สิ่งที่โพสต์นี้ครอบคลุม (และทำไมมันสำคัญ)
Snowflake ทำให้แนวคิดง่าย ๆ แต่นำไปไกลในคลังข้อมูลบนคลาวด์เป็นที่แพร่หลาย: เก็บที่เก็บข้อมูลและการประมวลผลคำสั่งแยกจากกัน แนวแยกนี้เปลี่ยนสองปัญหาที่ทีมข้อมูลเจอเป็นประจำ—วิธีที่คลังข้อมูลปรับขนาด และ วิธีที่คุณจ่ายเงิน
แทนที่จะมองคลังข้อมูลเป็น “กล่อง” เดียวคงที่ (ที่ผู้ใช้มากขึ้น ข้อมูลมากขึ้น หรือคำสั่งซับซ้อนมากขึ้นต่างแย่งทรัพยากรร่วมกัน) โมเดลของ Snowflake ให้คุณเก็บข้อมูลครั้งเดียวแล้วสปิน compute ให้เหมาะเมื่อต้องการ ผลลัพธ์มักเป็นเวลาตอบที่เร็วขึ้น คอขวดน้อยลงในช่วงพีก และการควบคุมต้นทุนที่ชัดเจนขึ้นว่าอะไรเสียเงิน (และเมื่อไหร่)
ธีม #1: ประสิทธิภาพและการปรับขนาดโดยไม่ต้องแลกกับข้อจำกัดเดิม
โพสต์นี้อธิบายด้วยภาษาง่าย ๆ ว่าการแยก storage กับ compute แปลว่าอะไรจริง ๆ—และส่งผลอย่างไรต่อ:
- Concurrency (คนจำนวนมากรันคำสั่งพร้อมกัน)
- Elastic scaling (ปรับ compute ขึ้น/ลงได้)
- พฤติกรรมต้นทุน (จ่ายเฉพาะ compute ขณะรัน และค่า storage ต่อเนื่อง)
เราจะชี้ด้วยด้วยว่าโมเดลนี้ไม่ได้แก้ทุกอย่างแบบวิเศษ—เพราะความประหลาดใจด้านต้นทุนและประสิทธิภาพบางอย่างมาจากการออกแบบโหลดงาน ไม่ใช่แพลตฟอร์มเอง
ธีม #2: ทำไมระบบนิเวศจึงสำคัญพอ ๆ กับความเร็ว
แพลตฟอร์มที่รวดเร็วไม่ใช่เรื่องทั้งหมด สำหรับหลายทีม เวลาในการได้ผลลัพธ์ขึ้นอยู่กับว่าคุณเชื่อมคลังข้อมูลกับเครื่องมือที่ใช้อยู่แล้วได้ง่ายแค่ไหน—ท่อ ETL/ELT, แดชบอร์ด BI, เครื่องมือ catalog/กำกับดูแล, ควบคุมความปลอดภัย และแหล่งข้อมูลพันธมิตร
ระบบนิเวศของ Snowflake (รวมถึงรูปแบบการแชร์ข้อมูลและการแจกจ่ายแบบ marketplace) สามารถย่นเวลาในการติดตั้งและลดงานวิศวกรรมเฉพาะทาง โพสต์นี้ครอบคลุมว่า “ความลึกของระบบนิเวศ” ดูเป็นอย่างไรในทางปฏิบัติ และประเมินอย่างไรสำหรับองค์กรของคุณ
ใครเหมาะกับบทความนี้
คู่มือนี้เขียนให้กับ ผู้นำด้านข้อมูล นักวิเคราะห์ และผู้ตัดสินใจที่ไม่ชำนาญพิเศษ—ใครก็ตามที่ต้องเข้าใจการแลกเปลี่ยนเบื้องหลังสถาปัตยกรรม Snowflake การปรับขนาด ต้นทุน และการเชื่อมต่อ โดยไม่จมอยู่กับศัพท์เทคนิคของผู้ขาย
ก่อนจะแยก: ทำไมคลังข้อมูลแบบเดิมถึงมีข้อจำกัด
คลังข้อมูลแบบดั้งเดิมถูกสร้างบนสมมติฐานง่าย ๆ: คุณซื้อ (หรือเช่า) ฮาร์ดแวร์จำนวนหนึ่ง แล้วรันทุกอย่างบนกล่องหรือคลัสเตอร์เดียวกัน นั่นใช้ได้ดีเมื่อโหลดงานคาดการณ์ได้และการเติบโตเป็นไปอย่างช้า ๆ—แต่สร้างข้อจำกัดเชิงโครงสร้างเมื่อปริมาณข้อมูลและจำนวนผู้ใช้เร่งขึ้น
แบบคลาสสิก: คลัสเตอร์คงที่และการวางแผนกำลังการผลิตอย่างรอบคอบ
ระบบ on-prem และการปรับขึ้นบนคลาวด์ยุคแรกมักมีลักษณะดังนี้:
- คลัสเตอร์ MPP (massively parallel processing) เดียวจัดการ storage, CPU และหน่วยความจำรวมกัน
- คุณกำหนดขนาดคลัสเตอร์สำหรับความต้องการสูงสุด เพราะการปรับขนาดช้า มีความเสี่ยง หรืออาจต้องหยุดทำงาน
- การวางแผนกำลังการผลิตกลายเป็นโครงการซ้ำ ๆ: คาดการณ์การเติบโต อธิบายงบประมาณ สั่งฮาร์ดแวร์ ติดตั้ง ย้ายข้อมูล
ถึงแม้ว่าผู้ขายจะเสนอ “node” หลายตัว แต่รูปแบบแกนกลางยังเหมือนเดิม: การสเกลมักหมายถึงการเพิ่มขนาดหรือจำนวนโหนดในสภาพแวดล้อมที่ใช้ร่วมกัน
ปัญหาที่ตามมา: การสเกลช้า ค่าใช้จ่ายที่เสียเปล่า และคิวงาน
การออกแบบนี้สร้างปัญหาทั่วไปหลายอย่าง:
- การสเกลช้า: ถ้างานปิดงบไตรมาสต้องการแรงประมวลผลเพิ่มทันที คุณอาจเพิ่มได้ไม่เร็ว ต้องรอหรือเผื่อขนาดไว้
- ความจุว่างเปล่า: คลัสเตอร์ที่ออกแบบไว้สำหรับพีกมักถูกใช้งานน้อย แต่คุณยังต้องจ่ายค่าใช้จ่ายเหล่านั้น
- คิวงานเมื่อมีโหลดสูง: เมื่อหลายทีมรันคำสั่งพร้อมกัน พวกเขาต้องแย่งทรัพยากร งานหนักอาจบล็อกแดชบอร์ดแบบ interactive ทำให้เกิด timeout และกฎเช่น “อย่ารันคิวรี่นั้นในเวลาทำการ”
เครื่องมือและการเชื่อมต่อ: มีพลังแต่เปราะบางบ่อยครั้ง
เพราะคลังข้อมูลเหล่านี้ผูกแน่นกับสภาพแวดล้อม การเชื่อมต่อมักเติบโตแบบออร์แกนิก: สคริปต์ ETL ที่เขียนเอง ตัวเชื่อมที่ทำขึ้นเฉพาะหน้างาน และ pipeline แบบครั้งเดียว สิ่งเหล่านี้ใช้งานได้—จนกว่าสกีมาจะเปลี่ยน ระบบต้นทางย้าย หรือนำเครื่องมือใหม่เข้ามา การดูแลให้ทุกอย่างทำงานอาจเหมือนการบำรุงรักษาไม่หยุด มากกว่าความก้าวหน้าอย่างต่อเนื่อง
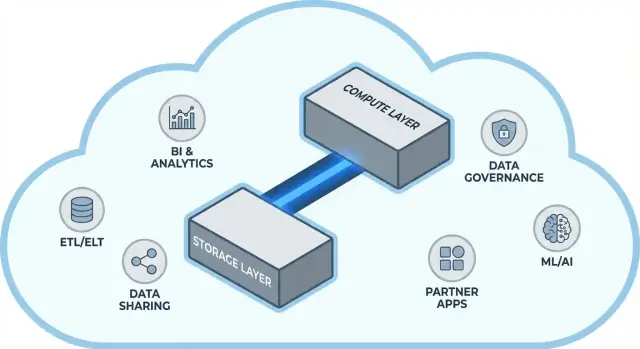
ไอเดียหลัก: การแยกระหว่าง storage และ compute
คลังข้อมูลแบบเดิมมักผูกสองงานที่ต่างกันมากไว้ด้วยกัน: storage (ที่เก็บข้อมูลของคุณ) และ compute (แรงที่อ่าน, join, aggregate และเขียนข้อมูลนั้น)
Storage vs. compute (คำง่าย ๆ)
Storage เปรียบเสมือนห้องเก็บของระยะยาว: ตาราง ไฟล์ และเมตาดาต้าถูกเก็บอย่างปลอดภัยและราคาถูก ออกแบบให้ทนทานและเข้าถึงได้เสมอ
Compute เปรียบเสมือนพ่อครัวในครัว: คือชุด CPU และหน่วยความจำที่ “ปรุง” คำสั่งของคุณ—รัน SQL, จัดเรียง, สแกน, สร้างผลลัพธ์ และจัดการผู้ใช้หลายคนพร้อมกัน
การเปลี่ยนแปลงสำคัญ: ปรับขนาดแยกกันได้
Snowflake แยกทั้งสองส่วนนี้เพื่อให้คุณปรับแต่ละส่วนโดยไม่บังคับให้อีกส่วนต้องเปลี่ยนตาม
- ถ้าปริมาณข้อมูลเพิ่ม คุณเพิ่ม storage (โดยปกติเป็นการเพิ่มทีละเล็กทีละน้อยและคาดเดาได้มากกว่า)
- ถ้ามีการใช้งานรายงานเพิ่มขึ้น คุณเพิ่ม compute (โดยปรับขนาดหรือเพิ่ม virtual warehouses) โดยไม่ต้องย้ายหรือทำสำเนาข้อมูลพื้นฐาน
ในทางปฏิบัติ นี่เปลี่ยนการดำเนินงานประจำ: คุณไม่ต้อง "ซื้อ compute เผื่อ" เพราะ storage โต และคุณสามารถแยกโหลดงาน (เช่น นักวิเคราะห์ vs ETL) เพื่อไม่ให้ชะลอกันเอง
สิ่งที่มันไม่ใช่
การแยกนี้ทรงพลัง แต่ไม่ใช่เวทมนตร์
- มัน ไม่ใช่การสเกลฟรี การเพิ่มหรือตัวใหญ่ของ warehouse ย่อมหมายถึงค่าใช้จ่าย compute ที่สูงขึ้น
- มัน ไม่ใช่การประหยัดอัตโนมัติทุกครั้ง คำสั่งที่เขียนไม่ดี ตารางรีเฟรชที่ไม่จำเป็น หรือ warehouse เปิดตลอดเวลายังทำให้ค่าใช้จ่ายสูงได้
- มัน ไม่ใช่ข้อแก้ตัวที่จะไม่วางแผน คุณยังต้องเลือกขนาด warehouse ตั้งกฎ auto-suspend และจับ compute ให้สอดคล้องกับรูปแบบการใช้งานทางธุรกิจ
คุณค่าคือการควบคุม: จ่ายแยกสำหรับ storage และ compute และจับคู่แต่ละอย่างกับสิ่งที่ทีมต้องการจริง ๆ
สถาปัตยกรรมของ Snowflake แบบง่าย ๆ
Snowflake เข้าใจง่ายที่สุดเมื่อมองเป็นสามเลเยอร์ที่ทำงานร่วมกัน แต่ปรับขนาดได้แยกกัน
1) Storage: cloud object storage
ตารางของคุณสุดท้ายจะอยู่เป็นไฟล์ข้อมูลใน cloud object storage ของผู้ให้บริการ (เช่น S3, Azure Blob หรือ GCS) Snowflake จัดการรูปแบบไฟล์ การบีบอัด และการจัดระเบียบให้ คุณไม่ต้อง "ต่อดิสก์" หรือกำหนดขนาดโวลิว์—storage โตตามข้อมูล
2) Compute: virtual warehouses
Compute ถูกแพ็กเป็น virtual warehouses: คลัสเตอร์อิสระของ CPU/หน่วยความจำที่รันคำสั่ง คุณสามารถรันหลาย warehouses บนข้อมูลชุดเดียวกันพร้อมกัน นั่นคือความแตกต่างสำคัญจากระบบเก่าที่โหลดงานหนักมักแย่งกันใช้พูลทรัพยากรเดียว
3) บริการคลาวด์: เมตาดาต้าและการประสานงาน
เลเยอร์บริการแยกต่างหากจัดการ "สมอง" ของระบบ: การตรวจสอบสิทธิ์ การแยกแยะและปรับแผนคิวรี การจัดการธุรกรรม/เมตาดาต้า และการประสานงาน เลเยอร์นี้ตัดสินใจ วิธี รันคำสั่งอย่างมีประสิทธิภาพก่อนที่ compute จะเข้าถึงข้อมูล
การไหลของคำสั่ง
เมื่อคุณส่ง SQL เลเยอร์บริการของ Snowflake จะ parse สร้างแผนการรัน แล้วส่งแผนนั้นไปยัง virtual warehouse ที่เลือก Warehouse จะอ่านเฉพาะไฟล์ข้อมูลที่จำเป็นจาก object storage (และได้ประโยชน์จาก caching เมื่อเป็นไปได้) ประมวลผล และคืนผลลัพธ์—โดยไม่ย้ายข้อมูลต้นทางถาวรเข้าไปใน warehouse
ความสามารถในการทำงานพร้อมกันและการแยก (แบบไม่ใช้ศัพท์ยาก)
ถ้าคนจำนวนมากรันคำสั่งพร้อมกัน คุณสามารถ:\n\n- ใช้ warehouses แยกกัน สำหรับทีม/โหลดงานต่าง ๆ (การแยกโหลดงาน), หรือ\n- เปิด multi-cluster warehouses เพื่อให้ Snowflake เพิ่มคลัสเตอร์ compute เมื่อเกิดพีก แล้วลดกลับเมื่อหมด
นั่นคือรากฐานด้านสถาปัตยกรรมที่ทำให้ Snowflake ควบคุมปัญหา "เพื่อนบ้านเสียงดัง" ได้ดี
การปรับขนาดและความพร้อมในการประมวลผลพร้อมกัน: สิ่งที่เปลี่ยนจริง ๆ
การเปลี่ยนแปลงเชิงปฏิบัติของ Snowflake คือคุณปรับ compute แยกจาก ข้อมูล ได้ แทนที่จะบอกว่า "คลังข้อมูลใหญ่ขึ้น" คุณสามารถหมุนทรัพยากรขึ้น/ลงต่อโหลดงานได้โดยไม่ต้องคัดลอกตาราง รีพาร์ติชันดิสก์ หรือกำหนดเวลาหยุดทำงาน
ความยืดหยุ่น: ปรับขนาด compute โดยไม่ย้ายข้อมูล
ใน Snowflake, virtual warehouse คือเอนจิน compute ที่รันคำสั่ง คุณสามารถปรับขนาดได้ (เช่น จาก Small เป็น Large) ในไม่กี่วินาทีโดยที่ข้อมูลยังคงอยู่ใน storage แชร์ นั่นหมายความว่าการปรับจูนประสิทธิภาพมักกลายเป็นคำถามง่าย ๆ: "โหลดงานนี้ต้องการแรงมากขึ้นตอนนี้ไหม?"
สิ่งนี้ยังเอื้อต่อการบูร์สชั่วคราว: ปรับขึ้นเพื่อปิดงบสิ้นเดือน แล้วลดลงเมื่อพีกผ่านไป
ความพร้อมในการประมวลผลพร้อมกัน: คิวลดลง
ระบบดั้งเดิมมักบังคับให้ทีมต่าง ๆ แบ่ง compute เดียวกัน ซึ่งเปรียบเสมือนคิวที่แคชเชียร์ในช่วงชั่วโมงเร่งด่วน
Snowflake ให้คุณรัน warehouses แยกตามทีมหรือโหลดงาน—เช่น หนึ่งสำหรับนักวิเคราะห์ หนึ่งสำหรับแดชบอร์ด และหนึ่งสำหรับ ETL เนื่องจาก warehouses เหล่านี้อ่านข้อมูลพื้นฐานชุดเดียวกัน คุณจึงลดปัญหา "แดชบอร์ดของฉันช้าทำให้รายงานของคุณช้า" และทำให้ประสิทธิภาพคาดเดาได้มากขึ้น
การแลกเปลี่ยนที่คุณจะสังเกต
compute ยืดหยุ่นไม่ใช่ความสำเร็จอัตโนมัติ ปัญหาทั่ว ๆ ไปได้แก่:
- Cold starts: warehouses ที่ถูกระงับอาจใช้เวลาสักครู่ในการ resume ซึ่งเพิ่มความหน่วงสำหรับงานที่ไม่บ่อย
- การเลือกขนาดที่ถูกต้อง: ขนาดใหญ่เกินไปคือการเสียเงิน ขนาดเล็กไปทำให้คิวรีช้าและคนหงุดหงิด
- ต้องมีแนวป้องกัน: ใช้ auto-suspend/auto-resume, resource monitors, และความชัดเจนในความเป็นเจ้าของเพื่อป้องกันไม่ให้ warehouses วิ่งเปล่า ๆ หรือแพร่กระจายโดยไม่มีการควบคุม
การเปลี่ยนแปลงสุทธิ: การสเกลและ concurrency เปลี่ยนจากโครงการโครงสร้างพื้นฐานเป็นการตัดสินใจปฏิบัติการประจำวัน
รูปแบบต้นทุน: จุดที่ประหยัดได้ (และจุดที่ไม่)
วาง KPIs บนมือถือ
สร้างแอป Flutter สำหรับตรวจเช็ค KPI และการแจ้งเตือนโดยใช้โมเดลข้อมูลที่มีอยู่
วิธีที่ Snowflake คิดบิลจริง ๆ
คำว่า "จ่ายตามที่ใช้" ของ Snowflake คือการรันมิเตอร์สองตัวคู่ขนาน:\n\n- Compute: คิดค่าตามเวลาที่ virtual warehouse รัน (เป็นเครดิต)\n- Storage: คิดค่าตามปริมาณข้อมูลที่เก็บ (บวกพื้นที่เก็บเพิ่มเติมสำหรับฟีเจอร์อย่าง Time Travel/Fail-safe)
การแยกนี้คือที่ที่การประหยัด อาจ เกิดขึ้น: คุณเก็บข้อมูลจำนวนมากได้ค่อนข้างถูก ในขณะที่เปิด compute เฉพาะเมื่อจำเป็น
จุดที่ต้นทุนไต่ขึ้น
การใช้จ่ายที่ "ไม่คาดคิด" ส่วนใหญ่เกิดจากพฤติกรรม compute มากกว่าขนาด storage ตัวขับเคลื่อนทั่วไปได้แก่:
- Warehouse ขนาดใหญ่เกินความจำเป็น\n- โหลดงานเปิดตลอดเวลา (warehouses ถูกปล่อยให้ทำงานทั้งคืนหรือวันหยุด)
- คำสั่งที่ไม่มีประสิทธิภาพ (สแกนไม่กรอง, join ที่ไม่จำเป็น, การแปลงหนักที่รันซ้ำ)
- รูปแบบ concurrency สูง (แดชบอร์ดหลายตัวรีเฟรชตลอดเวลา)
การแยก storage กับ compute ไม่ได้ทำให้คำสั่งมีประสิทธิภาพโดยอัตโนมัติ—SQL แย่ ๆ ยังคงเผาผลาญเครดิตเร็วได้
มาตรการใช้งานจริงที่ได้ผล
คุณไม่จำเป็นต้องให้ฝ่ายการเงินมาจัดการ แค่วางแนวป้องกันไม่กี่อย่าง:\n\n- Auto-suspend / auto-resume เพื่อหยุดจ่ายเมื่อว่าง\n- Resource monitors เพื่อแจ้งเตือนหรือจำกัดการใช้เครดิตต่อ warehouse/ทีม\n- การวางตาราง (รันงานเป็นชุดในหน้าต่างที่กำหนด; หยุด dev/test นอกเวลาทำการ)\n- Right-sizing และทดสอบขนาดที่เล็กกว่าก่อนจะเพิ่มขึ้น\n\nถ้าใช้ดี โมเดลนี้ให้ผลตอบแทนกับวินัย: compute ที่รันสั้นและขนาดเหมาะสมคู่กับการเติบโตของ storage ที่คาดการณ์ได้
การแชร์ข้อมูลและการทำงานร่วมกันในฐานะฟีเจอร์ระดับแรก
Snowflake มองการแชร์เป็นสิ่งที่ออกแบบเข้าไปในแพลตฟอร์ม ไม่ใช่ของต่อท้ายที่ผูกเข้ากับการส่งออก ไฟล์ดาวน์โหลด และ ETL แบบครั้งเดียว
แชร์โดยไม่ต้องคัดลอก (ในหลายกรณี)
แทนที่จะส่ง extract กัน Snowflake สามารถให้บัญชีอื่นคิวรีข้อมูลพื้นฐานเดียวกันผ่าน "share" ที่ปลอดภัย ในหลายกรณี ข้อมูลไม่จำเป็นต้องทำสำเนาไปยัง warehouse ที่สองหรือผลักไปยัง object storage เพื่อดาวน์โหลด ผู้บริโภคเห็นฐานข้อมูล/ตารางที่แชร์เหมือนเป็นของตัวเอง ในขณะที่ผู้ให้ยังคงควบคุมสิ่งที่เปิดเผยได้
แนวทางที่แยกกันแบบนี้มีคุณค่าเพราะลดการกระจายข้อมูล เพิ่มความเร็วในการเข้าถึง และลดจำนวน pipeline ที่ต้องสร้างและดูแล
รูปแบบการทำงานร่วมกันที่พบบ่อย
การแชร์กับพันธมิตรและลูกค้า: ผู้ให้บริการสามารถเผยชุดข้อมูลคัดสรรให้ลูกค้า (เช่น วิเคราะห์การใช้งานหรือข้อมูลอ้างอิง) ด้วยขอบเขตที่ชัดเจน—เฉพาะสกีมา ตาราง หรือวิวที่อนุญาต
การแชร์ภายในโดเมน: ทีมกลางสามารถเผยชุดข้อมูลที่ผ่านการรับรองให้ฝ่าย product, finance และ operations โดยไม่ต้องให้แต่ละทีมทำสำเนาของตัวเอง สนับสนุนวัฒนธรรม "ตัวเลขชุดเดียว" ในขณะที่ยังให้แต่ละทีมรัน compute ของตัวเองได้
การทำงานร่วมกันที่มีการควบคุม: โครงการร่วมกับเอเจนซี ซัพพลายเออร์ หรือบริษัทในเครือ สามารถทำงานบนชุดข้อมูลที่แชร์ได้ในขณะที่คอลัมน์ที่อ่อนไหวถูกปกปิดและการเข้าถึงถูกบันทึก
ข้อจำกัดที่ต้องวางแผน
การแชร์ไม่ใช่ "ตั้งค่าแล้วลืม" คุณยังต้องมี:\n\n- การกำกับดูแล: เจ้าของที่ชัดเจน การทบทวนการเข้าถึง และนโยบายสำหรับข้อมูล PII/ที่ถูกควบคุม\n- สัญญาและความคาดหวัง: ใครจ่ายค่า compute, SLA, การเก็บรักษา, และจะทำอย่างไรเมื่อคำนิยามเปลี่ยน\n- การค้นหา: หากไม่มี catalog และการตั้งชื่อที่ดี คนจะไม่เจอหรือไม่เชื่อถือข้อมูลที่แชร์ จัดแนว shares กับเอกสารและ data catalog ของคุณถ้ามี
ทำไมระบบนิเวศจึงสำคัญพอ ๆ กับประสิทธิภาพ
คลังข้อมูลที่เร็วมีค่า แต่ความเร็วเพียงอย่างเดียวไม่ค่อยเป็นตัวกำหนดว่าโครงการจะส่งมอบตรงเวลา สิ่งที่มักสร้างความแตกต่างคือ ระบบนิเวศ รอบแพลตฟอร์ม: การเชื่อมต่อที่มีอยู่ เครื่องมือ และความรู้ที่ลดงานเขียนเอง
“ระบบนิเวศ” สำหรับแพลตฟอร์มข้อมูลหมายความว่าอย่างไร
ในทางปฏิบัติ ระบบนิเวศประกอบด้วย:\n\n- ตัวเชื่อม ไปยังแหล่งและปลายทางข้อมูล (SaaS, ฐานข้อมูล, เครื่องมือสตรีมมิ่ง)\n- เครื่องมือพันธมิตร สำหรับการ ingest, transform, BI, คุณภาพข้อมูล และการสังเกตการณ์\n- แอปและการรวมแบบเนทีฟ ที่รันใกล้ข้อมูล\n- เทมเพลตและสถาปัตยกรรมอ้างอิง (โมเดลทั่วไป แพตเทิร์น คู่มือการดีพลอย)\n- ความรู้จากชุมชน: ตัวอย่าง ฟอรัม พบปะ และแหล่งหาคนทำงาน
ทำไมระบบนิเวศจึงชนะตัวเลขเบนช์มาร์กในการส่งมอบงาน
เบนช์มาร์กวัดชิ้นเล็กของประสิทธิภาพภายใต้สภาพควบคุม โครงการจริงใช้เวลาส่วนใหญ่ใน:\n\n- นำข้อมูลเข้าอย่างเชื่อถือได้และเพิ่มทีละน้อย\n- การออกแบบโมเดล ทดสอบ และจัดเอกสารชุดข้อมูล\n- งานปฏิบัติการ (มอนิเตอร์ การแจ้งเตือน การควบคุมค่าใช้จ่าย)\n- การตรวจสอบความปลอดภัย การตั้งสิทธิ์ และการตรวจสอบ
ถ้าแพลตฟอร์มมีการผสานงานสำหรับขั้นตอนเหล่านี้เป็นผู้ที่โตแล้ว คุณจะไม่ต้องเขียนโค้ดเชื่อมเองมาก นั่นมักย่นเวลาการติดตั้ง ปรับปรุงความเชื่อถือได้ และทำให้เปลี่ยนทีมหรือผู้ขายได้ง่ายโดยไม่ต้องเขียนใหม่ทั้งหมด
เลนส์ง่าย ๆ ในการประเมิน: ความครอบคลุม คุณภาพ และความสามารถในการดูแลรักษา
เมื่อประเมินระบบนิเวศ ให้ดูว่า:\n\n- Coverage: ครอบคลุมแหล่งข้อมูลหลัก เครื่องมือ BI orchestration และความต้องการกำกับดูแลของคุณไหม\n- Quality: ตัวเชื่อมได้รับการดูแลอย่างสม่ำเสมอ มีเอกสารดี และพิสูจน์แล้วกับสเกลของคุณหรือไม่\n- Maintainability: ต้องใช้ความพยายามอย่างต่อเนื่องเท่าไร—อัปเกรด การเปลี่ยนแปลงที่ทำลาย การดีบัก และการสนับสนุน
ประสิทธิภาพให้ความสามารถ ระบบนิเวศกำหนดว่าคุณจะเปลี่ยนความสามารถนั้นเป็นผลลัพธ์ทางธุรกิจได้เร็วแค่ไหน
ระบบเชื่อมต่อ: นำข้อมูลเข้า ออก และใช้งาน
ติดตามการใช้จ่ายของ warehouse
สร้างศูนย์ติดตามต้นทุนและการใช้งานแบบเบา ๆ ที่ช่วยให้ทีมเห็นตัวขับเคลื่อนการใช้ compute
Snowflake รันคำสั่งได้เร็ว แต่คุณค่าจะเกิดขึ้นเมื่อข้อมูลไหลผ่านสแตกของคุณอย่างเชื่อถือได้: จากแหล่ง เข้า Snowflake แล้วออกไปยังเครื่องมือที่คนใช้งาน “ไมล์สุดท้าย” มักเป็นตัวกำหนดว่าแพลตฟอร์มรู้สึกว่าไร้รอยต่อหรือเปราะบางอย่างต่อเนื่อง
หมวดการเชื่อมต่อหลักที่ควรวางแผน
ทีมส่วนใหญ่ต้องการผสมผสานของ:\n\n- ELT/ETL เพื่อดึงจากฐานข้อมูล SaaS ไฟล์ และ object storage\n- BI และ analytics สำหรับแดชบอร์ด การสำรวจแบบ self-serve และชั้นความหมาย\n- Reverse ETL เพื่อส่งข้อมูลที่คัดสรรกลับไปยัง CRM การตลาด และระบบสนับสนุน\n- Orchestration สำหรับการตั้งเวลา ขึ้นต่อกัน backfill และการ promote สภาพแวดล้อม\n- Streaming สำหรับเหตุการณ์ใกล้เวลาและ change data capture\n- เครื่องมือ ML สำหรับ pipeline คุณลักษณะ งานฝึก และการมอนิเตอร์โมเดล
คำถามที่ต้องถามก่อนเลือกตัวเชื่อม
ไม่ใช่ทุกเครื่องมือที่ “รองรับ Snowflake” จะเหมือนกัน ในการประเมิน ให้มุ่งที่รายละเอียดเชิงปฏิบัติ:\n\n- ตัวเชื่อม ได้รับการรับรอง/รองรับ โดยใคร และเส้นทางการยกระดับเป็นอย่างไร?\n- มันรองรับ โหลดเพิ่มทีละน้อย ได้ดีไหม (CDC, timestamp, high-water marks)?\n- จัดการ schema drift อย่างไร—คอลัมน์ใหม่ การเปลี่ยนประเภท ข้อมูลที่ถูกลบ?\n- การันตีด้าน retry, deduplication, exactly-once vs at-least-once เป็นแบบไหน?
อย่าละเลยงานปฏิบัติการ
การเชื่อมต่อยังต้องเตรียมพร้อมสำหรับวัน-2: มอนิเตอร์และการแจ้งเตือน, hook ไปยัง lineage/catalog, และ กระบวนการตอบสนองเหตุการณ์ (ticketing, on-call, runbooks) ระบบนิเวศที่แข็งแรงไม่ใช่แค่โลโก้ใหม่ ๆ—มันคือความประหลาดใจที่น้อยลงเมื่อ pipeline ล้มตอนตีสอง
การกำกับดูแล ความปลอดภัย และความเชื่อถือในสเกลใหญ่
เมื่อทีมเติบโต ส่วนที่ยากที่สุดของงานวิเคราะห์มักไม่ใช่ความเร็ว แต่ว่าทำยังไงให้คนที่ถูกต้องเข้าถึงข้อมูลที่ถูกต้องเพื่อวัตถุประสงค์ที่ถูกต้อง พร้อมหลักฐานว่าแนวควบคุมทำงาน Snowflake ออกแบบฟีเจอร์กำกับดูแลสำหรับความเป็นจริงนั้น: ผู้ใช้มาก ผลิตภัณฑ์ข้อมูลมาก และการแชร์บ่อย
พื้นฐานการกำกับดูแลที่ใช้ได้จริง
เริ่มจากบทบาทที่ชัดเจนและแนวคิด least-privilege แทนการให้สิทธิ์แก่บุคคลโดยตรง ให้กำหนดบทบาทเช่น ANALYST_FINANCE หรือ ETL_MARKETING แล้วให้บทบาทเหล่านั้นเข้าถึงฐานข้อมูล สกีมา ตาราง และ (เมื่อจำเป็น) วิว
สำหรับฟิลด์ที่อ่อนไหว (PII ตัวระบุทางการเงิน) ใช้นโยบาย masking เพื่อให้คนสามารถคิวรีชุดข้อมูลโดยไม่เห็นค่าเวอร์ชันดิบเว้นแต่บทบาทของพวกเขาจะอนุญาต จับคู่นั้นกับ การตรวจสอบ: ติดตามว่าใครคิวรีอะไร และเมื่อไหร่ เพื่อให้ทีมความปลอดภัยและคอมไพลแอนซ์ตอบคำถามได้โดยไม่ต้องเดา
ทำไมการกำกับดูแลเปลี่ยนการแชร์และการทำ self-service
การกำกับดูแลที่ดีทำให้การแชร์ปลอดภัยและขยายตัวได้ เมื่อโมเดลการแชร์ของคุณสร้างขึ้นจากบทบาท นโยบาย และการตรวจสอบ คุณสามารถเปิด self-service ได้อย่างมั่นใจมากขึ้นโดยไม่เสี่ยงเปิดเผยข้อมูลโดยไม่ได้ตั้งใจ
นอกจากนี้ยังลดแรงเสียดทานสำหรับการปฏิบัติตาม: นโยบายกลายเป็นการควบคุมที่ทำซ้ำได้ แทนการเป็นข้อยกเว้นที่ทำครั้งเดียว นั่นสำคัญเมื่อชุดข้อมูลถูกนำกลับมาใช้ซ้ำในหลายโครงการ ฝ่าย หรือพันธมิตรภายนอก
เคล็ดลับปฏิบัติที่ป้องกันความเจ็บปวดในอนาคต
- การตั้งชื่อ: มาตรฐานชื่อฐานข้อมูล/สกีมา ที่สื่อจุดประสงค์และความอ่อนไหว (เช่น
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X) ความสอดคล้องช่วยเร่งการตรวจสอบและลดความผิดพลาด
- การแยกสภาพแวดล้อม: เก็บ DEV/TEST/PROD แยกเชิงตรรกะ โดยควบคุมเข้มงวดใน PROD ปฏิบัติต่อข้อมูลผลผลิตเป็นข้อยกเว้น ไม่ใช่ค่าเริ่มต้น
- การทบทวนการเข้าถึง: ตั้งรอบเวลา (รายเดือนสำหรับข้อมูลความเสี่ยงสูง รายไตรมาสสำหรับอื่น ๆ) ทบทวนสมาชิกบทบาท ผู้ใช้เลิกใช้งาน และบทบาทมีสิทธิพิเศษ
ความเชื่อถือในสเกลใหญ่เกี่ยวกับชุดของนิสัยเล็ก ๆ ที่เชื่อถือได้มากกว่าการควบคุมที่ “สมบูรณ์แบบ” เดียว
โหลดงานและรูปแบบแนวปฏิบัติที่ดีที่สุด
ส่งมอบแดชบอร์ดปฏิบัติการ
สร้างพอร์ทัลปฏิบัติการภายในที่อ่านข้อมูลจาก Snowflake โดยไม่ต้องเขียนสแตกทั้งหมดด้วยมือ
Snowflake มักโดดเด่นเมื่อคนและเครื่องมือต้องคิวรีข้อมูลชุดเดียวกันเพื่อเหตุผลต่าง ๆ เพราะ compute ถูกรวมเป็น warehouses อิสระ คุณสามารถแมปแต่ละโหลดงานให้เข้ากับรูปแบบและตารางเวลาที่เหมาะสม
การแมปโหลดงานที่พบบ่อย
การวิเคราะห์ & แดชบอร์ด: ใช้ warehouse เฉพาะสำหรับเครื่องมือ BI ขนาดที่เหมาะกับการโหลดคงที่และคาดการณ์ได้ เพื่อไม่ให้รีเฟรชแดชบอร์ดช้าจากการสำรวจแบบ ad hoc
การวิเคราะห์แบบ ad hoc: ให้ warehouse แยกสำหรับนักวิเคราะห์ (มักเล็กกว่า) เปิด auto-suspend คุณจะได้การวนรอบที่เร็วโดยไม่จ่ายสำหรับเวลาว่าง
Data science & การทดลอง: ใช้ warehouse ที่ขนาดเหมาะกับการสแกนหนักและบูร์สเป็นครั้งคราว หากการทดลองพีก ให้ปรับขึ้นชั่วคราวโดยไม่กระทบผู้ใช้ BI
แอปข้อมูล & embedded analytics: ปฏิบัติราวกับทราฟฟิกแอปเป็นบริการโปรดักชัน—warehouse แยก, timeout ที่ระมัดระวัง, และ resource monitors เพื่อป้องกันค่าใช้จ่ายที่ไม่คาดคิด
ถ้าคุณสร้างแอปข้อมูลภายในน้ำหนักเบา (เช่น พอร์ทัลปฏิบัติการที่คิวรี Snowflake แล้วแสดง KPI หน้าจอ) เส้นทางที่เร็วคือสร้าง scaffold React + API ทำงานและวนรับฟีดแบ็กผู้มีส่วนได้ส่วนเสีย แพลตฟอร์มอย่าง Koder.ai (แพลตฟอร์ม vibe-coding ที่สร้างเว็บ/เซิร์ฟเวอร์/มือถือจากแชท) สามารถช่วยทีมต้นแบบแอปที่ใช้ Snowflake ได้อย่างรวดเร็ว แล้วส่งออกซอร์สโค้ดเมื่อคุณพร้อมปฏิบัติงานจริง
แพตเทิร์นปฏิบัติที่ดีที่สุดที่ทำงานได้จริง
กฎง่าย ๆ: แยก warehouses ตามผู้ชมและจุดประสงค์ (BI, ELT, ad hoc, ML, แอป) จับคู่กับ นิสัยการคิวรีที่ดี—หลีกเลี่ยง SELECT * กรองให้เร็ว และสังเกต join ที่ไม่มีประสิทธิภาพ ในด้านการโมเดล ให้เน้นโครงสร้างที่สอดคล้องกับวิธีการที่คนคิวรี (มักเป็น semantic layer ที่ชัดเจนหรือ marts ที่กำหนดไว้ดี) แทนการโอเวอร์ออปติไมซ์เลย์เอาต์กายภาพ
เมื่อควรพิจารณาทางเลือกหรือส่วนเติมเต็ม
Snowflake ไม่ได้แทนที่ทุกอย่าง สำหรับ workload แบบธุรกรรมที่มี throughput สูงและหน่วงต่ำ (OLTP) ฐานข้อมูลเชิงพิเศษมักเหมาะกว่า โดยใช้ Snowflake สำหรับวิเคราะห์ รายงาน การแชร์ และผลิตภัณฑ์ข้อมูลลงท้าย การตั้งค่าผสมเป็นเรื่องปกติและมักเป็นทางปฏิบัติที่สุด
การพิจารณาการย้าย: ควรวางแผนอะไรบ้างก่อนย้าย
การย้ายไป Snowflake มักไม่ใช่การ "lift and shift" การแยกระหว่าง storage/compute เปลี่ยนวิธีที่คุณขนาด ปรับจูน และจ่ายสำหรับโหลดงาน—ดังนั้นการวางแผนล่วงหน้าจะป้องกันปัญหาในภายหลัง
ลำดับการย้ายที่เป็นประโยชน์
เริ่มจากการสำรวจ: แหล่งข้อมูลใดป้อนคลังงาน, pipeline ใดแปลงข้อมูล, แดชบอร์ดใดพึ่งพา, และใครเป็นเจ้าของแต่ละชิ้น จากนั้นจัดลำดับความสำคัญตามผลกระทบทางธุรกิจและความซับซ้อน (เช่น รายงานการเงินที่สำคัญก่อน sandbox ทดลองทีหลัง)
ถัดมา แปลง SQL และตรรกะ ETL มากของ SQL มาตรฐานย้ายได้ แต่รายละเอียดเช่น ฟังก์ชัน การจัดการวันที่ โค้ดเชิงกระบวนการ และรูปแบบ temp-table มักต้องเขียนใหม่ ตรวจสอบผลลัพธ์ตั้งแต่ต้น: รันผลลัพธ์คู่ขนาน เปรียบเทียบ row counts และการรวม และยืนยันกรณีมุม (null, เขตเวลา, ตรรกะ dedup) สุดท้าย วางแผน cutover: หน้าต่าง freeze ทางการ, ทางเลิกคืน, และนิยาม "เสร็จ" ชัดเจนสำหรับแต่ละชุดข้อมูลและรายงาน
ความเสี่ยงที่พบทั่วไป
การพึ่งพาที่ซ่อนอยู่คือเรื่องปกติที่สุด: extract ในสเปรดชีต สตริงการเชื่อมต่อที่ hard-coded งานลงท้ายที่ไม่มีใครจำ การประหลาดใจด้านประสิทธิภาพเกิดขึ้นเมื่อสมมติฐานการปรับจูนเก่าไม่ใช้แล้ว (เช่น ใช้ warehouses เล็กเกินไป หรือรันคิวรีเล็ก ๆ จำนวนมากโดยไม่คิดเรื่อง concurrency) การกระโดดของต้นทุนนิยมเกิดเมื่อปล่อย warehouses ให้รัน ไม่ควบคุม retry หรือทำสำเนา dev/test มากเกินไป ช่องโหว่สิทธิ์ปรากฏเมื่อย้ายจากบทบาทกว้างไปสู่การกำกับดูแลละเอียด—การทดสอบควรรวมการรันโดยผู้ใช้ที่มีสิทธิ์น้อยสุด
การจัดการการเปลี่ยนแปลง (อย่าข้าม)
ตั้งโมเดลความเป็นเจ้าของ (ใครเป็นเจ้าของข้อมูล pipeline และค่าใช้จ่าย) ให้การฝึกอบรมตามบทบาทกับนักวิเคราะห์และวิศวกร และกำหนดแผนสนับสนุนสำหรับสัปดาห์แรกหลัง cutover (on-call rotation, runbook กรณีเหตุการณ์, และช่องทางรายงานปัญหา)
วิธีประเมินแพลตฟอร์ม: คำถามที่ควรถาม (และแผนพายโลท)
การเลือกแพลตฟอร์มข้อมูลสมัยใหม่ไม่ใช่แค่ความเร็วจุดสูงสุด แต่คือว่าแพลตฟอร์มเข้ากับโหลดงานจริง วิธีการทำงานของทีม และเครื่องมือที่คุณพึ่งพาได้แค่ไหน
เช็คลิสต์การประเมินเชิงปฏิบัติ
ใช้คำถามเหล่านี้นำการคัดสรรและการสนทนากับผู้ขาย:\n\n- โหลดงาน: คุณรันแดชบอร์ดตามตารางเป็นส่วนใหญ่, การวิเคราะห์ ad-hoc, data science, ELT/ETL, หรือแอปสำหรับลูกค้า? คุณต้องการ batch ที่คาดการณ์ได้ หรือความสามารถบูร์สแบบยืดหยุ่น?\n- ความต้องการ concurrency: มีกี่คน (หรือแอป) ที่จะคิวรีพร้อมกัน และการใช้งานตอนพีกมีลักษณะ "กระโดด" มากแค่ไหน?\n- ความต้องการแชร์ข้อมูล: คุณต้องแชร์ข้อมูลสดกับพันธมิตร หน่วยงานธุรกิจ หรือลูกค้าโดยไม่ส่งไฟล์ไหม? คุณคาดว่าจะบริโภคชุดข้อมูลจากภายนอกไหม?\n- การเข้ากันได้ของเครื่องมือ: เครื่องมือ BI, orchestration, catalog, และ CI/CD ของคุณจะผสานงานได้เรียบร้อยไหม? อะไรจะพังถ้าย้าย?\n- การกำกับดูแลและความปลอดภัย: คุณต้องการการควบคุมแบบละเอียด, audit trail, masking, นโยบายการเก็บรักษา และการแยกหน้าที่ชัดเจนไหม?\n- ข้อจำกัดด้านต้นทุน: ต้นทุนแบบไหนสำคัญที่สุด—ค่าใช้จ่ายสแตติก, ค่าใช้จ่ายตอนพีก หรือความสามารถปิด compute ได้? คุณจะป้องกันการเปิดทิ้งไว้ตลอดเวลาอย่างไร?
แผนพายโลทสั้น ๆ (2–4 สัปดาห์)
เลือก 2–3 ชุดข้อมูลตัวแทน (อย่าใช้ตัวอย่างเล็ก ๆ): หนึ่ง fact table ขนาดใหญ่ หนึ่งแหล่งกึ่งโครงสร้างที่ยุ่ง และหนึ่งโดเมนที่สำคัญทางธุรกิจ
จากนั้นรัน คิวรีผู้ใช้จริง: แดชบอร์ดในช่วงพีกตอนเช้า, การสำรวจโดยนักวิเคราะห์, โหลดตามตาราง และ join ที่แย่ที่สุด ติดตาม: เวลาคิวรี, พฤติกรรม concurrency, เวลาในการ ingest, ความพยายามเชิงปฏิบัติการ, และต้นทุนต่อโหลดงาน
ถ้าการประเมินรวม "เราส่งอะไรให้ผู้ใช้จริงได้เร็วแค่ไหน" ให้เพิ่มชิ้นงานเล็ก ๆ ในพายโลท—เช่น แอปมาตรวัดภายในหรือเวิร์กโฟลว์คำขอข้อมูลที่มีการกำกับดูแล ซึ่งคิวรี Snowflake การสร้างชั้นบาง ๆ มักเผยความจริงด้านการรวมและความปลอดภัยเร็วกว่าการดูเฉพาะเบนช์มาร์ก และเครื่องมืออย่าง Koder.ai ช่วยเร่งรอบต้นแบบสู่การผลิตโดยสร้างโครงแอปผ่านแชทและให้คุณส่งออกโค้ดเมื่อพร้อม
ขั้นตอนถัดไปที่แนะนำ
ถ้าต้องการความช่วยเหลือประมาณการค่าใช้จ่ายและเปรียบเทียบตัวเลือก ให้เริ่มจาก /pricing
สำหรับคำแนะนำเรื่องการย้ายและการกำกับดูแล มองหาบทความที่เกี่ยวข้องใน /blog.