27 ก.ย. 2568·4 นาที
การปรับใช้ Blue/Green และ Canary: กลยุทธ์การปล่อยที่ชัดเจน
เรียนรู้ว่าเมื่อใดควรใช้ Blue/Green vs Canary วิธีการสลับทราฟฟิกที่ทำงาน อะไรต้องมอนิเตอร์ และขั้นตอนปฏิบัติสำหรับการโรลเอาต์และการย้อนกลับเพื่อการปล่อยที่ปลอดภัยขึ้น.
ความหมายของการปรับใช้ Blue/Green และ Canary
การส่งโค้ดใหม่มีความเสี่ยงเพราะเหตุผลง่าย ๆ: คุณไม่สามารถรู้แน่จนกว่าผู้ใช้จริงจะเข้ามาใช้งาน Blue/Green และ Canary เป็นสองวิธีที่ใช้ลดความเสี่ยงนั้นในขณะเดียวกันก็รักษาเวลาหยุดทำงานให้ใกล้เคียงกับศูนย์
อธิบาย Blue/Green แบบเข้าใจง่าย
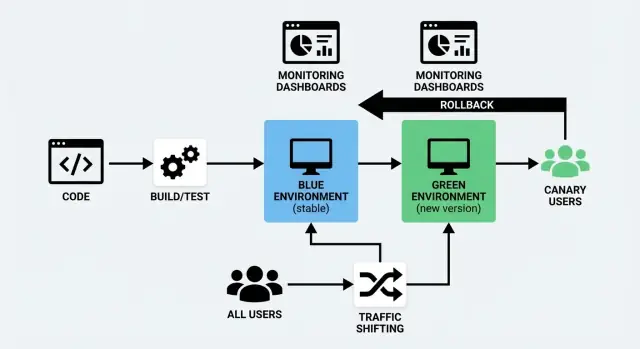
การ ปรับใช้แบบ Blue/Green ใช้สองสภาพแวดล้อมแยกกันแต่คล้ายกัน:
- Blue: เวอร์ชันที่ให้บริการผู้ใช้ในปัจจุบัน (การตั้งค่าที่ “สด”)\n- Green: สภาพแวดล้อมสำรองที่เตรียมไว้ให้ปรับใช้เวอร์ชันใหม่ได้ทันที
คุณเตรียม Green ในเบื้องหลัง—ดีพลอยบิลด์ใหม่ รันการตรวจสอบ อุ่นระบบ—แล้วค่อยเปลี่ยนทราฟฟิกจาก Blue ไปยัง Green เมื่อมั่นใจ หากมีปัญหาสามารถสลับกลับได้อย่างรวดเร็ว
แนวคิดสำคัญไม่ใช่ “สีสองสี” แต่คือ การสลับแบบสะอาดและย้อนกลับได้
อธิบาย Canary แบบเข้าใจง่าย
การ ปล่อยแบบคานารี คือการค่อย ๆ โรลเอาต์ แทนที่จะสลับผู้ใช้ทั้งหมดในคราวเดียว คุณส่งเวอร์ชันใหม่ให้ผู้ใช้ส่วนน้อยก่อน (เช่น 1–5%) หากทุกอย่างดูปกติก็ค่อยขยายสัดส่วนขึ้นทีละขั้นจนถึง 100%
แนวคิดสำคัญคือ เรียนรู้จากทราฟฟิกจริงก่อนตัดสินใจเต็มรูปแบบ
เป้าหมายร่วมกัน: ปล่อยให้ปลอดภัยขึ้นและลด downtime
ทั้งสองวิธีเป็นกลยุทธ์การปรับใช้ที่มุ่งจะ:
- ลดผลกระทบต่อผู้ใช้เมื่อมีปัญหาเกิดขึ้น
- สนับสนุนการปรับใช้แบบ ไม่มีช่วงเวลาหยุดทำงาน (หรือใกล้เคียงที่สุดเท่าที่ระบบของคุณจะอนุญาต)
- ทำให้การย้อนกลับไม่ตึงเครียดและคาดเดาได้มากขึ้น
ทั้งคู่ทำได้ต่างกัน: Blue/Green มุ่งที่การสลับอย่างรวดเร็วระหว่างสภาพแวดล้อม ในขณะที่ Canary มุ่งที่การเปิดเผยอย่างควบคุมผ่านการ เปลี่ยนเส้นทางทราฟฟิก
ไม่มีตัวเลือกที่ “ดีที่สุด” เสมอไป
ไม่มีวิธีใดเหนือกว่าโดยอัตโนมัติ การเลือกขึ้นกับพฤติกรรมการใช้งานของผลิตภัณฑ์ ความเชื่อมั่นของการทดสอบ ความเร็วที่คุณต้องการรับฟีดแบ็ค และประเภทความล้มเหลวที่ต้องการหลีกเลี่ยง
หลายทีมก็ผสมทั้งสองวิธี—ใช้ Blue/Green เพื่อความเรียบง่ายด้านโครงสร้างพื้นฐาน และใช้เทคนิค Canary เพื่อการเปิดเผยต่อผู้ใช้อย่างค่อยเป็นค่อยไป
ในส่วนถัดไปเราจะเปรียบเทียบตรง ๆ และแสดงเมื่อใดที่แต่ละวิธีเหมาะสมที่สุด
Blue/Green กับ Canary: เปรียบเทียบแบบเร็ว
Blue/Green และ Canary ต่างก็เป็นวิธีปล่อยการเปลี่ยนแปลงโดยไม่รบกวนผู้ใช้—แต่ต่างกันที่ วิธีที่ทราฟฟิกย้ายไปยังเวอร์ชันใหม่
วิธีการสลับทราฟฟิก
Blue/Green มีสองสภาพแวดล้อมเต็มรูปแบบ: “Blue” (ปัจจุบัน) และ “Green” (ใหม่) คุณตรวจสอบ Green แล้ว สลับทราฟฟิกทั้งหมดในครั้งเดียว—เหมือนพลิกสวิตช์เดียวที่ควบคุมได้
Canary ปล่อยเวอร์ชันใหม่ให้ผู้ใช้ส่วนน้อยก่อน (เช่น 1–5%) แล้วค่อย เปลี่ยนทราฟฟิกอย่างค่อยเป็นค่อยไป ขณะเฝ้าดูประสิทธิภาพจากโลกจริง
ข้อดีข้อเสียที่สำคัญ
| ปัจจัย | Blue/Green | Canary |
|---|---|---|
| ความเร็ว | สลับรวดเร็วหลังการตรวจสอบ | ช้ากว่าโดยออกแบบให้ค่อยเป็นค่อยไป |
| ความเสี่ยง | ปานกลาง: ถ้าปล่อยไม่ดีจะกระทบทุกคนหลังสลับ | ต่ำกว่า: ปัญหามักจะปรากฏก่อนการโรลเอาต์เต็มรูปแบบ |
| ความซับซ้อน | ปานกลาง (ต้องมีสองสภาพแวดล้อมและการสลับที่สะอาด) | สูงกว่า (ต้องแบ่งทราฟฟิก วิเคราะห์ และโรลเอาต์เป็นขั้น) |
| ต้นทุน | สูงกว่า (ต้องสำรองความจุเป็นสองเท่าในช่วงโรลเอาต์) | มักต่ำกว่า (สามารถใช้ความจุเดิมแล้วค่อย ๆ เพิ่ม) |
| เหมาะกับ | การเปลี่ยนแปลงใหญ่ที่ประสานงานกัน | การปรับปรุงเล็ก ๆ และบ่อยครั้ง |
แนวทางการตัดสินใจอย่างง่าย
เลือก Blue/Green เมื่อคุณต้องการช่วงสลับที่ชัดเจนและคาดเดาได้—โดยเฉพาะการเปลี่ยนแปลงใหญ่ การโยกย้าย หรือการปล่อยที่ต้องการแยก “เก่า vs ใหม่” อย่างชัดเจน
เลือก Canary เมื่อคุณปล่อยบ่อย ต้องการเรียนรู้จากการใช้งานจริงอย่างปลอดภัย และต้องการลด blast radius โดยให้เมตริกชี้นำแต่ละขั้น
ถ้าคุณไม่แน่ใจ ให้เริ่มจาก Blue/Green เพื่อความเรียบง่ายทางปฏิบัติการ แล้วเพิ่ม Canary สำหรับบริการที่มีความเสี่ยงสูงเมื่อการมอนิเตอร์และนิสัยการย้อนกลับมั่นคงแล้ว
เมื่อใดที่ Blue/Green เหมาะสม
Blue/Green เหมาะเมื่อคุณต้องการให้การปล่อยรู้สึกเหมือน “พลิกสวิตช์” คุณรันสองสภาพแวดล้อมที่ใกล้เคียงกับ production: Blue (ปัจจุบัน) และ Green (ใหม่) เมื่อยืนยัน Green แล้วก็เปลี่ยนผู้ใช้ไปยังมัน
คุณต้องการ downtime ใกล้ศูนย์
ถ้าผลิตภัณฑ์ของคุณทนต่อหน้าต่างบำรุงรักษาไม่ได้—เช่น กระบวนการชำระเงิน ระบบจอง แดชบอร์ดที่ล็อกอิน—Blue/Green ช่วยได้เพราะเวอร์ชันใหม่เริ่ม ทำความร้อนระบบ และตรวจสอบ ก่อน ที่ผู้ใช้จริงจะถูกส่งไป ส่วนใหญ่ของ “เวลาการปรับใช้” จะเกิดขึ้นด้านข้าง ไม่ได้เกิดตรงหน้าลูกค้า
คุณต้องการย้อนกลับที่ง่ายที่สุด
การย้อนกลับมักเป็นการสลับทราฟฟิกกลับไปยัง Blue นั่นมีประโยชน์เมื่อ:
- การปล่อยต้องย้อนกลับได้ภายในไม่กี่นาที
- ต้องการหลีกเลี่ยงการแก้ไขฉุกเฉินภายใต้ความกดดัน
- ต้องการการตอบสนองต่อความล้มเหลวที่ชัดเจนและทำซ้ำได้
ข้อดีสำคัญคือการย้อนกลับไม่ต้อง rebuild หรือ redeploy—มันคือการสลับทราฟฟิก
การเปลี่ยนแปลงฐานข้อมูลต้องเข้ากันได้
Blue/Green ง่ายที่สุดเมื่อการย้ายฐานข้อมูลเป็น backward compatible เพราะช่วงสั้น ๆ อาจมีทั้ง Blue และ Green อยู่พร้อมกัน (และอาจทั้งคู่อ่าน/เขียน ขึ้นกับการตั้งค่า routing และ job)
ตัวอย่างที่เข้ากันได้ดีได้แก่:
- การเปลี่ยนสคีมาแบบเพิ่ม (คอลัมน์ใหม่ที่ nullable, ตารางใหม่)
- ขยายรูปแบบข้อมูลที่โค้ดเก่าสามารถเพิกเฉยได้
สิ่งที่เสี่ยงได้แก่การลบคอลัมน์ เปลี่ยนชื่อฟิลด์ หรือลบความหมายเดิม—สิ่งเหล่านี้อาจทำลายคำสัญญาการสลับกลับเว้นแต่ว่าคุณวางแผนการย้ายหลายขั้นตอน
คุณมีงบพอสำหรับสภาพแวดล้อมซ้ำและการควบคุม routing
Blue/Green ต้องการความจุเพิ่ม (สองสแตก) และวิธีการชี้ทราฟฟิก (load balancer, ingress, หรือ routing ของแพลตฟอร์ม) หากคุณมีระบบอัตโนมัติในการ provision สภาพแวดล้อมและคันโยกการ routing ที่สะอาด Blue/Green จะเป็นค่าเริ่มต้นที่ใช้งานได้จริงสำหรับการปล่อยที่มั่นใจและไม่ตื่นเต้นมาก
เมื่อใดที่ Canary เหมาะสมกว่า
การปล่อยแบบคานารีคือการเปิดตัวแบบค่อยเป็นค่อยไปที่คุณมอบการเปลี่ยนแปลงให้กลุ่มผู้ใช้เล็ก ๆ ก่อน เรียนรู้จากผล แล้วขยาย เป็นตัวเลือกที่ดีเมื่อคุณต้องการลดความเสี่ยงโดยไม่ต้องหยุดโลกเพื่อการปล่อยครั้งใหญ่
คุณมีทราฟฟิกจำนวนมากและสัญญาณชัดเจน
Canary ทำงานได้ดีสำหรับแอปที่มีทราฟฟิกสูงเพราะแม้ 1–5% ของทราฟฟิกก็ให้ข้อมูลที่มีความหมายอย่างรวดเร็ว หากคุณติดตามเมตริกชัดเจนอยู่แล้ว (อัตราข้อผิดพลาด latency การแปลง การชำระเงิน สำเร็จ) คุณจะสามารถตรวจสอบการปล่อยบนรูปแบบการใช้งานจริงแทนที่จะพึ่งแต่สภาพแวดล้อมทดสอบเท่านั้น
คุณกังวลเรื่องประสิทธิภาพและกรณีขอบ
บางปัญหาแสดงขึ้นภายใต้โหลดจริงเท่านั้น: คิวรีฐานข้อมูลช้า การพลาดแคช ความหน่วงในบางภูมิภาค อุปกรณ์เฉพาะ หรือฟลูว์ผู้ใช้ที่หาไม่ง่าย ด้วยการปล่อยแบบคานารี คุณสามารถยืนยันว่าการเปลี่ยนแปลงไม่เพิ่มข้อผิดพลาดหรือทำให้ประสิทธิภาพแย่ก่อนที่จะกระจายไปยังทุกคน
คุณต้องการโรลเอาต์แบบเป็นขั้น ไม่ใช่สลับครั้งเดียว
หากผลิตภัณฑ์ของคุณปล่อยบ่อย มีหลายทีมร่วมกัน หรือรวมการเปลี่ยนแปลงที่สามารถแนะนำแบบค่อยเป็นค่อยไป (ปรับ UI ทดลองราคา ตรรกะคำแนะนำ) การโรลเอาต์แบบคานารีเหมาะอย่างยิ่ง คุณสามารถขยายจาก 1% → 10% → 50% → 100% ตามที่เมตริกบอก
Feature flags อยู่ในเครื่องมือของคุณ
Canary เข้าคู่ได้ดีเป็นพิเศษกับ feature flags: คุณสามารถดีพลอยโค้ดอย่างปลอดภัย แล้วเปิดฟีเจอร์ให้กลุ่มย่อยของผู้ใช้ ภูมิภาค หรือบัญชี การย้อนกลับจึงไม่ดราม่ามาก—มักแค่ปิด flag แทนการ redeploy
หากคุณกำลังก้าวสู่ progressive delivery การปล่อยแบบคานารีมักเป็นจุดเริ่มต้นที่ยืดหยุ่นที่สุด
See also: /blog/feature-flags-and-progressive-delivery
พื้นฐานของการเปลี่ยนเส้นทางทราฟฟิก (แบบไม่ใช้ศัพท์เทคนิค)
การเปลี่ยนเส้นทางทราฟฟิกหมายถึงการควบคุม ใคร ได้เวอร์ชันใหม่ของแอปและ เมื่อใด แทนที่จะพลิกทุกคนพร้อมกัน คุณย้ายคำขออย่างค่อยเป็นค่อยไป (หรือแบบเลือกเฉพาะ) จากเวอร์ชันเก่าไปยังเวอร์ชันใหม่ นี่คือหัวใจของทั้ง blue/green deployment และ canary release—และยังเป็นสิ่งที่ทำให้การปรับใช้แบบ ไม่มีช่วงเวลาหยุดทำงาน เป็นไปได้จริง
"พวงมาลัย": จุดที่ทราฟฟิกถูกชี้
คุณสามารถสลับทราฟฟิกได้ที่จุดต่าง ๆ ในสแตกของคุณ ตัวเลือกที่เหมาะขึ้นกับสิ่งที่คุณรันอยู่แล้วและความละเอียดที่ต้องการควบคุม
- Load balancer: แบ่งคำขอขาเข้าไปยังสองสภาพแวดล้อมหรือสองชุดเซิร์ฟเวอร์
- Ingress controller (Kubernetes): ชี้ทราฟฟิกไปยัง Services ต่าง ๆ ตามกฎ
- Service mesh: ควบคุมทราฟฟิกระหว่างเซอร์วิสด้วยกฎที่ละเอียดและมองเห็นได้ดีขึ้น
- CDN / edge routing: มีประโยชน์เมื่อคุณต้องการตัดสินใจชี้เส้นทางใกล้ผู้ใช้ บ่อยครั้งสำหรับทราฟฟิกเว็บ
คุณไม่ต้องมีทุกเลเยอร์ เลือกแหล่งเดียวเป็น “แหล่งความจริง” สำหรับการตัดสินใจ routing เพื่อให้ การจัดการการปล่อย ของคุณไม่กลายเป็นการเดา
วิธีแบ่งทราฟฟิกที่พบบ่อย
ทีมส่วนใหญ่ใช้หนึ่งในวิธีเหล่านี้ (หรือผสมกัน) สำหรับ การเปลี่ยนเส้นทางทราฟฟิก:
- แบบเปอร์เซ็นต์: 1% → 5% → 25% → 50% → 100% (รูปแบบคานารีคลาสสิก)
- แบบอิงเฮดเดอร์: ชี้คำขอที่มีเฮดเดอร์พิเศษ (เช่น จากเครื่องมือ QA หรือนักทดสอบภายใน) ไปยังเวอร์ชันใหม่
- กลุ่มผู้ใช้: เปิดให้กลุ่มเฉพาะก่อน—พนักงาน ผู้ใช้เบต้า ภูมิภาค หรือลูกค้าระดับพรีเมียม
แบบเปอร์เซ็นต์อธิบายง่าย แต่การใช้กลุ่มมักปลอดภัยกว่าเพราะคุณควบคุมได้ว่า ใคร เห็นการเปลี่ยนแปลง (และหลีกเลี่ยงการทำให้ลูกค้ารายใหญ่ตกใจในชั่วโมงแรก)
Session และ cache: สองข้อที่ต้องระวัง
สองสิ่งที่มักทำให้แผนการปรับใช้เป๋คือ:
Sticky sessions (session affinity). ถ้าระบบผูกผู้ใช้กับเซิร์ฟเวอร์/เวอร์ชันหนึ่ง การแบ่งทราฟฟิก 10% อาจไม่ทำงานเหมือน 10% จริง ๆ และอาจเกิดบั๊กสับสนเมื่อผู้ใช้เด้งไปมาระหว่างเวอร์ชัน หากเป็นไปได้ให้ใช้พื้นที่เก็บ session ร่วมกันหรือทำให้ routing เก็บผู้ใช้ให้อยู่กับเวอร์ชันเดียวสม่ำเสมอ
การอุ่นแคช. เวอร์ชันใหม่มักเจอแคชเย็น (CDN, แคชแอป, แคชคิวรีฐานข้อมูล) สิ่งนี้อาจดูเหมือนการถดถอยด้านประสิทธิภาพแม้โค้ดจะปกติดี จัดเวลาให้อุ่นแคชก่อนเพิ่มทราฟฟิก โดยเฉพาะหน้าที่มีทราฟฟิกสูงและ endpoint ที่แพง
ทำให้การเปลี่ยนทราฟฟิกเป็นการปฏิบัติการที่ควบคุมได้
จัดการการเปลี่ยน routing เหมือนการเปลี่ยนแปลงใน production ไม่ใช่การกดปุ่มแบบสุ่ม
จดบันทึก:
- ใคร เปลี่ยนสัดส่วนทราฟฟิกได้
- อย่างไร ที่ได้รับการอนุมัติ (on-call? release manager? change ticket?)
- ที่ไหน ทำการเปลี่ยน (config ของ load balancer, กฎ ingress, policy ของ mesh)
- หน้าตาของการ "หยุด" (ทริกเกอร์ให้หยุดโรลเอาต์และทำตามแผนย้อนกลับ)
การมีการกำกับดูแลเล็กน้อยนี้จะป้องกันไม่ให้คนตั้งใจดี "แค่ผลักไป 50%" ขณะที่คุณยังไม่แน่ใจว่าคานารีสุขภาพดีหรือไม่
ต้องมอนิเตอร์อะไรระหว่างการโรลเอาต์
เป็นเจ้าของเส้นทางการปล่อยของคุณ
ควบคุมเส้นทางการปล่อยด้วยการส่งออกซอร์สโค้ดเมื่อคุณต้องการ.
การโรลเอาต์ไม่ใช่แค่ "ดีพลอยสำเร็จไหม?" แต่คือ "ผู้ใช้จริงได้ประสบการณ์ที่แย่ลงไหม?" วิธีที่ง่ายที่สุดที่จะใจเย็นระหว่าง Blue/Green หรือ Canary คือดูสัญญาณไม่กี่อย่างที่บอกคุณว่า: ระบบยังแข็งแรง และการเปลี่ยนแปลงทำร้ายลูกค้าหรือไม่
สัญญาณหลักสี่อย่าง: ข้อผิดพลาด latency ความอิ่มตัว ผลกระทบต่อผู้ใช้
อัตราข้อผิดพลาด: ติดตาม HTTP 5xx ความล้มเหลวของคำขอ timeouts และข้อผิดพลาดจาก dependency (ฐานข้อมูล การชำระเงิน API ภายนอก) คานารีที่เพิ่มข้อผิดพลาดเล็กน้อยก็ยังสร้างภาระการสนับสนุนได้มาก
Latency: ดู p50 และ p95 (และ p99 ถ้ามี) การเปลี่ยนแปลงที่รักษาค่าเฉลี่ยให้คงที่อาจยังสร้างความหน่วงในหางยาวที่ผู้ใช้รับรู้ได้
Saturation: ดูว่าระบบเต็มหรือไม่—CPU, memory, disk IO, การเชื่อมต่อ DB, ความลึกของคิว, thread pools ปัญหาความอิ่มตัวมักแสดงก่อนการล่มทั้งหมด
สัญญาณผลกระทบต่อผู้ใช้: วัดสิ่งที่ผู้ใช้สัมผัสจริง—การชำระเงินล้มเหลว อัตราการล็อกอินสำเร็จ ผลการค้นหาที่คืนค่า อัตราแครชของแอป หรือเวลาการโหลดหน้าสำคัญ เหล่านี้มักมีความหมายมากกว่าสถานะโครงสร้างพื้นฐานเพียงอย่างเดียว
สร้าง “แดชบอร์ดการปล่อย” ที่ทุกคนอ่านได้
สร้างแดชบอร์ดเล็ก ๆ ที่พอดูบนหน้าจอเดียวและแชร์ในช่องทางการปล่อยของคุณ เก็บให้สม่ำเสมอในทุกการโรลเอาต์เพื่อคนจะได้ไม่เสียเวลาไล่หากราฟ
ควรรวม:
- อัตราข้อผิดพลาด (รวม + endpoint สำคัญ)
- latency (p50/p95 สำหรับเส้นทางสำคัญ)
- saturation (ข้อจำกัด 3 อันดับแรกของสแตก เช่น CPU แอป การเชื่อมต่อ DB ความลึกคิว)
- KPI ผลกระทบต่อธุรกิจ (ฟลูว์สำคัญ 1–3 รายการ)
หากคุณรัน canary release ให้แบ่งเมตริกตามเวอร์ชัน/กลุ่ม instance เพื่อเปรียบเทียบ canary vs baseline โดยตรง สำหรับ blue/green deployment ให้เปรียบเทียบสภาพแวดล้อมใหม่กับเก่าในช่วงหน้าต่างการสลับ
กำหนดเกณฑ์ชัดเจนสำหรับการหยุด/ย้อนกลับ
ตัดสินใจเรื่องกฎก่อนเริ่มสลับทราฟฟิก ตัวอย่างเกณฑ์เช่น:
- อัตราข้อผิดพลาดเพิ่มขึ้น X% เกิน baseline เป็นเวลา Y นาที
- p95 latency เกินขีดจำกัดที่กำหนด (หรือเพิ่ม X% เทียบ baseline)
- KPI ผลกระทบต่อผู้ใช้ลดต่ำกว่าค่าที่ยอมรับได้
ตัวเลขที่แน่นอนขึ้นกับบริการของคุณ แต่ส่วนสำคัญคือทุกคนต้องตกลงกัน หากทุกคนรู้แผนการย้อนกลับและทริกเกอร์ จะเลี่ยงการถกเถียงขณะลูกค้ากำลังได้รับผลกระทบ
การแจ้งเตือนที่เน้นช่วงการโรลเอาต์
เพิ่ม (หรือปรับเข้ม) การแจ้งเตือนเฉพาะในช่วงการโรลเอาต์:
- กระโดดของ 5xx/timeouts ที่ไม่คาดคิด
- ถดถอยของ latency อย่างฉับพลันในเส้นทางสำคัญ
- การเติบโตอย่างรวดเร็วของสัญญาณ saturation (connection pools, queues)
ให้การแจ้งเตือนสามารถลงมือทำได้: “อะไรเปลี่ยน ที่ไหน และต้องทำอย่างไรต่อ” หากการแจ้งเตือนดังเกินไป ผู้คนจะพลาดสัญญาณสำคัญเมื่อการเปลี่ยนทราฟฟิกกำลังเกิดขึ้น
การตรวจสอบก่อนปล่อยที่จับปัญหาได้ตั้งแต่ต้น
ความล้มเหลวส่วนใหญ่ไม่ได้เกิดจาก “บั๊กใหญ่” แต่เกิดจากความไม่ลงรอยเล็ก ๆ: ค่าคอนฟิกหายไป การย้ายฐานข้อมูลไม่ถูกต้อง ใบรับรองหมดอายุ หรือการรวมระบบที่ทำงานต่างกันในสภาพแวดล้อมใหม่ การตรวจสอบก่อนปล่อยเป็นโอกาสจับปัญหาเหล่านี้ขณะที่ blast radius ยังเล็ก
เริ่มจาก health checks และ smoke tests
ก่อนสลับทราฟฟิกใด ๆ (ทั้ง blue/green หรือ canary) ยืนยันว่าเวอร์ชันใหม่ยังมีชีวิตและให้บริการคำขอได้
- ให้จุดตรวจสุขภาพของแอปรายงาน OK (ไม่ใช่แค่ “process กำลังรัน”)
- ยืนยัน dependencies: ฐานข้อมูล แคช คิว storage อีเมล/SMS providers
- ยืนยัน secrets และ environment variables อยู่ครบและสเกปถูกต้อง
รัน end-to-end tests สั้น ๆ กับสภาพแวดล้อมใหม่
Unit tests ดีมาก แต่ไม่ได้พิสูจน์ระบบที่ดีพลอยแล้วทั้งหมด รันชุดทดสอบ end-to-end อัตโนมัติสั้น ๆ กับสภาพแวดล้อมใหม่ที่เสร็จภายในไม่กี่นาที
เน้นฟลูว์ที่ข้ามขอบเขตบริการ (เว็บ → API → DB → third-party) และรวมอย่างน้อยหนึ่งคำขอ “จริง” ต่อการรวมระบบสำคัญ
ยืนยันเส้นทางผู้ใช้สำคัญ (งานที่สร้างรายได้)
เทสต์อัตโนมัติอาจพลาดสิ่งชัดเจน ทำการตรวจสอบแบบมนุษย์ของเวิร์กโฟลว์หลัก:
- เข้าสู่ระบบและรีเซ็ตรหัสผ่าน
- กระบวนการเช็คเอาต์หรือการชำระเงิน (รวมถึงเส้นทางความล้มเหลว)
- การกระทำหลักที่ผู้ใช้ทำประจำ (สร้าง / อัปเดต / ลบ)
ถ้ารองรับหลายบทบาท (admin vs customer) ให้สำรวจอย่างน้อยหนึ่งเส้นทางต่อบทบาท
เก็บ checklist ความพร้อมก่อนปล่อย
เช็คลิสต์ทำให้ความรู้ในทีมกลายเป็นกลยุทธ์ที่ทำซ้ำได้ เก็บให้สั้นและปฏิบัติได้:
- การย้ายฐานข้อมูลถูกใช้และย้อนกลับได้ (หรือชัดเจนว่าไม่เป็นปัญหา)
- ความสามารถด้าน observability พร้อม: logs, dashboards, alerts สำหรับเมตริกสำคัญ
- แผนย้อนกลับทบทวนแล้ว (ใคร ทำอย่างไร และหน้าตาของ "หยุด")
เมื่อการตรวจสอบเหล่านี้เป็นเรื่องปกติ การเปลี่ยนทราฟฟิกจะกลายเป็นขั้นตอนควบคุมได้ ไม่ใช่ความเสี่ยงแบบสุ่ม
Blue/Green Rollout: คู่มือปฏิบัติ
ทำให้การปล่อยเป็นเรื่องปกติ
ทำให้การปรับใช้อยู่ในรูปแบบที่ทำซ้ำได้สำหรับแอปที่คุณสร้างและส่งบ่อย ๆ.
การโรลเอาต์แบบ Blue/Green ง่ายขึ้นเมื่อคุณจัดให้เป็นเช็คลิสต์: เตรียม ดีพลอย ตรวจสอบ สลับ เฝ้าดู แล้วทำความสะอาด
1) ดีพลอยไปยัง Green (โดยไม่แตะผู้ใช้)
ส่งเวอร์ชันใหม่ไปยังสภาพแวดล้อม Green ขณะที่ Blue ยังคงให้บริการจริง จัดให้คอนฟิกและ secrets สอดคล้องกันเพื่อให้ Green เป็นกระจกที่สมจริง
2) ยืนยัน Green ก่อนสลับทราฟฟิกใด ๆ
ทำการตรวจสอบสัญญาณสูงโดยเร็ว: แอปเริ่มขึ้นอย่างสะอาด หน้าเพจหลักโหลดได้ การชำระเงิน/ล็อกอินทำงาน และ logs ปกติ ถ้ามี smoke tests อัตโนมัติให้รันตรงนี้ นี่คือจังหวะที่จะยืนยันว่าแดชบอร์ดและการแจ้งเตือนสำหรับ Green ทำงานแล้ว
3) วางแผนการย้ายฐานข้อมูลแบบปลอดภัย (ขยาย/บีบ)
Blue/Green ซับซ้อนเมื่อฐานข้อมูลเปลี่ยน ใช้วิธี ขยาย/บีบ:
- ขยาย: เพิ่มคอลัมน์/ตารางใหม่ในแบบที่เข้ากันย้อนหลังได้
- ดีพลอย Green ให้ทำงานกับทั้งสคีมาเก่าและใหม่ได้
- บีบ: เอาฟิลด์เก่าออกหลังจาก Blue ถูกยกเลิกและมั่นใจว่าโค้ดใหม่เสถียร
วิธีนี้เลี่ยงสถานการณ์ที่ “Green ทำงาน แต่ Blue พัง” ขณะสลับ
4) อุ่นแคชและจัดการ background jobs
ก่อนสลับทราฟฟิก อุ่นแคชสำคัญ (หน้าแรก คิวรีที่ใช้บ่อย) เพื่อให้ผู้ใช้ไม่ต้องจ่ายค่า cold start
สำหรับ background jobs/cron workers ให้ตัดสินใจว่าใครจะรัน:
- รันงานใน สภาพแวดล้อมเดียวเท่านั้น ระหว่างการสลับเพื่อลดการประมวลผลซ้ำสอง
5) สลับทราฟฟิก แล้วเฝ้าดู
พลิก routing จาก Blue ไป Green (load balancer/DNS/ingress) ดูอัตราข้อผิดพลาด latency และเมตริกทางธุรกิจในหน้าต่างสั้น ๆ
6) ยืนยันหลังสลับและทำความสะอาด
ตรวจสอบแบบผู้ใช้จริง แล้วคง Blue ไว้ชั่วคราวเป็น fallback เมื่อตัวระบบนิ่งแล้ว ปิด job ของ Blue เก็บ logs และลบ Blue เพื่อลดต้นทุนและความสับสน
Canary Rollout: คู่มือปฏิบัติ
การโรลเอาต์แบบคานารีคือการเรียนรู้อย่างปลอดภัย แทนที่จะส่งผู้ใช้ทั้งหมดไปยังเวอร์ชันใหม่ทีเดียว คุณเปิดเผยเพียงส่วนน้อยของทราฟฟิกจริง ดูอย่างใกล้ชิด แล้วค่อยขยาย เป้าหมายไม่ใช่แค่ “ไปช้า” แต่คือ “พิสูจน์ว่าปลอดภัย” ด้วยหลักฐานในแต่ละขั้น
แผนการเพิ่มอย่างง่าย (1–5% → 25% → 50% → 100%)
- เตรียม canary
ดีพลอยเวอร์ชันใหม่ขนานกับเวอร์ชันเสถียร ตรวจสอบให้แน่ใจว่าคุณสามารถชี้เปอร์เซ็นต์ทราฟฟิกได้ และทั้งสองเวอร์ชันสามารถมองเห็นได้ในระบบมอนิเตอร์ (แดชบอร์ดแยกหรือตั้งแท็กช่วยได้)
- ขั้นที่ 1: 1–5%
เริ่มเล็ก ๆ ที่นี่ปัญหาเด่น ๆ จะปรากฏเร็ว: endpoint พัง คอนฟิกหาย การย้าย DB ที่ไม่คาดคิด หรือสปายค์ของ latency
จดบันทึกของขั้นนี้:
- สิ่งที่เปลี่ยนในรีลีสนี้ (รวมถึงคอนฟิกเล็ก ๆ)
- สิ่งที่คาดหวังให้เกิดขึ้น
- สิ่งที่สังเกต (ข้อผิดพลาด latency ปัญหาที่กระทบผู้ใช้)
- ขั้นที่ 2: 25%
ถ้าขั้นแรกสะอาด ให้เพิ่มเป็นประมาณหนึ่งในสี่ของทราฟฟิก คุณจะเห็นความหลากหลายของการใช้งานจริงมากขึ้น: เฉพาะอุปกรณ์ ระดับ concurrency สูง และกรณีขอบ
- ขั้นที่ 3: 50%
ครึ่งหนึ่งของทราฟฟิกคือจุดที่ปัญหาด้านความจุและประสิทธิภาพชัดขึ้น ถ้าคุณจะเจอขีดจำกัดการสเกล มักเห็นสัญญาณบอกเหตุช่วงนี้
- ขั้นที่ 4: 100% (โปรโมท)
เมื่อเมตริกนิ่งและผลกระทบต่อผู้ใช้ยอมรับได้ ให้ย้ายทราฟฟิกทั้งหมดมายังเวอร์ชันใหม่และประกาศโปรโมท
เลือกช่วงเวลาการเพิ่ม (รอนานแค่ไหนในแต่ละขั้น)
เวลารอขึ้นกับ ความเสี่ยง และ ปริมาณทราฟฟิก:
- การเปลี่ยนแปลงความเสี่ยงสูงหรือทราฟฟิกต่ำ: รอนานในแต่ละขั้นเพื่อเก็บสัญญาณเพียงพอ (เช่น 30–60 นาที หรือนานกว่า). บริการที่ทราฟฟิกน้อยอาจต้องใช้ชั่วโมงเพื่อเห็นพฤติกรรม
- การเปลี่ยนแปลงความเสี่ยงต่ำและทราฟฟิกสูง: ขั้นสั้น ๆ ก็พอได้ (เช่น 5–15 นาที) เพราะเก็บข้อมูลได้เร็ว
คำนึงถึงวัฏจักรธุรกิจด้วย หากสินค้ามีช่วงพีค (เช่น เวลาพักกลางวัน สุดสัปดาห์ รอบการเรียกเก็บเงิน) ให้รันคานารีนานพอที่จะครอบคลุมสภาวะที่มักก่อปัญหา
อัตโนมัติการโปรโมทและย้อนกลับ
การโรลเอาต์แบบแมนนวลสร้างความลังเลและไม่สม่ำเสมอ เมื่อเป็นไปได้ให้ทำงานอัตโนมัติ:
- โปรโมท เมื่อเมตริกหลักยังอยู่ในขอบเขตที่กำหนดเป็นเวลาหนึ่งหน้าต่าง
- ย้อนกลับ เมื่อเกณฑ์ถูกละเมิด (เช่น อัตราข้อผิดพลาดหรือ latency ข้ามขีดจำกัด)
การอัตโนมัติไม่ตัดการตัดสินใจของมนุษย์ออก—มันลดความล่าช้า
ปฏิบัติต่อแต่ละขั้นเหมือนการทดลอง
สำหรับทุกขั้นสรุป:
- สรุปการเปลี่ยนแปลง (อะไรเปลี่ยนบ้าง)
- เกณฑ์ความสำเร็จ (เมตริกใดต้องคงที่)
- ผลที่สังเกตได้ (สิ่งที่เห็น รวมถึง “ไม่มีอะไรผิดปกติ”)
- การตัดสินใจ (โปรโมท หยุด หรือย้อนกลับ) และเหตุผล
บันทึกเหล่านี้เปลี่ยนประวัติการโรลเอาต์ของคุณให้เป็น playbook สำหรับการปล่อยครั้งถัดไป—และช่วยให้การวิเคราะห์เหตุการณ์ในอนาคตง่ายขึ้น
แผนย้อนกลับและการจัดการความล้มเหลว
การย้อนกลับง่ายที่สุดเมื่อคุณตัดสินใจไว้ล่วงหน้าว่า “แย่” คืออะไร และใครมีสิทธิ์กดปุ่ม แผนย้อนกลับไม่ใช่ความคิดเศร้า แต่เป็นวิธีทำให้ปัญหาเล็กไม่กลายเป็นการล่มนาน
กำหนดทริกเกอร์ย้อนกลับชัดเจน
เลือกสัญญาณสั้น ๆ และตั้งเกณฑ์ชัดเจนเพื่อไม่ต้องถกเถียงตอนเหตุฉุกเฉิน ทริกเกอร์ทั่วไปได้แก่:
- อัตราข้อผิดพลาด: กระโดดของ 5xx การชำระเงินล้มเหลว ล็อกอินล้ม หรือ API timeouts
- latency: p95/p99 เกินขีดจำกัดที่ตกลงกันเป็นเวลาต่อเนื่อง (เช่น 5–10 นาที)
- KPI ทางธุรกิจ: ลดลงอย่างฉับพลันของ conversion การชำระเงินสำเร็จ การสมัคร หรือลดการใช้งาน
ทำให้ทริกเกอร์วัดได้ (เช่น “p95 > 800ms นาน 10 นาที”) และผูกกับเจ้าของ (on-call, release manager) ที่มีสิทธิ์ดำเนินการทันที
ทำให้การย้อนกลับรวดเร็ว (และไม่ตื่นเต้น)
ความเร็วสำคัญกว่าความสง่างาม การย้อนกลับควรเป็นหนึ่งใน:
- ย้อนการเปลี่ยนทราฟฟิก (ปกติสำหรับ blue/green และ canary): ย้ายทราฟฟิกกลับไปยังเวอร์ชันก่อนที่รู้ว่าดี
- ดีพลอยเวอร์ชันก่อนหน้าอีกครั้ง: หากโครงสร้างพื้นฐานเปลี่ยน ให้ push บิลด์เสถียรล่าสุดและรัน health checks
หลีกเลี่ยง “แก้ด้วยมือแล้วสานต่อโรลเอาต์” เป็นทางเลือกแรก ยุติก่อน แล้วค่อยวิเคราะห์
วางแผนสำหรับโรลเอาต์แบบบางส่วน
ด้วย canary บางผู้ใช้อาจสร้างข้อมูลภายใต้เวอร์ชันใหม่ ตัดสินใจล่วงหน้าว่า:
- ผู้ใช้ "canary" จะถูกส่งกลับทันทีหรือคงอยู่บน canary ขณะประเมิน?
- ถ้าเปลี่ยนรูปแบบข้อมูล ฐานข้อมูลย้อนกลับได้หรือไม่? หากไม่ การย้อนกลับอาจต้องมีมาตรการแยกต่างหาก
บทเรียนหลังเหตุการณ์เพื่อปรับปรุงครั้งถัดไป
เมื่อระบบนิ่งแล้ว เขียนสรุปสั้น ๆ: อะไรเป็นเหตุให้ต้องย้อนกลับ สัญญาณไหนขาด และจะเปลี่ยนเช็คลิสต์อย่างไร ถือเป็นรอบปรับปรุงผลิตภัณฑ์สำหรับกระบวนการปล่อย ไม่ใช่การตำหนิ
Feature Flags และ Progressive Delivery
รันการซ้อมปล่อย
สร้าง workflow หนึ่งอัน ปรับใช้ แล้วฝึกย้อนกลับ เพื่อให้วันปล่อยซอฟต์แวร์สงบขึ้น.
Feature flags ให้คุณแยก "deploy" (ส่งโค้ดสู่ production) ออกจาก "release" (เปิดใช้งานให้ผู้ใช้) นี่สำคัญเพราะคุณจะใช้ pipeline เดิม—Blue/Green หรือ Canary—พร้อมควบคุมการเปิดเผยด้วยสวิตช์ง่าย ๆ
ดีพลอยโดยไม่ต้องกดดัน เปิดใช้งานอย่างตั้งใจ
ด้วย flags คุณ merge และดีพลอยปลอดภัยแม้ฟีเจอร์ยังไม่พร้อมสำหรับทุกคน โค้ดอยู่แต่เป็นสถานะนิ่ง เมื่อมั่นใจคุณเปิด flag ทีละน้อย—มักเร็วกว่าการส่งบิลด์ใหม่—และถ้าเกิดปัญหาก็ปิดได้เร็ว
เปิดให้เฉพาะเป้าหมาย (ไม่ใช่เปิด-ปิดทั้งหมด)
Progressive delivery คือการเพิ่มการเข้าถึงเป็นขั้นตอน Flag สามารถเปิดให้:
- กลุ่มผู้ใช้เฉพาะ (พนักงานภายใน ผู้ใช้เบต้า ระดับจ่ายเงิน)
- ภูมิภาค (เริ่มจากประเทศหรือดาต้าเซ็นเตอร์เดียว)
- เปอร์เซ็นต์ของผู้ใช้ (1% → 10% → 50% → 100%)
นี่มีประโยชน์เมื่อคานารีบอกว่า เวอร์ชันใหม่ ปลอดภัย แต่ว่ายังต้องการจัดการความเสี่ยงของ ฟีเจอร์ แยกต่างหาก
แนวทางป้องกันไม่ให้เกิด “หนี้ของ flag”
Feature flags ทรงพลัง แต่ต้องมีการกำกับเล็กน้อย:
- ความรับผิดชอบ: แต่ละ flag มีทีมหรือคนรับผิดชอบ
- วันหมดอายุ: ตั้งวันที่ลบหรือทบทวนเพื่อไม่ให้ flag เก่าทับถม
- เอกสาร: เขียนว่าฟีเจอร์ทำอะไร ใครได้รับผลกระทบ และวิธีย้อนกลับ
กฎปฏิบัติ: ถ้าใครตอบไม่ได้ว่า "เกิดอะไรขึ้นเมื่อเราปิดอันนี้?" แปลว่า flag ยังไม่พร้อม
For deeper guidance on using flags as part of a release strategy, see /blog/feature-flags-release-strategy.
จะเลือกกลยุทธ์อย่างไรและเริ่มต้นอย่างไร
การเลือกระหว่าง Blue/Green และ Canary ไม่ใช่เรื่อง "อันไหนดีกว่า" แต่คือคุณต้องการควบคุมความเสี่ยงแบบไหน และทีมกับเครื่องมือของคุณทำงานแบบไหนได้จริง
วิธีตัดสินใจอย่างรวดเร็ว
ถ้าความสำคัญสูงสุดคือการสลับที่สะอาด คาดเดาได้ และปุ่ม "กลับไปเวอร์ชันเก่า" ง่าย ๆ ให้เลือก Blue/Green
ถ้าความสำคัญสูงสุดคือการลด blast radius และเรียนรู้จากทราฟฟิกจริงก่อนขยาย ให้เลือก Canary—โดยเฉพาะเมื่อการเปลี่ยนแปลงบ่อยหรือยากจะทดสอบล่วงหน้าทั้งหมด
กฎปฏิบัติ: เริ่มด้วยวิธีที่ทีมของคุณสามารถ รันได้สม่ำเสมอ ตอนตี 2 เมื่อมีปัญหา
เริ่มจากเล็ก ๆ: ทดลองกับหนึ่งสิ่ง
เลือก บริการหนึ่ง (หรือเวิร์กโฟลว์ที่ผู้ใช้เห็นหนึ่งอย่าง) และทำพายล็อตในการปล่อยไม่กี่ครั้ง เลือกสิ่งที่สำคัญพอที่จะมีความหมาย แต่ไม่อ่อนไหวจนทุกคนกลัว จุดมุ่งหมายคือสร้างการฝึกฝนเรื่องการเปลี่ยนทราฟฟิก การมอนิเตอร์ และการย้อนกลับ
เขียน runbook สั้น ๆ (และมอบหมายความรับผิดชอบ)
เก็บให้สั้น—หนึ่งหน้าก็พอ:
- หน้าตาของ "ดี" (เมตริกหลักและเกณฑ์)
- ใครรับผิดชอบระหว่างการโรลเอาต์
- วิธีหยุด ย้อนกลับ และสื่อสาร
ให้ความรับผิดชอบชัดเจน กลยุทธ์ไม่มีเจ้าของจะกลายเป็นแค่คำแนะนำ
ใช้สิ่งที่คุณมีอยู่ก่อน
ก่อนเพิ่มแพลตฟอร์มใหม่ ดูเครื่องมือที่คุณมีอยู่แล้ว: การตั้งค่า load balancer, สคริปต์การปรับใช้, การมอนิเตอร์ที่มี และกระบวนการ incident ใหม่ เฉพาะเมื่อเครื่องมือใหม่ลดแรงเสียดทานที่คุณเจอจริง ๆ จึงค่อยเพิ่ม
If you’re building and shipping new services quickly, platforms that combine app generation with deployment controls can also reduce operational drag. For example, Koder.ai is a vibe-coding platform that lets teams create web, backend, and mobile apps from a chat interface—and then deploy and host them with practical safety features like snapshots and rollback, plus support for custom domains and source code export. Those capabilities map well to the core goal of this article: make releases repeatable, observable, and reversible.
ขั้นตอนแนะนำต่อไป
If you want to see implementation options and supported workflows, review /pricing and /docs/deployments. Then schedule your first pilot release, capture what worked, and iterate your runbook after every rollout.