21 ก.ย. 2568·3 นาที
เหตุใด C และ C++ ยังคงขับเคลื่อน OS, ฐานข้อมูล และเอนจินเกม
ดูว่า C และ C++ ยังคงเป็นแกนกลางของระบบปฏิบัติการ ฐานข้อมูล และเอนจินเกมอย่างไร—ผ่านการควบคุมหน่วยความจำ ความเร็ว และการเข้าถึงระดับต่ำ
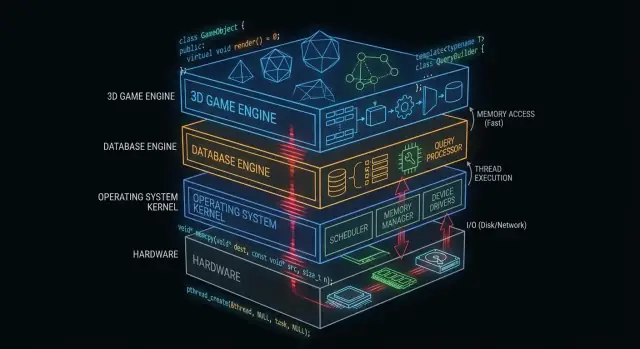
ทำไม C และ C++ ยังคงสำคัญในเบื้องหลัง
“ใต้ฝากระโปรง” คือสิ่งที่แอปของคุณพึ่งพา แต่แทบไม่ถูกแตะโดยตรง: เคอร์เนลระบบปฏิบัติการ, ไดรเวอร์อุปกรณ์, เอนจินเก็บข้อมูลของฐานข้อมูล, สแต็กเครือข่าย, runtime และไลบรารีที่ต้องการประสิทธิภาพสูง
ในทางกลับกัน สิ่งที่นักพัฒนาแอปส่วนใหญ่ เห็น ในชีวิตประจำวันคือชั้นผิวหน้า: เฟรมเวิร์ก, API, runtime ที่จัดการแล้ว, ตัวจัดการแพ็กเกจ และบริการคลาวด์ ชั้นเหล่านี้ถูกออกแบบให้ปลอดภัยและช่วยให้ทำงานได้ไว—แม้จะตั้งใจซ่อนความซับซ้อนไว้ก็ตาม
ทำไมบางชั้นต้องอยู่ใกล้ฮาร์ดแวร์
ชิ้นส่วนซอฟต์แวร์บางอย่างมีข้อกำหนดที่ยากจะทำให้เป็นจริงได้โดยไม่มีการควบคุมโดยตรง:
- ประสิทธิภาพและความหน่วงที่คาดการณ์ได้ (เช่น การจัดตารางเวลา CPU, การจัดการ interrupt, การสตรีม asset)
- การควบคุมหน่วยความจำอย่างละเอียด (โครงเลย์เอาต์, การจัดแนว, พฤติกรรมแคช, หลีกเลี่ยงการหยุดชะงัก)
- การเข้าถึงฮาร์ดแวร์โดยตรง (รีจิสเตอร์, DMA, ไดรเวอร์, ไฟล์ระบบและอุปกรณ์บล็อก)
- ไบนารีขนาดเล็ก พกพาได้ ซึ่งสามารถรันได้ตั้งแต่ช่วงบูตแรกหรือในสภาพแวดล้อมจำกัด
C และ C++ ยังคงถูกใช้บ่อยในพื้นที่เหล่านี้เพราะคอมไพล์เป็นโค้ดเนทีฟที่มีค่าออบเฮดน้อย และให้วิศวกรควบคุมหน่วยความจำและระบบเรียกได้อย่างละเอียด
ที่ที่ C และ C++ พบบ่อยในปัจจุบัน
โดยรวมแล้ว คุณจะพบ C และ C++ ขับเคลื่อน:
- แกนของระบบปฏิบัติการ และไลบรารีระดับล่าง
- ไดรเวอร์และเฟิร์มแวร์ฝังตัว
- เอนจินฐานข้อมูล (การรันคำสั่ง, การเก็บข้อมูล, ดัชนี)
- เอนจินเกมและระบบเรียลไทม์ (เรนเดริง, ฟิสิกส์, เสียง)
- คอมไพเลอร์, toolchain และ runtime ของภาษาอื่นๆ ที่ภาษาอื่นพึ่งพา
บทความนี้จะพูดถึง (และไม่พูดถึง) อะไร
บทความนี้เน้นที่กลไก: ชิ้นส่วนเบื้องหลังทำอะไร ทำไมโค้ดเนทีฟจึงได้เปรียบ และการแลกเปลี่ยนที่มาพร้อมกับพลังนั้น
จะไม่กล่าวว่า C/C++ เป็นตัวเลือกที่ดีที่สุดสำหรับทุกโปรเจกต์ และจะไม่กลายเป็นสงครามภาษา เป้าหมายคือความเข้าใจเชิงปฏิบัติว่าเหตุใดภาษาพวกนี้ยังคงมีบทบาทสำคัญ—และเหตุใดสแต็กซอฟต์แวร์สมัยใหม่ยังคงสร้างบนฐานของพวกมัน
อะไรทำให้ C และ C++ เหมาะกับซอฟต์แวร์ระบบ
C และ C++ ถูกใช้อย่างกว้างขวางสำหรับซอฟต์แวร์ระบบเพราะพวกมันทำให้เขียนโปรแกรมที่ “ใกล้ชิดกับโลหะ”: ขนาดเล็ก, เร็ว และผสานแนบชิดกับ OS และฮาร์ดแวร์
คอมไพล์เป็นโค้ดเนทีฟ (อธิบายแบบง่าย)
เมื่อโค้ด C/C++ ถูกคอมไพล์ จะกลายเป็นคำสั่งเครื่องที่ CPU สามารถรันได้โดยตรง ไม่มี runtime ที่ต้องแปลคำสั่งขณะรัน
สิ่งนี้สำคัญสำหรับส่วนประกอบโครงสร้างพื้นฐาน—เคอร์เนล, เอนจินฐานข้อมูล, เอนจินเกม—ที่แม้ค่าบัฟเฟอร์เล็กน้อยก็อาจสะสมภายใต้ภาระงาน
ประสิทธิภาพที่คาดการณ์ได้สำหรับโครงสร้างพื้นฐานหลัก
ซอฟต์แวร์ระบบมักต้องการการจับเวลาที่สม่ำเสมอ ไม่ใช่แค่ความเร็วเฉลี่ยดี ตัวอย่างเช่น:
- scheduler ของระบบปฏิบัติการต้องตอบสนองอย่างรวดเร็วภายใต้ภาระ
- ฐานข้อมูลต้องรักษาความหน่วงให้คงที่เมื่อลูกค้าจำนวนมากร้องขอพร้อมกัน
- เอนจินเกมต้องรักษางบประมาณเฟรม (เช่น ~16 ms สำหรับ 60 FPS)
C/C++ ให้การควบคุมการใช้ CPU, การจัดวางหน่วยความจำ และโครงสร้างข้อมูล ซึ่งช่วยวิศวกรกำหนดประสิทธิภาพที่คาดการณ์ได้
การเข้าถึงหน่วยความจำและพอยน์เตอร์โดยตรง
พอยน์เตอร์ให้คุณทำงานกับที่อยู่หน่วยความจำโดยตรง พลังนี้ฟังดูน่ากลัว แต่เปิดประตูสู่ความสามารถที่ภาษาระดับสูงมักจะซ่อนไว้:
- ตัวจัดสรรหน่วยความจำแบบกำหนดเองที่ปรับให้เหมาะกับภาระงาน
- รูปแบบในหน่วยความจำที่กะทัดรัด (มีประโยชน์ในฐานข้อมูลและแคช)
- รูปแบบ I/O แบบ zero-copy ที่ข้อมูลไม่ถูกก็อปปี้ซ้ำๆ
ใช้อย่างระมัดระวัง ระดับการควบคุมนั้นสามารถให้ประสิทธิภาพอย่างมีนัยสำคัญ
การแลกเปลี่ยน: ความปลอดภัย ความซับซ้อน และเวลาในการพัฒนา
อิสระเดียวกันก็เป็นความเสี่ยงด้วย ข้อแลกเปลี่ยนที่พบบ่อยได้แก่:
- ความปลอดภัย: ความผิดพลาดอาจทำให้แอปป crash, ข้อมูลเสียหาย หรือเปิดช่องโหว่ความปลอดภัย
- ความซับซ้อน: การจัดการหน่วยความจำด้วยตนเองและ undefined behavior ต้องวินัย
- เวลาในการพัฒนา: การทดสอบ การตรวจทาน และ tooling เป็นสิ่งที่ไม่สามารถต่อรองได้เพื่อความเชื่อถือได้
แนวทางที่พบบ่อยคือเก็บส่วนที่ต้องการประสิทธิภาพไว้ใน C/C++ แล้วรอบ ๆ ด้วยภาษาเรียกใช้งานที่ปลอดภัยกว่าเพื่อฟีเจอร์และ UX
C/C++ ในเคอร์เนลระบบปฏิบัติการ
เคอร์เนลของระบบปฏิบัติการอยู่ใกล้ฮาร์ดแวร์ที่สุด เมื่อแล็ปท็อปคุณตื่นขึ้น, เบราว์เซอร์เปิดขึ้น, หรือโปรแกรมขอแรมเพิ่ม เคอร์เนลกำลังประสานงานคำขอเหล่านั้นและตัดสินใจว่าจะเกิดอะไรขึ้นต่อไป
เคอร์เนลทำอะไรจริง ๆ
ในเชิงปฏิบัติ เคอร์เนลจัดการงานหลักไม่กี่อย่าง:
- การจัดตาราง: ตัดสินใจว่าโปรแกรม (และเธรด) ใดจะได้เวลา CPU และนานเท่าไร
- การจัดการหน่วยความจำ: แจกจ่ายหน่วยความจำให้กระบวนการ แยกขอบเขต และเก็บคืนหน่วยความจำอย่างปลอดภัย
- การจัดการอุปกรณ์: สื่อสารกับฮาร์ดแวร์ผ่านไดรเวอร์ (ดิสก์, เครือข่าย, คีย์บอร์ด, GPU ฯลฯ)
- ขอบเขตความปลอดภัย: บังคับสิทธิ์เพื่อไม่ให้โปรแกรมหนึ่งอ่านหรือทำลายข้อมูลของอีกโปรแกรม
เพราะความรับผิดชอบเหล่านี้อยู่ตรงกลางของระบบ โค้ดเคอร์เนลจึงละเอียดอ่อนทั้งด้านประสิทธิภาพและความถูกต้อง
ทำไมการควบคุมอย่างเข้มงวดจึงเอื้อกับ C (และบางครั้ง C++)
นักพัฒนาเคอร์เนลต้องการการควบคุมที่แม่นยำในเรื่อง:
- รูปแบบหน่วยความจำ: โครงสร้างขนาดคงที่ การจัดแนว และพฤติกรรมการจัดสรรที่คาดการณ์ได้
- คำสั่ง CPU และ calling conventions: การโต้ตอบกับ interrupt, context switch และการซิงโครไนซ์ระดับล่าง
- รีจิสเตอร์ฮาร์ดแวร์: อ่าน/เขียนที่อยู่เฉพาะและจัดการโหมด CPU พิเศษ
C ยังคงเป็นภาษาที่ใช้ในเคอร์เนลบ่อยเพราะมันแมปชัดเจนกับแนวคิดระดับเครื่อง แต่ยังอ่านง่ายและพกพาข้ามสถาปัตยกรรมได้ หลายเคอร์เนลยังพึ่งพาแอสเซมบลีสำหรับส่วนที่เฉพาะฮาร์ดแวร์ที่สุด ขณะที่ C ทำงานส่วนใหญ่
C++ อาจปรากฏในเคอร์เนลได้ แต่โดยทั่วไปใช้ในสไตล์จำกัด (ใช้ฟีเจอร์ runtime น้อย, นโยบาย exception ระมัดระวัง, กฎการจัดสรรเข้มงวด) เมื่อใช้จะเน้นปรับปรุงการ abstraction โดยไม่เสียการควบคุม
โค้ลเคอร์เนลที่อยู่ใกล้ ๆ มักเขียนด้วย C/C++
แม้เคอร์เนลจะอนุรักษ์นิยม แต่ส่วนประกอบที่อยู่ใกล้มักเป็น C/C++:
- ไดรเวอร์อุปกรณ์ (โดยเฉพาะตัวที่ต้องการประสิทธิภาพ)
- ไลบรารีมาตรฐานและ runtime (บางส่วนของ libc, เธรดระดับล่าง)
- บูตโหลดเดอร์และโค้ดช่วงเริ่มต้น
- บริการระบบที่ต้องการความเร็วเนทีฟ (เช่น ผู้ช่วยเครือข่ายหรือที่เก็บข้อมูล)
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีที่ไดรเวอร์เชื่อมซอฟต์แวร์กับฮาร์ดแวร์ ดู /blog/device-drivers-and-hardware-access.
ไดรเวอร์อุปกรณ์และการเข้าถึงฮาร์ดแวร์
ไดรเวอร์อุปกรณ์แปลความระหว่างระบบปฏิบัติการกับฮาร์ดแวร์จริง—การ์ดเครือข่าย, GPU, คอนโทรลเลอร์ SSD, อุปกรณ์เสียง และอื่นๆ เมื่อต้องคลิก “เล่น”, คัดลอกไฟล์, หรือเชื่อมต่อ Wi‑Fi ไดรเวอร์มักเป็นโค้ดแรกที่ต้องตอบสนอง
เพราะไดรเวอร์อยู่บนเส้นทางร้อนของ I/O จึงต้องการประสิทธิภาพสูงมาก เพียงไมโครวินาทีเพิ่มขึ้นต่อแพ็กเก็ตหรือคำขอดิสก์ก็สะสมได้อย่างรวดเร็วบนระบบที่มีงานเยอะ C และ C++ ยังคงเป็นที่นิยมเพราะเรียก API ของเคอร์เนลตรง, ควบคุมรูปแบบหน่วยความจำได้แม่นยำ, และรันด้วยค่าออบเฮดต่ำ
Interrupt, DMA และทำไม API ระดับต่ำจึงสำคัญ
ฮาร์ดแวร์ไม่ได้รออย่างสุภาพ อุปกรณ์ส่งสัญญาณไปยัง CPU ผ่าน interrupt—การแจ้งเตือนเร่งด่วนว่าเหตุการณ์เกิดขึ้น (แพ็กเก็ตมาถึง, การโอนเสร็จ) โค้ดไดรเวอร์ต้องจัดการเหตุการณ์เหล่านี้อย่างรวดเร็วและถูกต้อง ภายใต้ข้อจำกัดด้านเวลาและเธรด
สำหรับ throughput สูง ไดรเวอร์ยังพึ่งพา DMA (Direct Memory Access) ที่อุปกรณ์อ่าน/เขียนหน่วยความจำระบบโดยไม่ต้องให้ CPU ก็อปปี้ทุกไบต์ การตั้งค่า DMA มักเกี่ยวข้องกับ:
- เตรียมบัฟเฟอร์ในรูปแบบและการจัดแนวที่ถูกต้อง
- ส่งที่อยู่ทางกายภาพหรือตัวบ่งชี้ที่แม็ปแล้วให้กับอุปกรณ์
- ซิงโครไนซ์ความเป็นเจ้าของหน่วยความจำระหว่างอุปกรณ์กับ CPU
งานพวกนี้ต้องการอินเทอร์เฟซระดับล่าง: รีจิสเตอร์แม็ปในหน่วยความจำ, ธงบิต, และลำดับการอ่าน/เขียนที่ระมัดระวัง C/C++ ทำให้เป็นไปได้ที่จะแสดงตรรกะ “ใกล้ชิดกับโลหะ” ประเภทนี้ในขณะที่ยังพกพาได้ข้ามคอมไพเลอร์และแพลตฟอร์ม
ความเสถียรเป็นสิ่งที่ต่อรองไม่ได้
ต่างจากแอปธรรมดา ข้อบกพร่องในไดรเวอร์อาจทำให้ระบบทั้งระบบพัง ข้อมูลเสียหาย หรือเปิดช่องโหว่ การเสี่ยงนี้กำหนดรูปแบบการเขียนและการตรวจทานโค้ดของไดรเวอร์
ทีมลดความเสี่ยงด้วยมาตรฐานการเขียนโค้ดที่เข้มงวด, การตรวจเช็คเชิงป้องกัน, และการตรวจทานแบบหลายชั้น แนวปฏิบัติที่พบบ่อยรวมถึงจำกัดการใช้พอยน์เตอร์ที่ไม่ปลอดภัย ตรวจสอบข้อมูลจากฮาร์ดแวร์/เฟิร์มแวร์ และรันการวิเคราะห์แบบสถิตใน CI
การจัดการหน่วยความจำ: พลังและกับดัก
Get more build credits
รับเครดิตโดยการสร้างเนื้อหาเกี่ยวกับ Koder.ai หรือเชิญผู้อื่นผ่านลิงก์แนะนำของคุณ
การจัดการหน่วยความจำเป็นหนึ่งในเหตุผลใหญ่ที่ C และ C++ ยังคงครองส่วนหนึ่งของระบบปฏิบัติการ, ฐานข้อมูล, และเอนจินเกม แต่มันก็เป็นพื้นที่ที่ง่ายที่สุดในการสร้างบั๊กเล็กๆ ที่ยากจะจับ
“การจัดการหน่วยความจำ” หมายถึงอะไร
ในเชิงปฏิบัติ การจัดการหน่วยความจำรวมถึง:
- การจอง หน่วยความจำ (ขอพื้นที่เพื่อเก็บข้อมูล)
- การคืน มัน (คืนเมื่อเลิกใช้)
- จัดการ การแตกชิ้น (fragmentation) (ช่องว่างที่เหลือทำให้การจัดสรรในอนาคตช้าหรือยาก)
ใน C นี่มักชัดเจน (malloc/free) ใน C++ อาจชัดเจน (new/delete) หรือห่อด้วยรูปแบบที่ปลอดภัยกว่า
ทำไมการควบคุมด้วยมือจึงเป็นข้อได้เปรียบ
ในส่วนประกอบที่ต้องการประสิทธิภาพ การควบคุมด้วยมืออาจเป็นฟีเจอร์:
- คุณสามารถ หลีกเลี่ยงการหยุดชะงักที่ไม่คาดคิด จาก garbage collection
- คุณเลือก ที่ไหนและอย่างไร ที่จะจัดสรรหน่วยความจำ (เช่น pool หรือ arena allocator) เพื่อปรับปรุงความสม่ำเสมอ
- ปรับรูปแบบการจัดสรรให้เข้ากับภาระงานจริง (อ็อบเจ็กต์เล็กจำนวนมาก vs บัฟเฟอร์ใหญ่ต่อเนื่อง)
สิ่งนี้สำคัญเมื่อฐานข้อมูลต้องรักษาความหน่วงคงที่ หรือเอนจินเกมต้องรักษางบประมาณเฟรม
โหมดล้มเหลวที่พบบ่อย (และทำไมจึงร้ายแรง)
อิสระเดียวกันสร้างปัญหาคลาสสิก:
- หน่วยความจำรั่ว: ลืมคืนหน่วยความจำ ทำให้การใช้ทรัพยากรเพิ่มขึ้นจนประสิทธิภาพลดหรือโปรเซสพัง
- บัฟเฟอร์โอเวอร์โฟลว์: เขียนเลยขอบอาร์เรย์ ทำให้ข้อมูลเสียหายหรือเปิดช่องโหว่
- ใช้หลังคืน (use-after-free): ใช้พอยน์เตอร์หลังจากคืนแล้ว ทำให้ crash ที่ยากจะทำซ้ำ
บั๊กเหล่านี้อาจเกิดขึ้นแบบละเอียดเพราะโปรแกรมอาจ “ดูปกติ” จนกว่าจะมีภาระงานเฉพาะที่กระตุ้นให้ล้มเหลว
แนวปฏิบัติสมัยใหม่ช่วยได้อย่างไร
C++ สมัยใหม่ลดความเสี่ยงโดยไม่เสียการควบคุม:
- RAII (Resource Acquisition Is Initialization) ผูกอายุของทรัพยากรกับสโคป ทำให้การทำความสะอาดเกิดขึ้นอัตโนมัติ
- สมาร์ทพอยน์เตอร์ (เช่น
std::unique_ptrและstd::shared_ptr) ทำให้ความเป็นเจ้าของชัดเจนและป้องกันการรั่วได้หลายกรณี - Sanitizers (AddressSanitizer, UndefinedBehaviorSanitizer) และการวิเคราะห์แบบสถิติจับปัญหาแต่เนิ่น ๆ ใน CI
ใช้อย่างถูกต้อง เครื่องมือเหล่านี้ทำให้ C/C++ ยังคงเร็วในขณะเดียวกันลดโอกาสที่บั๊กหน่วยความจำจะหลุดไปถึง production
ความขนานและประสิทธิภาพมัลติคอร์
CPU สมัยใหม่ไม่ได้เร็วขึ้นมากต่อคอร์ แต่มีคอร์มากขึ้น เรื่องประสิทธิภาพจึงเปลี่ยนจาก “โค้ดของฉันเร็วแค่ไหน” เป็น “โค้ดของฉันทำงานขนานได้ดีแค่ไหนโดยไม่ชนกัน” C และ C++ เป็นที่นิยมเพราะให้การควบคุมระดับล่างเหนือเธรด, การซิงโครไนซ์, และพฤติกรรมหน่วยความจำด้วยค่าออบเฮดต่ำ
เธรด คอร์ และการจัดตาราง
เธรดคือหน่วยที่โปรแกรมใช้ทำงาน ส่วนคอร์คือสถานที่ที่งานวิ่ง scheduler ของ OS แมปเธรดที่พร้อมรันไปยังคอร์ที่ว่างอยู่ โดยทำการประเมินอย่างต่อเนื่อง
รายละเอียดเล็ก ๆ ของการจัดตารางมีผลในการใช้งานจริง: หยุดเธรดผิดเวลาสามารถทำให้ pipeline ติดขัด คิวสะสม หรือเกิดพฤติกรรมหยุด-ไป-หยุดมา สำหรับงานที่ใช้ CPU มาก การรักษาจำนวนเธรดที่ทำงานใกล้เคียงกับจำนวนคอร์มักช่วยลดการ thrash
พื้นฐานการล็อก: mutex, atomics และ contention
- Mutexes เข้าใจง่าย แต่การแชร์หนัก ๆ ทำให้เกิด contention—เวลาเสียไปกับการรอแทนที่จะทำงาน
- Atomics อาจเร็วกว่าสำหรับการอัปเดตสถานะร่วมขนาดเล็ก แต่ต้องออกแบบอย่างระมัดระวังเพื่อหลีกเลี่ยงบั๊กทางความถูกต้องที่ซับซ้อน
เป้าหมายเชิงปฏิบัติไม่ใช่ “ไม่ล็อกเลย” แต่คือ: ล็อกให้น้อย ลงล็อกอย่างชาญฉลาด—เก็บ critical section ให้เล็ก หลีกเลี่ยงล็อกแบบรวม และลดสถานะเปลี่ยนร่วม
ทำไมการกระพือความหน่วงจึงสำคัญ
ฐานข้อมูลและเอนจินเกมไม่เพียงสนใจความเร็วเฉลี่ยเท่านั้น แต่สนใจช่วงเวลาที่หยุดชะงักที่สุด การเกิด lock convoy, page fault, หรือ worker ค้างอาจทำให้เกิด stutter ที่สังเกตได้ หรือคำขอช้าจนละเมิด SLA
รูปแบบ C/C++ ที่พบบ่อย
ระบบประสิทธิภาพสูงหลายระบบพึ่งพา:
- Thread pools เพื่อใช้ซ้ำ worker และทำให้การจัดตารางคาดการณ์ได้
- Work-stealing queues เพื่อบาลานซ์โหลดข้ามคอร์
- Lock-free queues ในเส้นทางร้อนบางแห่งเพื่อลดการบล็อก—ใช้อย่างระมัดระวังเพราะพิสูจน์ความถูกต้องยาก
รูปแบบเหล่านี้มุ่งถึงทั้ง throughput ที่สม่ำเสมอและ latency ที่คงที่ภายใต้ความกดดัน
เอนจินฐานข้อมูล: ที่ที่ C/C++ ให้ความเร็ว
เอนจินฐานข้อมูลไม่ใช่แค่ “เก็บแถว” แต่มันคือวงจร CPU และ I/O ที่แน่นซึ่งทำงานล้านครั้งต่อวินาที ความไม่มีประสิทธิภาพเล็กน้อยสะสมอย่างรวดเร็ว นั่นคือเหตุผลที่เอนจินและส่วนประกอบหลักจำนวนมากยังเขียนด้วย C หรือ C++
งานหลักของเอนจิน: parse, plan, execute
เมื่อส่ง SQL เอนจินจะ:
- แยกวิเคราะห์ (parse) ข้อความเป็นตัวแทนโครงสร้าง
- วางแผน (plan) เลือกวิธีที่มีประสิทธิภาพในการตอบคำถาม
- รัน (execute) สแกน, ค้นหาดัชนี, join, sort, aggregate และส่งแถวกลับ
แต่ละขั้นได้ประโยชน์จากการควบคุมหน่วยความจำและ CPU อย่างระมัดระวัง C/C++ ช่วยให้ parser เร็ว การลดย้ายหน่วยความจำระหว่างการวางแผน และเส้นทางการรันที่ lean—มักมีโครงสร้างข้อมูลแบบเฉพาะที่ออกแบบมาสำหรับภาระงาน
เอนจินเก็บข้อมูล: เพจ ดัชนี และบัฟเฟอร์
ภายใต้ชั้น SQL เอนจินเก็บข้อมูลจัดการรายละเอียดที่ไม่สะดุดตาแต่สำคัญ:
- เพจ: ข้อมูลอ่าน/เขียนเป็นบล็อกขนาดคงที่ ไม่ใช่เป็นแถวทีละแถว
- ดัชนี: โครงสร้างเช่น B-tree, LSM-tree ต้องอัปเดตอย่างมีประสิทธิภาพ
- การบัฟเฟอร์: buffer pool ตัดสินใจว่าสิ่งใดอยู่ในหน่วยความจำ สิ่งใดถูกไล่ออก และการรวมการอ่าน/เขียนอย่างไร
C/C++ เหมาะกับงานเหล่านี้เพราะพึ่งพา layout หน่วยความจำที่คาดการณ์ได้และการควบคุมขอบเขต I/O โดยตรง
โครงสร้างข้อมูลที่เป็นมิตรกับแคช (ทำไมจึงสำคัญ)
ประสิทธิภาพสมัยใหม่นิยมขึ้นกับแคช CPU มากกว่าความเร็ว CPU ดิบ ด้วย C/C++ นักพัฒนาสามารถจัดกลุ่มฟิลด์ที่ใช้บ่อยไว้ด้วยกัน เก็บคอลัมน์ในอาเรย์ต่อเนื่อง และลดการเดินตามพอยน์เตอร์—รูปแบบที่ทำให้ข้อมูลอยู่ใกล้ CPU และลดการ stall
ที่ที่ภาษาระดับสูงยังมีบทบาท
แม้ฐานข้อมูลที่หนักด้วย C/C++ ฟีเจอร์รอบนอกมักถูกขับเคลื่อนด้วยภาษาระดับสูง เช่น เครื่องมือแอดมิน, สำรองข้อมูล, มอนิเตอร์, การย้ายข้อมูล และการออเคสตรา โค้ดบ็อททอมที่ต้องการประสิทธิภาพยังคงเป็น native; ระบบรอบนอกให้ความสำคัญกับความเร็วในการทำซ้ำและการใช้งาน
การเก็บข้อมูล, แคช และ I/O ในฐานข้อมูล
Build the mobile surface
สร้างแอปมือถือด้วย Flutter และแยกการทำงานเชิงผลิตภัณฑ์จากงานปรับจูนระดับล่าง
ฐานข้อมูลให้ความรู้สึกเหมือนทันทีเพราะพวกมันพยายามหลีกเลี่ยงดิสก์ แม้ SSD จะเร็ว การอ่านจากสตอเรจก็ช้ากว่าการอ่านจาก RAM หลายเท่า เอนจินฐานข้อมูลที่เขียนด้วย C/C++ สามารถควบคุมทุกขั้นตอนของการรอ และมักหลีกเลี่ยงมันได้
Buffer pool และ page cache อธิบายง่าย
คิดว่าข้อมูลบนดิสก์เหมือนกล่องในคลังสินค้า การดึงกล่อง (อ่านดิสก์) ใช้เวลา จึงเก็บของที่ใช้บ่อยไว้บนโต๊ะ (RAM)
- Buffer pool: “โต๊ะ” ของฐานข้อมูล เก็บเพจที่ใช้ล่าสุด (บล็อกขนาดคงที่ของตารางและดัชนี)
- Page cache: “โต๊ะ” ของระบบปฏิบัติการ แคชข้อมูลไฟล์ที่อ่านล่าสุด
หลายฐานข้อมูลบริหาร buffer pool เองเพื่อคาดการณ์ว่าสิ่งใดควรร้อน และหลีกเลี่ยงการต่อสู้กับ OS เรื่องหน่วยความจำ
ทำไมดิสก์ช้าจึงสำคัญ—และแคชทำให้มองไม่เห็น
สตอเรจไม่เพียงช้า แต่ยังไม่แน่นอน ความหน่วงกระโดด, คิว, และการเข้าถึงแบบสุ่มทำให้เกิดความล่าช้า แคชช่วยได้โดย:
- ให้การอ่านจาก RAM ส่วนใหญ่
- รวมการเขียนเป็น I/O ขนาดใหญ่จำนวนน้อยลง
- พรีเฟตช์เพจที่มีแนวโน้มจะถูกใช้ต่อไป (เช่น ระหว่างการสแกนดัชนี)
การตัดสินใจออกแบบที่ได้ประโยชน์จากการควบคุมระดับล่าง
C/C++ ให้เอนจินฐานข้อมูลปรับจูนรายละเอียดที่สำคัญที่ throughput สูง: การอ่านที่จัดแนว, direct I/O vs buffered I/O, นโยบายไล่ออกแบบกำหนดเอง, และเลย์เอาต์ในหน่วยความจำที่รอบคอบ การเลือกเหล่านี้ลดการก็อปปี้ หลีกเลี่ยง contention และรักษาแคชของ CPU ให้เต็มด้วยข้อมูลที่ใช้จริง
การบีบอัดและ checksum อาจเป็นคอขวดของ CPU
แคชลด I/O แต่เพิ่มงานของ CPU การถอดรหัสเพจ, คำนวณ checksum, เข้ารหัสล็อก, และตรวจสอบระเบียนอาจกลายเป็นคอขวด เพราะ C และ C++ ให้การควบคุมรูปแบบการเข้าถึงหน่วยความจำและลูปที่เหมาะกับ SIMD จึงมักใช้เพื่อรีดประสิทธิภาพจากแต่ละคอร์
เอนจินเกม: ข้อจำกัดแบบเรียลไทม์
เอนจินเกมทำงานภายใต้ความคาดหวังเรียลไทม์: ผู้เล่นขยับกล้อง กดปุ่ม และโลกต้องตอบสนองทันที วัดเป็นเวลาเฟรม ไม่ใช่แค่ throughput เฉลี่ย
งบประมาณเฟรม: ทำไมมิลลิวินาทีสำคัญ
ที่ 60 FPS คุณมีประมาณ 16.7 ms เพื่อสร้างเฟรมหนึ่ง: จำลอง, แอนิเมชัน, ฟิสิกส์, มิกซ์เสียง, culling, ยื่นคำสั่งเรนเดอร์ และมักสตรีม asset พลาดงบประมาณจะถูกสังเกตเป็น stutter, input lag, หรือจังหวะไม่สม่ำเสมอ
นี่คือเหตุผลที่ การเขียนโปรแกรมภาษา C และ การเขียนโปรแกรม C++ ยังคงพบบ่อยในแกนของเอนจิน: ประสิทธิภาพที่คาดการณ์ได้, ออบเฮดต่ำ, และการควบคุมหน่วยความจำและการใช้ CPU อย่างละเอียด
ระบบหลักมักเขียนด้วย C/C++
เอ็นจินส่วนใหญ่ใช้โค้ดเนทีฟสำหรับงานหนัก:
- เรนเดอริง (การ travers เรียนฉาก, สร้าง draw-call, จัดการทรัพยากร GPU)
- ฟิสิกส์ (การตรวจชน การจำกัด, ร่างกายแข็ง)
- แอนิเมชัน (skeletal blending, IK, การประเมินโพส)
- เสียง (มิกซ์เรียลไทม์, spatialization)
ระบบเหล่านี้รันทุกเฟรม จึงสะสมความไม่มีประสิทธิภาพได้อย่างรวดเร็ว
ลูปแน่นและเลย์เอาต์ข้อมูล
ประสิทธิภาพเกมจำนวนมากมาจากลูปแน่น: วนดูเอนทิตี อัปเดตทรานส์ฟอร์ม ทดสอบการชน สกินเวอร์เท็กซ์ C/C++ ช่วยให้จัดหน่วยความจำเพื่อประสิทธิภาพแคชได้ง่ายขึ้น (อาเรย์ต่อเนื่อง, ลดการจัดสรร, ลดการชี้ผ่านแบบเสมือน) เลย์เอาต์ข้อมูลอาจสำคัญเท่ากับการเลือกอัลกอริทึม
สคริปต์อยู่ตรงไหน (และไม่อยู่ตรงไหน)
หลายสตูดิโอใช้ภาษาสคริปต์สำหรับโลจิกการเล่นเกม—ภารกิจ, กฎ UI, ทริกเกอร์—เพราะความเร็วในการทำซ้ำสำคัญ แกนเอนจินยังคงเป็น native และสคริปต์เรียกเข้าไปที่ระบบ C/C++ ผ่าน binding รูปแบบที่พบบ่อย: สคริปต์เป็นผู้ประสาน; C/C++ ประมวลผลส่วนที่แพง
คอมไพเลอร์, Toolchain และการเชื่อมต่อระหว่างภาษา
Own your codebase
เป็นเจ้าของโค้ดของคุณ: ส่งออกซอร์สโค้ดเมื่อใดก็ได้เพื่อใช้เครื่องมือหรือปรับแต่งเอง
C และ C++ ไม่ได้แค่ “รัน”—พวกมันถูกสร้างเป็นไบนารีเนทีฟที่ตรงกับ CPU และระบบปฏิบัติการ ท่อการสร้างนี้เป็นเหตุผลสำคัญที่ภาษานี้ยังคงศูนย์กลางสำหรับระบบปฏิบัติการ, ฐานข้อมูล, และเอนจินเกม
เกิดอะไรขึ้นระหว่างการ build
การ build ทั่วไปมีขั้นตอนหลัก:
- คอมไพเลอร์: เปลี่ยนซอร์ส C/C++ เป็นไฟล์ออบเจ็กต์ที่เฉพาะกับเครื่อง
- ลิงเกอร์: นำออบเจ็กต์มาต่อกับไลบรารีเพื่อผลิต executable หรือ shared library
- ผลลัพธ์ไบนารี: ผลิตภัณฑ์สุดท้ายที่ OS โหลดได้โดยตรง (มักมีสัญลักษณ์ debug แยกต่างหาก)
ขั้นตอนลิงเกอร์คือที่ปัญหาในโลกจริงมักปรากฏ: สัญลักษณ์หาย, เวอร์ชันไลบรารีไม่ตรงกัน, หรือตั้งค่า build ไม่เข้ากัน
ทำไม toolchain และการรองรับแพลตฟอร์มจึงสำคัญ
Toolchain คือชุดเต็ม: คอมไพเลอร์, ลิงเกอร์, ไลบรารีมาตรฐาน, และเครื่องมือ build สำหรับซอฟต์แวร์ระบบ การรองรับแพลตฟอร์มมักเป็นปัจจัยตัดสิน:
- SDK ของคอนโซลและมือถืออาจต้องคอมไพเลอร์และลิงเกอร์เฉพาะ
- ซอฟต์แวร์เซิร์ฟเวอร์ต้องการ build ที่เสถียรข้ามดิสโทร Linux และสถาปัตยกรรม CPU
- งาน OS และไดรเวอร์อาจต้อง cross-compiler, flag เคร่งครัด, และวินัยเรื่อง ABI
ทีมมักเลือก C/C++ เพราะ toolchain มีความเป็นผู้ใหญ่และมีให้ใช้ข้ามสภาพแวดล้อม—จากอุปกรณ์ฝังตัวถึงเซิร์ฟเวอร์
การเชื่อมต่อกับภาษาอื่น (FFI)
C มักถูกมองเป็น “อะแดปเตอร์สากล” หลายภาษาสามารถเรียกฟังก์ชัน C ผ่าน FFI ได้ ดังนั้นทีมมักใส่ตรรกะที่ต้องการประสิทธิภาพในไลบรารี C/C++ แล้วเปิด API เล็กๆ ให้โค้ดระดับสูงเรียก นี่คือเหตุผลที่ Python, Rust, Java และภาษาอื่น ๆ มักห่อหุ้มส่วนประกอบ C/C++ ที่มีอยู่แทนการเขียนใหม่
การดีบักและโปรไฟล์: ทีมวัดอะไร
ทีม C/C++ มักวัด:
- เวลา CPU (ฟังก์ชันฮอต, call stack)
- การใช้หน่วยความจำ (การจัดสรร, การรั่ว, fragmentation)
- ความหน่วง (เวลาเฟรมในเกม, เวลา query ในฐานข้อมูล)
- พฤติกรรม I/O (cache miss, การอ่านดิสก์, syscall)
เวิร์กโฟลว์คงที่: หา bottleneck, ยืนยันด้วยข้อมูล, แล้วปรับจูนชิ้นเล็กที่สุดที่สำคัญ
การเลือก C/C++ วันนี้: แนวทางเชิงปฏิบัติ
C และ C++ ยังคงเป็นเครื่องมือที่ยอดเยี่ยม—เมื่อคุณสร้างซอฟต์แวร์ที่มิลลิวินาที สองสามไบต์ หรือตัวคำสั่ง CPU เฉพาะมีความหมายจริง พวกมันไม่ใช่ตัวเลือกดีเริ่มต้นสำหรับทุกฟีเจอร์หรือตัวทีม
เมื่อ C/C++ เป็นตัวเลือกที่เหมาะสม
เลือก C/C++ เมื่อส่วนประกอบเป็น critical path ด้านประสิทธิภาพ, ต้องการ การควบคุมหน่วยความจำอย่างเข้มงวด, หรือจะผสานกับ OS หรือฮาร์ดแวร์อย่างใกล้ชิด
ตัวอย่างที่เหมาะสม:
- เส้นทางร้อนที่ความหน่วงเห็นได้ (parsing, compression, rendering, การรัน query)
- โมดูลระดับล่างที่ต้องคาดการณ์ได้ (allocator, scheduler, primitive เครือข่าย)
- ไลบรารีข้ามแพลตฟอร์มที่ native code เป็นผลิตภัณฑ์ (SDK, engine, embedded)
- สถานการณ์ที่การพกพาข้ามคอมไพเลอร์/toolchain เป็นข้อกำหนด
เมื่อควรเลือกภาษาอื่น
เลือกภาษาระดับสูงเมื่อความสำคัญคือ ความปลอดภัย, ความเร็วในการทำซ้ำ, หรือ การดูแลรักษาในระดับใหญ่
มักจะฉลาดกว่าที่จะใช้ Rust, Go, Java, C#, Python, หรือ TypeScript เมื่อ:
- ทีมใหญ่และคาดว่ามีการเปลี่ยนคนบ่อย (การมี foot-guns น้อยสำคัญ)
- ฟีเจอร์เปลี่ยนบ่อยและความถูกต้องสำคัญกว่าการรีดประสิทธิภาพสุดท้าย
- ต้องการการรับประกันความปลอดภัยหน่วยความจำที่แข็งแรง
- ผลิตภาพของนักพัฒนาและแหล่งรับสมัครสำคัญกว่าความเร็วดิบ
ในทางปฏิบัติ ผลิตภัณฑ์ส่วนใหญ่เป็นผสม: ไลบรารีเนทีฟสำหรับ path ที่สำคัญ และบริการ/UI ระดับสูงสำหรับส่วนอื่น ๆ
หมายเหตุเชิงปฏิบัติสำหรับทีมแอป (ที่ Koder.ai เข้ามาเกี่ยวข้อง)
ถ้าคุณหลัก ๆ สร้างเว็บ, แบ็กเอนด์, หรือฟีเจอร์มือถือ คุณมักไม่ต้อง เขียน C/C++ เพื่อได้ประโยชน์จากมัน—คุณจะใช้ผ่าน OS, ฐานข้อมูล, runtime และ dependency ของคุณ แพลตฟอร์มอย่าง Koder.ai ใช้การแยกนี้: คุณสามารถสร้างแอป React, แบ็กเอนด์ Go + PostgreSQL, หรือแอป Flutter ได้อย่างรวดเร็วผ่าน workflow แบบแชท ในขณะเดียวกันยังผสานคอมโพเนนต์เนทีฟเมื่อจำเป็น (เช่น เรียกไลบรารี C/C++ ที่มีอยู่ผ่านขอบเขต FFI) วิธีนี้ทำให้ส่วนใหญ่ของผลิตภัณฑ์อยู่ในโค้ดที่ทำซ้ำได้เร็ว โดยไม่มองข้ามจุดที่โค้ดเนทีฟเป็นเครื่องมือที่เหมาะสม
เช็คลิสต์เชิงปฏิบัติ (แยกตามคอมโพเนนต์)
ถามคำถามเหล่านี้ก่อนตัดสินใจ:
- นี่อยู่บน critical path ไหม? วัดก่อน; อย่าเดา
- โหมดล้มเหลวเป็นอย่างไร? การทำให้หน่วยความจำเสียหายใน C/C++ อาจร้ายแรง
- ขอบเขตอินเทอร์เฟซคืออะไร? แยกโค้ดเนทีฟไว้หลัง API เล็ก ๆ ได้ไหม
- คุณมีความเชี่ยวชาญไหม? การตรวจทาน, การทดสอบ, และการโปรไฟล์เป็นสิ่งที่ไม่ต่อรองได้
- เป้าหมายการปรับใช้คืออะไร? คอนโซล, อุปกรณ์ฝังตัว, เคอร์เนล, และไดรเวอร์มักชอบ C/C++
- จะทดสอบและโปรไฟล์อย่างไร? วางแผน tooling และ CI ตั้งแต่วันแรก
บทความแนะนำอ่านต่อ
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing