26 дек. 2025 г.·7 мин
Внутренние инструменты для разработчиков с Claude Code: безопасные CLI‑панели
Создавайте внутренние инструменты с Claude Code для поиска логов, управления флагами и проверок данных, одновременно применяя принцип наименьших привилегий и чёткие ограничения.
Какая проблема должна действительно решать ваш внутренний инструмент
Внутренние инструменты часто появляются как сократительный путь: одна команда или одна страница, которая экономит команде 20 минут во время инцидента. Риск в том, что тот же самый «краткий путь» тихо превращается в привилегированный бэкдор, если вы заранее не определите проблему и границы.
Команды обычно тянутся к инструменту, когда одна и та же боль повторяется каждый день, например:
- Поиск по логам, который медленный, непоследовательный или разбросан по разным системам
- Флаги функций, для которых требуется рискованное ручное изменение или прямая запись в базу данных
- Проверки данных, которые зависят от одного человека, запускающего скрипт с его ноутбука
- Задачи на дежурстве, простые, но легко сделать неправильно в 2:00 утра
Эти проблемы кажутся небольшими, пока инструмент не получит доступ к продакшен‑логам, не начнёт запрашивать данные клиентов или переключать флаг. Тогда вы столкнётесь с контролем доступа, аудитами и случайными записями. Инструмент «только для инженеров» всё равно может вызвать аварию, если выполнит широкий запрос, попадёт в неправильную среду или изменит состояние без явного подтверждения.
Определяйте успех в узких, измеримых терминах: ускорение операций без расширения прав. Хороший внутренний инструмент убирает шаги, а не защиту. Вместо того чтобы давать всем широкий доступ к базе данных, чтобы проверить предполагаемую проблему с биллингом, сделайте инструмент, который отвечает на один вопрос: «Покажи сегодняшние неудачные события биллинга для аккаунта X», используя только права на чтение и ограниченные учётные данные.
Прежде чем выбирать интерфейс, решите, что нужно людям в моменте. CLI хорош для повторяемых задач во время дежурства. Веб‑панель удобнее, когда результатам нужен контекст и совместная видимость. Иногда выпускают оба варианта, но только если это тонкие представления над одними и теми же охраняемыми операциями. Цель — одна хорошо определённая возможность, а не новая поверхность администратора.
Выберите одну боль и держите область небольшой
Самый быстрый способ сделать внутренний инструмент полезным (и безопасным) — выбрать одну ясную задачу и выполнить её хорошо. Если он попытается в первый же день обрабатывать логи, флаги функций, исправления данных и управление пользователями, в нём появятся скрытые поведения и сюрпризы.
Начните с одного вопроса, который пользователи задают в реальной работе. Например: «По ID запроса покажи ошибку и строки вокруг неё по всем сервисам.» Это узко, тестируемо и легко объяснимо.
Будьте конкретны, для кого инструмент. Разработчику, отлаживающему локально, нужны другие опции, чем дежурному, и оба отличаются от саппорта или аналитика. Смешивая аудитории, вы добавляете «мощные» команды, к которым большинству пользователей не стоит иметь доступ.
Запишите входы и выходы как небольшой контракт.
Входы должны быть явными: ID запроса, диапазон времени, среда. Выходы — предсказуемыми: совпавшие строки, имя сервиса, метка времени, счётчик. Избегайте скрытых побочных эффектов вроде «также очищает кэш» или «также ретритует задачу». Это те функции, которые приводят к авариям.
По умолчанию делайте доступ только для чтения. Поиск, diff, валидация и отчёты могут быть очень полезными без прав на запись. Добавляйте операции записи только тогда, когда вы можете назвать реальный сценарий, который этого требует, и жёстко его ограничить.
Простое заявление о сфере ответственности, которое держит команды в рамках:
- Одна основная задача, один основной экран или команда
- Один источник данных (или одно логическое представление), а не «всё подряд»
- Явные флаги для среды и диапазона времени
- Сначала только чтение, никаких фоновых действий
- Если есть записи — требуйте подтверждения и логируйте каждое изменение
Раннее картирование источников данных и чувствительных операций
Прежде чем Claude Code что‑то запишет, выпишите, с чем инструмент будет взаимодействовать. Большинство проблем безопасности и надёжности проявляются здесь, а не в UI. Рассматривайте эту карту как контракт: она показывает ревьюверам, что в рамках, а что — вне рамок.
Начните с конкретного инвентаря источников данных и их владельцев. Например: логи (app, gateway, auth) и где они хранятся; точные таблицы или представления базы данных, к которым инструмент может обращаться; хранилище флагов функций и правила именования; метрики и трейсы и какие метки безопасно использовать в фильтрах; и планируете ли вы записывать заметки в тикетную или инцидентную систему.
Затем назовите операции, которые инструменту разрешено выполнять. Избегайте разрешения «admin». Вместо этого определяйте проверяемые глаголы. Общие примеры: поиск и экспорт только для чтения (с лимитами), аннотация (добавление заметки без правки истории), переключение конкретных флагов с TTL, ограниченные бэкофиллы (по дате и числу записей) и режимы dry‑run, которые показывают воздействие без изменения данных.
Чувствительные поля требуют явной обработки. Решите, что должно быть замаскировано (почты, токены, session ID, API‑ключи, идентификаторы клиентов) и что можно показывать усечённо. Например: показывать последние 4 символа ID или хешировать его так, чтобы люди могли сопоставлять события без доступа к сырым данным.
Наконец, договоритесь о правилах хранения и аудита. Если пользователь запустил запрос или переключил флаг, записывайте, кто это сделал, когда, какие фильтры использовались и сколько результатов было получено. Храните записи аудита дольше, чем обычные логи приложения. Даже простое правило вроде «запросы хранятся 30 дней, записи аудита — 1 год» спасает от спорных обсуждений во время инцидента.
Модель доступа с принципом наименьших привилегий, которая остаётся простой
Наименьшие привилегии проще реализовать, если модель скучна. Начните с перечня того, что инструмент может делать, затем пометьте каждое действие как read‑only или write. Большинству людей для большинства функций нужен доступ только для чтения.
Для веб‑панели используйте существующую систему удостоверений (SSO с OAuth). Избегайте локальных паролей. Для CLI предпочитайте короткоживущие токены с быстрым истечением и скоупом только для нужных действий. Долгоживущие общие токены склонны попадать в тикеты, историю shell или копироваться на личные машины.
Держите RBAC небольшим. Если вам нужно больше, чем несколько ролей, вероятно инструмент делает слишком много. Многие команды обходятся тремя ролями:
- Viewer: только чтение, безопасные настройки по умолчанию
- Operator: чтение плюс небольшой набор низкорисковых действий
- Admin: действия с высоким риском, используются редко
Разделяйте среды с самого начала, даже если UI выглядит одинаково. Сделайте так, чтобы «случайно сделать в проде» было сложно. Используйте разные учётные данные для каждой среды, разные файлы конфигурации и разные API‑эндпоинты. Если пользователь поддерживает только staging, он вообще не должен уметь аутентифицироваться в production.
Действия с высоким риском заслуживают шага утверждения. Подумайте о удалении данных, смене флагов функций, перезапуске сервисов или выполнении тяжёлых запросов. Добавьте проверку со вторым участником, когда радиус поражения велик. Практичные подходы: подтверждения с вводом текста, включающего цель (имя сервиса и среду), запись, кто запросил и кто одобрил, и небольшой отложенный запуск или окно выполнения для самых опасных операций.
Если вы генерируете инструмент с Claude Code, сделайте правилом, чтобы каждый endpoint и команда объявляли требуемую роль заранее. Такая привычка делает проверки прав легкими по мере роста инструмента.
Ограждения, которые предотвращают ошибки и тяжёлые запросы
Итерации без сюрпризов
Держите эксперименты изолированными, пока вы итеративно улучшаете область, валидацию и безопасные настройки.
Самый частый режим сбоя внутренних инструментов — это не злоумышленник, а уставший коллега, который запускает «правильную» команду с неправильными входами. Рассматривайте ограждения как продуктовую функцию, а не косметику.
Безопасные настройки по умолчанию
Начните с безопасной позиции: по умолчанию только чтение. Даже если пользователь — админ, инструмент должен открываться в режиме только для выборки данных. Делайте операции записи явными и очевидными.
Для любой операции, изменяющей состояние (переключение флага, бэкофилл, удаление записи), требуйте ввода‑подтверждения с набором текста. «Вы уверены? y/N» слишком легко нажимается по привычке. Попросите пользователя перепечатать что‑то конкретное, например имя среды плюс целевой ID.
Строгая валидация входных данных предотвращает большинство катастроф. Принимайте только те формы, которые вы действительно поддерживаете (ID, даты, среды) и отвергайте всё остальное на ранней стадии. Для поисков ограничивайте мощь: ставьте лимиты на результаты, требуйте разумных диапазонов времени и используйте allow‑list вместо произвольных паттернов для вашего лог‑хранилища.
Чтобы избежать безконтрольных запросов, добавьте таймауты и лимиты по частоте. Безопасный инструмент быстро падает с объяснением, вместо того чтобы зависать и бить по базе данных.
Набор ограждений, который хорошо работает на практике:
- По умолчанию только чтение, с явным переключателем в режим записи
- Ввод‑подтверждение для записи (включая env + target)
- Строгая валидация ID, дат, лимитов и допустимых паттернов
- Таймауты запросов и лимиты на пользователя
- Маскирование секретов в выводе и в собственных логах инструмента
Гигиена вывода
Считайте, что вывод инструмента будут копировать в тикеты и чаты. Маскируйте секреты по умолчанию (токены, cookies, API‑ключи и при необходимости почты). Также очищайте то, что вы храните: логи аудита должны фиксировать, что было запрошено, а не сырые возвращённые данные.
Для дашборда поиска логов возвращайте короткий превью и счётчик, а не полный полезный груз. Если кто‑то действительно нуждается в полном событии, сделайте отдельное, явно охраняемое действие с собственным подтверждением.
Как работать с Claude Code, не теряя контроля
Относитесь к Claude Code как к быстрому младшему коллеге: полезному, но не телепатичному. Ваша задача — держать работу ограниченной, проверяемой и отменяемой. Это разница между инструментами, которые кажутся безопасными, и инструментами, которые вас будят в 2:00 утра.
Начните со спецификации, которой модель может следовать
Прежде чем просить код, напишите небольшую спецификацию, которая называет действие пользователя и ожидаемый результат. Держите её про поведение, а не про детали фреймворков. Хорошая спецификация обычно помещается на половину страницы и охватывает:
- Команды или экраны (точные имена)
- Входы (флаги, поля, форматы, лимиты)
- Выходы (что показывается, что сохраняется)
- Ошибки (некорректный ввод, таймауты, пустые результаты)
- Проверки прав (что происходит, когда доступ запрещён)
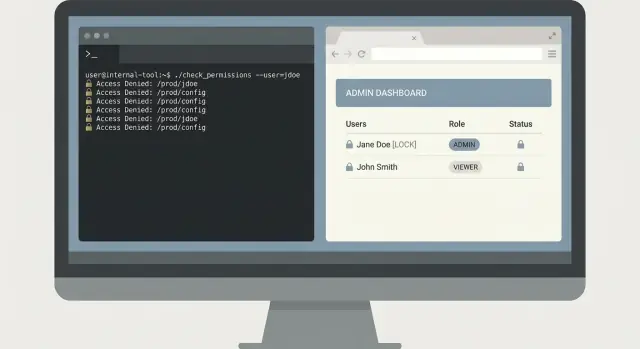
Например, для CLI поиска логов определите одну команду целиком: logs search --service api --since 30m --text \"timeout\", с жёстким лимитом результатов и понятным сообщением «доступ запрещён».
Просите небольшими шагами, которые можно проверить
Запросите сначала скелет: wiring CLI, загрузку конфигурации и заглушку для вызова данных. Затем попросите одну завершённую функцию целиком (включая валидацию и ошибки). Небольшие изменения делают ревью реальным.
После каждого изменения просите объяснение простым языком, что изменилось и почему. Если объяснение не совпадает с патчем, остановитесь и переформулируйте поведение и ограничения безопасности.
Генерируйте тесты рано, ещё до добавления новых функций. Как минимум, покройте позитивный сценарий, некорректные входы (плохие даты, отсутствие флагов), отказ по правам, пустые результаты и таймауты или лимиты бэкенда.
CLI против веб‑дашборда: выбор правильного интерфейса
CLI и внутренняя веб‑панель могут решать одну и ту же задачу, но падать по‑разному. Выбирайте интерфейс, в котором безопасный путь — самый легкий путь.
CLI обычно лучше, когда важна скорость и пользователь уже знает, чего хочет. Он также хорошо подходит для read‑only сценариев, потому что вы можете держать права узкими и избегать кнопок, которые случайно запускают записи.
CLI — хороший выбор для быстрых on‑call запросов, скриптов и автоматизации, явных следов аудита (каждая команда расписана) и простого развёртывания (один бинарник, одна конфигурация).
Веб‑панель удобнее, когда нужна коллективная видимость или пошаговое руководство. Она может уменьшать ошибки, подталкивая людей к безопасным настройкам по умолчанию (диапазоны времени, среда, предустановленные действия). Дашборды также полезны для командных обзоров состояния, охраняемых действий с подтверждениями и встроенных объяснений назначения кнопок.
Когда возможно, используйте один бэкенд‑API для обоих клиентов. Поместите авторизацию, лимиты, ограничения запросов и логирование аудита в API, а не в UI. Тогда CLI и панель будут лишь разными клиентами с разной эргономикой.
Также решите, где это запускается, потому что это меняет риск. CLI на ноутбуке может утечь вместе с токенами. Запуск на бастионе или внутри внутреннего кластера снижает экспозицию и упрощает логи и применение политик.
Пример: для поиска логов CLI отлично подходит дежурному инженеру, который тянет последние 10 минут для одного сервиса. Панель лучше подходит для совместной комнаты инцидента, где всем нужен один и тот же фильтрованный вид и шаг «экспорт для постмортема», проверяемый по правам.
Реалистичный пример: инструмент поиска логов для on‑call
Спланируйте до того, как строить
Спроектируйте входы, выходы и права доступа до генерации кода.
Сейчас 02:10, и дежурный получает отчёт: «При оплате иногда падает для одного клиента». Саппорт прислал скриншот с ID запроса, но никто не хочет вставлять случайные запросы в систему логов с админскими правами.
Небольшой CLI может эффективно решить это. Главное — держать его узким: быстро найти ошибку, показать только нужное и не менять данные продакшена.
Минимальный поток в CLI
Начните с одной команды, которая требует границ по времени и конкретного идентификатора. Требуйте ID запроса и окно времени, по умолчанию ставьте короткое окно.
oncall-logs search --request-id req_123 --since 30m --until now
Сначала возвращайте сводку: имя сервиса, класс ошибки, количество и три топ‑сообщения. Затем разрешайте явный шаг расширения, который выводит полные строки логов только по запросу пользователя.
oncall-logs show --request-id req_123 --limit 20
Такой двухшаговый дизайн предотвращает случайные дампы данных. Он также облегчает ревью, потому что инструмент имеет ясный безопасный путь по умолчанию.
Дополнительное действие (без записей)
Дежурному часто нужно оставить след для следующего человека. Вместо записи в базу добавьте опцию, которая формирует полезную нагрузку для заметки в тикете или применяет тег в системе инцидентов, но никогда не трогает записи клиентов.
Чтобы сохранить принцип наименьших привилегий, CLI должен использовать readonly‑токен для логов и отдельный, ограниченный токен для действия с тикетом или тегом.
Храните запись аудита для каждого запуска: кто выполнил, какой был ID запроса, какие были временные границы и расширял ли он детали. Этот лог аудита — ваша подушка безопасности, когда что‑то идёт не так или нужен разбор доступа.
Распространённые ошибки, создающие проблемы с безопасностью и надёжностью
Небольшие внутренние инструменты часто начинаются как «быстрая помощница». Именно поэтому они обретают рискованные настройки. Самый быстрый способ потерять доверие — один плохой инцидент, например инструмент, который удаляет данные, хотя должен был только читать.
Чаще всего встречаются следующие ошибки:
- Дать инструменту права записи в продакшен базу, когда ему нужны только чтения, и полагаться на «будем осторожны»
- Пропустить трассировку аудита, так что позже нельзя ответить, кто запускал команду, какие входы использовал и что изменилось
- Разрешать произвольный SQL, regex или ad‑hoc фильтры, которые случайно просканируют огромные таблицы или логи и выведут систему из строя
- Смешивать среды так, что staging‑действия доходят до production из‑за общих конфигураций, токенов или базовых URL
- Печатать секреты в терминал, консоль браузера или логи, а затем забывать, что эти выводы копируются в тикеты и чаты
Реалистичная авария выглядит так: дежурный использует CLI поиска логов во время инцидента. Инструмент принимает любой regex и шлёт его в лог‑бэкенд. Один тяжёлый паттерн выполняется на часах высокого трафика, взрывает стоимость и замедляет все поиски. В той же сессии CLI выдал API‑токен в debug‑выводе, и он оказался вставлен в публичный документ инцидента.
Безопасные настройки по умолчанию, которые предотвращают большинство инцидентов
Рассматривайте read‑only как реальную границу безопасности, а не привычку. Используйте разные учётные записи для каждой среды и отдельные сервисные аккаунты для каждого инструмента.
Пара ограждений делает большую часть работы:
- Используйте allow‑list запросов (или шаблоны) вместо сырого SQL и ограничивайте диапазоны времени и число строк
- Логируйте каждое действие с request ID, идентичностью пользователя, целевой средой и точными параметрами
- Требуйте явного выбора среды, с громким подтверждением для production
- Маскируйте секреты по умолчанию и отключайте debug‑вывод, если не использован привилегированный флаг
Если инструмент не может по дизайну сделать что‑то опасное, команде не придётся полагаться на идеальное внимание ночью.
Бычный чек‑лист перед релизом инструмента
Поместите логику за API
Разверните сервис на Go и PostgreSQL, чтобы сосредоточить охраняемые операции за одним API.
Перед тем как дать инструмент реальным пользователям (особенно on‑call), относитесь к нему как к production‑сервису. Подтвердите, что доступ, права и ограничения реальны, а не подразумеваемы.
Начните с доступа и прав. Многие инциденты происходят потому, что «временный» доступ становится постоянным или инструмент тихо получает права записи со временем.
- Аутентификация и отписка: подтвердите, кто может войти, как даётся доступ и как его отзывают в тот же день, когда человек меняет команду
- Роли держите маленькими: 2–3 роли максимум (viewer, operator, admin) и запишите, что каждая может делать
- По умолчанию только чтение: просмотр — путь по умолчанию, для всего, что меняет данные, нужен явный отдельный роль
- Обращение с секретами: храните токены и ключи вне репозитория и убедитесь, что инструмент их не печатает в логах или ошибках
- Break‑glass: если нужен экстренный доступ, делайте его временным и логируйте
Затем проверьте ограждения, которые предотвращают типичные ошибки:
- Подтверждения для рискованных действий: требуйте ввода текста для удаления, бэкофиллов и изменений конфигурации
- Лимиты и таймауты: ограничьте размер результатов, заставляйте диапазоны времени и прерывайте запросы, чтобы плохой запрос не выполнялся вечно
- Валидация входов: проверяйте ID, даты и имена сред; отвергайте всё, что похоже на «выполнить везде»
- Аудит‑логи: записывайте кто, что и откуда; делайте логи удобными для поиска во время инцидента
- Базовые метрики и ошибки: отслеживайте успешность, задержки и типичные ошибки, чтобы заметить поломки раньше
Делайте контроль изменений как для любого сервиса: peer review, пара целевых тестов для опасных путей и план отката (включая способ быстро отключить инструмент при проблемах).
Следующие шаги: безопасный rollout и непрерывное улучшение
Относитесь к первому релизу как к контролируемому эксперименту. Начните с одной команды, одного рабочего процесса и небольшого набора реальных задач. Инструмент поиска логов для on‑call — хороший пилот, потому что вы легко измеряете сэкономленное время и быстро замечаете рискованные запросы.
Держите rollout предсказуемым: пилотируйте с 3–10 пользователями, стартуйте в staging, ограничьте доступ ролями с наименьшими правами (не общими токенами), выставьте явные лимиты и записывайте аудит‑логи для каждой команды или нажатия кнопки. Убедитесь, что можно быстро откатить конфигурацию и права.
Запишите контракт инструмента простым языком. Перечислите каждую команду (или действие на панели), разрешённые параметры, что значит успех и что означают ошибки. Люди перестают доверять внутренним инструментам, когда выводы кажутся неоднозначными, даже если код правильный.
Добавьте обратную связь, которую вы реально проверяете. Отслеживайте медленные запросы, частые фильтры и опции, которые путают людей. Когда вы видите повторяющиеся обходные пути, это часто знак, что интерфейсу не хватает безопасного дефолта.
Обслуживание требует владельца и расписания. Решите, кто обновляет зависимости, кто вращает учётные данные и кто получает страницу, если инструмент ломается во время инцидента. Проверяйте изменения, сгенерированные AI, как любой production‑код: диффы прав, безопасность запросов и логирование.
Если ваша команда предпочитает итерации через чат, Koder.ai (koder.ai) может быть практичным способом сгенерировать небольшой CLI или панель из разговора, хранить снимки известных рабочих состояний и быстро откатываться, когда изменение приносит риск.