01 ก.ย. 2568·4 นาที
จากไอเดียสู่แอปที่ปรับใช้ได้ในเวิร์กโฟลว์เดียว
เรื่องเล่าปฏิบัติจากต้นจนจบที่แสดงวิธีย้ายจากไอเดียแอปไปสู่ผลิตภัณฑ์ที่ปรับใช้ได้โดยใช้เวิร์กโฟลว์ที่มี AI ช่วย—ขั้นตอน คำสั่ง และการตรวจสอบ
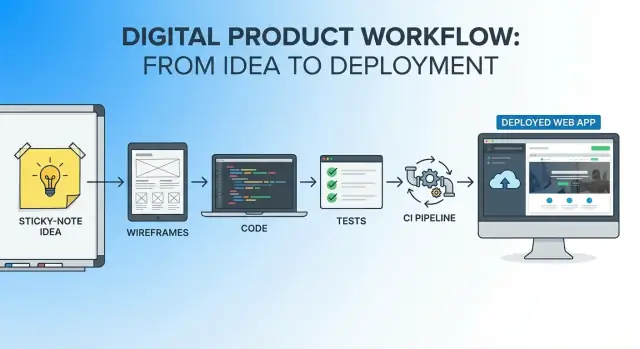
เป้าหมาย: เส้นทางเดียวต่อเนื่องจากไอเดียถึงแอปใช้งานจริง
ลองจินตนาการถึงไอเดียแอปเล็ก ๆ ที่มีประโยชน์: “Queue Buddy” ที่พนักงานคาเฟ่แตะปุ่มครั้งเดียวเพื่อเพิ่มลูกค้าในรายการรอ และส่งข้อความอัตโนมัติเมื่อโต๊ะพร้อม ตัวชี้วัดความสำเร็จชัดเจนและวัดได้: ลดการโทรสอบถามเรื่องเวลารอโดยเฉลี่ยลง 50% ในสองสัปดาห์ ในขณะที่การสอนงานพนักงานไม่เกิน 10 นาที
นี่คือจิตวิญญาณของบทความนี้: เลือกไอเดียที่ชัดเจนและมีขอบเขต กำหนดว่า “ดี” เป็นอย่างไร แล้วเดินจากแนวคิดไปสู่การปรับใช้จริงโดยไม่ต้องสลับเครื่องมือ เอกสาร และแบบคิดบ่อย ๆ
ความหมายของ “เวิร์กโฟลว์เดียว”
เวิร์กโฟลว์เดียวคือ เธรดต่อเนื่องหนึ่งเส้น ตั้งแต่ประโยคแรกของไอเดียจนถึงการปล่อยสู่โปรดักชัน:
- ที่เดียวที่บันทึกการตัดสินใจ (กำลังสร้างอะไรและทำไม)
- ชุดชิ้นงานที่พัฒนาไปพร้อมกัน (ข้อกำหนด → หน้าจอ → งาน → โค้ด → การทดสอบ → หมายเหตุการปรับใช้)
- วงจรตอบรับเดียว (การเปลี่ยนแปลงทุกอย่างสามารถย้อนกลับไปหาจุดมุ่งหมายและตัวชี้วัดได้)
คุณยังคงใช้หลายเครื่องมือ (editor, repo, CI, โฮสติ้ง) แต่คุณจะไม่ “เริ่มใหม่” โครงการในทุกเฟส เรื่องราวและข้อจำกัดเดียวกันจะเดินต่อไป
บทบาทของ AI: ผู้ช่วย ไม่ใช่ผู้ควบคุมอัตโนมัติ
AI มีประโยชน์ที่สุดเมื่อมัน:\n
- ร่างตัวเลือกได้เร็ว (การเขียนข้อกำหนด, user flows, รูปร่าง API)
- สร้างโค้ดเริ่มต้นและการทดสอบที่คุณสามารถตรวจทานเป็นชิ้นเล็ก ๆ ได้
- ชี้จุดกรณีขอบที่คุณอาจพลาด (การตรวจสอบ, สิทธิ์, การบันทึก)
แต่มันไม่ใช่เจ้าของการตัดสินใจผลิตภัณฑ์ คุณคือคนตัดสินใจ เวิร์กโฟลว์ถูกออกแบบให้คุณตรวจสอบเสมอ: การเปลี่ยนแปลงนี้ทำให้ตัวชี้วัดดีขึ้นหรือไม่? ปลอดภัยที่จะส่งหรือยัง?
เส้นทางแบบครบวงจรที่เราจะตาม
ในส่วนถัดไป คุณจะเดินตามขั้นตอนทีละขั้น:
- ชัดเจนปัญหา ผู้ใช้ และ “ชัยชนะเล็ก ๆ” ที่จะส่งได้
- เปลี่ยนไอเดียเป็นเอกสารข้อกำหนดน้ำหนักเบา
- สเก็ตช์การเดินทางผู้ใช้และหน้าจอหลัก
- เลือกสถาปัตยกรรมที่เหมาะสำหรับเวอร์ชัน 1
- บูตสแตรปโครงร่าง repo ที่ใช้งานได้
- สร้างฟีเจอร์หลักเป็นชิ้นบางที่ตรวจทานได้
- เพิ่มพื้นฐานความปลอดภัย: การตรวจสอบข้อมูล สิทธิ์ การบันทึก
- เพิ่มการทดสอบที่ปกป้องเส้นทางหลักและส่วนที่เสี่ยง
- ตั้งค่า build, CI และคุณภาพเป็นเกณฑ์
- ปรับใช้ด้วยกระบวนการที่ชัดเจนและย้อนกลับได้
- ตรวจสอบ เรียนรู้ และวนกลับ—โดยไม่ทำลายเธรด
เมื่อจบ คุณจะมีวิธีทำซ้ำได้ในการย้ายจาก “ไอเดีย” ไปสู่ “แอปใช้งานได้จริง” ในขณะที่ควบคุมขอบเขต คุณภาพ และการเรียนรู้ไว้แนบแน่น
เริ่มด้วยความชัดเจน: ปัญหา ผู้ใช้ และชัยชนะเล็ก ๆ
ก่อนขอให้ AI ร่างหน้าจอ API หรือตารางฐานข้อมูล คุณต้องมีเป้าหมายชัด ๆ ตรงนี้ชัดเจนเพียงเล็กน้อยจะประหยัดเวลาจากผลลัพธ์ที่ “เกือบถูกต้อง” ในภายหลัง
ประโยคเดียวสรุปปัญหา
คุณกำลังสร้างแอปเพราะกลุ่มคนเฉพาะประสบ friction เดิมซ้ำ ๆ: พวกเขาทำงานสำคัญไม่เสร็จเร็ว พอใจ หรือมั่นใจด้วยเครื่องมือที่มี เป้าหมายของเวอร์ชัน 1 คือเอาขั้นตอนที่เจ็บปวดออกหนึ่งข้อ—ไม่ใช่พยายามอัตโนมัติทั้งหมด—เพื่อให้ผู้ใช้จาก “ฉันต้องทำ X” เป็น “X เสร็จแล้ว” ได้ในไม่กี่นาที พร้อมบันทึกที่ชัดเจน
ผู้ใช้เป้าหมายและ 3 งานสำคัญของพวกเขา
เลือกผู้ใช้หลักหนึ่งคน ผู้ใช้รองค่อยว่ากันทีหลัง
- ผู้ใช้หลัก: ผู้ปฏิบัติงาน/เจ้าของที่ยุ่งซึ่งจัดการกระบวนการแบบ end-to-end (ไม่ใช่ผู้เชี่ยวชาญ)
- งานสำคัญ:
- จับข้อมูลร้องขอ (หรือข้อมูลเข้า) อย่างรวดเร็วโดยไม่พลาดรายละเอียดสำคัญ
- ติดตามสถานะแบบสรุปและรู้ว่าต้องทำอะไรต่อ
- แชร์ผลลัพธ์ (ยืนยัน สรุป หรือส่งออก) ที่ผู้อื่นเชื่อถือได้
ข้อสมมติฐาน (สิ่งที่ต้องเป็นจริง)
ข้อสมมติฐานคือที่ที่ไอเดียดี ๆ มักล้ม—ทำให้มันปรากฏ
- ผู้ใช้ยอมแลกการตั้งค่านิดหน่อยเพื่อกระบวนการที่ทำซ้ำได้
- ข้อมูลที่ต้องการมีอยู่ (หรือป้อนได้) อย่างแม่นยำพอสมควร
- ร่องรอยการตรวจสอบน้ำหนักเบาพอ; ฟีเจอร์การปฏิบัติตามกฎแบบเต็มรูปแบบไม่จำเป็นสำหรับ v1
- “ความช่วยเหลือของ AI” ช่วยให้เร็วขึ้น แต่ผู้ใช้ยังต้องการการควบคุมสุดท้าย
นิยามของความเสร็จสำหรับการปล่อยแรก
เวอร์ชัน 1 ควรเป็นชัยชนะเล็ก ๆ ที่ส่งได้
- ผู้ใช้ทำเส้นทางหลักเสร็จในไม่เกิน 3 นาที
- ข้อมูลถูกตรวจสอบและจัดเก็บ พร้อมสิทธิ์พื้นฐานและบันทึกกิจกรรม
- มีผลลัพธ์ที่แชร์ได้หนึ่งแบบ (อีเมล, PDF, หรือลิงก์) และสม่ำเสมอ
- คุณสามารถปรับใช้ ย้อนกลับ และตอบได้ว่า: “มันทำงานไหม?”
เปลี่ยนไอเดียเป็นเอกสารข้อกำหนดน้ำหนักเบา
เอกสารข้อกำหนดน้ำหนักเบา (คิดว่า: หนึ่งหน้า) เป็นสะพานระหว่าง “ไอเดียเจ๋ง” กับ “แผนที่สร้างได้” มันทำให้คุณโฟกัส ให้ AI มีบริบทที่ถูกต้อง และป้องกันไม่ให้เวอร์ชันแรกบานเป็นโครงการเป็นเดือน
ร่าง PRD หนึ่งหน้า (ส่วนที่สำคัญ)
ทำให้กระชับและอ่านจบเร็ว ตัวอย่างเทมเพลตเรียบง่าย:
- ปัญหา: แก้ปัญหาอะไรในหนึ่งประโยค?
- ผู้ใช้เป้าหมาย: ใครเจอปัญหานี้บ่อยที่สุด?
- ขอบเขต (เวอร์ชัน 1): จะสร้างอะไรตอนนี้
- สิ่งที่ไม่ใช่เป้าหมาย: สิ่งที่คุณชัดเจนว่าจะไม่สร้างตอนนี้ (ที่นี่แหละ scope creep ตาย)
- ข้อจำกัด: งบประมาณ ไทม์ไลน์ ข้อจำกัดทางเทคนิค ความสอดคล้อง อุปกรณ์ แหล่งข้อมูล
- ตัวชี้วัดความสำเร็จ: “มันทำงาน” เป็นอย่างไร (แม้แต่ตัวชี้วัดตัวชี้แทนง่าย ๆ ก็ใช้ได้)
กำหนดและจัดลำดับ 5–10 ฟีเจอร์หลัก
เขียน 5–10 ฟีเจอร์สูงสุดเป็นผลลัพธ์ แล้วจัดลำดับ:
- ต้องมี (app ล้มเหลวโดยไม่มีฟีเจอร์นี้)
- ควรมี (มีคุณค่าสูง แต่รอได้)
- น่าจะมี (เก็บไว้ข้างๆ)
การจัดลำดับนี้ยังเป็นวิธีนำทางแผนและโค้ดที่ AI สร้าง: “ทำเฉพาะ must-haves ก่อน”
เพิ่มเกณฑ์ยอมรับสำหรับฟีเจอร์ชั้นนำ
สำหรับ 3–5 ฟีเจอร์ด้านบน เพิ่ม 2–4 เกณฑ์ยอมรับแต่ละฟีเจอร์ ใช้ภาษาธรรมดาและเป็นสิ่งที่ทดสอบได้
ตัวอย่าง:
- ฟีเจอร์: สร้างบัญชี
- ผู้ใช้สมัครได้ด้วยอีเมลและรหัสผ่าน
- รหัสผ่านต้องมีอย่างน้อย 12 ตัวอักษร
- หลังสมัคร ผู้ใช้ไปที่แดชบอร์ด
- อีเมลซ้ำแสดงข้อความผิดพลาดที่ชัดเจน
จับข้อคำถามเปิดเพื่อยืนยันอย่างรวดเร็ว
จบด้วยรายการ “คำถามเปิด” สั้น ๆ—สิ่งที่คุณตอบได้ด้วยการแชทหนึ่งครั้ง โทรหาลูกค้าหนึ่งสาย หรือค้นหาอย่างรวดเร็ว
ตัวอย่าง: “ผู้ใช้ต้องการ Google login ไหม?” “ข้อมูลขั้นต่ำที่ต้องเก็บคืออะไร?” “ต้องอนุมัติจาก admin ไหม?”
เอกสารนี้ไม่ใช่กระดาษงาน; มันคือต้นฉบับร่วมที่คุณจะอัปเดตไปเรื่อย ๆ ระหว่างการสร้าง
สเก็ตช์การเดินทางผู้ใช้และหน้าจอหลัก
ก่อนขอให้ AI สร้างหน้าจอหรือโค้ด ให้เรียงเรื่องราวของผลิตภัณฑ์ก่อน การสเก็ตช์การเดินทางอย่างรวดเร็วทำให้ทุกคนตรงกัน: ผู้ใช้ต้องการทำอะไร ความสำเร็จเป็นอย่างไร และจุดที่อาจเกิดปัญหา
มอบแมปการไหลผู้ใช้หลัก (เส้นทางปกติ + ขอบเคสสำคัญ)
เริ่มจากเส้นทางปกติ: ลำดับที่เรียบง่ายที่สุดที่ให้คุณค่าหลัก
ตัวอย่าง flow (ทั่วไป):
- ผู้ใช้สมัคร / เข้าสู่ระบบ
- ผู้ใช้สร้าง Project ใหม่
- ผู้ใช้เพิ่ม Tasks
- ผู้ใช้ทำเครื่องหมาย Task ว่าเสร็จ
- ผู้ใช้เห็นความคืบหน้า / การยืนยัน
แล้วเพิ่มขอบเคสที่เกิดได้สูงและมีค่าเสียหายถ้าไม่ได้จัดการ:
- ผู้ใช้หยุดกลางคันในการสมัคร (ข้อมูลชั่วคราวจะจัดการยังไง?)
- ผู้ใช้เสียสิทธิ์การเข้าถึง (session หมดอายุ, สิทธิ์ถูกเพิกถอน)
- สถานะว่าง (ยังไม่มีโปรเจกต์)
- บันทึกล้มเหลว (network error) และพฤติกรรม retry
คุณไม่ต้องมีไดอะแกรมใหญ่ รายการหมายเลขพร้อมบันทึกก็เพียงพอสำหรับการทำต้นแบบและการสร้างโค้ด
ระบุหน้าจอ/เพจหลักและสิ่งที่แต่ละหน้าต้องทำให้สำเร็จ
เขียน “งานที่ต้องทำ” สั้น ๆ สำหรับแต่ละหน้าจอ โฟกัสที่ผลลัพธ์มากกว่าด้าน UI
- Login / Signup: พาผู้ใช้เข้าระบบ; อธิบายข้อผิดพลาดอย่างชัดเจน; เปิดใช้งานการรีเซ็ตรหัสผ่าน
- Dashboard: แสดงรายการปัจจุบันและการกระทำถัดไป; จัดการ empty state อย่างสวยงาม
- Project Detail: แสดงข้อมูลโปรเจกต์; เพิ่ม/แก้ไข tasks; แสดงสถานะ
- Task Editor (modal/page): สร้างหรือแก้ไข task; ตรวจสอบฟิลด์ที่จำเป็น
- Settings / Account: จัดการโปรไฟล์; ออกจากระบบ; จัดการลบบัญชีถ้าต้องการ
ถ้าคุณทำงานกับ AI รายการนี้จะเป็นวัสดุ prompt ที่ดี: “Generate a Dashboard that supports X, Y, Z and includes empty/loading/error states.”
กำหนดเอนทิตีข้อมูลในระดับสูง
เก็บที่ระดับ "สเก็ชมบนกระดาษ"—พอสำหรับหน้าจอและการไหล
- User: id, email, name, role
- Project: id, ownerId, title, createdAt
- Task: id, projectId, title, status, dueDate
บันทึกความสัมพันธ์ (User → Projects → Tasks) และสิ่งใดที่ส่งผลต่อสิทธิ์
ระบุจุดที่ต้องคำนึงถึงความเชื่อถือและความปลอดภัย
ทำเครื่องหมายจุดที่ความผิดพลาดทำลายความเชื่อถือ:
- การตรวจสอบตัวตนและการจัดการ session
- สิทธิ์ (ใครดู/แก้ไขโปรเจกต์ได้?)
- การกระทำที่ทำลายข้อมูล (ลบโปรเจกต์/Task) และการยืนยัน
- ความสามารถในการตรวจสอบ (logging พื้นฐานสำหรับการแก้ไขและลบ)
นี่ไม่ใช่การออกแบบเกินงาม—แต่เพื่อป้องกันความประหลาดใจที่เปลี่ยน “เดโมที่ใช้งานได้” ให้เป็นปัญหาฝ่ายสนับสนุนหลังปล่อย
เลือกสถาปัตยกรรมที่สมเหตุสมผลสำหรับเวอร์ชัน 1
สถาปัตยกรรมเวอร์ชัน 1 ควรทำสิ่งเดียวให้ดี: ให้คุณปล่อยผลิตภัณฑ์ที่เล็กและมีประโยชน์ได้โดยไม่ติดกับทางตัน กฎที่ดีคือ “หนึ่ง repo หนึ่ง backend ที่ปรับใช้ได้ หนึ่ง frontend ที่ปรับใช้ได้ หนึ่งฐานข้อมูล”—แล้วเพิ่มส่วนอื่นเมื่อมีความจำเป็นชัดเจน
เลือกสแตกที่เรียบง่ายที่สุดที่พอเหมาะ
ถ้าสร้างเว็บแอปทั่วไป ค่าเริ่มต้นที่สมเหตุสมผลคือ:
- Frontend: React (หรือ Next.js ถ้าต้องการ routing + server rendering พื้นฐาน)
- Backend: Node.js + framework เบา ๆ (Express/Fastify) หรือ Next.js API routes ถ้า API เล็ก
- Database: Postgres (เชื่อถือได้ ยืดหยุ่น และรองรับได้เกือบทุกที่)
รักษาจำนวนบริการให้น้อย สำหรับ v1 “modular monolith” (codebase จัดระเบียบดี แต่เป็น backend หนึ่งชิ้น) มักจะง่ายกว่าการแยกเป็นไมโครเซอร์วิส
ถ้าคุณชอบสภาพแวดล้อมที่เน้น AI เป็นหลักที่สถาปัตยกรรม งาน และโค้ดที่สร้างอยู่ใกล้กัน แพลตฟอร์มอย่าง Koder.ai อาจเหมาะ: คุณสามารถอธิบายขอบเขต v1 ในแชท ทำซ้ำใน “planning mode” และสร้าง frontend React กับ backend Go + PostgreSQL—ยังรักษาการตรวจทานและการควบคุมไว้กับคุณ
ร่าง API แบบสัญญา
ก่อนสร้างโค้ด ให้เขียนตาราง API เล็ก ๆ เพื่อให้คุณและ AI มีเป้าหมายร่วมกัน ตัวอย่างรูปแบบ:
GET /api/projects→{ items: Project[] }POST /api/projects→{ project: Project }GET /api/projects/:id→{ project: Project, tasks: Task[] }POST /api/projects/:id/tasks→{ task: Task }
เพิ่มบันทึกสำหรับรหัสสถานะ รูปแบบข้อผิดพลาด (เช่น { error: { code, message } }) และการแบ่งหน้า
ตัดสินใจเรื่องการพิสูจน์ตัวตน (หรือข้ามไป)
ถ้า v1 สามารถเป็นสาธารณะหรือผู้ใช้เดี่ยว ให้ข้าม auth เพื่อปล่อยเร็วขึ้น ถ้าต้องมีบัญชี ใช้ผู้ให้บริการจัดการ (magic link ทางอีเมลหรื OAuth) และทำสิทธิ์ให้เรียบง่าย: “ผู้ใช้เป็นเจ้าของเรคอร์ดของตัวเอง” หลีกเลี่ยงบทบาทซับซ้อนจนกว่าการใช้งานจริงจะต้องการ
ตั้งเป้าหมายประสิทธิภาพและความน่าเชื่อถือสำหรับการเปิดตัวแรก
จดข้อจำกัดปฏิบัติได้ไม่กี่ข้อ:
- ปริมาณทราฟฟิคที่คาดหวัง (แม้เป็นตัวเลขหยาบ)
- เป้าหมายเวลาในการตอบ (เช่น “คำขอส่วนใหญ่ภายใน 300ms”)
- การบันทึกขั้นพื้นฐาน (requests, errors, และเหตุการณ์ธุรกิจสำคัญ)
- การสำรองข้อมูลและแผนการย้อนกลับ
บันทึกเหล่านี้ชี้ทางให้การสร้างโค้ดด้วย AI ไปสู่สิ่งที่ปรับใช้ได้จริง ไม่ใช่แค่ใช้งานได้
บูตสแตรป Repo: จากโฟลเดอร์ว่างสู่โครงร่างทำงานได้
Keep everyone in one workflow
นำเพื่อนร่วมทีมมาร่วมในเธรดเดียวกันตั้งแต่ข้อกำหนดจนถึงการปรับใช้
วิธีที่เร็วที่สุดในการฆ่ากำลังใจคือถกเครื่องมือหลายวันแล้วยังไม่มีโค้ดรันได้ เป้าหมายที่นี่คือ: ไปให้ถึง “hello app” ที่เริ่มต้นท้องถิ่น มีหน้าจอที่มองเห็นได้ และรับคำขอได้—ในขณะที่ยังเล็กพอที่การเปลี่ยนแปลงแต่ละครั้งตรวจทานง่าย
ขอ AI ให้สร้าง skeleton ที่ใช้ได้จริง (ไม่ใช่ของเสร็จ)
ให้ prompt ที่เข้มงวด: ตัวเลือกเฟรมเวิร์ก หน้าพื้นฐาน API แบบสตับ และไฟล์ที่คาดหวัง คุณต้องการ convention ที่คาดเดาได้ ไม่ใช่ความฉลาดล้ำ
การเรียกผ่านครั้งแรกที่ดีคือโครงสร้างแบบ:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
ถ้าใช้ repo เดียว ให้ขอ routes พื้นฐาน (เช่น / และ /settings) และ endpoint API หนึ่งตัว (เช่น GET /health หรือ GET /api/status) นั่นพอพิสูจน์ว่าท่อทำงาน
ถ้าใช้ Koder.ai นี่ก็เป็นจุดเริ่มต้นตามธรรมชาติ: ขอ skeleton “web + api + database-ready” แบบน้อยที่สุด แล้วส่งออกซอร์สเมื่อพอใจกับโครงสร้างและนโยบาย
สร้าง UI ขั้นพื้นฐานเชื่อมต่อกับ backend สตับ
ทำ UI ให้ธรรมดาตั้งใจ: หน้าหนึ่ง ปุ่มหนึ่ง การเรียกหนึ่งครั้ง
พฤติกรรมตัวอย่าง:
- โฮมเพจแสดง “App is running.”
- ปุ่มเรียก endpoint ฝั่ง backend
- แสดงผลลัพธ์บนหน้า
นี่ให้วง feedback ทันที: ถ้า UI โหลดแต่การเรียกล้มเหลว คุณรู้ว่าจะดูตรงไหน (CORS, port, routing, network) หลีกเลี่ยงการเพิ่ม auth, DB, หรือสถานะซับซ้อนในขั้นนี้—ทำหลัง skeleton เสถียร
เพิ่มตัวแปรสิ่งแวดล้อมและคำแนะนำการพัฒนาในเครื่อง
สร้าง .env.example ตั้งแต่วันแรก มันป้องกันปัญหา “ทำงานบนเครื่องฉัน” และทำให้ onboarding ง่าย
ตัวอย่าง:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
แล้วทำ README ให้รันได้ในเวลาน้อยกว่าหนึ่งนาที:
- ติดตั้ง dependencies
- คัดลอก
.env.exampleเป็น.env - สตาร์ท web + api
- เปิด URL บราวเซอร์
ทำการเปลี่ยนแปลงเล็ก ๆ และ commit ตั้งแต่เนิ่น ๆ
ปฏิบัติต่อเฟสนี้เหมือนวางรากฐานให้เรียบร้อย commit หลังความสำเร็จเล็ก ๆ แต่ละครั้ง: “init repo,” “add web shell,” “add api health endpoint,” “wire web to api.” การ commit เล็ก ๆ ทำให้การทำซ้ำด้วย AI ปลอดภัย: ถ้าการเปลี่ยนแปลงที่สร้างผิดพลาด คุณย้อนกลับได้โดยไม่เสียเวลาเป็นวัน
สร้างฟีเจอร์หลักเป็นชิ้นบางที่ตรวจทานได้
เมื่อ skeleton รันครบวงจรแล้ว หลีกเลี่ยงการอยาก “ทำให้เสร็จทั้งหมด” ให้สร้าง vertical slice แคบ ๆ ที่แตะฐานข้อมูล, API, และ UI แล้วทำซ้ำ ชิ้นบางทำให้รีวิวเร็ว bug เล็ก และการช่วยจาก AI ตรวจสอบง่าย
เริ่มด้วยโมเดลข้อมูลหลัก (และ migrations)
เลือกโมเดลที่แอปไม่ทำงานได้ถ้าไม่มี—มักเป็น “สิ่ง” ที่ผู้ใช้สร้างหรือจัดการ กำหนดอย่างชัดเจน (ฟิลด์ จำเป็น vs ตัวเลือก ค่าเริ่มต้น) แล้วเพิ่ม migrations ถ้าใช้ relational DB รักษาสิ่งแรกให้เรียบ ๆ: หลีกเลี่ยง normalization ฉลาดเกินไปและความยืดหยุ่นที่เกินความจำเป็น
ถ้าใช้ AI ร่างโมเดล ให้ขอให้มันอธิบายเหตุผลของแต่ละฟิลด์และค่าเริ่มต้น ถ้ามันอธิบายไม่ได้ในหนึ่งประโยค นั่นอาจไม่สมควรอยู่ใน v1
สร้าง endpoints หลักพร้อมกฎการตรวจสอบ
สร้างเฉพาะ endpoints ที่ต้องใช้ในเส้นทางผู้ใช้แรก: มักจะเป็น create, read, และ update ขั้นพื้นฐาน วาง validation ใกล้ขอบเขต (request DTO/schema) และทำให้กฎชัดเจน:
- ฟิลด์ที่จำเป็น รูปแบบ และช่วงที่อนุญาต
- การตรวจสิทธิ์/ความเป็นเจ้าของ (“ผู้ใช้นี้เข้าถึงเรคอร์ดนี้ได้ไหม?”)
- รูปแบบการตอบที่สม่ำเสมอ (สำเร็จและล้มเหลว)
การตรวจสอบเป็นส่วนหนึ่งของฟีเจอร์ ไม่ใช่การขัดเกลา—มันป้องกันข้อมูลเละเทะที่จะทำให้คุณช้าลง
การจัดการข้อผิดพลาดที่ช่วยมนุษย์
ปฏิบัติต่อข้อความผิดพลาดเป็น UX สำหรับการดีบักและการสนับสนุน คืนข้อความที่ชัดและปฏิบัติได้ (อะไรล้มเหลวและจะแก้ยังไง) ในขณะที่ไม่เปิดเผยรายละเอียดอ่อนไหว บันทึกบริบทเชิงเทคนิคฝั่งเซิร์ฟเวอร์พร้อม request ID เพื่อให้คุณสามารถติดตามเหตุการณ์โดยไม่เดา
ใช้ข้อเสนอจาก AI—แล้วตรวจทานทุกการเปลี่ยนแปลง
ขอให้ AI เสนอการเปลี่ยนแปลงเป็นขนาด PR ทีละน้อย: หนึ่ง migration + หนึ่ง endpoint + หนึ่ง test ต่อครั้ง ตรวจทาน diff เหมือนงานเพื่อนร่วมทีม: ตรวจชื่อนิสัย กรณีขอบ สมมติความปลอดภัย และว่าการเปลี่ยนแปลงรองรับ “ชัยชนะเล็ก ๆ” ของผู้ใช้จริงหรือไม่ ถ้ามันเพิ่มฟีเจอร์เกิน ให้ตัดและเดินต่อ
ทำให้ปลอดพอสมควร: ตรวจสอบข้อมูล สิทธิ์ และการบันทึก
Release with a rollback plan
ใช้ snapshots และ rollback เพื่อให้การปล่อยงานกลับได้และไม่เครียด
เวอร์ชัน 1 ไม่ต้องการความปลอดภัยระดับองค์กร—แต่ต้องป้องกันความล้มเหลวที่คาดได้ซึ่งทำให้แอปกลายเป็นปัญหาฝ่ายสนับสนุน เป้าหมายคือ “ปลอดพอ”: ป้องกันข้อมูลไม่ดี จำกัดการเข้าถึงเริ่มต้น และทิ้งร่องรอยที่เป็นประโยชน์เมื่อมีปัญหา
การตรวจสอบข้อมูลเข้า + ป้องกันการใช้งานในทางที่ผิดพื้นฐาน
ปฏิบัติต่อทุกขอบเขตว่าเป็น untrusted: ฟิลด์ฟอร์ม, payload API, query params, และแม้แต่ webhooks ภายใน ตรวจสอบชนิด ความยาว และค่าที่อนุญาต และ normalize ข้อมูล (trim strings, convert casing) ก่อนเก็บ
ค่าปฏิบัติทั่วไป:
- Validation ฝั่งเซิร์ฟเวอร์ (เสมอ) แม้ว่าจะมี validation ใน UI
- Rate limits สำหรับการล็อกอิน รีเซ็ตรหัสผ่าน และ endpoints ที่มีค่าใช้จ่ายสูง
- การตรวจไฟล์อัปโหลด: ขนาดสูงสุดชนิด MIME ที่อนุญาต และสแกนไวรัสถ้ารับอัปโหลดสาธารณะ
- ข้อความผิดพลาดที่ปลอดภัย: บอกผู้ใช้สิ่งที่จะแก้แต่ไม่เปิดเผย stack traces หรือไอดีภายใน
ถ้าใช้ AI สร้าง handlers ให้ขอมันใส่กฎ validation อย่างชัดเจน (เช่น “max 140 chars” หรือ “must be one of: …”) แทนการบอกว่า “validate input.”
สิทธิ์: เริ่มเล็ก ปฏิเสธเป็นค่าเริ่มต้น
โมเดลสิทธิ์เรียบง่ายมักพอสำหรับ V1:
- Anonymous: เข้าถึงได้เฉพาะหน้าสาธารณะ
- Signed-in user: สร้างและดูข้อมูลของตนเองได้
- Owner/editor (ถ้าต้องการ): แก้ไขเรคอร์ดที่แชร์ได้
ทำให้การตรวจความเป็นเจ้าของเป็นศูนย์กลางและนำกลับมาใช้ใหม่ได้ (middleware/policy functions) เพื่อไม่ต้องกระจาย if userId == … ในโค้ด
การบันทึก (logging) ที่ช่วยให้ดีบักได้เร็ว
ล็อกที่ดีตอบคำถาม: เกิดอะไรขึ้น กับใคร และที่ไหน? ใส่:
- Request ID (propagate ผ่านบริการ)
- User ID (เมื่อพิสูจน์ตัวตน)
- Action + resource (เช่น
update_project,project_id) - Timing (ระยะเวลาสำหรับคำขอช้า)
ล็อกเหตุการณ์ ไม่ล็อกความลับ: ห้ามเขียนรหัสผ่าน โทเค็น หรือรายละเอียดการชำระเงินเต็มรูปแบบ
เช็คลิสต์ “ข้อผิดพลาดทั่วไป” แบบรวดเร็ว
ก่อนเรียกว่า “ปลอดพอ” ให้เช็ก:
- Auth ต้องการในทุก route ที่ไม่ใช่สาธารณะ
- การตรวจสิทธิ์ (ไม่ใช่แค่การพิสูจน์ตัวตน)
- Rate limits บน auth และ endpoints ที่เขียนหนัก
- Validation ฝั่งเซิร์ฟเวอร์สำหรับทุก input
- ความลับเก็บใน env/secret manager (ไม่ใช่ใน repo)
- Logging ที่สม่ำเสมอและไม่อ่อนไหวพร้อม request IDs
เพิ่มการทดสอบที่ปกป้องเส้นทางหลักและส่วนที่เสี่ยง
การทดสอบไม่ใช่การไล่ล่าคะแนนสมบูรณ์—แต่เพื่อป้องกันความล้มเหลวที่ทำร้ายผู้ใช้ ทำลายความเชื่อถือ หรือสร้างเหตุการณ์แก้ปัญหาแพง ในเวิร์กโฟลว์ที่มี AI เป็นผู้ช่วย การทดสอบก็เป็น “สัญญา” ที่ทำให้โค้ดที่สร้างสอดคล้องกับสิ่งที่คุณตั้งใจจริง
เริ่มจากตรรกะที่มีความเสี่ยงสูงสุด
ก่อนเพิ่มความครอบคลุมมาก ให้ระบุที่ที่ความผิดพลาดมีค่าเสียหายสูง พื้นที่เสี่ยงทั่วไปได้แก่ เงิน/เครดิต สิทธิ์ การแปลงข้อมูล และ validation ขอบเคส เขียน unit tests สำหรับส่วนเหล่านี้ก่อน เก็บให้เล็กและเฉพาะ: ให้ input X แล้วคาด output Y (หรือ error) ถ้าฟังก์ชันมีสาขามากเกินไปให้ทดสอบอย่างสะดวก นั่นคือสัญญาณว่าควรปรับให้เรียบ
เพิ่ม integration test หนึ่งหรือสองชุดสำหรับเส้นทางหลัก
Unit tests พบ bug ในตรรกะ; integration tests พบ bug ในการเชื่อมต่อ—routes, DB calls, checks, และ UI ทำงานร่วมกัน เลือก journey แกนกลาง (happy path) แล้วอัตโนมัติมัน end-to-end:
- สร้างบัญชี / เข้าสู่ระบบ
- ทำการกระทำหลักของแอป
- ยืนยันผลลัพธ์ปรากฏตามที่ผู้ใช้คาดหวัง (หน้า, อีเมล, แดชบอร์ด)
การมี integration tests หนึ่งหรือสองชุดที่ดีมักป้องกันเหตุการณ์ได้มากกว่าทดสอบย่อยนับสิบ
ใช้ AI ร่างการทดสอบ—แล้วทำให้มีความหมาย
AI ดีในการสร้างโครงการทดสอบและระบุขอบเคสที่คุณอาจพลาด ขอให้มันช่วย:
- ขอบเขต (ค่าว่าง ความยาวสูงสุด โซนเวลา)
- กรณีลบ (เข้าถึงไม่ได้ สถานะไม่ถูกต้อง)
- ตัวอย่างข้อมูลสมจริง (ไม่ใช่แค่ “foo/bar”)
แล้วตรวจทานทุก assertion การทดสอบควรตรวจพฤติกรรม ไม่ใช่รายละเอียดการทำงานภายใน ถ้าการทดสอบยังผ่านแม้มีบั๊ก แปลว่ามันไม่ได้ทำงาน
ตั้งเป้าความครอบคลุมเล็ก ๆ และเน้นความน่าเชื่อถือ
เลือกเป้าขนาดเล็ก (เช่น 60–70% ในโมดูลหลัก) และใช้เป็นแนวป้องกัน ไม่ใช่ถ้วยรางวัล เน้นการทดสอบที่เสถียร รันเร็วใน CI และล้มด้วยเหตุผลที่ถูกต้อง การทดสอบที่ flaky จะกัดกร่อนความเชื่อมั่น—และเมื่อคนเริ่มไม่เชื่อชุดทดสอบ มันก็เลิกปกป้องคุณ
เตรียมการอัตโนมัติ: Build, CI, และประตูคุณภาพ
การอัตโนมัติคือที่ที่เวิร์กโฟลว์ที่มี AI เป็นผู้ช่วยหยุดเป็นแค่ “โครงการที่รันบนเครื่องฉัน” และกลายเป็นสิ่งที่คุณปล่อยด้วยความมั่นใจ เป้าหมายไม่ใช่เครื่องมือหรู—แต่ว่าทำซ้ำได้
เริ่มจากคำสั่ง build ที่ทำซ้ำได้หนึ่งคำสั่ง
เลือกคำสั่งเดียวที่ให้ผลเหมือนกันทั้งเครื่องท้องถิ่นและ CI ถ้าใช้ Node อาจเป็น npm run build; สำหรับ Python อาจเป็น make build; สำหรับมือถือ อาจเป็นขั้นตอน Gradle/Xcode เฉพาะ
แยก config ระหว่าง development และ production ตั้งแต่เนิ่น กฎง่าย ๆ: dev สะดวก; production ปลอดภัย
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
เพิ่ม linting และ formatting เป็นประตูคุณภาพ
Linter จับรูปแบบเสี่ยง (ตัวแปรไม่ถูกใช้, async ไม่ปลอดภัย) Formatter ป้องกันการถกเถียงเรื่องสไตล์ใน diff กฎสำหรับ v1 ควรพอประมาณ แต่บังคับใช้อย่างสม่ำเสมอ
ลำดับประตูปฏิบัติได้:
- format → 2) lint → 3) tests → 4) build
ตั้งค่า CI พื้นฐาน: รันทดสอบในทุก push
workflow CI แรกของคุณอาจเล็ก: ติดตั้ง deps, รัน gates, และ fail fast นั่นเพียงพอที่จะป้องกันโค้ดเสียตกลงใน main
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
กำหนดการจัดการความลับ (และทำให้ยากต่อการทำผิด)
ตัดสินใจว่าความลับเก็บที่ไหน: CI secret store, password manager, หรือการตั้งค่า environment ของแพลตฟอร์มการปรับใช้ อย่าคอมมิตลง git—เพิ่ม .env ใน .gitignore และใส่ .env.example ที่มีตัวแทนปลอดภัย
ถ้าต้องการก้าวต่อ เชื่อมประตูพวกนี้กับกระบวนการปรับใช้ เพื่อให้ “CI ผ่าน” เป็นทางเดียวสู่โปรดักชัน
ปรับใช้สู่โปรดักชันด้วยกระบวนการที่ชัดเจนและย้อนกลับได้
Turn learning into credits
รับเครดิตโดยสร้างเนื้อหาเกี่ยวกับ Koder.ai หรือแชร์ลิงก์แนะนำของคุณ
การส่งไม่ใช่การกดปุ่มครั้งเดียว—แต่วิธีการที่ทำซ้ำได้ เป้าหมายสำหรับเวอร์ชัน 1 ง่าย: เลือกเป้าหมายการปรับใช้ที่เข้ากับสแตกของคุณ ปรับใช้ทีละน้อย และมีวิธีย้อนกลับเสมอ
เลือกเป้าหมายการปรับใช้ที่เหมาะ (อย่าซื้อเกินความจำเป็น)
เลือกแพลตฟอร์มที่พอเหมาะกับการรันแอปของคุณ:
- Static site + serverless API: Vercel / Netlify
- Docker-based web app: Render / Fly.io
- ต้องการ VM แบบดั้งเดิม: small VPS (ก็ต่อเมื่อจำเป็น)
การเน้น “ง่ายต่อการ redeploy” มักดีกว่าการเน้น “ควบคุมสูงสุด” ในขั้นนี้
ถ้าความสำคัญคือการลดการสลับเครื่องมือ พิจารณาแพลตฟอร์มที่รวม build + hosting + rollback ไว้ด้วยกัน เช่น Koder.ai ที่รองรับการปรับใช้และโฮสติ้งพร้อมกับ snapshots และ rollback เพื่อให้คุณปฏิบัติการปล่อยเป็นขั้นตอนที่ย้อนกลับได้
ใช้เช็คลิสต์การปรับใช้ทุกครั้ง
เขียนเช็คลิสต์ครั้งเดียวแล้วใช้ซ้ำในทุกการปล่อย ให้สั้นพอที่คนจะทำตามจริง:
- ยืนยันว่าสิ่งแวดล้อมและความลับถูกตั้งค่า
- รัน database migrations (หรือยืนยันว่ายังไม่ต้องมี)
- สร้างและสตาร์ทแอปด้วย config การผลิต
- รัน smoke test ของเส้นทางผู้ใช้หลัก
- ยืนยันว่าล็อกไหลและเห็นข้อผิดพลาด
ถ้าคุณเก็บไว้ใน repo (เช่น /docs/deploy.md) มันจะอยู่ใกล้โค้ดโดยธรรมชาติ
เพิ่ม
เพิ่ม health checks และ status endpoint
สร้าง endpoint เบาหวิวที่ตอบว่า: “แอปยังขึ้นและเข้าถึง dependency ได้ไหม?” รูปแบบปกติคือ:
GET /healthสำหรับ load balancers และ uptime monitorsGET /statusคืนค่าเวอร์ชันแอป + การตรวจบริการ
เก็บการตอบให้เร็ว ปลอดแคช และปลอดภัย (ไม่เผยความลับ)
วางแผน rollback ก่อนจำเป็น
แผน rollback ควรชัดเจน:
- วิธี redeploy เวอร์ชันก่อนหน้า (tag, release, หรือ image)
- จัดการ migrations ยังไง (backward-compatible ก่อน; reversible เฉพาะเมื่อจำเป็น)
- ใครตัดสินใจ rollback และสัญญาณที่กระตุ้นให้วนกลับ (อัตราข้อผิดพลาด, health checks ล้มเหลว)
เมื่อการปรับใช้ย้อนกลับได้ การปล่อยจะกลายเป็นกิจวัตร และคุณสามารถปล่อยบ่อยขึ้นโดยเครียดน้อยลง
ปิดวง: ตรวจสอบ เรียนรู้ และวนกลับในเวิร์กโฟลว์เดียวกัน
การเปิดตัวคือจุดเริ่มต้นของเฟสที่มีประโยชน์ที่สุด: เรียนรู้ว่าผู้ใช้จริงทำอะไร ที่ไหนแอปล้ม และการเปลี่ยนแปลงเล็ก ๆ ใดขยับตัวชี้วัดของคุณได้ เป้าหมายคือต่อเวิร์กโฟลว์ที่มี AI ช่วยไว้เดิม—คราวนี้ชี้ไปที่หลักฐานแทนสมมติฐาน
ตั้งค่าการมอนิเตอร์พื้นฐาน (uptime, errors, performance)
เริ่มด้วยสแตกมอนิเตอร์ขั้นต่ำที่ตอบสามคำถาม: ยังขึ้นไหม? ล้มไหม? ช้าหรือไม่?
Uptime checks อาจเรียบง่าย (เรียก health endpoint เป็นช่วงๆ) การติดตามข้อผิดพลาดควรจับ stack traces และบริบทคำขอ (ไม่เก็บข้อมูลอ่อนไหว) การมอนิเตอร์ประสิทธิภาพเริ่มจาก response times สำหรับ endpoints สำคัญและเมตริกโหลดหน้า frontend
ให้ AI ช่วยโดยสร้าง:
- รูปแบบการล็อกและ correlation IDs เพื่อให้การกระทำผู้ใช้หนึ่งรายการติดตามได้ทั้งระบบ
- เกณฑ์แจ้งเตือน (เริ่มอนุรักษ์นิยม) และเช็คลิสต์ on-call ว่าทำอะไรก่อน
เพิ่มการวิเคราะห์ผลิตภัณฑ์ที่ผูกกับตัวชี้วัดความสำเร็จ
อย่าติดตามทุกอย่าง—ติดตามสิ่งที่พิสูจน์ว่าแอปทำงาน กำหนดตัวชี้วัดความสำเร็จหลักหนึ่งตัว (เช่น: “completed checkout,” “created first project,” หรือ “invited a teammate”) แล้วติดตั้ง funnel เล็ก ๆ: เข้า → การกระทำหลัก → สำเร็จ
ขอให้ AI เสนอชื่อเหตุการณ์และ properties แล้วตรวจทานเรื่องความเป็นส่วนตัวและความชัดเจน เก็บเหตุการณ์ให้คงที่; เปลี่ยนชื่อบ่อยทำให้แนวโน้มไม่มีความหมาย
เปลี่ยนคำติชมผู้ใช้เป็นแผนปรับปรุงถัดไป
สร้างช่องทางรับ: ปุ่ม feedback ในแอป, อีเมลสั้น ๆ, และแบบฟอร์มบั๊กเบา ๆ แยกหมวดทุกสัปดาห์: รวมคำติชมเป็นธีม ผูกธีมกับ analytics และตัดสินใจปรับปรุง 1–2 อย่างต่อไป
รักษาเวิร์กโฟลว์ต่อเนื่องหลังปล่อย
ปฏิบัติต่อการแจ้งเตือนมอนิเตอร์ การตกของ analytics และธีมคำติชมเหมือนเป็น “ข้อกำหนดใหม่” ป้อนมันเข้ากระบวนการเดิม: อัปเดตเอกสาร ร่างข้อเสนอการเปลี่ยนแปลงเป็นชิ้นเล็ก ๆ ดำเนินการ เพิ่มการทดสอบเป้าหมาย และปรับใช้ผ่านกระบวนการปล่อยที่ย้อนกลับได้ สำหรับทีม หน้า “Learning Log” ร่วม (เชื่อมจาก /blog หรือเอกสารภายใน) ช่วยให้การตัดสินใจมองเห็นและทำซ้ำได้
คำถามที่พบบ่อย
What does “single workflow” mean in practice?
A “single workflow” is one continuous thread from idea to production where:
- decisions are recorded in one place
- artifacts evolve together (requirements → screens → tasks → code → tests → deploy notes)
- every change can be traced back to the goal and success metric
You can still use multiple tools, but you avoid “restarting” the project at each phase.
How should AI fit into the workflow without becoming “autopilot”?
Use AI to generate options and drafts, then you choose and verify:
- ask for requirements wording, flows, or API shapes
- request starter code in small, reviewable chunks
- have it enumerate edge cases (validation, permissions, logging)
Keep the decision rule explicit: Does this move the metric, and is it safe to ship?
How do I decide what to ship in version 1 without scope creep?
Define a measurable success metric and a tight v1 “definition of done.” For example:
- one primary user
- one core flow that completes in under 3 minutes
- validated, stored data with basic permissions and an activity log
- one shareable output (link/email/PDF)
- deploy + rollback + “is it working?” visibility
If a feature doesn’t support those outcomes, it’s a non-goal for v1.
What should a lightweight requirements doc (PRD) include?
Keep it to a skimmable, one-page PRD that includes:
- Problem (one sentence)
- Target users
- Scope (v1)
- Non-goals (explicitly)
- Constraints (time, budget, devices, compliance)
- Success metric
Then add 5–10 core features max, ranked Must/Should/Nice. Use that ranking to constrain AI-generated plans and code.
How do I write acceptance criteria that actually help build and test?
For your top 3–5 features, add 2–4 testable statements each. Good acceptance criteria are:
- written in plain language
- unambiguous (pass/fail)
- tied to a user outcome (not an implementation)
Example patterns: validation rules, expected redirects, error messages, and permission behavior (e.g., “unauthorized users see a clear error and no data leaks”).
What user flows and edge cases should I map before generating screens or code?
Start with a numbered happy path and then list a few high-likelihood, high-cost failures:
- abandoned signup / partial data handling
- expired session or revoked permission
- empty states (no data yet)
- failed saves (network errors) and retry behavior
A simple list is enough; the goal is to guide UI states, API responses, and tests.
What’s a sensible version-1 architecture for most web apps?
Default to a “modular monolith” for v1:
- one repo
- one deployable frontend
- one deployable backend
- one database (often Postgres)
Only add services when a requirement forces it. This reduces coordination overhead and makes AI-assisted iteration easier to review and revert.
How do I outline APIs so the frontend, backend, and tests stay aligned?
Write a tiny “API contract” table before code generation:
- endpoints + request/response shape
- status codes
- consistent error format (e.g.,
{ error: { code, message } }) - pagination notes if needed
This prevents mismatches between UI and backend and gives tests a stable target.
What’s the fastest way to bootstrap a repo skeleton without overbuilding?
Aim for a “hello app” that proves the plumbing works:
- one visible page
- one button that calls a stub backend endpoint (e.g.,
/health) - display the response
- include
.env.exampleand a README that runs in under a minute
Commit small milestones early so you can safely revert if a generated change goes wrong.
What tests and CI gates matter most for an AI-assisted workflow?
Prioritize tests that prevent expensive failures:
- unit tests for high-risk logic (permissions, validation, data transforms)
- 1–2 integration tests for the core happy path (sign in → primary action → confirm result)
In CI, enforce simple gates in a consistent order:
- format → 2) lint → 3) tests → 4) build
Keep tests stable and fast; flaky suites stop protecting you.