10 มิ.ย. 2568·3 นาที
ชั้นแคชลดภาระ—แต่เพิ่มความซับซ้อนที่ซ่อนอยู่
ชั้นแคชลดความหน่วงและภาระต้นทาง แต่เพิ่มโหมดล้มเหลวและงานปฏิบัติการ เรียนรู้ชั้นที่พบบ่อย ความเสี่ยง และแนวทางลดความซับซ้อน
ชั้นแคชลดความหน่วงและภาระต้นทาง แต่เพิ่มโหมดล้มเหลวและงานปฏิบัติการ เรียนรู้ชั้นที่พบบ่อย ความเสี่ยง และแนวทางลดความซับซ้อน
แคชเก็บสำเนาข้อมูลใกล้จุดที่ต้องการ จึงตอบคำขอได้เร็วขึ้นโดยไม่ต้องไปถึงระบบหลักบ่อย ๆ ผลตอบแทนมักเป็นการผสมของ ความเร็ว (latency ต่ำกว่า), ต้นทุน (ลดการอ่านฐานข้อมูลหรือการเรียก service ภายนอกที่แพง) และ ความเสถียร (บริการต้นทางทนต่อการระเบิดของทราฟฟิกได้ดีขึ้น)
เมื่อแคชตอบคำขอได้ ระบบต้นทาง (app servers, databases, third‑party APIs) ทำงานน้อยลง การลดภาระแบบนี้อาจเห็นได้ชัด: คิวรีน้อยลง, วงจร CPU ลดลง, hop เครือข่ายน้อยลง และโอกาสเกิด timeout ลดลง
แคชช่วยเกลี่ยการพุ่งของทราฟฟิก—ทำให้ระบบที่ออกแบบมาสำหรับภาระเฉลี่ยสามารถจัดการช่วงพีคได้โดยไม่ต้องสเกลทันที (หรือไม่ล่ม)
แคชไม่ทำให้งานหายไป; มัน ย้าย งานไปสู่การออกแบบและการปฏิบัติการ คุณต้องตอบคำถามใหม่ ๆ:
แต่ละชั้นแคชเพิ่มการตั้งค่า, การมอนิเตอร์ และกรณีขอบ หากแคชทำให้ 99% ของคำขอตอบได้เร็วขึ้น ก็ยังอาจเกิดเหตุการณ์เจ็บปวดในอีก 1%: การหมดอายุพร้อมกัน, ประสบการณ์ผู้ใช้ไม่สอดคล้อง หรือการพุ่งของคำขอไปยังต้นทาง
แคชเดียว คือสโตร์เดียว (เช่น แคชในหน่วยความจำข้างแอป) ขณะที่ ชั้นแคช คือจุดตรวจสอบแยกต่างหากในเส้นทางคำขอ—CDN, แคชในเบราว์เซอร์, แคชแอป, แคชฐานข้อมูล—แต่ละชั้นมีกฎและโหมดล้มเหลวของตัวเอง
บทความนี้เน้นความซับซ้อนเชิงปฏิบัติที่เกิดจากหลายชั้น: ความถูกต้อง, การล้างแคช และการปฏิบัติการ (ไม่ลงลึกเรื่องอัลกอริธึมแคชระดับต่ำหรือการจูนเฉพาะผู้ขาย)
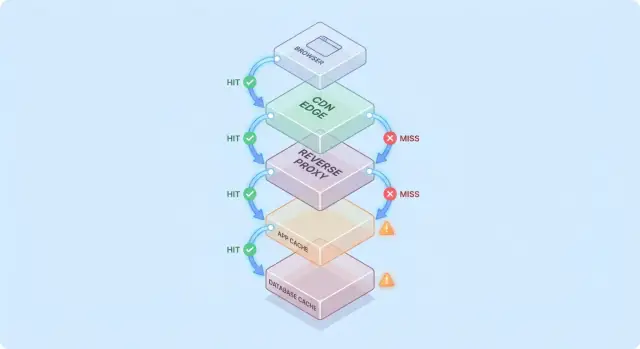
การแคชจะง่ายขึ้นเมื่อนึกภาพคำขอเดินผ่านกองของจุดตรวจสอบ “อาจมีอยู่แล้ว” ทีละชั้น
เส้นทางทั่วไปเป็นแบบนี้:
ที่แต่ละฮอป ระบบอาจตอบด้วยการตอบที่แคชแล้ว (hit) หรือส่งคำขอต่อไปยังชั้นถัดไป (miss) ยิ่ง hit เกิดเร็วเท่าไร (เช่น ที่ edge) คุณก็หลีกเลี่ยงภาระลึกลงไปในสแตกได้มากขึ้น
Hit ทำให้แดชบอร์ดดูดี แต่ Miss คือที่ที่ความซับซ้อนปรากฏ: มันกระตุ้นงานจริง (ตรรกะแอป, คิวรีฐานข้อมูล) และเพิ่มโอเวอร์เฮด (การค้นหาแคช, การซีเรียลไลซ์, การเขียนแคช)
แบบจำลองใจที่เป็นประโยชน์คือ: ทุกครั้งที่ miss จะจ่ายค่าตัวแคชสองครั้ง—คุณยังคงทำงานต้นฉบับอยู่ และยังมีงานรอบ ๆ แคชอีกด้วย
การเพิ่มชั้นแคชมักไม่ใช่การขจัดคอขวด แต่เป็นการ ย้าย มัน:
สมมติหน้า product ถูกแคชที่ CDN นาน 5 นาที และแอปยังคงแคชรายละเอียดสินค้าใน Redis นาน 30 นาที
หากราคาสินค้าเปลี่ยน CDN อาจรีเฟรชเร็วกว่า ในขณะที่ Redis ยังคงส่งราคาที่เก่าอยู่ ตอนนี้ “ความจริง” ขึ้นอยู่กับชั้นที่ตอบคำขอ—นี่เป็นตัวอย่างว่าทำไมชั้นแคชลดภาระแต่เพิ่มความซับซ้อนของระบบ
การแคชไม่ใช่ฟีเจอร์เดียว—มันคือสแต็กของจุดที่ข้อมูลถูกเก็บและนำกลับมาใช้ใหม่ แต่ละชั้นลดภาระได้ แต่แต่ละชั้นมีกฎความสด, การล้าง, และการมองเห็นที่ต่างกัน
เบราว์เซอร์แคชภาพ สคริปต์ CSS และบางครั้ง API responses ตาม HTTP header (เช่น Cache-Control และ ETag) ลดการดาวน์โหลดซ้ำได้ทั้งหมด—ดีทั้งเรื่องประสิทธิภาพและลดทราฟฟิก CDN/origin
ความเสี่ยงคือเมื่อคำตอบถูกแคชฝั่งไคลเอ็นต์ คุณจะไม่ควบคุมเวลาการ revalidation ได้เต็มที่ ผู้ใช้บางคนอาจเก็บแอสเซทเก่ากว่าคนอื่น (หรือเคลียร์แคชโดยไม่คาดคิด) จึงมักใช้ URL เวอร์ชัน (เช่น app.3f2c.js) เป็นมาตรการความปลอดภัย
CDN แคชคอนเทนต์ใกล้ผู้ใช้ เหมาะสำหรับไฟล์สแตติก, หน้าสาธารณะ, และคำตอบที่ “ค่อนข้างคงที่” เช่น รูปสินค้า, เอกสาร, หรือ API ที่จำกัดอัตรา
CDN ยังสามารถแคช HTML กึ่งสแตติกได้เมื่อจัดการการแปรผัน (cookies, headers, geo, อุปกรณ์) อย่างระมัดระวัง กฎการแปรผันที่กำหนดไม่ดีเป็นสาเหตุบ่อยของการส่งคอนเทนต์ผิดให้ผู้ใช้ผิด
Reverse proxy (เช่น NGINX หรือ Varnish) นั่งหน้าระบบแอปและสามารถแคชทั้ง response เหมาะเมื่อคุณต้องการควบคุมศูนย์กลาง, การไล่ออกที่คาดการณ์ได้, และการป้องกันต้นทางในช่วงพีค
โดยทั่วไปกระจายน้อยกว่า CDN แต่ปรับแต่งเส้นทางและ header ของแอปได้ง่ายกว่า
แคชนี้มุ่งเป้าไปที่ออบเจ็กต์ ผลลัพธ์ที่คำนวนแล้ว และการเรียกที่แพง (เช่น “user profile by id” หรือ “กฎการตั้งราคาตามภูมิภาค”) ยืดหยุ่นและสามารถรับรู้ตรรกะทางธุรกิจได้
แต่ก็เพิ่มจุดตัดสินใจ: การออกแบบคีย์, การเลือก TTL, ตรรกะการล้าง, และความต้องการปฏิบัติการ เช่น ขนาดและการสำรอง
ฐานข้อมูลส่วนใหญ่แคชเพจ, ดัชนี, และ query plans โดยอัตโนมัติ บางระบบรองรับ result caching ซึ่งช่วยเร่งคิวรีซ้ำโดยไม่ต้องเปลี่ยนโค้ดแอป
ควรมองว่าเป็นโบนัสไม่ใช่การรับประกัน: แคชใน DB มักคาดเดาได้น้อยที่สุดภายใต้รูปแบบการคิวรีหลากหลาย และมันไม่ลดต้นทุนการเขียน ล็อก หรือ contention ในแบบที่แคชด้านบนทำได้
การแคชคุ้มค่ามากเมื่อมันเปลี่ยนงานต้นทางที่ซ้ำและแพงให้กลายเป็นการค้นหาที่ถูกลง เคล็ดลับคือตรงกับงานโหลดที่คำขอค่อนข้างเหมือนกันและคงอยู่นานพอให้ซ้ำสูง
ถ้าระบบของคุณอ่านมากกว่าเขียน แคชสามารถลดงานฐานข้อมูลและแอปได้มาก หน้าสินค้า, โปรไฟล์สาธารณะ, บทความช่วยเหลือ และผลการค้นหาที่พารามิเตอร์เหมือนกันมักถูกขอซ้ำ
แคชยังช่วยงาน “แพง” ที่ไม่จำเป็นต้องผูกกับฐานข้อมูลโดยตรง: การสร้าง PDF, ย่อขนาดรูป, เรนเดอร์เทมเพลต, หรือคำนวณสรุป แม้แคชสั้น ๆ (วินาทีถึงนาที) ก็ลดการคำนวณซ้ำในช่วงที่มีงานหนาแน่นได้
แคชมีประสิทธิภาพเมื่อทราฟฟิกไม่สม่ำเสมอ หากอีเมลการตลาด ข่าว หรือโพสต์โซเชียลส่งผู้ใช้จำนวนมากมายมายังหน้าไม่กี่ URL CDN หรือ edge cache จะดูดซับการพุ่งส่วนใหญ่
นี่ลดภาระได้เกินแค่ “ตอบเร็วขึ้น”: ช่วยป้องกันการสเกลซ้อน, หลีกเลี่ยงการเชื่อมต่อ DB หมด, และให้เวลาสำหรับ rate limits และ backpressure ทำงาน
ถ้าต้นทางของคุณอยู่ไกลจากผู้ใช้ การแคชลดทั้งภาระและความรู้สึกช้า การให้บริการจาก CDN ใกล้ผู้ใช้หลีกเลี่ยงการเดินทางไกลซ้ำไปกลับ
แคชภายในช่วยเมื่อคอขวดมาจากสโตร์หน่วงสูง (DB ระยะไกล, API ภายนอก) ลดจำนวนการเรียกช่วยลดแรงกดดันความพร้อมกันและปรับปรุง tail latency
การแคชให้ประโยชน์น้อยเมื่อการตอบเป็นแบบส่วนบุคคลสูง (ข้อมูลต่อผู้ใช้, รายละเอียดบัญชี) หรือข้อมูลเปลี่ยนบ่อยมาก (แดชบอร์ดแบบเรียลไทม์, สต็อกที่เปลี่ยนเร็ว) ในกรณีเหล่านี้อัตรา hit ต่ำ, ต้นทุนการล้างสูง และงานที่ประหยัดได้อาจน้อย
กฎปฏิบัติ: แคชคุ้มค่าเมื่อผู้ใช้หลายคนขอสิ่งเดียวกันภายในหน้าต่างที่ “สิ่งเดียวกัน” ยังใช้ได้ หากไม่มีการชนกันแบบนี้ ชั้นแคชเพิ่มความซับซ้อนโดยไม่ค่อยลดภาระ
การแคชง่ายเมื่อข้อมูลไม่เปลี่ยน แต่เมื่อเปลี่ยน คุณต้องตัดสินใจที่ยาก: เมื่อไหร่ ข้อมูลแคชจะไม่น่าเชื่อถืออีกต่อไป และ อย่างไร แต่ละชั้นจะรับรู้การเปลี่ยนแปลงนั้น
Time-to-live (TTL) ดึงดูดเพราะเป็นตัวเลขเดียวและไม่ต้องประสานงาน ปัญหาคือ TTL ที่ "ถูกต้อง" ขึ้นกับการใช้งาน
ถ้าตั้ง TTL 5 นาทีสำหรับราคาสินค้า บางผู้ใช้อาจเห็นราคาที่เก่าหลังเปลี่ยน—เป็นปัญหาทางกฎหมายหรือฝ่ายช่วยเหลือได้ ถ้าตั้ง 5 วินาที อาจไม่ลดภาระมากพอ ยิ่งกว่านั้นฟิลด์ต่าง ๆ ใน response อาจเปลี่ยนต่างกัน (inventory vs description) ทำให้ TTL เดียวยอมรับไม่ได้ในหลายกรณี
การล้างตามอีเวนต์หมายถึง: เมื่อแหล่งความจริงเปลี่ยน ให้ปล่อยอีเวนต์แล้วล้าง/อัปเดตคีย์ที่เกี่ยวข้องทั้งหมด วิธีนี้แม่นยำ แต่เพิ่มงานใหม่:
แผนที่นี้คือจุดที่ “สองเรื่องยาก: ตั้งชื่อและการล้าง” กลายเป็นปัญหาเชิงปฏิบัติ หากคุณแคช /users/123 และยังแคชลิสต์ “top contributors” การเปลี่ยนชื่อผู้ใช้กระทบมากกว่าหนึ่งคีย์ หากไม่ติดตามความสัมพันธ์ คุณจะเสิร์ฟความจริงผสม
Cache-aside (แอปอ่าน/เขียน DB แล้วเติมแคช) เป็นแบบที่พบบ่อย แต่การล้างเป็นความรับผิดชอบของคุณ
Write-through (เขียนทั้งแคชและ DB พร้อมกัน) ลดความเสี่ยงสเตลเนส แต่เพิ่ม latency และความซับซ้อนการจัดการความล้มเหลว
Write-back (เขียนแคชก่อน แล้ว flush ทีหลัง) เร่งความเร็ว แต่ทำให้ความถูกต้องและการกู้คืนยากขึ้นมาก
Stale-while-revalidate เสิร์ฟข้อมูลเก่านิดหน่อยในขณะที่รีเฟรชเบื้องหลัง ช่วยเกลี่ยพีคและปกป้องต้นทาง แต่เป็นการตัดสินใจเชิงผลิตภัณฑ์: คุณเลือก “เร็วและเกือบทันสมัย” แทน “ล่าสุดเสมอ” อย่างชัดเจน
แคชเปลี่ยนความหมายของ “ถูกต้อง” โดยไม่มีแคช ผู้ใช้ส่วนใหญ่จะเห็นข้อมูลที่คอมมิตล่าสุด (ขึ้นกับพฤติกรรม DB) แต่กับแคช ผู้ใช้อาจเห็นข้อมูลที่ล้าหลังเล็กน้อย—หรือไม่สอดคล้องกันระหว่างหน้าต่าง ๆ—บ่อยครั้งโดยไม่มีสัญญาณชัดเจน
ความสอดคล้องแบบเข้มงวด มุ่งหวัง “อ่านหลังเขียน”: ถ้าผู้ใช้เปลี่ยนที่อยู่ การโหลดครั้งถัดไปควรแสดงที่อยู่ใหม่ทั้งหมดทันที รู้สึกเป็นธรรมชาติแต่มีค่าใช้จ่ายหากทุกการเขียนต้องล้างหรือรีเฟรชหลายแคชทันที
ความสอดคล้องแบบ eventual ยอมให้มีความล้าหลังสั้น ๆ: การอัปเดตจะปรากฏในไม่ช้าแต่ไม่ทันที ผู้ใช้ยอมรับได้สำหรับเนื้อหาที่ความเสี่ยงต่ำ (เช่น จำนวนวิว) แต่ไม่สำหรับเรื่องเงิน สิทธิ์ หรือสิ่งที่มีผลต่อการกระทำทันที
กับกรณีทั่วไป การเขียนเกิดพร้อมกับการเติมแคช:
ตอนนี้แคชเก็บข้อมูลเก่าเป็นเวลาทั้ง TTL แม้ว่าฐานข้อมูลจะถูกต้อง
เมื่อมีหลายชั้น ระบบต่าง ๆ อาจไม่เห็นด้วย:
การเวอร์ชันลดความกำกวม:
user:123:v7) ช่วยให้คุณเดินหน้าอย่างปลอดภัย: การเขียนเพิ่มเวอร์ชันและการอ่านจะเลื่อนไปยังคีย์ใหม่โดยไม่ต้องลบแบบเวลาจำกัดการตัดสินใจสำคัญไม่ใช่ "ข้อมูลเก่าแย่หรือไม่" แต่เป็น ตรงไหน ที่มันแย่
ตั้งงบความล้าสมัยต่อฟีเจอร์ (วินาที/นาที/ชั่วโมง) และให้สอดคล้องกับความคาดหวังผู้ใช้ ผลลัพธ์คือคุณสามารถทดสอบและมอนิเตอร์ “ความถูกต้องของแคช” เป็นข้อกำหนดผลิตภัณฑ์ได้
แคชมักล้มเหลวในแบบที่ดูเหมือน “ทุกอย่างปกติดี แล้วก็พังพร้อมกัน” เหตุล้มเหลวเหล่านี้ไม่ได้หมายความว่าแคชแย่—แต่แคชรวมรูปแบบทราฟฟิก ทำให้การเปลี่ยนเล็ก ๆ กระตุ้นผลใหญ่ได้
หลังการดีพลอย, autoscale, หรือการ flush แคช คุณอาจมีแคชว่างเปล่า ทราฟฟิกชุดถัดไปจะทำให้คำขอจำนวนมากไปที่ DB หรือ API ต้นทางโดยตรง
นี่เจ็บปวดเมื่อทราฟฟิกเพิ่มเร็ว เพราะแคชยังไม่มีเวลาวอร์ม หากดีพลอยตรงกับพีค อาจกลายเป็นการทดสอบภาระโดยไม่ตั้งใจ
Stampede เกิดเมื่อผู้ใช้จำนวนมากร้องขอไอเท็มเดียวกันตอนมันหมดอายุ (หรือยังไม่ถูกแคช) แทนที่จะมีคำขอเดียวคำนวณค่า มีหลายร้อยหรือพันคำขอทำงานซ้ำ—ทำให้ต้นทางล้ม
การบรรเทาปัญหาทั่วไปมี:
ถ้าความต้องการความถูกต้องอนุญาต stale-while-revalidate ก็ช่วยเกลี่ยพีคได้
บางคีย์ฮอตมาก (payload หน้าแรก, สินค้าที่กำลังฮิต) ทำให้ภาระไม่สม่ำเสมอ: โหนดแคชหรือเส้นทางต้นทางบางตัวถูกกดหนัก ขณะที่อื่นว่าง
การบรรเทาประกอบด้วย แยกคีย์ใหญ่เป็นหลายคีย์ ย่อย/ชาร์ด หรือย้ายไปแคชชั้นอื่น (เช่น ให้เนื้อหาสาธารณะไปยัง CDN)
การล่มของแคชอาจแย่กว่าการไม่มีแคช เพราะแอปอาจพึ่งพามัน ตัดสินใจก่อน:
ไม่ว่าจะเลือกแบบไหน ให้มี rate limits และ circuit breakers ป้องกันการล้มของแคชไม่ให้เป็นเหตุล้มของต้นทาง
แคชลดภาระต้นทาง แต่เพิ่มจำนวนบริการที่ต้องดูแลในแต่ละวัน แม้แคชที่เป็นบริการจัดการ ยังต้องวางแผน จูน และตอบเหตุการณ์
ชั้นแคชใหม่มักเป็นคลัสเตอร์ใหม่ (หรือชั้นใหม่) ที่มีขีดจำกัดของตัวเอง ทีมต้องตัดสินใจขนาดหน่วยความจำ นโยบายไล่ออก และพฤติกรรมเมื่ออยู่ภายใต้แรงกดดัน ถ้าแคชมีขนาดไม่พอ มันจะ churn: อัตรา hit ลด ความหน่วงเพิ่ม และต้นทางถูกกดหนักอยู่ดี
แคชมักไม่อยู่ที่เดียว คุณอาจมี CDN, แคชแอป, และแคชฐานข้อมูล—ทุกชั้นตีความกฎต่างกันนิดหน่อย
ความแตกต่างเล็ก ๆ สะสมเป็น:
เมื่อเวลาผ่านไปคำถามว่า “ทำไมคำขอนี้ถูกแคช?” กลายเป็นงานโบราณคดี
แคชสร้างงานซ้ำ: วอร์มคีย์สำคัญหลังดีพลอย, ไล่/รีวาลิเดตเมื่อข้อมูลเปลี่ยน, รีชาร์ดเมื่อเพิ่ม/ลบโหนด, ซ้อมสถานการณ์หลัง flush ทั้งหมด
เมื่อผู้ใช้รายงานข้อมูลเก่าหรือความหน่วงกะทันหัน ผู้ตอบเหตุการณ์มีผู้ต้องสงสัยหลายอย่าง: CDN, คลัสเตอร์แคช, client แคชของแอป, และต้นทาง การดีบักมักหมายถึงการเช็ค hit rate, สปายค์ eviction, และ timeout ข้ามชั้น—แล้วตัดสินใจข้าม, ไล่, หรือสเกล
แคชชนะเมื่อมันลดงานต้นทางและปรับปรุงความเร็วที่ผู้ใช้รับรู้ เพราะคำขออาจถูกตอบจากหลายชั้น (edge/CDN, แคชแอป, แคช DB) คุณต้องการการสังเกตการณ์ที่ตอบคำถาม:
อัตรา hit สูงฟังดูดี แต่ซ่อนปัญหาได้ (เช่น การอ่านแคชช้า หรือ churn ตลอด) ติดตามเมตริกเล็ก ๆ ต่อชั้น:
ถ้า hit ratio เพิ่มแต่ latency รวมไม่ดีขึ้น แคชอาจช้า, ถูกซีเรียลไลซ์มากเกินไป, หรือส่ง payload ใหญ่เกินไป
Distributed tracing ควรแสดงว่าคำขอถูกเสิร์ฟที่ edge, แคชแอป, หรือฐานข้อมูล เพิ่ม tag สม่ำเสมอเช่น cache.layer=cdn|app|db และ cache.result=hit|miss|stale เพื่อกรอง trace และเปรียบเทียบเวลาเส้นทาง hit กับ miss
บันทึกคีย์แคชอย่างระมัดระวัง: หลีกเลี่ยงการบันทึก identifier ผู้ใช้, อีเมล, โทเค็น หรือ URL เต็มที่มี query string ใช้คีย์ที่ normalized หรือตั้ง hash และบันทึกเฉพาะพรีฟิกซ์สั้น ๆ
แจ้งเตือนเมื่อมี สปายค์อัตรา miss ผิดปกติ, การกระโดดของ latency บน miss, และ สัญญาณ stampede (miss พร้อมกันจำนวนมากสำหรับ pattern คีย์เดียวกัน) แยกแดชบอร์ดเป็น view ของ edge, app, และ database รวมถึงพาเนล end‑to‑end
แคชตอบคำถามอย่างรวดเร็วได้ดี—แต่ก็สามารถตอบคำตอบที่ ผิด ให้กับ คนผิด ได้ด้วย เหตุการณ์ด้านความปลอดภัยที่เกี่ยวกับแคชมักเงียบ: ทุกอย่างดูเร็วและปกติ แต่ข้อมูลหลุด
ความผิดพลาดทั่วไปคือการแคชคอนเทนต์เฉพาะบุคคลหรือลับ (รายละเอียดบัญชี, ใบแจ้งหนี้, ตั๋วสนับสนุน, หน้าผู้ดูแล) ในชั้นที่แชร์ (CDN, reverse proxy, แคชแอป) โดยเฉพาะเมื่อมีกฎ “cache everything” กว้างเกินไป
การรั่วไหลที่ละเอียดอ่อนอีกแบบคือการแคชคำตอบที่มี session state (เช่น Set-Cookie) แล้วเสิร์ฟให้ผู้ใช้อื่น
บั๊กคลาสสิกคือแคช HTML/JSON สำหรับผู้ใช้ A แล้วเสิร์ฟให้ผู้ใช้ B เพราะคีย์แคชไม่รวมบริบทผู้ใช้ ในระบบมัลติเทแนนท์ ต้องรวมไอดีเทแนนท์ในคีย์
กฎง่าย ๆ: ถ้าคำตอบขึ้นกับการพิสูจน์ตัวตน, บทบาท, ภูมิศาสตร์, ระดับราคา, feature flags, หรือเทแนนท์ คีย์แคช (หรือกฎ bypass) ต้องสะท้อนการขึ้นต่อเหล่านี้
พฤติกรรมการแคช HTTP ขึ้นอยู่กับ header:
Cache-Control: ป้องกันการจัดเก็บโดยไม่ได้ตั้งใจด้วย private / no-store เมื่อจำเป็นVary: ทำให้แคชแยกคำตอบตาม header ที่เกี่ยวข้อง (เช่น Authorization, Accept-Language)Set-Cookie: มักเป็นสัญญาณว่าคำตอบไม่ควรถูกแคชสาธารณะถ้าความเสี่ยงหรือการปฏิบัติตามกฎเคร่งครัด—PII, ข้อมูลสุขภาพ/การเงิน, เอกสารทางกฎหมาย—ใช้ Cache-Control: no-store และปรับปรุงฝั่งเซิร์ฟเวอร์แทน สำหรับหน้าผสม ให้แคชเฉพาะชิ้นส่วนที่ไม่ละเอียดอ่อน และเก็บข้อมูลส่วนบุคคลออกจากแคชที่แชร์
ชั้นแคชสามารถลดภาระต้นทาง แต่ไม่ใช่ “ประสิทธิภาพฟรี” เสมอ พิจารณาแต่ละชั้นเป็นการลงทุน: คุณแลก latency ต่ำและงานต้นทางน้อยด้วยเงิน เวลาและพื้นผิวความถูกต้องที่ใหญ่ขึ้น
ต้นทุนโครงสร้างพื้นฐานเพิ่มเติม vs การลดต้นทุนต้นทาง. CDN อาจลด egress และการอ่าน DB แต่คุณต้องจ่ายค่าคำขอ CDN, พื้นที่เก็บแคช, และบางครั้งค่าการ invalidate แคช แคชแอป (Redis/Memcached) เพิ่มค่าโฮสติ้ง, อัปเกรด และภาระ on‑call การประหยัดอาจปรากฏเป็นการลดจำนวน replica DB, ขนาด instance เล็กลง, หรือการเลื่อนการสเกลออกไป
ชนะด้าน latency vs ต้นทุนความสด. ทุกแคชนำการตัดสินใจเรื่องความล้าสมัยมา สภาพความสดเข้มงวดต้องการท่อการล้างมากขึ้น (และ miss มากขึ้น) การยอมรับความล้าสมัยช่วยประหยัดคำนวณ แต่เสี่ยงความไว้วางใจผู้ใช้—โดยเฉพาะราคาค่าบริการ, ความพร้อมของสินค้า, หรือสิทธิ์
เวลาเอ็นจิเนียริ่ง: ความเร็วฟีเจอร์ vs งานความน่าเชื่อถือ. ชั้นใหม่มักหมายถึงเส้นทางโค้ดเพิ่ม การทดสอบมากขึ้น และชั้นของเหตุการณ์ใหม่ให้ป้องกัน (stampedes, hot keys, ล้างไม่สมบูรณ์) ต้องงบสำหรับการบำรุงรักษาต่อเนื่อง ไม่ใช่แค่การติดตั้งครั้งแรก
ก่อนเปิดใช้กว้าง ให้ทดลองจำกัด:
เพิ่มชั้นแคชใหม่เมื่อ:
แคชให้ผลเร็วเมื่อมองเป็นฟีเจอร์ผลิตภัณฑ์: ต้องมีเจ้าของ กฎชัด และวิธีปิดที่ปลอดภัย
เพิ่มชั้นแคชทีละชั้น (เช่น CDN หรือ แคชแอปก่อน) และกำหนดทีม/บุคคลรับผิดชอบตรง
กำหนดความรับผิดชอบสำหรับ:
บั๊กแคชส่วนใหญ่คือ “บั๊กคีย์” ใช้คอนเวนชันที่มีเอกสารรวมอินพุตที่เปลี่ยนผล: ขอบเขต tenant/user, locale, ประเภทอุปกรณ์, และ feature flags ที่เกี่ยวข้อง
เพิ่มการเวอร์ชันคีย์ชัดเจน (เช่น product:v3:...) เพื่อให้สามารถล้างด้วยการเพิ่มเวอร์ชันแทนการพยายามลบรายการเป็นล้าน
พยายามให้ทุกอย่างสดตลอดเวลาจะผลักความซับซ้อนเข้าในทุกเส้นทางการเขียน
แทนที่จะนั้น ตัดสินใจว่า “ยอมรับความล้าสมัยได้เท่าไร” ต่อ endpoint แล้วเข้ารหัสด้วย:
สมมติว่าแคชจะช้า ผิดพลาด หรือใช้งานไม่ได้
ใช้ timeouts และ circuit breakers เพื่อไม่ให้การเรียกแคชทำให้เส้นทางคำขอล่ม ทำ degradation ชัดเจน: ถ้าแคชล้ม ให้ fallback เป็นต้นทางพร้อม rate limit หรือเสิร์ฟ response ขั้นต่ำ
เปิดใช้แคชภายใต้ canary หรือ rollout เป็นเปอร์เซ็นต์ และเก็บสวิตช์ bypass (ต่อ route หรือ header) สำหรับการแก้ปัญหาอย่างรวดเร็ว
เขียน runbook: วิธี purge, การเพิ่มเวอร์ชันคีย์, วิธีปิดการแคชชั่วคราว, และที่เช็คเมตริก ติดลิงก์จากหน้ารันบุ๊คภายในเพื่อให้ on‑call ทำงานได้เร็ว
งานแคชมักสะดุดเพราะการเปลี่ยนแตะหลายชั้น (headers, ตรรกะแอป, data models, rollback) หนึ่งวิธีลดต้นทุน iteration คือโปรโตไทป์เส้นทางคำขอเต็มในสภาพแวดล้อมควบคุม
กับ Koder.ai ทีมสามารถสปินสแตกแอปสมจริง (React ฝั่งเว็บ, Go backend กับ PostgreSQL, แม้แต่ Flutter mobile) จาก workflow แบบแชท แล้วทดสอบการตัดสินใจแคช (TTL, การออกแบบคีย์, stale-while-revalidate) แบบ end‑to‑end ฟีเจอร์อย่าง planning mode ช่วยเอกสารพฤติกรรมที่ตั้งใจไว้ก่อนลงมือทำ และ snapshots/rollback ทำให้การทดลองค่ากำหนดแคชหรือการล้างปลอดภัยขึ้น เมื่อพร้อม คุณสามารถ export source code หรือ deploy/host ด้วยโดเมนที่กำหนดเอง—เหมาะสำหรับการทดสอบประสิทธิภาพที่ต้องเลียนแบบทราฟฟิกจริง
ถ้าใช้แพลตฟอร์มแบบนี้ ให้ถือเป็นเครื่องมือเสริมการสังเกตการณ์ระดับ production: จุดมุ่งหมายคือการเร่งการทำซ้ำด้านการออกแบบแคช ในขณะที่คงข้อกำหนดความถูกต้องและขั้นตอนย้อนกลับไว้อย่างชัดเจน
การแคชลดภาระโดยการตอบคำขอซ้ำโดยไม่ต้องไปถึง origin (app servers, databases, third‑party APIs) ผลประโยชน์ใหญ่สุดมาจาก:
ยิ่งการตอบจากแคชเกิดขึ้นเร็วในเส้นทางคำขอ (เช่น เบราว์เซอร์/CDN มากกว่าแอป) ยิ่งหลีกเลี่ยงงานฝั่งต้นทางได้มากขึ้น
แคชเดียวคือสโตร์เดียว (เช่น แคชในหน่วยความจำข้างแอป) ส่วนชั้นแคชคือจุดตรวจสอบในเส้นทางคำขอ (เบราว์เซอร์, CDN, reverse proxy, แคชแอป, แคชฐานข้อมูล)
หลายชั้นช่วยลดภาระได้กว้างขึ้น แต่ก็เพิ่มกฎ, โหมดล้มเหลว, และวิธีทำให้ข้อมูลไม่สอดคล้องกันเมื่อชั้นต่าง ๆ ขัดแย้งกัน
การ miss จะทำให้เกิดงานจริงบวกกับโอเวอร์เฮดของแคช ในการ miss คุณมักจะต้องจ่ายสำหรับ:
ดังนั้นการ miss อาจช้ากว่า “ไม่มีแคช” เว้นแต่แคชจะถูกออกแบบมาอย่างดีและอัตรา hit สูงใน endpoint ที่สำคัญ
TTL ง่ายเพราะไม่ต้องประสานงาน แต่ต้องเดาว่าเท่าไหร่ถึงพอใช้ได้ ถ้า TTL ยาวเกิน ผู้ใช้จะเห็นข้อมูลเก่าหลังการเปลี่ยนแปลง ถ้าสั้นเกิน ก็จะไม่ลดภาระมากพอ
แนวทางปฏิบัติคือกำหนด TTL แยกตามฟีเจอร์ตามผลกระทบต่อผู้ใช้ (เช่น นาทีสำหรับหน้าเอกสาร วินาทีหรือ no-cache สำหรับยอดคงเหลือ/ราคา) แล้วปรับจากข้อมูลจริงของ hit/miss และเหตุการณ์
ใช้เมื่อความล้าสมัยมีค่าเสียหายและคุณสามารถเชื่อมการเขียนกับคีย์แคชที่เกี่ยวข้องได้อย่างเชื่อถือได้ เหมาะเมื่อ:
ถ้าการรับประกันพวกนี้ทำไม่ได้ ให้เลือกความล้าสมัยแบบจำกัด (TTL + revalidation) แทนการล้างที่สมบูรณ์แบบแต่เสี่ยงเงียบ
หลายชั้นอาจทำให้ส่วนต่าง ๆ ของระบบขัดแย้งกัน ตัวอย่าง: CDN ส่ง HTML เก่าขณะที่แคชแอปส่ง JSON ใหม่ ทำให้ UI ผสมกัน
เพื่อลดปัญหานี้:
product:v3:...) เพื่อให้การอ่านเลื่อนไปยังคีย์ใหม่อย่างปลอดภัยVary/header สะท้อนสิ่งที่เปลี่ยนจริงStampede เกิดเมื่อคำขอจำนวนมากสร้างค่าเดียวกันพร้อมกัน (มักเกิดเมื่อล็อกหมดอายุ) จนต้นทางรับไม่ไหว
การป้องกันทั่วไป:
ตัดสินใจ fallback ล่วงหน้า:
ใส่ timeouts, circuit breakers และ rate limits เพื่อไม่ให้เหตุแคชล้มเหลวกลายเป็นเหตุต้นทางล่ม
มุ่งที่เมตริกที่อธิบายผลลัพธ์ ไม่ใช่แค่อัตรา hit:
ในการ tracing ให้ติด tag เช่น cache.layer และ cache.result เพื่อเปรียบเทียบเส้นทาง hit กับ miss และจับการถดถอยได้เร็ว
ความเสี่ยงปกติคือการแคชเนื้อหาส่วนบุคคลหรือความลับในชั้นที่แชร์ (CDN/reverse proxy) เพราะกฎกว้างเกินไป
แนวปฏิบัติ:
Cache-Control: private หรือ no-store สำหรับคำตอบที่ละเอียดอ่อนVary ให้ถูกต้อง (เช่น Authorization, Accept-Language) เมื่อคำตอบต่างกันSet-Cookie เป็นสัญญาณแรง ๆ ว่าคำตอบไม่ควรถูกแคชสาธารณะ