30 ก.ย. 2568·3 นาที
วิธีที่ AI ซ่อนความซับซ้อนของแบ็กเอนด์ เพื่อให้ผู้ก่อตั้งส่งงานได้เร็วขึ้น
AI ช่วยอัตโนมัติการตั้งโครง, การเชื่อมต่อ และงานปฏิบัติการซ้ำๆ ทำให้ผู้ก่อตั้งใช้เวลาน้อยลงกับท่อระบบแบ็กเอนด์ และใช้เวลามากขึ้นกับผลิตภัณฑ์, UX, และการออกสู่ตลาด
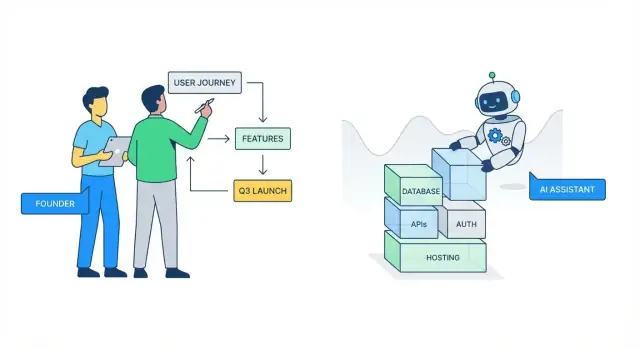
ทำไมความซับซ้อนของแบ็กเอนด์ถึงทำให้ผู้ก่อตั้งช้าลง
“ความซับซ้อนของแบ็กเอนด์” คือสิ่งที่ทำงานเบื้องหลังทั้งหมดเพื่อให้ผลิตภัณฑ์ดูเรียบง่าย: การเก็บข้อมูลอย่างปลอดภัย, การเปิดข้อมูลผ่าน API, การจัดการการล็อกอิน, การส่งอีเมล, การประมวลผลการชำระเงิน, งานแบ็กกราวนด์, การมอนิเตอริงข้อผิดพลาด และการรักษาเสถียรภาพเมื่อการใช้งานเพิ่มขึ้น
สำหรับผู้ก่อตั้งและทีมเริ่มต้น งานพวกนี้ชะลอความเคลื่อนไหวเพราะต้องใช้ต้นทุนการตั้งค่าที่สูงก่อนผู้ใช้จะเห็นคุณค่า คุณอาจเสียเวลาหลายวันถกเถียงสคีมาฐานข้อมูล, เชื่อมระบบการยืนยันตัวตน, หรือตั้งค่าสภาพแวดล้อม—แล้วค่อยรู้จากลูกค้ารายแรกว่าฟีเจอร์ต้องเปลี่ยน
งานแบ็กเอนด์ยังเชื่อมโยงกัน: การตัดสินใจผลิตภัณฑ์เล็กๆ (เช่น “ผู้ใช้สามารถอยู่ในหลายทีมได้”) อาจลามไปสู่การเปลี่ยนแปลงฐานข้อมูล, กฎสิทธิ์, การอัปเดต API, และมิเกรชัน
รูปแบบเมื่ิอ AI “ทำให้เป็นนามธรรม”
ในการใช้งานจริง การทำให้นามธรรมด้วย AI หมายถึงคุณบอกสิ่งที่ต้องการ แล้วเครื่องมือสร้างหรือประสานงานส่วนที่น่าเบื่อให้:\n\n- ร่าง endpoints CRUD, การตรวจสอบอินพุต, และการจัดการข้อผิดพลาดพื้นฐาน\n- เสนอโมเดลข้อมูลและความสัมพันธ์ตามฟีเจอร์ของคุณ\n- สร้างโฟลว์การยืนยันตัวตน (sessions, tokens) และโครงสิทธิ์\n- สร้างโค้ดเชื่อมต่อสำหรับบริการทั่วไป (อีเมล, การชำระเงิน, การวิเคราะห์)\n\nประโยชน์หลักไม่ใช่ความสมบูรณ์แบบ—แต่เป็นความเร็วสู่จุดเริ่มต้นที่ทำงานได้ให้คุณวนซ้ำต่อ
แพลตฟอร์มอย่าง Koder.ai ไปไกลกว่านั้นด้วยการจับคู่เวิร์กโฟลว์ที่ขับเคลื่อนด้วยแชทกับสถาปัตยกรรมแบบ agent-based: คุณอธิบายผลลัพธ์ (เว็บ, แบ็กเอนด์, หรือมือถือ) แล้วระบบจะ scaffold แอปให้ครบตั้งแต่ต้นจนจบ (เช่น React บนเว็บ, Go + PostgreSQL บนแบ็กเอนด์, และ Flutter สำหรับมือถือ) ทำให้คุณขยับจากไอเดียไปยังฐานที่ deploy ได้โดยไม่ต้องเสียเวลาทำ plumbing เป็นสัปดาห์
สิ่งที่มันไม่ได้หมายความว่า
AI ไม่ได้ยกเลิกความจำเป็นในการตัดสินใจด้านผลิตภัณฑ์และความเสี่ยง มันจะไม่รู้กฎธุรกิจที่แน่นอนของคุณ, ข้อมูลที่คุณต้องเก็บ, ความเข้มงวดของสิทธิ์ที่ควรเป็นอย่างไร, หรือความหมายของ “ปลอดภัยพอ” สำหรับโดเมนของคุณ นอกจากนี้มันยังไม่สามารถป้องกันปัญหาสเกลหรือการบำรุงรักษาทุกอย่างได้หากทางเลือกสถาปัตยกรรมพื้นฐานไม่แข็งแรง
ตั้งความคาดหวังให้ถูกต้อง: AI ช่วยให้คุณวนซ้ำเร็วขึ้นและหลีกเลี่ยงการเริ่มจากหน้าว่าง แต่คุณยังเป็นเจ้าของตรรกะผลิตภัณฑ์, การแลกเปลี่ยนข้อดีข้อเสีย, และมาตรฐานคุณภาพสุดท้าย
ต้นทุนจริงของงานแบ็กเอนด์สำหรับทีมเริ่มต้น
ทีมเริ่มต้นแทบจะไม่ได้ “เลือก” งานแบ็กเอนด์—มันโผล่มาเป็นกองงานจำเป็นระหว่างไอเดียกับสิ่งที่ผู้ใช้สัมผัสได้ แหล่งดูดเวลาคือไม่ใช่แค่การเขียนโค้ด แต่เป็นภาระทางความคิดของการตัดสินใจเล็กๆ หลายสิบครั้งก่อนคุณจะตรวจสอบผลิตภัณฑ์
เวลาของผู้ก่อตั้งหายไปเงียบๆ ที่ไหนบ้าง
งานบางอย่างมักกินชั่วโมงอย่างไม่สมส่วน:\n\n- การยืนยันตัวตนและสิทธิ์: ฟลว์ล็อกอิน, รีเซ็ตรหัส, บทบาท, กรณีขอบ, และ “เกิดอะไรขึ้นถ้า…”\n- โมเดลข้อมูล: ตัดสินใจตาราง/คอลเลกชัน, ความสัมพันธ์, มิเกรชัน, และวิธีเปลี่ยนแปลงโดยไม่ทำลายทุกอย่าง\n- การดีพลอย: สภาพแวดล้อม, ความลับ, การตั้งค่า CI/CD, และเหตุการณ์ “ทำไม prod ต่างจาก local” ครั้งแรก\n- การเชื่อมต่อ: webhooks, การ retry, idempotency, การตรวจสอบลายเซ็น, และการแมปความแตกต่างของผู้ให้บริการภายนอกเข้ากับผลิตภัณฑ์ของคุณ
ต้นทุนที่ซ่อนอยู่คืิอการ สลับบริบท ระหว่างการคิดเชิงผลิตภัณฑ์ (“ผู้ใช้ควรทำอะไรได้บ้าง?”) กับการคิดเชิงโครงสร้างพื้นฐาน (“จะเก็บและเปิดเผยมันอย่างปลอดภัยอย่างไร?”) การสลับนี้ชะลอความก้าวหน้า เพิ่มความผิดพลาด และเปลี่ยนการดีบักให้กลายเป็นการเลี้ยวหลายชั่วโมง—โดยเฉพาะเมื่อคุณยังต้องจัดการการขาย, สนับสนุน, และระดมทุนด้วย
มันชะลอวงจรการเรียนรู้อย่างไร
ทุกวันที่ใช้ไปในการเดินสายพื้นฐานของแบ็กเอนด์คือวันที่ไม่ได้คุยกับผู้ใช้และวนปรับปรุง วงจร build–measure–learn ยืดออก: คุณปล่อยช้าลง เรียนรู้ช้าลง และเสี่ยงสร้างของผิดที่มีความปราณีตมากขึ้น
สัปดาห์หนึ่งสูญไปกับ “แค่ตั้งค่ากันให้เสร็จ”
สถานการณ์ทั่วไป: จันทร์–อังคาร ทำ auth และตารางผู้ใช้, พุธ ตั้งค่า deployment และ environment vars, พฤหัสเชื่อมการชำระเงินหรืออีเมล, ศุกร์ ไล่บั๊ก webhook และเขียนแผงผู้ดูแล เราจบสัปดาห์ด้วย “ท่อ” ไม่ใช่ฟีเจอร์ที่ผู้ใช้ยอมจ่าย
AI ที่ช่วยนามธรรมแบ็กเอนด์ไม่ใช่การลบความรับผิดชอบ แต่ช่วยทวงคืนสัปดาห์นั้นให้คุณส่งการทดลองได้เร็วขึ้นและรักษาโมเมนตัม
ความหมายของการ “นามธรรม” ด้วย AI ในทางปฏิบัติ
การนามธรรมด้วย AI ไม่ใช่เวทมนตร์—มันคือการยกงานแบ็กเอนด์ขึ้นระดับหนึ่ง แทนที่จะคิดเป็นเฟรมเวิร์ก ไฟล์ และโค้ดเชื่อม คุณอธิบายผลลัพธ์ที่ต้องการ (“ผู้ใช้สมัครได้”, “เก็บคำสั่งซื้อ”, “ส่ง webhook เมื่อชำระเงิน”) แล้ว AI ช่วยแปลความตั้งใจนั้นเป็นบล็อกการสร้างที่จับต้องได้
AI เป็นผู้ช่วยสำหรับงานวิศวกรรมซ้ำๆ
งานแบ็กเอนด์จำนวนมากคาดเดาได้: การเดินเส้นทาง, กำหนด DTOs, ตั้ง endpoints CRUD, ตรวจสอบอินพุต, สร้างมิเกรชัน, และเขียน adapter การเชื่อมต่อซ้ำๆ AI แสดงจุดแข็งเมื่อสิ่งเหล่านี้เป็นรูปแบบและแนวปฏิบัติที่ชัดเจน
นี่คือ “การนามธรรม” ในทางปฏิบัติ: ลดเวลาที่คุณใช้จำคอนเวนชันและค้นหาด็อกซ์ ในขณะที่ยังคงให้คุณควบคุมสิ่งที่จะสร้าง
พรอมป์กลายเป็นโครง สคอนฟิก และคำแนะนำโค้ดอย่างไร
พรอมป์ที่ดีทำหน้าที่เหมือนสเปคย่อ ตัวอย่าง: “สร้างบริการ Orders พร้อม endpoints เพื่อสร้าง, ลิสต์, ยกเลิกคำสั่งซื้อ. ใช้การเปลี่ยนสถานะ. เพิ่ม audit fields. ส่งกลับการแบ่งหน้า.” จากนั้น AI สามารถเสนอ:\n\n- โครงโมดูลที่ scaffold (controllers/services/models)\n- อัปเดต config (env vars, CORS, คิว, rate limits)\n- มิเกรชันและโมเดลข้อมูลที่สอดคล้องกับฟีเจอร์\n- ตัวอย่างเทสต์และสคริปต์เอกสาร API\n\nคุณยังคงทบทวน ปรับชื่อ และตัดสินขอบเขต—แต่ต้นทุนการเริ่มต้นจากหน้าว่างลดลงอย่างมาก
จุดที่ AI ช่วยได้มากที่สุด—และที่มันยังลำบาก
AI มักเด่นกับคอมโพเนนต์มาตรฐาน: โฟลว์ auth, แนว REST, งานแบ็กกราวนด์, แคชชิ่งพื้นฐาน, และการเชื่อมต่อทั่วไป\n\nมันลำบากเมื่อข้อกำหนดคลุมเครือ (“ทำให้สเกลได้”), เมื่อกฎธุรกิจซับซ้อน (“ตรรกะคืนเงินขึ้นกับประเภทสัญญาและวันที่”), และในกรณีขอบที่เกี่ยวข้องกับ concurrency, เงิน, และสิทธิ์ ในสถานการณ์แบบนั้น ทางที่เร็วที่สุดมักคือชี้แจงกฎก่อน (แม้ด้วยภาษาธรรมดา) แล้วบอกให้ AI นำ สัญญานั้น ไป implement—และตรวจสอบด้วยเทสต์
Scaffolding และ Boilerplate: ชัยชนะที่เร็วที่สุด
ผู้ก่อตั้งเสียวันกับงานที่ไม่ขยับผลิตภัณฑ์: ตั้งโฟลเดอร์, คัดลอก pattern เดิม, และเปลี่ยน “hello world” ให้เป็นสิ่งที่ดีพลอยได้ AI-powered backend abstraction มีค่ายิ่งที่นี่เพราะผลลัพธ์คาดเดาได้และทำซ้ำได้—เหมาะกับการอัตโนมัติ
สร้าง skeleton โปรเจกต์ที่สอดคล้องกับความตั้งใจ
แทนการเริ่มจากรีโปเปล่า คุณสามารถบอกว่ากำลังสร้างอะไร (“SaaS แบบ multi-tenant พร้อม REST API, Postgres, งานแบ็กกราวนด์”) แล้วสร้างโครงที่สอดคล้อง: บริการ/โมดูล, routing, เลเยอร์เข้าถึงฐานข้อมูล, logging, และ convention การจัดการข้อผิดพลาด
นี่ให้ทีมของคุณจุดเริ่มต้นเดียวกันและตัดวงจรการถกเถียงตอนต้นว่า “ไฟล์นี้ควรอยู่ที่ไหน?”
endpoints CRUD โดยไม่ต้องคัดลอก/วางซ้ำๆ
MVP ส่วนใหญ่ต้องการพื้นฐานเดียวกัน: endpoints สำหรับ create/read/update/delete บวกการตรวจสอบที่ตรงไปตรงมา AI สามารถ scaffold endpoints เหล่านี้อย่างสม่ำเสมอ—การแยก request, รหัสสถานะ, และกฎการตรวจสอบ—ทำให้คุณใช้เวลาไปกับตรรกะผลิตภัณฑ์ (กฎราคา, ขั้นตอน onboarding, สิทธิ์) แทนงานเชื่อม
ประโยชน์เชิงปฏิบัติ: รูปแบบที่สม่ำเสมอทำให้การ refactor ภายหลังถูกกว่า เมื่อทุก endpoint ตามคอนเวนชันเดียวกัน คุณสามารถเปลี่ยนพฤติกรรม (เช่น การแบ่งหน้า หรือรูปแบบข้อผิดพลาด) ทีเดียวแล้วแพร่หลายได้
ตั้งค่า config และ environment variables ให้ถูกต้อง
การตั้งค่าสภาพแวดล้อมผิดพลาดทำให้เกิดความล่าช้าแฝง: ความลับหาย, URL ฐานข้อมูลผิด, การตั้งค่า dev/prod ไม่สอดคล้อง AI สามารถสร้างแนวทาง config ที่สมเหตุสมผลตั้งแต่ต้น—เทมเพลต env, ไฟล์ config, และเอกสาร “ต้องตั้งค่าอะไรที่ไหน” ชัดเจน—ทำให้เพื่อนร่วมทีมรันโปรเจกต์โลคัลได้ราบรื่นขึ้น
ลด boilerplate ข้ามบริการและโมดูล
เมื่อคุณเพิ่มฟีเจอร์ การทำซ้ำก็เติบโต: มิดเดิลแวร์ซ้ำ, DTOs ซ้ำ, รูปแบบ “service + controller” ซ้ำ AI สามารถแยกชิ้นที่ใช้ร่วมกันเป็น helper และเทมเพลตที่นำกลับมาใช้ใหม่ เพื่อให้โค้ดเบสเล็กลงและหาได้ง่ายขึ้น
ผลลัพธ์ที่ดีที่สุดไม่ใช่แค่ความเร็ววันนี้—แต่คือโค้ดเบสที่ยังเข้าใจได้เมื่อ MVP เติบโตเป็นผลิตภัณฑ์จริง
ช่วยออกแบบข้อมูลโดยไม่ต้องเป็นผู้เชี่ยวชาญฐานข้อมูล
การออกแบบข้อมูลคือที่ผู้ก่อตั้งหลายคนติดขัด: คุณรู้ว่าผลิตภัณฑ์ควรทำอะไร แต่เปลี่ยนสิ่งนั้นเป็นตาราง ความสัมพันธ์ และข้อจำกัดกลับเหมือนการเรียนภาษาที่สอง
เครื่องมือ AI สะพานช่องว่างนั้นโดยแปลความต้องการผลิตภัณฑ์เป็นสคีมาฉบับร่างที่คุณสามารถตอบกลับได้—ดังนั้นคุณใช้เวลาในการตัดสินใจเชิงผลิตภัณฑ์ ไม่ใช่ท่องกฎฐานข้อมูล
จากความต้องการผลิตภัณฑ์สู่เอนทิตีและความสัมพันธ์
ถ้าคุณอธิบายวัตถุหลักของคุณ (“ผู้ใช้สร้างโปรเจกต์ได้; โปรเจกต์มีงาน; งานมอบหมายให้ผู้ใช้ได้”) AI สามารถเสนอโมเดลที่มีโครงสร้าง: เอนทิตี, ฟิลด์, และความสัมพันธ์ (one-to-many vs many-to-many)
ชัยชนะไม่ใช่ AI ถูกต้องวิเศษ—แต่คุณเริ่มจากข้อเสนอที่จับต้องได้และตรวจสอบได้เร็ว:\n\n- “Task” ควรเป็นของ “Project” เดียวหรือแชร์ได้?\n- คุณต้องมี “Organizations” ตอนนี้ไหม หรือ “Projects” พอให้เป็นของผู้ใช้คนเดียวสำหรับ MVP?
มิเกรชันและ seed data—สร้างแล้วตรวจทาน
เมื่อโมเดลตกลงกัน AI สามารถสร้างมิเกรชันและข้อมูลตัวอย่างเพื่อให้แอปใช้งานได้ในสภาพแวดล้อมพัฒนา ซึ่งรวมถึง:\n\n- การสร้างตารางและดัชนี\n- การเพิ่ม foreign keys\n- การใส่ระเบียนตัวอย่างที่สมจริงหลายรายการ
การตรวจทานโดยมนุษย์สำคัญที่นี่ คุณต้องเช็คการตั้งค่าเริ่มต้นที่อาจทำให้ข้อมูลหาย, ข้อจำกัดที่ขาดหาย, หรือการใส่ดัชนีผิดฟิลด์
การตั้งชื่อสอดคล้องระหว่างสคีมาและโค้ด
การไหลของชื่อเป็นแหล่งบั๊กเงียบ (“customer” ในโค้ด, “client” ในฐานข้อมูล) AI ช่วยรักษาชื่อให้สอดคล้องข้ามโมเดล, มิเกรชัน, payload ของ API, และเอกสาร—โดยเฉพาะเมื่อฟีเจอร์เปลี่ยนระหว่างการสร้าง
ข้อควรระวัง: สคีมาไม่สามารถตัดสินกลยุทธ์ผลิตภัณฑ์ให้คุณ
AI เสนอโครงได้ แต่ไม่สามารถตัดสินใจว่าคุณควรมุ่งไปทางไหน: ยืดหยุ่น vs เรียบง่าย, ตรวจสอบย้อนหลังได้ vs ความเร็ว, หรือว่าคุณจะต้องการ multi-tenancy ในอนาคตหรือไม่ นั่นคือการตัดสินใจเชิงผลิตภัณฑ์
กฎช่วยได้: model ในสิ่งที่คุณต้องพิสูจน์สำหรับ MVP และเหลือที่ให้ขยาย—โดยไม่ออกแบบเกินความจำเป็นตั้งแต่วันแรก
การยืนยันตัวตนและการอนุญาตโดยไม่ต้องปวดหัว
รักษาความต่อเนื่องด้วยการย้อนกลับ
ทำการเปลี่ยนแปลงอย่างมั่นใจด้วยสแนปช็อตและย้อนกลับเมื่อการวนซ้ำผิดพลาด
การยืนยันตัวตน (ใครเป็นผู้ใช้) และการอนุญาต (ทำอะไรได้บ้าง) เป็นสองจุดที่ผลิตภัณฑ์ต้นมักเสียวัน AI ช่วยโดยสร้างส่วนมาตรฐานอย่างรวดเร็ว—แต่คุณค่าจริงไม่ใช่ความปลอดภัยวิเศษ มันคือการเริ่มจากแนวปฏิบัติที่พิสูจน์แล้วแทนการคิดใหม่ทั้งหมด
โฟลว์ล็อกอินเร็วที่ตรงกับแพทเทิร์นทั่วไป
MVP ส่วนใหญ่ต้องการหนึ่งในฟลว์เหล่านี้:\n\n- อีเมล + รหัสผ่าน พร้อมรีเซ็ตรหัส, ยืนยันอีเมล, และการจำกัดความถี่\n- OAuth sign-in (Google, Apple, GitHub) พร้อมการผูกบัญชีอย่างปลอดภัย\n- การ onboard แบบเชิญ สำหรับทีม (ยอมรับเชิญ → ตั้งรหัสหรือ OAuth)
AI สามารถ scaffold routes, controllers, ฟอร์ม UI, และการเชื่อมระหว่างพวกมัน (ส่งอีเมลรีเซ็ต, จัดการ callback, บันทึกผู้ใช้) ช่วยให้รวดเร็วและครบถ้วน: endpoints น้อยลงที่ลืม และ edge cases ที่ค้างครึ่งเดียว
การควบคุมการเข้าถึงแบบบทบาท (RBAC): ง่ายแต่ทำผิดได้ง่าย
RBAC มักพอสำหรับช่วงเริ่มต้น: admin, member, อาจมี viewer ความผิดพลาดมักเกิดเมื่อ:\n\n- บทบาทถูกตรวจบาง endpoint แต่ไม่ครบทุกที่\n- ตรรกะ “เจ้าของ” ถูกผสมกับบทบาท (ownership มักเป็นกฎแยกต่างหาก)\n- การซ่อนฝั่ง frontend ถูกมองว่าเป็นความปลอดภัย (การอนุญาตต้องตรวจฝั่งเซิร์ฟเวอร์)
baseline ที่ AI สร้างดีควรรวมชั้นอนุญาตเดียว (middleware/policies) เพื่อไม่ให้คุณกระจายการตรวจ everywhere
Sessions vs tokens (ภาพรวม)
- Sessions (cookie-based) โดยทั่วไปง่ายสุดสำหรับเว็บแอป: เซิร์ฟเวอร์สามารถเพิกถอน, หมุน, และปกป้องด้วยคุกกี้
HttpOnly\n- Tokens (JWTs) สะดวกสำหรับไคลเอนต์มือถือ/API แต่การเพิกถอนและกลยุทธ์การหมดอายุต้องมีการออกแบบ
ถ้าไม่แน่ใจ ให้เริ่มจาก sessions สำหรับ MVP ที่เน้นเบราว์เซอร์ แล้วเพิ่ม token เมื่อมีไคลเอนต์จริงต้องการ
เช็คลิสต์: ตรวจสอบโค้ด auth ที่ AI สร้างอย่างปลอดภัย
- รหัสผ่านแฮชด้วยอัลกอริทึมสมัยใหม่ (เช่น bcrypt/argon2), ห้ามเก็บหรือบันทึกเป็นข้อความธรรมดา\n- การตรวจสิทธิ์เกิดขึ้นที่เซิร์ฟเวอร์สำหรับทุก route ที่ป้องกัน\n- ตั้งค่าคุกกี้ถูกต้อง (
HttpOnly,Secure, ค่าSameSiteที่สมเหตุสมผล) หากใช้ sessions\n- callback ของ OAuth ตรวจสอบstateและ redirect URLs ที่อนุญาต\n- มี rate limiting สำหรับ endpoints ล็อกอิน/รีเซ็ต\n- ไม่มีความลับถูก hardcoded; โหลดจาก environment variables\n- มีทางเพิกถอน sessions/tokens และหมุน credentials
การเชื่อมต่อและ Webhooks: โค้ดเชื่อมลดลง โมเมนตัมเพิ่มขึ้น
การเชื่อมต่อคือที่ที่ไทม์ไลน์ MVP มักพังทลาย: Stripe สำหรับการชำระเงิน, Postmark สำหรับอีเมล, Segment สำหรับการวิเคราะห์, HubSpot สำหรับ CRM แต่ละอย่างเป็น “แค่ API” จนกว่าคุณต้องจัดการกับสคีมาที่ต่างกัน, การรับรอง, retries, rate limits, รูปแบบข้อผิดพลาด และกรณีขอบที่เอกสารไม่ครบ
AI-powered backend abstraction ช่วยเปลี่ยนงานชิ้นเดี่ยวเหล่านี้ให้เป็นรูปแบบที่ทำซ้ำได้—ทำให้คุณใช้เวลาน้อยลงกับการเดินสายและมากขึ้นกับการตัดสินใจเชิงผลิตภัณฑ์
เชื่อมต่อบริการทั่วไปโดยไม่ต้องตั้งค่าหนึ่งสัปดาห์
ชัยชนะเร็วมักมาจากการเชื่อมต่อมาตรฐาน:\n\n- การชำระเงิน: สร้างลูกค้า, เริ่มสมัครสมาชิก, จัดการการชำระเงินล้มเหลว\n- อีเมล: แม่แบบเชิงธุรกรรม, เหตุการณ์การส่ง, รายการ suppression\n- การวิเคราะห์: การตั้งชื่อ event ให้สม่ำเสมอ, การเชื่อมตัวตนผู้ใช้\n- CRM: ซิงก์บัญชีและผู้ติดต่อโดยไม่ต้องทำข้อมูลซ้ำ
แทนการเย็บ SDK ด้วยมือ AI สามารถ scaffold ชิ้น “น่าเบื่อแต่จำเป็น”: environment variables, shared HTTP clients, โมเดล request/response ที่มีชนิดข้อมูล, ค่าเริ่มต้นที่สมเหตุสมผลสำหรับ timeout และ retry
Webhooks: handler อัตโนมัติ ลดเหตุการณ์ที่พลาด
Webhooks คืออีกครึ่งของการเชื่อม—เช่น invoice.paid ของ Stripe, เหตุการณ์ “delivered” ของอีเมล, การอัปเดต CRM เครื่องมือ abstraction สามารถสร้าง endpoints ของ webhook และการตรวจสอบลายเซ็น และแปลงเป็นเหตุการณ์ภายในที่ชัดเจนให้คุณจัดการ (เช่น PaymentSucceeded)
รายละเอียดสำคัญ: การประมวลผล webhook ควร idempotent หาก Stripe retry เหตุการณ์เดิม ระบบของคุณไม่ควรให้บริการซ้ำ AI scaffold สามารถชี้ให้เก็บ event ID และละเว้นรายการซ้ำได้
การแมปข้อมูลระหว่างระบบ (และจุดที่ทีมพลาด)
บั๊กส่วนใหญ่เกิดจากรูปแบบข้อมูลไม่ตรงกัน: ID ที่ไม่ตรง, โซนเวลา, เงินเป็น float, หรือฟิลด์ที่เป็น “optional” แล้วไม่มีในโปรดักชัน จัดการ ID ภายนอกเป็นฟิลด์สำคัญ เก็บ payload ดิบของ webhook เพื่อ audit/ดีบัก และอย่าซิงก์ข้อมูลมากกว่าที่คุณใช้จริง
ทดสอบในสเตจจิงก่อนขึ้นโปรดักชัน
ใช้บัญชี sandbox, คีย์แยก, และ endpoint webhook ในสเตจจิง รีเพลย์ payload ที่บันทึกไว้เพื่อตรวจว่า handler ทำงาน และยืนยัน workflow ทั้งหมด (payment → webhook → database → email) ก่อนเปิดใช้งานจริง
การออกแบบ API ที่สอดคล้องกับผลิตภัณฑ์
เร่งความเร็วในการทำงานบน auth และ roles
สร้างโครงสำหรับล็อกอินและบทบาท แล้วปรับกฎให้เข้ากับผลิตภัณฑ์ของคุณ
เมื่อผู้ก่อตั้งพูดว่า “แบ็กเอนด์ทำให้เราช้าลง” มักเป็นปัญหา API: frontend ต้องการโครงข้อมูลแบบหนึ่ง แต่ backend ส่งมาอีกแบบ และทุกคนต้องเสียเวลาต่อกัน
AI สามารถลดแรงเสียดทานนั้นโดยปฏิบัติต่อ API เป็นสัญญาที่มีชีวิต—สิ่งที่คุณสร้าง, ตรวจสอบ, และพัฒนาอย่างตั้งใจเมื่อความต้องการเปลี่ยน
เริ่มจากสัญญา ไม่ใช่การเดา
เวิร์กโฟลว์ที่ใช้ได้จริงคือขอให้ AI ร่างสัญญา API พื้นฐานสำหรับฟีเจอร์ (endpoints, พารามิเตอร์, และกรณีข้อผิดพลาด) พร้อมตัวอย่าง request/response ตัวอย่างเหล่านี้จะเป็นอ้างอิงร่วมในติกเก็ตและ PRs และช่วยลดความคลาดเคลื่อน
OpenAPI สองทิศทาง
ถ้าคุณมี endpoints อยู่แล้ว AI ช่วยสกัด OpenAPI spec จาก routes และ payload จริง เพื่อให้เอกสารตรงกับความจริง ถ้าคุณชอบออกแบบก่อน AI สามารถ scaffold routes, controllers, และ validators จากไฟล์ OpenAPI ได้ ไม่ว่าจะทางไหน คุณจะมีแหล่งความจริงเดียวที่ขับเคลื่อนเอกสาร, mocks, และการสร้างไคลเอนต์
รักษา frontend และ backend ให้ตรงกันด้วย typed contracts
สัญญาที่มีชนิดข้อมูล (TypeScript types, Kotlin/Swift models ฯลฯ) ป้องกันการ drift ของฟิลด์ AI สามารถ:\n\n- สร้างไทป์ของไคลเอนต์จาก OpenAPI\n- แนะนำ DTOs หรือการนิยามสคีมาที่ใช้ร่วมกัน\n- แจ้งจุดที่ frontend คาดฟิลด์ที่ backend ไม่ได้ส่ง (และในทางกลับกัน)
ที่นี่คือที่การ “ส่งงานได้เร็วขึ้น” กลายเป็นเรื่องจริง: ลดความประหลาดใจจากการบูรณาการ และลดการเดินสายด้วยมือ
หลีกเลี่ยงการเปลี่ยนแปลงที่ทำลายเมื่อวิวัฒนาการ
เมื่อผลิตภัณฑ์วนปรับ AI สามารถตรวจ diff และเตือนเมื่อการเปลี่ยนแปลงเป็น breaking (ลบฟิลด์, เปลี่ยนความหมาย, เปลี่ยนรหัสสถานะ) มันยังสามารถเสนอแนวทางปลอดภัย: การเปลี่ยนแบบ additive, versioning, หน้าต่าง deprecation, และเลเยอร์ความเข้ากันได้
ผลลัพธ์คือ API ที่เติบโตไปกับผลิตภัณฑ์ แทนที่จะต่อสู้กับมันเสมอ
การทดสอบและดีบัก: ความมั่นใจที่เร็วขึ้น ไฟร์ดริลน้อยลง
เมื่อคุณขยับไว ช่วงเวลาที่น่ากลัวที่สุดคืิอปล่อยการเปลี่ยนแปลงแล้วพบว่าคุณทำลายสิ่งอื่น การทดสอบและดีบักคือวิธีซื้อความมั่นใจ—แต่งานเขียนเทสต์จากศูนย์อาจรู้สึกเหมือนภาษีที่คุณ “จ่ายไม่ไหว” ในช่วงต้น
AI สามารถลดภาระนั้นด้วยการแปลงสิ่งที่คุณรู้เกี่ยวกับผลิตภัณฑ์เป็นตะแกรงความปลอดภัยที่ทำซ้ำได้
ร่างเทสต์สำหรับฟลว์ที่สำคัญ
แทนการไล่ให้ครอบคลุมทั้งหมด ให้เริ่มจากเส้นทางผู้ใช้หลักที่ต้องไม่ล้มเหลว: ลงชื่อ, ชำระเงิน, สร้างเรคคอร์ด, เชิญเพื่อนร่วมงาน
AI มีประโยชน์ตรงที่มันสามารถร่างเทสต์สำหรับ:\n\n- เส้นทางปกติ (happy path)\n- ชุดกรณีขอบเล็กๆ (อินพุตไม่ถูก, สิทธิ์ไม่พอ, คำขอซ้ำ)
คุณยังตัดสินใจว่าพฤติกรรมที่ถูกต้องคืออะไร แต่ไม่ต้องเขียนทุก assertion ด้วยมือ
สร้าง mock data และ fixtures ได้เร็ว
หลายชุดทดสอบติดเพราะการสร้างข้อมูลทดสอบสมจริงน่าเบื่อ AI สามารถสร้าง fixtures ที่ตรงกับโมเดลของคุณ (ผู้ใช้, แผน, ใบแจ้งหนี้) และสร้างแบบแปรผัน—สมาชิกหมดอายุ, บัญชีถูกล็อก, โปรเจกต์ถูกเก็บ—ทำให้คุณทดสอบพฤติกรรมโดยไม่ต้องปั้นเรคคอร์ดเป็นพัน
ใช้ AI เป็นพาร์ทเนอร์ในการดีบัก
เมื่อเทสต์ล้ม AI ช่วยสรุปลล็อกที่มีเสียงดัง แปล stack trace เป็นภาษาง่ายๆ และแนะนำการแก้ (“endpoint นี้คืน 403 เพราะผู้ใช้ทดสอบไม่มีบทบาท”) มันช่วยค้นความไม่ตรงกันระหว่างสิ่งที่เทสต์คาดหวังกับสิ่งที่ API คืนจริง
กรอบคุณภาพที่ทำให้คุณซื่อสัตย์
AI เร่งการสร้างผลงาน แต่ไม่ควรเป็นกลไกความปลอดภัยเดียว รักษากรอบน้ำหนักเบา:\n\n- การตรวจโค้ด (แม้แค่ 10 นาทีจากเพื่อนร่วมงาน)\n- CI ที่รันเทสต์ทุก PR\n- เป้าหมายความคุ้มครองขั้นต่ำสำหรับโมดูลสำคัญ ไม่ใช่ทั้งโค้ดเบส
ขั้นตอนถัดไปที่เป็นประโยชน์: ตั้งโฟลเดอร์ “core flows” สำหรับเทสต์และให้ CI หยุดการ merge เมื่อเทสต์เหล่านั้นล้ม นั่นป้องกันไฟร์ดริลยามดึกได้มาก
อัตโนมัติ DevOps โดยไม่ต้องมีวิศวกร Ops เต็มเวลา
DevOps คือที่ “แค่ปล่อย” มักกลายเป็นคืนยาว: deployment ที่ไม่เสถียร, สภาพแวดล้อมไม่ตรงกัน, และบั๊กลึกลับที่เกิดเฉพาะในโปรดักชัน
เครื่องมือที่ขับเคลื่อนด้วย AI ไม่สามารถแทนการตัดสินใจวิศวกรรมที่ดีได้ทั้งหมด แต่สามารถตัดงานซ้ำๆ ออกไปมาก ซึ่งทำให้ผู้ก่อตั้งเร็วขึ้น
ตั้งค่า CI, linting, และการจัดรูปแบบแบบอัตโนมัติ
กับโค้ดที่ไม่มีเวลาตั้งค่าพื้นฐาน ความสม่ำเสมอจะไม่เกิด AI assistant สามารถสร้างจุดเริ่มต้นที่สะอาดสำหรับ CI (GitHub Actions/GitLab CI), เพิ่ม linting และกฎการจัดรูปแบบ และให้มันรันทุก PR
นั่นแปลว่าการถกเถียงเรื่องสไตล์ลดลง รีวิวเร็วขึ้น และบั๊กเล็กๆ น้อยๆ เข้าสู่ main น้อยลง
pipeline การดีพลอยพร้อมการแยกสภาพแวดล้อม
ผู้ก่อตั้งมัก deploy ตรงสู่ production จนเจ็บ AI ช่วย scaffold pipeline ง่ายๆ ที่รองรับ dev → staging → prod รวมถึง:\n\n- environment variables และความลับแยกตามสภาพแวดล้อม\n- ขั้นตอน build ที่ทำซ้ำได้ (ให้ staging ตรงกับ prod)\n- ขั้นตอนอนุมัติก่อน production\n เป้าหมายไม่ใช่ความซับซ้อน—แต่คือการลดเหตุการณ์ “มันทำงานบนเครื่องฉัน” และทำให้การปล่อยเป็นกิจวัตร
การมอนิเตอริงพื้นฐาน: logs, metrics, และ alerts
คุณไม่ต้องการ setup มอนิเตอริงระดับองค์กรเพื่อปลอดภัย AI สามารถแนะนำ baseline ง่ายๆ:\n\n- logs ที่มีโครงสร้าง (ค้นหาโดย request/user ได้)\n- ตัวชี้วัดหลักบางตัว (อัตราข้อผิดพลาด, latency, ความหนาคิว)\n- แจ้งเตือนเมื่อเกณฑ์ “มีบางอย่างพัง” ถูกแตะ
นี่ช่วยให้คุณมีคำตอบเร็วเมื่อมีลูกค้าแจ้งปัญหา
สิ่งที่ควรทำด้วยมือในช่วงต้นเพื่อลดความเสี่ยง
อัตโนมัติส่วนที่ซ้ำได้ แต่ควบคุมการตัดสินใจที่มีผลสูงด้วยมือ: การเข้าถึง production, การหมุนความลับ, มิเกรชันฐานข้อมูล, และเกณฑ์การแจ้งเตือน AI สามารถร่าง playbook ให้ แต่คุณต้องเป็นเจ้าของว่า “ใครทำอะไรได้” และ “เมื่อไหร่เราดัน"\n
ความปลอดภัยและการปฏิบัติตาม: สิ่งที่ AI ตัดสินใจแทนคุณไม่ได้
ข้ามสัปดาห์การตั้งค่าแบ็กเอนด์
อธิบายผลิตภัณฑ์ของคุณในแชท แล้วได้เว็บแอปและแบ็กเอนด์เป็นฐานทำงานอย่างรวดเร็ว
AI สร้างโค้ดที่ดูปลอดภัยได้และตั้งการป้องกันทั่วไป แต่วิธีการจัดการความปลอดภัยและการปฏิบัติตามเป็นการตัดสินใจเชิงผลิตภัณฑ์ ขึ้นกับสิ่งที่คุณสร้าง ผู้ใช้เป็นใคร และความเสี่ยงที่คุณยินยอมรับ
ถือว่า AI เป็นตัวเร่ง ไม่ใช่เจ้าของความปลอดภัยของคุณ
พื้นฐานความปลอดภัยที่คุณยังต้องรับผิดชอบ
การจัดการความลับ เป็นความรับผิดชอบของผู้ก่อตั้ง คีย์ API, ข้อมูลประจำตัวฐานข้อมูล, คีย์ลงนาม JWT, และความลับ webhook ไม่ควรอยู่ในซอร์สโค้ดหรือบันทึกแชท ใช้ environment variables และที่เก็บความลับที่จัดการโดยผู้ให้บริการเมื่อเป็นไปได้ และหมุนคีย์เมื่อคนออกหรือสงสัยว่ารั่ว
หลักการสิทธิ์น้อยที่สุด (least privilege) คืออีกเรื่องที่ไม่ต่อรองได้ AI อาจ scaffold บทบาทและนโยบาย แต่คุณต้องตัดสินว่าใครควรเข้าถึงอะไร กฎง่ายๆ: ถ้าบริการหรือผู้ใช้ไม่ต้องการสิทธิ์ อย่าให้ สิ่งนี้ใช้กับ:\n\n- บัญชีฐานข้อมูล (อ่าน vs เขียน)\n- บริการคลาวด์ (storage, email, queues)\n- แผงผู้ดูแล (หลีกเลี่ยง “ทุกคนเป็น admin” ในโปรดักชัน)
การจัดการข้อมูลส่วนบุคคล (PII) และการตัดสินใจเรื่องการเข้าถึง
ถ้าคุณเก็บข้อมูลส่วนบุคคล (อีเมล, เบอร์โทร, ที่อยู่, ตัวระบุการชำระเงิน, ข้อมูลสุขภาพ) การปฏิบัติตามไม่ใช่การติ๊กถูก—มันกำหนดสถาปัตยกรรมของคุณ
ในภาพรวม ให้กำหนด:\n\n- อะไรถือเป็น PII ในแอปของคุณ และเก็บที่ไหน\n- ใครดู/ส่งออกได้ (ทีมซัพพอร์ต, แอดมิน, ผู้ใช้ปลายทาง)\n- มันถูกบันทึกอย่างไร (หลีกเลี่ยงการพิมพ์ PII ในล็อกและตัวติดตามข้อผิดพลาด)\n- กฎการเก็บข้อมูล (เมื่อคุณลบข้อมูล และอย่างไร)\n AI ช่วย implement การควบคุมการเข้าถึงข้อมูล แต่ไม่สามารถบอกได้ว่าอะไร “เหมาะสม” สำหรับผู้ใช้ของคุณหรือกฎระเบียบที่ตลาดของคุณต้องปฏิบัติตาม
การสแกน dependency และช่องโหว่
แบ็กเอนด์สมัยใหม่พึ่งพาแพ็กเกจ, คอนเทนเนอร์, และบริการภายนอก ทำให้การตรวจหาช่องโหว่เป็นกิจวัตร:\n\n- เปิดการแจ้งเตือน dependency ในรีโปของคุณ\n- สแกนอิมเมจคอนเทนเนอร์ใน CI\n- แพทช์เป็นประจำ โดยเฉพาะไลบรารี auth และ crypto
คำเตือนชัดเจนหนึ่งข้อ
อย่า deploy โค้ดแบ็กเอนด์ที่สร้างโดย AI โดยไม่ให้มนุษย์ตรวจทาน ตรวจสอบฟลูว์การยืนยันตัวตน, การตรวจสิทธิ์, การตรวจอินพุต, และโค้ดที่แตะเงินหรือ PII ก่อนขึ้นโปรดักชัน
การแลกเปลี่ยน ความปลอดภัย และเมื่อไหร่ควรลงลึก
AI backend abstraction อาจรู้สึกเหมือนเวทมนตร์—จนกว่าจะเจอขอบ เมื่อถึงจุดนั้น เป้าหมายไม่ใช่หลีกเลี่ยงวิศวกรรมจริงตลอดไป แต่นำส่วนที่แพงออกไปจนกว่าจะมี traction พอ
ความเสี่ยงจริงที่ต้องจับตามอง
การล็อกกับผู้ให้บริการ (vendor lock-in) ชัดเจน: ถ้าสคีมา, auth, และเวิร์กโฟลว์ผูกกับ convention ของแพลตฟอร์มหนึ่ง การย้ายทีหลังอาจมีค่าใช้จ่ายสูง
สถาปัตยกรรมไม่ชัดเจน เสียงเบากว่า: เมื่อ AI สร้างบริการ นโยบาย และการเชื่อมต่อ ทีมบางครั้งอธิบายไม่ได้ว่า request ไหลอย่างไร, ข้อมูลถูกเก็บที่ไหน, หรือเกิดอะไรเมื่อล้มเหลว
ความซับซ้อนที่ซ่อนอยู่ ปรากฏตอนสเกล, ตรวจสอบ, หรือกรณีขอบ—rate limits, retries, idempotency, สิทธิ์, และมิเกรชันไม่หายไป; แค่รอเวลา
กรอบป้องกันที่ทำให้คุณปลอดภัย (และเร็ว)
เก็บ “ทางหนี” ตั้งแต่วันแรก:\n\n- ข้อมูลพกพา: แน่ใจว่าคุณส่งออกตาราง/คอลเลกชันและไฟล์ดิบได้ตามต้องการ\n- API ที่มีเอกสาร: ปฏิบัติต่อ API เป็นสัญญาผลิตภัณฑ์—จด endpoints, กฎ auth, และกรณีข้อผิดพลาดสำคัญ\n- เป็นเจ้าของ domain model: แม้ AI จะ scaffold มัน คุณก็ต้องตัดสินชื่อนิยามความสัมพันธ์ และอะไรคือแหล่งความจริง
ถ้าคุณใช้แพลตฟอร์มที่เน้น AI ให้เลือกฟีเจอร์ที่ทำให้กรอบป้องกันเหล่านี้ใช้งานได้จริง—เช่นการส่งออกซอร์สโค้ด, การควบคุมการโฮสต์/ดีพลอย, และสแนปช็อต/ย้อนกลับเมื่อการเปลี่ยนแปลงอัตโนมัติผิดพลาด (Koder.ai, ตัวอย่าง, รองรับการส่งออกโค้ดและสแนปช็อตเพื่อช่วยทีมขยับเร็วและมีทางหนี)
นิสัยง่ายๆ ที่ช่วยได้: เขียน “แผนที่แบ็กเอนด์” สั้นๆ ทุกสัปดาห์ (มีบริการอะไรบ้าง, แตะอะไรบ้าง, และรันโลคัลอย่างไร)
เมื่อไหร่ควรดึงวิศวกรหรือที่ปรึกษา
ทำเมื่อเหตุใดเหตุหนึ่งเป็นจริง: คุณจัดการการชำระเงินหรือข้อมูลที่อ่อนไหว, เวลาทำงานเริ่มมีผลต่อรายได้, คุณต้องการสิทธิ์ที่ซับซ้อน, มิเกรชันบ่อย, หรือปัญหาด้านประสิทธิภาพเกิดซ้ำ
ขั้นตอนที่เป็นรูปธรรมถัดไป
เริ่มเล็ก: กำหนดเอนทิตีหลัก, ลิสต์การเชื่อมต่อที่ต้องการ, และตัดสินว่าสิ่งใดต้องตรวจสอบได้ จากนั้นเปรียบเทียบตัวเลือกและระดับการสนับสนุนบน /pricing และขุดเข้าไปในไกด์เชิงปฏิบัติและตัวอย่างใน /blog.
คำถามที่พบบ่อย
What does “backend complexity” actually include for an early-stage product?
ความซับซ้อนของแบ็กเอนด์คืองาน “มองไม่เห็น” ที่ทำให้ผลิตภัณฑ์ดูเรียบง่าย: การเก็บข้อมูลอย่างปลอดภัย, API, การรับรองตัวตน, อีเมล, การชำระเงิน, งานแบ็กกราวนด์, การดีพลอย และการมอนิเตอริง มันช้าในช่วงต้นเพราะต้องจ่ายต้นทุนการตั้งค่าก่อนที่ผู้ใช้จะเห็นคุณค่า—และการตัดสินใจผลิตภัณฑ์เล็กๆ สามารถลามไปสู่การเปลี่ยนแปลงสคีมา, สิทธิ์, API และการมิเกรชันได้
What does it mean for AI to “abstract away” backend work in practice?
โดยหลักแล้วมันหมายถึงคุณอธิบายผลลัพธ์ที่ต้องการ (เช่น “ผู้ใช้สมัครได้”, “เก็บคำสั่งซื้อ”, “ส่ง webhook เมื่อชำระเงิน”) แล้วเครื่องมือจะสร้างส่วนที่ซ้ำซ้อนให้:
- endpoints CRUD + การตรวจสอบอินพุต
- โมเดลข้อมูลเริ่มต้นและมิเกรชัน
- โฟลว์การยืนยันตัวตนและโครงสิทธิ์
- โค้ดเชื่อมต่อ (อีเมล, การชำระเงิน, การวิเคราะห์)
คุณยังต้องตรวจทานและเป็นเจ้าของพฤติกรรมสุดท้าย แต่คุณจะเริ่มจากฐานที่ใช้งานได้แทนที่จะเริ่มจากรีโปเปล่า
What are realistic expectations—what won’t AI backend abstraction do?
AI ไม่ได้ตัดสินใจด้านผลิตภัณฑ์และความเสี่ยงให้คุณ มันจะไม่สรุปได้อย่างน่าเชื่อถือ:
- กฎธุรกิจและกรณีขอบที่แน่นอนของคุณ
- ความหมายของ “ปลอดภัยพอ” สำหรับโดเมนของคุณ
- การจัดการเรื่องเงิน, ความพร้อมกัน (concurrency) และสิทธิ์อย่างถูกต้องโดยอัตโนมัติ
- การตัดสินใจสถาปัตยกรรมระยะยาวเมื่อความต้องการไม่ชัดเจน
ถือว่าเอาต์พุตของ AI เป็นฉบับร่างที่ต้องตรวจทาน ทดสอบ และมีความต้องการชัดเจน
How do I write prompts that produce usable backend scaffolds instead of vague code?
เขียนพรอมป์เหมือนสเปคย่อที่มีสัญญา (contract) ชัดเจน รวมถึง:
- เอนทิตีและฟิลด์สำคัญ (เช่น
Order: status, total, userId) - endpoints ที่ต้องการและตัวอย่าง (request/response)
- กฎการตรวจสอบและกรณีข้อผิดพลาด
- สิทธิ์ (ใครทำอะไรได้บ้าง)
- ความต้องการนอกหน้าที่หลัก (pagination, audit fields, idempotency)
ยิ่งชัดเจน ยิ่งได้โครงที่ใช้งานได้จริงมากขึ้น
Can AI help with data modeling if I’m not a database expert?
ใช้ AI เพื่อ draft schema ฉบับแรกที่คุณจะตอบกลับ แล้วปรับตามความต้องการ MVP:
- เริ่มจากเอนทิตีหลักและความสัมพันธ์ (one-to-many vs many-to-many)
- ขอให้สร้างมิเกรชันและ seed data สำหรับพัฒนาโลคัล
- ตรวจสอบดัชนี (indexes), foreign keys, และขั้นตอนมิเกรชันที่ทำลายข้อมูล
- รักษาการตั้งชื่อให้สอดคล้องระหว่าง DB, payloads ของ API และโค้ด
ตั้งเป้าออกแบบเพื่อพิสูจน์สมมติฐานของ MVP ก่อน ไม่ต้อง over-design ตั้งแต่วันแรก
How can AI help speed up authentication and authorization without creating security holes?
AI สามารถสร้างโฟลว์ล็อกอินมาตรฐานได้เร็ว (email/password, OAuth, invite) แต่คุณต้องตรวจสอบความปลอดภัยและความถูกต้องของการอนุญาตด้วยตัวเอง
เช็คลิสต์ด่วน:
How does AI help with integrations and webhooks like Stripe without causing double-charges or missed events?
การเชื่อมต่อกับบริการภายนอกช้าเพราะต้องจัดการ retries, timeouts, idempotency, การตรวจสอบลายเซ็น และรูปแบบข้อมูลที่ต่างกัน
AI ช่วยโดย scaffold:
- HTTP client ร่วมและเทมเพลต environment variables
- endpoints สำหรับ webhook พร้อมการตรวจสอบลายเซ็น
- การประมวลผลแบบ idempotent (เก็บ event ID และละเว้นรายการซ้ำ)
- เหตุการณ์ภายใน (เช่น
PaymentSucceeded) เพื่อจัดระเบียบโค้ด
แต่ยังต้องทดสอบในสเตจจิงด้วยคีย์ sandbox และ replay payload ของ webhook จริงก่อนใช้งานจริง
How can AI help keep API design aligned with the product as it changes?
ปฏิบัติต่อ API เป็นสัญญาที่มีชีวิตและรักษาความสอดคล้องหน้า frontend/back-end:
- ขอให้ AI ร่างรายการ endpoints พร้อมตัวอย่าง request/response
- เก็บ OpenAPI spec และสร้างตัวตรวจสอบ/ไคลเอนต์จากมัน
- ใช้ DTO ที่มีชนิดข้อมูล (typed) เพื่อป้องกันการลื่นไหลของฟิลด์
- เปลี่ยนแปลงแบบ additive เมื่อเป็นไปได้; versioning หรือ deprecate การเปลี่ยนแปลงที่ทำลายความเข้ากันได้
วิธีนี้ลดการเผชิญหน้าและปัญหาเรื่องรูปแบบข้อมูลที่ต่างกัน
How do I use AI to accelerate testing and debugging without skipping quality?
ใช้ AI เพื่อร่างชุดทดสอบสำหรับเส้นทางหลักแทนการไล่ครอบคลุมทุกอย่าง:
- ทดสอบเส้นทางปกติ (happy path) เช่น sign-up, checkout, สร้างบันทึก, เชิญเพื่อนร่วมงาน
- กรณีขอบที่สำคัญเล็กน้อย (input ผิด, สิทธิ์ไม่พอ, คำขอซ้ำ)
- fixtures ที่สมจริง (สมาชิกหมดอายุ, โครงการที่ถูกเก็บ, ผู้ใช้ถูกล็อก)
- AI ช่วยเป็นพาร์ทเนอร์ในการดีบัก: สรุปล็อก, แปล stack trace เป็นภาษาง่ายๆ และแนะนำสาเหตุที่เป็นไปได้
ผสานกับ CI ที่บล็อกการ merge เมื่อทดสอบชุดหลักล้มเหลว
What guardrails should founders keep when adopting AI-assisted backend abstraction?
ใช้ AI อัตโนมัติเพื่อเล่นงานซ้ำๆ แต่ปล่อยให้คนเป็นผู้ตัดสินใจในงานที่มีผลกระทบสูง
สิ่งที่ควรอัตโนมัติได้ดี:
- Pipeline CI, linting, และการจัดรูปแบบโค้ด
- การแยกสภาพแวดล้อม dev/staging/prod
- การมอนิเตอริงขั้นต่ำ: logs ที่มีโครงสร้าง, ตัวชี้วัดพื้นฐาน, แจ้งเตือน
ควรควบคุมด้วยมือสำหรับ: