12 มิ.ย. 2568·5 นาที
จาก User Stories สู่สคีมาฐานข้อมูล: วิธีการที่มี AI เป็นผู้ช่วย
เรียนรู้วิธีปฏิบัติในการเปลี่ยน user stories, entities และ workflows ให้กลายเป็นโครงสร้างฐานข้อมูลที่ชัดเจน และวิธีที่ AI ช่วยตรวจหาช่องว่างและกฎได้.
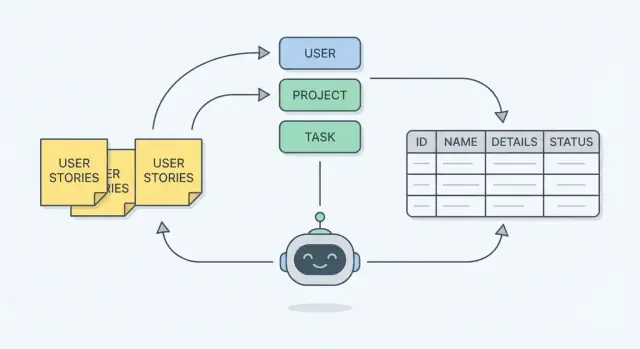
เรียนรู้วิธีปฏิบัติในการเปลี่ยน user stories, entities และ workflows ให้กลายเป็นโครงสร้างฐานข้อมูลที่ชัดเจน และวิธีที่ AI ช่วยตรวจหาช่องว่างและกฎได้.
โครงสร้างฐานข้อมูล เป็นแผนว่าระบบของคุณจะจดจำอะไร ในเชิงปฏิบัติ มันคือ:
เมื่อสคีมาสอดคล้องกับงานจริง มันสะท้อนสิ่งที่ผู้คนทำจริงๆ—สร้าง ทบทวน อนุมัติ นัดหมาย มอบหมาย ยกเลิก—มากกว่าสิ่งที่ฟังดูเรียบร้อยบนไวท์บอร์ด.
User stories และ acceptance criteria อธิบายความต้องการจริงด้วยภาษาง่าย: ใครทำอะไร และ “เสร็จ” หมายถึงอะไร ถ้าคุณใช้สิ่งเหล่านี้เป็นแหล่ง ข้อมูลในสคีมาจะมีโอกาสน้อยที่จะพลาดรายละเอียดสำคัญ (เช่น “เราต้องเก็บว่าใครอนุมัติการคืนเงิน” หรือ “การจองสามารถถูกเลื่อนหลายครั้งได้”).
การเริ่มจาก stories ยังช่วยให้คุณตรงประเด็นเรื่องขอบเขต หากมันไม่อยู่ใน stories (หรือ workflow) ให้ถือว่าเป็นทางเลือกแทนที่จะสร้างโมเดลซับซ้อนโดยไม่จำเป็น.
AI ช่วยให้เร็วขึ้นโดย:
AI ไม่สามารถรับประกันได้ว่า:
จงถือว่า AI เป็นผู้ช่วยที่แข็งแรง ไม่ใช่ผู้ตัดสินใจ
ถ้าคุณอยากให้ผู้ช่วยตัวนั้นกลายเป็นแรงขับเคลื่อน แพลตฟอร์ม vibe-coding อย่าง Koder.ai สามารถช่วยให้คุณไปจากการตัดสินใจสคีมาไปเป็นแอป React + Go + PostgreSQL ที่ใช้งานได้เร็วขึ้น—โดยยังให้คุณควบคุมโมเดล ข้อจำกัด และ migration.
การออกแบบสคีมาเป็นวงจร: ร่าง → ทดสอบกับ stories → หาแนวข้อมูลที่ขาด → ปรับแต่ง เป้าหมายไม่ใช่ผลลัพธ์แรกที่สมบูรณ์ แต่อยู่ที่โมเดลที่คุณสามารถย้อนกลับไปหาแต่ละ user story แล้วตอบได้อย่างมั่นใจว่า: “ใช่ เราจัดเก็บทุกสิ่งที่ workflow นี้ต้องการได้—และอธิบายได้ว่าทำไมแต่ละตารางถึงมีอยู่.”
ก่อนจะแปลงข้อกำหนดเป็นตาราง ให้ชัดเจนว่าคุณกำลังจำลองอะไร สคีมาที่ดีมักไม่เริ่มจากหน้ากระดาษว่าง—มันเริ่มจากงานเฉพาะเจาะจงที่คนทำและหลักฐานที่คุณต้องการในภายหลัง (หน้าจอ ผลลัพธ์ และกรณีมุม).
User stories เป็นหัวข้อใหญ่ แต่ยังไม่พอ ควรรวบรวม:
ถ้าคุณใช้ AI ข้อมูลเหล่านี้ช่วยยึดโมเดล AI ไว้ AI อาจเสนอ entities และ fields ได้เร็ว แต่ต้องมี artifacts จริงเพื่อหลีกเลี่ยงการคิดค้นโครงสร้างที่ไม่ตรงกับผลิตภัณฑ์ของคุณ.
Acceptance criteria มักมีข้อบังคับฐานข้อมูลที่สำคัญที่สุด แม้ว่าจะไม่ได้กล่าวถึงข้อมูลอย่างชัดเจน มองหาประโยคเช่น:
เรื่องเล่าไม่ชัดเจน (“As a user, I can manage projects”) มักซ่อนหลายเอนทิตีและ workflow ช่องว่างบ่อยคือกรณีมุมเช่น การยกเลิก การลองใหม่ การคืนบางส่วน หรือการมอบหมายซ้ำ.
ก่อนคิดเรื่องตารางหรือไดอะแกรม อ่าน user stories แล้วเน้น คำนาม ในการเขียนข้อกำหนด คำนามมักชี้ไปยัง “สิ่ง” ที่ระบบต้องจำ—ซึ่งมักกลายเป็น entities ในสคีมา.
โมเดลคิดแบบง่าย: คำนามกลายเป็นเอนทิตี ขณะที่ กริยากลายเป็นการกระทำหรือ workflow ถ้า story บอกว่า “A manager assigns a technician to a job,” เอนทิตีที่เป็นไปได้คือ manager, technician, และ job—และ “assigns” บอกถึงความสัมพันธ์ที่คุณจะโมเดลต่อไป.
ไม่ใช่ทุกคำนามควรมีตารางของตัวเอง คำนามเป็นผู้สมัครที่ดีเมื่อมัน:
ถ้าคำนามปรากฏแค่ครั้งเดียว หรือแค่บรรยายสิ่งอื่น (“red button”, “Friday”) มันอาจไม่ใช่เอนทิตี.
ข้อผิดพลาดทั่วไปคือแปลงทุกรายละเอียดเป็นตาราง ใช้กฎง่ายๆ:
สองตัวอย่างคลาสสิก:
AI ช่วยเร็วขึ้นโดยสแกน stories แล้วคืนรายการคำนามที่เป็นผู้สมัครจัดกลุ่มตามธีม (people, work items, documents, locations). คำสั่งที่มีประโยชน์: “Extract nouns that represent data we must store, and group duplicates/synonyms.”
ถือผลลัพธ์เป็น จุดเริ่มต้น ไม่ใช่คำตอบ ถามต่อเช่น:
เป้าหมายของขั้นตอน 1 คือรายการสั้นสะอาดของ entities ที่คุณปกป้องโดยอ้างอิงกลับไปยัง stories จริง.
เมื่อคุณตั้งชื่อเอนทิตีแล้ว (เช่น Order, Customer, Ticket) งานถัดไปคือจับรายละเอียดที่คุณจะต้องใช้ในภายหลัง ในฐานข้อมูล รายละเอียดเหล่านี้คือ ฟิลด์ (หรือเรียกว่า attributes)—สิ่งที่ระบบต้องจำ.
เริ่มจาก user story แล้วอ่าน acceptance criteria เหมือนเช็คลิสต์ของสิ่งที่ต้องเก็บ.
ถ้าข้อกำหนดบอกว่า “Users can filter orders by delivery date,” แปลว่า delivery_date ไม่ใช่ช่องทางเลือก—มันต้องมีเป็นฟิลด์ (หรืออนุมานได้จากข้อมูลอื่นที่เก็บไว้). ถ้าบอกว่า “Show who approved the request and when,” คุณน่าจะต้องมี approved_by และ approved_at.
ทดสอบเชิงปฏิบัติ: ใครสักคนจะต้องใช้ข้อมูลนี้ในการแสดง ค้นหา เรียงลำดับ ตรวจสอบ หรือคำนวณไหม? ถ้าใช่ มันควรเป็นฟิลด์.
หลาย story มีคำว่า “status”, “type”, หรือ “priority” ให้ถือพวกนี้เป็น ค่าที่ควบคุมได้—ชุดค่าที่อนุญาตจำกัด.
ถ้าชุดค่าน้อยและคงที่ enum ก็พอ แต่ถ้าอาจขยาย ต้องการป้ายชื่อ หรือมีสิทธิ์จัดการ (เช่น categories ที่ผู้ดูแลระบบจัดการ) ให้ใช้ตาราง lookup แยก (เช่น status_codes) แล้วเก็บการอ้างอิง.
นี่แหละวิธีที่ stories กลายเป็นฟิลด์ที่คุณไว้วางใจได้—ค้นหาได้ รายงานได้ และป้อนผิดได้ยาก.
เมื่อคุณมีรายการเอนทิตี (User, Order, Invoice, Comment ฯลฯ) และร่างฟิลด์แล้ว ขั้นตอนถัดไปคือเชื่อมพวกมัน ความสัมพันธ์คือเลเยอร์ที่บอกว่า “สิ่งเหล่านี้โต้ตอบกันอย่างไร” ซึ่ง implied โดย stories.
หนึ่งต่อหนึ่ง (1:1) หมายถึง “สิ่งหนึ่งมีอีกสิ่งหนึ่งพอดีหนึ่งอัน.”
User ↔ Profile (มักรวมกันได้ถ้าไม่มีเหตุผลจะแยก)หนึ่งต่อหลาย (1:N) หมายถึง “สิ่งหนึ่งอาจมีหลายสิ่งอื่น.” นี่คือรูปแบบที่พบบ่อยที่สุด.
User → Order (เก็บ user_id บน Order).หลายต่อหลาย (M:N) หมายถึง “หลายสิ่งสัมพันธ์กับหลายสิ่ง.” ต้องมีตารางเพิ่ม.
ฐานข้อมูลไม่ควรเก็บ “ลิสต์ product IDs” ในคอลัมน์เดียวของ Order เพราะจะเกิดปัญหาในภายหลัง ให้สร้าง ตารางเชื่อม ที่เป็นตัวแทนของความสัมพันธ์เอง.
ตัวอย่าง:
OrderProductOrderItem (ตารางเชื่อม)OrderItem มักมี:
order_idproduct_idquantity, unit_price, discountสังเกตว่า รายละเอียดจาก story (เช่น “quantity”) มักเป็นของ ความสัมพันธ์ ไม่ใช่ของเอนทิตีใดเอนทิตีหนึ่ง.
Stories ยังบอกได้ว่าการเชื่อมเป็น บังคับ หรือ บางครั้งอาจไม่มี.
Order ต้องมี user_id (ไม่ควรเป็นค่าว่าง).phone อาจว่างได้.shipping_address_id อาจว่างสำหรับสินค้าดิจิทัล.เช็คลัด: ถ้า story บอกว่าคุณไม่สามารถสร้างเรคอร์ดโดยไม่เชื่อม ให้ถือว่าเป็น required ถ้ามีคำว่า “can”, “may”, หรือมีข้อยกเว้น ให้ถือเป็น optional.
เมื่ออ่าน story ให้เขียนมันใหม่เป็นการจับคู่เรียบง่าย:
User 1:N CommentComment N:1 Userทำอย่างนี้สำหรับทุกการโต้ตอบใน stories ของคุณ เมื่อจบคุณจะมีโมเดลที่เชื่อมต่อกันตรงกับวิธีการทำงานก่อนจะเปิดเครื่องมือ ER diagram.
User stories บอกคุณ จะทำอะไร ผู้ใช้ต้องการ Workflows แสดงให้เห็น งานเคลื่อนไหวอย่างไรทีละขั้นตอน การแปลง workflow เป็นข้อมูลคือวิธีเร็วสุดในการจับปัญหา “เราลืมเก็บสิ่งนี้” ก่อนสร้างจริง.
เขียน workflow เป็นลำดับการกระทำและการเปลี่ยนสถานะ เช่น:
คำที่เน้นมักกลายเป็นฟิลด์ status (หรือเป็นตาราง state เล็กๆ) พร้อมค่าที่อนุญาตชัดเจน.
เมื่อเดินตามแต่ละขั้น ให้ถามว่า: “เราต้องรู้อะไรในภายหลัง?” Workflows มักเผยฟิลด์อย่างเช่น:
submitted_at, approved_at, completed_atcreated_by, assigned_to, approved_byrejection_reason, approval_notesequence สำหรับกระบวนการหลายขั้นถ้า workflow มีการรอ การเลื่อนขั้น หรือการส่งต่อ มักต้องมี timestamp หนึ่งรายการและฟิลด์ “ใครถือมันอยู่ตอนนี้”.
บางขั้นของ workflow ไม่ใช่แค่ฟิลด์—มันคือโครงสร้างข้อมูลแยก:
ให้ AI ทั้ง: (1) user stories และ acceptance criteria และ (2) ขั้นตอน workflow ถามให้มันระบุทุกขั้นและบอกข้อมูลที่ต้องการสำหรับแต่ละขั้น (state, actor, timestamps, outputs) แล้วเน้นข้อกำหนดที่สคีมาปัจจุบันไม่รองรับ.
ในแพลตฟอร์มอย่าง Koder.ai การตรวจสอบช่องว่างแบบนี้มีประโยชน์เพราะคุณสามารถทำซ้ำได้เร็ว: ปรับสมมติฐานสคีมา สร้างโครงสร้างใหม่ และเดินหน้าต่อโดยไม่ต้องผ่านงานบ็อยเลอร์เพลตแบบแมนนวลนานๆ.
เมื่อแปลง user stories เป็นตาราง คุณไม่ได้แค่ลงรายการฟิลด์—คุณกำลังตัดสินใจว่าข้อมูลจะยังคง ระบุได้ และ สม่ำเสมอ อย่างไรตลอดเวลา.
primary key ระบุเรคอร์ดแต่ละแถวอย่างไม่ซ้ำกัน—คิดว่ามันเหมือนบัตรประจำแถวถาวรของแถว.
ทำไมทุกแถวต้องมี: stories แสดงถึงการอัปเดต การอ้างอิง และประวัติ ถ้า story บอกว่า “Support can view an order and issue a refund,” คุณต้องมีวิธีชี้ไปยัง ออร์เดอร์นั้น อย่างเสถียร—แม้ว่าลูกค้าจะเปลี่ยนอีเมล ที่อยู่ถูกแก้ไข หรือสถานะออร์เดอร์เปลี่ยน.
ในทางปฏิบัติ มักเป็น id ภายใน (เลขหรือ UUID) ที่ไม่เปลี่ยน.
foreign key คือวิธีที่ตารางหนึ่งชี้ไปยังอีกตาราง ถ้า orders.customer_id อ้างถึง customers.id ฐานข้อมูลจะบังคับให้แต่ละออร์เดอร์ต้องเป็นของลูกค้าที่มีจริง.
นี่สอดคล้องกับ story เช่น “As a user, I can see my invoices.” ใบแจ้งหนี้ไม่ล่องลอย มันเชื่อมกับลูกค้า (และบ่อยครั้งกับ order หรือ subscription).
User stories มักมีข้อกำหนดการไม่ซ้ำ:
กฎเหล่านี้ป้องกันข้อมูลซ้ำที่สับสนซึ่งจะกลายเป็น “bug” ทางข้อมูลในภายหลัง.
Indexes ทำให้การค้นหาเช่น “find customer by email” หรือ “list orders by customer” เร็วขึ้น เริ่มจากดัชนีที่สอดคล้องกับการค้นหาที่พบบ่อยและกฎ unique.
สิ่งที่เลื่อน: การทำดัชนีหนักสำหรับรายงานที่หายากหรือฟิลเตอร์คาดการณ์ไว้ จับบันทึกข้อกำหนดไว้ แล้วปรับเมื่อเห็นช้าในคิวรีจริง.
เป้าหมายของ normalization ง่าย: ป้องกัน ข้อมูลซ้ำที่ขัดแย้ง ถ้าข้อเท็จจริงเดียวถูกเก็บในสองที่ สักวันมันจะขัดแย้ง (สะกดสองแบบ ราคาสองแบบ ที่อยู่ “ปัจจุบัน” สองค่า) สคีมาที่เป็นแบบ normalized เก็บแต่ละข้อเท็จจริงครั้งเดียว แล้วอ้างอิงมัน.
1) มองหากลุ่มที่ซ้ำ
ถ้าเห็นแบบ Phone1, Phone2, Phone3 หรือ ItemA, ItemB, ItemC นั่นคือสัญญาณให้แยกตาราง (เช่น CustomerPhones, OrderItems). กลุ่มซ้ำทำให้ค้นหา ตรวจสอบ และขยายยาก.
2) อย่าคัดลอกชื่อ/รายละเอียดซ้ำในหลายตาราง
ถ้า CustomerName ปรากฏใน Orders, Invoices, และ Shipments คุณมีแหล่งความจริงหลายแห่ง เก็บรายละเอียดลูกค้าใน Customers และเก็บ customer_id ที่อื่นแทน.
3) หลีกเลี่ยง “หลายคอลัมน์สำหรับสิ่งเดียวกัน”
คอลัมน์อย่าง billing_address, shipping_address, home_address อาจเหมาะถ้ามันต่างกันจริง แต่ถ้าคุณกำลังโมเดล “หลายที่อยู่แบบต่างประเภท” ให้ใช้ตาราง Addresses พร้อมฟิลด์ type.
4) แยก lookup จากข้อความฟรี
ถ้าผู้ใช้เลือกจากชุดที่รู้จัก (status, category, role) โมเดลให้สม่ำเสมอ: enum ที่จำกัดหรือ lookup table ป้องกัน “Pending” vs “pending” vs “PENDING.”
5) ตรวจสอบว่าทุกฟิลด์ที่ไม่ใช่ ID ขึ้นกับสิ่งที่ถูกต้อง
เช็คลางสัญชาตญาณ: ในตาราง ถ้าคอลัมน์บรรยายสิ่งที่ไม่ใช่เอนทิตีหลักของตาราง มันน่าจะอยู่ที่อื่น ตัวอย่าง: Orders ไม่ควรเก็บ product_price ยกเว้นหมายถึง “ราคาตอนสั่ง” (snapshot ทางประวัติ).
บางครั้งคุณ ตั้งใจ เก็บข้อมูลซ้ำเพื่อ:
ข้อสำคัญคือตั้งใจทำ: ระบุว่า field ไหนเป็นแหล่งความจริงและวิธีอัปเดตสำเนา.
AI สามารถชี้ความผิดปกติของการซ้ำ (คอลัมน์ซ้ำ ชื่อฟิลด์คล้ายกัน ฟิลด์ status ที่ไม่สอดคล้อง) และแนะนำการแยกเป็นตาราง มนุษย์ยังต้องตัดสินแลกเปรียบเทียบ—ความเรียบง่าย vs ความยืดหยุ่น vs ประสิทธิภาพ—ตามการใช้งานจริงของผลิตภัณฑ์.
กฎที่เป็นประโยชน์: เก็บข้อเท็จจริงที่คุณไม่สามารถสร้างซ้ำได้อย่างเชื่อถือได้ คำนวณทุกอย่างที่เหลือ.
ข้อมูลที่เก็บ คือแหล่งความจริง: รายการบรรทัด เหตุการณ์เวลากำกับ สถานะการเปลี่ยนแปลง ใครทำอะไร ข้อมูลที่คำนวณ ได้มาจากข้อเท็จจริงเหล่านั้น: ยอดรวม ตัวนับ ธงเช่น “is overdue” และการสรุปเช่น “current inventory”.
ถ้าค่าสองค่าคำนวณจากข้อเท็จจริงเดียวกัน ให้เก็บข้อเท็จจริงแล้วคำนวณค่าที่เหลือ มิฉะนั้นคุณเสี่ยงเกิดความขัดแย้ง.
ค่าที่คำนวณเปลี่ยนเมื่อ input เปลี่ยน ถ้าคุณเก็บทั้ง input และผลลัพธ์ คุณต้องรักษาความสอดคล้องในทุก workflow และกรณีมุม (แก้ไข คืนเงิน การเปลี่ยนแปลงวันที่ย้อนหลัง) หนึ่งการอัปเดตพลาดก็ทำให้ฐานข้อมูลเล่าเรื่องต่างกันได้.
ตัวอย่าง: เก็บ order_total พร้อม order_items. ถ้ามีการเปลี่ยน quantity หรือใช้ส่วนลดแล้ว total ไม่ได้อัปเดตอย่างแม่นยำ ฝ่ายการเงินจะเห็นตัวเลขหนึ่ง ขณะที่ตะกร้าแสดงอีกตัวหนึ่ง.
Workflows เผยเมื่อคุณต้องการ ความจริงในอดีต ไม่ใช่แค่ความจริงปัจจุบัน ถ้าผู้ใช้ต้องรู้ว่าค่าเป็นอย่างไร ณ เวลานั้น ให้เก็บ snapshot.
สำหรับ order คุณอาจเก็บ:
order_total ที่จับไว้ตอน checkout (snapshot), เพราะภาษี ส่วนลด และกฎราคาอาจเปลี่ยนแปลงในภายหลังสำหรับ inventory ระดับมักคำนวณจากการเคลื่อนไหว (รับสินค้า ขาย ปรับปรุง) แต่ถ้าต้องมี audit trail ให้เก็บการเคลื่อนไหวและอาจเก็บ snapshot เป็นระยะเพื่อความเร็วรายงาน.
สำหรับการติดตามล็อกอิน ให้เก็บ last_login_at เป็นข้อเท็จจริง (timestamps เหตุการณ์). “is active in the last 30 days?” คำนวณ.
มาใช้แอป support ticket ที่คุ้นเคย เราจะเริ่มจาก 5 user stories ไปสู่ ER model ง่ายๆ (entities + fields + relationships) แล้วเช็คกับ workflow หนึ่งชุด.
จากคำนาม เราได้เอนทิตีหลัก:
closed_at, insert TicketEvent(type = “closed”, actor_id = closer).ก่อน (ข้อผิดพลาดทั่วไป): Ticket มี assignee_id แต่เราลืมให้แน่ใจว่าเฉพาะ agent เท่านั้นที่เป็น assignee.
หลัง: AI แจ้งเตือนและคุณเพิ่มกฎปฏิบัติ: assignee ต้องเป็น User ที่มี role = “agent” (implement ผ่านการตรวจสอบในแอปหรือ constraint/policy ในฐานข้อมูล ขึ้นกับสแต็กของคุณ). นี่ป้องกันการ “assigned to customer” ที่ทำให้รายงานพังในภายหลัง.
สคีมาเสร็จเมื่อทุก user storyสามารถตอบได้ด้วยข้อมูลที่คุณเก็บและ query ได้อย่างเชื่อถือ วิธีการตรวจสอบที่ง่ายที่สุดคือหยิบแต่ละ story แล้วถาม: “เราตอบคำถามนี้จากฐานข้อมูลได้ไหม ในทุกกรณี?” ถ้าคำตอบคือ “อาจจะ” แปลว่ายังมีช่องว่าง.
เขียน story ใหม่เป็นคำถามทดสอบ—สิ่งที่หน้าจอ รายงาน หรือ API ควรถาม เช่น:
ถ้าคุณไม่สามารถเขียน story เป็นคำถามชัดเจน story นั้นไม่ชัด ถ้าคุณเขียนได้แต่สคีมาตอบไม่ได้ คุณขาดฟิลด์ ความสัมพันธ์ สถานะ/เหตุการณ์ หรือข้อจำกัด.
สร้างข้อมูลตัวอย่างเล็กๆ (5–20 แถวต่อแต่ละตารางสำคัญ) รวมกรณีปกติและกรณีแปลก (ซ้ำ ค่าว่าง ยกเลิก) แล้ว “เล่นตาม” stories ด้วยข้อมูลนั้น คุณจะเจอปัญหาเร็ว เช่น “เราไม่สามารถบอกได้ว่าที่อยู่ไหนถูกใช้ตอนซื้อ” หรือ “ไม่มีที่เก็บว่าใครอนุมัติการเปลี่ยนแปลง”.
ขอให้ AI สร้างคำถามตรวจสอบต่อ story (รวมกรณีมุมและสถานการณ์การลบ) และบอกว่าต้องการข้อมูลอะไรเพื่อตอบคำถามเหล่านั้น เปรียบเทียบรายการนั้นกับสคีมา: ช่องว่างไหนคือรายการงานชัดเจน ไม่ใช่ความรู้สึกว่า “บางอย่างไม่ถูกต้อง.”
AI ช่วยเร่งการออกแบบข้อมูล แต่ก็เพิ่มความเสี่ยงในการรั่วข้อมูลลับหรือการฝังสมมติฐานแย่ๆ ถือมันเป็นผู้ช่วยเร็วที่ยังต้องการกรอบควบคุม.
แชร์อินพุตที่เป็นจริงพอจะโมเดล แต่ถูก sanitize ให้ปลอดภัย:
invoice_total: 129.50, status: "paid")หลีกเลี่ยงสิ่งที่ระบุตัวบุคคลหรือเปิดเผยการปฏิบัติที่เป็นความลับ:
ถ้าต้องการความสมจริง ให้สร้างตัวอย่างสังเคราะห์ที่ตรงกับรูปแบบและช่วงค่า—อย่าคัดลอกจาก production.
สคีมาล้มเหลวบ่อยเพราะ “ทุกคนสมมติ” ต่างกัน ใส่บันทึกการตัดสินใจสั้นๆ ใกล้ ER model (หรือใน repo เดียวกัน):
นี่เปลี่ยนผลลัพธ์จาก AI ให้เป็นความรู้ทีม แทนที่จะเป็นของใช้ครั้งเดียว.
สคีมาจะวิวัฒน์ตาม stories ใหม่ เก็บความปลอดภัยโดย:
ถ้าคุณใช้แพลตฟอร์มอย่าง Koder.ai ใช้ guardrails เช่น snapshots และ rollback เมื่อทำซ้ำสคีมา และ export ซอร์สโค้ดเมื่อคุณต้องการการปรับแต่งแบบดั้งเดิมหรือรีวิวลึก.
เริ่มจาก stories แล้วเน้นคำนามที่แทนสิ่งที่ระบบต้องจดจำ (เช่น Ticket, User, Category).
เลื่อนคำนามเป็นเอนทิตีเมื่อมัน:
เก็บรายการสั้นๆ ที่คุณสามารถอ้างอิงกลับไปยังประโยคใน story ได้.
ใช้ทดสอบ “attribute vs. entity”:
customer.phone_number).ข้อสังเกตง่ายๆ: ถ้าคุณอาจต้องการ “หลายรายการ” ของสิ่งนี้ ให้พิจารณาตารางแยก.
มอง acceptance criteria เป็นเช็คลิสต์ของข้อมูลที่ต้องเก็บไว้. ถ้าข้อกำหนดบอกว่าต้องกรอง/แสดง/ตรวจสอบเรื่องใด ให้เก็บมัน (หรือสามารถคำนวณจากข้อมูลที่เก็บได้อย่างเชื่อถือได้).
ตัวอย่าง:
approved_by, approved_atdelivery_dateเขียนประโยคจาก story ใหม่เป็นประโยคความสัมพันธ์:
customer_id บน orders)order_items)ถ้าความสัมพันธ์มีข้อมูลของตัวมันเอง (quantity, price, role) ให้ใส่ข้อมูลนั้นไว้บนตารางเชื่อม.
โมเดล M:N ด้วยตารางเชื่อมที่เก็บ foreign keys ทั้งสองบวกฟิลด์ที่เกี่ยวข้องกับความสัมพันธ์.
รูปแบบทั่วไป:
ordersproductsเดินผ่าน workflow ทีละขั้นและถามว่า: “เราต้องพิสูจน์ว่ามันเกิดขึ้นจริงภายหลังยังไง?”
สิ่งที่มักต้องเพิ่ม:
submitted_at, closed_atเริ่มด้วย:
id)orders.customer_id → customers.id)จากนั้นเพิ่ม indexes สำหรับการค้นหาที่ใช้บ่อย (เช่น , , ). เลื่อนการสร้างดัชนีเชิงคาดการณ์ออกไปจนเห็นรูปแบบการใช้งานจริง.
ตรวจสอบความสอดคล้องแบบรวดเร็ว:
Phone1/Phone2 ให้แยกเป็นตารางลูก.ทำ denormalize เมื่อต้องการจริงๆ ด้วยเหตุผลชัดเจน (ประสิทธิภาพ รายงาน snapshot audit) และจดไว้ว่าแหล่งข้อมูลใดเป็น authoritative.
เก็บข้อเท็จจริงที่ไม่สามารถสร้างใหม่ได้อย่างเชื่อถือ; คำนวณสิ่งที่เหลือ.
ควรเก็บ:
ควรคำนวณ:
ถ้าคุณเก็บค่าที่ได้มาจากการคำนวณ (เช่น ) ให้ตัดสินใจว่ามีวิธีการซิงค์อย่างไรและทดสอบกรณีมุม (refunds, edits, partial shipments).
ใช้ AI ในการร่าง แล้วตรวจสอบกับ artifacts ของคุณ:
คำสั่งที่ใช้ได้ผล:
แนวทาง:
emailorder_items ที่มี order_id, product_id, quantity, unit_priceหลีกเลี่ยงการเก็บ “ลิสต์ ID” ในคอลัมน์เดียว—จะทำให้การค้นหา การอัปเดต และการรักษาความถูกต้องยากขึ้น.
created_byassigned_toclosed_byrejection_reasonถ้าคุณต้องรู้ว่าใครเปลี่ยนอะไรเมื่อไหร่ ให้เพิ่มตาราง event/audit แทนการเขียนทับฟิลด์เดียว.
emailcustomer_idstatus + created_atorder_total