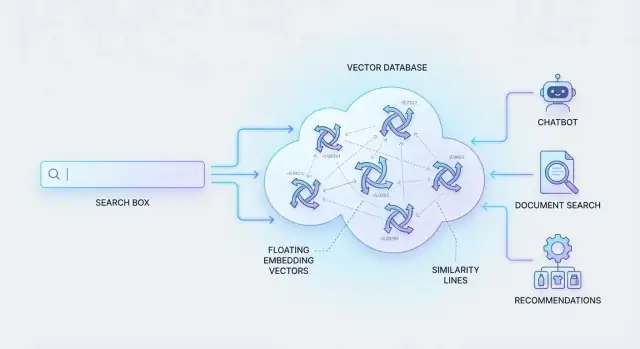
Что такое семантический поиск (без жаргона)
Семантический поиск — это способ поиска, который сосредоточен на том, что вы имеете в виду, а не только на точных словах из запроса.
Если вы когда‑нибудь искали что‑то и думали: «ответ же очевидно здесь — почему он не находит его?», — вы столкнулись с ограничениями поисков по ключевым словам. Традиционный поиск сопоставляет термины. Это работает, когда формулировка запроса и содержание совпадают.
Почему поиск по ключевым словам часто промахивается
Поиск по ключевым словам плохо справляется с:
- Синонимами и формулировками: «cancel» vs «close» vs «terminate» учётной записи.
- Интентом: «how do I stop being billed?» на самом деле про отмену подписки.
- Контекстом: «apple charger» (бренд) vs «apple tree charger» (абсурд, но идея ясна).
Он также может переоценивать страницы с повторяющимися словами, возвращая поверхностно релевантные результаты и игнорируя страницу, которая действительно отвечает на вопрос другими словами.
Простой пример
Представьте хелп-центр со статьёй под заголовком «Pause or cancel your subscription». Пользователь ищет:
“stop my payments next month”
Система по ключевым словам может не поднять эту статью высоко, если в ней нет слов «stop» или «payments». Семантический поиск понимает, что «stop my payments» тесно связано с «cancel subscription» и покажет статью выше — потому что совпадает смысл.
Где тут векторные базы
Чтобы это работало, системы представляют контент и запросы как «отпечатки смысла» (числа, которые фиксируют схожесть). Затем нужно быстро искать по миллионам таких отпечатков.
Именно для этого созданы векторные базы данных: они хранят эти числовые представления и эффективно возвращают самые похожие совпадения, чтобы семантический поиск казался мгновенным даже в больших масштабах.
Эмбеддинги: превращаем контент в значимые векторы
Эмбеддинг — это числовое представление смысла. Вместо описания документа ключевыми словами вы представляете его в виде списка чисел (вектора), который отражает, о чём этот контент. Два фрагмента с похожим смыслом окажутся близко друг к другу в этом числовом пространстве.
Как выглядит эмбеддинг на практике
Думайте об эмбеддинге как о координате на высокоразмерной карте. Вы обычно не будете читать эти числа — они не предназначены для человека. Их ценность в поведении: если «cancel my subscription» и «how do I stop my plan?» дают близкие векторы, система будет считать их связанными, даже если в тексте мало общих слов.
Текст, изображения и аудио тоже могут быть векторами
Эмбеддинги не ограничены текстом.
- Текстовые эмбеддинги — для предложений, абзацев, тикетов службы поддержки, описаний товаров и т.д.
- Эмбеддинги изображений — для визуального сходства и концептов (например, «красные кроссовки для бега»).
- Аудио-эмбеддинги — для представления говорящего, интонации или смысла произнесённых слов (в связке с моделями речи).
Так одна векторная база может поддерживать «поиск по картинке», «найти похожие песни» или «рекомендовать похожие товары».
Эмбеддинги генерируют модели — не пишут вручную
Векторы не появляются из ручной разметки. Их производят модели машинного обучения, обученные сжимать смысл в числа. Вы отправляете контент в модель эмбеддингов (хостите её сами или используете провайдера), она возвращает вектор. Ваше приложение хранит этот вектор вместе с исходным контентом и метаданными.
Почему выбор эмбеддинга влияет на качество и стоимость
Выбор модели эмбеддингов сильно сказывается на результатах. Более крупные или специализированные модели обычно дают лучше релевантность, но дороже и медленнее. Маленькие модели дешевле и быстрее, но могут упускать нюансы — особенно в узких доменных задачах, при мультиязычности или коротких запросах. Многие команды тестируют несколько моделей на ранних этапах, чтобы найти оптимум перед масштабированием.
Как векторные базы хранят данные
Векторная база строится вокруг простой идеи: хранить «смысл» (вектор) вместе с информацией, нужной для идентификации, фильтрации и показа результатов.
Базовая модель данных
Большинство записей выглядят так:
- ID: уникальный идентификатор под вашим контролем (например,
doc_18492 или UUID)
- Vector (embedding): массив чисел, представляющий смысл контента
- Metadata: поля ключ–значение: title, URL, tags, author, language, created_at, **tenant_id`
Например, статья хелп-центра может хранить:
- ID:
kb_123
- Vector: 768 чисел с плавающей точкой (для распространённой модели эмбеддингов)
- Metadata:
{"title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"]}
Вектор — то, что даёт семантическую схожесть. ID и метаданные — то, что делает результаты удобными.
Почему метаданные важнее, чем ожидают
Метаданные выполняют две роли:
- Фильтрация до/после векторного поиска: «показывать только результаты по продукту X», «только на английском», «только документы, доступные этому пользователю» или «только элементы моложе 90 дней». Это важно для релевантности и контроля доступа.
- Отображение и действия: пользователям не нужен вектор — им нужен заголовок, сниппет и ссылка. Метаданные дают UI нужные детали.
Без хороших метаданных вы можете найти правильный смысл, но показать неправильный контекст.
Распространённые размеры векторов и последствия для хранения
Размер эмбеддинга зависит от модели: 384, 768, 1024 и 1536 измерений — распространённые варианты. Больше измерений может захватывать нюансы, но увеличивает:
- Хранилище (каждая запись хранит больше чисел)
- Нагрузку на память для быстрого поиска
- Время построения индекса (особенно для ANN-индексации)
Простая интуиция: удвоение измерений часто повышает стоимость и задержку, если не компенсировать это индексацией или компрессией.
Паттерны обновления: вставки, изменения и удаления
Данные меняются, поэтому векторные базы обычно поддерживают:
- Insert: добавить новый контент с эмбеддингом и метаданными
- Update: изменить метаданные (например, теги) или заменить вектор, если контент изменился
- Delete: удалить устаревший или отозванный контент
- Re-embed: пересчитать векторы при смене модели эмбеддингов, изменении чанкинга или значительном редактировании текста
Планирование обновлений заранее предотвращает проблему «устаревших знаний», когда поиск возвращает контент, который больше не соответствует действительности.
Поиск по сходству: находить «близкий по смыслу» быстро
Когда текст, изображения или товары превращены в эмбеддинги, поиск становится геометрической задачей: «Какие векторы самые близкие к этому вектору запроса?» Это называется nearest-neighbor search. Вместо сопоставления ключевых слов система сравнивает смысл, измеряя, насколько близки два вектора.
Nearest neighbors простыми словами
Представьте каждый фрагмент контента как точку в огромном многомерном пространстве. Когда пользователь делает запрос, его текст превращается в ещё одну точку. Поиск по сходству возвращает элементы, точки которых ближе всего — ваши «ближайшие соседи». Эти соседи, скорее всего, разделяют интент, тему или контекст, даже если не совпадают слова.
Популярные метрики сходства
Векторные БД обычно поддерживают несколько способов оценить «близость»:
- Cosine similarity: сравнивает угол между векторами (хорошо, когда важна направленность/смысл больше, чем длина)
- Dot product: близко к косинусу, но учитывает длину вектора; часто используется с нормализованными эмбеддингами
- Euclidean distance: евклидово расстояние (полезно в некоторых моделях и доменах)
Разные модели эмбеддингов обучены с прицелом на конкретную метрику, поэтому важно использовать рекомендованную моделью метрику.
Точный поиск vs приближённый (ANN)
Точный поиск сверяет каждый вектор, чтобы найти истинных ближайших соседей. Это точно, но медленно и дорого при миллионах элементов.
Большинство систем используют approximate nearest neighbor (ANN). ANN применяет умные структуры индексации, чтобы сузить поиск до перспективных кандидатов. Результаты обычно «достаточно близки» к лучшим — но гораздо быстрее.
Трейд‑офф задержки и полноты
ANN популярен, потому что позволяет настраивать компромисс:
- Меньшая задержка (быстрее ответы) за счёт поиска меньшего числа кандидатов.
- Большая полнота (меньше шансов пропустить истинные лучшие совпадения) за счёт поиска большего числа кандидатов.
Именно эта настройка делает векторный поиск пригодным в продакшн‑приложениях: можно держать отклик быстрым и при этом возвращать релевантные результаты.
Сквозной рабочий процесс семантического поиска
Семантический поиск удобно представить как простой конвейер: вы превращаете текст в смысл, ищете похожие смыслы, затем показываете самые полезные совпадения.
1) Встраиваем запрос
Пользователь вводит вопрос (например: «How do I cancel my plan without losing data?»). Система пропускает текст через модель эмбеддингов и получает вектор — массив чисел, который отражает смысл запроса, а не его точную формулировку.
2) Поиск в векторной базе
Этот вектор запроса отправляется в векторную базу, которая выполняет поиск по сходству и находит «ближайшие» векторы среди сохранённого контента.
Большинство систем возвращают top-K совпадений: K самых похожих чанков/документов.
- Почему K настраиваем: меньшее K быстрее и часто достаточно (например, K=5).
- Большее K повышает полноту (меньше шансов пропустить правильный ответ), но может включать больше «почти релевантных» результатов (например, K=50).
3) (Опционально) Переранжирование для точности
Векторный поиск оптимизирован по скорости, поэтому начальный top-K может содержать близкие промахи. Реранкер — вторая модель, которая рассматривает запрос и каждый кандидат вместе и переставляет их по релевантности.
Думайте так: векторный поиск даёт сильный шорт-лист; реранжер выбирает лучший порядок.
4) Возврат результатов (или передача дальше)
Наконец вы возвращаете лучшие совпадения пользователю (как результаты поиска) или передаёте их AI‑ассистенту (например, в RAG‑системе) как «подкрепляющий» контекст.
Если вы строите такой конвейер в приложении, платформы вроде Koder.ai могут помочь прототипировать быстро: вы описываете семантический поиск или RAG‑опыт в чат‑интерфейсе, затем итеративно правите React фронт и Go/PostgreSQL бекенд, при этом конвейер извлечения (embed → vector search → optional rerank → answer) остаётся ключевой частью продукта.
Короткий пример «ключевые слова vs семантика»
Если статья хелп‑центра говорит «terminate subscription», а пользователь вводит «cancel my plan», поиск по ключевым словам может не найти совпадение из‑за разницы слов.
Семантический поиск обычно вернёт её, потому что эмбеддинг фиксирует, что обе фразы выражают один и тот же интент. Добавьте реранжирование — и топ‑результаты станут не просто «похожими», а прямо полезными для запроса пользователя.
Гибридный поиск и мета‑фильтры для лучших результатов
Сначала спланируйте пайплайн
Набросайте схему загрузки данных, разбиения и обновлений до того, как напишите хоть строчку кода.
Чисто векторный поиск отлично работает со «смыслом», но пользователи не всегда ищут по смыслу. Иногда нужен точный матч: полное имя человека, SKU, номер счёта или код ошибки. Гибридный поиск решает это, сочетая семантические сигналы (вектора) с лексическими (традиционный поиск типа BM25).
Что делает «гибридный поиск» на практике
Гибридный запрос обычно запускает два пути:
- Векторный поиск: находит концептуально похожий контент, даже если формулировки отличаются.
- Ключевой/BM25 поиск: находит контент с совпадающими токенами, вознаграждая точные термины и редкие слова.
Система затем объединяет кандидатов в единый ранжированный список.
Когда гибрид — лучший выбор по умолчанию
Гибрид полезен, когда в данных есть «must‑match» строки:
- Названия продуктов с модификаторами (например, «Pro Max», «Gen 2»)
- ID (номера заказов, тикетов, артикулы)
- Коды ошибок («E0421», «ORA-00933») и флаги команд
- Редкие терминологии домена, где синонимы рискованны
Семантика в одиночку вернёт широкие релевантные страницы; поиск по ключевым словам в одиночку может пропустить ответы, сформулированные иначе. Гибрид покрывает оба случая.
Использование мета‑фильтров для сужения пространства поиска
Мета‑фильтры ограничивают документооборот до ранжирования (или параллельно с ним), повышая релевантность и скорость. Частые фильтры:
- Язык (только английские документы)
- Диапазон дат (последняя политика, последние release notes)
- Категория или источник (доки vs тикеты; «billing» vs «security»)
- Теги доступа (только то, что пользователь может видеть)
Как работает скоринг (в общих чертах)
Большинство систем делают практический микс: запускают оба поиска, нормализуют оценки, чтобы их можно было сравнить, затем применяют веса (например, «сделать упор на ключевые слова для ID»). Некоторые продукты также реранжируют объединённый шорт‑лист лёгкой моделью или правилами, а фильтры гарантируют, что ранжируется правильное подмножество.
RAG: использование векторных баз для обоснования ответов LLM
Retrieval‑Augmented Generation (RAG) — практический шаблон, чтобы получить более надёжные ответы от LLM: сначала извлекайте релевантную информацию, затем генерируйте ответ, опираясь на найденный контекст.
Идея RAG в одном предложении
Вместо того, чтобы просить модель «помнить» ваши корпоративные документы, вы храните эти документы (в виде эмбеддингов) в векторной базе, извлекаете наиболее релевантные чанки во время запроса и передаёте их в LLM как поддерживающий контекст.
Почему векторная база снижает галлюцинации
LLM отлично генерируют текст, но при отсутствии фактов склонны уверенно выдумывать. Векторная база упрощает получение ближайших по смыслу фрагментов из вашей базы знаний и передачу их в prompt.
Это смещает модель от «придумывать ответ» к «обобщить и объяснить эти источники». Также это облегчает аудит, потому что вы можете отслеживать, какие чанки были извлечены и показывать цитаты.
Основы чанкинга (чтобы извлечение работало)
Качество RAG часто зависит скорее от чанкинга, чем от модели.
- Размер чанка: ориентируйтесь на чанки с завершённой мыслью (часто короткий раздел). Слишком маленькие теряют смысл; слишком большие тянут шум.
- Перекрытие: добавляйте небольшое перекрытие, чтобы важные детали на границах не отрывались от контекста.
- Сохраняйте контекст: храните заголовки, подзаголовки и идентификаторы (имя документа, раздел, дату) в метаданных, чтобы результаты были понятными и фильтруемыми.
Простой «диаграммный» поток RAG (описание)
Представьте такой поток:
User question → Embed question → Vector DB retrieve top-k chunks (+ optional metadata filters) → Build prompt with retrieved chunks → LLM generates answer → Return answer (and sources).
Векторная база — это «быстрая память», которая поставляет наиболее релевантные доказательства для каждого запроса.
Распространённые кейсы AI, которые питают векторные базы
От чата к приложению — весь цикл
Опишите желаемый UX, и Koder.ai сформирует структуру приложения за вас.
Векторные базы не просто делают поиск «умнее» — они открывают продуктовые сценарии, где пользователь может описать желаемое на естественном языке и получить релевантные результаты. Ниже несколько практических кейсов.
Поддержка клиентов: находить ответы вне ключевых слов
Команды поддержки часто имеют базу знаний, старые тикеты, транскрипты чатов и release notes — но поиск по ключевым словам плохо справляется с синонимами, парафразами и расплывчатыми формулировками проблем.
С семантическим поиском агент или чат‑бот может извлечь прошлые тикеты с тем же смыслом, даже если формулировки другие. Это ускоряет решение, уменьшает дублирование и помогает новым агентам быстрее вникнуть. Сочетание векторного поиска с мета‑фильтрами (линия продукта, язык, тип проблемы, диапазон дат) держит результаты в фокусе.
Поиск по каталогу: пользователи ищут на человеческом языке
Покупатели редко знают точные названия товаров. Они ищут по намерению, например: «маленький рюкзак для ноутбука и делового вида». Эмбеддинги фиксируют предпочтения — стиль, функцию, ограничения — и результаты кажутся ближе к человеческому консультанту.
Это работает для ретейла, путешествий, недвижимости, вакансий и маркетплейсов. Можно сочетать семантическую релевантность со структурными ограничениями: цена, размер, наличие, локация.
Рекомендации: «похожие товары» и открытие контента
Классическая функция векторной БД — «найти похожие элементы». Если пользователь смотрит товар, читает статью или смотрит видео, вы можете найти контент с похожим смыслом или атрибутами — даже когда категории не совпадают.
Полезно для:
- Модулей «Ещё похожее»
- Связанных статей и предложений из базы знаний
- Поиска дубликатов или почти‑дубликатов (контент‑модерация, очистка)
Внутренний поиск с учётом прав: политики, документы, заметки
Внутри компаний информация разбросана по докам, вики, PDF и заметкам. Семантический поиск помогает сотрудникам задавать вопросы естественно («Какая у нас политика по компенсации расходов на конференции?») и находить правильный документ.
Обязательная часть — контроль доступа. Результаты должны уважать права — часто через фильтрацию по команде, владельцу документа, уровню конфиденциальности или ACL — чтобы пользователь видел только то, что ему разрешено.
Если хотите развить это дальше, тот же слой извлечения питает RAG‑системы (описано выше).
Конвейеры данных: ingestion, chunking и обновления
Система семантического поиска хороша ровно настолько, насколько хорош конвейер, который её кормит. Если документы приходят неравномерно, чанкятся плохо или никогда не переобрабатываются после правок, результаты будут расходиться с ожиданиями пользователей.
Простой рабочий поток ingestion (который работает)
Большинство команд придерживается последовательности:
- Собрать данные (доки, PDF, тикеты, логи чатов, страницы вики, продуктовые данные).
- Очистить (убрать boilerplate, исправить кодировки, нормализовать пробелы, извлечь основной текст).
- Разбить на чанки (на удобные для извлечения фрагменты).
- Встроить (сгенерировать векторы выбранной моделью эмбеддингов).
- Upsert (записать векторы + метаданные в векторную базу, заменяя при необходимости).
Шаг «чанк» — где многие выигрывают или проигрывают. Чанки слишком большие размывают смысл; слишком маленькие теряют контекст. Практический подход — чанкать по естественной структуре (заголовки, абзацы, Q&A) и держать небольшой overlap для непрерывности.
Как поддерживать эмбеддинги актуальными
Контент постоянно меняется — политики обновляются, цены меняются, статьи переписываются. Обращайтесь с эмбеддингами как с производным слоем данных, который нужно пересчитать.
Типовые тактики:
- Храните ID исходного документа, chunk ID и хеш содержимого. Если хеш изменился — переоб embed этот чанк.
- Используйте soft deletes (отмечайте старые чанки неактивными), чтобы избежать «призрачных» результатов.
- Перестраивайте выборочно, а не всё подряд.
Batch vs streaming обновлений
- Batch подходит для больших backfill‑ов, ночных синков и предсказуемого контента (документация, базы знаний).
- Streaming подходит для быстро меняющихся источников (тикеты поддержки, UGC, инвентарь). Он уменьшает устаревание, но требует строгого мониторинга и контроля затрат.
Несколько языков и несколько моделей
Если вы обслуживаете несколько языков, можно либо использовать мультиязычную модель эмбеддингов (проще), либо модели по языкам (иногда качество выше). Если вы экспериментируете с моделями, версионируйте эмбеддинги (например, embedding_model=v3), чтобы проводить A/B и откаты без поломки поиска.
Как оценивать качество и производительность
Семантический поиск может «хорошо выглядеть» в демо и провалиться в продакшене. Разница в измерениях: нужны чёткие метрики релевантности и целевые показатели скорости, проверенные на реальных запросах.
Метрики релевантности, отражающие удовлетворённость
Начните с небольшого набора метрик и придерживайтесь их:
- Precision / Recall: Precision — сколько возвращённых результатов действительно релевантны; recall — сколько релевантных элементов удалось найти. Полезны при наличии чётких «релевантных» меток.
- MRR (Mean Reciprocal Rank): хорошо, когда ожидается один «лучший» ответ. Награждает размещение правильного документа ближе к верху.
- nDCG: полезен, когда несколько результатов могут быть релевантны в разной степени (очень релевантные vs умеренно релевантные).
- Latency (p50/p95): отслеживайте среднюю и хвостовую задержку. Быстрый p50 и медленный p95 всё равно создают ощущение тормозов.
Соберите тестовый набор, которому можно доверять
Создайте набор оценок из:
- Реальных запросов из логов поиска или тикетов (анонимизируйте)
- Ожидаемых документов (gold labels), согласованных экспертами домена
- Краевых случаев: короткие запросы, длинные вопросы, неоднозначные термины, редкие имена продуктов и запросы «ничего не найдено», где правильное поведение — признаться
Версионируйте тестовый набор, чтобы сравнивать релизы.
A/B тесты и петли обратной связи
Оффлайн‑метрик недостаточно. Запускайте A/B тесты и собирайте лёгкие сигналы:
- Палец вверх/вниз по результатам
- Click-through и dwell time
- События «refine search»
Используйте фидбек для обновления релевантных суждений и поиска паттернов сбоев.
Мониторинг дрейфа со временем
Производительность может измениться, когда:
- Вы меняете модель эмбеддингов или чанкинг
- Ваш корпус сдвигается (новые продукты, изменения политик, сезонные термины)
Перезапускайте тест‑сьют после любых изменений, мониторьте метрики еженедельно и ставьте алерты на резкие падения MRR/nDCG или скачки p95 задержки.
Безопасность, приватность и контроль доступа
Экономьте кредиты
Создавайте контент о Koder.ai или приглашайте коллег, чтобы продлить время разработки.
Векторный поиск меняет как данные извлекаются, но не должен менять кто имеет к ним доступ. Если система может «найти» правильный чанк, она также может случайно вернуть чанк, который пользователь не должен видеть — если вы не встроите права и приватность на этапе извлечения.
Контроль доступа: применять на этапе извлечения
Самое безопасное правило: пользователь должен извлекать только те данные, которые ему разрешено читать. Не полагайтесь на приложение, чтобы «скрыть» результаты после возврата из векторной базы — к тому моменту контент уже вышел из хранилища.
Практики:
- ACL на уровне документа/чанка: храните поля прав рядом с каждым вектором, чтобы каждый запрос мог их применять.
- Изоляция арендаторов: для multi‑tenant приложений разделяйте данные по tenant (логические партиции, namespace или отдельные индексы), чтобы избежать перекрёстного доступа.
Мета‑фильтры для прав доступа
Многие векторные БД поддерживают фильтры по метаданным (например, tenant_id, department, project_id, visibility), которые выполняются вместе с поиском. При правильном использовании это чистый способ применять права во время извлечения.
Важная деталь: фильтр должен быть обязательным и выполняться на сервере, а не опциональной логикой на клиенте. При сложной модели прав рассмотрите предвычисленные «эффективные группы доступа» или отдельный сервис авторизации, который выдаёт токен‑фильтр на время запроса.
PII и чувствительные данные: решите, что никогда не встраивать
Эмбеддинги кодируют смысл исходного текста. Это не обязательно раскрывает исходные PII, но повышает риск (например, чувствительные факты становятся легче доступными).
Практики:
- Избегайте встраивания сильно чувствительных полей (SSN, платёжные данные, медидентификаторы), если это возможно.
- Редактируйте перед эмбеддингом (заменяйте точные значения плейсхолдерами), если текст должен быть доступен в поиске.
- Храните оригиналы отдельно и возвращайте их только после проверки прав.
Операционные потребности: бэкапы, хранение и аудит
Обращайтесь с индексом как с продуктивными данными:
- Бэкапы и восстановление: индексы дорого перестраивать; планируйте снепшоты или путь восстановления из исходных данных.
- Политики хранения: удаляйте векторы при истечении срока хранения или по запросу пользователя.
- Аудит: логируйте, кто что запрашивал (хотя бы контекст запроса и возвращённые ID документов) для расследований и соответствия требованиям.
При правильной реализации эти практики делают семантический поиск «волшебным» для пользователей — без неприятных сюрпризов в области безопасности.
Подводные камни, затраты и практический чек‑лист выбора
Векторные базы могут казаться «plug‑and‑play», но большинство разочарований связаны со смежными решениями: как вы чанките данные, какую модель эмбеддингов выбираете и насколько надёжно поддерживаете актуальность данных.
Частые причины неудач (и как их заметить)
Плохой чанкинг — главная причина нерелевантных результатов. Если пользователи часто говорят «нашёл правильный документ, но не тот фрагмент», значит стратегия чанкинга нуждается в улучшении.
Неподходящая модель эмбеддингов проявляется как систематическое смещение релевантности — ответы хорошие по языку, но вне темы. Это случается, если модель не для вашего домена (юриспруденция, медицина, служба поддержки) или типа контента (таблицы, код, мультиязычность).
Устаревшие данные быстро подрывают доверие: пользователи ищут актуальную политику, а получают версию квартальной давности. Если исходный контент меняется, эмбеддинги и метаданные должны обновляться, а удаления реально удалять.
Cold‑start и обработка пустых результатов
В начале у вас может быть мало контента и слабые сигналы для настройки. Планируйте:
- Фоллбэки: поиск по ключевым словам или курируемые «топ‑ответы», когда семантические результаты слабые.
- UX для пустых результатов: показывайте родственные категории, задавайте уточняющий вопрос или расширяйте фильтры.
- Warm‑up запросы: протестируйте с набором репрезентативных вопросов перед запуском.
Драйверы затрат
Затраты обычно идут от четырёх вещей:
- Вычисления эмбеддингов (однажды для бэкафаила + для обновлений)
- Хранение (векторы, метаданные и индексы)
- Объём запросов (чтения, сетевой трафик, конкурентность)
- Реранжирование (опционально, но может добавить стоимость на каждый запрос)
При сравнении провайдеров попросите простой месячный расчёт на основе ожидаемого количества документов, среднего размера чанка и пикового QPS. Много сюрпризов возникает после индексации и при росте трафика.
Практический чек‑лист для выбора векторной базы
Короткий чек‑лист, чтобы выбрать базу, подходящую вам:
- Качество поиска: поддерживает ли гибридный поиск (ключевые слова + вектора) и мета‑фильтры? Можно ли добавить реранжер?
- Производительность: варианты ANN, предсказуемая задержка при пиковом трафике, простое масштабирование
- Операции с данными: upsert, delete, переиндексация, версионирование и backfill без даунтайма
- Наблюдаемость: логи запросов, метрики recall/latency и инструменты для отладки «почему этот результат»
- Безопасность: шифрование, изоляция арендаторов, ролевой доступ и фильтры по правам
- Интеграция: SDK, поддерживаемые языки и коннекторы к хранилищам (S3, БД, документы)
- Полная стоимость: прозрачное ценообразование для хранилища, записей, чтений и управляемых вычислений
Выбор — это не гонка за новым типом индекса, а про надёжность: сможете ли вы поддерживать данные свежими, контролировать доступ и сохранять качество по мере роста контента и трафика?