поиски по эмбеддингам и результаты векторных запросов для повторяющихся запросов (часто с коротким TTL)
- Состояние лимитов и счётчики троттлинга (чтобы защитить API и расходы)
Здесь же можно кешировать выводы, такие как подсчитанные токены, решения модерации или результаты парсинга документов — всё детерминированное и дорогое.
Основы инвалидации кэша (без сложностей)
Три практических правила:
- Используйте понятные ключи кэша, которые кодируют входные данные (
user_id, модель, параметры инструмента, версия документа). - Устанавливайте TTL в зависимости от того, как быстро меняются исходные данные. Короткий TTL лучше хитрых условий.
- Обходите кэш, когда корректность важнее скорости: после обновления документа, смены прав или по явному запросу на обновление.
Если вы не можете объяснить, когда запись кэша станет неверной, не кешируйте её.
Не кешируйте секреты или персональные данные в общих кэшах
Избегайте помещения API‑ключей, токенов аутентификации, сырых подсказок с чувствительным текстом или персонального контента в слои типа CDN. Если нужно кешировать пользовательские данные, изолируйте по пользователю и шифруйте на диске — или храните их в основной базе.
Измеряйте эффект: скорость vs устаревший UI
Кеширование должно быть доказано цифрами, а не предположением. Отслеживайте p95 latency до/после, hit rate кэша и ошибки, видимые пользователю (например, «сообщение изменено после рендеринга»). Быстрый ответ, который позднее противоречит UI, часто хуже слегка медленного, но согласованного.
Персистентность и долгие задачи: джобы, очереди и статус
Преобразуйте архитектуру в код
Опишите модель состояния, и Koder.ai сгенерирует скелет для React, Go и PostgreSQL.
Некоторые AI‑функции выполняются за секунды. Другие — минуты: загрузка и парсинг PDF, эмбеддинг и индексация базы знаний, многошаговые workflow инструментов. Для таких случаев «состояние» — это не только то, что на экране, но и то, что переживает обновления, повторы и время.
Что хранить (и зачем)
Храните только то, что приносит реальную продуктовую ценность.
История разговоров — очевидное: сообщения, метки времени, идентичность пользователя и часто, какая модель/инструменты использовались. Это даёт возможность «продолжить позже», аудит и поддержку.
Настройки пользователя и рабочего пространства: предпочитаемая модель, дефолты temperature, feature‑тогглы, системные подсказки и UI‑предпочтения — должны жить в БД.
Файлы и артефакты (загрузки, извлечённый текст, сгенерированные отчёты) обычно лежат в объектном хранилище, а в БД хранятся записи‑метаданные (владелец, размер, content type, состояние обработки).
Фоновые задания для долгих операций
Если запрос не уложится в обычный HTTP‑таймаут, переносите работу в очередь.
Типичный шаблон:
- Фронтенд вызывает API, например
POST /jobsс входными данными (file id, conversation id, параметры). - Бэкенд ставит задачу в очередь (экстракция, индексация, пакетные вызовы инструментов) и сразу возвращает
job_id. - Воркеры асинхронно обрабатывают задания и записывают результаты в персистентное хранилище.
Это делает UI отзывчивым и повторные попытки безопаснее.
Статус, которому UI может доверять
Делайте состояние задания явным и доступным для опроса: queued → running → succeeded/failed (опционально canceled). Храните переходы на сервере с метками времени и деталями ошибок.
На фронтенде отражайте статус явно:
Queued/running: показывайте спиннер и блокируйте дублирующие действия.Failed: показывайте краткую ошибку и кнопку Повторить.Succeeded: загружайте полученный артефакт или обновляйте разговор.
Предоставьте GET /jobs/{id} (polling) или потоковые обновления (SSE/WebSocket), чтобы UI не гадавал.
Ключи идемпотентности: повторы без дублей
Сетевые таймауты происходят. Если фронтенд повторяет POST /jobs, вы не хотите две одинаковые задачи и двойной счёт.
Требуйте Idempotency-Key для каждой логической операции. Бэкенд хранит ключ вместе с результатом job_id/response и возвращает тот же результат для повторных запросов.
Политики очистки и истечения
AI‑приложения быстро накапливают данные. Определите правила хранения рано:
- Удаляйте старые разговоры через N дней (или дайте пользователю настраивать).
- Удаляйте производные артефакты при удалении источника.
- Периодически очищайте неудачные задания и промежуточные файлы.
Рассматривайте очистку как часть управления состоянием: это снижает риски, стоимость и путаницу.
Стриминг ответов и реальное время: управление частичным состоянием
Стриминг делает состояние сложнее, потому что «ответ» перестаёт быть одним целым. Вы работаете с частичными токенами (текст приходит семантическими кусками) и иногда с частичной работой инструментов (поиск начался, а закончится позже). Это значит, что UI и бэкенд должны согласовать, что считать временным, а что — финальным состоянием.
Бэкенд: стримьте типизированные события, а не просто текст
Чистый паттерн — стримить последовательность мелких событий, каждое с типом и полезной нагрузкой. Например:
token: инкрементальный текст (или небольшой фрагмент)tool_start: начат вызов инструмента (например, «Идёт поиск…», с id)tool_result: результат инструмента готов (тот же id)done: сообщение ассистента завершеноerror: произошла ошибка (включите безопасное для пользователя сообщение и debug id)
Такой поток событий легче версионировать и отлаживать, чем голый текстовый стрим, потому что фронтенд может рендерить прогресс корректно и показывать статус инструментов, не догадываясь.
Фронтенд: добавляйте приписывая, потом финализируйте
На клиенте обрабатывайте стриминг как append‑only: создайте «черновое» сообщение ассистента и дописывайте в него по мере прихода token‑событий. Когда приходит done, выполните commit: пометьте сообщение финальным, сохраните при необходимости и разблокируйте действия вроде копирования, оценки или регенерации.
Это избегает переписывания истории в процессе стриминга и делает UI предсказуемым.
Обработка прерываний (отмена, обрывы, таймауты)
Стриминг увеличивает шанс «половинчатой» работы:
- Пользователь отменил: отправьте сигнал отмены; прекратите рендерить токены; оставьте черновик помеченным как отменённый.
- Падение сети: остановите стрим; покажите «переподключение…» и не допускайте предположений о завершении.
- Таймауты/ошибки сервера: финализируйте черновик как неуспешный и предложите повтор (не сшивайте потоки молча).
Ре-гидация (rehydration): перезагрузка и восстановление стабильного состояния
Если страница перезагрузилась в середине стриминга, восстанавливайте из последнего стабильного состояния: последние зафиксированные сообщения плюс любые метаданные черновика (message id, накопленный текст, статусы инструментов). Если возобновить стрим невозможно, показывайте черновик как прерванный и дайте пользователю возможность повторить запрос, а не притворяйтесь, что он завершился.
Безопасность и приватность: защита состояния по‑всему
Экспортируйте код и владейте им
Генерируйте быстро, затем экспортируйте исходный код и расширяйте его по‑своему.
Состояние — это не только «данные, которые вы храните» — это подсказки пользователя, загрузки, предпочтения, сгенерированный вывод и метаданные, которые всё это связывают. В AI‑приложениях это состояние может быть необычно чувствительным (персональная информация, проприетарные документы, внутренние решения), поэтому безопасность нужно проектировать на каждом слое.
Храните секреты на сервере
Всё, что позволяет клиенту выдавать себя за ваше приложение, должно оставаться на бэкенде: API‑ключи, приватные коннекторы (Slack/Drive/DB креды), внутренние системные подсказки или логика маршрутизации. Фронтенд может запросить действие («суммируй этот файл»), но бэкенд должен решать, как оно выполняется и с какими учётными данными.
Авторизуйте каждую запись (и большинство чтений)
Рассматривайте каждую мутацию состояния как привилегированную операцию. Когда клиент пытается создать сообщение, переименовать разговор или прикрепить файл, бэкенд должен проверить:
- Пользователь аутентифицирован.
- Пользователь владеет ресурсом (conversation, workspace, project).
- Пользователь имеет право выполнить это действие (роль, план, политика организации).
Это предотвращает атаки с подстановкой ID, когда кто‑то меняет conversation_id, чтобы получить доступ к чужой истории.
Никогда не доверяйте браузеру: валидируйте и санитизируйте
Предполагаете, что любой клиент‑переданный стейт — недоверенные данные. Валидируйте схему и ограничения (типы, длины, разрешённые enum), и санитизируйте для назначения (SQL/NoSQL, логи, HTML‑рендеринг). Если вы принимаете «обновления состояния» (настройки, параметры инструментов), применяйте белый список полей вместо слияния произвольного JSON.
Аудит‑трейл для критических действий
Для действий, меняющих долговечное состояние — шаринг, экспорт, удаление, доступ к коннекторам — записывайте, кто что сделал и когда. Лёгкий лог аудита помогает при инцидентах, поддержке и соответствию требованиям.
Минимизация данных и шифрование
Храните только то, что нужно для фичи. Если вам не нужна полная история подсказок навсегда, рассмотрите окна хранения или редактирование/редакцию. Шифруйте чувствительные данные в покое там, где это уместно (токены, креды коннекторов, загруженные документы) и используйте TLS в транспортировке. Разделяйте операционные метаданные и контент, чтобы иметь возможность жёстче ограничивать доступ.
Практическая референс‑архитектура и чеклист для сборки
Полезный дефолт для AI‑приложений прост: бэкенд — источник правды, фронтенд — быстрый оптимистичный кэш. UI может выглядеть мгновенно, но всё, что вы бы расстроились потерять (сообщения, статус заданий, результаты инструментов, события, влияющие на биллинг), должно подтверждаться и сохраняться на сервере.
Если вы строите в workflow в стиле vibe‑кодинга — где большая часть продуктовой поверхности быстро генерируется — модель состояния становится ещё важнее. Платформы вроде Koder.ai помогают командам быстро выпустить целые веб‑, бэкенд‑ и мобильные приложения из чата, но правило остаётся: быстрая итерация безопасна, когда источники правды, идентификаторы и переходы статусов продуманы заранее.
Референс‑архитектура (та, что можно выпустить)
Фронтенд (браузер/мобильное)
- UI‑состояние: открытые панели, черновик подсказки, выбранная модель, временные индикаторы «печатает».
- Кэшированное серверное состояние: недавние разговоры, последний известный статус джобов, буфер частичного стрима.
- Единый pipeline запросов, который всегда прикрепляет:
session_id,conversation_idи новыйrequest_id.
Бэкенд (API + воркеры)
- API‑сервис: валидирует вход, создаёт записи, выдаёт стрим‑ответы.
- Долговечное хранилище (SQL/NoSQL): разговоры, сообщения, вызовы инструментов, статус заданий.
- Очередь + воркеры: долгие задачи (индексация RAG, парсинг файлов, генерация изображений).
- Кэш (опционально): горячие чтения (сводки разговоров, метаданные эмбеддингов), всегда с ключами версий/таймштампами.
Примечание: один практичный способ держать это последовательным — стандартизировать бэкенд‑стек рано. Например, Koder.ai‑сгенерированные бэкенды часто используют Go с PostgreSQL (а на фронтенде React), что упрощает централизацию авторитетного состояния в SQL, оставляя клиентский кэш сменяемым.
Спроектируйте модель состояния в первую очередь
Перед тем как строить экраны, определите поля, на которые вы будете опираться на каждом слое:
IDs и владение:user_id,org_id,conversation_id,message_id,request_id.Таймстемпы и порядок:created_at,updated_atи явнаяsequenceдля сообщений.Поля статуса:queued | running | streaming | succeeded | failed | canceled(для джобов и вызовов инструментов).Версионирование:etagилиversionдля безопасных обновлений с конфликтами.
Это предотвращает классическую ошибку, когда UI «выглядит правильно», но не может согласовать повторы, обновления или параллельные правки.
Делайте API консистентным
Поддерживайте предсказуемость эндпоинтов:
GET /conversations(list)GET /conversations/{id}(get)POST /conversations(create)POST /conversations/{id}/messages(append)PATCH /jobs/{id}(update status)GET /streams/{request_id}илиPOST .../stream(stream)
Возвращайте одинаковый формат (включая ошибки) везде, чтобы фронтенд мог унифицированно обновлять состояние.
Добавьте наблюдаемость в места, где состояние ломается
Логируйте и привязывайте request_id к каждому AI‑вызову. Записывайте входы/выходы вызовов инструментов (с редакцией), задержки, повторы и финальный статус. Делайте просто доступным ответ на вопрос: «Что видела модель, какие инструменты запускались и какое состояние мы сохранили?»
Чеклист разработки (чтобы избежать типичных багов со состоянием)
- Бэкенд — источник правды; кэш фронтенда явно помечен и сменяем.
- Каждая запись идемпотентна (безопасна для повтора) с
request_id(и/илиIdempotency-Key). - Переходы статусов явные и валидируемые (нет молчаливых прыжков из
queuedвsucceeded). - Стриминг‑обновления мёрджатся по ID/последовательности, а не по правилу «последнее сообщение побеждает».
- Конфликты обрабатываются через
version/etagили серверные правила слияния. - PII и секреты никогда не лежат в клиентском состоянии; логи по умолчанию редактируются.
- Есть единая панель для отладки: запросы, вызовы инструментов, статусы джобов и ошибки.
Когда вы переходите к более быстрым циклaм разработки (включая генерацию с помощью ИИ), подумайте о добавлении ограждений, которые будут автоматически обеспечивать эти пункты чеклиста — валидация схем, идемпотентность и событийный стриминг — чтобы "движение быстро" не оборачивалось дрейфом состояния. Практически это то место, где платформа end‑to‑end вроде Koder.ai может помочь: она ускоряет доставку, оставаясь при этом дающей возможность экспортировать код и поддерживать согласованные паттерны управления состоянием между web, бэкендом и мобильными клиентами.