Что решает приложение для управления устареванием
Устаревание функции — это любое плановое изменение, при котором то, на что полагаются пользователи, сокращается, заменяется или удаляется. Это может означать:
- Удаление или перемещение элемента интерфейса (кнопки, панели, настройки)
- Закрытие, версионирование или изменение поведения API-эндпоинта
- Изменение плана или прав (снижение лимитов, объединение дополнений, удаление тарифного уровня)
Даже если продукт движется в правильном направлении, устаревания проваливаются, когда их воспринимают как одноразовое объявление вместо управляемого рабочего процесса устаревания.
Частые сценарии отказа
Внезапные удаления — очевидная проблема, но реальный ущерб чаще проявляется иначе: сломанные интеграции, неполные инструкции по миграции, несогласованность сообщений в разных каналах и всплески обращений в поддержку сразу после релиза.
Команды также теряют контроль над тем, «кто затронут» и «кто что одобрял». Без журнала аудита трудно ответить на простые вопросы: какие аккаунты ещё используют старый флаг функции? Каким клиентам отправляли уведомления? Какая была обещанная дата?
Почему помогает выделенное приложение
Приложение для управления устареваниями централизуеt планирование снятия поддержки, чтобы у каждого устаревания был понятный владелец, таймлайн и статус. Оно обеспечивает согласованность коммуникаций (email, уведомления в приложении, автоматизация заметок о релизах), отслеживает прогресс миграции пользователей и создаёт ответственность через утверждения и журнал аудита.
Вместо разбросанных документов и таблиц вы получаете единую версию правды для обнаружения воздействия, шаблонов сообщений и аналитики принятия.
Кто этим пользуется
Product-менеджеры координируют объём и даты. Инженеры связывают изменения с флагами функций и релизами. Поддержка и Customer Success опираются на точные списки клиентов и сценарии общения. Соответствие и безопасность могут требовать утверждений, хранения уведомлений и доказательств информирования клиентов.
Цели, область и что не входит в задачу
Приложение для управления устареванием должно уменьшать хаос, а не добавлять ещё одно место для «проверки». Прежде чем проектировать экраны или модели данных, договоритесь, как выглядит успех и что явно не входит в зону ответственности.
Цели (что вы оптимизируете)
Начните с результатов, которые важны для Product, Support и Engineering:
- Меньше обращений и эскалаций из-за ломающих изменений (метрика: объём тикетов, привязанных к устареванию).
- Больше завершённых миграций до дедлайна (метрика: % мигрировавших по когорте/тарифу).
- Меньше отмен в последний момент из-за поздно обнаруженных рисков (метрика: число продлений сроков или откатов).
Преобразуйте это в чёткие показатели успеха и уровни обслуживания:
- Время от объявления → первого действия клиента
- Время от объявления → 80% миграции
- % мигрировавших к дедлайну (в целом и по приоритетным аккаунтам)
- SLA для коммуникаций: например, «Клиенты получают как минимум 30 дней уведомления при крупных удалениях.»
Область (что управляет приложение)
Будьте конкретны в отношении объекта устаревания. Можно начать узко и расширяться:
- Продуктные фичи (поведение UI, настройки)
- API-эндпоинты/поля
- Интеграции (вебхуки, коннекторы третьих сторон)
- Планы/тарифы (права, лимиты)
- Или единая модель «change», которая может представлять всё вышеуказанное
Также определите, что означает «миграция» в вашем контексте: включение новой фичи, переключение эндпоинта, установка новой интеграции или выполнение чеклиста.
Ограничения (правила, которые нельзя игнорировать)
Типичные ограничения, формирующие дизайн:
- Конфиденциальность и соответствие: какие данные пользователей можно хранить и показывать
- Хранение данных: срок ведения журнала аудита, экспорт, политики удаления
- Мультиарендность: сегментация по рабочим пространствам/организациям, региональное хостинг
- Утверждения: кто может публиковать таймлайны, отправлять сообщения клиентам или менять дедлайны
Что не делать (Non-Goals)
Чтобы избежать разрастания зоны ответственности, заранее решите, что приложение не будет делать — по крайней мере в v1:
- Не заменять вашу полноценную систему поддержки, сайт с документацией или CRM
- Не становиться общим инструментом управления проектами
- Не выполнять автоматическую миграцию клиентов без явных мер предосторожности и владельцев
Чёткие цели и границы упрощают принятие решений по рабочим процессам, разрешениям и уведомлениям.
Жизненный цикл устаревания и стадии рабочего процесса
Приложение должно делать жизненный цикл явным, чтобы все знали, что значит «хорошо» и что нужно сделать для перехода. Начните с картирования текущего процесса end-to-end: первоначальное объявление, запланированные напоминания, сценарии поддержки и окончательное удаление. Рабочий процесс приложения должен сначала отражать реальность, а затем постепенно стандартизироваться.
Простая исполнимая модель стадий
Практическая модель по умолчанию:
Proposed → Approved → Announced → Migration → Sunset → Done
У каждой стадии должно быть чёткое определение, критерии выхода и владелец. Например, «Announced» не должно означать «кто-то однажды опубликовал сообщение»; это значит, что объявление доставлено по согласованным каналам и запланированы последующие действия.
Контрольные точки, предотвращающие хаос в последний момент
Добавьте обязательные контрольные точки, которые нужно завершить (и зафиксировать) перед переводом стадии в завершённую:
- Юридическая/коммуникационная проверка формулировок, дат и договорных последствий
- Обновлённая документация (доки, FAQ, внутренние runbook)
- Готов план отката или смягчения, включая ответственного и способ исполнения
- Готовность поддержки, включая макросы/скрипты и пути эскалации
Обращайтесь с этими пунктами как с первоклассными объектами: чек-листы с исполнителями, сроками и доказательствами (ссылки на тикеты или документы).
Владение и подписи
Устаревания проваливаются, когда ответственность размыта. Определите, кто владеет каждой стадией (Product, Engineering, Support, Docs) и требуйте подписей при высоком риске — особенно при переходах Approved → Announced и Migration → Sunset.
Цель — лёгкий рабочий процесс в повседневности, но строгие правила в точках, где ошибки дорого обходятся.
Модель данных: сущности и связи
Чёткая модель данных предотвращает превращение устареваний в разбросанные доки, одноразовые сообщения и неясное владение. Начните с небольшого набора ключевых объектов и добавляйте поля только когда они реально помогают принимать решения.
Основные сущности
Feature — то, что видят пользователи (настройка, эндпоинт API, отчёт, рабочий поток).
Deprecation — ограниченное во времени событие изменения для фичи: когда объявляют, вводят ограничения и окончательно отключают.
Migration Plan объясняет, как пользователи должны перейти на замену и как вы будете измерять прогресс.
Audience Segment определяет, кто затронут (например, «аккаунты на плане X, использовавшие Feature Y за последние 30 дней»).
Message фиксирует, что вы отправите, куда и когда (email, in-app, баннер, макрос поддержки).
Обязательные поля (то, что пригодится позже)
Для Deprecation и Migration Plan сделайте обязательными:
- Таймлайны: дата объявления, мягкая дата (предупреждения/ограничения), жёсткая дата (sunset), плюс таймзона.
- Затронутые поверхности: области UI, маршруты API, страницы доков, интеграции, биллинг/права.
- Путь замены: ссылка на новую фичу, пошаговые заметки по миграции и известные ограничения.
- Уровень риска: низкий/средний/высокий с кратким обоснованием (например, «ломает автоматизацию для продвинутых пользователей»).
Связи (как всё соединяется)
Моделируйте реальную иерархию:
- Одна Feature → много Deprecations (несколько снятий со времени, региональные выкаты или изменения по политике).
- Одна Deprecation → обычно один Migration Plan, и много Audience Segments (разные сообщения и дедлайны).
- Одна Deprecation → много Messages (по каналам и стадиям), каждая опционально привязана к конкретному Audience Segment.
Поля аудита и управления
Добавьте поля аудита везде: created_by, approved_by, created_at, updated_at, approved_at, а также change history (кто что изменил и почему). Это даёт точный журнал аудита, когда поддержка, юристы или руководство спрашивают: «Когда мы это решили?»
Роли, права и утверждения
Чёткие роли и лёгкие утверждения предотвращают две частые ошибки: «все могут менять всё» и «ничего не выпускается, потому что никто не знает, кто решает». Проектируйте приложение так, чтобы ответственность была явной, и каждое внешне заметное действие имело владельца.
Ключевые роли
- Admin: управляет настройками рабочей области, ролями, глобальными шаблонами и правилами соответствия.
- Product Manager (PM): владеет планом устаревания, сроками, целевыми аудиториями и намерением сообщений.
- Engineer: выполняет технические шаги, подтверждает готовность и обновляет статус миграции.
- Support: отслеживает влияние на клиентов, пишет FAQ/макросы и эскалирует блокеры.
- Read-only: просматривает статусы, таймлайны и отчёты без прав на изменение.
Права по действиям
Модель прав вокруг ключевых действий, а не экранов:
- Создавать/редактировать записи устареваний (PM, Admin), с ограничением полей после утверждения.
- Утверждать планы, даты и изменения с высоким влиянием (Admin, назначенные утверждающие).
- Отправлять сообщения (PM/Support с утверждением) и редактировать шаблоны (Admin).
- Менять таймлайны (PM) с требованием утверждения для крупных сдвигов.
- Завершать (PM + подпись инженера) когда выполнены пороги миграции.
Потоки утверждений для изменений с высоким риском
Требуйте утверждений, когда изменение затрагивает много пользователей, регламентированных клиентов или критические рабочие процессы. Типичные точки: первоначальное утверждение плана, «готовность к объявлению» и финальное подтверждение «sunset/disable». Внешние коммуникации (email, баннеры, обновления справки) должны проходить через утверждение.
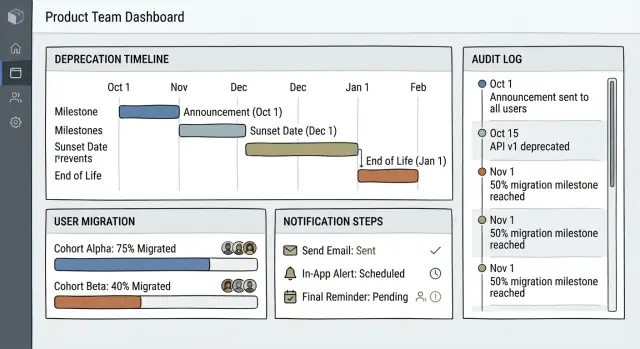
Требования к журналу аудита
Храните неизменяемый журнал аудита: кто, что, когда и почему изменил (включая содержимое сообщений, определение аудитории и правки таймлайна). Добавляйте ссылки на связанные тикеты и инциденты, чтобы постмортемы и проверки соответствия были быстрыми и фактичными.
UX: ключевые экраны и архитектура информации
Приложение выигрывает или проигрывает за ясность. Люди должны быстро ответить на три вопроса: Что меняется? Кто затронут? Что делать дальше? Информационная архитектура должна отражать этот поток, используя простой язык и согласованные шаблоны.
Дашборд: «командный центр»
Дашборд должен читаться за минуту. Сфокусируйтесь на текущей работе и рисках, а не на длинном инвентаре.
Покажите:
- Активные устаревания с текущей стадией (Announced → Migration → Removal)
- Ближайшие дедлайны (следующие 7/14/30 дней) с меткой «дней осталось»
- Высокорисковые элементы: большая аудитория, низкий процент миграции или отсутствующие утверждения
Держите фильтры простыми: Статус, Владелец, Продуктовая область, Окно дедлайна. Избегайте жаргона вроде «sunset state»; используйте «Планируемое удаление».
Страница деталей устаревания: единая версия правды
Каждому устареванию нужна каноническая страница, которой команды доверяют во время выполнения.
Структурируйте как таймлайн с первыми важными решениями и следующими шагами:
- Краткое резюме в шапке: имя, владелец, текущая стадия, дата удаления, ссылки на замену
- Таймлайн: дата объявления, начало миграции, cutoff, удаление (с редактируемыми вехами)
- Затронутые пользователи: ключевые сегменты, подсчёты и способ определения аудитории
- Сообщения и доки: уведомления в приложении, шаблоны писем, фрагмент для заметок о релизе и ссылки на документацию
Используйте короткие прямые ярлыки: «Фича-замена», «Кого это затронет», «Что нужно сделать пользователям».
Последовательность через шаблоны
Снижают ошибки, если предоставить шаблоны для:
- Стандартных таймлайнов (например, планы 30/60/90 дней)
- Чек-листов (утверждения, отправленные коммуникации, проинформированная поддержка, обновлённая документация)
- Шагов миграции (что меняется для пользователей, подсказки FAQ)
Шаблоны должны быть доступны при создании и видны на странице деталей как чек-лист.
Доступность и простота понимания по умолчанию
Минимизируйте когнитивную нагрузку:
- Пишите простым языком; избегайте внутренних акронимов
- Используйте высококонтрастные индикаторы статуса и читаемые форматы дат
- Обеспечьте навигацию с клавиатуры и смысловые заголовки для скринридеров
Хороший UX делает рабочий процесс неизбежным: следующий шаг всегда очевиден, и страница рассказывает одни и те же вещи продукту, инженерии, поддержке и клиентам.
Сегментация аудитории и обнаружение воздействия
Устаревание проваливается, когда вы уведомляете всех одинаково. Приложение должно ответить на два вопроса: кто затронут и насколько. Сегментация и обнаружение воздействия делают сообщения точными, уменьшают шум в поддержке и помогают приоритизировать миграции.
Источники сегментации (откуда берётся аудитория)
Начните с сегментов, которые соответствуют тому, как клиенты покупают, используют и эксплуатируют продукт:
- План / тариф (Free, Pro, Enterprise)
- Уровень использования (power users vs периодические пользователи)
- Тип интеграции (только API, только UI, конкретный коннектор)
- Регион / размещение данных (важно для тайминга и юридических ограничений)
- Возраст аккаунта (новые клиенты могли никогда не пользоваться старой фичей)
Рассматривайте сегменты как фильтры, которые можно комбинировать (например, «Enterprise + EU + использует API»). Сохраняйте определение сегмента для аудита позже.
Как вычислять «затронутые» (какие сигналы использовать)
Воздействие вычисляйте по конкретным сигналам, обычно:
- Логи использования фичи (feature toggles, посещения страниц, клики по кнопкам)
- API-вызовы (эндпоинты, связанные с устаревающей возможностью)
- UI-события (рабочие процессы, которые подразумевают зависимость)
Используйте временное окно («использовано за последние 30/90 дней») и порог («≥10 событий»), чтобы отделить активную зависимость от исторического шума.
Пограничные случаи
Общие окружения создают ложные срабатывания, если их не моделировать:
- Общие аккаунты / сервисные пользователи: атрибутируйте API-использование рабочему пространству или ключу интеграции, а не человеку.
- Несколько рабочих пространств: пользователь может быть затронут в одном пространстве, но не в другом.
- Администраторы vs конечные пользователи: администраторы нуждаются в ранних и подробных уведомлениях; конечные пользователи — в пошаговых инструкциях.
Предварительный просмотр перед отправкой
Перед любой рассылкой email или уведомлением в приложении предоставьте шаг предварительного просмотра, который показывает примерный список затронутых аккаунтов/пользователей, почему они были помечены (основные сигналы) и прогнозируемый охват по сегментам. Такая «сухая прогонка» предотвращает неловкие рассылки и повышает доверие к рабочему процессу.
Уведомления, сообщения и шаблоны
Большинство провалов связаны с тем, что пользователи либо не услышали об изменении, либо услышали слишком поздно. Рассматривайте сообщения как актив рабочего процесса: запланированные, подотчётные и адаптированные под сегмент.
Каналы для реальной доставки
Поддерживайте несколько каналов, чтобы команды могли достучаться до пользователей там, где те уже обращают внимание:
- Баннер в приложении для активных пользователей в нужный момент
- Email для более широкого охвата и подробных инструкций
- Webhooks для отправки событий во внутренние системы
- Slack (или подобные) для оповещений внутренних заинтересованных лиц
- Ссылка на статус-страницу (опционально) когда изменение влияет на доступность или надёжность
Каждое уведомление должно ссылаться на конкретную запись устаревания, чтобы получатели и команды могли проследить «что отправлено, кому и почему».
Каденция: от предупреждения до дедлайна
Заложите стандартный график, который команды могут корректировать для каждого случая:
- Announcement: что меняется и почему, плюс путь замены
- Reminders: в зависимости от оставшихся дней и активности пользователя (например, если он всё ещё использует старую фичу)
- Deadline warning: точная дата/время, последствия и варианты поддержки
- Final notice: подтверждение переключения и куда идти дальше
Шаблоны с переменными
Предоставьте шаблоны с обязательными полями и предпросмотром:
- Feature:
{{feature_name}}
- Deadline:
{{deadline}}
- Replacement:
{{replacement_link}} (например, /docs/migrate/new-api)
- CTA:
{{cta_text}} и {{cta_url}}
Контролирующие меры безопасности
Добавьте предохранители, чтобы предотвратить случайные массовые рассылки:
- Тестовые отправки внутренним аккаунтам и заранее заданным сегментам
- Ограничения по скорости и лимиты на арендатора
- Тихие часы по таймзонам
- Обработка отписок там, где это применимо (и альтернативные каналы, если пользователи отказались)
Отслеживание миграции и руководство для пользователей
План устаревания успешен, когда пользователи видят точно, что дальше делать, — и когда ваша команда может подтвердить, кто действительно перешёл. Рассматривайте миграцию как набор конкретных отслеживаемых шагов, а не как расплывчатое «обновитесь, пожалуйста».
Миграционные шаги в форме чек-листа
Моделируйте миграцию как маленький чек-лист с понятными результатами (а не просто инструкциями). Например: «Создать новый API-ключ», «Переключить инициализацию SDK», «Убрать вызовы старого эндпоинта», «Проверить подпись вебхука». Каждый шаг должен включать:
- Короткое описание и критерии «выполнено»
- Ссылки туда, где это делается (страница настроек, мастер или доки)
- Опциональную валидацию (например, обнаружение использования нового эндпоинта)
Держите чек-лист видимым на странице устаревания и в любом баннере в приложении, чтобы пользователи могли продолжить с того места, где остановились.
Руководство по миграции (помощь, а не домашняя работа)
Добавьте панель «guided migration», которая собирает всё, что пользователи обычно ищут:
- Соответствующие страницы документации (например, /docs/migrations/legacy-to-v2)
- Точки входа для мастера (например, /settings/integrations/new-setup)
- Примеры конфигураций и сниппеты для копирования
- Короткое FAQ с типичными ошибками и как безопасно откатиться
Это не только контент; это навигация. Самые быстрые миграции происходят, когда приложение направляет людей на нужный экран.
Отслеживание завершения с нужной детализацией
Отслеживайте завершение по аккаунту, рабочему пространству и интеграции (если применимо). Многие команды сначала мигрируют одно рабочее пространство, затем откатывают изменения поэтапно.
Храните прогресс как события и состояния: статус шага, метки времени, актор и обнаруженные сигналы (например, «v2 endpoints замечены за последние 24 ч»). Показывайте «% выполнено» и возможность детального разбора того, что блокирует.
Передача в поддержку с автоконтекстом
Когда пользователи застревают, сделайте эскалацию бесшовной: кнопка «Связаться с поддержкой» должна создавать тикет, назначать CSM (или очередь) и прикреплять контекст автоматически — идентификаторы аккаунта, текущий шаг, сообщения об ошибках, тип интеграции и недавняя активность миграции. Это сокращает переписку и ускоряет решение.