15 ก.ย. 2568·3 นาที
David Patterson, แนวคิด RISC และผลกระทบระยะยาวของการออกแบบร่วม
สำรวจว่าการคิดแบบ RISC ของ David Patterson และการออกแบบร่วมฮาร์ดแวร์–ซอฟต์แวร์ช่วยเพิ่มประสิทธิภาพต่อวัตต์ รูปทรงของ CPU และมีอิทธิพลต่อ RISC-V ในวันนี้อย่างไร
สำรวจว่าการคิดแบบ RISC ของ David Patterson และการออกแบบร่วมฮาร์ดแวร์–ซอฟต์แวร์ช่วยเพิ่มประสิทธิภาพต่อวัตต์ รูปทรงของ CPU และมีอิทธิพลต่อ RISC-V ในวันนี้อย่างไร
David Patterson มักถูกเรียกว่า “ผู้บุกเบิก RISC” แต่ผลกระทบของเขาลึกกว่านั้น—ไม่ใช่เพียงดีไซน์ CPU ตัวใดตัวหนึ่ง เขาช่วยเผยแพร่วิธีคิดเชิงปฏิบัติ: มองประสิทธิภาพเป็นสิ่งที่วัดได้, ทำให้เรียบง่าย, และปรับปรุงแบบรอบด้าน—ตั้งแต่ชุดคำสั่งที่ชิปเข้าใจไปจนถึงเครื่องมือซอฟต์แวร์ที่สร้างคำสั่งเหล่านั้น
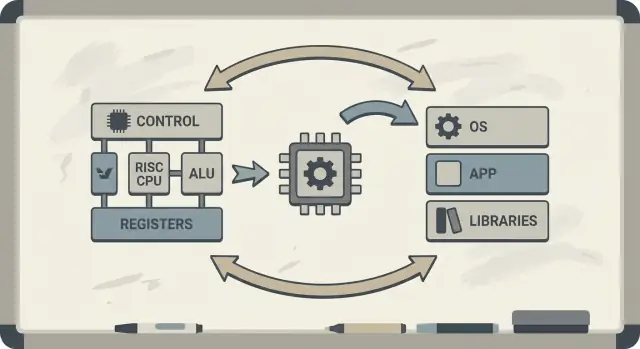
RISC (Reduced Instruction Set Computing) คือความคิดที่ว่าโปรเซสเซอร์จะทำงานได้เร็วและคาดเดาได้มากขึ้นเมื่อมุ่งเน้นชุดคำสั่งที่เล็กลงและเรียบง่าย แทนที่จะใส่ชุดคำสั่งซับซ้อนจำนวนมากลงในฮาร์ดแวร์ ให้ทำให้การดำเนินการที่พบบ่อยเร็ว สม่ำเสมอ และง่ายต่อการทำ pipeline ผลลัพธ์ไม่ใช่ “ความสามารถน้อยลง” แต่เป็นว่าบล็อกพื้นฐานที่เรียบง่าย เมื่อรันอย่างมีประสิทธิภาพ มักชนะในงานจริง
Patterson ยังผลักดันแนวคิดการออกแบบร่วมฮาร์ดแวร์–ซอฟต์แวร์: วงจรป้อนกลับที่สถาปนิกชิป นักเขียนคอมไพเลอร์ และผู้ออกแบบระบบวนกันปรับปรุง
ถ้าโปรเซสเซอร์ถูกออกแบบมาให้รันรูปแบบง่าย ๆ ได้ดี คอมไพเลอร์ก็จะสร้างรูปแบบเหล่านั้นได้สม่ำเสมอ หากคอมไพเลอร์เผยว่าโปรแกรมจริงใช้งานในกรณีบางอย่าง (เช่นการเข้าถึงหน่วยความจำ) มาก ฮาร์ดแวร์ก็สามารถปรับเพื่อรองรับกรณีนั้นได้ดีขึ้น นี่คือสาเหตุที่การพูดคุยเรื่องสถาปัตยกรรมชุดคำสั่ง (ISA) มักเชื่อมโยงกับการปรับแต่งคอมไพเลอร์ แคช และการทำพายพลายน์
คุณจะเข้าใจว่าทำไมแนวคิด RISC เกี่ยวข้องกับประสิทธิภาพต่อวัตต์ (ไม่ใช่แค่ความเร็วดิบ ๆ), ทำไม “ความคาดเดาได้” ช่วยให้ CPU สมัยใหม่และชิปมือถือประหยัดพลังงานขึ้น และหลักการเหล่านี้ปรากฏในอุปกรณ์ปัจจุบันอย่างไร—ตั้งแต่แล็ปท็อปจนถึงเซิร์ฟเวอร์คลาวด์
ถ้าคุณอยากได้แผนที่แนวคิดหลักก่อนลงลึก ให้ข้ามไปที่ /blog/key-takeaways-and-next-steps
ไมโครโปรเซสเซอร์ยุคแรกถูกสร้างภายใต้ข้อจำกัดเข้มงวด: ชิปมีพื้นที่ทรานซิสเตอร์จำกัด หน่วยความจำแพง และสตอเรจช้า นักออกแบบพยายามส่งมอบคอมพิวเตอร์ที่ราคาจับต้องได้และ “เร็วพอ” มักมีแคชเล็ก (หรือไม่มี), ความถี่นาฬิกาไม่สูงนัก, และหน่วยความจำหลักจำกัดเมื่อเทียบกับความต้องการของซอฟต์แวร์
แนวคิดยอดนิยมตอนนั้นคือถ้า CPU เสนอคำสั่งระดับสูงที่ทรงพลัง—ซึ่งทำหลายขั้นตอนในครั้งเดียว—โปรแกรมจะรันเร็วขึ้นและเขียนง่ายขึ้น ถ้าคำสั่งหนึ่ง “ทำงานแทนหลายคำสั่ง” ความคิดคือจะต้องใช้คำสั่งรวมทั้งหมดน้อยลง ประหยัดเวลาและหน่วยความจำ
นั่นคือสัญชาตญาณเบื้องหลังการออกแบบ CISC (complex instruction set computing): ให้โปรแกรมเมอร์และคอมไพเลอร์มีกล่องเครื่องมือใหญ่ของการดำเนินการหรู ๆ
ปัญหาคือโปรแกรมจริง (และคอมไพเลอร์ที่แปลมัน) มักไม่ได้ใช้ความซับซ้อนนั้นอย่างสม่ำเสมอ คำสั่งที่ซับซ้อนที่สุดหลายตัวถูกใช้งานไม่บ่อย ขณะที่ชุดการดำเนินการง่าย ๆ จำนวนเล็ก—โหลดข้อมูล เก็บข้อมูล บวก เปรียบเทียบ กระโดด—ปรากฏซ้ำแล้วซ้ำเล่า
ในขณะเดียวกัน การสนับสนุนเมนูคำสั่งที่ซับซ้อนมากทำให้ CPU ยากต่อการสร้างและช้ากว่าในการปรับแต่ง ความซับซ้อนใช้พื้นที่ชิปและความพยายามในการออกแบบที่ควรนำไปทำให้การดำเนินการที่พบบ่อยวิ่งได้เร็วและคาดเดาได้
RISC ตอบช่องว่างนั้น: มุ่งไปที่สิ่งที่ซอฟต์แวร์ทำบ่อยที่สุด แล้วทำให้เส้นทางเหล่านั้นเร็ว—จากนั้นปล่อยให้คอมไพเลอร์ทำหน้าที่ “จัดการ” ในแบบเป็นระบบ
วิธีคิดง่าย ๆ เกี่ยวกับ CISC vs RISC คือเปรียบเทียบกล่องเครื่องมือ
CISC เหมือนเวิร์กช็อปที่เต็มไปด้วยเครื่องมือเฉพาะทางและหรูหราหลายชิ้น—แต่ละชิ้นทำงานมากในครั้งเดียว คำสั่งเดียวอาจโหลดข้อมูลจากหน่วยความจำ คำนวณ แล้วเก็บผลลัพธ์ รวม ๆ กันไว้
RISC เหมือนการพกเครื่องมือที่เชื่อถือได้ชุดเล็ก ๆ ที่ใช้บ่อย—ค้อน ไขควง ตลับเมตร—แล้วประกอบทุกอย่างจากขั้นตอนที่ทำซ้ำได้ แต่ละคำสั่งมักทำงานเล็ก ๆ ที่ชัดเจนหนึ่งอย่าง
เมื่อคำสั่งเรียบง่ายและสม่ำเสมอ CPU สามารถประมวลผลพวกมันด้วยสายการประกอบที่ชัดเจนกว่า (pipeline) สายการประกอบนั้นง่ายต่อการออกแบบ ให้รันที่ความถี่สูงกว่า และง่ายต่อการทำให้ไม่ว่างงาน
กับคำสั่งแบบ CISC ที่ทำมาก ๆ ในครั้งเดียว CPU มักต้องถอดรหัสและแบ่งคำสั่งซับซ้อนเป็นขั้นตอนย่อยภายในอยู่ดี ซึ่งเพิ่มความซับซ้อนและทำให้ยากที่จะรักษาการไหลของ pipeline ให้ราบรื่น
RISC มุ่งเป้าไปที่ เวลาคำสั่งที่คาดเดาได้—หลายคำสั่งใช้เวลาประมาณเดียวกัน ความคาดเดานี้ช่วยให้ CPU จัดตารางงานได้มีประสิทธิภาพและช่วยให้คอมไพเลอร์สร้างโค้ดที่รักษา pipeline ให้ไม่ติดขัด
RISC มักต้องใช้ คำสั่งมากขึ้นเพื่อทำงานเดียวกัน ซึ่งอาจหมายถึง:
แต่สิ่งเหล่านี้ยังคงคุ้มค่าถ้าคำสั่งแต่ละคำสั่งเร็ว pipeline ราบรื่น และการออกแบบโดยรวมเรียบง่าย ในทางปฏิบัติ คอมไพเลอร์ที่ปรับแต่งดีและแคชที่ดีสามารถชดเชยข้อเสียเรื่องคำสั่งมากขึ้นได้—และ CPU จะใช้เวลามากขึ้นทำงานที่มีประโยชน์ และใช้น้อยลงกับการแก้ไขคำสั่งซับซ้อน
Berkeley RISC ไม่ได้เป็นเพียงชุดคำสั่งใหม่ แต่มันคือทัศนคติในการวิจัย: อย่าเริ่มจากสิ่งที่ดูสง่างามบนกระดาษ—เริ่มจากสิ่งที่โปรแกรมทำจริง แล้วปรับ CPU รอบความเป็นจริงนั้น
ในเชิงแนวคิด ทีม Berkeley มุ่งไปที่คอร์ CPU ที่เรียบง่ายพอจะรันได้เร็วและคาดเดาได้ แทนที่จะยัดฮาร์ดแวร์ด้วยลูกเล่นคำสั่งซับซ้อนหลายอย่าง พวกเขาให้คอมไพเลอร์ทำงานมากขึ้น: เลือกคำสั่งตรงไปตรงมา จัดตารางคำสั่งให้ดี และเก็บข้อมูลในรีจิสเตอร์ให้มากที่สุดเท่าที่จะเป็นไปได้
การแบ่งงานแบบนี้มีความหมาย คอร์ที่เล็กและชัดเจนง่ายต่อการทำ pipeline อย่างมีประสิทธิภาพ ง่ายต่อการเข้าใจ และมักเร็วต่อทรานซิสเตอร์ คอมไพเลอร์ที่เห็นโปรแกรมทั้งตัวสามารถวางแผนล่วงหน้าในแบบที่ฮาร์ดแวร์ทำได้ยากในเวลาจริง
David Patterson เน้นการวัดเพราะการออกแบบคอมพิวเตอร์เต็มไปด้วยมายาคติ—ฟีเจอร์ที่ฟังดูมีประโยชน์แต่หาใช้งานจริงไม่บ่อย Berkeley RISC ผลักดันให้ใช้ benchmark และ trace ของเวิร์กโหลดเพื่อหาเส้นทางร้อน: ลูป, การเรียกฟังก์ชัน, และการเข้าถึงหน่วยความจำที่กินเวลา
สิ่งนี้เชื่อมโดยตรงกับหลักการ “ทำให้กรณีที่พบบ่อยเร็ว” หากคำสั่งส่วนใหญ่เป็นการดำเนินการเรียบง่ายและโหลด/สโตร์ การปรับจุดที่พบบ่อยเหล่านั้นจะคุ้มค่ากว่าการเร่งคำสั่งที่ซับซ้อนและเกิดขึ้นไม่บ่อย
ข้อสรุปที่คงทนคือ RISC เป็นทั้งสถาปัตยกรรมและกรอบความคิด: ทำให้สิ่งที่พบบ่อยเรียบง่าย, ยืนยันด้วยข้อมูล, และมองฮาร์ดแวร์กับซอฟต์แวร์เป็นระบบเดียวที่ปรับจูนร่วมกันได้
การออกแบบร่วมฮาร์ดแวร์–ซอฟต์แวร์คือแนวคิดที่ว่าไม่ควรออกแบบ CPU แบบโดดเดี่ยว คุณออกแบบชิป และ คอมไพเลอร์ (และบางครั้งระบบปฏิบัติการ) โดยคำนึงถึงกันและกัน เพื่อให้โปรแกรมจริงรันได้เร็วและมีประสิทธิภาพ ไม่ใช่แค่ลำดับคำสั่ง “กรณีดีที่สุด” เชิงสังเคราะห์
การออกแบบร่วมทำงานเหมือนวงจรวิศวกรรม:
ตัวเลือก ISA: ISA ตัดสินว่าสิ่งใด CPU จะสื่อสารได้ง่าย (เช่น “load/store” การเข้าถึงหน่วยความจำ, จำนวนรีจิสเตอร์มาก, โหมด addressing เรียบง่าย)
ยุทธศาสตร์คอมไพเลอร์: คอมไพเลอร์ปรับตัว—เก็บตัวแปรร้อนในรีจิสเตอร์, เรียงลำดับคำสั่งเพื่อลด stall, และเลือก calling conventions ที่ลดค่าบังคับ
ผลลัพธ์จากเวิร์กโหลด: คุณวัดโปรแกรมจริง (คอมไพเลอร์, ฐานข้อมูล, กราฟิก, โค้ด OS) และดูว่าเวลาและพลังงานไปที่ใด
การออกแบบถัดไป: ปรับ ISA และไมโครสถาปัตยกรรม (ความลึก pipeline, จำนวนรีจิสเตอร์, ขนาดแคช) ตามการวัดเหล่านั้น
นี่คือตัวอย่างวงจรเล็ก (C) ที่ชี้ให้เห็นความสัมพันธ์:
for (int i = 0; i < n; i++)
sum += a[i];
บน ISA แบบ RISC คอมไพเลอร์มักเก็บ sum และ i ใน รีจิสเตอร์, ใช้คำสั่ง load แบบเรียบง่ายสำหรับ a[i], และทำ instruction scheduling เพื่อให้ CPU ยังคงงานระหว่างที่การโหลดกำลังมา
ถ้าชิปเพิ่มคำสั่งซับซ้อนหรือฮาร์ดแวร์พิเศษที่คอมไพเลอร์ใช้ไม่บ่อย พื้นที่นั้นยังคงใช้พลังงานและความพยายามในการออกแบบ ในขณะเดียวกันสิ่งที่คอมไพเลอร์ ใช้จริง—รีจิสเตอร์เพียงพอ, pipeline ที่คาดเดาได้, calling conventions ที่มีประสิทธิภาพ—อาจถูกละเลย Patterson เน้นการใช้ซิลิกอนในที่ที่ซอฟต์แวร์จริงจะได้ประโยชน์จริงๆ
หนึ่งในแนวคิดสำคัญของ RISC คือทำให้ “สายการประกอบ” ของ CPU ง่ายต่อการรักษาให้ไม่ว่าง สายการประกอบนั้นคือ pipeline: แทนที่จะทำคำสั่งหนึ่งให้เสร็จก่อนเริ่มคำสั่งถัดไป โปรเซสเซอร์แบ่งงานออกเป็นสเตจ (fetch, decode, execute, write-back) และทับกัน เมื่อทุกอย่างไหล คุณจะทำคำสั่งใกล้เคียงหนึ่งต่อรอบนาฬิกา—เหมือนรถผ่านโรงงานหลายสถานี
Pipeline ทำงานดีที่สุดเมื่อไอเท็มแต่ละชิ้นในสายคล้ายกัน คำสั่ง RISC ถูกออกแบบให้ค่อนข้างสม่ำเสมอและคาดเดาได้ (มักความยาวคงที่ พร้อม addressing แบบเรียบง่าย) ซึ่งลดกรณีพิเศษที่ต้องใช้เวลาพิเศษหรือทรัพยากรผิดปกติ
โปรแกรมจริงไม่ได้ราบรื่นเสมอ บางครั้งคำสั่งหนึ่งขึ้นกับผลของคำสั่งก่อนหน้า (ไม่สามารถใช้ค่าก่อนมันถูกคำนวณ) บางครั้ง CPU ต้องรอข้อมูลจากหน่วยความจำ หรือยังไม่รู้เส้นทางของ branch
สถานการณ์เหล่านี้ทำให้เกิด stalls—การหยุดชั่วคราวที่บางส่วนของ pipeline นิ่ง ความเข้าใจง่ายคือ: stall เกิดเมื่อสเตจถัดไปไม่สามารถทำงานที่มีประโยชน์ได้เพราะบางสิ่งที่ต้องการยังมาไม่ถึง
นี่คือจุดที่การออกแบบร่วมเผยให้เห็นอย่างชัดเจน หากฮาร์ดแวร์คาดเดาได้ คอมไพเลอร์ช่วยได้ โดยจัดเรียงคำสั่งใหม่ (โดยไม่เปลี่ยนความหมายของโปรแกรม) เพื่อเติม “ช่องว่าง” ตัวอย่างเช่น ขณะที่รอค่ายังไม่พร้อม คอมไพเลอร์อาจสลับคำสั่งที่ไม่ขึ้นกับค่านั้นมาไว้ก่อน
ผลลัพธ์คือความรับผิดชอบที่แชร์: CPU ยังคงเรียบง่ายและเร็วในกรณีที่พบบ่อย ขณะที่คอมไพเลอร์ทำการวางแผนร่วมกัน ทั้งคู่ลด stalls และเพิ่ม throughput—มักปรับปรุงประสิทธิภาพจริงโดยไม่ต้องเพิ่มชุดคำสั่งซับซ้อนกว่าเดิม
CPU สามารถทำการดำเนินการง่าย ๆ ในไม่กี่รอบ แต่การดึงข้อมูลจากหน่วยความจำหลัก (DRAM) อาจใช้เวลาหลายร้อยรอบ ความต่างนี้เกิดเพราะ DRAM อยู่ไกลทางกายภาพกว่า ถูกปรับให้เหมาะกับความจุและต้นทุน และถูกจำกัดทั้งความหน่วง (latency) และแบนด์วิดท์ (bandwidth)
เมื่อ CPU เร็วขึ้น หน่วยความจำไม่ได้ก้าวขึ้นตามในอัตราเดียวกัน—ช่องว่างที่เพิ่มนี้มักถูกเรียกว่าผนังหน่วยความจำ (memory wall)
แคชคือหน่วยความจำเล็กและเร็วที่วางใกล้ CPU เพื่อลดการจ่ายค่าปรับเป็น DRAM พวกมันทำงานเพราะโปรแกรมจริงมี locality:
ชิปสมัยใหม่ซ้อนแคช (L1, L2, L3) พยายามเก็บ “working set” ของโค้ดและข้อมูลให้ใกล้คอร์ที่สุด
นี่คือที่การออกแบบร่วมฮาร์ดแวร์–ซอฟต์แวร์ให้ผลมาก ISA กับคอมไพเลอร์ร่วมกันกำหนดแรงกดดันต่อแคชที่โปรแกรมสร้างขึ้น
ในแง่ง่าย ๆ memory wall คือเหตุผลที่แม้ CPU จะมีความถี่สูงก็อาจรู้สึกช้า: การเปิดแอปขนาดใหญ่, รันคิวรีฐานข้อมูล, เลื่อนฟีด, หรือประมวลผลชุดข้อมูลใหญ่ มักคอขวดที่การพลาดแคชและแบนด์วิดท์ของหน่วยความจำ—ไม่ใช่ที่ความเร็วการคำนวณดิบ
มานานแล้วที่การพูดคุยเรื่อง CPU เหมือนการแข่งขัน: ชิปไหนทำงานเสร็จเร็วกว่า “ชนะ” แต่คอมพิวเตอร์จริงอยู่ภายในข้อจำกัดทางกายภาพ—แบตเตอรี่ ความร้อน เสียงพัดลม ค่าไฟ
นั่นคือเหตุผลที่ ประสิทธิภาพต่อวัตต์ กลายเป็นเมตริกสำคัญ: งานที่มีประโยชน์เทียบกับพลังงานที่ใช้
คิดว่าเป็นความคุ้มค่า ไม่ใช่พลังสูงสุด สองโปรเซสเซอร์อาจรู้สึกเร็วใกล้เคียงกัน แต่ตัวหนึ่งทำได้โดยใช้น้อยกว่า นั่นมีผลโดยตรงกับอายุแบตเตอรี่และความสบาย ในดาต้าเซ็นเตอร์มีผลกับค่าไฟและการระบายความร้อน รวมถึงความหนาแน่นที่คุณสามารถวางเซิร์ฟเวอร์ติดกันโดยไม่ร้อนเกินไป
การคิดแบบ RISC ผลักดันการออกแบบ CPU ไปทางทำสิ่งน้อยลงในฮาร์ดแวร์และคาดเดาได้มากขึ้น คอร์ที่เรียบง่ายสามารถลดพลังงานได้หลายทาง:
จุดประสงค์ไม่ใช่ว่า “เรียบง่ายดีกว่าทุกครั้ง” แต่ความซับซ้อนมีต้นทุนพลังงาน และชุดคำสั่ง/ไมโครสถาปัตยกรรมที่เลือกดี ๆ สามารถแลกความฉลาดบางอย่างเพื่อประสิทธิภาพที่มากขึ้น
โทรศัพท์ห่วงใยแบตเตอรี่และความร้อน เซิร์ฟเวอร์ห่วงใยการจ่ายพลังงานและการระบายความร้อน สภาพแวดล้อมต่างกันแต่บทเรียนเดียวกัน: ชิปที่เร็วที่สุดไม่จำเป็นต้องเป็นคอมพิวเตอร์ที่ดีที่สุด ผู้ชนะมักเป็นการออกแบบที่ให้ throughput สม่ำเสมอในขณะที่ควบคุมการใช้พลังงานได้ดี
RISC มักถูกสรุปว่า “คำสั่งเรียบง่ายชนะ” แต่บทเรียนที่คงทนนั้นละเอียดขึ้น: ชุดคำสั่งสำคัญ แต่การเพิ่มประสิทธิภาพส่วนใหญ่เกิดจากวิธีการสร้างชิป ไม่ใช่เพียงว่า ISA ดูอย่างไรบนกระดาษ
ข้อโต้แย้ง RISC ยุคแรกชี้ว่าชุดคำสั่งที่เรียบง่ายจะทำให้เครื่องเร็วขึ้นโดยอัตโนมัติ ในทางปฏิบัติ การเพิ่มความเร็วที่ใหญ่ที่สุดมักมาจากการตัดสินใจนำไปปฏิบัติที่ RISC ทำให้เป็นเรื่องง่าย: การถอดรหัสที่เรียบง่าย, การทำ pipeline ให้ลึกขึ้น, ความถี่สูงขึ้น, และคอมไพเลอร์ที่สามารถจัดตารางงานได้คาดเดาได้มากขึ้น
นั่นคือเหตุผลว่าทำไมสอง CPU ที่มี ISA ต่างกันอาจมีประสิทธิภาพใกล้เคียงกันถ้าไมโครสถาปัตยกรรม ขนาดแคช การทำนายสาขา และกระบวนการผลิตต่างกัน ISA กำหนดกฎ; ไมโครสถาปัตยกรรมเล่นเกม
แนวคิดสำคัญจากยุค Patterson คือการออกแบบจากข้อมูล ไม่ใช่จากสมมติฐาน แทนที่จะเพิ่มคำสั่งเพราะดูเหมือนจะมีประโยชน์ ทีมงานวัดสิ่งที่โปรแกรมทำจริง แล้วปรับจูนกรณีที่พบมากที่สุด วิธีคิดนี้มักชนะการออกแบบที่ขับเคลื่อนด้วยฟีเจอร์ ที่ซับซ้อนเติบโตเร็วกว่าเมื่อเทียบกับประโยชน์ และช่วยให้การแลกเปลี่ยนชัดเจนขึ้น: คำสั่งที่ประหยัดบรรทัดโค้ดอาจต้องแลกกับรอบเวลา พลังงาน หรือพื้นที่ชิป—และต้นทุนเหล่านั้นปรากฏชัดในทุกที่
แนวคิด RISC ไม่ได้ทำให้เกิดชิป RISC เพียงอย่างเดียว เมื่อเวลาผ่านไป ชิป CISC หลายตัวก็รับเทคนิคแบบ RISC ภายใน (เช่นการแบ่งคำสั่งซับซ้อนเป็นการดำเนินการภายในที่เรียบง่าย) ในขณะที่ยังคงความเข้ากันได้ของ ISA ดั้งเดิมไว้
ผลลัพธ์ไม่ใช่ “RISC ชนะ CISC” แต่เป็นวิวัฒนาการไปสู่การออกแบบที่ให้ความสำคัญกับการวัด ผลที่คาดเดาได้ และการประสานฮาร์ดแวร์–ซอฟต์แวร์—ไม่ว่าป้ายชื่อ ISA จะเป็นอะไร
RISC ไม่ได้อยู่แค่ในห้องทดลอง หนึ่งในเส้นตรงจากงานวิจัยสู่การใช้งานจริงคือเส้นทางจาก MIPS ถึง RISC-V—สอง ISA ที่ทำให้ความเรียบง่ายและความชัดเจนเป็นคุณสมบัติ ไม่ใช่ข้อจำกัด
MIPS มักถูกจดจำในฐานะ ISA สำหรับการสอน และด้วยเหตุผลที่ดี: กฎเข้าใจง่าย รูปแบบคำสั่งสอดคล้องกัน และโมเดล load/store ช่วยไม่ให้คอมไพเลอร์ยุ่งยาก ความชัดเจนนี้ไม่ใช่แค่เรื่องวิชาการ MIPS ถูกใช้ในผลิตภัณฑ์จริงมาหลายปี (ตั้งแต่วิร์กสเตชันจนถึงระบบฝังตัว) เพราะ ISA ที่ตรงไปตรงมาทำให้สร้าง pipeline ดำเนินการได้ง่าย คอมไพเลอร์ที่คาดเดาได้ และทูลเชนที่มีประสิทธิภาพ เมื่อพฤติกรรมฮาร์ดแวร์สม่ำเสมอ ซอฟต์แวร์ก็วางแผนได้น่าเชื่อถือ
RISC-V เติมชีวิตให้แนวคิด RISC โดยก้าวสำคัญที่ MIPS ไม่ได้ทำ: เป็น ISA แบบเปิด การเปิดให้ลองนี้เปลี่ยนแรงจูงใจ มหาวิทยาลัย สตาร์ทอัพ และบริษัทใหญ่สามารถทดลอง ส่งซิลิคอน และแชร์ทูลโดยไม่ต้องต่อรองสิทธิ์ของชุดคำสั่ง
สำหรับการออกแบบร่วม การเปิดนี้สำคัญเพราะฝั่งซอฟต์แวร์ (คอมไพเลอร์, OS, รันไทม์) สามารถวิวัฒนาร่วมกับฝั่งฮาร์ดแวร์ในที่สาธารณะโดยมีอุปสรรคทางสิทธิน้อยลง
อีกเหตุผลที่ RISC-V เข้ากับการออกแบบร่วมได้ดีคือแนวทางแบบโมดูลาร์ คุณเริ่มจาก ISA พื้นฐานเล็ก ๆ แล้วเพิ่มส่วนขยายสำหรับความต้องการเฉพาะ—เช่น คณิตศาสตร์แบบเวกเตอร์ ข้อจำกัดฝังตัว หรือฟีเจอร์ด้านความปลอดภัย
สิ่งนี้ส่งเสริมการแลกเปลี่ยนที่เหมาะสมกว่า: แทนที่จะยัดฟีเจอร์ทุกอย่างในดีไซน์เดียว ทีมสามารถจับคู่ฟีเจอร์ฮาร์ดแวร์กับซอฟต์แวร์ที่พวกเขาจะรันจริง
ถ้าคุณต้องการบทนำเชิงลึกขึ้น ดู /blog/what-is-risc-v
การออกแบบร่วมไม่ใช่ประวัติศาสตร์ยุค RISC เท่านั้น—มันคือวิธีที่คอมพิวติ้งสมัยใหม่ก้าวหน้าต่อไป แนวคิดสำคัญยังคงแบบ Patterson: คุณไม่ “ชนะ” ด้วยฮาร์ดแวร์หรือซอฟต์แวร์เพียงอย่างเดียว คุณชนะเมื่อทั้งสองเข้ากันกับจุดแข็งและข้อจำกัดของกันและกัน
สมาร์ทโฟนและอุปกรณ์ฝังตัวหลายตัวพึ่งพาหลักการ RISC (มักเป็น ARM-based): คำสั่งเรียบง่าย การดำเนินการคาดเดาได้ และเน้นการใช้พลังงานต่ำ ความคาดเดานี้ช่วยให้คอมไพเลอร์สร้างโค้ดที่มีประสิทธิภาพและช่วยให้นักออกแบบสร้างคอร์ที่กินพลังงานน้อยเมื่อคุณเลื่อนหน้า แต่สามารถระเบิดประสิทธิภาพเมื่อถ่ายภาพหรือเล่นเกม
แล็ปท็อปและเซิร์ฟเวอร์ก็ไล่ตามเป้าหมายเดียวกัน—โดยเฉพาะเรื่อง ประสิทธิภาพต่อวัตต์ แม้ ISA จะไม่ใช่แบบ RISC แบบดั้งเดิม หลายการตัดสินใจภายในยังคงมุ่งสู่ประสิทธิภาพแบบ RISC: pipelining ลึก, การประมวลผลกว้าง, และการจัดการพลังงานเชิงรุกที่ปรับให้เข้ากับพฤติกรรมซอฟต์แวร์จริง
GPU, AI accelerators (TPUs/NPUs), และเอนจินมีเดีย คือรูปแบบปฏิบัติของการออกแบบร่วม: แทนที่จะโยนงานทั้งหมดผ่าน CPU ทั่วไป แพลตฟอร์มให้ฮาร์ดแวร์ที่ตรงกับรูปแบบการคำนวณที่พบบ่อย
สิ่งที่ทำให้เป็นการออกแบบร่วม (ไม่ใช่แค่ฮาร์ดแวร์เพิ่ม) คือสแตกซอฟต์แวร์รอบ ๆ:
ถ้าซอฟต์แวร์ไม่มุ่งเป้าไปที่ accelerator ความเร็วเชิงทฤษฎีก็ยังอยู่ในระดับทฤษฎี
สองแพลตฟอร์มที่สเป็กใกล้เคียงกันอาจให้ความรู้สึกต่างกันมากเพราะ “ผลิตภัณฑ์จริง” รวมคอมไพเลอร์ ไลบรารี และเฟรมเวิร์ก ไลบรารีคณิตศาสตร์ที่ปรับแต่งดี (เช่น BLAS), JIT ดี, หรือคอมไพเลอร์ที่ฉลาดสามารถให้ประโยชน์มากโดยไม่ต้องเปลี่ยนชิป
นี่คือเหตุผลที่การออกแบบ CPU สมัยใหม่มักขับเคลื่อนด้วย benchmark: ทีมฮาร์ดแวร์ดูว่าคอมไพเลอร์และเวิร์กโหลดทำอะไรจริง แล้วปรับฟีเจอร์ (แคช, การทำนายสาขา, คำสั่งเวกเตอร์, prefetching) เพื่อเร่งกรณีที่พบบ่อย
เมื่อตรวจแพลตฟอร์ม (โทรศัพท์ แล็ปท็อป เซิร์ฟเวอร์ หรือบอร์ดฝังตัว) มองหาสัญญาณการออกแบบร่วม:
ความก้าวหน้าของคอมพิวติ้งยุคใหม่เกี่ยวกับระบบฮาร์ดแวร์พร้อมซอฟต์แวร์ที่ถูกปรับแต่ง—วัด แล้วออกแบบ—รอบเวิร์กโหลดจริง ไม่ใช่แค่ CPU ที่เร็วขึ้นตัวเดียว
แนวคิด RISC และข้อความกว้างของ Patterson สรุปเป็นบทเรียนคงทนไม่กี่ข้อ: ทำให้สิ่งที่ต้องเร็วเรียบง่าย, วัดในสถานการณ์จริง, และมองฮาร์ดแวร์กับซอฟต์แวร์เป็นระบบเดียว—เพราะผู้ใช้สัมผัสทั้งระบบ ไม่ใช่องค์ประกอบแยกกัน
อันดับแรก ความเรียบง่ายเป็นกลยุทธ์ไม่ใช่ความงาม ชุดคำสั่งที่ชัดเจนและการดำเนินการที่คาดเดาได้ทำให้คอมไพเลอร์สร้างโค้ดที่ดีขึ้นและ CPU รันโค้ดนั้นได้มีประสิทธิภาพมากขึ้น
ประการที่สอง การวัดชนะสัญชาตญาณ ใช้ benchmark ที่เป็นตัวแทน รวบรวมข้อมูลโปรไฟล์ และปล่อยให้คอขวดจริงชี้นำการตัดสินใจ—ไม่ว่าจะเป็นการปรับแต่งคอมไพเลอร์ การเลือก SKU ของ CPU หรือการออกแบบเส้นทางร้อนที่สำคัญ
ประการที่สาม การออกแบบร่วมคือที่ที่ผลประโยชน์ซ้อนกัน โค้ดที่เป็นมิตรกับ pipeline โครงสร้างข้อมูลที่คำนึงถึงแคช และเป้าหมาย performance-per-watt ที่สมจริง มักให้ความเร็วใช้งานจริงมากกว่าการไล่ตาม throughput เชิงทฤษฎีสูงสุด
ถ้าคุณกำลังเลือกแพลตฟอร์ม (x86, ARM, หรือ RISC-V-based) ประเมินแบบที่ผู้ใช้ของคุณจะทำ:
ถ้าหน้าที่ของคุณคือ เปลี่ยนการวัดเหล่านี้เป็นซอฟต์แวร์ที่ส่งมอบได้ การย่อวงจรการสร้าง–วัดอาจช่วยได้ ทีมตัวอย่างใช้ Koder.ai เพื่อสร้างต้นแบบและพัฒนาแอปจริงผ่านเวิร์กโฟลว์แบบแชท (เว็บ, backend, และมือถือ) แล้วรัน benchmark แบบ end-to-end เดิมหลังการเปลี่ยนแต่ละครั้ง ฟีเจอร์อย่างโหมดวางแผน, สแน็ปชอต, และการย้อนกลับ สนับสนุนวินัย “วัด แล้วออกแบบ” แบบเดียวกับที่ Patterson ผลัก—ปรับใช้กับการพัฒนาผลิตภัณฑ์สมัยใหม่
สำหรับบทนำเชิงลึกเกี่ยวกับประสิทธิภาพ ดู /blog/performance-per-watt-basics หากคุณกำลังเปรียบเทียบสภาพแวดล้อมและต้องการวิธีง่าย ๆ ประเมินการแลกเปลี่ยนค่าใช้จ่าย/ประสิทธิภาพ, /pricing อาจช่วยได้
ข้อสรุปที่คงทน: แนวคิด—ความเรียบง่าย, การวัด, และการออกแบบร่วม—ยังคงให้ผลตอบแทน แม้ว่าการนำไปปฏิบัติจะพัฒนาไปจากท่อ MIPS สู่คอร์ที่หลากหลายและ ISA ใหม่อย่าง RISC-V.
RISC (Reduced Instruction Set Computing) เน้นชุดคำสั่งที่เล็กกว่า เรียบง่าย และสม่ำเสมอ ซึ่งง่ายต่อการทำ pipeline และการปรับแต่ง จุดประสงค์ไม่ใช่ “ความสามารถน้อยลง” แต่เป็น การดำเนินการที่คาดเดาได้และมีประสิทธิภาพมากขึ้น ในการทำงานที่โปรแกรมจริง ๆ ใช้บ่อยที่สุด (การโหลด/เก็บข้อมูล, การคำนวณ, การตัดสินใจ/สาขา)
CISC มีชุดคำสั่งที่ซับซ้อนและเฉพาะทางจำนวนมาก บางคำสั่งอาจทำหลายขั้นตอนรวมกันในครั้งเดียว ส่วน RISC ใช้บล็อกพื้นฐานที่เรียบง่าย (มักเป็นรูปแบบ load/store + คำสั่ง ALU) แล้วให้คอมไพเลอร์ประกอบบล็อกเหล่านั้นอย่างมีประสิทธิภาพ ใน CPU สมัยใหม่เส้นแบ่งเริ่มเบลอเพราะชิป CISC หลายตัวจะแปลงคำสั่งซับซ้อนเหล่านั้นเป็นการดำเนินการภายในที่เรียบง่าย
คำสั่งที่เรียบง่ายและสม่ำเสมอทำให้สร้าง pipeline ที่ราบรื่นขึ้นได้ง่ายกว่า (เหมือนสายการประกอบที่ไม่ต้องมีกรณีพิเศษมาก) นั่นช่วยเพิ่ม throughput (ใกล้เคียงหนึ่งคำสั่งต่อรอบนาฬิกา) และลดเวลาที่ต้องจัดการกรณีพิเศษ ซึ่งมักช่วยทั้งเรื่องประสิทธิภาพและการใช้พลังงาน
ISA และรูปแบบการทำงานที่คาดเดาได้ช่วยให้คอมไพเลอร์สามารถ:
สิ่งเหล่านี้ลดช่องว่างใน pipeline และงานที่เสียเปล่า ช่วยให้ได้ประสิทธิภาพจริงโดยไม่ต้องเพิ่มฮาร์ดแวร์ซับซ้อนที่ซอฟต์แวร์ไม่ใช้
Hardware–software co-design คือวงจรเชิงปฏิสัมพันธ์ที่เลือก ISA, ยุทธศาสตร์ของคอมไพเลอร์ และการวัดผลของเวิร์กโหลดมาช่วยกันปรับปรุง แทนที่จะออกแบบ CPU แยกส่วน ทีมงานจะปรับฮาร์ดแวร์ ทูลเชน และบางครั้ง OS/รันไทม์ร่วมกัน เพื่อให้โปรแกรมจริงรันได้เร็วและมีประสิทธิภาพกว่าแค่ทดสอบชุดคำสั่งสังเคราะห์
Stalls เกิดเมื่อ pipeline ไม่สามารถเดินต่อได้เพราะรอก่อน:
ความคาดเดาได้แบบ RISC ช่วยให้ฮาร์ดแวร์และคอมไพเลอร์ลดความถี่และต้นทุนของการหยุดเหล่านี้ได้
“Memory wall” คือช่องว่างที่กว้างขึ้นระหว่างการประมวลผลเร็วของ CPU กับการเข้าถึงหน่วยความจำหลักที่ช้า (DRAM) แคช (L1/L2/L3) ช่วยบรรเทาด้วยการอาศัย locality:
แต่การพลาดแคชยังคงเป็นคอขวดและมักทำให้โปรแกรมติดกับหน่วยความจำ แม้คอร์จะเร็วมาก
มันคือเมตริกของ ประสิทธิภาพพลังงาน: งานที่มีประโยชน์ต่อพลังงานที่ใช้ สองโปรเซสเซอร์อาจรู้สึกเร็วใกล้เคียงกัน แต่ตัวหนึ่งทำได้โดยใช้พลังงานน้อยกว่า นั่นสำคัญกับแบตเตอรี่ ความร้อน เสียงพัดลม และค่าไฟในดาต้าเซ็นเตอร์ การออกแบบที่ยึดหลัก RISC มักมุ่งสู่การรันที่คาดเดาได้เพื่อลดการสลับที่เสียเปล่า ซึ่งช่วยปรับปรุง performance per watt
คำตอบไม่ใช่การที่ RISC “ชนะ” CISC โดยสมบูรณ์ เพราะชิป CISC หลายตัวยืมเทคนิคภายในแบบ RISC (การแบ่งคำสั่งเป็น micro-ops, pipelining ฯลฯ) แต่สิ่งที่เปลี่ยนคือกรอบความคิด: วัดผลเวิร์กโหลดจริง, ทำให้กรณีที่พบบ่อยเร็วขึ้น, และประสานฮาร์ดแวร์กับซอฟต์แวร์
RISC-V เป็น ISA แบบเปิดที่มีฐานเล็กและส่วนขยายแบบโมดูลาร์ ทำให้เหมาะกับการออกแบบร่วม: ทีมสามารถปรับฟีเจอร์ฮาร์ดแวร์ให้ตรงกับความต้องการซอฟต์แวร์ และพัฒนาทูลเชนแบบสาธารณะได้ นั่นคือการต่อยอดแนวคิด RISC แบบทันสมัย (ดูเพิ่มเติมที่ /blog/what-is-risc-v)