15 มิ.ย. 2568·4 นาที
ให้ AI ออกแบบสคีมา แบ็กเอนด์, API และแบบจำลองข้อมูล
สำรวจว่าการสร้างสคีมาและ API โดย AI ช่วยเร่งการส่งมอบได้อย่างไร จุดที่ล้มเหลว และเวิร์กโฟลว์ปฏิบัติได้สำหรับการทบทวน ทดสอบ และการกำกับดูแลการออกแบบแบ็กเอนด์
สำรวจว่าการสร้างสคีมาและ API โดย AI ช่วยเร่งการส่งมอบได้อย่างไร จุดที่ล้มเหลว และเวิร์กโฟลว์ปฏิบัติได้สำหรับการทบทวน ทดสอบ และการกำกับดูแลการออกแบบแบ็กเอนด์
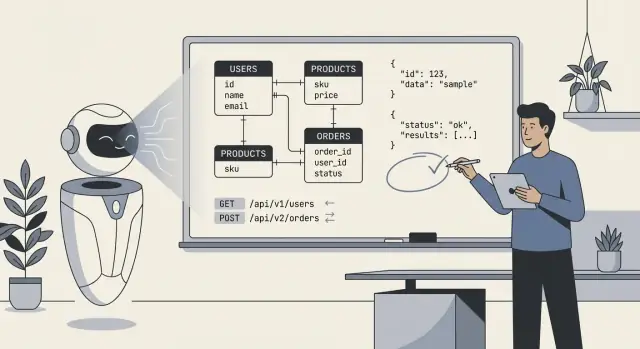
เมื่อคนพูดว่า “AI ออกแบบแบ็กเอนด์ของเรา” ส่วนใหญ่หมายถึงโมเดลสร้างร่างแรกของพิมพ์เขียวทางเทคนิคหลัก: ตารางฐานข้อมูล (หรือคอลเลกชัน), ความสัมพันธ์ระหว่างส่วนต่าง ๆ และ API ที่อ่าน/เขียนข้อมูล ในปฏิบัติจริง มันคือไม่ใช่ "AI สร้างทุกอย่าง" แต่เป็น "AI เสนอโครงสร้างให้เรานำไปใช้งานและปรับปรุงต่อ"\
อย่างน้อย AI สามารถสร้าง:
users, orders, subscriptions พร้อมฟิลด์และชนิดพื้นฐานAI อาจอนุมานรูปแบบ "ทั่วไป" ได้ แต่ไม่สามารถเลือกโมเดลที่ ถูกต้องที่สุด เมื่อความต้องการไม่ชัดเจนหรือเฉพาะทาง มันจะไม่รู้เกี่ยวกับนโยบายจริงของคุณสำหรับ:
cancelled เทียบกับ refunded เทียบกับ voided)มองผลลัพธ์จาก AI เป็นจุดเริ่มต้นที่มีโครงสร้างและรวดเร็ว—มีประโยชน์สำหรับการสำรวจตัวเลือกและจับสิ่งที่ขาดหาย—แต่ไม่ใช่สเปกที่คุณควรส่งขึ้น production ทันที งานของคุณคือมอบกฎชัดเจนและกรณีมุม แล้วตรวจทานสิ่งที่ AI ผลิต เหมือนกับการตรวจร่างแรกของวิศวกรจูเนียร์: ให้ประโยชน์ บางครั้งน่าประทับใจ แต่บางครั้งผิดพลาดในวิธีที่ละเอียดอ่อน
AI สามารถร่างสคีมาหรือ API ได้อย่างรวดเร็ว แต่ไม่สามารถคิดข้อมูลที่ขาดหายซึ่งทำให้แบ็กเอนด์ “เหมาะ” กับผลิตภัณฑ์ของคุณ ผลลัพธ์ที่ดีที่สุดเกิดขึ้นเมื่อคุณปฏิบัติต่อ AI เหมือนนักออกแบบจูเนียร์: ให้ข้อจำกัดชัดเจน แล้วมันจะเสนอตัวเลือก
ก่อนขอให้สร้างตาราง จุดสิ้นสุด หรือโมเดล ให้เขียนสิ่งจำเป็นไว้ก่อน:
เมื่อความต้องการไม่ชัดเจน AI มักจะ "เดา" ค่าดีฟอลต์: ฟิลด์เป็นทางเลือกเกือบทุกที่, คอลัมน์สถานะทั่วไป, ความเป็นเจ้าของไม่ชัดเจน, และการตั้งชื่อลูกผีสิง สิ่งนี้นำไปสู่สคีมาที่ดูสมเหตุสมผลแต่พังเมื่อเจอสถานการณ์จริง โดยเฉพาะเรื่องสิทธิ์ รายงาน และกรณีมุม คุณจะจ่ายค่าความยุ่งยากนั้นในภายหลังด้วยมิเกรชัน การแก้ทาง และ API ที่ทำให้สับสน
ใช้เริ่มต้นนี้แล้ววางในพรอมต์ของคุณ:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
AI ดีที่สุดเมื่อคุณใช้มันเป็นเครื่องมือร่างเร็ว: มันสามารถสเก็ตช์โมเดลข้อมูลคร่าว ๆ และชุด endpoints ที่เข้ากันได้ในไม่กี่นาที ความเร็วนี้เปลี่ยนวิธีทำงานของคุณ—ไม่ใช่เพราะผลลัพธ์ถูกต้องเสมอไป แต่เพราะคุณสามารถทำซ้ำจากสิ่งที่รูปธรรมได้ทันที
ข้อได้เปรียบใหญ่ที่สุดคือขจัดความว่างเปล่า เริ่มด้วยคำอธิบายสั้น ๆ ของเอนทิตี เวิร์กโฟลว์หลัก และข้อจำกัด แล้ว AI สามารถเสนอ ตาราง/คอลเลกชัน ความสัมพันธ์ และพื้นฐานของ API ได้อย่างรวดเร็ว เหมาะกับการทำเดโมหรือตรวจสอบไอเดียที่ยังไม่มั่นคง
ความเร็วนี้เหมาะกับ:
มนุษย์เหนื่อยและเบี่ยงเบน แต่ AI ไม่เป็น ดังนั้นมันเหมาะสำหรับการทำมาตรฐานซ้ำ ๆ ทั่วทั้งแบ็กเอนด์:
createdAt, updatedAt, customerId)/resources, /resources/:id) และ payload ที่สอดคล้องความสอดคล้องนี้ทำให้แบ็กเอนด์ของคุณง่ายต่อการเอกสาร ทดสอบ และส่งต่อ
AI มักจะช่วยให้ครบถ้วน หากขอชุด CRUD ทั้งหมดและการดำเนินการทั่วไป (ค้นหา, รายการ, อัปเดตแบบกลุ่ม) มันมักสร้างพื้นผิวเริ่มต้นที่ครอบคลุมกว่าร่างที่รีบ ๆ โดยคน
ตัวอย่างที่ได้เร็วคือข้อผิดพลาดมาตรฐาน: รูปร่างข้อผิดพลาดเดียว (code, message, details) ทั่วทุก endpoint แม้จะปรับปรุงภายหลัง แต่การมีรูปแบบเดียวตั้งแต่ต้นป้องกันการผสมผสานที่ยุ่งเหยิง
แนวคิดสำคัญ: ให้ AI ผลิต 80% แรกอย่างรวดเร็ว แล้วใช้เวลาใน 20% ที่ต้องการการตัดสินใจ—กฎธุรกิจ กรณีมุม และเหตุผลเบื้องหลังโมเดล
สคีมาที่สร้างโดย AI มักดู "สะอาด" เมื่อมองครั้งแรก: ตารางเป็นระเบียบ ชื่อสมเหตุสมผล และความสัมพันธ์สอดคล้องกับเส้นทางที่คาดหวัง ปัญหามักเกิดเมื่อข้อมูลจริง ผู้ใช้จริง และเวิร์กโฟลว์จริงเข้ามาใช้งานระบบ
AI อาจไปสุดทางทั้งสองด้าน:
การทดสอบกลิ่นด่วน: ถ้าหน้าส่วนใหญ่ต้องการ join 6 ครั้งขึ้นไป คุณอาจ over-normalized; ถ้าการอัปเดตต้องเปลี่ยนค่าตัวเดียวในหลายแถว แสดงว่า under-normalized
AI มักละเลยข้อกำหนด "น่าเบื่อ" ที่มีผลต่อการออกแบบแบ็กเอนด์จริง:
tenant_id บนตาราง หรือตรวจไม่พบการบังคับขอบเขต tenant ในข้อจำกัด uniquenessdeleted_at แต่ไม่ปรับกฎ uniqueness หรือรูปแบบคิวรีให้ไม่รวมแถวที่ลบแล้วcreated_by/updated_by, ประวัติการเปลี่ยนแปลง, หรือบันทึกเหตุการณ์ที่ไม่เปลี่ยนแปลงdate และ timestamp โดยไม่มีนโยบายชัดเจน (เก็บเป็น UTC หรือเก็บเป็นเวลาท้องถิ่น) ทำให้เกิดบั๊กเลื่อนวันAI อาจเดาว่า:
ข้อผิดพลาดเหล่านี้มักปรากฏผ่านมิเกรชันที่ยุ่งยากและการแก้ทางในแอป
สคีมาที่สร้างมามักไม่สะท้อน "วิธีที่คุณจะคิวรี":
tenant_id + created_at)ถ้าโมเดลอธิบายไม่ได้ว่า 5 คิวรีหลักของแอปคืออะไร มันไม่สามารถออกแบบสคีมาให้รองรับคิวรีเหล่านั้นได้เชื่อถือได้
AI มักทำ API ที่ดูเป็นมาตรฐานได้ดี มันจะเลียนแบบรูปแบบจากเฟรมเวิร์กและ API สาธารณะ ซึ่งช่วยประหยัดเวลา แต่ความเสี่ยงคือมันอาจเลือกสิ่งที่ดูเป็นไปได้มากกว่าสิ่งที่ถูกต้องสำหรับผลิตภัณฑ์ของคุณ ข้อมูล และการเปลี่ยนแปลงในอนาคต
พื้นฐานการจำลองทรัพยากร. เมื่อโดเมนชัดเจน AI มักเลือกคำนามและโครงสร้าง URL ที่สมเหตุสมผล (เช่น /customers, /orders/{id}, /orders/{id}/items) และรักษาความสอดคล้องของการตั้งชื่อ
โครงร่าง endpoint พื้นฐาน. AI มักรวมสิ่งจำเป็น: list vs detail, create/update/delete และรูปแบบ request/response ที่คาดเดาได้
ธรรมเนียมพื้นฐาน. ถ้าคุณบอกให้ชัด มันสามารถทำให้ pagination, filtering, sorting เป็นมาตรฐาน เช่น ?limit=50&cursor=... (cursor pagination) หรือ ?page=2&pageSize=25 (page-based) พร้อม ?sort=-createdAt และตัวกรองอย่าง ?status=active
การเปิดเผยรายละเอียดการออกแบบภายใน (leaky abstractions). ข้อผิดพลาดคลาสสิกคือการเปิดเผยตารางภายในเป็น "resources" โดยตรง โดยเฉพาะเมื่อสคีมามี join tables, ฟิลด์ denormalized, หรือคอลัมน์ audit คุณจะพบ endpoints อย่าง /user_role_assignments ซึ่งสะท้อนรายละเอียดการ implement มากกว่าคอนเซ็ปต์ที่ผู้ใช้ต้องการ (เช่น “roles for a user”) ทำให้ API ยากต่อการใช้งานและเปลี่ยนแปลงในอนาคต
การจัดการข้อผิดพลาดไม่สอดคล้อง. AI อาจผสมสไตล์: คืน 200 พร้อม body ที่เป็น error บางครั้ง และใช้ 4xx/5xx บางครั้ง คุณควรกำหนดสัญญาชัดเจน:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })การเวอร์ชันเป็นของรอง. การออกแบบที่สร้างโดย AI หลายครั้งข้ามกลยุทธ์การเวอร์ชันจนกลายเป็นปัญหา ให้ตัดสินใจตั้งแต่วันแรกว่าจะใช้ path versioning (/v1/...) หรือ header-based และนิยามว่าอะไรคือการเปลี่ยนแปลงที่ทำให้เกิด breaking change การมีกฎนี้แม้ไม่เคยเปลี่ยนเวอร์ชัน ก็ป้องกันการเปลี่ยนแปลงที่ไม่ตั้งใจ
ใช้ AI เพื่อความเร็วและความสอดคล้อง แต่ปฏิบัติต่อการออกแบบ API เป็นอินเทอร์เฟซของผลิตภัณฑ์ ถ้า endpoint สะท้อนฐานข้อมูลแทนความคิดของผู้ใช้ นั่นคือสัญญาณว่า AI เลือกวิธีที่ง่ายในการสร้าง มากกว่าจะคิดเพื่อการใช้งานระยะยาว
ปฏิบัติต่อ AI เป็นนักออกแบบจูเนียร์ที่เร็ว: ดีในการสร้างร่าง แต่ไม่รับผิดชอบระบบสุดท้าย เป้าหมายคือใช้ความเร็วของมันพร้อมกับทำให้สถาปัตยกรรมมีเจตนา ตรวจสอบได้ และขับเคลื่อนด้วยการทดสอบ
ถ้าคุณใช้เครื่องมือ vibe-coding เช่น Koder.ai การแยกขอบเขตความรับผิดชอบนี้ยิ่งสำคัญ: แพลตฟอร์มสามารถร่างและนำไปใช้งานแบ็กเอนด์ได้อย่างรวดเร็ว (เช่น บริการ Go กับ PostgreSQL) แต่คุณยังต้องนิยาม invariants, ขอบเขตการอนุญาต (authorization), และกฎมิเกรชันที่ยอมรับได้
เริ่มด้วยพรอมต์ที่กระชับ บรรยายโดเมน ข้อจำกัด และ "ความสำเร็จคืออะไร" ขอ แบบจำลองเชิงแนวความคิดก่อน (entities, relationships, invariants) ไม่ใช่ตาราง
แล้วทำซ้ำตามลูป:
ลูปนี้ได้ผลเพราะเปลี่ยน "คำแนะนำจาก AI" ให้เป็น artifacts ที่พิสูจน์หรือปฏิเสธได้
เก็บสามชั้นให้แตกต่าง:
ขอให้ AI แยกส่วนเหล่านี้เป็นส่วน ๆ เมื่อมีการเปลี่ยนแปลง อัปเดตแบบจำลองเชิงแนวคิดก่อน แล้วจึงปรับสคีมาและ API ตาม ลดการผูกมัดโดยไม่ได้ตั้งใจและทำให้การรีแฟกเตอร์น้อยผลกระทบ
ทุกการวนรอบควร留下ร่องรอย ใช้สรุปแบบ ADR สั้น ๆ (หน้าเดียวหรือน้อยกว่า) ที่บันทึก:
deleted_at”)เมื่อคุณนำข้อคิดเห็นกลับไปให้ AI ให้แนบบันทึกการตัดสินใจที่เกี่ยวข้องแบบ verbatim เพื่อป้องกันไม่ให้โมเดล "ลืม" ตัวเลือกก่อนหน้าและช่วยให้ทีมเข้าใจเหตุผลในอีกหลายเดือนต่อมา
AI ควบคุมได้ง่ายที่สุดเมื่อคุณปฏิบัติต่อพรอมต์เหมือนการเขียนสเปก: นิยามโดเมน ระบุข้อจำกัด และยืนยันผลลัพธ์ที่เป็นรูปธรรม (DDL, ตาราง endpoint, ตัวอย่าง) เป้าหมายไม่ใช่ "สร้างสรรค์" แต่คือ "แม่นยำ"
ขอโมเดลข้อมูล และ กฎที่ทำให้มันสอดคล้อง
ถ้าคุณมีคอนเวนชันอยู่แล้ว ให้บอก: สไตล์การตั้งชื่อ, ชนิด ID (UUID vs bigint), นโยบาย nullable, และความคาดหวังการทำดัชนี
ขอเป็นตาราง API ที่มีสัญญาชัดเจน ไม่ใช่แค่รายการเส้นทาง
เพิ่มพฤติกรรมธุรกิจ: สไตล์ pagination, ฟิลด์ที่อนุญาตให้เรียง, และวิธีกรอง
ให้โมเดลคิดเป็นรุ่นปล่อย
billing_address to Customer. Provide a safe migration plan: forward migration SQL, backfill steps, feature-flag rollout, and a rollback strategy. API must remain compatible for 30 days; old clients may omit the field.”พรอมต์กว้างจะให้ระบบกว้างเกินไป:
เมื่อคุณต้องการผลลัพธ์ที่ดีกว่า ให้ทำพรอมต์ให้แคบ: ระบุ กฎ, กรณีมุม, และ รูปแบบผลลัพธ์
AI อาจร่างแบ็กเอนด์ได้ดี แต่การปล่อยใช้งานอย่างปลอดภัยยังต้องผ่านการทบทวนของคน ใช้เช็คลิสต์นี้เป็น "ประตูการปล่อย": หากคุณตอบข้อใดข้อหนึ่งไม่ได้อย่างมั่นใจ ให้หยุดและแก้ก่อนเดี๋ยวนั้น
(tenant_id, slug))ยืนยันกฎของระบบเป็นลายลักษณ์อักษร:
ก่อน merge ให้ทดสอบสั้น ๆ “happy path + worst path”: คำขอปกติหนึ่งรายการ, คำขอไม่ถูกต้องหนึ่งรายการ, คำขอที่ไม่ได้รับอนุญาตหนึ่งรายการ, สถานการณ์ที่มีปริมาณสูงหนึ่งรายการ หากพฤติกรรม API ทำให้คุณแปลกใจ มันจะทำให้ผู้ใช้ของคุณแปลกใจด้วย
AI สามารถสร้างสคีมาและพื้นผิว API ได้อย่างรวดเร็ว แต่มันพิสูจน์ไม่ได้ว่าระบบทำงานถูกต้องภายใต้ทราฟฟิกจริง ข้อมูลจริง และการเปลี่ยนแปลงในอนาคต ให้ยึดผลลัพธ์ของ AI เป็นร่างและหนุนด้วยการทดสอบที่ล็อกพฤติกรรม
เริ่มด้วย contract tests ที่ตรวจคำขอ การตอบกลับ และข้อผิดพลาด — ไม่ใช่แค่ “happy paths” ให้ชุดเล็ก ๆ ที่รันต่อ instance จริง (หรือคอนเทนเนอร์)
โฟกัสที่:
ถ้าคุณเผยแพร่สเปก OpenAPI ให้สร้างการทดสอบจากสเปกนั้น—แต่เพิ่มเคสที่เขียนมือสำหรับส่วนยากที่สเปกอาจอธิบายไม่ได้ (กฎอนุญาต การจำกัดธุรกิจ)
สคีมาที่สร้างมามักขาดรายละเอียดเชิงปฏิบัติ: ค่าดีฟอลต์ที่ปลอดภัย, backfills, และความย้อนกลับ เพิ่มการทดสอบมิเกรชันที่:
เก็บแผน rollback แบบสคริปต์สำหรับ production: ทำอย่างไรถ้ามิเกรชันช้า, ล็อกตาราง, หรือทำให้ความเข้ากันไม่ได้
อย่าเบนช์มาร์กแค่ endpoint ธรรมดา จับ pattern การคิวรีตัวแทน (รายการยอดนิยม, ค้นหา, join, การรวม) แล้วโหลดทดสอบพวกนี้
วัด:
นี่คือจุดที่การออกแบบของ AI มักพัง: ตารางที่ดู "สมเหตุสมผล" แต่ก่อให้เกิด joins หนักภายใต้ภาระ
เพิ่มการตรวจอัตโนมัติสำหรับ:
แม้แต่การทดสอบความปลอดภัยพื้นฐานก็ป้องกันความผิดพลาดหนัก ๆ ของ AI: endpoints ที่ใช้งานได้แต่เปิดเผยข้อมูลเกินความจำเป็น
AI อาจร่างสคีมา "รุ่น 0" ได้ดี แต่แบ็กเอนด์ของคุณจะมีชีวิตจนถึงรุ่น 50 ความแตกต่างระหว่างระบบที่อยู่รอดได้ดีและระบบที่ยุบตัวคือวิธีที่คุณวิวัฒนาการมัน: มิเกรชัน การรีแฟกเตอร์ที่ควบคุมได้ และเอกสารเจตนา
ปฏิบัติทุกรายการเปลี่ยนสคีมาเหมือนมิเกรชัน แม้ AI จะบอกว่า "alter table" ให้ใช้ขั้นตอนชัดเจนและย้อนกลับได้: เพิ่มคอลัมน์ใหม่ก่อน, backfill, แล้วค่อยบังคับข้อจำกัด ชอบการเปลี่ยนแปลงเชิงเพิ่ม (เพิ่มฟิลด์, ตารางใหม่) แทนการทำลาย (rename/drop) จนกว่าจะแน่ใจว่าไม่มีอะไรขึ้นอยู่กับรูปแบบเก่า
เมื่อขอ AI อัปเดตสคีมา ให้แนบสคีมาปัจจุบันและกฎมิเกรชันที่คุณทำตาม (เช่น: "ไม่ลบคอลัมน์; ใช้ expand/contract") เพื่อลดโอกาสที่มันจะเสนอการเปลี่ยนแปลงที่เสี่ยงใน production
การเปลี่ยนแปลงที่ทำให้แตกต่างมักไม่ใช่เหตุการณ์เดียว แต่เป็นการเปลี่ยนผ่าน
AI ช่วยเสนอแผนทีละขั้นตอน (รวม SQL snippet และลำดับการเปิดตัว) แต่คุณต้องตรวจผลกระทบตอนรัน: ล็อก, ธุรกรรมยาว, และว่า backfill หยุดแล้วทำต่อได้หรือไม่
รีแฟกเตอร์ควรพยายามแยกการเปลี่ยนแปลง ถ้าต้อง normalize, แยกตาราง, หรือนำ event log มาใช้ ให้รักษา compatibility layers: views, โค้ดแปลความ, หรือ "shadow" tables ขอให้ AI เสนอการรีแฟกเตอร์ที่ยังคงสัญญา API เดิม และระบุสิ่งที่จะเปลี่ยนในคิวรี ดัชนี และข้อจำกัด
การลืมเจตนาเดิมคือสาเหตุของการเบี่ยงเบนระยะยาว เก็บเอกสารสั้น ๆ "data model contract": กฎการตั้งชื่อ, กลยุทธ์ ID, ความหมาย timestamp, นโยบาย soft-delete, และ invariants (เช่น “ยอดคำสั่งเป็นค่าที่คำนวณ ไม่ใช่ค่าที่เก็บ”) แนบไว้ในเอกสารภายในและใช้ซ้ำในพรอมต์ AI ในอนาคตเพื่อให้การออกแบบอยู่ในกรอบเดียวกัน
AI อาจร่างตารางและ endpoints ได้เร็ว แต่มันไม่รับความเสี่ยงของคุณ ให้ถือความปลอดภัยและความเป็นส่วนตัวเป็นข้อกำหนดชั้นหนึ่งที่ใส่ลงในพรอมต์ แล้วยืนยันในการรีวิว โดยเฉพาะรอบข้อมูลที่อ่อนไหว
ก่อนยอมรับสคีมา ให้ติดป้ายฟิลด์ตามความอ่อนไหว (public, internal, confidential, regulated) การจัดหมวดหมู่นี้จะกำหนดว่าจะเข้ารหัส บดบัง หรือเก็บสิ่งใด เมื่อจำเป็น ตัวอย่าง: รหัสผ่านไม่ควรถูกเก็บเป็นข้อความ (เก็บเฉพาะ salted hashes), โทเคนควรมีอายุสั้นและเข้ารหัสที่เก็บ, และ PII เช่น อีเมล/โทรศัพท์อาจต้องถูกปกปิดในมุมมองแอดมินและการส่งออก หากฟิลด์ไม่จำเป็นเพื่อคุณค่าเชิงผลิตภัณฑ์ อย่าเก็บ — AI มักเพิ่มฟิลด์ "น่าใส่" ที่เพิ่มพื้นที่เสี่ยง
API ที่สร้างโดย AI มักตั้งค่าเป็นเช็คบทบาทง่าย ๆ RBAC มองเห็นได้ง่ายแต่ล้มเหลวเมื่อมีกฎความเป็นเจ้าของ ("ผู้ใช้ดูเฉพาะบิลของตัวเอง") หรือกฎตามบริบท ("ซัพพอร์ตดูข้อมูลได้เฉพาะตอนมีตั๋ว active") ABAC จัดการกรณีนี้ได้ดีกว่า แต่ต้องมีนโยบายชัดเจน
ระบุรูปแบบที่ใช้และยืนยันว่า endpoint ทุกตัวบังคับใช้อย่างสอดคล้อง โดยเฉพาะรายการ/ค้นหา ซึ่งเป็นจุดที่ข้อมูลมักรั่ว
โค้ดที่สร้างอาจล็อก body ของ request, headers, หรือแถวฐานข้อมูลในข้อผิดพลาด ซึ่งรั่วรหัสผ่าน โทเคน และ PII เข้าสู่ logs และ APM ตั้งค่าดีฟอลต์เช่น: structured logs, allowlist ฟิลด์ที่ล็อก, redaction ของความลับ (Authorization, cookies, reset tokens), และหลีกเลี่ยงการล็อก payload ดิบเมื่อเกิด validation failure
ออกแบบการลบตั้งแต่วันแรก: การลบโดยผู้ใช้, ปิดบัญชี, และเวิร์กโฟลว์ "สิทธิ์ถูกลืม" กำหนดช่วงเก็บข้อมูลตามประเภทข้อมูล (เช่น audit events vs marketing events) และแน่ใจว่าคุณพิสูจน์ได้ว่าอะไรถูกลบเมื่อไร
ถ้าคุณเก็บบันทึกตรวจสอบ ให้เก็บตัวระบุขั้นต่ำ ป้องกันด้วยการเข้าถึงที่เข้มงวด และบันทึกวิธีการส่งออกหรือลบข้อมูลเมื่อต้องการ
AI ดีที่สุดเมื่อคุณใช้มันเป็นนักสถาปนิกจูเนียร์ที่เร็ว: เก่งในการสร้างร่างแรก อ่อนในการตัดสินการประนีประนอมที่สำคัญในโดเมน คำถามที่ถูกต้องไม่ใช่ "AI ออกแบบแบ็กเอนด์ฉันได้ไหม" แต่คือ "ส่วนไหน AI ร่างได้ปลอดภัย และส่วนไหนต้องมีเจ้าของผู้เชี่ยวชาญ?"
AI ช่วยประหยัดเวลาจริงเมื่อคุณกำลังสร้าง:
ที่นี่ AI มีคุณค่าสำหรับความเร็ว ความสอดคล้อง และความครอบคลุม โดยเฉพาะเมื่อคุณรู้ว่าผลิตภัณฑ์ควรทำงานอย่างไรและสามารถจับข้อผิดพลาดได้
ระวัง (หรืออย่าใช้ AI เกินแค่แรงบันดาลใจ) เมื่อทำงานใน:
ในบริเวณเหล่านี้ ความเชี่ยวชาญโดเมนสำคัญกว่าความเร็วของ AI ข้อกำหนดเล็ก ๆ น้อย ๆ ทางกฎหมาย คลินิก บัญชี มักไม่อยู่ในพรอมต์ และ AI มักเติมช่องว่างอย่างมั่นใจ
กฎปฏิบัติ: ให้ AI เสนอทางเลือก แต่กำหนดการทบทวนสุดท้ายสำหรับ invariants ของโมเดลข้อมูล ขอบเขตการอนุญาต และกลยุทธ์มิเกรชัน หากคุณระบุไม่ได้ว่าใครรับผิดชอบสำหรับสคีมาและสัญญา API อย่าเอาสคีมาที่ออกแบบโดย AIขึ้น production
ถ้าคุณกำลังประเมินเวิร์กโฟลว์และการป้องกันความเสี่ยง ให้ดูคำแนะนำที่เกี่ยวข้องใน /blog. ถ้าคุณต้องการช่วยนำแนวปฏิบัติเหล่านี้ไปใช้กับกระบวนการทีมของคุณ ให้ตรวจสอบ /pricing.
ถ้าคุณต้องการเวิร์กโฟลว์แบบ end-to-end ที่สามารถวนรอบผ่านแชท สร้างแอปที่ใช้งานได้ และยังคงควบคุมผ่านการส่งออกซอร์สโค้ดและ snapshot ที่ย้อนกลับได้ Koder.ai ถูกออกแบบมาเพื่อสไตล์การสร้าง-และ-ทบทวนแบบนั้น
It usually means the model generated a first draft of:
A human team still needs to validate business rules, security boundaries, query performance, and migration safety before shipping.
Provide concrete inputs the AI can’t safely guess:
The clearer the constraints, the less the AI “fills gaps” with brittle defaults.
Start with a conceptual model (business concepts + invariants), then derive:
Keeping these layers separate makes it easier to change storage without breaking the API—or to revise the API without accidentally corrupting business rules.
Common issues include:
tenant_id and composite unique constraints)deleted_at)Ask the AI to design around your top queries and then verify:
tenant_id + created_at)If you can’t list the top 5 queries/endpoints, treat any indexing plan as incomplete.
AI is good at standard scaffolding, but you should watch for:
200 with errors, inconsistent 4xx/5xx)Treat the API as a product interface: model endpoints around user concepts, not database implementation details.
Use a repeatable loop:
Use consistent HTTP codes and a single error envelope, for example:
Prioritize tests that lock in behavior:
Tests are how you “own” the design instead of inheriting the AI’s assumptions.
Use AI mainly for drafts when patterns are well-understood (CRUD-heavy MVPs, internal tools). Be cautious when:
A good policy: AI can propose options, but humans must sign off on schema invariants, authorization, and rollout/migration strategy.
A schema can look “clean” and still fail under real workflows and load.
This turns AI output into artifacts you can prove or reject instead of trusting prose.
400, 401, 403, 404, 409, 422, 429{"error":{"code":"...","message":"...","details":[...]}}
Also ensure error messages don’t leak internals (SQL, stack traces, secrets) and stay consistent across all endpoints.