02 ต.ค. 2568·3 นาที
Brendan Burns และ Kubernetes: แนวคิดที่หล่อหลอมการออร์เคสตรา
มุมมองเชิงปฏิบัติเกี่ยวกับแนวคิดยุค Kubernetes ของ Brendan Burns—สภาวะเชิงประกาศ, controllers, การสเกล และการปฏิบัติการบริการ—และเหตุใดแนวคิดเหล่านี้จึงกลายเป็นมาตรฐาน
ทำไม Kubernetes ถึงเปลี่ยนรูปแบบการปฏิบัติการประจำวัน
Kubernetes ไม่ได้แค่เสนอเครื่องมือใหม่—มันเปลี่ยนภาพของ “งานปฏิบัติการประจำวัน” เมื่อคุณรันบริการเป็นสิบหรือเป็นร้อย ก่อนยุค orchestration ทีมมักต่อต่อสคริปต์ runbook ด้วยความรู้แบบเฉพาะกลุ่มเพื่อตอบคำถามซ้ำๆ: บริการนี้ควรไปรันที่ไหน? เราจะปล่อยการเปลี่ยนแปลงอย่างปลอดภัยได้อย่างไร? จะเกิดอะไรขึ้นถ้าโหนดพังตอนตีสอง?
สิ่งที่ “orchestration” แก้ปัญหาจริงๆ
โดยแก่นแท้แล้ว orchestration คือชั้นประสานระหว่างความตั้งใจของคุณ ("รันบริการนี้แบบ นี้") กับความวุ่นวายของความเป็นจริง—เครื่องล้ม, ทราฟฟิกเปลี่ยน, และการปรับใช้ต่อเนื่อง แทนที่จะมองเซิร์ฟเวอร์แต่ละเครื่องเป็นเอกเทศ orchestration มองการประมวลผลเป็นพูลและ workloads เป็นหน่วยที่ตั้งเวลาได้และย้ายได้
Kubernetes ทำให้แบบจำลองที่ทีมอธิบายสิ่งที่ต้องการ แล้วระบบพยายามทำให้ความจริงตรงกับคำอธิบายนั้นเป็นที่นิยม การเปลี่ยนแปลงนี้สำคัญเพราะทำให้งานปฏิบัติการน้อยลงเรื่อง “ฮีโร่” และมากขึ้นเรื่องกระบวนการที่ทำซ้ำได้
ผลลัพธ์สามอย่างที่ทีมรู้สึกได้ทันที
Kubernetes ทำให้ผลลัพธ์การปฏิบัติการที่ทีมส่วนใหญ่ต้องการเป็นมาตรฐาน:
- การปรับใช้: วิธีที่สม่ำเสมอในการประกาศว่าจะรันอะไร, อัพเดตมัน, และตรวจสอบว่ามันมีสุขภาพดี
- การสเกล: เส้นทางปฏิบัติจากอินสแตนซ์เดียวไปสู่หลายตัว โดยไม่ต้องออกแบบบริการใหม่หรือเตรียมเครื่องด้วยมือ
- การปฏิบัติการของบริการ: วิธีที่เสถียรให้บริการหากัน เจาะจราจร และทำงานต่อเมื่ออินสแตนซ์เปลี่ยน
ข้อสังเกตเรื่องขอบเขตและแหล่งข้อมูล
บทความนี้เน้นแนวคิดและรูปแบบที่เกี่ยวกับ Kubernetes (และผู้นำความคิดอย่าง Brendan Burns) มากกว่าจะเป็นชีวประวัติส่วนบุคคล และเมื่อเราพูดว่า “มันเริ่มอย่างไร” หรือ “ทำไมออกแบบแบบนี้” ข้อกล่าวอ้างควรตั้งอยู่บนแหล่งสาธารณะ—เช่น การบรรยายในงาน, เอกสารออกแบบ, และเอกสารอัปสตรีม—เพื่อให้เรื่องราวตรวจสอบได้แทนที่จะเป็นตำนาน
Brendan Burns ในเรื่องราวต้นกำเนิดของ Kubernetes (ระดับสูง)
Brendan Burns ถูกยอมรับอย่างกว้างขวางว่าเป็นหนึ่งในสามผู้ก่อตั้งดั้งเดิมของ Kubernetes ร่วมกับ Joe Beda และ Craig McLuckie ในงานเริ่มแรกของ Kubernetes ที่ Google Burns ช่วยกำหนดทิศทางทางเทคนิคและวิธีอธิบายโครงการให้ผู้ใช้—โดยเฉพาะด้าน “การดำเนินงานซอฟต์แวร์” มากกว่าแค่ “การรันคอนเทนเนอร์” (แหล่งที่มา: Kubernetes: Up & Running, O’Reilly; รายการ AUTHORS/maintainers ในที่เก็บโครงการ Kubernetes)
ความร่วมมือแบบโอเพนซอร์สหล่อหลอมการออกแบบ
Kubernetes ไม่ได้ถูกปล่อยออกมาเป็นระบบภายในที่เสร็จแล้ว; มันถูกสร้างแบบเปิดด้วยผู้ร่วมพัฒนาที่เพิ่มขึ้น กรณีการใช้งาน และข้อจำกัด ความเป็นสาธารณะนั้นผลักดันโครงการให้มุ่งสู่ส่วนติดต่อ (API) ที่ยั่งยืนในสภาพแวดล้อมต่างๆ:
- API ที่ชัดเจนและมีเวอร์ชัน แทนรายละเอียดการใช้งานที่ซ่อนอยู่
- พฤติกรรมที่พกพาได้ระหว่างผู้ให้บริการคลาวด์และการติดตั้งบนเซิร์ฟเวอร์ขององค์กร
- จุดขยายเพื่อให้คอร์ยังเล็กพอและรองรับความต้องการหลากหลายได้
แรงกดดันจากการร่วมมือแบบนี้สำคัญเพราะมันมีอิทธิพลต่อสิ่งที่ Kubernetes ปรับให้เหมาะสม: พรีมิติฟร่วมกันและรูปแบบที่ทำซ้ำได้ที่หลายทีมเห็นด้วย แม้จะไม่เห็นด้วยในเครื่องมือก็ตาม
“การทำให้เป็นมาตรฐาน” หมายความว่าอะไรที่นี่
เมื่อคนพูดว่า Kubernetes “ทำให้เป็นมาตรฐาน” ทางปฏิบัติ พวกเขาไม่ได้หมายความว่ามันทำให้ทุกระบบเหมือนกัน พวกเขาหมายถึงมันให้คำศัพท์ร่วมและเวิร์กโฟลว์ที่ทำซ้ำได้ระหว่างทีม:
- คำว่า “deployment,” “service,” “ingress,” “job,” “namespace” เป็นคำร่วม
- แบบจำลองที่สอดคล้องกันในการประกาศสิ่งที่ต้องการ (และปล่อยให้ระบบทำให้เป็นจริง)
- วิธีที่ทำนายได้ในการโรลเอาท์ การสเกล และการกู้คืนจากความล้มเหลว
แบบจำลองร่วมนี้ทำให้เอกสาร เครื่องมือ และแนวปฏิบัติของทีมถ่ายโอนกันได้ง่ายขึ้นระหว่างบริษัท
Kubernetes เป็นโครงการ vs ระบบนิเวศ
ควรแยก Kubernetes (โครงการโอเพนซอร์ส) ออกจาก ระบบนิเวศ Kubernetes
โครงการคือ API คอร์และส่วนควบคุมที่ทำงานเป็นแพลตฟอร์ม ส่วนระบบนิเวศคือทุกอย่างที่เติบโตรอบๆ มัน—การแจกจ่าย บริการที่จัดการ add-ons และโครงการ CNCF ที่เกี่ยวข้อง คุณสมบัติหลายอย่างที่ทีมพึ่งพาในโลกจริง (เช่น สแตกการสังเกต, เอนจินนโยบาย, เครื่องมือ GitOps) มักจะอยู่ในระบบนิเวศ ไม่ได้อยู่ในคอร์โปรเจกต์เอง
ไอเดียหลัก: สถานะที่ต้องการเชิงประกาศ (Declarative Desired State)
การตั้งค่าเชิงประกาศเป็นการเปลี่ยนวิธีอธิบายระบบ: แทนการเขียนลำดับขั้นตอน ให้ระบุสิ่งที่คุณต้องการเป็นผลลัพธ์สุดท้าย
ในคำศัพท์ของ Kubernetes คุณไม่บอกแพลตฟอร์มว่า “สตาร์ทคอนเทนเนอร์แล้วเปิดพอร์ตแล้วรีสตาร์ทถ้ามันแครช” คุณประกาศว่า "ควรมีสำเนาแอป 3 ตัว รันบนพอร์ตนี้ โดยใช้อิมเมจคอนเทนเนอร์นี้" Kubernetes รับผิดชอบทำให้ความเป็นจริงตรงกับคำอธิบายนั้น
สภาวะที่ต้องการ vs สคริปต์เชิงคำสั่ง
ปฏิบัติการเชิงคำสั่งเหมือน runbook: ลำดับคำสั่งที่ใช้ได้ผลครั้งก่อนและรันซ้ำเมื่อมีการเปลี่ยน
สภาวะที่ต้องการใกล้เคียงกับข้อตกลง คุณบันทึกผลลัพธ์ที่ตั้งใจไว้ในไฟล์คอนฟิก และระบบจะพยายามทำให้ผลลัพธ์นั้นเป็นจริงอย่างต่อเนื่อง หากบางอย่างเบี้ยว—อินสแตนซ์ตาย, โหนดหาย, หรือมีการเปลี่ยนแปลงด้วยมือ—แพลตฟอร์มจะตรวจจับและแก้ไขให้
ก่อน/หลัง: คำสั่ง runbook vs YAML
ก่อน (แนวคิด runbook แบบเชิงคำสั่ง):
- SSH เข้าเซิร์ฟเวอร์
- ดึงอิมเมจคอนเทนเนอร์ใหม่
- หยุดโปรเซสเก่า
- สตาร์ทโปรเซสใหม่
- อัปเดตกฎ load balancer
- ถ้าทราฟฟิกพุ่ง ให้ทำซ้ำบนเซิร์ฟเวอร์อื่น
แนวทางนี้ใช้ได้ แต่ทำให้เกิดเซิร์ฟเวอร์แบบ “snowflake” และรายการตรวจสอบยาวที่มีคนจำนวนน้อยเท่านั้นเชื่อใจได้
หลัง (สภาวะเชิงประกาศ):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
คุณแก้ไฟล์ (เช่น อัปเดต image หรือ replicas) แล้ว apply มัน controllers ของ Kubernetes จะพยายาม reconcile สิ่งที่รันกับสิ่งที่ประกาศ
ทำไมมันลดงานซ้ำและการเบี้ยวของคอนฟิก
สภาวะเชิงประกาศลดงานซ้ำด้วยการเปลี่ยนจาก “ทำ 17 ขั้นตอนนี้” เป็น “รักษาให้เป็นแบบนี้” และลดการเบี้ยวของคอนฟิกเพราะแหล่งความจริงชัดเจนและตรวจทานได้—มักเก็บในระบบควบคุมเวอร์ชัน ทำให้การเซอร์ไพรซ์ตรวจเจอได้ง่ายและย้อนกลับได้อย่างสม่ำเสมอ
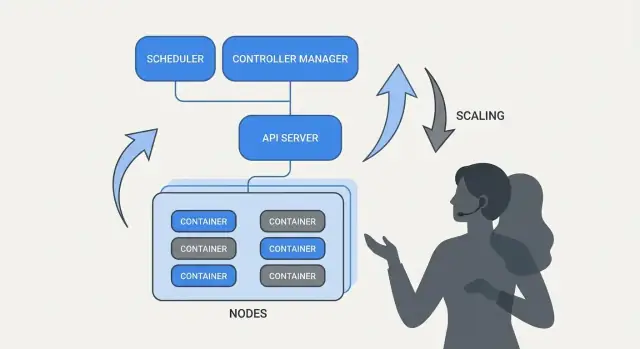
Controllers และ Reconciliation: ระบบที่คงสิ่งที่ตั้งใจไว้ให้จริง
Kubernetes ดูเหมือน “จัดการตัวเอง” เพราะมันสร้างบนรูปแบบง่ายๆ: คุณประกาศสิ่งที่ต้องการ แล้วระบบทำงานต่อเนื่องเพื่อให้ความจริงตรงกับคำประกาศ เครื่องยนต์ของรูปแบบนี้คือ controller
Controller คืออะไร (พูดง่ายๆ)
Controller เป็นลูปที่เฝ้าดูสถานะปัจจุบันของคลัสเตอร์และเทียบกับสถานะที่คุณประกาศใน YAML (หรือผ่าน API) เมื่อมันพบความต่าง มันจะทำการเพื่อลดความต่างนั้น
มันไม่ใช่สคริปต์รันครั้งเดียวและไม่รอมนุษย์กดปุ่ม มันรันซ้ำๆ—สังเกต ตัดสินใจ ปฏิบัติ—เพื่อจะตอบสนองต่อการเปลี่ยนแปลงได้ทุกเมื่อ
Reconciliation: วิธีที่ Kubernetes “รักษาให้ถูกต้อง”
พฤติกรรมเปรียบเทียบและแก้ไขซ้ำๆ นี้เรียกว่า reconciliation มันคือกลไกเบื้องหลังคำสัญญาทั่วไปเรื่อง “self-healing” ระบบไม่ได้ป้องกันความล้มเหลวได้วิเศษ แต่มันสังเกตการเบี้ยวและแก้ไข
การเบี้ยวเกิดจากเหตุผลธรรมดาๆ:
- กระบวนการแครช
- โหนดหายไป
- ใครบางคนสเกลขึ้นลงด้วยมือ
- การอัปเดต deployment
Reconciliation ทำให้ Kubernetes มองเหตุการณ์เหล่านี้เป็นสัญญาณเพื่อเช็กเจตนาและคืนสภาพตามที่ต้องการ
ผลลัพธ์ที่ผู้คนสนใจจริงๆ
Controllers แปลเป็นผลลัพธ์การปฏิบัติการที่คุ้นเคย:
- ทดแทน pods ที่ล้ม: ถ้า pod ตาย controller สังเกตว่าคุณยังต้องการมันและจัดตารางตัวใหม่
- รักษาจำนวน replica: ถ้าคุณขอ 5 replicas แต่มีแค่ 4 Kubernetes จะสร้างที่ขาดหายไป
- รักษาความก้าวหน้าในการโรลเอาท์: ระหว่างการอัปเดต controllers ค่อยๆ ย้ายระบบไปเวอร์ชันใหม่ในการรักษาความพร้อมตามที่ต้องการ
จุดสำคัญคือคุณไม่ตามอาการด้วยมืออีกต่อไป คุณประกาศเป้าหมายและ control loops ทำงานต่อเนื่องให้เป็นอย่างนั้น
ทำไมแนวทางนี้ขยายเกินกว่าหนึ่งฟีเจอร์
แนวทางนี้ไม่ได้จำกัดแค่ชนิดทรัพยากรเดียว Kubernetes ใช้แนวคิด controller-and-reconciliation กับหลายออบเจ็กต์—Deployments, ReplicaSets, Jobs, Nodes, endpoints และอื่นๆ ความสอดคล้องนี้เป็นเหตุผลสำคัญที่ Kubernetes กลายเป็นแพลตฟอร์ม: เมื่อคุณเข้าใจรูปแบบ คุณทำนายพฤติกรรมของระบบได้เมื่อเพิ่มความสามารถใหม่ๆ (รวมถึง custom resources ที่ทำตามลูปเดียวกัน)
การจัดตารางเป็นฟีเจอร์ผลิตภัณฑ์ ไม่ใช่งานด้วยมือ
เปิดตัวเว็บแอป
สร้าง UI ด้วย React ที่ตรงตามขอบเขตบริการและจังหวะการปล่อยของคุณ
ถ้า Kubernetes ทำได้แค่ “รันคอนเทนเนอร์” มันก็ยังปล่อยทีมให้ต้องตัดสินใจว่า ที่ไหน ควรให้ workload แต่ละตัวรัน การจัดตารางคือระบบในตัวที่วาง Pods บนโหนดที่เหมาะสมโดยอัตโนมัติตามความต้องการทรัพยากรและกฎที่คุณกำหนด
สิ่งนี้สำคัญเพราะการตัดสินใจเรื่องที่วางส่งผลโดยตรงต่อ uptime และต้นทุน Web API ที่อยู่บนโหนดแออัดอาจช้า หรือแครช งานแบทช์ที่อยู่ใกล้บริการที่ต้องตอบสนองเร็วอาจสร้างปัญหา noisy-neighbor Kubernetes เปลี่ยนสิ่งนี้เป็นความสามารถผลิตภัณฑ์ที่ทำซ้ำได้แทนการทำสเปรดชีตและ SSH
ตัวจัดตารางพยายามเพิ่มประสิทธิภาพอะไร
ในระดับพื้นฐาน scheduler มองหาโหนดที่สามารถตอบสนองคำขอของ Pod ได้
- คำขอ CPU/หน่วยความจำ: requests จองความจุสำหรับการตัดสินใจวาง หากคุณขอ 500m CPU และ 1Gi memory Kubernetes จะพิจารณาโหนดที่มีทรัพยากรเพียงพอเท่านั้น
นิสัยเดียวนี้—การตั้ง requests ที่สมจริง—มักลดความไม่เสถียรแบบสุ่มเพราะบริการสำคัญหยุดแข่งขันกับทุกอย่างอื่น
ข้อจำกัดที่ทีมมักใช้จริง
นอกจากทรัพยากร คลัสเตอร์โปรดักชันส่วนใหญ่พึ่งพากฎปฏิบัติไม่กี่อย่าง:
- Affinity / anti-affinity: “วางด้วยกัน” (เพื่อ locality ของแคช) หรือ “แยกจากกัน” (เพื่อหลีกเลี่ยงความล้มเหลวของโหนดเดียวที่กระทบทุกสำเนา)
- Taints and tolerations: ทำเครื่องหมายโหนดบางตัวว่าเป็นจุดประสงค์พิเศษ (โหนด GPU, โหนดระบบ, โหนดตามข้อกำหนด) และอนุญาตเฉพาะ workload ที่ได้รับอนุญาตให้ลงที่นั่น
วิธีนี้ลดการหยุดให้บริการได้อย่างไร
ฟีเจอร์การจัดตารางช่วยทีมเข้ารหัสเจตนาการปฏิบัติการ:
- กระจาย replicas ข้ามโหนดเพื่ออยู่รอดจากความล้มเหลวของโหนด
- แยกงานที่มีสไปค์ออกจากบริการที่ต้องตอบสนองต่อผู้ใช้
- ป้องกันไม่ให้โหนดมีค่าใช้จ่ายสูง (เช่น GPU) ถูกใช้งานโดย workload ผิดประเภท
ข้อสรุปทางปฏิบัติ: ปฏิบัติต่อกฎการจัดตารางเหมือนความต้องการผลิตภัณฑ์—จดบันทึก ทบทวน และใช้สม่ำเสมอ—เพื่อให้ความน่าเชื่อถือไม่ขึ้นกับใครคนหนึ่งที่จำตำแหน่งโหนดได้ในตีสอง
การสเกล: จากอินสแตนซ์เดียวสู่พันๆ โดยไม่ต้องเขียนใหม่
หนึ่งในไอเดียที่ใช้งานได้จริงของ Kubernetes คือการสเกลไม่ควรต้องเปลี่ยนโค้ดแอปหรือคิดวิธีปรับใช้ใหม่ หากแอปรันเป็นคอนเทนเนอร์หนึ่งตัว นิยาม workload เดียวกันมักขยายได้เป็นร้อยหรือพันสำเนา
การสเกลมีสองชั้น
Kubernetes แยกการสเกลเป็นสองการตัดสินใจที่เกี่ยวข้อง:
- ควรรันกี่ Pod (จำนวนสำเนาเพื่อเพิ่มทราฟฟิกหรือความทนทาน)
- ความจุของคลัสเตอร์มีเท่าไร (มีโหนดเพียงพอและขนาดที่เหมาะสมเพื่อวางพ็อดเหล่านั้น)
การแยกนี้สำคัญ: คุณอาจขอ 200 pods แต่ถ้าคลัสเตอร์มีที่ว่างแค่ 50 การ “สเกล” จะกลายเป็นคิวงานที่รอการจัดตาราง
แนวคิดการสเกลอัตโนมัติ (HPA, VPA, Cluster Autoscaler)
Kubernetes มักใช้สามตัวช่วย autoscale ที่มุ่งไปที่คันโยกต่างกัน:
- Horizontal Pod Autoscaler (HPA): เปลี่ยน จำนวน pods ตามสัญญาณเช่นการใช้งาน CPU, memory หรือเมตริกแอปเฉพาะ
- Vertical Pod Autoscaler (VPA): ปรับ requests/limits ของ pod เพื่อให้แต่ละ pod ได้ CPU/หน่วยความจำมากขึ้นหรือน้อยลง
- Cluster Autoscaler: เพิ่มหรือลด โหนด เพื่อให้ scheduler มีที่วางพ็อดที่คุณขอ
ใช้ร่วมกัน สิ่งนี้ทำให้การสเกลกลายเป็นนโยบาย: “รักษา latency ให้คงที่” หรือ “รักษา CPU ที่ประมาณ X%” แทนการโทรปลุกด้วยมือ
สิ่งที่ “การสเกลที่ดี” ขึ้นอยู่กับ
การสเกลทำงานได้เท่าที่อินพุตจะดี:
- เมตริก: CPU ง่ายแต่ไม่เสมอไปที่สื่อความหมาย; อัตราการร้องขอ, ความลึกคิว และความหน่วงมักสะท้อนโหลดจริงได้ดีกว่า
- requests/limits: บอก scheduler ว่า Pod ต้องการอะไร หากไม่มี พิกัดการวางและการทำ autoscale จะกลายเป็นการคาดเดา
- รูปแบบโหลด: ทราฟฟิกที่เป็นสไปค์, อัตราการอุ่นตัวช้า, งานแบ็กกราวด์หนัก เปลี่ยนความเร็วที่การสเกลควรตอบสนอง
กับดักที่พบบ่อย
สองความผิดพลาดที่ปรากฏบ่อย: สเกลบนเมตริกที่ผิด (CPU ต่ำแต่การร้องขอล้มเหลว) และ ขาด requests (autoscaler คาดการณ์ความจุไม่ได้ พ็อดถูกยัดรวมกันมากเกินไป และประสิทธิภาพไม่สม่ำเสมอ)
การปรับใช้ที่ปลอดภัย: โรลเอาท์, เช็กสุขภาพ, และการย้อนกลับ
การเปลี่ยนแปลงใหญ่ที่ Kubernetes ทำให้เป็นที่นิยมคือการมองการ “deploy” เป็นปัญหาการควบคุมอย่างต่อเนื่อง ไม่ใช่สคริปต์ครั้งเดียวที่รันวันศุกร์เวลา 5 โมง โรลเอาท์และการย้อนกลับเป็นพฤติกรรมระดับหนึ่ง: คุณประกาศเวอร์ชันที่ต้องการ และ Kubernetes ค่อยๆ ย้ายระบบไปทางนั้นพร้อมตรวจสอบความปลอดภัยของการเปลี่ยน
โรลเอาท์ในฐานะการเปลี่ยนผ่านที่ควบคุมได้
ด้วย Deployment การโรลเอาท์คือการแทนที่ Pods เก่าแบบค่อยเป็นค่อยไป แทนที่จะหยุดทุกอย่างแล้วเริ่มใหม่ Kubernetes สามารถอัปเดตเป็นขั้นตอน—รักษาความสามารถให้บริการในขณะที่เวอร์ชันใหม่พิสูจน์ตัวเองกับทราฟฟิกจริง
ถ้าเวอร์ชันใหม่เริ่มล้ม การย้อนกลับไม่ใช่ขั้นตอนฉุกเฉิน แต่เป็นการปฏิบัติการปกติ: คุณสามารถย้อนกลับไปยัง ReplicaSet ก่อนหน้า (เวอร์ชันที่รู้ว่าดีล่าสุด) แล้วให้ controller คืนสภาพเก่า
Probes: ป้องกันการปล่อย "รันแต่แย่"
เช็กสุขภาพทำให้โรลเอาท์จากการหวังผลเป็นการวัดผลจริง
- Readiness probes ระบุว่า Pod ควรรับทราฟฟิกหรือไม่ คอนเทนเนอร์อาจรันอยู่แต่ยังไม่พร้อม (กำลังอุ่นแคช รอ dependency) Readiness ป้องกันไม่ให้ส่งผู้ใช้ไปยังอินสแตนซ์ที่ตอบไม่ได้อย่างถูกต้อง
- Liveness probes ตรวจจับเมื่อคอนเทนเนอร์ติดหรือไม่สุขภาพและต้องการรีสตาร์ท ช่วยหลีกเลี่ยงโหมดล้มเหลวช้าๆ ที่โปรเซสยัง “มีชีวิต” แต่ทำงานไม่ได้
ใช้ probes ดีๆ จะลดความสำเร็จเทียม—deploy ที่ ดู ว่าดีเพราะ Pods สตาร์ท แต่จริงๆ ล้มเหลวเมื่อรับคำขอ
กลยุทธ์การปรับใช้: rolling, blue/green, canary
Kubernetes รองรับ rolling update โดยพื้นฐาน แต่ทีมมักวางรูปแบบเพิ่มเติม:
- Blue/green: มีสองสภาพแวดล้อมเต็มรูปแบบแล้วสลับทราฟฟิกเมื่อ green ตรวจสอบแล้ว
- Canary: ส่งส่วนน้อยของทราฟฟิกไปยังเวอร์ชันใหม่ ดูเมตริกแล้วขยายทีละน้อย
ความปลอดภัยที่วัดได้ (และอัตโนมัติ)
การปรับใช้ที่ปลอดภัยขึ้นกับสัญญาณ: อัตราข้อผิดพลาด, ความหน่วง, ความอิ่มตัว และผลกระทบต่อลูกค้า ทีมจำนวนมากเชื่อมการตัดสินใจโรลเอาท์เข้ากับ SLOs และ error budgets—ถ้า canary เบิร์นงบเกิน ระบบจะหยุดการโปรโมต
เป้าหมายคือทริกเกอร์การย้อนกลับอัตโนมัติบนตัวชี้วัดจริง (readiness ล้มเหลว, 5xx เพิ่มขึ้น, latency พุ่ง) เพื่อให้การย้อนกลับเป็นการตอบสนองของระบบที่คาดเดาได้ ไม่ใช่ภารกิจฮีโร่ยามดึก
การปฏิบัติการบริการ: การค้นหาเสิร์ฟวิส, การกำหนดเส้นทาง, และเครือข่ายที่เสถียร
สร้างจากสเปคเชิงประกาศ
เปลี่ยนสเปคที่พร้อมใช้งานด้านปฏิบัติการให้เป็นแอปจริงที่คุณสามารถปรับใช้และวนพัฒนาได้อย่างรวดเร็ว
แพลตฟอร์มคอนเทนเนอร์จะรู้สึกว่า “อัตโนมัติ” ก็ต่อเมื่อส่วนอื่นของระบบยังหาบริการคุณได้หลังจากมันย้าย ในคลัสเตอร์โปรดักชันจริง พ็อดถูกสร้าง ลบ ย้าย และสเกลตลอดเวลา ถ้าทุกการเปลี่ยนแปลงต้องแก้ IP ในคอนฟิก การปฏิบัติการจะกลายเป็นงานไม่หยุดและการหยุดให้บริการจะเกิดขึ้นบ่อย
ทำไม service discovery ถึงสำคัญ
Service discovery ให้ไคลเอนต์วิธีที่เชื่อถือได้ในการเข้าถึงชุด backend ที่เปลี่ยนแปลง ใน Kubernetes จุดเปลี่ยนคือคุณหยุดเป้าหมายอินสแตนซ์เฉพาะ ("เรียก 10.2.3.4") และแทนที่ด้วยชื่อที่คงที่ ("เรียก checkout") แพลตฟอร์มดูแลว่าพ็อดไหนให้บริการชื่อนั้นอยู่
Services, selectors, และ endpoints (อธิบายง่ายๆ)
Service เป็นหน้าประตูที่คงที่สำหรับกลุ่มพ็อด มีชื่อและที่อยู่เสมอภายในคลัสเตอร์ แม้พ็อดข้างใต้จะเปลี่ยน
Selector คือวิธีที่ Kubernetes ตัดสินใจว่าพ็อดไหนอยู่ “ข้างหลัง” หน้าประตูนั้น โดยทั่วไปใช้ labels เช่น app=checkout
Endpoints (หรือ EndpointSlices) คือรายการไอพีพ็อดปัจจุบันที่ตรงกับ selector เมื่อพ็อดสเกลขึ้น โรลเอาท์ หรือย้าย รายการนี้จะอัพเดตอัตโนมัติ—ไคลเอนต์ยังคงใช้ชื่อ Service เดิม
ที่อยู่ที่คงที่, โหลดบาลานซ์, และการกำหนดเส้นทางทราฟฟิก
เชิงปฏิบัติ สิ่งนี้ให้:
- ที่อยู่คงที่: แอปคุยกับชื่อ DNS ของ Service แทนการไล่หาที่อยู่ IP ของพ็อด
- โหลดบาลานซ์: ทราฟฟิกถูกกระจายไปพ็อดที่พร้อมใช้งาน
- การกำหนดเส้นทางที่ทำนายได้: แยก “ใครควรรับทราฟฟิก” (labels/selectors) ออกจาก “พ็อดอยู่ที่ไหนในตอนนั้น”
สำหรับทราฟฟิกนอกคลัสเตอร์ (north–south) Kubernetes มักใช้ Ingress หรือแนวทางใหม่กว่าอย่าง Gateway ทั้งสองให้จุดเข้าออกที่ควบคุมได้เพื่อกำหนดเส้นทางตามชื่อโฮสต์หรือพาธ และมักรวมการสิ้นสุด TLS ไว้ที่เดียว แนวคิดสำคัญยังคงเดิม: รักษาการเข้าถึงภายนอกให้คงที่ในขณะที่ backend เปลี่ยนไป
การฟื้นตัวอัตโนมัติ: ความหมายจริงในโปรดักชัน
“Self-healing” ใน Kubernetes ไม่ใช่เวทมนตร์ มันคือชุดการตอบสนองอัตโนมัติเมื่อเกิดความล้มเหลว: รีสตาร์ท, ย้ายใหม่, และ ทดแทน แพลตฟอร์มเฝ้าดูสิ่งที่คุณประกาศ (desired state) และคอยผลักดันความจริงกลับไปทางนั้น
รีสตาร์ท: เมื่อคอนเทนเนอร์แครช
ถ้ากระบวนการออกหรือคอนเทนเนอร์ไม่สุขภาพ Kubernetes สามารถรีสตาร์ทมันบนโหนดเดิมได้ มักขับเคลื่อนโดย:
- Liveness probes: "คอนเทนเนอร์ยังทำงานอยู่ไหม?" ถ้าไม่ ให้รีสตาร์ท
- Restart policies: กฎว่าควรรีสตาร์ทเมื่อไร
รูปแบบโปรดักชันที่พบบ่อย: คอนเทนเนอร์แครช → Kubernetes รีสตาร์ทมัน → Service ยังคงส่งทราฟฟิกเฉพาะไปยังพ็อดที่พร้อม
ย้ายใหม่และทดแทน: เมื่อโหนดพัง
ถ้าโหนดทั้งตัวล้ม (ฮาร์ดแวร์, kernel panic, เสียการเชื่อมต่อ) Kubernetes ตรวจจับว่าโหนดไม่พร้อมและเริ่มย้ายงานไปที่อื่น ในภาพรวม:
- โหนดถูกทำเครื่องหมายว่าไม่พร้อม
- พ็อดที่รันอยู่ที่นั่นถือว่าเสียหาย
- Controllers สร้างพ็อดทดแทนบนโหนดที่พร้อมเพื่อคืนจำนวน replica ที่ต้องการ
นี่คือการฟื้นตัวในระดับคลัสเตอร์: ระบบทดแทนความจุมากกว่ารอให้มนุษย์ SSH เข้าไป
การสังเกตเหตุการณ์: คุณรู้ได้อย่างไรว่าระบบกำลังฟื้น
การฟื้นตัวมีประโยชน์เมื่อคุณตรวจสอบได้ ทีมมักดู:
- Logs (ทั้งล็อกแอปและเหตุการณ์แพลตฟอร์ม) เพื่อดูว่าอะไรรีสตาร์ทและเพราะอะไร
- Metrics เช่น จำนวนการรีสตาร์ท, probe ล้ม, และสถานะ readiness ของโหนด
- Alerts เมื่อการฟื้นไม่ทำงาน (เช่น CrashLoopBackOff ซ้ำๆ, ขาด replica, หรือการไล่ eviction มากเกิน)
การกำหนดค่าผิดที่ทำให้การฟื้นล้มเหลว
แม้ใช้ Kubernetes การ "ฟื้น" อาจล้มเหลวหากการ์ดการ์ดล้ม:
- liveness/readiness probes ผิดหรือขาด (สัญญาณบวกลวงหรือพ็อดไม่เคยพร้อม)
- ขาด requests/limits ทำให้การจัดตารางหรือ OOM เกิดขึ้นไม่คาดคิด
- replica น้อยเกิน (พ็อดเดียวไม่สามารถให้ความต่อเนื่อง)
- การตั้งค่า probe กระชั้นเกินไปที่ทำให้เกิดรีสตาร์ทเป็นพายุ
- workload พึ่งพาสถานะบนโหนดโดยไม่มีกลยุทธ์เก็บข้อมูลทนทาน
เมื่อการฟื้นถูกตั้งค่าอย่างดี การหยุดให้บริการจะสั้นลงและวัดผลได้มากขึ้น
API มาตรฐานและการขยาย: Kubernetes กลายเป็นแพลตฟอร์มอย่างไร
วางแผนการโรลเอาท์ก่อน
ใช้โหมดวางแผนเพื่อแม็ปรายการบริการ, API และการโรลเอาท์ก่อนเปลี่ยนแปลงโค้ด
Kubernetes ไม่ได้ชนะเพราะรันคอนเทนเนอร์ได้เพียงอย่างเดียว แต่เพราะมันเสนอ API มาตรฐาน สำหรับความต้องการการปฏิบัติการทั่วไป—การปรับใช้ การสเกล เครือข่าย และการสังเกต เมื่อทีมยอมรับรูปแบบวัตถุเดียวกัน (เช่น Deployments, Services, Jobs) เครื่องมือสามารถแชร์ข้ามองค์กร การฝึกอบรมง่ายขึ้น และการส่งมอบระหว่าง dev กับ ops ไม่ต้องพึ่งความรู้แบบกลุ่ม
ทำไม API มาตรฐานเปลี่ยนเวิร์กโฟลว์ของทีม
API ที่สม่ำเสมอหมายความว่า pipeline การปรับใช้ของคุณไม่ต้องรู้ quirks ของแต่ละแอป มันสามารถทำการเดียวกัน—create, update, rollback, และเช็กสุขภาพ—โดยใช้แนวคิด Kubernetes เดียวกัน
นอกจากนี้ยังปรับปรุงการประสานงาน: ทีมความปลอดภัยสามารถกำหนด guardrails เป็นนโยบาย; SRE สามารถมาตรฐาน runbook รอบสัญญาณสุขภาพทั่วไป; นักพัฒนาสามารถคิดเรื่องการปล่อยด้วยคำศัพท์ร่วมกัน
ขยาย Kubernetes: CRDs และ Operators
การเปลี่ยนเป็นแพลตฟอร์มชัดเจนด้วย Custom Resource Definitions (CRDs) CRD ให้คุณเพิ่มชนิดออบเจ็กต์ใหม่ในคลัสเตอร์ (เช่น Database, Cache, หรือ Queue) และจัดการมันด้วยรูปแบบ API เดียวกับทรัพยากรในตัว
Operator จับวัตถุแบบกำหนดเองเหล่านั้นกับ controller ที่ reconcile ความเป็นจริงตามสภาวะที่ต้องการ—จัดการงานที่เคยทำด้วยมือ เช่น สำรองข้อมูล, failover, หรืการอัปเกรด เวลาประโยชน์ไม่ใช่เวทมนตร์อัตโนมัติ แต่มาจาก การใช้ลูปควบคุมแบบเดียวกัน ที่ Kubernetes ใช้กับทุกอย่าง
เข้ากับ GitOps, CI/CD และการตรวจสอบนโยบาย
เพราะ Kubernetes ขับเคลื่อนด้วย API มันรวมเข้ากับเวิร์กโฟลว์สมัยใหม่ได้ดี:
- GitOps: สถานะที่ต้องการอยู่ใน Git; การเปลี่ยนแปลงถูกตรวจทานเหมือนโค้ด
- CI/CD: pipeline สามารถ apply manifests รอ readiness และโปรโมตเวอร์ชัน
- การตรวจสอบนโยบาย: admission controllers สามารถบล็อกคอนฟิกเสี่ยงก่อนเข้าผลิต
ถ้าคุณต้องการคำแนะนำการปรับใช้และการปฏิบัติการที่เป็นประโยชน์มากขึ้นบนแนวคิดเหล่านี้ ลองเรียกดู /blog
ทีมสามารถนำไปใช้วันนี้ได้อย่างไร (แม้นอก Kubernetes)
ไอเดียใหญ่จาก Kubernetes—หลายอย่างเกี่ยวข้องกับการวางกรอบตอนต้นโดย Brendan Burns—สามารถแปลใช้ได้ดีแม้คุณรันบน VM, serverless, หรือคอนเทนเนอร์ที่เล็กกว่า
รูปแบบที่ปรับปรุงการปฏิบัติการรายวัน
จงจด "สถานะที่ต้องการ" และให้ระบบอัตโนมัติบังคับใช้มัน. ไม่ว่าจะเป็น Terraform, Ansible, หรือ pipeline CI ให้จัดการคอนฟิกเป็นแหล่งความจริง ผลลัพธ์คือขั้นตอนปรับใช้ด้วยมือที่น้อยลงและความประหลาดใจก้อน้อยลง
ใช้ reconciliation แทนสคริปต์ครั้งเดียว. แทนสคริปต์รันครั้งเดียวและหวังผล สร้างลูปที่ตรวจสอบคุณสมบัติเชิงสำคัญอย่างต่อเนื่อง (เวอร์ชัน, คอนฟิก, จำนวนอินสแตนซ์, สุขภาพ) นี่คือวิธีที่คุณได้ปฏิบัติการที่ทำซ้ำได้และการกู้คืนที่คาดเดาได้
ทำให้การจัดตารางและการสเกลเป็นฟีเจอร์ผลิตภัณฑ์. นิยามเมื่อไหร่และทำไมคุณเพิ่มความจุ (CPU, ความลึกคิว, SLO ความหน่วง) แม้ไม่มี autoscaling ของ Kubernetes ทีมสามารถมาตรฐานกฎการสเกลเพื่อให้การเติบโตไม่ต้องเขียนแอปใหม่หรือปลุกใคร
มาตรฐานการโรลเอาท์. การอัปเดตทีละน้อย เช็กสุขภาพ และขั้นตอนย้อนกลับอย่างรวดเร็วลดความเสี่ยงของการเปลี่ยน คุณสามารถทำสิ่งนี้ด้วย load balancers, feature flags, และ pipeline ที่กั้นการปล่อยบนสัญญาณจริง
เช็คลิสต์การนำไปใช้อย่างปลอดภัย
- กำหนดสถานะที่ต้องการของบริการ: เวอร์ชัน, คอนฟิก, พึ่งพา, และจำนวนอินสแตนซ์ขั้นต่ำ
- เพิ่ม endpoints สุขภาพ (เทียบเท่า liveness และ readiness) และเชื่อมเข้ากับ load balancer หรือ pipeline การปรับใช้
- อัตโนมัติขั้นตอนการโรลเอาท์: ปรับใช้, ตรวจสอบ, ย้ายทราฟฟิก, และย้อนกลับเมื่อล้มเหลว
- สร้าง "reconciler" ขนาดเล็ก: การตรวจสอบตามกำหนดเพื่อแก้ไขการเบี้ยว (คอนฟิกผิด, อินสแตนซ์ขาด)
- เพิ่มทริกเกอร์การสเกลพร้อมขอบเขตชัดเจน (max instances, cooldowns, กฎอนุมัติ)
สิ่งที่รูปแบบเหล่านี้ไม่แก้ให้โดยลำพัง
รูปแบบเหล่านี้จะไม่แก้ การออกแบบแอปที่แย่, การย้ายข้อมูลที่ไม่ปลอดภัย, หรือ การควบคุมต้นทุน คุณยังต้องมี API ที่มีเวอร์ชัน, แผนการมิเกรชัน, งบประมาณ/ข้อจำกัด, และการสังเกตที่เชื่อมการปล่อยเข้ากับผลกระทบต่อลูกค้า
ขั้นตอนต่อไป
เลือกบริการที่หันหน้าเข้าลูกค้าหนึ่งชิ้นและทำเช็คลิสต์แบบ end-to-end แล้วขยายต่อ
ถ้าคุณกำลังสร้างบริการใหม่และต้องการไปสู่ "สิ่งที่ปรับใช้ได้" ได้เร็วขึ้น Koder.ai ช่วยคุณสร้างเว็บ/แบ็กเอนด์/มือถือจากสเปคแบบแชท—โดยทั่วไปเป็น React หน้า frontend, Go กับ PostgreSQL เป็นแบ็กเอนด์, และ Flutter สำหรับมือถือ—แล้วส่งออกรหัสต้นฉบับเพื่อให้คุณนำแนวทาง Kubernetes ที่กล่าวถึงที่นี่ไปใช้ (คอนฟิกเชิงประกาศ, โรลเอาท์ที่ทำซ้ำได้, และการปฏิบัติการที่รองรับ rollback) สำหรับทีมที่ประเมินต้นทุนและการกำกับดูแล คุณยังสามารถดู /pricing.
คำถามที่พบบ่อย
What problem does “orchestration” actually solve in day-to-day operations?
Orchestration ประสานเจตนารมณ์ของคุณ (สิ่งที่ควรจะรัน) กับความเปลี่ยนแปลงในโลกจริง (โหนดล้มเหลว, การโรลเอาท์แบบหมุนเวียน, เหตุการณ์การสเกล) แทนที่จะจัดการเซิร์ฟเวอร์ทีละเครื่อง คุณจะจัดการ workloads และปล่อยให้แพลตฟอร์มวาง ติดตั้งใหม่ และทดแทนให้โดยอัตโนมัติ
เชิงปฏิบัติ มันลด:
- การกำหนดตำแหน่งด้วยมือ ("จะไปโหนดไหน?")
- ขั้นตอนการปรับใช้ที่ขับเคลื่อนด้วย runbook
- การล่องลอยของการตั้งค่าจากการแก้ปัญหาแบบฉุกเฉิน
What does “declarative desired state” mean in Kubernetes terms?
การตั้งค่าแบบเชิงประกาศ (declarative) ระบุ ผลลัพธ์สุดท้าย ที่คุณต้องการ (เช่น “มีสำเนาแอป 3 ตัว ฟังพอร์ตนี้ ใช้อิมเมจนี้”) แทนการระบุลำดับขั้นตอน
ประโยชน์ที่ใช้ได้ทันที:
- คอนฟิกกลายเป็นแหล่งความจริงที่ตรวจทานได้ (มักเก็บใน Git)
- ระบบสามารถตรวจจับการล่องลอยและแก้ไขให้ตรงตามที่ประกาศ
- การย้อนสถานะ (rollback) ง่ายขึ้นเพราะสามารถย้อนกลับไปยังการประกาศที่รู้ว่าดีได้
What are controllers and reconciliation, and why do they matter?
Controller เป็นลูปที่รันต่อเนื่องซึ่งเปรียบเทียบ สถานะปัจจุบัน กับ สถานะที่ต้องการ และทำการเพื่อปิดช่องว่างนั้น
นี่คือเหตุผลที่ Kubernetes ดูเหมือนจะ “จัดการตัวเอง” ในผลลัพธ์ทั่วไป:
- สร้าง Pods ใหม่หลังจากเกิดการล้มเหลว
- รักษาจำนวนสำเนาเมื่อเกิดความผิดปกติ
- เดินหน้าหรือหยุดการโรลเอาท์ตามสัญญาณด้านสุขภาพ
How does Kubernetes scheduling reduce outages compared to manual placement?
ตัวจัดตาราง (scheduler) ตัดสินใจ ที่ไหน ให้แต่ละ Pod รัน โดยพิจารณาจากข้อจำกัดและความจุที่มี หากไม่ควบคุม อาจเกิดปัญหา noisy neighbor, hotspot หรือสำเนาไปอยู่ด้วยกันบนโหนดเดียว
กฎทั่วไปที่ควรเข้ารหัสเป็นนโยบายการปฏิบัติการ:
- กำหนด resource requests (CPU/หน่วยความจำ) เพื่อการวางแผนที่ทำนายได้
- ใช้ affinity/anti-affinity เพื่อกระจายหรือจัดวางร่วมกัน
- ใช้ taints/tolerations สำหรับโหนดเฉพาะทาง (GPU, ข้อกำหนดการปฏิบัติตาม, ระบบ)
Why are CPU/memory requests and limits so important?
Requests แจ้งให้ scheduler รู้ว่า Pod ต้องการอะไร; limits จำกัดสิ่งที่ Pod ใช้ได้จริง หากไม่มี requests ที่สมเหตุสมผล การวางตำแหน่งจะกลายเป็นการคาดเดาและเสถียรภาพมักจะทรุด
จุดเริ่มต้นเชิงปฏิบัติ:
- ตั้ง requests ให้ใกล้เคียงการใช้งานปกติ
- ตั้ง limits อย่างระมัดระวัง (ต่ำเกินไปทำให้ถูกบีบ/OOM; สูงเกินไปซ่อนปัญหาความแย่งใช้)
- ทบทวนหลังจากดูเมตริกจริง (p95, ช่วงพีค และเวลาการอุ่นตัว)
How do rollouts, probes, and rollbacks work together for safer deployments?
การโรลเอาท์ด้วย Deployment คือการแทนที่ Pods เก่าเป็นทีละขั้นเพื่อรักษาความสามารถให้บริการระหว่างการอัพเดต
เพื่อให้โรลเอาท์ปลอดภัย:
- เพิ่ม readiness probes เพื่อไม่ให้ Pod ใหม่รับทราฟฟิกก่อนพร้อมจริง
- เพิ่ม liveness probes เพื่อรีสตาร์ทกระบวนการที่ค้างหรือเสีย
- ใช้ rollback เป็นการปฏิบัติการปกติโดยย้อนกลับไปยัง revision ก่อนหน้าที่รู้ว่าดี
When should I use rolling vs. blue/green vs. canary deployments?
รูปแบบที่ใช้ขึ้นกับความเสี่ยงและรูปแบบทราฟฟิก:
- Rolling: การแทนที่แบบขั้นบันได; ง่ายที่สุดและมีในตัว
- Blue/green: สองสภาพแวดล้อมเต็มรูปแบบ; สลับทราฟฟิกเมื่อสีเขียวเช็กแล้ว
- Canary: ส่งส่วนน้อยของทราฟฟิกไปยังเวอร์ชันใหม่ แล้วขยายตามเมตริก
เลือกตามความยอมรับความเสี่ยง รูปแบบทราฟฟิก และความเร็วในการตรวจจับรีเกรสชั่น (อัตราข้อผิดพลาด/ความหน่วง/การเบิร์น SLO)
How does Kubernetes service discovery stay stable when Pods change?
A Service ให้หน้าประตูที่คงที่สำหรับกลุ่ม Pods ชุดหนึ่ง มีชื่อและที่อยู่เสมอภายในคลัสเตอร์ แม้ว่าพ็อดจะเปลี่ยนไป
Labels/selectors ระบุว่าพ็อดไหน “อยู่หลัง” หน้าประตูนั้น และ EndpointSlices เก็บรายการ IP ของพ็อดที่ตรงกับ selector ปัจจุบัน
เชิงปฏิบัติ:
- ไคลเอนต์เรียก
service-nameแทนการตามหา IP ของ Pod - การสเกลและการย้ายพ็อดไม่ต้องแก้คอนฟิกฝั่งไคลเอนต์
- โหลดบาลานซ์กระจายทราฟฟิกไปยัง backend ที่พร้อมใช้งาน
What’s the difference between HPA, VPA, and Cluster Autoscaler, and what goes wrong most often?
การสเกลทำงานดีที่สุดเมื่อแต่ละชั้นมีสัญญาณชัดเจน:
- HPA: เปลี่ยนจำนวน replica ตามเมตริก (CPU, memory, หรือตัวชี้วัดเฉพาะอย่าง QPS/latency)
- VPA: ปรับ requests/limits ของ Pod ให้สอดคล้องกับการใช้งานจริง
- Cluster Autoscaler: เพิ่ม/ลดโหนดเพื่อให้ scheduler มีที่วางพ็อดที่ร้องขอ
ข้อผิดพลาดทั่วไป:
How do CRDs and Operators turn Kubernetes into a platform (not just a container runtime)?
CRDs ช่วยให้คุณนิยามวัตถุ API ใหม่ (เช่น Database, Cache) เพื่อจัดการระบบระดับสูงผ่าน API ของ Kubernetes
Operators จับคู่ CRDs กับ controller ที่คอย reconcile สถานะจริงให้ตรงกับที่ต้องการ อัตโนมัติงานเช่น:
- การจัดเตรียมและอัปเกรด
- สำรองข้อมูลและกู้คืน
- เวิร์กโฟลว์การ failover
ปฏิบัติเหมือนซอฟต์แวร์โปรดักชัน: ประเมินความพร้อมใช้งาน, การสังเกตเหตุการณ์, และโหมดล้มเหลวก่อนจะพึ่งพา