03 เม.ย. 2568·4 นาที
การจัดการสถานะข้าม Frontend และ Backend ในแอป AI
เรียนรู้การไหลของสถานะ UI, session และข้อมูลระหว่าง frontend และ backend ในแอป AI พร้อมรูปแบบปฏิบัติสำหรับการซิงค์ การเก็บถาวร การแคช และความปลอดภัย
ความหมายของ “state” ในแอปที่ใช้ AI
“State” คือทุกอย่างที่แอปต้องจำเพื่อทำงานได้ถูกต้องจากช่วงเวลาหนึ่งไปยังอีกช่วงเวลา
ถ้าผู้ใช้กด Send ใน UI ของแชท แอปไม่ควรลืมสิ่งที่พวกเขาพิมพ์ สิ่งที่ผู้ช่วยตอบไปแล้ว ว่ามีคำขอกำลังรันหรือไม่ หรือการตั้งค่าใดบ้าง (โทน โมเดล เครื่องมือ) ถูกเปิดอยู่ ทั้งหมดนั้นคือสถานะ (state)
State พูดง่าย ๆ
วิธีคิดที่เป็นประโยชน์คือ: ความจริงปัจจุบันของแอป—ค่าที่มีผลต่อสิ่งที่ผู้ใช้เห็นและสิ่งที่ระบบจะทำต่อไป นั่นรวมทั้งสิ่งที่ชัดเจนอย่างข้อมูลในฟอร์ม แต่ยังมีข้อเท็จจริง “ที่มองไม่เห็น” เช่น:
- การสนทนาที่ผู้ใช้กำลังอยู่
- ว่าการตอบล่าสุดยังเป็นการสตรีมหรือเสร็จแล้ว
- รายการข้อความและลำดับของมัน
- การเรียกใช้เครื่องมือและผลลัพธ์ของเครื่องมือ (ผลการค้นหา การดูฐานข้อมูล การสกัดไฟล์)
- ข้อผิดพลาด การลองใหม่ และการหน่วงการจำกัดอัตรา
ทำไมแอป AI ถึงมีส่วนเคลื่อนไหวมากกว่า
แอปแบบดั้งเดิมมักอ่านข้อมูล แสดง และบันทึกการอัปเดต แต่แอป AI เพิ่มขั้นตอนและผลลัพธ์ระหว่างทาง:
- การกระทำของผู้ใช้ครั้งเดียวอาจกระตุ้น หลายการทำงานด้านหลัง (เรียก LLM, เรียกเครื่องมือ, เรียก LLM อีกครั้ง)
- การตอบอาจมาถึง เป็นช่วง ๆ (สตรีมโทเค็น) ทำให้ UI ต้องจัดการสถานะบางส่วน
- บริบทสำคัญ: ระบบอาจต้องเก็บ หน่วยความจำการสนทนา ผลลัพธ์ของเครื่องมือ และการตั้งค่าโมเดลให้สอดคล้องกันในหลายคำขอ
ความเคลื่อนไหวเพิ่มเติมนี้คือเหตุผลที่การจัดการสถานะมักเป็นความซับซ้อนที่ซ่อนอยู่ในแอป AI
สิ่งที่ไกด์นี้จะครอบคลุม
ในส่วนถัดไป เราจะแยกสถานะเป็นประเภทเชิงปฏิบัติ (UI state, session state, persisted data และ model/runtime state) และแสดงว่าควรเก็บแต่ละอย่างไว้ที่ใด (frontend vs backend) เราจะพูดถึงการซิงค์ การแคช งานรันยาว การอัพเดตแบบสตรีม และความปลอดภัย—เพราะสถานะมีประโยชน์เมื่อมันถูกต้องและได้รับการปกป้อง
ตัวอย่างสถานการณ์อย่างรวดเร็ว
นึกภาพแอปแชทที่ผู้ใช้ถามว่า: “สรุปรายการแจ้งหนี้เดือนที่แล้วและระบุสิ่งผิดปกติ” ฝั่ง backend อาจ (1) ดึงข้อมูลแจ้งหนี้ (2) รันเครื่องมือวิเคราะห์ (3) สตรีมสรุปกลับไปที่ UI และ (4) บันทึกรายงานสุดท้าย
เพื่อให้รู้สึกต่อเนื่อง แอปต้องติดตามข้อความ ผลลัพธ์จากเครื่องมือ ความคืบหน้า และเอาต์พุตที่บันทึกไว้—โดยไม่สับสนการสนทนาและไม่รั่วไหลข้อมูลระหว่างผู้ใช้
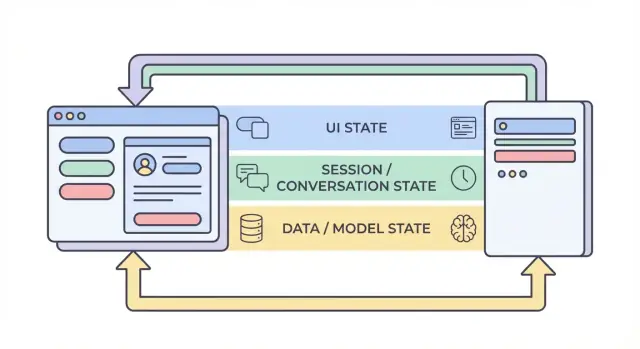
สี่ชั้นของสถานะ: UI, session, data, และ model
เมื่อคนพูดถึง “state” ในแอป AI มักจะผสมสิ่งที่ต่างกันมาก การแยกสถานะเป็นสี่ชั้น—UI, session, data, และ model/runtime—จะช่วยให้ตัดสินใจง่ายขึ้นว่า อะไร ควรอยู่ที่ไหน, ใคร เปลี่ยนได้, และ อย่างไร ควรถูกเก็บ
1) UI state (สิ่งที่ผู้ใช้กำลังทำอยู่ตอนนี้)
UI state คือสถานะแบบเรียลไทม์ในเบราว์เซอร์หรือแอปมือถือ: ข้อความที่พิมพ์ ปุ่มเปิด/ปิด รายการที่เลือก แท็บที่เปิด และปุ่มที่ถูกปิดใช้งาน
แอป AI เพิ่มรายละเอียดเฉพาะ UI บางอย่าง:
- ตัวชี้สถานะโหลดและสถานะ “กำลังคิด”
- โทเค็นที่สตรีมมา (ข้อความบางส่วนปรากฏเมื่อถูกสร้าง)
- ข้อความร่างท้องถิ่น (ก่อนส่ง)
UI state ควรรีเซ็ตง่ายและปลอดภัยถ้าหายไป ถ้าผู้ใช้รีเฟรชหน้าแล้วสูญหาย นั่นมักจะเป็นเรื่องปกติ
2) Session / conversation state (บริบทที่แชร์สำหรับฟลว์ของผู้ใช้)
Session state ผูกผู้ใช้กับการโต้ตอบที่กำลังดำเนินอยู่: ตัวตนผู้ใช้, conversation ID, และมุมมองที่สอดคล้องของประวัติข้อความ
ในแอป AI มักรวมถึง:
- ประวัติข้อความ (หรือการอ้างอิงถึงมัน)
- ร่องรอยการเรียกเครื่องมือ (เครื่องมือใดถูกเรียกและผลลัพธ์เป็นอย่างไร)
- ตัวเลือก “ชุดงาน” อย่างโปรเจกต์/เอกสารปัจจุบัน โมเดลที่เลือก หรือ workspace
ชั้นนี้มักข้าม frontend และ backend: frontend เก็บไอดีแบบน้ำหนักเบา ในขณะที่ backend เป็นผู้มีอำนาจสำหรับความต่อเนื่องของ session และการควบคุมการเข้าถึง
3) Data state (ระเบียนทนทานในที่เก็บ)
Data state คือสิ่งที่คุณตั้งใจเก็บในฐานข้อมูล: โปรเจกต์ เอกสาร embeddings การตั้งค่าผู้ใช้ บันทึกการตรวจสอบ เหตุการณ์การเรียกเก็บเงิน และสำเนาการสนทนาที่บันทึก
ไม่เหมือน UI และ session state, data state ควรจะ:
- ทนทาน (ยังอยู่หลังรีสตาร์ท)
- สามารถค้นหาได้ (สามารถค้น/กรอง)
- ตรวจสอบได้ (เข้าใจว่าเกิดอะไรขึ้นย้อนหลัง)
4) Model / runtime state (วิธีตั้งค่า AI ตอนนี้)
Model/runtime state คือการตั้งค่าการทำงานที่ใช้เพื่อสร้างคำตอบ: system prompts, เครื่องมือที่เปิดใช้, temperature/max tokens, การตั้งค่าความปลอดภัย, การจำกัดอัตรา และแคชชั่วคราวบางอย่าง
บางส่วนเป็นการกำหนดค่า (ค่าเริ่มต้นที่คงที่); บางส่วนเป็นชั่วคราว (แคชสั้นหรืองบประมาณโทเค็นต่อคำขอ) ส่วนใหญ่ควรอยู่ที่ backend เพื่อควบคุมอย่างสม่ำเสมอและไม่เปิดเผยโดยไม่จำเป็น
ทำไมการแยกชั้นช่วยลดบั๊ก
เมื่อชั้นเหล่านี้เบลอ คุณจะเจอล้มเหลวแบบคลาสสิก: UI แสดงข้อความที่ไม่ได้ถูกบันทึก, backend ใช้การตั้งค่า prompt ต่างจากที่ frontend คาดหวัง, หรือหน่วยความจำการสนทนา “รั่วไหล” ระหว่างผู้ใช้ ขอบเขตที่ชัดเจนสร้างแหล่งความจริงที่ชัดเจนขึ้น—และทำให้เห็นชัดเจนว่าสิ่งใดต้องถาวร สิ่งใดคำนวณใหม่ได้ และสิ่งใดต้องปกป้อง
อะไรควรอยู่ที่ frontend กับ backend (และทำไม)
วิธีที่เชื่อถือได้ในการลดบั๊กในแอป AI คือการตัดสินใจสำหรับแต่ละชิ้นของสถานะว่า ควรอยู่ที่ไหน: ในเบราว์เซอร์ (frontend), บนเซิร์ฟเวอร์ (backend), หรือทั้งสอง การเลือกนี้มีผลต่อความน่าเชื่อถือ ความปลอดภัย และความ “ประหลาดใจ” ที่ผู้ใช้จะเจอเมื่อรีเฟรช เปิดแท็บใหม่ หรือตัดการเชื่อมต่อ
Frontend state: เร็ว ชั่วคราว และควบคุมโดยผู้ใช้
Frontend เหมาะกับสิ่งที่เปลี่ยนเร็วและไม่จำเป็นต้องทนต่อการรีเฟรช การเก็บไว้ท้องถิ่นทำให้ UI ตอบสนองและหลีกเลี่ยงการเรียก API ที่ไม่จำเป็น
ตัวอย่างที่มักอยู่ที่ frontend เท่านั้น:
- ข้อความร่างที่ผู้ใช้พิมพ์
- ตัวกรองและลำดับการเรียงในตารางแบบท้องถิ่น
- สถานะโมดัล เปิด/ปิด แท็บที่เลือก สถานะ hover
ถ้าสูญหายเมื่อรีเฟรช โดยปกติจะรับได้
Backend state: น่าเชื่อถือ ละเอียดอ่อน และแชร์ได้
Backend ควรเก็บสิ่งที่ต้องเชื่อถือ ตรวจสอบได้ หรือบังคับใช้อย่างสม่ำเสมอ รวมทั้งสถานะที่อุปกรณ์/แท็บอื่น ๆ ต้องเห็น หรือต้องถูกต้องแม้ไคลเอนต์ถูกดัดแปลง
ตัวอย่างที่มักอยู่ที่ backend เท่านั้น:
- สิทธิ์และบทบาท (ผู้ใช้ทำอะไรได้บ้าง)
- สถานะการเรียกเก็บเงิน/แผนและข้อจำกัดการใช้งาน
- งานรันยาว (การทำดัชนีเอกสาร, การส่งออกขนาดใหญ่, การเทรนปรับแต่ง) และสถานะของมัน
แนวคิดที่ดี: ถ้าสถานะผิดพลาดแล้วอาจทำให้เสียเงิน รั่วไหลข้อมูล หรือทำลายการควบคุมการเข้าถึง ให้อยู่ที่ backend
Shared state: ประสานงาน แต่มีแหล่งความจริงเดียว
สถานะบางอย่างถูกแชร์โดยธรรมชาติ:
- ชื่อการสนทนา
- แหล่งความรู้ที่เลือกสำหรับแชท
- ฟิลด์โปรไฟล์ผู้ใช้ที่ใช้ข้ามอุปกรณ์
แม้จะแชร์ ให้เลือก “แหล่งความจริง” โดยทั่วไป backend เป็นผู้มีอำนาจแล้ว frontend เก็บแคชสำหรับความเร็ว
กฎง่าย ๆ (และรูปแบบที่ไม่ควรทำ)
เก็บสถานะใกล้จุดที่ต้องการที่สุด แต่เก็บสิ่งที่ต้องอยู่หลังรีเฟรช ข้ามอุปกรณ์ หรือการขัดจังหวะ
หลีกเลี่ยงรูปแบบที่ไม่ควรทำ เช่น เก็บสถานะละเอียดอ่อนหรือเชิงอำนาจไว้เฉพาะบนเบราว์เซอร์ (เช่น ธง isAdmin ฝั่งไคลเอนต์ ระดับแผน หรือสถานะงานเสร็จ) UI แสดงค่าได้ แต่ backend ต้องยืนยัน
วงจรคำขอ AI ทั่วไป: จากการคลิกถึงเสร็จสมบูรณ์
ฟีเจอร์ AI ดูเหมือนเป็น “การกระทำครั้งเดียว” แต่จริง ๆ เป็นโซ่ของการเปลี่ยนสถานะที่แชร์ระหว่างเบราว์เซอร์และเซิร์ฟเวอร์ การเข้าใจวงจรทำให้หลีกเลี่ยง UI ที่ไม่ตรงกัน ขาดบริบท และการเก็บเงินซ้ำได้ง่ายขึ้น
1) การกระทำของผู้ใช้ → frontend เตรียมเจตนา
ผู้ใช้กด Send UI จะอัปเดตสถานะท้องถิ่นทันที: อาจเพิ่มฟองข้อความ “pending” ปิดปุ่มส่ง และจับอินพุตปัจจุบัน (ข้อความ ไฟล์ที่แนบ เครื่องมือที่เลือก)
ตอนนี้ frontend ควรสร้างหรือแนบตัวระบุการเชื่อมโยง:
- conversation_id: เธรดที่ข้อความนี้อยู่
- message_id: ไอดีของไคลเอนต์สำหรับข้อความผู้ใช้ใหม่
- request_id: เอกลักษณ์ต่อการพยายามแต่ละครั้ง (มีประโยชน์สำหรับการลองใหม่)
ไอดีเหล่านี้ช่วยให้ทั้งสองฝั่งพูดถึงเหตุการณ์เดียวกันได้แม้การตอบมาช้า หรือซ้ำกัน
2) เรียก API → เซิร์ฟเวอร์ตรวจสอบและบันทึก
Frontend ส่งคำขอ API พร้อมข้อความผู้ใช้และไอดี เซิร์ฟเวอร์ตรวจสอบสิทธิ การจำกัดอัตรา และรูปแบบ payload แล้วจึงบันทึกข้อความผู้ใช้ (หรืออย่างน้อยบันทึกล็อกที่ไม่เปลี่ยนแปลง) โดยใช้คีย์ conversation_id และ message_id
ขั้นตอนการเก็บรักษานี้ป้องกัน “ประวัติผี” เมื่อผู้ใช้รีเฟรชกลางคำขอ
3) เซิร์ฟเวอร์สร้างบริบทขึ้นใหม่
เพื่อเรียกโมเดล เซิร์ฟเวอร์สร้างบริบทจากแหล่งความจริงของตน:
- ดึงข้อความล่าสุดสำหรับ
conversation_id - ดึงบันทึกที่เกี่ยวข้อง (เอกสาร การตั้งค่า เครื่องมือ)
- ใช้นโยบายการสนทนา (system prompts, กฎหน่วยความจำ, การตัดทอน)
แนวคิดสำคัญ: อย่าไว้วางใจให้ไคลเอนต์ส่งประวัติทั้งหมด ไคลเอนต์อาจล้าสมัย
4) การเรียกโมเดล/เครื่องมือ → สถานะกลางทาง
เซิร์ฟเวอร์อาจเรียกเครื่องมือ (ค้นหา ดูฐานข้อมูล) ก่อนหรือระหว่างการสร้างของโมเดล การเรียกแต่ละครั้งสร้างสถานะกลางทางที่ควรถูกติดตามกับ request_id เพื่อให้สามารถตรวจสอบและลองใหม่ได้อย่างปลอดภัย
5) การตอบ (สตรีมหรือไม่) → เสร็จสิ้นที่ UI
เมื่อสตรีม เซิร์ฟเวอร์ส่งโทเค็น/เหตุการณ์บางส่วน UI จะอัปเดตข้อความผู้ช่วยที่ค้างเป็นช่วง ๆ แต่ยังถือว่าเป็น “กำลังดำเนินการ” จนกว่าเหตุการณ์สุดท้ายจะมาบ่งชี้ว่าจบแล้ว
6) จุดล้มเหลวที่ต้องวางแผน
การลองใหม่ การส่งซ้ำ และการตอบที่ออกนอกลำดับเกิดขึ้นได้ ใช้ request_id เพื่อลดการซ้ำบนเซิร์ฟเวอร์ และ message_id เพื่อปรับให้ UI สอดคล้อง (ไม่สนใจชิ้นส่วนที่มาช้าซึ่งไม่ตรงกับคำขอปัจจุบัน) แสดงสถานะ “ล้มเหลว” ชัดเจนพร้อมการลองใหม่ที่ปลอดภัยซึ่งจะไม่สร้างข้อความซ้ำ
เซสชันและหน่วยความจำการสนทนา: เก็บบริบทโดยไม่วุ่นวาย
Keep state secure
Generate server-side authorization checks and safe validation patterns for state writes.
Session คือ “เธรด” ที่ผูกการกระทำของผู้ใช้เข้าด้วยกัน: workspace ที่อยู่ คำค้นล่าสุดที่ค้นหา ข้อความร่างที่แก้ไข และการสนทนาที่คำตอบของ AI ควรต่อยอด หน่วยความจำ session ที่ดีทำให้แอปรู้สึกต่อเนื่องข้ามหน้า—และข้ามอุปกรณ์—โดยไม่เปลี่ยน backend ให้เป็นที่ทิ้งของข้อมูลทั้งหมดที่ผู้ใช้เคยพูด
เป้าหมายของ session state
ตั้งเป้าให้ได้: (1) ความต่อเนื่อง (ผู้ใช้กลับมาได้), (2) ความถูกต้อง (AI ใช้บริบทที่ถูกต้องสำหรับการสนทนาที่ถูกต้อง), และ (3) การกักกัน (session หนึ่งไม่รั่วไหลไปยังอีกอัน) หากสนับสนุนหลายอุปกรณ์ ให้ถือว่า session เป็น scope ของผู้ใช้รวมกับ scope ของอุปกรณ์: “บัญชีเดียวกัน” ไม่ได้หมายความว่า “งานที่เปิดเหมือนกันเสมอไป”
คุกกี้ vs โทเค็น vs เซสชันบนเซิร์ฟเวอร์
โดยทั่วไปคุณจะเลือกหนึ่งในวิธีเหล่านี้เพื่อระบุ session:
- Cookies: ง่ายที่สุดสำหรับเว็บเพราะเบราว์เซอร์ส่งให้โดยอัตโนมัติ ดีสำหรับ session แบบดั้งเดิม แต่ต้องตั้งธงความปลอดภัย (
HttpOnly,Secure,SameSite) และจัดการ CSRF - Tokens (เช่น JWT): ดีสำหรับ API และแอปมือถือเพราะไคลเอนต์แนบเองได้ เหมาะกับการสเกล แต่การเพิกถอนและการหมุนต้องออกแบบเพิ่ม (และไม่ควรใส่สถานะละเอียดอ่อนลงในโทเค็น)
- Server sessions: เซิร์ฟเวอร์เก็บข้อมูล session (มักใน Redis) และไคลเอนต์ถือเฉพาะไอดี session ที่ไม่สามารถอ่านได้ ง่ายต่อการเพิกถอนและอัปเดต แต่ต้องรันและสเกลสตอร์ session
ยุทธศาสตร์หน่วยความจำการสนทนา
“หน่วยความจำ” คือสถานะที่คุณเลือกส่งกลับเข้าไปในโมเดล
- ประวัติเต็ม: แม่นยำที่สุด แต่แพงและอาจเปิดเผยเนื้อหาเก่าๆ ที่ละเอียดอ่อน
- สรุปประวัติ: เก็บสรุปแบบรันนิ่งบวกกับไม่กี่เทิร์นล่าสุด ถูกกว่าและมักเพียงพอ
- บริบทแบบหน้าต่าง: เฉพาะ N ข้อความล่าสุด ง่ายสุดแต่เสียการตัดสินใจก่อนหน้าได้
รูปแบบที่ใช้งานได้จริงคือ สรุป + หน้าต่าง: คาดเดาได้และช่วยหลีกเลี่ยงพฤติกรรมของโมเดลที่น่าตกใจ
การเรียกเครื่องมือ: ทำซ้ำได้และตรวจสอบได้
ถ้า AI ใช้เครื่องมือ (ค้นหา, คิวรีฐานข้อมูล, อ่านไฟล์), เก็บการเรียกแต่ละครั้งพร้อม: อินพุต, ตราประทับเวลา, เวอร์ชันของเครื่องมือ, และผลลัพธ์ที่คืน (หรือการอ้างอิงถึงมัน) นี่ช่วยให้คุณอธิบายได้ว่า “ทำไม AI ถึงพูดแบบนั้น”, เล่นซ้ำเพื่อดีบัก, และตรวจจับเมื่อผลลัพธ์เปลี่ยนเพราะเครื่องมือหรือชุดข้อมูลเปลี่ยน
แนวทางการคุ้มครองความเป็นส่วนตัว
อย่าเก็บหน่วยความจำระยะยาวโดยค่าเริ่มต้น เก็บเฉพาะสิ่งที่ต้องใช้สำหรับความต่อเนื่อง (conversation IDs, สรุป และบันทึกเครื่องมือ), ตั้งขอบเขตการเก็บรักษา และหลีกเลี่ยงการบันทึกข้อความดิบของผู้ใช้หากไม่มีเหตุผลชัดเจนและความยินยอมของผู้ใช้
การซิงค์สถานะอย่างปลอดภัย: แหล่งความจริงและการจัดการความขัดแย้ง
สถานะเสี่ยงเมื่อสิ่งเดียวกันถูกแก้ไขได้จากหลายที่—UI ของคุณ แท็บเบราว์เซอร์ที่สอง หรืองานแบ็กกราวด์ การแก้คือการกำหนดความเป็นเจ้าของชัดเจนมากกว่าการเขียนโค้ดฉลาด
กำหนดแหล่งความจริง
ตัดสินใจว่าระบบใดเป็นผู้มีอำนาจสำหรับแต่ละชิ้นของสถานะ ในแอป AI ส่วนใหญ่ backend ควรเป็นเจ้าของบันทึกหลักสำหรับสิ่งที่ต้องถูกต้อง: การตั้งค่าการสนทนา, สิทธิ์เครื่องมือ, ประวัติข้อความ, ขีดจำกัดบิลลิ่ง, และสถานะงาน ฝั่ง frontend เก็บแคชเพื่อความเร็ว แต่ควรถือว่า backend ถูกต้องเมื่อเกิดความขัดแย้ง
กฎปฏิบัติ: ถ้าคุณจะโกรธเมื่อสูญเสียมันตอนรีเฟรช มันคงอยู่ที่ backend
อัพเดต UI แบบ Optimistic (ใช้ระมัดระวัง)
Optimistic updates ทำให้แอปรู้สึกทันใจ: เปลี่ยน UI ทันทีแล้วยืนยันกับเซิร์ฟเวอร์ วิธีนี้เหมาะกับการกระทำที่เสี่ยงต่ำและย้อนกลับได้ (เช่น การติดดาวการสนทนา)
จะทำให้สับสนเมื่อเซิร์ฟเวอร์อาจปฏิเสธหรือแปลงค่า (เช่น การตรวจสิทธิ์ ขีดจำกัด ค่าที่เซิร์ฟเวอร์ใส่) ในกรณีนั้น ให้แสดงสถานะ “กำลังบันทึก…” และอัปเดต UI หลังการยืนยัน
จัดการความขัดแย้ง (สองแท็บ อัปเดตร่วมกัน)
ความขัดแย้งเกิดเมื่อไคลเอนต์สองตัวอัปเดตบันทึกเดียวกันจากเวอร์ชันเริ่มต้นที่ต่างกัน ตัวอย่างทั่วไป: แท็บ A และ แท็บ B เปลี่ยนค่า temperature ของโมเดล
ใช้การกำหนดเวอร์ชันเบา ๆ เพื่อให้ backend ตรวจจับการเขียนเก่า:
- เวลาที่อัปเดต (
updated_at) (เรียบง่ายและอ่านได้) - ETags / เฮดเดอร์
If-Match(เป็นมาตรฐาน HTTP) - หมายเลข revision เพิ่มขึ้น (ตรวจจับความขัดแย้งอย่างชัดเจน)
ถ้าเวอร์ชันไม่ตรง ให้คืนการตอบสนองความขัดแย้ง (เช่น HTTP 409) และส่งกลับวัตถุเซิร์ฟเวอร์ล่าสุด
ออกแบบ API เพื่อลดการไม่ตรงกัน
หลังการเขียน ให้ API คืนวัตถุที่บันทึกแล้ว (รวมค่าเริ่มต้นที่เซิร์ฟเวอร์สร้าง ฟิลด์ที่ถูกปกติ และเวอร์ชันใหม่) เพื่อให้ frontend แทนที่แคชของตนทันที—เป็นการอัปเดตแหล่งความจริงครั้งเดียวแทนการเดาว่ามีอะไรเปลี่ยน
การแคชและประสิทธิภาพ: เร่งความเร็วโดยไม่ทำให้สถานะเก่า
การแคชคือวิธีที่เร็วที่สุดวิธีหนึ่งทำให้แอป AI รู้สึกทันใจ แต่ก็สร้างสำเนาของสถานะอีกชั้น หากคุณแคชผิดหรือแคชผิดที่ คุณจะส่ง UI ที่เร็วแต่สับสน
ควรแคชอะไรบนไคลเอนต์
แคชฝั่งไคลเอนต์ควรมุ่งที่ประสบการณ์ ไม่ใช่อำนาจ ตัวอย่างที่เหมาะสมได้แก่ ตัวอย่างการสนทนาล่าสุด (หัวข้อ ข้อความย่อ), การตั้งค่า UI (ธีม โมเดลที่เลือก แถบด้านข้าง), และสถานะ UI แบบ optimistic (ข้อความที่กำลังส่ง)
ให้แคชฝั่งไคลเอนต์เล็กและทิ้งได้: ถ้าล้างแล้ว แอปยังทำงานได้โดยการดึงข้อมูลจากเซิร์ฟเวอร์
ควรแคชอะไรบนเซิร์ฟเวอร์
แคชบนเซิร์ฟเวอร์ควรมุ่งที่งานที่แพงหรือถูกเรียกซ้ำบ่อย:
- ผลลัพธ์เครื่องมือที่ปลอดภัยต่อการใช้ซ้ำ (เช่น ข้อมูลสภาพอากาศสำหรับเมืองเดียวกันภายใน 5 นาที)
- การค้นหา embedding และผลการค้นหาเวกเตอร์สำหรับคำถามที่ซ้ำกัน (มักมี TTL สั้น)
- สถานะการจำกัดอัตราและเคาน์เตอร์การบังคับ (เพื่อปกป้อง API และต้นทุน)
ที่นี่ยังสามารถแคชสถานะที่ได้จากการประมวลผล เช่น การนับโทเค็น การตัดสินการตรวจสอบเนื้อหา หรือการแยกเอกสาร—สิ่งที่เป็นผลลัพธ์ที่กำหนดได้และมีค่าใช้จ่ายสูง
พื้นฐานการยกเลิกแคช (ไม่ต้องซับซ้อน)
สามกฎปฏิบัติ:
- ใช้คีย์แคชที่ชัดเจนที่เข้ารหัสอินพุต (
user_id, model, พารามิเตอร์ของเครื่องมือ, เวอร์ชันเอกสาร) - ตั้ง TTL ตามความเร็วที่ข้อมูลพื้นฐานเปลี่ยน ค่า TTL สั้นมักดีกว่าโลจิกซับซ้อน
- ข้ามแคชเมื่อความถูกต้องสำคัญมากกว่าเร็ว: หลังผู้ใช้แก้ไขเอกสาร เปลี่ยนสิทธิ์ หรือร้องขอรีเฟรช
ถ้าคุณอธิบายไม่ได้ว่าเมื่อไหร่แคชจะผิด อย่าแคช
ห้ามแคชความลับหรือข้อมูลส่วนบุคคลในแคชที่แชร์
อย่าใส่ API keys โทเค็นยืนยันตัวตน prompt ดิบที่มีข้อความละเอียดอ่อน หรือเนื้อหาผู้ใช้ในเลเยอร์แชร์เช่น CDN แคช หากต้องแคชข้อมูลผู้ใช้ ให้แยกตามผู้ใช้และเข้ารหัสขณะพัก หรือเก็บในฐานข้อมูลหลักแทน
วัดผลกระทบ: ความเร็ว vs UI เก่า
การแคชต้องพิสูจน์ ไม่ใช่สมมติ ติดตาม p95 latency ก่อน/หลัง อัตราการโดนแคช และข้อผิดพลาดที่ผู้ใช้เห็นเช่น “ข้อความอัปเดตหลังการเรนเดอร์” การตอบสนองที่เร็วแต่ขัดแย้งกับ UI มักแย่กว่าการตอบช้ากว่าเล็กน้อยแต่สอดคล้อง
ความคงอยู่และงานรันยาว: งาน แถว และสถานะงาน
Deploy without extra setup
Go from chat to hosted web and backend builds without managing a full pipeline.
ฟีเจอร์ AI บางอย่างเสร็จภายในวินาที แต่บางอย่างใช้เวลานาที: อัปโหลดและแยก PDF, สร้าง embedding และทำดัชนีฐานความรู้, หรือรันเวิร์กโฟลว์แบบหลายขั้นตอน สำหรับสิ่งเหล่านี้ “สถานะ” ไม่ใช่แค่อยู่บนหน้าจอ—มันคือสิ่งที่อยู่หลังรีเฟรช ลองใหม่ และเวลา
ควรเก็บอะไร (และทำไม)
เก็บเฉพาะสิ่งที่ปลดล็อกคุณค่าจริง
ประวัติการสนทนา เป็นสิ่งชัดเจน: ข้อความ ตราประทับเวลา ตัวตนผู้ใช้ และ (มัก) โมเดล/เครื่องมือที่ใช้ นี่ขับเคลื่อนการกลับมาครั้งต่อไป บันทึกตรวจสอบ และการสนับสนุน
การตั้งค่าผู้ใช้และ workspace ควรอยู่ในฐานข้อมูล: โมเดลที่ชอบ ค่าเริ่มต้น temperature, ฟีเจอร์โท글, system prompts, การตั้งค่า UI ที่ติดตามผู้ใช้ข้ามอุปกรณ์
ไฟล์และอาร์ติแฟ็กต์ (ไฟล์ที่อัปโหลด ข้อความที่สกัด รายงานที่สร้าง) มักเก็บใน object storage โดยมีบันทึกฐานข้อมูลชี้ถึงไฟล์ ฐานข้อมูลเก็บเมตาดาต้า (เจ้าของ ขนาด ประเภทเนื้อหา สถานะการประมวลผล) ขณะที่ blob store เก็บเนื้อหา
งานแบ็กกราวด์สำหรับงานยาว
ถ้าคำขอไม่สามารถจบได้ภายใน timeout HTTP ปกติ ให้ย้ายงานไปที่คิว
รูปแบบทั่วไป:
- Frontend เรียก API เช่น
POST /jobsพร้อมอินพุต (id ไฟล์, conversation id, พารามิเตอร์) - Backend เข้าคิวงาน (การสกัด การทำดัชนี การรันชุดเครื่องมือ) และคืน
job_idทันที - workers ประมวลผลงานแบบอะซิงโครนัสและเขียนผลกลับไปที่สตอเรจถาวร
วิธีนี้ทำให้ UI ตอบสนองและการลองใหม่ปลอดภัยกว่า
สถานะที่ UI เชื่อถือได้
ทำให้สถานะงานชัดเจนและสามารถสอบถามได้: queued → running → succeeded/failed (ตัวเลือก canceled ได้) เก็บการเปลี่ยนแปลงเหล่านี้บนเซิร์ฟเวอร์พร้อมตราประทับเวลาและรายละเอียดข้อผิดพลาด
ฝั่ง frontend สะท้อนสถานะอย่างชัดเจน:
- Queued/running: แสดงสปินเนอร์และปิดการกระทำซ้ำ
- Failed: แสดงข้อผิดพลาดสั้น ๆ พร้อมปุ่ม Retry
- Succeeded: โหลดอาร์ติแฟ็กต์ที่ได้หรืออัปเดตการสนทนา
เปิด GET /jobs/{id} (polling) หรือสตรีมอัพเดต (SSE/WebSocket) เพื่อให้ UI ไม่ต้องเดา
Idempotency keys: ลองใหม่โดยไม่เขียนซ้ำ
เวลาขัดข้องเครือข่ายเกิดขึ้น ถ้า frontend ลอง POST /jobs ซ้ำ คุณไม่ต้องการงานซ้ำสองงาน (และค่าใช้จ่ายสองเท่า)
กำหนดให้มี Idempotency-Key ต่อการกระทำเชิงตรรกะ เซิร์ฟเวอร์เก็บคีย์พร้อม job_id/การตอบสนองที่ได้และคืนผลเดิมสำหรับคำขอซ้ำ
นโยบายล้างข้อมูลและหมดอายุ
แอป AI ที่รันเร็วสะสมข้อมูลเร็ว กำหนดกฎการเก็บรักษาตั้งแต่เนิ่น ๆ:
- ลบการสนทนาเก่า ๆ หลัง N วัน (หรือให้ผู้ใช้ตั้งค่า)
- ลบอาร์ติแฟ็กต์ที่ได้เมื่อแหล่งที่มาถูกลบ
- ล้างงานล้มเหลวและไฟล์กลางเป็นระยะ
ถือว่าการล้างข้อมูลเป็นส่วนหนึ่งของการจัดการสถานะ: ลดความเสี่ยง ต้นทุน และความสับสน
การตอบสนองแบบสตรีมและอัพเดตเรียลไทม์: จัดการสถานะบางส่วน
การสตรีมทำให้สถานะซับซ้อนขึ้นเพราะ “คำตอบ” ไม่ใช่ก้อนเดียวอีกต่อไป คุณรับมือกับโทเค็นบางส่วน (ข้อความทีละคำ) และบางครั้งงานเครื่องมือก็มาเป็นช่วง ๆ นั่นหมายความว่า UI และ backend ต้องตกลงกันว่าอะไรคือชั่วคราวและอะไรคือสถานะสุดท้าย
ฝั่ง backend: สตรีมเหตุการณ์ที่มีประเภท อย่าส่งแค่ข้อความ
รูปแบบที่สะอาดคือสตรีมลำดับของเหตุการณ์เล็ก ๆ แต่ละอันมีชนิดและเพย์โหลด เช่น:
token: ข้อความแบบเพิ่มทีละน้อย (หรือชิ้นเล็ก ๆ)tool_start: การเรียกเครื่องมือเริ่ม (เช่น “กำลังค้นหา…”, พร้อม id)tool_result: ผลลัพธ์ของเครื่องมือพร้อม id เดิมdone: ข้อความผู้ช่วยเสร็จแล้วerror: เกิดข้อผิดพลาด (รวมข้อความที่ปลอดภัยสำหรับผู้ใช้และ debug id)
สตรีมเหตุการณ์แบบนี้เวอร์ชันได้และดีบักได้ง่ายกว่าเพราะ frontend สามารถเรนเดอร์ความคืบหน้าได้อย่างแม่นยำ (และแสดงสถานะเครื่องมือ) โดยไม่ต้องเดา
ฝั่ง frontend: อัพเดตแบบ append-only แล้วคอมมิทเมื่อเสร็จ
ฝั่งไคลเอนต์ถือการสตรีมเป็น append-only: สร้างข้อความผู้ช่วย “ร่าง” แล้วเพิ่มเนื้อหาเมื่อได้รับเหตุการณ์ token เมื่อได้รับ done ให้คอมมิท: ทำเครื่องหมายข้อความเป็นสุดท้าย บันทึกมัน (ถ้าคุณเก็บท้องถิ่น) และปลดล็อกการกระทำเช่น คัดลอก ให้คะแนน หรือสร้างใหม่
วิธีนี้หลีกเลี่ยงการเขียนประวัติซ้ำกลางสตรีมและทำให้ UI คาดเดาได้
จัดการการขัดจังหวะ (ยกเลิก ตัดการ เชื่อมต่อ)
การสตรีมเพิ่มโอกาสงานเสร็จครึ่งหนึ่ง:
- ผู้ใช้ยกเลิก: ส่งสัญญาณยกเลิก; หยุดเรนเดอร์โทเค็น; เก็บร่างเป็นสถานะยกเลิกให้เห็น
- การเชื่อมต่อขาด: หยุดสตรีม; แสดง “กำลังเชื่อมต่อใหม่…” และอย่าสมมติว่าจบแล้ว
- เซิร์ฟเวอร์หมดเวลา/ข้อผิดพลาด: ทำให้ร่างเป็นล้มเหลว และให้ทางเลือกลองใหม่ที่เริ่มคำขอใหม่ (อย่าต่อสตรีมเงียบ ๆ)
การรีไฮเดรต: โหลดใหม่และสร้างสถานะที่เสถียรขึ้นใหม่
ถ้าหน้ารีโหลดกลางสตรีม ให้สร้างขึ้นจากสถานะที่เสถียรล่าสุด: ข้อความสุดท้ายที่คอมมิทแล้วบวกเมตาดาต้าร่าง (message id, ข้อความที่สะสมจนถึงตอนนั้น, สถานะเครื่องมือ) ถ้าไม่สามารถต่อสตรีมได้ ให้แสดงร่างเป็นถูกขัดจังหวะและให้ผู้ใช้ลองใหม่ แทนที่จะแกล้งทำว่าเสร็จ
ความปลอดภัยและความเป็นส่วนตัว: ปกป้องสถานะตั้งแต่ต้นทางถึงปลายทาง
Export and own the code
Generate fast, then export the source code to extend it your way.
สถานะไม่ใช่แค่ “ข้อมูลที่คุณเก็บ” — มันคือ prompt ของผู้ใช้ อัปโหลด การตั้งค่า ผลลัพธ์ที่สร้าง และเมตาดาต้าที่ผูกทุกอย่างเข้าด้วยกัน ในแอป AI สถานะนั้นอาจละเอียดอ่อนเป็นพิเศษ (ข้อมูลส่วนบุคคล เอกสารกรรมสิทธิ์ การตัดสินใจภายใน) ดังนั้นความปลอดภัยต้องถูกออกแบบในแต่ละชั้น
เก็บความลับไว้บนเซิร์ฟเวอร์
สิ่งที่ทำให้ไคลเอนต์ปลอมเป็นแอปของคุณต้องอยู่ที่ backend เท่านั้น: API keys, ตัวเชื่อมต่อส่วนตัว (Slack/Drive/DB credentials), และ system prompts หรือโลจิกการกำหนดเส้นทางภายใน ฝั่ง frontend ขอการกระทำได้ (“สรุปไฟล์นี้”) แต่ backend ควรตัดสินใจว่าจะประมวลผลอย่างไรและด้วยสิทธิ์ใด
อนุญาตทุกการเขียน (และหลายการอ่าน)
จัดการแต่ละการเปลี่ยนแปลงสถานะเป็นการดำเนินการที่มีสิทธิ์ เมื่อไคลเอนต์พยายามสร้างข้อความ เปลี่ยนชื่อการสนทนา หรือแนบไฟล์ Backend ควรตรวจสอบ:
- ผู้ใช้เข้าสู่ระบบแล้ว
- ผู้ใช้เป็นเจ้าของทรัพยากร (conversation, workspace, project)
- ผู้ใช้ได้รับอนุญาตให้ทำการนั้น (บทบาท ขีดจำกัดแผน นโยบายองค์กร)
นี้ป้องกันการโจมตีแบบ “เดา ID” ที่คนสลับ conversation_id แล้วเข้าถึงประวัติของผู้อื่น
อย่าไว้วางใจเบราว์เซอร์: ตรวจสอบและทำความสะอาด
สมมติว่าอินพุตจากไคลเอนต์ไม่เชื่อถือได้ ตรวจสอบสคีมาและข้อจำกัด (ชนิด ความยาว ค่า enum ที่อนุญาต) และทำความสะอาดสำหรับปลายทาง (SQL/NoSQL, logs, การเรนเดอร์ HTML) หากรับ “อัพเดตสถานะ” (เช่น การตั้งค่า พารามิเตอร์เครื่องมือ) whitelist ฟิลด์ที่อนุญาตแทนการรวม JSON โดยพลการ
บันทึกการตรวจสอบสำหรับการกระทำที่สำคัญ
สำหรับการกระทำที่เปลี่ยนสถานะถาวร—การแชร์ การส่งออก การลบ การเข้าถึงตัวเชื่อมต่อ—บันทึกว่าใครทำอะไรเมื่อไหร่ บันทึกการตรวจสอบแบบเบา ๆ ช่วยการตอบสนองต่อเหตุการณ์ การสนับสนุนลูกค้า และการปฏิบัติตามข้อกำหนด
การลดข้อมูลและการเข้ารหัส
เก็บเฉพาะสิ่งที่จำเป็นในการให้ฟีเจอร์ ถ้าไม่จำเป็นต้องเก็บ prompt ตลอดไป ให้พิจารณาหน้าต่างการเก็บรักษาหรือการตัดทอน เข้ารหัสข้อมูลละเอียดอ่อนขณะพักเมื่อเหมาะสม (โทเค็น, ข้อมูลเชื่อมต่อ), ใช้ TLS ขณะส่ง และแยกเมตาดาต้าการปฏิบัติจากเนื้อหาเพื่อจำกัดการเข้าถึง
สถาปัตยกรรมอ้างอิงเชิงปฏิบัติและเช็กลิสต์การสร้าง
ค่าเริ่มต้นที่มีประโยชน์สำหรับแอป AI คือเรียบง่าย: backend เป็นแหล่งความจริง, และ frontend เป็นแคชที่เร็วและคาดเดาได้ UI ให้ความรู้สึกทันใจ แต่สิ่งที่คุณเสียใจถ้ามันหายไป (ข้อความ สถานะงาน ผลลัพธ์ของเครื่องมือ เหตุการณ์ที่มีผลต่อการเรียกเก็บเงิน) ควรได้รับการยืนยันและจัดเก็บที่เซิร์ฟเวอร์
ถ้าคุณสร้างด้วยเวิร์กโฟลว์แบบ “vibe-coding”—ที่พื้นผิวผลิตภัณฑ์ถูกสร้างได้เร็ว—โมเดลสถานะจะสำคัญขึ้น แพลตฟอร์มอย่าง Koder.ai ช่วยทีมส่งแอปเว็บ แบ็กเอนด์ และมือถือจากแชทได้ แต่กฎเดิมยังคงใช้: การวนซ้ำเร็วปลอดภัยเมื่อแหล่งความจริง ไอดี และการเปลี่ยนสถานะถูกออกแบบล่วงหน้า
สถาปัตยกรรมอ้างอิง (ที่คุณส่งได้)
Frontend (เบราว์เซอร์/มือถือ)
- UI state: แผงที่เปิด ข้อความร่าง โมเดลที่เลือก ตัวบ่งชี้ “กำลังพิมพ์” ชั่วคราว
- แคชสถานะจากเซิร์ฟเวอร์: การสนทนาล่าสุด สถานะงานที่รู้ล่าสุด บัฟเฟอร์สตรีมบางส่วน
- ท่อคำขอเดียวที่แนบเสมอ:
session_id,conversation_id, และrequest_idใหม่
Backend (API + workers)
- บริการ API: ตรวจสอบอินพุต สร้างระเบียน ออกการตอบสนองแบบสตรีม
- ที่เก็บถาวร (SQL/NoSQL): การสนทนา ข้อความ การเรียกเครื่องมือ สถานะงาน
- คิว + workers: งานรันยาว (RAG indexing, การแยกไฟล์, การสร้างภาพ)
- แคช (ทางเลือก): อ่านฮอต (สรุปการสนทนา metadata ของ embeddings), คีย์ด้วยเวอร์ชัน/ตราประทับเวลา
หมายเหตุ: หนึ่งวิธีปฏิบัติที่เป็นประโยชน์คือกำหนดสแต็ก backend ให้ตรงกันตั้งแต่ต้น ตัวอย่างเช่น backends ที่สร้างโดย Koder.ai มักใช้ Go กับ PostgreSQL (และ React ฝั่ง frontend) ซึ่งทำให้ง่ายต่อการรวมสถานะ “ผู้มีอำนาจ” ใน SQL ขณะที่แคชฝั่งไคลเอนต์ทิ้งได้
ออกแบบโมเดลสถานะของคุณก่อน
ก่อนสร้างหน้าจอ ให้กำหนดฟิลด์ที่คุณจะพึ่งพาในแต่ละชั้น:
- IDs และความเป็นเจ้าของ:
user_id,org_id,conversation_id,message_id,request_id - ตราประทับเวลาและการจัดลำดับ:
created_at,updated_at, และsequenceสำหรับข้อความ - ฟิลด์สถานะ:
queued | running | streaming | succeeded | failed | canceled(สำหรับงานและการเรียกเครื่องมือ) - การเวอร์ชัน:
etagหรือversionสำหรับการอัปเดตที่ปลอดภัยจากความขัดแย้ง
นี้ป้องกันบั๊กคลาสสิกที่ UI “ดูถูก” แต่ไม่สามารถปรับให้เข้ากับการลองใหม่ รีเฟรช หรือการแก้ไขพร้อมกัน
ใช้รูปแบบ API ให้สอดคล้อง
ทำให้ endpoints คาดเดาได้ข้ามฟีเจอร์:
GET /conversations(list)GET /conversations/{id}(get)POST /conversations(create)POST /conversations/{id}/messages(append)PATCH /jobs/{id}(update status)GET /streams/{request_id}หรือPOST .../stream(stream)
คืนรูปแบบ envelope เดิมทุกที่ (รวมข้อผิดพลาด) เพื่อให้ frontend อัปเดตสถานะได้เป็นแบบเดียวกัน
เพิ่มการสังเกตการณ์ในจุดที่สถานะอาจพัง
บันทึกและคืน request_id สำหรับการเรียก AI ทุกครั้ง บันทึกการเรียกเครื่องมืออินพุต/เอาต์พุต (พร้อมการตัดข้อมูล) latency การลองใหม่ และสถานะสุดท้าย ทำให้ง่ายต่อการตอบคำถาม: “โมเดลเห็นอะไร เครื่องมืออะไรทำงานบ้าง และสถานะใดที่เราบันทึก?”
เช็กลิสต์การสร้าง (เพื่อหลีกเลี่ยงบั๊กสถานะทั่วไป)
- Backend เป็นแหล่งความจริง; แคช frontend ถูกติดป้ายชัดเจนและทิ้งได้
- ทุกการเขียนต้อง idempotent (ปลอดภัยต่อการลองใหม่) โดยใช้
request_id(และ/หรือ Idempotency-Key) - การเปลี่ยนสถานะต้องชัดเจนและตรวจสอบได้ (ไม่มีการเด้งเงียบจาก
queuedเป็นsucceeded) - การอัพเดตสตรีมควรรวมตาม IDs/sequence ไม่ใช่โดย "ข้อความล่าสุดชนะ"
- ความขัดแย้งจัดการด้วย
version/etagหรือกฎการรวมบนเซิร์ฟเวอร์ - PII และความลับไม่ถูกเก็บในสถานะไคลเอนต์; ตัดข้อมูลใน logs โดยค่าเริ่มต้น
- มีแดชบอร์ดรวมสำหรับดีบัก: คำขอ การเรียกเครื่องมือ สถานะงาน และข้อผิดพลาด
เมื่อคุณนำรอบการสร้างที่เร็วขึ้นมา (รวมถึงการสร้างโดย AI) ให้พิจารณาเพิ่ม guardrails ที่บังคับใช้รายการเช็คลิสต์เหล่านี้โดยอัตโนมัติ—การตรวจสคีมา idempotency และการสตรีมแบบ evented—เพื่อให้การ “เคลื่อนที่เร็ว” ไม่กลายเป็นการลอยของสถานะ ในทางปฏิบัติ นั่นคือจุดที่แพลตฟอร์มแบบครบวงจรเช่น Koder.ai มีประโยชน์: มันเร่งการส่งมอบ ในขณะที่ยังช่วยให้คุณส่งออกซอร์สโค้ดและรักษารูปแบบการจัดการสถานะให้สอดคล้องกันทั้งเว็บ แบ็กเอนด์ และมือถือ