23 ก.ค. 2568·1 นาที
วิธีที่ AI อ่านเลย์เอาต์และเจตนาเพื่อแปลงดีไซน์เป็นโค้ด UI
เรียนรู้ว่า AI อนุมานเลย์เอาต์ ลำดับชั้น และเจตนาของผู้ใช้จากดีไซน์ แล้วสร้างโค้ด UI ได้อย่างไร พร้อมข้อจำกัด แนวทางปฏิบัติ และคำแนะนำการตรวจสอบ
เรียนรู้ว่า AI อนุมานเลย์เอาต์ ลำดับชั้น และเจตนาของผู้ใช้จากดีไซน์ แล้วสร้างโค้ด UI ได้อย่างไร พร้อมข้อจำกัด แนวทางปฏิบัติ และคำแนะนำการตรวจสอบ
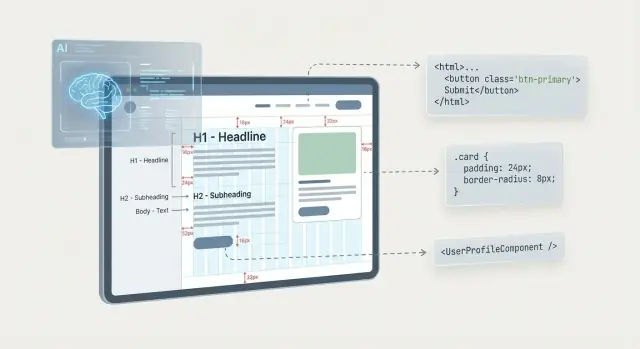
“Design to code” ด้วย AI คือนำแนวคิดการออกแบบเชิงภาพ—โดยปกติเป็นเฟรมใน Figma หรือสกรีนช็อต—มาแปลงเป็นโค้ด UI ที่รันได้ จุดประสงค์ไม่ใช่ “โค้ดที่สมบูรณ์แบบทุกเม็ด” แต่เป็นร่างเริ่มต้นที่ใช้งานได้ ซึ่งจับโครงสร้าง รูปแบบ และพฤติกรรมพื้นฐานไว้เพื่อให้มนุษย์มาปรับแต่งต่อได้
แกนหลักของระบบคือการจับ สิ่งที่มันสังเกตได้ แล้วแม็ปเข้ากับ วิธีที่ UI ถูกสร้างขึ้นโดยทั่วไป:
AI สามารถอนุมานรูปแบบทั่วไป: แถวไอคอนมักเป็น toolbar; ป้าย + ช่องกรอกที่ซ้อนกันมักเป็นแถวฟอร์ม; สไตล์ที่สม่ำเสมอบ่งชี้คอมโพเนนต์ที่นำกลับมาใช้ได้ เร็วๆ นี้มันอาจเดาพฤติกรรมตอบสนองจากข้อจำกัดและช่องว่างด้วย
แต่สิ่งที่พิกเซลบอกไม่ได้มักต้องระบุเอง: ชื่อคอมโพเนนต์จริง, โทเค็นการออกแบบ (สี/สเกลตัวอักษร), สเตท (hover/disabled/error), เบรกพอยต์, กฎข้อมูล และการโต้ตอบจริง (validation, การนำทาง, การเก็บเหตุการณ์)
จงถือผลลัพธ์ว่าเป็นจุดเริ่มต้น คาดว่าจะต้องทบทวนโครงสร้าง, แทนที่สไตล์ฉาบฉวยด้วยโทเค็น, จูนให้ตรงกับไลบรารีคอมโพเนนต์ของทีม และทำซ้ำ “Design to code” คือการเร่งกระบวนการ ไม่ใช่การอัตโนมัติที่ตัดการตัดสินใจของนักออกแบบและวิศวกรออกไป
AI ไม่สามารถอนุมานกฎผลิตภัณฑ์จาก “หน้าจอสวยๆ” ได้ มันทำงานจากหลักฐานที่คุณให้—บางอินพุตบรรยาย พิกเซล ส่วนบางอินพุตบรรยาย โครงสร้าง. ความต่างนี้มักเป็นตัวตัดสินว่าคุณจะได้โค้ด UI สะอาดหรือการจัดตำแหน่งแบบเปราะๆ
สกรีนช็อตคืออินพุตที่บางที่สุด: มีสีและรูปร่าง แต่ไม่มีความจริงชัดเจนว่าอันไหนคือปุ่มหรือป้าย อะไรนำกลับมาใช้ซ้ำได้ หรือเลย์เอาต์ควรปรับตัวอย่างไร
จากพิกเซลล้วน AI ต้องเดาขอบเขต (องค์ประกอบสิ้นสุดตรงไหน) สไตล์ตัวอักษร กฎช่องว่าง และแม้แต่ว่า “การ์ด” เป็นคอมโพเนนต์เดียวหรือชิ้นส่วนหลายชิ้น นอกจากนี้ยังไม่สามารถอนุมานข้อจำกัดได้—ดังนั้นพฤติกรรมตอบสนองจึงเป็นการคาดเดาเป็นส่วนใหญ่
เมื่อ AI เข้าถึงไฟล์ดีไซน์ (หรือการเอ็กซ์พอร์ตที่เก็บโครงสร้างไว้) มันจะได้เมตาดาต้าสำคัญ: เฟรม, กลุ่ม, ชื่อเลเยอร์, การตั้งค่า Auto Layout, ข้อจำกัด และคำจำกัดความของตัวอักษร/สไตล์
นี่คือจุดที่เลย์เอาต์กลายเป็นมากกว่าเรขาคณิต เช่น เฟรม Figma ที่มี Auto Layout สื่อเจตนาได้ชัดว่า “จัดไอเท็มเหล่านี้เป็นแนวตั้งโดยเว้นช่อง 16px” ดีกว่าสกรีนช็อตใดๆ ชื่อเลเยอร์ที่สม่ำเสมอยังช่วยแม็ปองค์ประกอบไปยังบทบาท UI (เช่น “Primary Button”, “Nav Item”, “Input/Error”)
การเชื่อมต่อกับระบบออกแบบลดการเดา โทเค็น (สี ช่องว่าง ตัวอักษร) ช่วยให้ AI สร้างโค้ดที่อ้างอิงแหล่งข้อมูลเดียวแทนค่าตัวเลขฮาร์ดโค้ด คอมโพเนนต์ที่เผยแพร่แล้วให้บล็อกพร้อมใช้งานและขอบเขตที่ชัดเจนสำหรับการนำกลับมาใช้
แม้แต่ข้อตกลงเล็กๆ—เช่น การตั้งชื่อวาไรแอนต์ (Button/Primary, Button/Secondary) และการใช้โทเค็นเชิงความหมาย (text/primary) แทน #111111—ก็ช่วยการแม็ปคอมโพเนนต์ได้ดีขึ้น
สเปกเติมเต็มคำถามว่า “ทำไม” อยู่เบื้องหลัง UI: พฤติกรรม hover, สเตทโหลดและสเตทว่าง, กฎการตรวจสอบ, พฤติกรรมคีย์บอร์ด, และข้อความแสดงข้อผิดพลาด
ถ้าไม่มีสิ่งเหล่านี้ AI มักจะสร้าง snapshot แบบสแตติก แต่ถ้ามี สินค้าที่ได้อาจรวม hooks สำหรับการโต้ตอบ การจัดการสเตท และ API คอมโพเนนต์ที่สมจริงขึ้น—ใกล้เคียงกับสิ่งที่ทีมสามารถปล่อยใช้และดูแลได้
เครื่องมือ design-to-code ไม่เห็นหน้าจอเหมือนคน มันพยายามอธิบายทุกเลเยอร์เป็นกฎเลย์เอาต์: แถว คอลัมน์ คอนเทนเนอร์ และช่องว่าง ยิ่งกฎเหล่านี้ชัดเจนเท่าไร ผลลัพธ์ก็ยิ่งพึ่งพาการวางตำแหน่งแบบเปราะๆ น้อยลง
โมเดลส่วนใหญ่เริ่มจากการมองหาการจัดชิดซ้ำและช่องว่างเท่าๆ กัน ถ้าองค์ประกอบหลายชิ้นมีขอบซ้ายเท่ากัน baseline หรือเส้นศูนย์กลางร่วม AI มักมองว่าพวกมันเป็นคอลัมน์หรือแทร็กกริด ช่องว่างที่สม่ำเสมอ (เช่น แบบแผน 8/16/24px) บ่งชี้ว่าเลย์เอาต์สามารถนิยามด้วย stack gaps, grid gutters, หรือช่องว่างที่เป็นโทเค็นได้
เมื่อช่องว่างแปรปรวนเล็กน้อย (15px ที่นี่ 17px ที่นู่น) AI อาจสรุปว่าเลย์เอาต์เป็นแบบ “แมนนวล” และถอยไปใช้พิกัดแบบ absolute เพื่อรักษาระยะห่างพิกเซล-เพอร์เฟกต์
AI ยังมองหาการ “ล้อม” ทางสายตา: พื้นหลัง เส้นขอบ เงา และช่องว่างที่คล้าย padding ที่บ่งชี้คอนเทนเนอร์ การ์ดที่มีพื้นหลังและ padding ภายในเป็นสัญญาณชัดเจนขององค์ประกอบพาเรนต์ที่มี children
จากตรงนั้นมันมักจะแม็ปโครงสร้างเป็นพริมิทีฟ เช่น:
การจัดกลุ่มที่สะอาดในไฟล์ดีไซน์ช่วยแยกพาเรนต์จากซิบลิงได้ดีขึ้น
ถ้าดีไซน์มีข้อจำกัด (pinning, hugging, fill) AI จะใช้ข้อมูลเหล่านั้นตัดสินว่าองค์ประกอบไหนยืดได้และองค์ประกอบไหนคงที่ “Fill” มักกลายเป็นความกว้างแบบยืดหยุ่น (เช่น flex: 1) ขณะที่ “hug” แม็ปไปยังองค์ประกอบขนาดพอเหมาะตามเนื้อหา
ตำแหน่งแบบ absolute มักโผล่เมื่อโมเดลไม่มั่นใจที่จะอธิบายความสัมพันธ์ด้วย flow layouts—มักมาจากช่องว่างไม่สม่ำเสมอ เลเยอร์ทับซ้อน หรือองค์ประกอบจัดไม่ตรง มันอาจดูถูกต้องที่ขนาดหน้าจอหนึ่ง แต่จะพังเมื่อความกว้างเปลี่ยนหรือขนาดฟอนต์เพิ่มขึ้น
การใช้สเกลช่องว่างเล็กๆ และจับกริดให้ตรงช่วยเพิ่มโอกาสที่ AI จะผลิตโค้ด flex/grid แทนพิกัด การสม่ำเสมอไม่ได้มีความสำคัญแค่เรื่องความสวยงาม แต่มันเป็นรูปแบบที่อ่านได้โดยเครื่อง
AI ไม่ได้ “เข้าใจ” ลำดับชั้นในเชิงความหมาย มันอนุมานความสำคัญจากรูปแบบที่มักบ่งบอกความสำคัญ ยิ่งดีไซน์สื่อสัญญาณพวกนั้นชัดเจน ผลลัพธ์ที่สร้างขึ้นก็ยิ่งตรงกับเจตนามากขึ้น
ไทโปกราฟีเป็นหนึ่งในเบาะแสที่ชัดที่สุด ขนาดตัวอักษรที่ใหญ่กว่า น้ำหนักที่หนากว่า ความคอนทราสต์สูงกว่า และระยะบรรทัดที่กว้างขึ้นมักบอกว่ามีความสำคัญสูงกว่า
เช่น หัวข้อขนาด 32px ตัวหนาเหนือย่อหน้าขนาด 16px ปกติจะเป็นรูปแบบ “heading + body” ชัดเจน ปัญหาเกิดเมื่อสไตล์เบลอแตกต่างกันแค่นิดเดียว เช่น ข้อความต่างกันแค่ 1–2px หรือใช้ความหนาเท่ากันแต่สีต่างกัน ในกรณีนี้ AI อาจจัดทั้งคู่เป็นข้อความทั่วไปหรือเลือกระดับหัวข้อผิด
ลำดับชั้นยังอนุมานจากความสัมพันธ์เชิงพื้นที่ องค์ประกอบที่อยู่ใกล้กัน จัดชิด และถูกแยกจากเนื้อหาอื่นด้วยช่องว่าง ถูกมองว่าเป็นกลุ่ม พื้นหลังร่วม (การ์ด, พาเนล, ส่วนที่ลงสี) ทำหน้าที่เป็นวงเล็บทางสายตา: AI มักตีความเป็นคอนเทนเนอร์อย่าง section, aside, หรือ wrapper ของคอมโพเนนต์ ช่องว่างที่ไม่สม่ำเสมอหรือ padding ที่เบี้ยวอาจทำให้เกิดการจัดกลุ่มผิด—เช่น ปุ่มไปติดกับการ์ดผิดชิ้น
รูปแบบที่ซ้ำกัน—การ์ดที่เหมือนกัน, ไอเท็มรายการ, แถวฟอร์ม—เป็นหลักฐานแข็งแรงของคอมโพเนนต์ที่นำกลับมาใช้ซ้ำ แม้ความแตกต่างเล็กน้อย (ขนาดไอคอน, มุมโค้ง, สไตล์ตัวหนังสือ) อาจทำให้ AI สร้างหลายเวอร์ชันเฉพาะกิจแทนที่จะเป็นคอมโพเนนต์เดียวที่มีวาไรแอนต์
ปุ่มสื่อเจตนาด้วยขนาด การเติมสี ความคอนทราสต์ และตำแหน่ง ปุ่มที่เติมสีเข้มมักถูกตีความเป็น action หลัก ขณะที่ปุ่มแบบขอบหรือข้อความเป็นรอง หากสองการกระทำดูเด่นเท่ากัน AI อาจเดาผิดว่าตัวไหนคือ “หลัก”
ในท้ายที่สุด AI พยายามแม็ปลำดับชั้นเป็นเชิงความหมาย: หัวข้อ (h1–h6), พื้นที่จัดกลุ่ม (section), และคลัสเตอร์ที่มีความหมาย (เช่น “รายละเอียดสินค้า” กับ “การสั่งซื้อ”) ขั้นตอนไทโปกราฟีที่ชัดเจนและการจัดกลุ่มที่สม่ำเสมอทำให้การแปลนี้เชื่อถือได้มากขึ้น
โมเดลคาดเดาเจตนาโดยจับคู่สิ่งที่เห็นกับรูปแบบที่เรียนรู้จาก UI หลายๆ แบบ: รูปร่าง ป้าย ไอคอน และตำแหน่งที่เป็นนิยาม
การจัดวางบางอย่างชี้ชัดถึงคอมโพเนนต์เฉพาะ แถบแนวนอนด้านบนที่มีโลโก้ซ้ายและลิงก์ขวาปกติมักเป็น navigation bar แถวไอเท็มความกว้างเท่ากันที่มีชิ้นหนึ่งถูกเน้นมักแม็ปเป็นแท็บ กล่องซ้ำที่มีภาพ หัวข้อ และข้อความสั้นอ่านเป็นการ์ด กริดแน่นที่มีหัวตารางและแถวมักกลายเป็นตาราง
การเดาเหล่านี้สำคัญเพราะมันส่งผลต่อโครงสร้าง: “แท็บ” บอกสเตทที่เลือกและการนำทางด้วยคีย์บอร์ด ในขณะที่ “แถวของปุ่ม” อาจไม่จำเป็นต้องมี
AI มองหาสัญญาณที่มักบ่งชี้การโต้ตอบ:
จากนั้นมันจะกำหนดพฤติกรรม: คลิก, เปิดเมนู, นำทาง, ส่ง, ขยาย/ยุบ ยิ่งดีไซน์แยกชัดว่าชิ้นไหนโต้ตอบได้กับชิ้นไหนสแตติก ผลลัพธ์ก็ยิ่งแม่นยำขึ้น
ถ้าดีไซน์โชว์หลายวาไรแอนต์—hover, active/selected, disabled, error, loading—AI สามารถแม็ปเป็นคอมโพเนนต์ที่มีสเตทได้ (เช่น disabled buttons, ข้อความการตรวจสอบ) เมื่อสเตทไม่ชัดเจน AI อาจละเว้น
ความกำกวมเป็นเรื่องปกติ: การ์ดคลิกได้หรือข้อมูลเพียงอย่างเดียว? chevron เป็นเครื่องประดับหรือเป็นตัวควบคุมการเปิดปิด? ในกรณีเหล่านี้ ชัดเจนด้วยการตั้งชื่อ, หมายเหตุ, หรือเฟรมแยกที่แสดงการโต้ตอบจะช่วยได้มาก
เมื่อ AI อ่านเลย์เอาต์ได้แล้ว ขั้นต่อไปคือแปลง “หน้าตาเป็นอย่างไร” ให้เป็น “คืออะไร”: HTML แบบมีความหมาย, คอมโพเนนต์ที่นำกลับมาใช้ได้, และสไตล์ที่สอดคล้องกัน
เครื่องมือส่วนใหญ่แม็ปเลเยอร์และกลุ่มในดีไซน์ให้เป็นต้นไม้ DOM: เฟรมเป็นคอนเทนเนอร์, เลเยอร์ข้อความเป็นหัวข้อ/ย่อหน้า, และไอเท็มซ้ำกลายเป็นรายการหรือกริด
เมื่อเจตนาชัด AI อาจแนบความหมายที่ดีกว่า—เช่น แถบท็อปกลายเป็น \u003cheader\u003e, โลโก้และลิงก์กลายเป็น \u003cnav\u003e, และการ์ดที่คลิกได้กลายเป็น \u003ca\u003e หรือ \u003cbutton\u003e. บางครั้ง ARIA roles อาจถูกอนุมาน (เช่น role="dialog" สำหรับโมดัล) แต่เฉพาะเมื่อรูปแบบชัดเจน; มิฉะนั้นผลลัพธ์ที่ปลอดภัยกว่าคือ HTML ปกติเพื่อใส่ TODO ตรวจสอบการเข้าถึงต่อไป.
มันคือการแปลงด้วย AI จากภาพ UI (เฟรม Figma, เอ็กซ์พอร์ตการออกแบบ หรือภาพหน้าจอ) ให้เป็นโค้ด UI ที่รันได้ จุดประสงค์คือร่างแรกที่แข็งแรง—โครงสร้าง รูปแบบความหายใจของการจัดวาง และโครงสร้างพื้นฐาน—เพื่อให้นักพัฒนานำไปรีแฟกเตอร์เป็นโทเค็น คอมโพเนนต์ และความหมายที่เหมาะกับการผลิตต่อได้.
โดยทั่วไปมันจะแปลงได้ดีในส่วนต่อไปนี้:
พิกเซลไม่ได้บอกทุกอย่าง คุณมักต้องระบุหรือจัดเตรียม:
ภาพหน้าจอเป็นอินพุตที่บางที่สุด: มีแค่สีและรูปทรงแต่ไม่มีโครงสร้างชัดเจน (เลเยอร์, ข้อจำกัด, คอมโพเนนต์). คาดว่าจะมีการเดาเยอะขึ้น ตำแหน่งแบบ absolute มากขึ้น และโค้ดที่นำกลับมาใช้ซ้ำได้น้อยกว่า.
ไฟล์ Figma/Sketch หรือการเอ็กซ์พอร์ตที่รักษาโครงสร้างไว้จะให้ข้อมูลสำคัญ: เฟรม, กลุ่ม, ชื่อเลเยอร์, Auto Layout, ข้อจำกัด และสไตล์—สัญญาณเหล่านี้ช่วยให้สร้างเลย์เอาต์แบบ flex/grid และขอบเขตคอมโพเนนต์ที่แม่นยำขึ้น.
AI มองหาการจัดชิดที่ซ้ำกันและช่องว่างที่สม่ำเสมอเพื่อนิยาม UI เป็นกฎ flex/grid. ถ้ามีจังหวะช่องว่างที่ชัดเจน (เช่น 8/16/24) มันสามารถสร้าง stacks และ grids ที่เสถียรได้.
ถ้าช่องว่างไม่สม่ำเสมอหรือองค์ประกอบเล็กน้อยเบี้ยว โมเดลมักจะถอยไปใช้ พิกัดแบบ absolute เพื่อรักษารูปลักษณ์ที่เป๊ะ—ซึ่งแลกมาด้วยการตอบสนองที่แย่ลง.
มันมองหาสัญญาณของการ “ครอบ” ทางสายตา:
การจัดกลุ่มและโครงสร้างที่ชัดเจนในเครื่องมือออกแบบ (เฟรม, Auto Layout) ทำให้การสร้างความสัมพันธ์ระหว่างพาเรนต์/ชิลด์ในโค้ดง่ายขึ้นมาก.
ตำแหน่งแบบ absolute ปรากฏเมื่อความสัมพันธ์ระหว่างองค์ประกอบไม่ชัดเจน—มีการซ้อนทับ, ช่องว่างไม่สม่ำเสมอ, หรือการจัดวางแบบแมนนวล. มันอาจจะดูถูกต้องที่ขนาดจอหนึ่งแต่พังเมื่อ:
ถ้าอยากได้ผลลัพธ์ที่ยืดหยุ่น ให้ดีไซน์ทำงานแบบ flex/grid ผ่าน Auto Layout และข้อจำกัด.
มันอนุมานลำดับชั้นจากสัญญาณทางสายตา:
เมื่อสไตล์ต่างกันแค่ 1–2px หรือขั้นตอนลำดับชั้นไม่ชัด มันอาจเลือกระดับหัวข้อผิดหรือจัดข้อความเป็นเพียงตัวหนังสือทั่วไป.
AI คาดเดาความโต้ตอบจากรูปลักษณ์ที่คุ้นเคย:
ถ้าองค์ประกอบหนึ่งอาจคลิกได้หรือเป็นข้อมูลอย่างเดียว ให้ใส่หมายเหตุหรือโชว์วาไรแอนต์ มิฉะนั้นโมเดลอาจต่อสายพฤติกรรมผิดหรือข้ามการโต้ตอบไป.
ทำการตรวจสอบอย่างรวดเร็วตามลำดับ:
มองผลลัพธ์เป็นโครงร่าง แล้วจดบันทึกสมมติฐานเพื่อไม่ให้การแก้ครั้งถัดไปทำลายการตัดสินใจของคุณ.