13 ส.ค. 2568·2 นาที
แนวคิดระบบกระจาย: ไอเดียของ Kleppmann สำหรับการปรับขนาด SaaS
แนวคิดระบบกระจายอธิบายผ่านตัวเลือกจริงที่ทีมต้องเผชิญเมื่อต้องเปลี่ยนโปรโตไทป์เป็น SaaS ที่เชื่อถือได้: การไหลของข้อมูล ความสอดคล้อง และการควบคุมภาระ
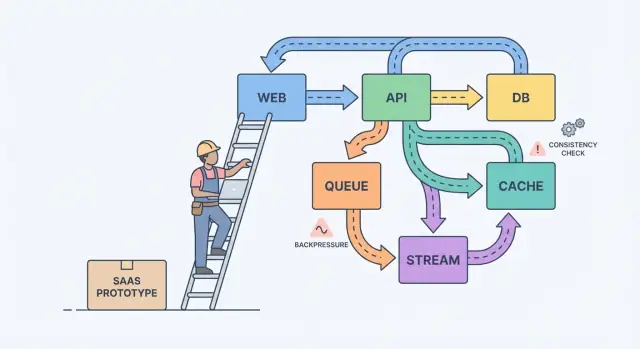
แนวคิดระบบกระจายอธิบายผ่านตัวเลือกจริงที่ทีมต้องเผชิญเมื่อต้องเปลี่ยนโปรโตไทป์เป็น SaaS ที่เชื่อถือได้: การไหลของข้อมูล ความสอดคล้อง และการควบคุมภาระ
โปรโตไทป์พิสูจน์ความคิดได้ แต่ SaaS ต้องอยู่รอดเมื่อมีการใช้งานจริง: ยอดทราฟฟิกสูงสุด ข้อมูลไม่สมบูรณ์ การ retry และลูกค้าที่สังเกตเห็นทุกความสะดุด นั่นแหละที่ทำให้เรื่องสับสน เพราะคำถามเปลี่ยนจาก “มันทำงานไหม?” เป็น “มันยังคงทำงานไหม?”
เมื่อมีผู้ใช้จริง “มันทำงานเมื่อวาน” มักพังเพราะเหตุผลจุกจิก งาน background ถูกรันช้ากว่าปกติ ลูกค้าคนหนึ่งอัพโหลดไฟล์ใหญ่กว่าข้อมูลทดสอบ 10 เท่า ผู้ให้บริการชำระเงินหน่วง 30 วินาที สิ่งเหล่านี้ไม่ใช่เรื่องแปลก แต่ผลกระทบจะกว้างเมื่อส่วนต่าง ๆ ของระบบพึ่งพากัน
ความซับซ้อนส่วนใหญ่ปรากฏในสี่ด้าน: ข้อมูล (ข้อเท็จจริงเดียวกันอยู่หลายที่และเปลี่ยนไป), ความหน่วง (เรียก 50 ms บางครั้งกลายเป็น 5 วินาที), ความล้มเหลว (timeout, อัพเดตบางส่วน, การ retry) และทีมงาน (คนต่างกันส่งมอบบริการต่างกันตามตารางเวลาที่ต่างกัน)
โมเดลง่าย ๆ ที่ช่วยได้คือ: components, messages และ state.
Components ทำงาน (เว็บแอป, API, worker, database). Messages ขนงานระหว่าง components (requests, events, jobs). State คือสิ่งที่คุณจำได้ (คำสั่งซื้อ, การตั้งค่าผู้ใช้, สถานะการเรียกเก็บเงิน). ปัญหาการสเกลมักเกิดจากความไม่ลงตัว: คุณส่งข้อความเร็วกว่าส่วนที่รับจะประมวลผลได้ หรือคุณอัพเดต state ในสองที่โดยไม่มีแหล่งความจริงชัดเจน
ตัวอย่างคลาสสิกคือการเรียกเก็บเงิน โปรโตไทป์อาจสร้าง invoice ส่งอีเมล และอัพเดตแผนของผู้ใช้ในคำขอเดียว ภายใต้ภาระงาน อีเมลช้าลง คำขอล้มเวลา client retry แล้วคุณมีสองใบแจ้งหนี้แต่แผนเปลี่ยนแค่ครั้งเดียว งานด้านความน่าเชื่อถือส่วนใหญ่คือการป้องกันไม่ให้ความล้มเหลวเหล่านี้กลายเป็นบั๊กที่ลูกค้าเห็น
ระบบส่วนใหญ่ซับซ้อนขึ้นเพราะเติบโตโดยไม่มีข้อตกลงว่าควรถูกต้องตรงไหน ต้องเร็วตรงไหน และควรเป็นอย่างไรเมื่อมีความล้มเหลว
เริ่มจากวาดขอบเขตว่าคุณสัญญาอะไรกับผู้ใช้ ภายในขอบเขตนั้น ระบุการกระทำที่ต้องถูกต้องทุกครั้ง (การเคลื่อนย้ายเงิน, การควบคุมการเข้าถึง, ความเป็นเจ้าของบัญชี) แล้วระบุส่วนที่ "จะถูกในที่สุด" ก็พอ (การนับวิเคราะห์, ดัชนีค้นหา, คำแนะนำ) การแยกแบบนี้จะเปลี่ยนทฤษฎีที่ฟุ้ง ๆ ให้เป็นลำดับความสำคัญ
ต่อมา เขียนลงว่าต้นทางความจริง (source of truth) ของคุณคือที่ไหน นั่นคือที่ที่ข้อเท็จจริงถูกบันทึกครั้งเดียว อย่างทนทาน และมีกฎชัดเจน ทุกอย่างที่เหลือเป็นข้อมูลอนุพันธ์ที่สร้างขึ้นเพื่อความเร็วหรือความสะดวก หากมุมมองอนุพันธ์เสียหาย คุณควรสามารถสร้างมันขึ้นใหม่จากแหล่งความจริงได้
เมื่อทีมติดขัด คำถามเหล่านี้มักช่วยให้เห็นสิ่งที่สำคัญ:
ถ้าผู้ใช้เปลี่ยนแผนการเรียกเก็บเงิน dashboard อาจช้ากว่าได้ แต่คุณทนไม่ได้กับความไม่ตรงกันระหว่างสถานะการชำระเงินจริงกับการเข้าถึง
ถ้าผู้ใช้คลิกแล้วต้องเห็นผลทันที (บันทึกโปรไฟล์, โหลดแดชบอร์ด, ตรวจสิทธิ์) API แบบ request-response ธรรมดามักเพียงพอ ทำให้ตรงไปตรงมา
เมื่อใดก็ตามที่งานทำทีหลังได้ ให้ย้ายไปเป็น async คิดถึงการส่งอีเมล การเรียกเก็บบัตร รายงาน การย่อขนาดอัพโหลด หรือการซิงก์ข้อมูลไปยังการค้นหา ผู้ใช้ไม่ควรรอ และ API ของคุณไม่ควรถูกผูกขณะงานเหล่านั้นรัน
คิวคือรายการสิ่งที่ต้องทำ: งานแต่ละชิ้นควรถูกจัดการหนึ่งครั้งโดย worker หนึ่งตัว สตรีม (หรือ log) คือบันทึก: อีเวนต์ถูกเก็บตามลำดับเพื่อให้ผู้อ่านหลายคนสามารถ replay, catch up หรือสร้างฟีเจอร์ใหม่โดยไม่ต้องเปลี่ยนผู้ผลิต
วิธีปฏิบัติในการเลือก:
ตัวอย่าง: SaaS ของคุณมีปุ่ม “Create invoice” API ตรวจสอบ input และเก็บ invoice ใน Postgres จากนั้นคิวจัดการ “send invoice email” และ “charge card” หากคุณเพิ่ม analytics, notifications, และ fraud checks ภายหลัง สตรีมของ InvoiceCreated อนุญาตให้แต่ละฟีเจอร์ subscribe โดยไม่ทำให้บริการหลักเป็นเขาวงกต
เมื่อผลิตภัณฑ์เติบโต อีเวนต์เปลี่ยนจาก "น่าจะมี" เป็นตาข่ายความปลอดภัย การออกแบบอีเวนต์ที่ดีสรุปเป็นสองคำถาม: ข้อเท็จจริงใดที่คุณบันทึก และส่วนอื่นของผลิตภัณฑ์จะตอบสนองอย่างไรโดยไม่ต้องเดา?
เริ่มจากชุดอีเวนต์ธุรกิจขนาดเล็ก เลือกช่วงเวลาที่สำคัญต่อผู้ใช้และรายได้: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
ชื่อนั้นอยู่ได้นานกว่ารหัส ใช้รูปอดีตกาลสำหรับข้อเท็จจริงที่เสร็จสมบูรณ์ รักษาให้เฉพาะเจาะจง และหลีกเลี่ยงคำจาก UI เช่น PaymentSucceeded ยังคงมีความหมายแม้คุณเพิ่มคูปอง, retry หรือผู้ให้บริการชำระเงินหลายรายในอนาคต
ปฏิบัติกับอีเวนต์เหมือนสัญญา หลีกเลี่ยงคำรวมแบบ "UserUpdated" ที่มีฟิลด์เปลี่ยนทุกสปรินต์ ให้เลือกข้อเท็จจริงเล็กที่สุดที่คุณยืนหยัดได้เป็นเวลาปี
เพื่อพัฒนาอย่างปลอดภัย ให้เพิ่มฟิลด์แบบเสริม (optional) หากต้องการเปลี่ยนแบบแตกหัก ให้เผยแพร่ชื่ออีเวนต์ใหม่ (หรือเวอร์ชันชัดเจน) แล้วรันทั้งคู่จนผู้บริโภคเก่าหมด
ควรเก็บอะไรไว้? ถ้าคุณเก็บแค่แถวล่าสุดในฐานข้อมูล คุณจะเสียเรื่องราวว่ามันมาถึงอย่างไร
อีเวนต์ดิบเหมาะกับการตรวจสอบ, replay และดีบั๊ก Snapshot เหมาะกับการอ่านเร็วและกู้คืนเร็ว หลายผลิตภัณฑ์ใช้ทั้งสองอย่าง: เก็บอีเวนต์ดิบสำหรับ workflow สำคัญ (บิลลิ่ง, สิทธิ์) และรักษา snapshot สำหรับหน้าที่เห็นโดยผู้ใช้
ความสอดคล้องปรากฏเป็นช่วงเวลาเช่น: “ฉันเปลี่ยนแผนแล้ว ทำไมยังขึ้น Free?” หรือ “ฉันส่งคำเชิญ ทำไมเพื่อนร่วมงานยังเข้าระบบไม่ได้?”
ความสอดคล้องแบบเข้มงวด (strong) หมายความว่าเมื่อคุณได้ข้อความสำเร็จ ทุกหน้าจอควรสะท้อนสถานะใหม่ทันที ความสอดคล้องแบบ eventual หมายความว่าการเปลี่ยนแปลงจะแพร่ไปตามเวลา และในหน้าต่างสั้น ๆ ส่วนต่าง ๆ ของแอปอาจไม่ตรงกัน ทั้งสองแบบไม่มีอันไหนดีกว่าโดยอัตโนมัติ คุณเลือกตามความเสียหายที่ความไม่ตรงกันจะก่อให้เกิด
ความสอดคล้องแบบเข้มงวดมักเหมาะกับเรื่องเงิน การเข้าถึง และความปลอดภัย: การเรียกเก็บเงิน การเปลี่ยนรหัสผ่าน การเพิกถอนคีย์ API การบังคับใช้ขีดจำกัดที่นั่ง Eventual consistency มักเหมาะกับฟีดกิจกรรม การค้นหา แดชบอร์ดวิเคราะห์ “last seen” และการแจ้งเตือน
ถ้าตกลงยอมให้ข้อมูลล้าสมัย ให้ออกแบบเพื่อรองรับมันแทนที่จะปกปิด: แสดงสถานะ “กำลังอัปเดต…” หลังจากเขียนจนกว่าจะได้รับการยืนยัน เสนอตัวเลือกรีเฟรชด้วยตนเองสำหรับรายการ และใช้ optimistic UI เฉพาะเมื่อคุณสามารถย้อนกลับได้สะดวก
การ retry เป็นจุดที่ความสอดคล้องแอบเปลี่ยนหน้า เครือข่ายหลุด ลูกค้าคลิกสองครั้ง worker รีสตาร์ท สำหรับงานสำคัญ ให้ทำให้คำขอ idempotent เพื่อให้การทำซ้ำไม่สร้างสองใบแจ้งหนี้ สองคำเชิญ หรือสองคืนเงิน แนวทางทั่วไปคือ idempotency key ต่อการกระทำบวกกฎฝั่งเซิร์ฟเวอร์ที่คืนผลลัพธ์เดิมเมื่อเห็นซ้ำ
Backpressure คือสิ่งที่คุณต้องการเมื่อคำขอหรืออีเวนต์มาถึงเร็วกว่าที่ระบบของคุณจะรับได้ หากไม่มี มันจะกองในหน่วยความจำ คิวโต และความช้าที่สุด (มักเป็นฐานข้อมูล) จะเป็นผู้ตัดสินว่าอะไรล้มเหลว
พูดง่าย ๆ: ผู้ผลิตยังคงส่งขณะที่ผู้บริโภคกำลังจมน้ำ ถ้าคุณยังรับงานมากขึ้น คุณไม่ได้แค่ช้าลง แต่คุณกระตุ้นปฏิกิริยาลูกโซ่ของ timeout และ retry ที่เพิ่มภาระ
สัญญาณเตือนมักเห็นได้ก่อนล่ม: backlog โตเท่านั้น, latency พุ่งหลังสไปก์หรือ deploy, retry เพิ่มขึ้นพร้อม timeout, endpoint ไม่เกี่ยวข้องล้มเมื่อ dependency ช้าลง, และการเชื่อมต่อฐานข้อมูลเต็ม
เมื่อถึงจุดนั้น ให้เลือกกฎชัดเจนสำหรับสิ่งที่จะเกิดเมื่อเต็ม เป้าหมายไม่ใช่ประมวลผลทุกอย่างด้วยทุกต้นทุน แต่คืออยู่รอดและกู้คืนเร็ว ทีมมักเริ่มด้วยหนึ่งหรือสองการควบคุม: rate limit (ต่อผู้ใช้หรือ API key), คิวมีขอบเขตพร้อมนโยบาย drop/delay ชัดเจน, circuit breaker สำหรับ dependency ที่ล้ม และลำดับความสำคัญให้คำขอแบบ interactive ชนะงาน background
ปกป้องฐานข้อมูลก่อน: รักษา connection pool ให้เล็กและคาดเดาได้ ตั้ง timeout สำหรับ query และกำหนดขีดจำกัดที่เข้มงวดกับ endpoint ที่แพงเช่นรายงาน ad-hoc
ความน่าเชื่อถือไม่จำเป็นต้องแก้ที่โค้ดใหญ่ มันมาจากการตัดสินใจไม่กี่อย่างที่ทำให้ความล้มเหลวมองเห็นได้ ถูกจำกัด และกู้คืนได้
เริ่มจาก flow ที่ทำให้ได้หรือเสียความไว้วางใจ แล้วเพิ่มราวกันตกก่อนเพิ่มฟีเจอร์:
Map critical paths. เขียนขั้นตอนเป๊ะ ๆ สำหรับ signup, login, password reset และ flow การชำระเงิน สำหรับแต่ละขั้น ให้ระบุ dependency (database, email provider, background worker) นี่บังคับให้ชัดเจนว่าส่วนไหนต้องทันทีและส่วนไหนแก้ทีหลังได้
Add observability basics. ให้คำขอแต่ละอันมี ID ที่ปรากฏใน logs ติดตามเมตริกเล็ก ๆ ที่สะท้อนความเจ็บปวดของผู้ใช้: อัตราข้อผิดพลาด, latency, ความลึกของคิว, และ query ช้า เพิ่ม tracing เฉพาะที่คำขอข้ามบริการ
Isolate slow or flaky work. งานใดที่คุยกับบริการภายนอกหรือปกติใช้เกินหนึ่งวินาที ควรย้ายเป็น jobs และ workers
Design for retries and partial failures. สมมติว่า timeout เกิดขึ้น ทำให้การทำงาน idempotent, ใช้ backoff, กำหนดขีดจำกัดเวลา, และรักษาการกระทำที่เห็นโดยผู้ใช้ให้สั้น
Practice recovery. แบ็คอัพมีค่าเมื่อคุณกู้คืนได้ ใช้การปล่อยแบบเล็ก ๆ และมีทางย้อนกลับเร็ว
ถ้าเครื่องมือของคุณรองรับ snapshot และ rollback (Koder.ai ทำ) สร้างนิสัยใช้ฟีเจอร์เหล่านั้นเป็นส่วนหนึ่งของการปล่อยปกติแทนจะเก็บไว้เป็นลูกเล่นฉุกเฉิน
ลองจินตนาการ SaaS เล็ก ๆ ช่วยทีม onboard ลูกค้าใหม่ Flow ง่าย: ผู้ใช้สมัคร เลือกแผน จ่าย แล้วได้รับอีเมลต้อนรับพร้อมขั้นตอนเริ่มต้นไม่กี่อย่าง
ในโปรโตไทป์ ทุกอย่างเกิดในคำขอเดียว: สร้างบัญชี เก็บเงิน เปลี่ยน “paid” ในผู้ใช้ ส่งอีเมล มันทำงานจนทราฟฟิกโต เกิด retry และบริการภายนอกช้าลง
เพื่อให้เชื่อถือได้ ทีมเปลี่ยนการกระทำสำคัญเป็นอีเวนต์และเก็บประวัติแบบ append-only พวกเขาแนะนำอีเวนต์บางอย่าง: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested นั่นให้ audit trail ทำให้งานวิเคราะห์ง่ายขึ้น และให้งานช้าที่จะเกิดใน background โดยไม่บล็อก signup
การตัดสินใจไม่กี่อย่างช่วยได้มาก:
PaymentSucceeded ด้วย idempotency key ชัดเจน เพื่อให้ retry ไม่มอบสิทธิ์ซ้ำถ้าการชำระเงินสำเร็จแต่การเข้าถึงยังไม่ถูกมอบ ผู้ใช้จะรู้สึกว่าถูกโกง การแก้ไม่ใช่ "ความสอดคล้องที่สมบูรณ์ทุกที่" แต่คือการตัดสินใจว่าสิ่งใดต้องสอดคล้องตอนนี้ แล้วสะท้อนการตัดสินใจนั้นใน UI ด้วยสถานะเช่น “กำลังเปิดใช้งานแผนของคุณ” จนกว่า EntitlementGranted จะมาถึง
ในวันที่ไม่ดี backpressure ทำให้ต่างกัน หากอีเมล API หน่วงในแคมเปญการตลาด แบบเดิมจะ timeout การเช็คเอาต์แล้วผู้ใช้ retry สร้างการเรียกเก็บและอีเมลซ้ำ ในดีไซน์ที่ดีกว่า การเช็คเอาต์สำเร็จ คำขออีเมลจะคิวไว้ และงาน replay จะดึง backlog ลงเมื่อผู้ให้บริการฟื้นตัว
เหตุการณ์ล่มส่วนใหญ่ไม่ใช่บั๊กเด่น ๆ แต่เกิดจากการตัดสินใจเล็ก ๆ ที่สมเหตุสมผลในโปรโตไทป์แล้วกลายเป็นนิสัย
กับดักหนึ่งคือแยกเป็น microservices เร็วเกินไป คุณได้บริการที่เรียกกันเองมาก วงจรความเป็นเจ้าของไม่ชัด และการเปลี่ยนต้อง deploy ห้ารอบแทนที่จะเป็นหนึ่ง
กับดักอีกอย่างคือใช้ “eventual consistency” เป็นข้อแก้ตัว ผู้ใช้ไม่สนใจคำศัพท์ พวกเขาสนใจที่คลิก Save แล้วหน้ากลับเป็นข้อมูลเก่า หรือตำแหน่ง invoice เปลี่ยนกลับไปมา ถ้าตกลงยอมช้า คุณยังต้องให้ feedback กับผู้ใช้ ตั้ง timeout และนิยามว่าแต่ละหน้าจอ “พอเพียง” แค่ไหน
คนทำผิดซ้ำอื่น ๆ: เผยแพร่อีเวนต์โดยไม่มีแผนการ reprocess, retry ไม่จำกัดที่เพิ่มภาระในเหตุการณ์, และให้ทุกบริการคุยตรงกับ schema เดียวกันในฐานข้อมูลจนการเปลี่ยนแปลงหนึ่งทำลายหลายทีม
“พร้อมใช้งาน” คือชุดการตัดสินใจที่คุณชี้ได้ตอนตีสอง ความชัดเจนชนะความฉลาดล้ำ
เริ่มจากตั้งชื่อแหล่งความจริง สำหรับแต่ละชนิดข้อมูลหลัก (ลูกค้า, subscription, invoice, permissions) ตัดสินใจว่าบันทึกสุดท้ายอยู่ที่ไหน ถ้าแอปของคุณอ่าน “ความจริง” จากสองที่ คุณจะโชว์คำตอบต่างกันให้ผู้ใช้ต่างกันในที่สุด
จากนั้นมาดู retry สมมติการกระทำสำคัญทุกอย่างจะรันสองครั้งสักครั้ง ถ้าคำขอเดิมเข้ามาซ้ำ คุณเลี่ยงการเรียกเก็บซ้ำ ส่งซ้ำ หรือสร้างซ้ำได้ไหม?
เช็คลิสต์เล็ก ๆ ที่จับความล้มเหลวเจ็บปวดได้ส่วนใหญ่:
การสเกลง่ายขึ้นเมื่อคุณมองการออกแบบระบบเป็นรายการสั้น ๆ ของการตัดสินใจ ไม่ใช่ทฤษฎีกองโต
เขียน 3–5 การตัดสินใจที่คาดว่าจะเจอในเดือนหน้าเป็นภาษาง่าย ๆ: “เราย้ายการส่งอีเมลไป background job ไหม?” “เรายอมรับ analytics ที่ล้าสักหน่อยไหม?” “การกระทำใดต้องสอดคล้องทันที?” ใช้รายการนั้นเพื่อให้ผลิตภัณฑ์และวิศวกรรมตรงกัน
จากนั้นเลือก workflow หนึ่งที่ตอนนี้เป็น synchronous แล้วแปลงเฉพาะอันนั้นเป็น async ใบเสร็จรับเงิน การแจ้งเตือน รายงาน และการประมวลผลไฟล์เป็นก้าวแรกที่พบได้ทั่วไป วัดสองอย่างก่อนและหลัง: latency ที่ผู้ใช้เห็น (หน้าเร็วขึ้นไหม?) และพฤติกรรมเมื่อเกิดความล้มเหลว (retry สร้างซ้ำหรือความสับสนไหม?)
ถ้าคุณอยากต้นแบบการเปลี่ยนแปลงเหล่านี้เร็ว ๆ Koder.ai (koder.ai) อาจมีประโยชน์สำหรับการวน iterate บน React + Go + PostgreSQL ขณะรักษา snapshot และ rollback ใกล้มือ เป้าหมายควรเรียบง่าย: ปล่อยการปรับปรุงหนึ่งอย่าง เรียนรู้จากทราฟฟิกจริง แล้วตัดสินใจถัดไป
A prototype answers “can we build it?” A SaaS must answer “will it keep working when users, data, and failures show up?”
The biggest shift is designing for:
Pick a boundary around what you promise users, then label actions by impact.
Start with must be correct every time:
Then mark can be eventually correct:
Choose one place where each “fact” is recorded once and treated as final (often Postgres for a small SaaS). That is your source of truth.
Everything else is derived for speed or convenience (caches, read models, search indexes). A good test: if the derived data is wrong, can you rebuild it from the source of truth without guessing?
Use request-response when the user needs an immediate result and the work is small.
Move work to async when it can happen later or can be slow:
Async keeps your API fast and reduces timeouts that trigger client retries.
A queue is a to-do list: each job should be handled once by one worker (with retries).
A stream/log is a record of events in order: multiple consumers can replay it to build features or recover.
Practical default:
Make important actions idempotent: repeating the same request should return the same outcome, not create a second invoice or charge.
Common pattern:
Also use unique constraints where possible (for example, one invoice per order).
Publish a small set of stable business facts, named in past tense, like PaymentSucceeded or SubscriptionStarted.
Keep events:
This keeps consumers from guessing what happened.
Common signs your system needs backpressure:
Good first controls:
Start with basics that match user pain:
Add tracing only where requests cross services; don’t instrument everything before you know what you’re looking for.
“Production ready” means you can answer hard questions quickly:
If your platform supports snapshots and rollback (like Koder.ai), use them as a normal release habit, not only during incidents.
Write it down as a short decision so everyone builds to the same rules.