14 พ.ย. 2568·3 นาที
Craig McLuckie และ Cloud-Native: แนวคิดเชิงแพลตฟอร์มชนะ
มุมมองเชิงปฏิบัติของบทบาท Craig McLuckie ในการยอมรับ cloud-native และเหตุผลที่แนวคิดเชิงแพลตฟอร์มช่วยให้คอนเทนเนอร์กลายเป็นโครงสร้างพื้นฐานที่เชื่อถือได้ในโปรดักชัน
ทำไมเรื่องนี้ถึงสำคัญสำหรับทีมที่รันซอฟต์แวร์
ทีมไม่ได้ลำบากเพราะเริ่มคอนเทนเนอร์ไม่เป็น แต่เพราะต้องรันเป็นร้อย ๆ ชิ้นอย่างปลอดภัย อัปเดตโดยไม่หยุดให้บริการ ฟื้นตัวเมื่อเกิดปัญหา และยังต้องส่งฟีเจอร์ตามตารางเวลา
เรื่องราวของ Craig McLuckie ในบริบท “cloud-native” สำคัญเพราะมันไม่ใช่การฉลองความสำเร็จจากเดโมหรู แต่มันคือบันทึกว่าคอนเทนเนอร์กลายเป็นสิ่งที่ "ปฏิบัติการได้" ในสภาพแวดล้อมจริง—ที่เกิดเหตุการณ์ไม่คาดฝัน มีการกำกับดูแล และธุรกิจต้องการการส่งมอบที่คาดการณ์ได้
Cloud-native กล่าวง่าย ๆ
“Cloud-native” ไม่ใช่แค่ “รันบนคลาวด์” แต่มันคือวิธีการสร้างและปฏิบัติการซอฟต์แวร์เพื่อให้สามารถปรับใช้บ่อย สเกลตามความต้องการ และซ่อมแซมได้อย่างรวดเร็วเมื่อบางส่วนล้มเหลว
ในการปฏิบัติ นั่นมักหมายถึง:
- แอปถูกแพ็กและส่งอย่างสม่ำเสมอ (มักด้วยคอนเทนเนอร์)
- ระบบออกแบบเป็นบริการขนาดเล็ก แทนการปล่อยเป็นรีลีสยักษ์ครั้งเดียว
- อัตโนมัติสำหรับการปรับใช้ การสเกล และการย้อนกลับ
- วิธีมาตรฐานในการสังเกต รักษาความปลอดภัย และกำกับดูแลสิ่งที่รันอยู่
ธีมหลัก: แนวคิดเชิงแพลตฟอร์มเปลี่ยนเครื่องมือเป็นโครงสร้างพื้นฐาน
การนำคอนเทนเนอร์ในช่วงแรกมักดูเหมือนกล่องเครื่องมือ: ทีมหยิบ Docker มาต่อสคริปต์กันเอง แล้วหวังว่า operation จะตามทัน แนวคิดเชิงแพลตฟอร์มกลับด้านนั้น แทนที่แต่ละทีมจะประดิษฐ์เส้นทางสู่โปรดักชันเอง คุณสร้าง “ทางลาดที่ปูไว้” ร่วมกัน—แพลตฟอร์มที่ทำให้วิธีที่ปลอดภัย ถูกกำกับ และสังเกตได้ กลายเป็นวิธีที่ง่ายที่สุด
การเปลี่ยนแปลงนี้คือสะพานจาก “เราสามารถรันคอนเทนเนอร์ได้” เป็น “เราสามารถรันธุรกิจบนพวกมันได้”
บทความนี้เหมาะกับใคร
สำหรับคนที่รับผิดชอบผลลัพธ์ ไม่ใช่แค่ไดอะแกรมสถาปัตยกรรม:
- ผู้นำด้านวิศวกรรมที่ต้องถ่วงดุลระหว่างความเร็วและความน่าเชื่อถือ
- ทีมผลิตภัณฑ์ที่อยากทำซ้ำได้เร็วขึ้นโดยไม่ล้มเหลว
- คนในทีม Platform, DevOps และ SRE ที่พยายามลดงานเชิงซ้ำและอุปสรรค
- นักพัฒนาที่อยากให้การปรับใช้เป็นเรื่องน่าเบื่อและทำซ้ำได้
ถ้าเป้าหมายของคุณคือการส่งมอบที่พึ่งพาได้ในระดับสเกล ประวัติศาสตร์นี้มีบทเรียนเชิงปฏิบัติ
ใครคือ Craig McLuckie (และทำไมคนถึงอ้างถึงเขา)
Craig McLuckie เป็นหนึ่งในชื่อที่รู้จักกันดีในขบวนการ cloud-native ยุคแรก คุณจะเห็นการอ้างถึงเขาเมื่อพูดถึง Kubernetes, Cloud Native Computing Foundation (CNCF) และแนวคิดที่ว่าโครงสร้างพื้นฐานควรถูกปฏิบัติเหมือนผลิตภัณฑ์—ไม่ใช่กองตั๋วงานและความรู้แบบชนเผ่า
ไม่ใช่ “ผู้คิดค้นคนเดียว” แต่เป็นผู้สร้างสำคัญ
ควรชี้ให้ชัด McLuckie ไม่ได้ “คิดค้น cloud-native คนเดียว” และ Kubernetes ก็ไม่ใช่โครงการของคนเดียว Kubernetes ถูกสร้างโดยทีมที่ Google และ McLuckie เป็นส่วนหนึ่งของความพยายามในช่วงแรก
สิ่งที่คนมักให้เครดิตเขาคือการช่วยเปลี่ยนแนวคิดด้านวิศวกรรมให้กลายเป็นสิ่งที่วงการโดยรวมสามารถนำไปใช้ได้จริง: การสร้างชุมชนให้เข้มแข็งขึ้น การจัดแพ็กเกจให้ชัดเจนขึ้น และการผลักดันแนวปฏิบัติในการปฏิบัติการที่ทำซ้ำได้
ธีมที่สอดคล้อง: ความน่าเชื่อถือผ่านการทำซ้ำ
ในช่วง Kubernetes และยุค CNCF ข้อความของ McLuckie มักจะเน้นไปที่การทำให้การปฏิบัติการในโปรดักชันคาดเดาได้ นั่นหมายถึง:
- วิธีมาตรฐานในการปรับใช้และย้อนกลับ
- สภาพแวดล้อมที่สอดคล้องจากแลปท็อปถึงโปรดักชัน
- ราวกันการปฏิบัติการที่ลดความประหลาดใจ
ถ้าคุณเคยได้ยินคำว่า “paved roads”, “golden paths” หรือ “platform as a product” คุณกำลังวนรอบแนวคิดเดียวกัน: ลดภาระทางความคิดของทีมโดยทำให้สิ่งที่ถูกต้องเป็นสิ่งที่ง่าย
ทำไมบทความนี้ถึงเอ่ยถึงเขา
โพสต์นี้ไม่ใช่ชีวประวัติ McLuckie เป็นจุดอ้างอิงที่มีประโยชน์เพราะงานของเขานั่งอยู่ตรงจุดตัดของสามแรงที่เปลี่ยนการส่งมอบซอฟต์แวร์: คอนเทนเนอร์, การจัดการงาน (orchestration), และการสร้างระบบนิเวศ บทเรียนที่นี่ไม่เกี่ยวกับบุคลิกภาพ แต่มันคือเหตุผลว่าทำไมแนวคิดเชิงแพลตฟอร์มถึงกลายเป็นกุญแจให้คอนเทนเนอร์รันได้ในโปรดักชันจริง
ก่อนยุค cloud-native: คอนเทนเนอร์มีจริง แต่โปรดักชันยังยาก
คอนเทนเนอร์เป็นแนวคิดที่น่าสนใจก่อนที่คำว่า “cloud-native” จะเป็นที่รู้จัก โดยพื้นฐานคอนเทนเนอร์คือวิธีแพ็กแอปพร้อมไฟล์และไลบรารีที่ต้องการ เพื่อให้มันรันเหมือนกันบนเครื่องต่าง ๆ—เหมือนการส่งสินค้าที่บรรจุในกล่องซึ่งมีชิ้นส่วนครบถ้วน
ทำไมการใช้คอนเทนเนอร์ในระยะแรกยังเป็นการทดลอง
ช่วงแรกหลายทีมใช้คอนเทนเนอร์กับโปรเจกต์ข้างเคียง เดโม และเวิร์กโฟลว์นักพัฒนา พวกมันดีสำหรับทดลองบริการใหม่ สร้างสภาพแวดล้อมทดสอบ และหลีกเลี่ยงปัญหา "รันบนเครื่องฉันได้" ในการส่งมอบ
แต่การขยับจากคอนเทนเนอร์ไม่กี่ชิ้นไปยังระบบโปรดักชันที่รัน 24/7 เป็นงานคนละแบบ เครื่องมือมีแล้ว แต่เรื่องการปฏิบัติการยังไม่ครบ
อุปสรรคโปรดักชันที่ทีมพบ
ปัญหาทั่วไปปรากฏเร็ว:
- การอัปเกรดและการย้อนกลับ: จะอัปเดตคอนเทนเนอร์หลายสิบ (หรือหลายร้อย) ที่กำลังรันอย่างปลอดภัยโดยไม่หยุดบริการได้อย่างไร? แล้วจะย้อนกลับเมื่อมีปัญหาได้อย่างไร?
- เครือข่าย: คอนเทนเนอร์ต้องค้นหากันได้อย่างเชื่อถือได้ การค้นหาบริการ การกำหนดเส้นทางทราฟฟิก การบาลานซ์โหลด และ "ใครคุยกับใคร" ยังไม่มีมาตรฐาน
- ความปลอดภัย: แหล่งที่มาของอิมเมจ การจัดการความลับ การควบคุมการเข้าถึง และการแพตช์ช่องโหว่กลายเป็นงานต่อเนื่อง ไม่ใช่การตั้งค่าเพียงครั้งเดียว
- การมอนิเตอร์และดีบัก: เมื่อคอนเทนเนอร์รีสตาร์ท logs อาจหายไป เมตริก การติดตาม และการแจ้งเตือนไม่ใช่เรื่องอัตโนมัติ ต้องออกแบบสำหรับโลกที่กระบวนการอยู่ได้สั้น
จาก “รันบนเครื่องฉันได้” เป็น “รันทุกวันในระดับสเกล”
คอนเทนเนอร์ช่วยให้พอร์ตได้ แต่พอร์ตเพียงอย่างเดียวไม่รับประกันความน่าเชื่อถือ ทีมยังต้องการแนวปฏิบัติการปรับใช้ที่สอดคล้อง ความเป็นเจ้าของที่ชัดเจน และราวกันปฏิบัติการ—เพื่อให้แอปที่ถูกคอนเทนเนอร์ไม่เพียงรันครั้งเดียว แต่รันได้อย่างคาดเดาทุกวัน
แนวคิดเชิงแพลตฟอร์ม: เปลี่ยนโครงสร้างพื้นฐานเป็นผลิตภัณฑ์
แนวคิดเชิงแพลตฟอร์มคือจังหวะที่บริษัทหยุดมองโครงสร้างพื้นฐานเป็นโปรเจกต์ชั่วคราว และเริ่มมองมันเป็นผลิตภัณฑ์ภายใน ลูกค้าคือทีมพัฒนา ทีมข้อมูล และทุกคนที่ส่งซอฟต์แวร์ เป้าหมายของผลิตภัณฑ์ไม่ได้เป็นจำนวนเซิร์ฟเวอร์หรือ YAML แต่เป็นเส้นทางจากไอเดียสู่โปรดักชันที่ราบรื่น
แพลตฟอร์มคือผลิตภัณฑ์ ไม่ใช่กองเครื่องมือ
แพลตฟอร์มที่แท้จริงมีคำสัญญาชัดเจน: "ถ้าคุณสร้างและปรับใช้ตามเส้นทางเหล่านี้ คุณจะได้ความน่าเชื่อถือ ความปลอดภัย และการส่งมอบที่คาดการณ์ได้" คำสัญญานั้นต้องพฤติกรรมแบบผลิตภัณฑ์—เอกสาร การสนับสนุน เวอร์ชัน และกลไกรับฟังความคิดเห็น นอกจากนี้ยังต้องประสบการณ์ผู้ใช้ที่ตั้งใจไว้: ค่าเริ่มต้นที่สมเหตุสมผล ทางลาดที่ปูไว้ และทางหนีเมื่อทีมต้องการทางเลือกจริง ๆ
ทำไมการมาตรฐานช่วยเร่งการส่งมอบ (และลดความเสี่ยง)
การมาตรฐานลดความเมื่อยล้าจากการตัดสินใจและป้องกันความซับซ้อนโดยไม่ได้ตั้งใจ เมื่อทีมแชร์รูปแบบการปรับใช้ การล็อก และการควบคุมการเข้าถึง ปัญหาจะเกิดซ้ำได้—ดังนั้นแก้ไขได้ การหมุนเวียน on-call ดีขึ้นเพราะเหตุการณ์จะคุ้นเคย การตรวจสอบความปลอดภัยเร็วขึ้นเพราะแพลตฟอร์มฝังราวกันแทนให้แต่ละทีมคิดใหม่ทุกครั้ง
นี่ไม่ใช่การยัดทุกคนเข้าในกล่องเดียว แต่มันคือการตกลงกันใน 80% ที่ควรเป็นเรื่องน่าเบื่อ เพื่อให้ทีมสามารถทุ่มเทพลังงานกับ 20% ที่สร้างความต่างทางธุรกิจ
จากเซิร์ฟเวอร์ทำมือสู่รูปแบบที่ทำซ้ำได้
ก่อนแนวทางแพลตฟอร์ม โครงสร้างพื้นฐานมักพึ่งพาความรู้พิเศษ: บางคนรู้ว่าเซิร์ฟเวอร์ไหนแพตช์แล้ว การตั้งค่าใดปลอดภัย และสคริปต์ไหน “ดีจริง” แนวคิดเชิงแพลตฟอร์มแทนที่สิ่งนั้นด้วยรูปแบบที่ทำซ้ำได้: เทมเพลต การจัดหาอัตโนมัติ และสภาพแวดล้อมที่สอดคล้องจาก dev ถึง production
การกำกับดูแลโดยไม่เพิ่มงานเอกสาร
หากทำถูก แพลตฟอร์มสร้างการกำกับดูแลที่ดีขึ้นโดยมีงานเอกสารน้อยลง นโยบายกลายเป็นการตรวจสอบอัตโนมัติ การอนุมัติเป็นเวิร์กโฟลว์ที่ตรวจสอบได้ และหลักฐานการปฏิบัติตามถูกสร้างขึ้นเมื่าทีมปรับใช้—องค์กรจึงได้การควบคุมโดยไม่ชะลอทุกคน
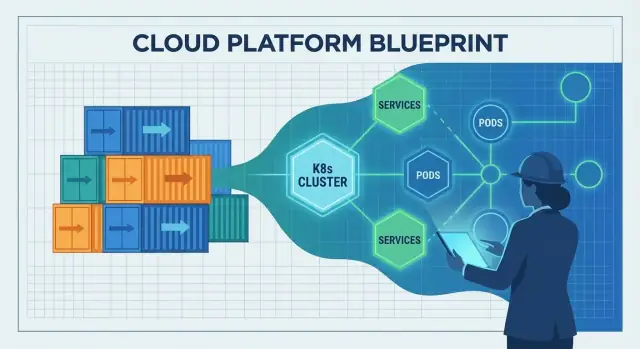
Kubernetes เป็นสะพานจากคอนเทนเนอร์สู่การปฏิบัติการ
คอนเทนเนอร์ทำให้ง่ายในการแพ็กและส่งแอป ปัญหาจริงคือหลังจากส่งไปแล้ว: เลือกที่จะรันที่ไหน ให้มันสุขภาพดีอย่างไร และปรับเมื่อทราฟฟิกหรือโครงสร้างพื้นฐานเปลี่ยนไป
นั่นคือช่องว่างที่ Kubernetes เติมเต็ม มันเปลี่ยน "กองคอนเทนเนอร์" ให้เป็นสิ่งที่คุณสามารถปฏิบัติการได้ทุกวัน แม้เมื่อเซิร์ฟเวอร์ล้มเหลว รีลีสเกิดขึ้น และความต้องการพุ่งขึ้น
การจัดการอย่างมีประโยชน์แก้ปัญหาอะไรบ้าง
Kubernetes มักถูกบรรยายว่าเป็น “การจัดการคอนเทนเนอร์” แต่ปัญหาเชิงปฏิบัติจริงแคบกว่านั้น:
- การจัดตารางงาน: ตัดสินใจว่า เครื่องไหน ควรรันคอนเทนเนอร์แต่ละชุด โดยพิจารณาจาก CPU/หน่วยความจำและกฎการจัดวาง
- การฟื้นฟูตนเอง: รีสตาร์ทคอนเทนเนอร์ที่ล้มเหลว ย้ายพวกมันหากโหนดล้ม และรักษาจำนวนอินสแตนซ์ตามที่ต้องการ
- การสเกล: เพิ่มหรือลดสำเนาตามความต้องการ และเปิดตัวเวอร์ชันใหม่โดยไม่ทำให้ทุกอย่างล่ม
ถ้าไม่มี orchestrator ทีมต้องเขียนสคริปต์พฤติกรรมเหล่านี้และจัดการข้อยกเว้นด้วยตัวเอง—จนสคริปต์ไม่สอดคล้องกับความเป็นจริง
control plane ร่วม
Kubernetes ทำให้แนวคิด control plane ที่ใช้ร่วมกันเป็นที่นิยม: ที่เดียวที่คุณประกาศสิ่งที่ต้องการ ("รัน 3 สำเนาของบริการนี้") และแพลตฟอร์มจะทำงานต่อเนื่องเพื่อให้โลกจริงตรงกับความตั้งใจนั้น
นี่คือการเปลี่ยนแปลงครั้งใหญ่ในความรับผิดชอบ:
- นักพัฒนาปรับใช้: สร้างอิมเมจ ใช้ deployment ตั้ง resource requests และกำหนด health checks
- แพลตฟอร์มดูแลให้รันต่อไป: วางงาน แทนที่อินสแตนซ์ที่ล้ม สมดุลการเปิดตัว และรักษาการค้นหาบริการ
สร้างจากรูปแบบการปฏิบัติการจริง
Kubernetes ไม่ได้เกิดขึ้นเพราะคอนเทนเนอร์เป็นเทรนด์ แต่มันโตมาจากบทเรียนการปฏิบัติการในฝูงเซิร์ฟเวอร์: มองโครงสร้างพื้นฐานเป็นระบบที่มีวงจรป้อนกลับ ไม่ใช่ชุดงานเซิร์ฟเวอร์ครั้งเดียว ความคิดเชิงปฏิบัติการนี้เองที่ทำให้มันเป็นสะพานจาก “เราสามารถรันคอนเทนเนอร์ได้” เป็น “เราสามารถรันพวกมันในโปรดักชันได้อย่างเชื่อถือได้”
สิ่งที่ cloud-native เปลี่ยนในการส่งมอบประจำวัน
Cut boilerplate setup
ข้ามขั้นตอน boilerplate และมุ่งไปที่ส่วนที่ทีมคุณจะนำมามาตรฐาน
Cloud-native ไม่ได้แค่แนะนำเครื่องมือใหม่ แต่มันเปลี่ยนจังหวะการส่งซอฟต์แวร์ประจำวัน ทีมเปลี่ยนจาก "เซิร์ฟเวอร์ทำมือและ runbook แบบแมนนวล" มาสู่ระบบที่ขับเคลื่อนด้วย API อัตโนมัติ และการกำหนดค่าที่เป็นประกาศ
จากตั๋วและ SSH สู่ API และอัตโนมัติ
การตั้งค่าที่ cloud-native สมมติว่าโครงสร้างพื้นฐานสามารถโปรแกรมได้ ต้องการฐานข้อมูล load balancer หรือสภาพแวดล้อมใหม่ไหม? แทนที่จะรอการตั้งค่าด้วยมือ ทีมจะอธิบายสิ่งที่ต้องการและให้อัตโนมัติสร้างมันขึ้นมา
การเปลี่ยนแปลงสำคัญคือ การกำหนดค่าที่เป็นประกาศ: คุณกำหนดสถานะที่ต้องการ ("รัน 3 สำเนาของบริการนี้ เปิดพอร์ตนี้ จำกัดหน่วยความจำ X") และแพลตฟอร์มจะพยายามทำให้สถานะจริงตรงกับนั้น ทำให้การเปลี่ยนแปลงตรวจทานได้ ทำซ้ำได้ และย้อนกลับง่ายขึ้น
การปรับใช้แบบ immutable ลดการเบี่ยงเบน
การส่งมอบแบบดั้งเดิมมักแปะแพตช์เซิร์ฟเวอร์ที่กำลังรัน เมื่อเวลาผ่านไปแต่ละเครื่องต่างกันเล็กน้อย—การเบี่ยงเบนของการตั้งค่าที่มักโผล่มาเมื่อเกิดเหตุ
การส่งมอบแบบ cloud-native ผลักดันทีมสู่ immutable deployments: สร้างแอーティแฟกต์ครั้งเดียว (มักเป็น container image) แล้วปรับใช้ หากต้องการเปลี่ยนแปลงก็ปล่อยเวอร์ชันใหม่ แทนการแก้ไขของที่กำลังรัน เมื่อรวมกับการเปิดตัวอัตโนมัติและ health checks วิธีนี้มักลดการเกิด "ปัญหาปริศนา" ที่เกิดจากการแก้ไขทีละจุด
ไมโครเซอร์วิสและคอนเทนเนอร์: วงจรซ้ำผลักดันซึ่งกันและกัน (มีข้อแลกเปลี่ยน)
คอนเทนเนอร์ทำให้แพ็กและรันบริการขนาดเล็กหลายตัวได้ง่ายขึ้น ซึ่งส่งเสริมสถาปัตยกรรมไมโครเซอร์วิส ไมโครเซอร์วิสกลับเพิ่มความต้องการรูปแบบการปรับใช้ การสเกล และการค้นหาบริการ—ซึ่งเป็นพื้นที่ที่ orchestration ทำได้ดี
ข้อแลกเปลี่ยนคือ: บริการมากขึ้นหมายถึงภาระการปฏิบัติการมากขึ้น (มอนิเตอร์ เครือข่าย เวอร์ชันการจัดการ การตอบเหตุการณ์) Cloud-native ช่วยจัดการความซับซ้อนนั้น แต่ไม่ทำให้มันหายไป
พอร์ตความสามารถ: มีจริง แต่ไม่เวทมนตร์
พอร์ตได้ดีขึ้นเพราะทีมมาตรฐานบน primitives และ API ร่วม อย่างไรก็ตาม “รันที่ไหนก็ได้” มักต้องทำงาน: ความแตกต่างด้านความปลอดภัย สตอเรจ เครือข่าย และบริการที่จัดการยังสำคัญ Cloud-native ถูกเข้าใจดีที่สุดว่า ลดการล็อกอินและความฝืด ไม่ใช่ขจัดมัน
CNCF และผลกระทบของระบบนิเวศ: ทำไมมันเร่งการนำไปใช้
Kubernetes ไม่ได้แพร่หลายเพียงเพราะมันทรงพลัง แต่มันแพร่เพราะมีที่ยืนเป็นกลาง มีการกำกับดูแลชัด และสถานที่ที่บริษัทต่าง ๆ สามารถร่วมมือโดยไม่มีผู้ขายรายใด “เป็นเจ้าของ” กฎ
มูลนิธิที่เป็นกลางทำให้การร่วมมือปลอดภัยขึ้น
Cloud Native Computing Foundation (CNCF) สร้างการกำกับดูแลร่วม: การตัดสินใจแบบเปิด เครื่่องมือการจัดการโครงการที่คาดเดาได้ และโร้ดแมปสาธารณะ นั่นสำคัญสำหรับทีมที่เดิมพันกับโครงสร้างพื้นฐานหลัก เมื่อกฎโปร่งใสและไม่ผูกกับโมเดลธุรกิจของบริษัทเดียว การนำไปใช้รู้สึกมีความเสี่ยงน้อยลง—และการมีส่วนร่วมก็เป็นที่น่าสนใจยิ่งขึ้น
บทบาทของ CNCF: มากกว่าแค่โลโก้
การโฮสต์ Kubernetes และโครงการที่เกี่ยวข้องช่วยเปลี่ยน “เครื่องมือโอเพนซอร์สยอดนิยม” ให้เป็นแพลตฟอร์มระยะยาวที่มีการสนับสนุนเชิงสถาบัน มันให้:
- วิธีจัดการผู้ดูแล โอเวอร์ซัน และแนวทางด้านความปลอดภัยอย่างสม่ำเสมอ
- เวทีสำหรับการประสานงานข้ามบริษัท
- สัญญาณต่อตลาด: โครงการนี้ถูกออกแบบมาให้อยู่ได้ยาวกว่าผู้ขายรายใดรายหนึ่ง
มาตรฐานเปิดและผู้ร่วมพัฒนาจำนวนมาก
ด้วยผู้ร่วมพัฒนาหลากหลาย (ผู้ให้บริการคลาวด์ สตาร์ทอัพ องค์กร และวิศวกรอิสระ) Kubernetes พัฒนาเร็วขึ้นและไปในทิศทางที่สอดคล้องกับสภาพโลกจริง: เครือข่าย สตอเรจ ความปลอดภัย และการปฏิบัติการวัน-2 API และมาตรฐานเปิดทำให้เครื่องมือรวมกันได้ง่ายขึ้น ลดการล็อกอินและเพิ่มความเชื่อมั่นสำหรับการใช้งานในโปรดักชัน
ผลกระทบของระบบนิเวศ (และข้อแลกเปลี่ยน)
CNCF ยังเร่งให้ระบบนิเวศเติบโต: service meshes, ingress controllers, CI/CD tools, policy engines, observability stacks และอื่น ๆ ความอุดมสมบูรณ์นั้นเป็นจุดแข็ง—แต่ก็สร้างความซ้ำซ้อนได้
สำหรับทีมส่วนใหญ่ ความสำเร็จเกิดจากการเลือกชุดเล็ก ๆ ของคอมโพเนนต์ที่ได้รับการสนับสนุนดี มุ่งความสามารถในการทำงานร่วมกัน และชัดเจนเรื่องความเป็นเจ้าของ วิธี "ดีที่สุดของทุกอย่าง" มักนำไปสู่ภาระการบำรุงรักษามากกว่าการส่งมอบที่ดีขึ้น
จากเครื่องมือสู่ความน่าเชื่อถือ: ชั้นปฏิบัติการที่ขาดหาย
Practice safe releases
ฝึกการเปลี่ยนแปลงอย่างปลอดภัยด้วย snapshots และการทำซ้ำแบบเป็นขั้นตอนในแชท
คอนเทนเนอร์และ Kubernetes แก้ปัญหาใหญ่อีกส่วนของคำถาม "เราจะรันซอฟต์แวร์อย่างไร?" แต่ไม่ได้แก้คำถามที่ยากกว่าโดยอัตโนมัติ: "เราจะรักษามันให้รันเมื่อผู้ใช้จริงมาถึงอย่างไร?" ชั้นที่ขาดคือความน่าเชื่อถือเชิงปฏิบัติการ—ความคาดหวังที่ชัดเจน แนวปฏิบัติร่วม และระบบที่ทำให้พฤติกรรมที่ถูกต้องเป็นค่าเริ่มต้น
กำหนดฐานการผลิต
ทีมสามารถส่งได้เร็วและยังเสี่ยงต่อการเกิดความพังได้หากฐานการผลิตไม่ชัดเจน ขั้นต่ำคุณต้องมี:
- การสังเกต: ความสามารถในการเห็นสิ่งที่เกิดขึ้นและเหตุผล (ไม่ใช่แค่ขึ้น/ลง)
- การตอบสนองต่อเหตุการณ์: บทบาท, การหมุน on-call, เส้นทางการยกระดับ, และการทบทวนหลังเหตุการณ์
- การวางแผนความจุ: เข้าใจโหลด ขีดจำกัด และพฤติกรรมภายใต้ความเครียด
ถ้าไม่มีฐานนี้ ทุกบริการจะประดิษฐ์กฎเองและความน่าเชื่อถือจะกลายเป็นเรื่องโชค
แนวปฏิบัติไม่ได้มาแทนแพลตฟอร์ม—แต่จับคู่กัน
DevOps และ SRE นำพฤติกรรมสำคัญ: การเป็นเจ้าของ อัตโนมัติ การวัดความน่าเชื่อถือ และการเรียนรู้จากเหตุการณ์ แต่พฤติกรรมเพียงอย่างเดียวไม่ขยายข้ามทีมหลายสิบทีมและบริการหลายร้อยได้
แพลตฟอร์มทำให้แนวปฏิบัติเหล่านั้นทำซ้ำได้ SRE ตั้งเป้า (เช่น SLO) และวงจรป้อนกลับ; แพลตฟอร์มให้ทางลาดที่ปูไว้เพื่อตอบโจทย์เหล่านั้น
องค์ประกอบความน่าเชื่อถือ "โต๊ะเท้า"
การส่งมอบที่เชื่อถือได้มักต้องการชุดความสามารถที่สอดคล้อง:
- Logging, metrics, tracing (เพื่อดีบักและปรับปรุง)
- Alerting ผูกกับผลกระทบต่อผู้ใช้ (เพื่อไม่ให้ on-call เป็นเสียงรบกวน)
- การย้อนกลับที่ปลอดภัย และรูปแบบการปรับใช้แบบก้าวหน้า (เพื่อทำให้ความล้มเหลวไม่เป็นหายนะ)
แพลตฟอร์มเข้ารหัสความคาดหวังอย่างไร
แพลตฟอร์มที่ดีฝังค่าเริ่มต้นเหล่านี้ไว้ในเทมเพลต pipeline และนโยบายเวลารัน: แดชบอร์ดมาตรฐาน กฎแจ้งเตือนทั่วไป ราวกันการปรับใช้ และกลไกการย้อนกลับ นี่คือวิธีที่ความน่าเชื่อถือหยุดเป็นเรื่องเลือกได้—และเริ่มเป็นผลลัพธ์ที่คาดเดาได้ของการส่งมอบซอฟต์แวร์
วิศวกรรมแพลตฟอร์ม: ทำให้ cloud-native ใช้งานได้สำหรับทีมส่วนใหญ่
เครื่องมือ cloud-native อาจทรงพลังและยังดู "มากเกินไป" สำหรับทีมผลิตภัณฑ์ส่วนใหญ่ วิศวกรรมแพลตฟอร์มมีอยู่เพื่อปิดช่องว่างนี้ ภารกิจง่าย ๆ คือ ลดภาระทางความคิดของทีมแอปพลิเคชันเพื่อให้พวกเขาส่งฟีเจอร์โดยไม่ต้องเป็นผู้เชี่ยวชาญโครงสร้างพื้นฐานเต็มเวลา
ภารกิจของทีมแพลตฟอร์ม: ทำให้เส้นทางที่ถูกต้องเป็นเส้นทางที่ง่าย
ทีมแพลตฟอร์มที่ดีปฏิบัติต่อโครงสร้างพื้นฐานภายในเป็นผลิตภัณฑ์ นั่นหมายถึงผู้ใช้ชัดเจน (นักพัฒนา) ผลลัพธ์ชัดเจน (การส่งมอบที่ปลอดภัยและทำซ้ำได้) และวงจรรับฟังความคิดเห็น แทนที่จะส่งมอบชุด primitive ของ Kubernetes ทีมแพลตฟอร์มเสนอวิธีที่มีความเห็นชอบในการสร้าง ปรับใช้ และปฏิบัติการบริการ
เลนส์ปฏิบัติหนึ่งคือถามว่า: “นักพัฒนาสามารถไปจากไอเดียถึงบริการที่รันได้โดยไม่ต้องเปิดตั๋วสิบใบหรือไม่?” เครื่องมือที่บีบอัดเวิร์กโฟลว์นั้น ในขณะเดียวกันยังรักษาราวกัน ไม่นำทางออกเป็นไปตามเป้าหมายของแพลตฟอร์ม cloud-native
บล็อกก่อสร้างที่ทำให้ cloud-native เป็นเรื่องปฏิบัติได้
แพลตฟอร์มส่วนใหญ่คือชุดของ “ทางลาดที่ปูไว้” ที่ทีมเลือกใช้เป็นค่าเริ่มต้น:
- เทมเพลตและ scaffolding สำหรับบริการใหม่ (โครง repo, CI, การสังเกตพื้นฐาน)
- เวิร์กโฟลว์แบบ self-service (สร้างสภาพแวดล้อม, ขอฐานข้อมูล, หมุนความลับ)
- รูปแบบการปรับใช้มาตรฐาน (ingress, autoscaling, health checks, canary releases)
เป้าหมายไม่ใช่ปิดบัง Kubernetes แต่คือการแพ็กมันด้วยค่าเริ่มต้นที่สมเหตุสมผลเพื่อลดความซับซ้อนโดยไม่ได้ตั้งใจ
ในบริบทนี้ Koder.ai สามารถใช้เป็น "DX accelerator" ชั้นหนึ่งสำหรับทีมที่ต้องการตั้งค่าเครื่องมือภายในหรือฟีเจตส์ผลิตภัณฑ์อย่างรวดเร็วผ่านแชท แล้วส่งออกซอร์สโค้ดเมื่อพร้อมจะผสานกับแพลตฟอร์มที่เป็นทางการยิ่งขึ้น สำหรับทีมแพลตฟอร์ม โหมดการวางแผนของมันและฟีเจอร์ snapshots/rollback ในตัวก็สามารถสะท้อนท่าทีที่เน้นความน่าเชื่อถือที่คุณต้องการในเวิร์กโฟลว์โปรดักชัน
ข้อแลกเปลี่ยน: ความยืดหยุ่นกับความสอดคล้อง
ทุกทางลาดที่ปูไว้มีข้อแลกเปลี่ยน: ความสอดคล้องและการปฏิบัติการที่ปลอดภัยมากขึ้น แต่ตัวเลือกเฉพาะกรณีน้อยลง ทีมแพลตฟอร์มจะทำได้ดีที่สุดเมื่อพวกเขาเสนอ:
- golden path สำหรับ 80% ของบริการ
- escape hatch สำหรับกรณีพิเศษที่แท้จริง (พร้อมความเป็นเจ้าของชัดเจน)
สัญญาณว่ามันได้ผล
ผลสำเร็จของแพลตฟอร์มเห็นได้จากตัวชี้วัด: การพาเข้าทีมใหม่เร็วขึ้น สคริปต์ปรับใช้แบบเฉพาะลดลง คลัสเตอร์ "snowflake" น้อยลง และความเป็นเจ้าของชัดเจนเมื่อเกิดเหตุ หากทีมตอบได้ว่า “ใครเป็นเจ้าของบริการนี้และเราส่งอย่างไร?” โดยไม่ต้องมีการประชุม แพลตฟอร์มนั้นทำงานได้ดี
สิ่งที่มักผิดพลาด: กับดักที่ชะลอความคืบหน้า cloud-native
Cloud-native สามารถทำให้การส่งมอบเร็วขึ้นและการปฏิบัติการสงบขึ้น—แต่เฉพาะเมื่อทีมชัดเจนเรื่องที่ต้องปรับปรุง ความล่าช้าหลายอย่างเกิดจากการที่ Kubernetes และระบบนิเวศถูกมองเป็นเป้าหมาย แทนที่จะเป็นเครื่องมือ
1) Kubernetes-first, outcomes-later
ข้อผิดพลาดทั่วไปคือนำ Kubernetes มาใช้เพราะเป็น "สิ่งที่ทีมสมัยใหม่ทำ" โดยไม่มีเป้าหมายเช่น lead time สั้นลง จำนวนเหตุการณ์น้อยลง หรือความสอดคล้องของสภาพแวดล้อม ผลลัพธ์คือมีงานย้ายมากโดยไม่เห็นผลลัพธ์ชัดเจน
ถ้าเกณฑ์ความสำเร็จไม่ได้กำหนดไว้ล่วงหน้า ทุกการตัดสินใจจะกลายเป็นเรื่องส่วนตัว: จะเลือกเครื่องมือไหน จะมาตรฐานมากแค่ไหน และเมื่อแพลตฟอร์มถือว่า “เสร็จ” แล้ว
2) ความซับซ้อนเพิ่มจากระบบนิเวศ
Kubernetes เป็นฐาน ไม่ใช่แพลตฟอร์มเต็มรูปแบบ ทีมมักติดตั้ง add-ons อย่างรวดเร็ว—service mesh, ingress controllers หลายตัว, custom operators, policy engines—โดยไม่มีขอบเขตหรือความเป็นเจ้าของที่ชัดเจน
กับดักอีกอย่างคือการปรับแต่งมากเกินไป: รูปแบบ YAML เฉพาะตัว เทมเพลตที่ทำด้วยมือ และข้อยกเว้นที่มีแต่ผู้สร้างคนแรกเท่านั้นที่เข้าใจ ความซับซ้อนเพิ่มขึ้น การพาเข้าทีมใหม่ช้าลง และการอัปเกรดกลายเป็นความเสี่ยง
3) ต้นทุน การขยายตัว และจุดบอดด้านความปลอดภัย
Cloud-native ทำให้สร้างทรัพยากรง่าย—และลืมพวกมันได้ง่าย ๆ การขยายตัวของคลัสเตอร์ เนมสเปซที่ไม่ได้ใช้ และเวิร์กโหลดที่จัดสรรเกินไป ค่อย ๆ พาให้ต้นทุนพุ่ง
จุดบอดด้านความปลอดภัยก็พบได้บ่อยเช่นกัน:
- สิทธิ์ที่ขยายขึ้นตามเวลา (RBAC กว้าง บัญชีบริการที่แชร์กัน)
- ความเสี่ยงในซัพพลายเชน (อิมเมจที่ยังไม่ได้ตรวจสอบ, charts ของบุคคลที่สามมากเกินไป)
- นโยบายที่ไม่สอดคล้องข้ามคลัสเตอร์และสภาพแวดล้อม
4) วิธีบรรเทา (โดยไม่หยุดความคืบหน้า)
เริ่มเล็กกับหนึ่งหรือสองบริการที่ขอบเขตชัดเจน กำหนดมาตรฐานตั้งแต่แรก (golden paths, base images ที่อนุมัติ, กฎการอัปเกรด) และรักษาพื้นที่ของแพลตฟอร์มให้จำกัดโดยเจตนา
วัดผลลัพธ์เช่น ความถี่การปรับใช้ เวลาเฉลี่ยจากการเริ่มพัฒนาไปถึงปรับใช้ และเวลาเฉลี่ยในการกู้คืน (MTTR) และจัดการสิ่งที่ไม่ช่วยให้ตัวเลขเหล่านี้ดีขึ้นเป็นสิ่งเลือกทำได้
แนวทางปฏิบัติที่เป็นประโยชน์เพื่อใช้บทเรียนเหล่านี้
Pick the right tier
เริ่มจากแผนฟรี แล้วขยับเมื่อความต้องการของทีมเพิ่มขึ้น
คุณจะไม่ "นำ cloud-native มาใช้" ในครั้งเดียว ทีมที่ประสบความสำเร็จทำตามแนวคิดหลักเดียวกับยุคของ McLuckie: สร้างแพลตฟอร์มที่ทำให้วิธีที่ถูกต้องเป็นวิธีที่ง่าย
เส้นทางการนำไปใช้ง่าย ๆ
เริ่มเล็ก แล้วจดสิ่งที่ได้ผล
- Pilot: เลือกบริการหนึ่งที่เจ็บปวดเพียงพอจะเปลี่ยน แต่ไม่ใช่หัวใจธุรกิจ แพ็กเป็นคอนเทนเนอร์ อัตโนมัติการสร้าง และปรับใช้ซ้ำจนรู้สึกเป็นกิจวัตร
- Platform MVP: แปลงบทเรียนจากพายลอตเป็นแพลตฟอร์มภายในบาง ๆ: เทมเพลตมาตรฐาน ทางลาดที่ปูไว้ การสังเกตพื้นฐาน และโมเดลความเป็นเจ้าของชัดเจน
- ขยาย: พาทีมและบริการมาใช้งานด้วยค่าเริ่มต้นเดียวกัน มุ่งความสอดคล้องมากกว่าการปรับแต่ง
- ปรับแต่ง: เพิ่มนโยบาย การควบคุมค่าใช้จ่าย เวิร์กโฟลว์เหตุการณ์ และฟีเจอร์ self-service เมื่อพื้นฐานมั่นคง
ถ้าคุณทดลองเวิร์กโฟลว์ใหม่ รูปแบบที่มีประโยชน์คือการต้นแบบประสบการณ์ “golden path” ครบวงจรก่อนจะตัดสินใจมาตรฐาน ตัวอย่างเช่น ทีมอาจใช้ Koder.ai เพื่อสร้างเว็บแอป (React), แลกกลับ (Go) และฐานข้อมูล (PostgreSQL) ผ่านแชท แล้วใช้โค้ดที่ได้เป็นจุดเริ่มต้นสำหรับเทมเพลตและข้อกำหนด CI/CD ของแพลตฟอร์ม
คำถามการตัดสินใจก่อนเพิ่มเครื่องมือ
ก่อนจะเพิ่มเครื่องมือ ถามตัวเอง:
- ทำไมต้องคอนเทนเนอร์? ปัญหาใดที่คุณแก้ (การเบี่ยงเบนของสภาพแวดล้อม, การแพ็ก, พอร์ตความสามารถ) และงานใหม่ใดที่คุณยอมรับ?
- ทำไมต้อง orchestration? คุณต้องการสเกลอัตโนมัติ การเปิดตัวแบบค่อยเป็นค่อยไป และความทนทานของบริการจริงหรือไม่—หรืออัตโนมัติง่าย ๆ ก็พอ?
- ทำไมต้องเป็นตอนนี้? เรื่องนี้มาจากความเจ็บปวดในการส่งมอบ ความเสี่ยงด้านความน่าเชื่อถือ หรืเป้าผลิตภัณฑ์ที่ชัดเจน (ไม่ใช่แค่ตามเทรนด์)?
ตัวชี้วัดที่แสดงความคืบหน้าจริง
ติดตามผลลัพธ์ ไม่ใช่การใช้เครื่องมือ:
- ความถี่การปรับใช้ และ lead time (ความเร็วในการส่งมอบ)
- ความน่าเชื่อถือ (การบรรลุ SLO, อัตราเหตุการณ์, MTTR)
- ความพึงพอใจของนักพัฒนา (แบบสำรวจสั้น ๆ, เวลาพาเข้าทีม, “เวลาถึงการปรับใช้ครั้งแรก”)
ถ้าคุณต้องการตัวอย่างแพ็กเกจ "platform MVP" ที่ดี ดู /blog สำหรับแนวทาง และสำหรับการวางแผนงบประมาณและโรลเอาต์ ดู /pricing
บทต่อไปของ cloud-native (และการเตรียมตัว)
บทเรียนสำคัญจากทศวรรษที่ผ่านมาง่าย ๆ: คอนเทนเนอร์ไม่ได้ “ชนะ” เพราะเป็นการแพ็กที่ฉลาด แต่เพราะแนวคิดเชิงแพลตฟอร์มทำให้พวกมันเชื่อถือได้—การปรับใช้ที่ทำซ้ำได้ การเปิดตัวที่ปลอดภัย การควบคุมความปลอดภัยที่สอดคล้อง และการปฏิบัติการที่คาดการณ์ได้
บทต่อไปไม่ใช่เรื่องของเครื่องมือเดี่ยวที่แย่งซีน แต่เป็นการทำให้ cloud-native รู้สึกน่าเบื่อในแง่ดีที่สุด: เหตุการณ์น้อยลง การแก้ปัญหาเฉพาะจุดน้อยลง และเส้นทางจากโค้ดสู่โปรดักชันที่ราบรื่นขึ้น
สิ่งที่ควรจับตามองต่อไป
Policy-as-code จะกลายเป็นค่าเริ่มต้น. แทนการตรวจสอบทุกการปรับใช้ด้วยมือ ทีมจะเขียนกฎด้านความปลอดภัย เครือข่าย และการปฏิบัติตามเป็นโค้ด ทำให้ราวกันเป็นอัตโนมัติและตรวจสอบได้
ประสบการณ์นักพัฒนา (DX) ถูกปฏิบัติเหมือนผลิตภัณฑ์. คาดว่าจะมุ่งเน้นทางลาดที่ปูไว้: เทมเพลต สภาพแวดล้อม self-service และ golden paths ชัดเจนที่ลดภาระทางความคิดโดยไม่จำกัดอำนาจ
ปฏิบัติการที่ง่ายขึ้น ไม่ใช่แดชบอร์ดเพิ่มขึ้น. แพลตฟอร์มที่ดีที่สุดจะซ่อนความซับซ้อน: ค่าเริ่มต้นที่มีความเห็นชอบ ชิ้นส่วนเคลื่อนไหวน้อยลง และรูปแบบความน่าเชื่อถือที่ฝังอยู่แทนที่จะมาติดตั้งทีหลัง
หลีกเลี่ยงกับดักการสะสมเครื่องมือ
ความก้าวหน้าของ cloud-native ช้าลงเมื่อทีมไล่ตามฟีเจอร์แทนผลลัพธ์ ถ้าคุณอธิบายไม่ได้ว่าเครื่องมือใหม่ช่วยลด lead time ลดอัตราเหตุการณ์ หรือปรับปรุงท่าทีความปลอดภัยอย่างไร มันอาจไม่ใช่สิ่งสำคัญ
ขั้นตอนต่อไปที่ชัดเจน
ประเมินจุดเจ็บปวดในการส่งมอบปัจจุบันและแมปกับความต้องการของแพลตฟอร์ม:
- การปรับใช้ล้มเหลวหรือช้าที่สุดที่ไหน?
- การอนุมัติและการตรวจสอบใดควรถูกทำเป็นราวกันอัตโนมัติ?
- นักพัฒนาสร้างซ้ำอะไรบ่อย ๆ (และควรเป็นมาตรฐาน)?
ใช้คำตอบเป็น backlog ของแพลตฟอร์มของคุณ—และวัดความสำเร็จด้วยผลลัพธ์ที่ทีมรู้สึกได้ทุกสัปดาห์
คำถามที่พบบ่อย
What does “cloud-native” mean (beyond “running in the cloud”)?
Cloud-native เป็นแนวทางการสร้างและดูแลซอฟต์แวร์เพื่อให้คุณสามารถ ปรับใช้บ่อยครั้ง, สเกลเมื่อความต้องการเปลี่ยนแปลง, และ กู้คืนได้เร็ว เมื่อล้มเหลว
ในการปฏิบัติ มักรวมถึงคอนเทนเนอร์, ระบบอัตโนมัติ, บริการขนาดเล็กกว่าเดิม และวิธีมาตรฐานสำหรับการสังเกต การรักษาความปลอดภัย และการกำกับดูแลสิ่งที่รันอยู่
Why weren’t containers alone enough for production at scale?
คอนเทนเนอร์ช่วยให้ส่งซอฟต์แวร์ได้สม่ำเสมอ แต่ไม่ได้แก้ปัญหาเชิงการปฏิบัติการทั้งหมดด้วยตัวเอง เช่น การอัปเกรดอย่างปลอดภัย, การค้นหาบริการ, การควบคุมด้านความปลอดภัย, และ การสังเกตที่ทนทาน
ช่องว่างจะปรากฏเมื่อคุณย้ายจากคอนเทนเนอร์ไม่กี่ชิ้นไปเป็น ร้อยๆ ชิ้น ที่รันตลอด 24/7
What is “platform thinking,” and how is it different from a toolbox of DevOps scripts?
“Platform thinking” คือการมองโครงสร้างพื้นฐานภายในองค์กรเป็น ผลิตภัณฑ์ภายใน มีผู้ใช้ชัดเจน (นักพัฒนา) และคำสัญญาชัดเจน (การส่งมอบที่ปลอดภัยและทำซ้ำได้)
แทนที่แต่ละทีมจะเย็บแพตช์เส้นทางสู่โปรดักชันด้วยตัวเอง องค์กรจะสร้าง paved roads (ทางเลือกที่แนะนำ) ที่มาพร้อมค่าเริ่มต้นที่สมเหตุสมผลและการสนับสนุน
What does Kubernetes actually solve for teams running containers?
Kubernetes ให้ชั้นปฏิบัติการที่เปลี่ยน “กองคอนเทนเนอร์” ให้เป็นระบบที่คุณสามารถดูแลได้ทุกวัน:
- การจัดตารางงาน: วางโหลดงานลงบนเครื่องที่มีทรัพยากรเพียงพอ
- การฟื้นฟูตนเอง: รีสตาร์ทและย้ายคอนเทนเนอร์เมื่อเกิดความล้มเหลว
- การสเกลและการเปิดตัว: ปรับจำนวนสำเนาและปรับรุ่นอย่างปลอดภัย
นอกจากนี้มันยังนำแนวคิด control plane ร่วมที่คุณประกาศสถานะที่ต้องการ และระบบจะพยายามทำให้โลกจริงตรงกับนั้น
What is “declarative configuration,” and why does it matter in delivery?
Declarative config คือการอธิบาย สิ่งที่คุณต้องการ (desired state) แทนการเขียนขั้นตอนทีละขั้น
ข้อดีเชิงปฏิบัติได้แก่:
- การเปลี่ยนแปลง ตรวจทานได้ (เวิร์กโฟลว์ Git)
- การปรับใช้ ทำซ้ำได้ ข้ามสภาพแวดล้อม
- การย้อนสถานะมัก ง่ายขึ้น เพราะสามารถยกเลิกการเปลี่ยนแปลงหรือปรับใช้แอーティแฟกต์ก่อนหน้าได้
What are immutable deployments, and how do they reduce “mystery outages”?
Immutable deployments คือการไม่แพตช์เซิร์ฟเวอร์ที่กำลังรัน แต่ สร้างแอーティแฟกต์ครั้งเดียว (มักเป็น container image) แล้วปรับใช้แอーティแฟกต์นั้น
เมื่อต้องการเปลี่ยนแปลง คุณปล่อยเวอร์ชันใหม่แทนการแก้ไขระบบที่กำลังทำงาน วิธีนี้ช่วยลดการเบี่ยงเบนของการตั้งค่า (configuration drift) และทำให้การจำลองเหตุการณ์และการย้อนกลับง่ายขึ้น
Why did the CNCF matter for Kubernetes adoption?
CNCF ให้ที่ยืนกลางที่เป็นกลางสำหรับ Kubernetes และโครงการที่เกี่ยวข้อง ช่วยลดความเสี่ยงในการเลือกใช้อินฟราสตรัคเจอร์หลัก
มันช่วยในด้าน:
- กระบวนการที่คาดเดาได้สำหรับการออกเวอร์ชันและแนวทางด้านความปลอดภัย
- เวทีสำหรับการประสานงานข้ามบริษัท
- สัญญาณไปยังตลาดว่าโครงการนี้ถูกออกแบบมาให้อยู่ได้ยาวนานกว่าหนึ่งผู้ขาย
What is a “production baseline,” and what should it include?
Production baseline คือชุดความสามารถและแนวปฏิบัติต่ำสุดที่ทำให้ความน่าเชื่อถือคาดเดาได้ เช่น:
- การสังเกต (logs, metrics, tracing ที่อธิบายเหตุผล ไม่ใช่แค่สถานะว่า "ทำงาน")
- การตอบสนองต่อเหตุการณ์ (บทบาท, ตำแหน่ง on-call, เส้นทางการยกระดับ, บทเรียนหลังเหตุการณ์)
- การวางแผนความจุ (ขีดจำกัด, คาดการณ์โหลด, พฤติกรรมภายใต้ความเครียด)
ถ้าไม่มีสิ่งเหล่านี้ แต่ละบริการจะตั้งกฎของตัวเองและความน่าเชื่อถือจะกลายเป็นเรื่องของโชค
What does a platform engineering team typically build to make cloud-native usable?
ทีม platform engineering มุ่งลดภาระทางความคิดของนักพัฒนาโดยแพ็กเกจ primitive ของ cloud-native เป็นค่าเริ่มต้นที่มีความเห็นชอบได้ ได้แก่:
- เทมเพลต/โครงสร้างสำหรับบริการใหม่ (repo, CI, การสังเกตพื้นฐาน)
- เวิร์กโฟลว์แบบ self-service (สร้างสภาพแวดล้อม, ขอฐานข้อมูล, หมุนรหัสลับ)
- รูปแบบการปรับใช้มาตรฐาน (health checks, autoscaling, canary)
เป้าหมายไม่ใช่ปิดบัง Kubernetes แต่คือจัดเป็นค่าเริ่มต้นที่ลดความซับซ้อนโดยไม่ทำลายความยืดหยุ่น
What are the most common cloud-native adoption pitfalls, and how can teams avoid them?
ข้อผิดพลาดทั่วไป ได้แก่:
- Kubernetes-first, outcomes-later: นำไปใช้เพราะเป็นเทรนด์โดยไม่ได้ตั้งเป้าหมายชัดเจน
- Ecosystem sprawl: เพิ่มส่วนเสริมจำนวนมากโดยไม่มีขอบเขตหรือความเป็นเจ้าของชัดเจน
- Security and cost drift: สิทธิ์ที่ขยายเกินความจำเป็น, อิมเมจที่ยังไม่ได้ตรวจสอบ, ทรัพยากรที่ถูกลืม
วิธีแก้ที่ยังรักษาความคืบหน้า: