Что вы строите: веб‑приложение IDP простыми словами
Веб‑приложение IDP — это внутреннее «главное окно» в вашу инженерную систему. Это место, куда разработчики приходят, чтобы обнаружить, что уже есть (сервисы, библиотеки, окружения), следовать предпочитаемому способу сборки и запуска ПО и запрашивать изменения без поиска по десятку разных инструментов.
Не менее важно: это не ещё одна замена для Git, CI, облачных консолей или тикетинга. Цель — снизить трение, оркестрируя то, что вы уже используете — сделать правильный путь самым простым.
Проблемы, которые он должен решить
Большинство команд строят IDP, потому что повседневная работа замедляется из‑за:
- Разрастания инструментов: знание «куда нажать» живёт в племенной памяти.
- Медленного онбординга: новые инженеры недели тратят на изучение процесса вместо доставки.
- Несогласованных стандартов: сервисы создаются и эксплуатируются по‑разному, что усложняет надёжность и безопасность.
Веб‑приложение должно превратить это в повторяемые рабочие процессы и понятную, индексируемую информацию.
Основные блоки
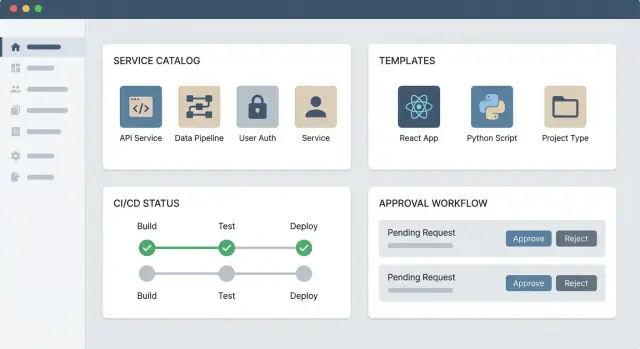
Практическое веб‑приложение IDP обычно состоит из трёх частей:
- Портал (UI): каталог сервисов, точки входа в документацию и формы самообслуживания (например, «создать сервис», «запросить доступ», «предоставить базу данных»).
- Backend API: бизнес‑логика, которая валидирует запросы, применяет политику и записывает действия.
- Интеграции: коннекторы к вашей цепочке инструментов (хостинг Git, CI/CD, инструменты инфраструктуры, хранилища секретов, управление инцидентами), чтобы действия происходили в системах учёта.
Кто за это отвечает (и кто нет)
Платформенная команда обычно отвечает за продукт портала: опыт, API, шаблоны и ограждения.
Продуктовые команды владеют своими сервисами: поддерживают метаданные актуальными, документацию/рукбуки и принимают предоставленные шаблоны. Здоровая модель — совместная ответственность: платформа строит «асфальтированную дорогу», а продуктовые команды на ней ездят и помогают улучшать её.
Пользователи, кейсы и метрики успеха
IDP‑приложение успешное тогда, когда оно обслуживает нужных людей и даёт правильные «happy paths». До выбора инструментов или рисунков архитектуры определите, кто будет пользоваться порталом, чего хочет добиться и как будете измерять прогресс.
Основные пользователи (и что им важно)
Большинство порталов имеют четыре ключевые аудитории:
- Разработчики приложений: хотят быстрые, безопасные настройки по умолчанию, чтобы создавать и запускать сервисы без ожидания тикетов.
- SRE / ops: хотят стандартизацию, меньше неожиданных изменений и чёткую ответственность при инцидентах.
- Безопасность / соответствие: хотят консистентные контролы (ревью доступа, обработка секретов, журналы аудита) без блокирования доставки.
- Менеджеры инженерных команд / продукт‑лиды: хотят видимость — что есть, кто за это отвечает и поставляют ли команды стабильно.
Если вы не можете описать выгоду для каждой группы в одном предложении, скорее всего вы строите портал, который будет восприниматься как опциональный.
Отобразите 5–10 ключевых путешествий
Выбирайте путешествия, которые происходят еженедельно (а не ежегодно), и делайте их сквозными:
- Создать новый сервис из шаблона (репозиторий + CI + владение + теги).
- Запросить окружение (dev/stage) с ограждениями.
- Просмотреть состояние сервиса (статус деплоя, алерты, зависимости).
- Повернуть ключи / секреты через аудируемый workflow.
- Запросить доступ к системе или данным с одобрениями.
Опишите каждое путешествие как: триггер → шаги → задействованные системы → ожидаемый результат → режимы отказа. Это станет вашим бэклогом продукта и критериями приёмки.
Определите измеримые метрики успеха
Хорошие метрики напрямую связаны со временем экономии и устранённым трением:
- Time-to-first-deploy для нового сервиса (медиана, p90).
- Объём ручных тикетов для типичных запросов (и время до решения).
- Уровень принятия: % зарегистрированных сервисов, % команд, использующих шаблоны.
- Change failure rate и mean time to restore (если портал стандартизирует доставку).
Напишите краткое заявление о зоне ответственности «версия 1»
Держите это коротким и на виду:
V1 scope: «Портал, который позволяет разработчикам создать сервис из утверждённых шаблонов, зарегистрировать его в каталоге сервисов с владельцем и показать статус деплоя + здоровье. Включает базовый RBAC и журналы аудита. Не включает кастомные дашборды, полную замену CMDB и уникальные рабочие процессы.»
Это заявление — ваш фильтр от feature‑creep и якорь дорожной карты для следующего этапа.
MVP: объём и дорожная карта для внутреннего портала
Портал успешен, когда решает одну болезненную проблему end‑to‑end, а затем заслуживает расширения. Самый быстрый путь — узкий MVP, отданный реальной команде за недели, а не кварталы.
Узкий MVP, который всё равно ощущается «завершённым»
Начните с трёх блоков:
- Каталог сервисов: одно место, чтобы найти, что есть, кто владеет и где ссылки на операционные инструменты.
- Один workflow самообслуживания: выберите частотный запрос (например, «создать новое репо сервиса» или «предоставить стандартное окружение») и автоматизируйте его.
- Хаб с доками/ссылками: не мигрируйте всё — делайте ссылки на существующие источники правды (CI/CD, инструменты инцидентов, рукбуки) пока учитесь, что реально используют люди.
Этот MVP маленький, но даёт понятный результат: «Я могу найти свой сервис и выполнить одно важное действие без запроса в Slack.»
Если вам нужно быстро валидировать UX и happy path рабочего процесса, платформа для быстрой генерации интерфейсов вроде Koder.ai может помочь прототипировать UI портала и экраны оркестрации по спецификации рабочего процесса. Поскольку Koder.ai может сгенерировать React‑приложение с бэкендом на Go + PostgreSQL и поддерживает экспорт исходников, команды могут быстро итератировать и при этом сохранить долгосрочное владение кодовой базой.
Структура бэклога: обнаруживать, создавать, эксплуатировать, управлять
Чтобы дорожная карта оставалась организованной, группируйте работу в четыре корзины:
- Discover: поиск, теги, владение, страницы команд, представления зависимостей.
- Create: шаблоны, скелет проекта, provisioning окружений, стандартные конфиги.
- Operate: ссылки на дашборды/рукбуки, on‑call, сводки SLO, общие операции.
- Govern: RBAC, шаги одобрения, журналы аудита, проверки политик.
Эта структура предотвращает ситуацию, когда портал — «только каталог» или «только автоматизация» без связующего звена.
Автоматизировать сейчас или ссылаться наружу
Автоматизируйте только то, что соответствует хотя бы одному критерию: (1) повторяется еженедельно, (2) склонно к ошибкам при ручном выполнении, (3) требует координации нескольких команд. Всё остальное может быть хорошо подобранной ссылкой на нужный инструмент с чёткими инструкциями и ответственностью.
Прогрессивное улучшение без редизайна
Проектируйте портал так, чтобы новые рабочие процессы подключались как дополнительные «действия» на странице сервиса или окружения. Если каждый новый workflow требует переделки навигации, принятие остановится. Рассматривайте рабочие процессы как модули: единообразные входы, единообразный статус, единообразная история — чтобы можно было добавлять новые сценарии, не ломая ментальную модель.
Справочная архитектура: UI, API и интеграции
Практичная архитектура портала IDP упрощает UX, одновременно надёжно обрабатывая «грязную» интеграционную работу в фоне. Цель — дать разработчикам одно веб‑приложение, даже если действия охватывают Git, CI/CD, облака, тикетинг и Kubernetes.
Выберите модель деплоя
Есть три распространённых паттерна, и правильный выбор зависит от того, как быстро нужно поставлять и сколько команд будут расширять портал:
- Монолитное приложение: самый быстрый MVP. UI, API и интеграционная логика идут вместе. Хорошо, когда платформная команда владеет большинством функций.
- Модульные сервисы: разделённые UI, ядро API и несколько сервисов‑интеграторов. Проще масштабирование и понятнее зоны ответственности по мере роста.
- Плагин‑подход: стабильное «ядро» плюс плагины для источников каталога, scaffolding, доков и рабочих процессов. Лучший вариант, когда много команд вносят функции.
Основные компоненты (что где исполняется)
Минимально ожидайте следующие блоки:
- Web UI (портал разработчика): просмотр каталога, золотые пути, формы, страницы статуса.
- Backend API (за API‑gateway): аутентификация, проверки RBAC, валидация, оркестрация.
- Integration workers: долгоживущие задачи (создание репо, provision окружения, настройка CI) выполняемые асинхронно.
- База данных: конфигурация портала, кэшированные представления каталога, история workflow, события аудита.
Где хранится состояние
Решите рано, что портал «владеет», а что только отображает:
- Держите источники правды в существующих системах (Git, облачные IAM, CI/CD, Kubernetes, тикетинг).
- Храните в БД портала: запросы workflow, статусы, одобрения, журналы аудита и кэш‑индексы для быстрой работы UI.
Надёжность интеграций
Интеграции падают по обычным причинам (лимиты, временные сбои, частичные успехи). Проектируйте для:
- Ретраев с backoff и понятных сообщений об ошибках
- Идемпотентности (повторный запуск не должен создавать дубликаты)
- Таймаутов и отмены
- Долговечной истории workflow, чтобы пользователи видели, что произошло, и могли безопасно восстановиться
Модель данных: каталог сервисов и владение
Ваш каталог сервисов — источник правды о том, что есть, кто владеет и как это вписывается в систему. Чёткая модель данных предотвращает «мистические сервисы», дубли и сломанные автоматизации.
Определите сущность «Сервис»
Сначала договоритесь, что в вашей организации означает «сервис». Для большинства команд это деплойable единица (API, воркер, сайт) с жизненным циклом.
Минимально моделируйте поля:
- Название + описание (читаемое для людей)
- Владельцы: основная команда и вторичные контакты (on‑call, tech lead)
- Исходные репозитории: один или несколько ссылок/ID репозиториев
- Окружения выполнения: dev/stage/prod или регионально-специфичные варианты
- Зависимости: upstream/downstream сервисы и общие библиотеки
Добавьте практичную метаинформацию, которая питает портал:
- Жизненный цикл (experimental, active, deprecated)
- Критичность/уровень (для ожиданий поддержки и управления)
- Ссылки (рукбуки, дашборды, SLO, канал инцидентов)
Моделируйте отношения явно
Отношения должны быть первоклассными, не просто текстовыми полями:
- Services ↔ teams: у команды может быть много сервисов; иногда совместное владение (используйте
primary_owner_team_id + additional_owner_team_ids).
- Services ↔ resources: связывайте с облачными ресурсами (Kubernetes‑неймспейсы, очереди, БД), чтобы ответить на вопрос «что использует этот сервис?»
- Service tiers: храните уровень как enum и связывайте с политикой (например, tier‑0 требует on‑call и журналов аудита).
Такая реляционная структура даёт страницы вроде «всё, что принадлежит команде X» или «все сервисы, которые касаются этой БД».
Идентификаторы и правила именования
Решите рано, какой канонический ID использовать, чтобы дубликаты не появлялись при импортах. Распространённые паттерны:
- Стабильный slug (например,
payments-api) с уникальностью
- Неизменяемый UUID плюс удобочитаемый slug
- Опционально: ключ, связанный с репо (
github_org/repo) если репо 1:1 с сервисом
Документируйте правила именования (допустимые символы, уникальность, политика переименования) и валидируйте их при создании.
План обновления данных
Каталог проваливается, когда устаревает. Выберите один подход или их сочетание:
- Запланированные импорты (ночная синхронизация из Git, CI/CD, облачной инвентаризации)
- Вебхуки (обновление при изменениях в репо, деплоях, смене владельцев)
- Потоки событий (публикация событий типа “service.created” или “dependency.updated”)
Храните поле last_seen_at и data_source для каждой записи, чтобы показывать свежесть и отлаживать конфликты.
Аутентификация, авторизация и аудит
Проектируйте интеграции с меньшим риском
Набросайте экраны коннекторов и оркестровочные потоки до подключения каждого API поставщика.
Если ваш IDP‑портал должен быть доверенным, ему нужны три работающие вещи: аутентификация (кто вы?), авторизация (что вы можете делать?) и аудит (что случилось и кто это сделал?). Настройте это правильно рано, и вы избежите переработок позже — особенно когда портал начнёт управлять изменениями в проде.
По умолчанию — SSO с маппингом групп
Большинство компаний уже имеют инфраструктуру идентификации. Используйте её.
Сделайте SSO через OIDC или SAML стандартным способом входа и подтягивайте членство в группах из вашего IdP (Okta, Azure AD, Google Workspace и т. п.). Затем отображайте группы в роли и членство команд в портале.
Это упрощает онбординг («войдите и вы уже в нужных командах»), исключает хранение паролей и даёт IT‑возможность применить глобальные политики (MFA, таймауты сессий).
Чёткие роли (и что они могут делать)
Избегайте расплывчатой модели «админ vs все». Практичный набор ролей для внутренней платформы:
- Developer: просматривать портал, использовать шаблоны и рабочие процессы в рамках доступной области.
- Service Owner: управлять записью каталога сервиса (метаданные, on‑call, жизненный цикл), видеть историю по сервису.
- Approver: утверждать или отклонять чувствительные запросы (доступ в прод, новые окружения, ресурсы с влиянием на затраты).
- Platform Admin: управлять шаблонами, интеграциями, глобальными настройками и политиками по умолчанию.
- Auditor: доступ только для чтения к журналам аудита, одобрениям и истории конфигураций.
Держите модель ролей простой и понятной. Её всегда можно расширить, но запутанная модель снижает принятие.
RBAC плюс права на уровне ресурса
RBAC необходим, но недостаточен. Порталу нужны права на уровне ресурса: доступ должен быть ограничен командой, сервисом или окружением.
Примеры:
- Разработчик может запустить workflow «создать sandbox‑окружение» для сервисов своей команды, но не для чужих.
- Владелец сервиса может редактировать запись каталога для принадлежащих сервисов.
- Утверждающий может одобрять запросы только для определённых cost‑center или прод‑неймспейсов.
Реализуйте это простым шаблоном политики: (principal) может (action) над (resource) если (condition). Начните со scoping по команде/сервису и расширяйте.
Журналы аудита для чувствительных действий
Считайте журналы аудита фичей первого класса, а не бэкэнд‑деталью. Портал должен записывать:
- Кто инициировал workflow (и откуда)
- Значения параметров (секреты редактировать)
- Кто одобрил/отклонил и комментарии
- Результирующие изменения (ссылки на CI/CD, тикеты или изменения в инфраструктуре)
- Изменения шаблонов, прав и интеграций
Делайте журналы аудита доступными из мест, где люди работают: страница сервиса, вкладка «History» у workflow и админ‑вид для соответствия. Это ускоряет разбор инцидентов.
UX для разработчиков: сделайте правильный путь простым
Хороший UX портала — не про красоту, а про снижение трения при доставке. Разработчики должны быстро ответить на три вопроса: Что есть? Что я могу создать? Что требует внимания прямо сейчас?
Навигация вокруг реальных задач
Вместо организации меню по бэкенд‑системам («Kubernetes», «Jira», «Terraform») стройте портал вокруг работы, которую реально выполняют разработчики:
- Discover: найти сервисы, API, доки, владельцев, рукбуки
- Create: начать новый сервис, добавить endpoint, запросить базу данных
- Operate: посмотреть состояние, инциденты, статус деплоя, недавние изменения
- Govern: права, проверки соответствия, исключения из политик
Такая навигация упрощает онбординг: новым коллегам не нужно знать вашу цепочку инструментов, чтобы начать.
Сделайте владение заметным
Каждая страница сервиса должна явно показывать:
- Команду‑владельца и командный канал
- Ротацию on‑call и путь эскалации
- Основные репозитории и цель деплоя
Разместите панель «Кто владеет?» у верхней части страницы, а не в вкладке. При инцидентах секунды важны.
Поиск, фильтры и статусы, соответствующие мышлению людей
Быстрый поиск — ключевая фича портала. Поддерживайте фильтры, которые разработчики естественно используют: команда, жизненный цикл (experimental/production), уровень, язык, платформа и «принадлежит мне». Добавьте чёткие индикаторы статуса (здоров/ухудшен, SLO под риском, блокировано одобрением), чтобы можно было быстро просканировать список.
Короткие формы с шаблонами и разумными дефолтами
При создании ресурсов спрашивайте только то, что реально нужно сейчас. Используйте шаблоны («золотые пути») и значения по умолчанию, чтобы избежать ошибок — соглашения по именованию, хуки логирования/метрик и стандартные CI‑настройки должны быть предзаполнены, а не вводиться вручную. Если поле опционально, скрывайте его в «Расширенных опциях», чтобы счастливый путь оставался быстрым.
Рабочие процессы самообслуживания: шаблоны, одобрения и история
Соответствуйте региональным требованиям
Запускайте приложение в нужной стране, чтобы соответствовать требованиям по защите данных.
Самообслуживание — это то, где портал заслуживает доверие: разработчики должны завершать частые задачи end‑to‑end без тикетов, а платформа при этом сохраняет контроль над безопасностью, соответствием и затратами.
Выберите типы workflow, которые важны в первую очередь
Начните с небольшого набора рабочих процессов, которые соответствуют частым и болезненным запросам. Типичные «первые четыре»:
- Создать сервис: скаффолдинг репо, регистрация в каталоге, назначение владельцев и bootstrap CI/CD.
- Provision окружения: поднять dev/stage с сетевыми и логирующими ограждениями и бюджетами.
- Запрос доступа: предоставить минимально необходимый доступ к системе (БД, очередь, внешнее API) с опцией срока действия.
- Ротация секретов: инициировать ротацию, обновить downstream‑конфиги и проверить работоспособность приложений.
Эти workflow должны быть опинионованы и отражать ваш золотой путь, при этом позволять контролируемые варианты (язык/рантайм, регион, уровень, классификация данных).
Определите контракт workflow (чтобы шаблоны оставались предсказуемыми)
Относитесь к каждому workflow как к API продукта. Чёткий контракт делает workflow переиспользуемыми, тестируемыми и легко интегрируемыми в вашу цепочку инструментов.
Практичный контракт включает:
- Входы: типизированные поля с дефолтами (например, имя сервиса, команда‑владелец, окружение, чувствительность данных).
- Валидацию: правила именования, допустимые регионы, проверки квот и «уже существует?» проверки.
- Шаги: последовательность действий (применить шаблон, вызвать CI/CD, создать облачные ресурсы, обновить каталог).
- Выходы: артефакты и ссылки, которые нужны разработчикам (URL репо, URL деплоя, ссылка на рукбук, созданные ресурсы).
Оставляйте UX сфокусированным: показывайте только те входы, которыми разработчик действительно управляет, а остальное выводите из каталога сервисов и политик.
Одобрения: быстрые, понятные и принудительные
Одобрения неизбежны для определённых действий (доступ в прод, чувствительные данные, рост затрат). Портал должен делать одобрения предсказуемыми:
- Кто утверждает: определяйте утверждающих по правилам (владелец команды, владелец системы, безопасность) вместо ad‑hoc ping’ов.
- Временные лимиты: задавайте SLA на одобрение и автопрекращение устаревших запросов.
- Эскалация: если первичный утверждающий недоступен, направляйте на бэкап‑группу или ротацию on‑call.
Важно: одобрения должны быть частью движка workflow, а не ручным побочным каналом. Разработчик должен видеть статус, следующие шаги и почему требуется одобрение.
Храните историю и результаты, чтобы команды могли сами дебажить
Каждый запуск workflow должен оставлять постоянную запись:
- Входные данные, результаты валидации и решения утверждающих
- Пошаговые логи (секреты редактировать)
- Итоговые выходы, созданные ресурсы и любые rollback‑действия
Эта история становится вашим «бумажным следом» и системой поддержки: когда что‑то ломается, разработчики видят, где и почему — часто решая проблему без тикета. Также платформа получает данные для улучшения шаблонов и выявления повторяющихся ошибок.
Интеграции: подключение портала к вашей цепочке инструментов
Портал ощущается «реальным», когда умеет читать и действовать в системах, которыми уже пользуются разработчики. Интеграции превращают запись в каталоге в то, что можно задеплойить, наблюдать и поддерживать.
Начните с чеклиста интеграций
Большинству порталов нужен базовый набор подключений:
- Git (репо, дефолтные ветки, CODEOWNERS, pull request’ы)
- CI/CD (пайплайны, статус сборки, артефакты, продвижения)
- Kubernetes (кластеры, неймспейсы, ворклоады, rollout’ы)
- Облако (аккаунты/проекты, сеть, управляемые сервисы)
- IAM (команды, группы, SSO, маппинг ролей)
- Секреты (vault, ссылки на секреты, статус ротации)
Будьте явны, какие данные только для чтения (например, статус пайплайна), а какие — для записи (например, триггер деплоя).
API‑первый подход; вебхуки и синк, когда нужно
Интеграции с API легче тестировать и понимать: можно валидировать аутент, схемы и обработку ошибок.
Используйте вебхуки для событий в почти‑реальном времени (PR смерджен, пайплайн завершён). Используйте плановый синк для систем, которые не могут пушить события или где допустима событинная согласованность (например, ночной импорт облачных аккаунтов).
Постройте слой коннекторов (не впекайте в ядро провайдеров)
Создайте тонкий «коннектор» или сервис интеграции, который нормализует детали в стабильный внутренний контракт (например, Repository, PipelineRun, Cluster). Это изолирует изменения при миграции инструментов и держит UI/API портала чистыми.
Практический паттерн:
- Портал вызывает ваш коннектор
- Коннектор обрабатывает аут, лимиты, ретраи, маппинг
- Коннектор возвращает нормализованные данные + полезные ссылки (например,
/deployments/123)
Документируйте режимы отказа и что пользователям делать
У каждой интеграции должен быть небольшой рукбук: как выглядит «деградация», как она показывается в UI и что делать.
Примеры:
- Git API — rate‑limit: портал показывает кэшированные данные репо; «Создать из шаблона» отключено.
- CI/CD недоступен: портал предоставляет ручный fallback (ссылку на UI пайплайна) и объяснение времени повтора.
- Секрет‑менеджер недоступен: блокируйте изменения, требующие новых секретов; разрешайте только чтение метаданных сервиса.
Держите эти доки рядом с продуктом (например, /docs/integrations), чтобы разработчикам не приходилось гадать.
Наблюдаемость: мониторинг портала и его автоматизаций
Портал — это не просто UI: это слой оркестрации, который триггерит CI/CD, создаёт облачные ресурсы, обновляет каталог и применяет одобрения. Наблюдаемость позволяет быстро и уверенно ответить: «Что случилось?», «Где произошёл сбой?» и «Кто должен действовать дальше?»
Трассируйте каждый запрос сквозь шаги
Инструментируйте каждый запуск workflow корреляционным ID, который следует за запросом от UI портала через backend API, проверки одобрения и внешние системы (Git, CI, облако, тикетинг). Добавьте трассировку запросов, чтобы единый просмотр показывал полный путь и тайминги каждого шага.
Дополните трассы структурными логами (JSON) с полями: имя workflow, run ID, имя шага, целевой сервис, окружение, актор и результат. Это облегчает фильтрацию по «всем неудачным запускам deploy‑template» или «всем событиям, влияющим на Сервис X».
Метрики, отражающие боль разработчиков
Базовых infra‑метрик недостаточно. Добавьте метрики workflow, которые сопоставимы с реальными результатами:
- Количество запусков, процент успеха и длительность по workflow и шагам
- Время ожидания одобрений vs время выполнения (помогает найти узкие места)
- Ретраи, таймауты и лимиты от коннекторов
Операционные виды внутри портала
Дайте платформенным командам «быстрый взгляд» на состояние:
- Очередь workflow: выполняются, в очереди, упали, ждут одобрения
- Здоровье коннекторов: валидность токенов, время последнего успешного вызова, процент ошибок
- Статус синхронизации: последний синк каталога, обнаруженный дрейф, размер бэклога
Связывайте каждый статус с подробностями и точными логами/трассами для этого прогона.
Алёрты, хранение и аудит
Настройте алёрты на ломанные интеграции (повторяющиеся 401/403), застрявшие одобрения (нет действий N часов) и сбои синка. Планируйте хранение данных: держите объёмные логи короче, а события аудита дольше для соответствия и расследований, с чётким контролем доступа и возможностью экспорта.
Безопасность и управление, не замедляя команды
Сначала спланируйте рабочие процессы
Спланируйте пути пользователей, вводы и сценарии отказов перед созданием экранов и API.
Безопасность в IDP работает лучше, когда она ощущается как «ограждения», а не как ворота. Цель — убрать рискованные варианты, сделав безопасный путь самым простым, при этом позволяя командам автономно доставлять.
Валидируйте входы и автоматически применяйте стандарты
Большая часть управления может происходить в момент запроса (новый сервис, репо, окружение или облачный ресурс). Рассматривайте каждую форму и API‑вызов как недоверенный вход.
Применяйте правила кодом, а не только в доках:
- Требуйте владения (команда, on‑call, контакт эскалации) и блокируйте создание, если оно отсутствует.
- Валидируйте правила именования (имена сервисов, репо, окружений), чтобы избежать коллизий.
- Требуйте теги/метаданные для учёта затрат, соответствия и обнаружения.
- Отвергайте запросы, не соответствующие минимальной политике (например, «публичный доступ» требует дополнительного ревью).
Это держит каталог чистым и облегчает аудит.
Защищайте секреты по дизайну
Портал часто взаимодействует с учётными данными (CI‑токены, облачные ключи, API‑ключи). Обращайтесь с секретами как с радиоактивными объектами:
- Никогда не логируйте секреты и не включайте их в сообщения об ошибках.
- Предпочитайте короткоживущие токены (OIDC, федеративный доступ, временные креды) вместо долгоживущих ключей.
- Храните секреты только в выделенном менеджере секретов; портал должен ссылаться на них, а не копировать.
Также убедитесь, что журналы аудита фиксируют кто что и когда сделал — без хранения самих значений секретов.
Моделируйте угрозы для «обычных» отказов
Сосредоточьтесь на реальных рисках:
- Эскалация привилегий через неверно настроенный RBAC и чрезмерно широкие права.
- Подделка вебхуков или callback’ов, которые триггерят действия без верификации.
- Утечки данных через debug‑эндпойнты, подробные логи или чрезмерно открытую поисковую выдачу.
Смягчайте риски подписанной верификацией вебхуков, принципом наименьших привилегий и строгим разделением операций чтения и изменения.
Сдвигайте проверки влево с CI и ревью прав
Запускайте security‑чеки в CI для кода портала и для сгенерированных шаблонов (линтинг, политические проверки, сканирование зависимостей). Затем планируйте регулярные ревью:
- RBAC‑ролей и маппинга групп
- Разрешений шаблонов (кто что может создать)
- Доступа «break‑glass» и процедур ротации
Управление устойчиво, когда оно рутинно, автоматизировано и прозрачно — а не одноразовый проект.
Роллаут, принятие и долгосрочное сопровождение
Портал приносит пользу только если команды им реально пользуются. Относитесь к развёртыванию как к запуску продукта: начните с малого, быстро учитесь, затем масштабируйте на основе фактов.
Начните с фокусного пилота
Пилотируйте с 1–3 командами, которые мотивированы и репрезентативны (одна «зелёная» команда, одна с наследием, одна со строгими требованиями соответствия). Наблюдайте, как они выполняют реальные задачи — регистрируют сервис, запрашивают инфраструктуру, триггерят деплой — и быстро устраняйте трения. Цель не в полноте функционала, а в доказательстве, что портал экономит время и уменьшает ошибки.
Сделайте миграцию рутинной и предсказуемой
Дайте шаги миграции, которые укладываются в обычный спринт. Пример:
- зарегистрировать существующий сервис в каталоге,
- прикрепить владение и on‑call информацию,
- подключить CI/CD,
- принять один шаблон (репо, пайплайн или инфра) для следующего компонента.
Делайте «day‑2» апгрейды простыми: позволяйте командам постепенно добавлять метаданные и заменять кастомные скрипты на рабочие процессы портала.
Документация и встроенная помощь, которые люди будут читать
Пишите короткие документы для ключевых workflow: «Зарегистрировать сервис», «Запросить базу данных», «Откатить деплой». Добавьте подсказки рядом с полями формы и ссылки на /docs/portal и /support для глубинного контекста. Обращайтесь с доками как с кодом: версионируйте, ревьюьте и чистите.
Владение — долгосрочное обязательство
Планируйте постоянное владение с самого начала: кто-то должен триажить бэклог, поддерживать коннекторы к внешним инструментам и помогать пользователям при сбоях автоматизаций. Определите SLA для инцидентов портала, задайте регулярный цикл обновления коннекторов и просматривайте журналы аудита, чтобы выявлять повторяющиеся боли и пробелы в политике.
По мере зрелости портала вы захотите функционал вроде снимков/отката конфигурации портала, предсказуемых развёртываний и простого продвижения окружений между регионами. Если вы быстро экспериментируете, Koder.ai также может помочь командам поднять внутренние приложения с режимом планирования, хостингом развёртываний и экспортом кода — полезно для пилотов, прежде чем превращать возможности в стабильные компоненты платформы.