21 ส.ค. 2568·3 นาที
6 JOIN ใน SQL ที่คุณควรรู้ (พร้อมตัวอย่างชัดเจนและเข้าใจง่าย)
เรียนรู้ 6 ประเภท JOIN ใน SQL ที่นักวิเคราะห์ควรรู้—INNER, LEFT, RIGHT, FULL OUTER, CROSS และ SELF—พร้อมตัวอย่างใช้งานและข้อควรระวัง
เรียนรู้ 6 ประเภท JOIN ใน SQL ที่นักวิเคราะห์ควรรู้—INNER, LEFT, RIGHT, FULL OUTER, CROSS และ SELF—พร้อมตัวอย่างใช้งานและข้อควรระวัง
SQL JOIN ช่วยให้คุณรวมแถวจากสองตาราง (หรือมากกว่า) เป็นผลลัพธ์เดียวด้วยการจับคู่คอลัมน์ที่เกี่ยวข้อง—โดยปกติจะเป็น ID
ฐานข้อมูลจริงมักจะแยกข้อมูลเป็นหลายตารางเพื่อไม่ให้ซ้ำซ้อน เช่น ชื่อของลูกค้าเก็บในตาราง customers ขณะที่การสั่งซื้อเก็บในตาราง orders JOIN คือวิธีที่คุณเชื่อมข้อมูลเหล่านั้นกลับเมื่อคุณต้องการคำตอบ
ดังนั้น JOIN จึงถูกใช้ทั่วในการรายงานและการวิเคราะห์:
ถ้าไม่มี JOIN คุณจะต้องรันคำสั่งแยกแล้วรวมผลด้วยมือ—ช้า เสี่ยงผิดพลาด และทำซ้ำยาก
ถ้าคุณสร้างผลิตภัณฑ์บนฐานข้อมูลเชิงสัมพันธ์ (แดชบอร์ด พื้นที่แอดมิน เครื่องมือภายใน พอร์ทัลลูกค้า) JOIN คือสิ่งที่เปลี่ยน "ตารางดิบ" ให้เป็นมุมมองที่ผู้ใช้เห็นได้ แพลตฟอร์มอย่าง Koder.ai (ที่สร้างแอป React + Go + PostgreSQL จากการคุย) ยังคงต้องพึ่งพื้นฐาน JOIN ที่ดีเมื่อต้องการหน้ารายการ รายงาน และหน้าตรวจสอบ เพราะตรรกะฐานข้อมูลยังคงสำคัญ แม้ว่าการพัฒนาจะเร็วขึ้น
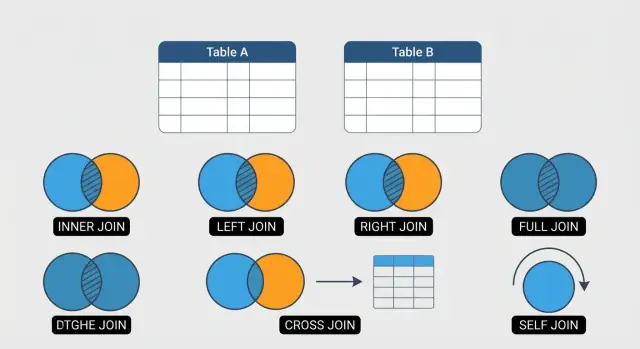
คู่มือนี้เน้น JOIN หกแบบที่ครอบคลุมงาน SQL ประจำวันได้ส่วนใหญ่:
รูปแบบ JOIN คล้ายกันในฐานข้อมูลส่วนใหญ่ (PostgreSQL, MySQL, SQL Server, SQLite) มีความแตกต่างเล็กน้อย—โดยเฉพาะการสนับสนุน FULL OUTER JOIN และพฤติกรรมขอบกรณี—แต่แนวคิดและรูปแบบหลักนำไปใช้ได้ข้ามระบบ
เพื่อให้ตัวอย่าง JOIN เรียบง่าย เราจะใช้สามตารางขนาดเล็กที่สะท้อนการตั้งค่าจริง: ลูกค้าสร้างคำสั่งซื้อ และคำสั่งซื้ออาจ (หรืออาจจะไม่) มีการชำระเงิน
โน้ตสั้นก่อนเริ่ม: ตารางตัวอย่างด้านล่างแสดงเฉพาะบางคอลัมน์ แต่ตัวอย่างบางคำสั่งจะอ้างถึงฟิลด์เพิ่มเติม (เช่น order_date, created_at, status, หรือ paid_at) ให้ถือว่าเป็นคอลัมน์ “ทั่วไป” ที่มักมีในสคีมาของการใช้งานจริง
Primary key: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
สังเกตว่า order_id = 104 อ้างอิง customer_id = 5 ซึ่ง ไม่มี ในตาราง customers กรณี "ไม่มีการจับคู่" นี้มีประโยชน์เพื่อดูพฤติกรรมของ LEFT JOIN, RIGHT JOIN, และ FULL OUTER JOIN
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
รายละเอียดสำคัญสองข้อสำหรับการสอน:
order_id = 102 มี สองแถวการชำระ (แบ่งจ่าย) เมื่อคุณ join orders กับ payments คำสั่งซื้อนั้นจะแสดง สองครั้ง — นี่คือที่มาของการเกิดซ้ำที่มักทำให้คนตกใจpayment_id = 9004 อ้างอิง order_id = 999 ซึ่งไม่มีใน orders นี่คืออีกกรณีของการ “ไม่จับคู่”orders กับ payments จะทำให้คำสั่งซื้อ 102 ซ้ำเพราะมีการชำระสองรายการINNER JOIN คืนเฉพาะแถวที่มีการจับคู่ใน ทั้งสอง ตาราง ถ้าลูกค้าไม่มีคำสั่งซื้อ เขาจะไม่ปรากฏ ถ้าคำสั่งซื้ออ้างอิงลูกค้าที่ไม่มี (ข้อมูลไม่ดี) คำสั่งซื้อจะไม่ปรากฏเช่นกัน
คุณเลือกตาราง “ซ้าย” แล้ว join กับตาราง “ขวา” โดยระบุเงื่อนไขใน ON:
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
แกนหลักคือบรรทัด ON o.customer_id = c.customer_id: บอก SQL ว่าแถวใดเกี่ยวข้องกัน
ถ้าต้องการรายการเฉพาะลูกค้าที่เคยสั่งซื้อจริงๆ พร้อมรายละเอียดคำสั่งซื้อ INNER JOIN คือทางเลือกตามธรรมชาติ:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
เป็นประโยชน์สำหรับงานอย่าง “ส่งอีเมลติดตามคำสั่งซื้อ” หรือ “คำนวณรายได้ต่อลูกค้า” เมื่อคุณสนใจเฉพาะลูกค้าที่มีการซื้อ
ถ้าคุณเขียน join แต่ลืม ON (หรือ join บนคอลัมน์ผิด) คุณอาจสร้าง Cartesian product (ทุกลูกค้าจับคู่กับทุกคำสั่งซื้อ) หรือได้ผลลัพธ์ผิดพลาดอย่างเงียบๆ
ตัวอย่างไม่ดี (อย่าใช้):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
จงใส่เงื่อนไข join ที่ชัดเจนใน ON เสมอ (หรือ USING ในกรณีที่เหมาะสม)
LEFT JOIN คืน แถวทั้งหมดจากตารางซ้าย และเพิ่มข้อมูลจากตารางขวาเมื่อมีการจับคู่ ถ้าไม่มีการจับคู่ คอลัมน์ฝั่งขวาจะเป็น NULL
ใช้ LEFT JOIN เมื่อต้องการรายการสมบูรณ์จากตารางหลัก พร้อมข้อมูลที่เกี่ยวข้องเมื่อมี
ตัวอย่าง: “แสดง ลูกค้าทั้งหมด และรวมคำสั่งซื้อของพวกเขา ถ้ามี”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id จะเป็น NULLตัวอย่าง: “ลูกค้าคนไหน ไม่เคยสั่งซื้อ บ้าง?”
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
เงื่อนไข WHERE ... IS NULL เก็บเฉพาะแถวจากตารางซ้ายที่การ join ไม่พบการจับคู่
LEFT JOIN อาจทำให้แถวของตารางซ้าย “ซ้ำ” เมื่อฝั่งขวามีหลายแถวที่จับคู่
ถ้าลูกค้าคนหนึ่งมี 3 คำสั่งซื้อ ลูกค้าคนนั้นจะปรากฏ 3 ครั้ง—ครั้งละหนึ่งคำสั่งซื้อ นี่เป็นพฤติกรรมปกติ แต่จะทำให้สับสนหากคุณพยายามนับลูกค้า
ตัวอย่างการนับที่อาจผิด:
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
ถ้าต้องการนับลูกค้า ควรนับคีย์ของลูกค้า (เช่น COUNT(DISTINCT c.customer_id)) ขึ้นกับสิ่งที่คุณวัด
RIGHT JOIN เก็บ แถวทั้งหมดจากตารางขวา และเฉพาะแถวที่จับคู่จากตารางซ้าย หากไม่มีการจับคู่ คอลัมน์ฝั่งซ้ายจะเป็น NULL มันเหมือนภาพสะท้อนของ LEFT JOIN
สมมติอยากแสดง การชำระทั้งหมด แม้ว่าจะจับกับคำสั่งซื้อไม่ได้ (อาจเพราะคำสั่งซื้อถูกลบหรือข้อมูลการชำระไม่สะอาด)
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
ผลลัพธ์:
payments อยู่ฝั่งขวา)o.order_id และ o.customer_id จะเป็น NULLบ่อยครั้งคุณสามารถเขียน RIGHT JOIN ให้เป็น LEFT JOIN โดยสลับลำดับตาราง:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
จะได้ผลเหมือนกัน แต่มักอ่านง่ายกว่าเพราะเริ่มจากตารางหลักที่คุณสนใจ (ตรงนี้คือ payments)
แนวทางการเขียน SQL ส่วนใหญ่ขอให้เริ่มจากตารางหลักแล้ว LEFT JOIN ตารางเพิ่มเติม เมื่อความสัมพันธ์ optional เขียนเป็น LEFT JOIN เสมอ คิวรีจะอ่านง่ายขึ้น
RIGHT JOIN อาจสะดวกเมื่อคุณแก้คิวรีเดิมและพบว่าตารางที่ต้องเก็บไว้ดันอยู่ฝั่งขวา แทนที่จะเขียนคิวรียาวใหม่ทั้งหมด การเปลี่ยน JOIN หนึ่งบรรทัดเป็น RIGHT JOIN อาจเร็วและเสี่ยงน้อย
FULL OUTER JOIN คืน ทุกแถวจากทั้งสองตาราง
INNER JOIN)NULLNULLกรณีธุรกิจคลาสสิกคือ ไกล่เกลี่ย orders กับ payments:
ตัวอย่าง:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN รองรับใน PostgreSQL, SQL Server, และ Oracle
มัน ไม่รองรับ ใน MySQL และ SQLite (ต้องใช้วิธีแก้ไข)
ถ้าฐานข้อมูลไม่รองรับ FULL OUTER JOIN คุณสามารถจำลองได้โดยรวม:
orders (พร้อมการจับคู่เมื่อมี)payments ที่ไม่จับกับ ordersรูปแบบหนึ่งที่พบบ่อย:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
เคล็ดลับ: เมื่อเห็น NULL ฝั่งใดฝั่งหนึ่ง นั่นคือสัญญาณว่าข้อมูลจากอีกฝั่ง “หายไป” ซึ่งต้องการสำหรับการตรวจสอบและไกล่เกลี่ย
CROSS JOIN คืน ทุกการจับคู่ที่เป็นไปได้ ของแถวจากสองตาราง ถ้าตาราง A มี 3 แถว และตาราง B มี 4 แถว ผลลัพธ์จะมี 3 × 4 = 12 แถว เรียกว่า Cartesian product
ฟังดูน่ากลัว—และเป็นได้—แต่มีประโยชน์เมื่อต้องการสร้างการผสมผสานจริงๆ
สมมติคุณเก็บตัวเลือกสินค้าแยกตาราง:
sizes: S, M, Lcolors: Red, BlueCROSS JOIN สร้างตัวแปรทั้งหมด (ใช้สร้าง SKU ล่วงหน้า สร้างแคตตาล็อก หรือทดสอบ):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
ผลลัพธ์ (3 × 2 = 6 แถว):
เพราะจำนวนแถวถูกคูณ CROSS JOIN อาจขยายเร็วมาก:
ซึ่งทำให้คิวรีช้าหลายและใช้หน่วยความจำมาก หากต้องการการผสม ให้จำกัดขนาดตารางนำเข้าและพิจารณาเพิ่ม LIMIT หรือกรองอย่างรอบคอบ
SELF JOIN ก็คือการ join ตารางกับตัวมันเอง ใช้เมื่อแถวหนึ่งในตารางสัมพันธ์กับอีกแถวหนึ่งในตารางเดียวกัน—เช่น โครงสร้างลำดับชั้นพนักงาน/ผู้จัดการ
เพราะใช้ตารางเดียวกันสองครั้ง คุณต้องตั้ง alias ให้แต่ละ "สำเนา" เพื่อให้คิวรีอ่านง่ายและบอก SQL ว่าหมายถึงฝั่งไหน
รูปแบบที่นิยม:
e สำหรับ employeem สำหรับ managerสมมติ employees มี:
idnamemanager_id (ชี้ไปที่ id ของพนักงานคนอื่น)เพื่อแสดงพนักงานแต่ละคนพร้อมชื่อผู้จัดการ:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
คิวรีใช้ LEFT JOIN ไม่ใช่ INNER JOIN เพราะบางคนอาจไม่มีผู้จัดการ (เช่น CEO) ในกรณีเหล่านั้น manager_id มักเป็น NULL และ LEFT JOIN จะยังคงเก็บแถวนั้นไว้พร้อมให้ manager_name เป็น NULL ถ้าใช้ INNER JOIN พนักงานระดับบนจะหายไปเพราะไม่มีแถว manager ที่ตรงกัน
JOIN ไม่ได้ "รู" ว่าตารางสองตารางสัมพันธ์กันอย่างไร—คุณต้องบอก โดยใส่เงื่อนไขการจับคู่ ซึ่งควรวางถัดจาก JOIN เพราะเป็นการอธิบายว่าตารางจับคู่กันอย่างไร ไม่ใช่การกรองผลลัพธ์สุดท้าย
ON: ยืดหยุ่นที่สุดและใช้บ่อยสุดใช้ ON เมื่อคุณต้องการควบคุมการจับคู่เต็มที่—ชื่อคอลัมน์ต่างกัน หลายเงื่อนไข หรือกฎเพิ่มเติม
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON ยังใช้สำหรับการจับคู่ซับซ้อน (เช่น จับสองคอลัมน์) โดยไม่ทำให้คิวรีสับสน
USING: สั้น แต่ใช้ได้เฉพาะคอลัมน์ชื่อเดียวกันบางฐานข้อมูล (เช่น PostgreSQL และ MySQL) รองรับ USING เป็นชอร์ตฮันด์เมื่อทั้งสองตารางมีคอลัมน์ชื่อเดียวกันและต้องการ join บนคอลัมน์นั้น
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
ข้อดีอย่างหนึ่ง: USING มักส่งคืนคอลัมน์ customer_id เพียงคอลัมน์เดียวในผลลัพธ์ (ไม่ใช่ 2 คอลัมน์)
เมื่อ join แล้ว ชื่อคอลัมน์มักซ้อนทับกัน (id, created_at, status) ถ้าคุณเขียน SELECT id ฐานข้อมูลอาจโชว์ข้อผิดพลาดว่า "ambiguous column" หรือแย่กว่านั้น คุณอาจอ่านผิด id
ควรใช้ prefix ของตาราง (หรือ alias) เพื่อความชัดเจน:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * ในคิวรีที่มี JOINSELECT * จะยุ่งเหยิงเร็วเมื่อ JOIN: คุณดึงคอลัมน์ไม่จำเป็น เสี่ยงชื่อซ้ำ และทำให้มองไม่ออกว่าคิวรีสร้างอะไรขึ้นมา
แทนที่จะใช้ ให้เลือกคอลัมน์ที่ต้องการ ผลลัพธ์จะสะอาด ดูแลรักษาง่าย และมักมีประสิทธิภาพกว่า—โดยเฉพาะเมื่อตารางกว้าง
เมื่อคุณ join ตาราง WHERE และ ON ต่างทำการกรองแต่ในช่วงเวลาที่ต่างกัน
ความต่างของเวลาเกิดเป็นเหตุผลที่คนเปลี่ยน LEFT JOIN เป็น INNER JOIN โดยไม่ตั้งใจ
ถ้าคุณต้องการ ลูกค้าทั้งหมด แม้ไม่มีคำสั่งซื้อที่ชำระล่าสุด:
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
ปัญหา: สำหรับลูกค้าที่ไม่มีคำสั่งซื้อ o.status และ o.order_date เป็น NULL เงื่อนไข WHERE จะตัดแถวนั้นทิ้ง ทำให้ LEFT JOIN ทำงานเหมือน INNER JOIN
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
ตอนนี้ลูกค้าที่ไม่มีคำสั่งซื้อที่เข้าเงื่อนไขยังปรากฏ (พร้อมคอลัมน์คำสั่งซื้อเป็น NULL) ซึ่งมักเป็นจุดประสงค์ของ LEFT JOIN
WHERE o.order_id IS NOT NULL อย่างชัดเจน)JOIN ไม่ได้แค่ “เพิ่มคอลัมน์”—มันอาจ เพิ่มจำนวนแถว ซึ่งเป็นพฤติกรรมที่ถูกต้องแต่ทำให้คนสับสนเมื่อตัวเลขรวมเปลี่ยนไปอย่างไม่คาดคิด
การ join คืนหนึ่งแถวผลลัพธ์สำหรับทุกคู่แถวที่จับคู่กัน
customers กับ orders ลูกค้าแต่ละคนอาจปรากฏหลายครั้งorders กับ payments แล้วแต่ละคำสั่งซื้อมีหลายการชำระ และคุณยัง join กับตาราง "many" อีก (เช่น order_items) คุณอาจได้ผลคูณระหว่าง payments × itemsถ้าจุดประสงค์คือ “หนึ่งแถวต่อคำสั่งซื้อ” หรือ “หนึ่งแถวต่อลูกค้า” ให้สรุปฝั่งที่เป็น many ก่อนแล้วค่อย join
-- One row per order from payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
จะช่วยให้รูปร่างของการ join คาดเดาได้: หนึ่งคำสั่งซื้อคงเป็นหนึ่งแถว
SELECT DISTINCT อาจแก้ปัญหาแถวซ้ำได้แต่ซ่อนสาเหตุจริง:
ใช้เมื่อเข้าใจสาเหตุของการซ้ำแน่ชัดเท่านั้น
ก่อนเชื่อผลลัพธ์ ให้เปรียบเทียบจำนวนแถว:
JOIN มักถูกตำหนิว่าเป็นสาเหตุคิวรีช้า แต่สาเหตุจริงมักเป็น ปริมาณข้อมูลที่คุณขอให้ฐานข้อมูลรวมกัน และ ความง่ายที่มันจะหาการจับคู่
คิดว่าดัชนีเหมือนสารบัญหนังสือ ถ้าไม่มีมัน ฐานข้อมูลอาจต้องสแกนหลายแถวเพื่อหาการจับคู่สำหรับเงื่อนไข JOIN หากมีดัชนีบนคีย์การ join (เช่น customers.customer_id และ orders.customer_id) ฐานข้อมูลจะกระโดดไปที่แถวที่เกี่ยวข้องได้เร็วขึ้น
คุณไม่ต้องรู้รายละเอียดภายในเพื่อใช้ให้ดี: ถ้าคอลัมน์ถูกใช้บ่อยในการจับคู่ (ON a.id = b.a_id) มันเป็นผู้สมัครที่ดีที่จะทำดัชนี
ถ้าเป็นไปได้ ให้ join บนตัวระบุที่เสถียรและไม่ซ้ำซ้อน:
customers.customer_id = orders.customer_idcustomers.email = orders.email หรือ customers.name = orders.nameชื่อเปลี่ยนได้และซ้ำได้ อีเมลอาจเปลี่ยนหรือมีรูปแบบต่างกัน ID ออกแบบมาสำหรับการจับคู่สม่ำเสมอและมักถูกทำดัชนี
สองนิสัยที่ทำให้ JOIN เร็วขึ้นอย่างเห็นได้ชัด:
SELECT * เมื่อ join หลายตาราง—คอลัมน์เกินความจำเป็นเพิ่มการใช้หน่วยความจำและเครือข่ายตัวอย่าง: จำกัดคำสั่งซื้อก่อนแล้วค่อย join:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
ถ้าคุณทำงานซ้ำบนคิวรีเหล่านี้ภายในกระบวนการสร้างแอป (เช่น สร้างหน้ารายงานบน PostgreSQL) เครื่องมืออย่าง Koder.ai ช่วยเร่งการสร้างสเกฟโฟลด์—สคีมา endpoints UI—ในขณะที่คุณควบคุมโลจิก JOIN ที่กำหนดความถูกต้อง
NULL)NULL เมื่อหาย)NULLการ JOIN ใน SQL รวมแถวจากสอง (หรือมากกว่า) ตารางให้เป็นชุดผลลัพธ์เดียว โดยจับคอลัมน์ที่เกี่ยวข้องเข้าด้วยกัน—บ่อยครั้งคือ primary key กับ foreign key (เช่น customers.customer_id = orders.customer_id) วิธีนี้แหละที่ช่วยให้คุณนำตารางที่ถูก normalized กลับมารวมกันเวลาต้องการรายงาน การตรวจสอบ หรือการวิเคราะห์
ใช้ INNER JOIN เมื่อคุณต้องการเฉพาะแถวที่มีความสัมพันธ์ในทั้งสองตารางเท่านั้น
เหมาะสำหรับความสัมพันธ์ที่ “ยืนยันแล้ว” เช่น การแสดงเฉพาะลูกค้าที่เคยซื้อของ
ใช้ LEFT JOIN เมื่อคุณต้องการเก็บแถวทั้งหมดจากตารางหลัก (ซ้าย) และดึงข้อมูลจากตารางขวาเมื่อมีการจับคู่
ตัวอย่างการหาที่ไม่มีการจับคู่:
SELECT c.customer_id, c.name
FROM customers c
LEFT JOIN orders o ON o.customer_id = c.customer_id
WHERE o.order_id ;
RIGHT JOIN จะเก็บแถวทั้งหมดจากตารางด้านขวาและใส่ค่า NULL ให้คอลัมน์ของตารางซ้ายเมื่อไม่มีการจับคู่ ทีมส่วนใหญ่หลีกเลี่ยงเพราะอ่านกลับด้านได้ยาก
โดยทั่วไปสามารถเขียนใหม่เป็น LEFT JOIN ได้โดยสลับลำดับตาราง เช่น:
FROM payments p
LEFT JOIN orders o o.order_id p.order_id
ใช้ FULL OUTER JOIN เมื่อคุณต้องการผลลัพธ์ที่รวมทั้งแถวที่จับคู่และแถวที่มีเฉพาะฝั่งใดฝั่งหนึ่ง ซึ่งเหมาะกับการไกล่เกลี่ย เช่น “คำสั่งซื้อที่ไม่มีการชำระ” และ “การชำระเงินที่ไม่มีคำสั่งซื้อ” เพราะฝั่งที่ไม่มีจะมีค่า NULL ในคอลัมน์อีกฝั่ง
บางฐานข้อมูล (เช่น MySQL และ SQLite) ไม่มี FULL OUTER JOIN ตรงๆ วิธีแก้คือรวมผลจาก
orders LEFT JOIN paymentspayments แต่ไม่มีใน ordersโดยใช้ (หรือ พร้อมเงื่อนไขที่ระมัดระวัง) เพื่อรักษาแถวที่อยู่ข้างเดียวทั้งสองฝั่ง
CROSS JOIN คืนค่าทุกการจับคู่ระหว่างสองตาราง (Cartesian product) และมีประโยชน์เมื่อต้องการสร้างสถานการณ์ เช่น ขนาด × สี หรือสร้างกริดปฏิทิน
ข้อควรระวัง: จำนวนแถวเพิ่มขึ้นเร็วมาก ดังนั้นใช้เมื่อขนาดตารางนำเข้าตัวเล็กและควบคุมได้
Self join คือการเชื่อมตารางกับตัวมันเองเพื่อเชื่อมความสัมพันธ์ภายในตารางเดียวกัน (เช่น พนักงาน → ผู้จัดการ)
คุณต้องใช้ alias เพื่อแยกความหมายของแต่ละสำเนา เช่น:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON กำหนดว่าแถวใดจะจับคู่กันระหว่างการ JOIN; WHERE กรองผลลัพธ์หลังการ JOIN เสร็จแล้ว
ด้วย LEFT JOIN การใส่เงื่อนไขของตารางขวาใน WHERE อาจทำให้แถวที่ไม่มีการจับคู่ถูกทิ้งไปและเปลี่ยนพฤติกรรมเป็นเหมือน INNER JOIN
ถ้าต้องการเก็บแถวซ้ายทั้งหมดแต่จำกัดว่าแถวขวาที่จะจับคู่นั้นต้องเป็นอย่างไร ให้ใส่เงื่อนไขของตารางขวาไว้ใน แทน
การ JOIN ทำให้แถวทวีคูณเมื่อความสัมพันธ์เป็น one-to-many หรือ many-to-many เช่น คำสั่งซื้อที่มีสองการชำระจะปรากฏสองครั้งเมื่อต่อกับตาราง payments
ป้องกันการนับซ้ำโดยสรุปฝั่งที่เป็น "many" ก่อนแล้วค่อย JOIN:
UNIONUNION ALLONWITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
ใช้ DISTINCT เป็นทางเลือกสุดท้ายเพราะมันอาจปกปิดปัญหาจริงและทำให้ผลรวมผิดพลาด