05 พ.ค. 2568·4 นาที
Datadog และการเปลี่ยนสู่แพลตฟอร์ม: เทเลเมทรี การรวม และเวิร์กโฟลว์
ดูว่าทำไม Datadog ถึงกลายเป็นแพลตฟอร์มเมื่อ telemetry, integrations, และ workflows กลายเป็นผลิตภัณฑ์—พร้อมแนวคิดเชิงปฏิบัติที่นำไปใช้ในสแตกของคุณได้จริง
ดูว่าทำไม Datadog ถึงกลายเป็นแพลตฟอร์มเมื่อ telemetry, integrations, และ workflows กลายเป็นผลิตภัณฑ์—พร้อมแนวคิดเชิงปฏิบัติที่นำไปใช้ในสแตกของคุณได้จริง
เครื่องมือสังเกตการณ์ (observability tool) ช่วยคุณตอบคำถามเฉพาะเกี่ยวกับระบบ—โดยปกติผ่านการแสดงแผนภูมิ ล็อก หรือผลลัพธ์คิวรี มันคือสิ่งที่คุณ “ใช้” เมื่อมีปัญหา
แพลตฟอร์มสังเกตการณ์ใหญ่มากกว่า: มันมาตรฐานการเก็บ telemetry วิธีที่ทีมสำรวจข้อมูล และวิธีจัดการเหตุการณ์ตั้งแต่ต้นจนจบ มันกลายเป็นสิ่งที่องค์กรของคุณ “รัน” ทุกวัน ข้ามหลายบริการและหลายทีม
ทีมส่วนใหญ่เริ่มที่แดชบอร์ด: แผนภูมิ CPU กราฟอัตราความผิดพลาด บางทีก็มีการค้นหาล็อกไม่กี่รายการ นั่นมีประโยชน์ แต่วัตถุประสงค์ที่แท้จริงไม่ใช่แค่แผนภูมิที่สวยขึ้น—คือการ ตรวจจับเร็วขึ้นและแก้ไขเร็วขึ้น
การเปลี่ยนเป็นแพลตฟอร์มเกิดขึ้นเมื่อคุณเลิกถามว่า “เราพล็อตอันนี้ได้ไหม?” แล้วเริ่มถาม:
คำถามเหล่านี้เน้นผลลัพธ์ และต้องการมากกว่าการแสดงผล: ต้องมีมาตรฐานข้อมูลร่วม การรวมที่สม่ำเสมอ และเวิร์กโฟลว์ที่เชื่อม telemetry เข้ากับการลงมือทำ
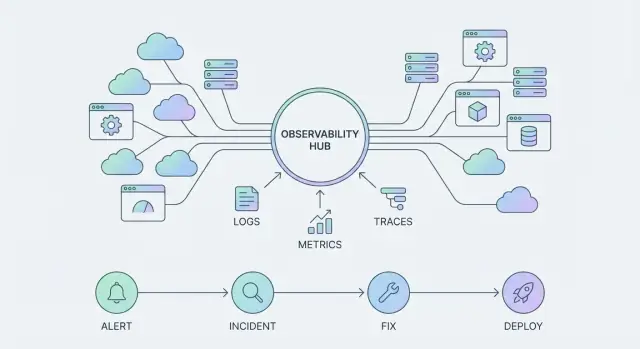
เมื่อแพลตฟอร์มอย่าง Datadog พัฒนา พื้นที่ผลิตภัณฑ์ไม่ได้มีแค่แดชบอร์ด แต่มันคือสามเสาที่เกี่ยวเนื่องกัน:
แดชบอร์ดเดียวช่วยทีมเดียวได้ แพลตฟอร์มจะแข็งแกร่งขึ้นเมื่อมีบริการถูกนำเข้ามา ทุกการรวมและทุกเวิร์กโฟลว์ที่เป็นมาตรฐานจะทวีมูลค่า เมื่อเวลาผ่านไปสิ่งนี้จะกลายเป็นการลดจุดบอด ลดการซ้ำซ้อนเครื่องมือ และย่นระยะเวลาเหตุการณ์—เพราะการปรับปรุงทุกอย่างจะนำกลับมาใช้ได้ ไม่ใช่แค่ครั้งเดียว
เมื่อการสังเกตการณ์เปลี่ยนจาก “เครื่องมือที่เราคิวรี” เป็น “แพลตฟอร์มที่เราสร้างขึ้น” telemetry จะหยุดเป็นของเสียดิบและเริ่มทำหน้าที่เป็นพื้นผิวของผลิตภัณฑ์ สิ่งที่คุณเลือกจะส่งออก—และความสม่ำเสมอของการส่ง—กำหนดว่าสิ่งที่ทีมของคุณจะเห็น อัตโนมัติ และเชื่อถือได้คืออะไร
ทีมส่วนใหญ่ตั้งมาตรฐานรอบสัญญาณไม่กี่ประเภท:
แต่ละสัญญาณมีประโยชน์ต่างกัน แต่เมื่อรวมกันแล้วจะกลายเป็นอินเทอร์เฟซเดียวต่อระบบของคุณ—สิ่งที่เห็นในแดชบอร์ด การแจ้งเตือน ไทม์ไลน์เหตุการณ์ และโพสต์มอร์เทม
ความล้มเหลวทั่วไปคือการเก็บ “ทุกอย่าง” แต่ตั้งชื่อไม่สอดคล้องกัน ถ้าหนึ่งบริการใช้ userId อีกบริการใช้ uid และอีกบริการไม่ล็อกเลย คุณจะไม่สามารถตัดแบ่งข้อมูล เชื่อมสัญญาณ หรือตั้งมอนิเตอร์ที่นำกลับมาใช้ได้อย่างน่าเชื่อถือ
ทีมจะได้คุณค่ามากขึ้นจากการตกลงร่วมกันเรื่องคอนเวนชันไม่กี่อย่าง—ชื่อบริการ แท็กสภาพแวดล้อม รหัสคำขอ และชุดแอตทริบิวต์มาตรฐาน—มากกว่าการเพิ่มปริมาณ ingestion เป็นสองเท่า
ฟิลด์ high-cardinality คือแอตทริบิวต์ที่มีค่าจำนวนมาก (เช่น user_id, order_id, session_id) มันทรงพลังสำหรับการดีบักปัญหา “เกิดกับลูกค้ารายเดียว” แต่ก็เพิ่มต้นทุนและทำให้คิวรีช้าหากใช้ทุกที่
แนวทางของแพลตฟอร์มคือมีเจตนา: เก็บ high-cardinality ไว้ที่ให้คุณค่าในการสืบสวนเท่านั้น และหลีกเลี่ยงในจุดที่ต้องการการรวมระดับโลก
ผลตอบแทนคือความเร็ว เมื่อ metrics, logs, traces, events, และ profiles แชร์ context เดียวกัน (service, version, region, request ID) วิศวกรใช้เวลาน้อยลงในการเย็บหลักฐานและมากขึ้นในการแก้ปัญหาจริง แทนที่จะต้องข้ามเครื่องมือและเดา คุณสามารถตามด้ายเดียวจากอาการไปยังสาเหตุหลักได้
ทีมส่วนใหญ่มักเริ่มสังเกตการณ์โดยการ “เอาข้อมูลเข้า” นั่นจำเป็น แต่ไม่ใช่กลยุทธ์ กลยุทธ์เทเลเมทรีคือสิ่งที่ทำให้การนำเข้าเร็วและทำให้ข้อมูลของคุณสม่ำเสมอพอที่จะขับเคลื่อนแดชบอร์ดร่วม มอนิเตอร์ที่เชื่อถือได้ และ SLO ที่มีความหมาย
Datadog มักรับ telemetry ผ่านช่องทางปฏิบัติไม่กี่ทาง:
ช่วงเริ่มต้น ความเร็วชนะ: ทีมติดตั้ง agent เปิด integration สองสามอย่าง แล้วเห็นคุณค่าทันที ความเสี่ยงคือแต่ละทีมคิดค้นแท็ก ชื่อบริการ และรูปแบบล็อกของตัวเอง—ทำให้มุมมองข้ามบริการเละและการแจ้งเตือนเชื่อถือไม่ได้
กฎง่ายๆ: อนุญาต onboarding แบบเร็ว แต่ต้องบังคับให้เป็นมาตรฐานภายใน 30 วัน วิธีนี้ให้ทีมมีโมเมนตัมโดยไม่ล็อกให้เกิดความยุ่งเหยิง
คุณไม่ต้องการไดเรกทอรีใหญ่เเห่งศัพท์ เริ่มจากชุดเล็กๆ ที่ทุกสัญญาณ (logs, metrics, traces) ต้องมี:
service: สั้น คงที่ ตัวพิมพ์เล็ก (เช่น checkout-api)\n- env: prod, staging, dev\n- team: ตัวระบุทีมที่เป็นเจ้าของ (เช่น payments)\n- version: เวอร์ชัน deploy หรือ git SHAถ้าต้องการอีกอันที่ให้ผลเร็ว ให้เพิ่ม tier (frontend, backend, data) เพื่อให้ง่ายต่อการกรอง
ปัญหาต้นทุนมักมาจากดีฟอลต์ที่ใจกว้างเกินไป:
เป้าหมายไม่ใช่เก็บให้น้อยลง แต่คือเก็บข้อมูลที่ ถูกต้อง อย่างสม่ำเสมอ เพื่อให้การใช้ขยายตัวได้โดยไม่เซอร์ไพรส์
คนมักคิดว่าเครื่องมือสังเกตการณ์คือ “สิ่งที่คุณติดตั้ง” แต่ในทางปฏิบัติ มันแพร่กระจายในองค์กรเหมือนการเชื่อมต่อที่ดี: ทีละ integration
integration ไม่ได้เป็นแค่ท่อข้อมูล มันมักมีสามส่วน:
ส่วนสุดท้ายนี่แหละที่เปลี่ยน integration ให้เป็นการกระจาย หากเครื่องมือแค่ อ่าน มันคือจุดหมายสำหรับแดชบอร์ด แต่ถ้ามัน เขียน ได้ มันกลายเป็นส่วนหนึ่งของงานประจำ
Integration ที่ดีลดเวลาติดตั้งเพราะมาพร้อมค่าเริ่มต้นที่สมเหตุสมผล: แดชบอร์ดสำเร็จรูป มอนิเตอร์แนะนำ กฎการแยกพาร์ส และแท็กทั่วไป แทนที่แต่ละทีมจะประดิษฐ์ “แดชบอร์ด CPU” หรือ “การแจ้งเตือน Postgres” ของตัวเอง คุณจะได้จุดเริ่มต้นมาตรฐานที่สอดคล้องกับแนวปฏิบัติ
ทีมยังคงปรับแต่ง แต่จะปรับจากฐานร่วม ซึ่งการมาตรฐานนี้สำคัญเมื่อคุณรวมเครื่องมือ: integrations สร้างแบบแผนที่ทำซ้ำได้ที่บริการใหม่สามารถคัดลอกได้ ทำให้การเติบโตจัดการได้
เมื่อประเมินตัวเลือก ให้ถามว่า: มัน รับสัญญาณ และ ทำ action ได้ไหม? ตัวอย่างเช่นการเปิด incident ในระบบตั๋วของคุณ อัปเดตช่องทาง incident หรือแนบลิงก์ trace กลับไปยัง PR หรือมุมมอง deploy การตั้งค่าทั้งสองทางเป็นจุดเริ่มต้นที่ทำให้เวิร์กโฟลว์รู้สึกว่าเป็น “ของแท้”
เริ่มเล็กและคาดเดาได้:
ถ้าต้องการกฎง่ายๆ: ให้ความสำคัญกับ integrations ที่ปรับปรุงการตอบเหตุการณ์ทันที ไม่ใช่แค่เพิ่มแผนภูมิ
มุมมองมาตรฐานคือที่ที่แพลตฟอร์มสังเกตการณ์กลายเป็นสิ่งที่ใช้งานได้ในแต่ละวัน เมื่อทีมแชร์โมเดลทางความคิดเดียวกัน—บริการคืออะไร, สุขภาพคืออะไร, และจะคลิกที่ไหนก่อน—การดีบักจะเร็วขึ้นและการส่งมอบงานระหว่างคนจะสะอาดขึ้น
เลือกสัญญาณ “ทองคำ” ไม่กี่อย่างและแมปแต่ละอันไปยังแดชบอร์ดที่นำกลับมาใช้ได้ สำหรับบริการส่วนใหญ่ นั่นคือ:
ความสำคัญคือความสอดคล้อง: เลย์เอาต์แดชบอร์ดแบบหนึ่งที่ใช้ได้กับหลายบริการดีกว่าแดชบอร์ดที่ออกแบบเฉพาะหลายอัน
แคตตาล็อกบริการ (แม้เพียงแบบน้ำหนักเบา) จะเปลี่ยน “ควรมีคนดู” เป็น “ทีมนี้เป็นเจ้าของ” เมื่อบริการถูกแท็กด้วยเจ้าของ สภาพแวดล้อม และการพึ่งพา แพลตฟอร์มสามารถตอบคำถามพื้นฐานได้ทันที: มอนิเตอร์ไหนใช้กับบริการนี้? แดชบอร์ดไหนควรเปิด? ใครจะถูกพาด?
ความชัดเจนนี้ลดการคุยกันใน Slack ระหว่างเหตุการณ์และช่วยวิศวกรใหม่ให้หาทางด้วยตัวเอง
Treat สิ่งเหล่านี้เป็นสิ่งมาตรฐาน ไม่ใช่ของเสริม:
Vanity dashboards (กราฟสวยแต่ไม่มีการตัดสินใจเบื้องหลัง), การแจ้งเตือนแบบครั้งเดียว (สร้างเพราะรีบแล้วไม่ปรับ) และคิวรีที่ไม่มีเอกสาร (มีคนเดียวที่เข้าใจฟิลเตอร์วิเศษ) สร้างเสียงรบกวนในแพลตฟอร์ม ถ้าคิวรีสำคัญ ให้บันทึก ตั้งชื่อ และแนบกับมุมมองบริการที่คนอื่นหาเจอได้
Observability จะเป็นเรื่อง “จริง” ต่อธุรกิจเมื่อมันย่นระยะเวลาระหว่างปัญหากับการแก้ไขที่มั่นใจได้ ซึ่งเกิดขึ้นผ่านเวิร์กโฟลว์—เส้นทางที่ทำซ้ำได้จากสัญญาณสู่การกระทำ และจากการกระทำสู่การเรียนรู้
เวิร์กโฟลว์ที่ขยายได้มากกว่าแค่การ page ใครสักคน
การแจ้งเตือนควรเปิดลูปการตีความเฉพาะทาง: ยืนยันผลกระทบ ระบุบริการที่ได้รับผล กระชับคอนเท็กซ์ที่เกี่ยวข้องที่สุด (deploy ล่าสุด, สุขภาพการพึ่งพา, การพุ่งของข้อผิดพลาด, สัญญาณ saturation) จากนั้นการสื่อสารเปลี่ยนเหตุการณ์ทางเทคนิคเป็นการตอบสนองที่ประสานงาน—ใครเป็นเจ้าของเหตุการณ์ ผู้ใช้เห็นอะไร และเมื่อไรจะมีอัปเดตครั้งต่อไป
การบรรเทาเป็นที่ที่คุณต้องการ “การเคลื่อนไหวที่ปลอดภัย” อยู่ใกล้มือ: feature flags, การย้ายทราฟฟิก, rollback, rate limits, หรือวิธีแก้ชั่วคราวที่รู้จัก สุดท้าย การเรียนรู้ปิดวงด้วยการทบทวนอย่างกระชับที่จับสิ่งที่เปลี่ยน งานที่ได้ผล และสิ่งที่ควรทำให้เป็นอัตโนมัติต่อไป
แพลตฟอร์มอย่าง Datadog เพิ่มคุณค่าเมื่อสนับสนุนงานร่วมกัน: ช่องเหตุการณ์, การอัปเดตสถานะ, การส่งมอบงาน, และไทม์ไลน์ที่สอดคล้อง การรวม ChatOps สามารถเปลี่ยนการแจ้งเตือนให้เป็นบทสนทนาที่มีโครงสร้าง—สร้าง incident กำหนดบทบาท และโพสต์กราฟและคิวรีสำคัญตรงในเธรดเพื่อให้ทุกคนเห็นหลักฐานเดียวกัน
Runbook ที่มีประโยชน์สั้น ชัด และปลอดภัย ควรมี: เป้าหมาย (คืนบริการ), เจ้าของ/รอบ on-call ชัดเจน, เช็คลิสต์ทีละขั้นตอน, ลิงก์ไปยังแดชบอร์ด/มอนิเตอร์ที่ถูกต้อง, และ “การกระทำที่ปลอดภัย” ที่ลดความเสี่ยง (พร้อมขั้นตอน rollback) ถ้ามันไม่ปลอดภัยที่จะรันตอนตีสาม มันยังไม่เสร็จ
การหาเหตุผลเร็วขึ้นเมื่อเหตุการณ์ถูกเชื่อมโยงโดยอัตโนมัติกับ deploys การเปลี่ยนแปลงคอนฟิก และการพลิก feature flag ทำให้การตีความเริ่มด้วยหลักฐาน ไม่ใช่การเดา
SLO (Service Level Objective) คือคำสัญญาเรียบง่ายเกี่ยวกับประสบการณ์ผู้ใช้ในช่วงเวลา—เช่น “99.9% ของคำร้องขอสำเร็จใน 30 วัน” หรือ “p95 โหลดหน้าอยู่ต่ำกว่า 2 วินาที”
นั่นดีกว่า “แดชบอร์ดเขียว” เพราะแดชบอร์ดมักแสดง สุขภาพระบบ (CPU, memory, คิว) มากกว่า ผลกระทบต่อผู้ใช้ บริการอาจดูเขียวแต่ผู้ใช้กำลังล้มเหลว (เช่น พึ่งพาไทม์เอาท์ หรือข้อผิดพลาดกระจุกตัวในภูมิภาคหนึ่ง) SLO บังคับให้ทีมวัดสิ่งที่ผู้ใช้รู้สึกจริงๆ
Error budget คือปริมาณความไม่เสถียรที่อนุญาตตาม SLO ถ้าคุณสัญญา 99.9% ใน 30 วัน คุณจะ “อนุญาต” เวลาที่ผิดพลาดประมาณ 43 นาทีในช่วงนั้น
นี้สร้างระบบปฏิบัติการสำหรับการตัดสินใจ:
แทนที่จะโต้วาทีด้วยความเห็นในที่ประชุมปล่อย คุณจะโต้วาทีตัวเลขที่ทุกคนเห็นได้
การตั้งแจ้งเตือน SLO ทำงานได้ดีเมื่อแจ้งตาม burn rate (ความเร็วที่ใช้งบผิดพลาด) ไม่ใช่จำนวนข้อผิดพลาดดิบ วิธีลดเสียงรบกวน:
หลายทีมใช้สองหน้าต่าง: fast burn (page เร็ว) และ slow burn (ตั๋ว/แจ้ง)
เริ่มเล็ก—2–4 SLO ที่คุณจะใช้จริง:\n
เมื่อชุดเหล่านี้เสถียรแล้วค่อยขยาย มิฉะนั้นคุณจะสร้างกำแพงแดชบอร์ดอีกผนัง สำหรับข้อมูลเพิ่มเติม ดู /blog/slo-monitoring-basics.
การแจ้งเตือนเป็นที่ที่หลายโปรแกรมสังเกตการณ์ติดขัด: ข้อมูลมีแต่ประสบการณ์ on-call กลับเต็มไปด้วยเสียงรบกวนและไม่เชื่อถือ หากคนเริ่มเพิกเฉยต่อการแจ้งเตือน แพลตฟอร์มของคุณจะสูญเสียความสามารถในการปกป้องธุรกิจ
สาเหตุที่พบบ่อยมีความคล้ายคลึงกันเสมอ:
ในบริบทของ Datadog สัญญาณซ้ำมักปรากฏเมื่อมอนิเตอร์ถูกสร้างจากพื้นผิวต่างกัน (metrics, logs, traces) โดยไม่ตัดสินใจว่าผิวแบบใดคือผิว canonical ที่จะ page
การขยายการแจ้งเตือนเริ่มที่กฎการ routing ที่มีความหมายต่อมนุษย์:\n
ค่าเริ่มต้นที่มีประโยชน์คือ: แจ้งเตือนตามอาการ ไม่ใช่ทุกการเปลี่ยนแปลงของเมตริก Page เมื่อสิ่งที่ผู้ใช้รู้สึก (อัตราความผิดพลาด, เช็คเอาต์ล้มเหลว, latency ยืดเยื้อ, การเผา SLO) ไม่ใช่ “อินพุต” (CPU, จำนวนพ็อด) เว้นแต่พวกมันจะทำนายผลกระทบได้แน่นอน
ทำความสะอาดมอนิเตอร์เป็นส่วนหนึ่งของการปฏิบัติ: การล้างและปรับมอนิเตอร์รายเดือน เอามอนิเตอร์ที่ไม่เคยเกิดออก ปรับเกณฑ์ที่เกิดบ่อยเกินไป และรวมตัวซ้ำเพื่อให้แต่ละเหตุการณ์มีหน้าเพจหลักบวกบริบทสนับสนุน
เมื่อทำดีแล้ว การแจ้งเตือนจะกลายเป็นเวิร์กโฟลว์ที่ผู้คนเชื่อถือ ไม่ใช่เครื่องสร้างเสียงรบกวน
เรียก observability ว่า “แพลตฟอร์ม” ไม่ใช่แค่มีล็อก เมตริก แทรซ และการรวมเยอะๆ แต่มันหมายถึงการกำกับดูแล: ความสอดคล้องและแนวป้องกันที่ทำให้ระบบใช้งานได้เมื่อจำนวนทีม บริการ แดชบอร์ด และมอนิเตอร์เพิ่มขึ้น
ถ้าไม่มีการกำกับดูแล Datadog (หรือแพลตฟอร์มใดๆ) อาจลื่นไถลเป็นสมุดขยะแบบมีเสียง—ร้อยแดชบอร์ดที่แตกต่างเล็กน้อย แท็กไม่สอดคล้อง เจ้าของไม่ชัด และการแจ้งเตือนที่ไม่มีใครเชื่อถือ
การกำกับดูแลที่ดีชัดเจนว่าใครตัดสินใจอะไร และใครรับผิดชอบเมื่อแพลตฟอร์มยุ่งเหยิง:
การควบคุมแบบน้ำหนักเบาบางอย่างให้ผลมากกว่านโยบายยาวๆ:
service, env, team, tier) พร้อมกฎชัดเจนสำหรับแท็กเสริม และบังคับใน CI เมื่อเป็นไปได้\n- การเข้าถึงและความเป็นเจ้าของ: ใช้ role-based access สำหรับข้อมูลอ่อนไหวและกำหนดเจ้าของสำหรับแดชบอร์ด/มอนิเตอร์\n- ลำดับอนุมัติสำหรับการเปลี่ยนแปลงที่มีผลกระทบสูง: มอนิเตอร์ที่ page คน, พายพลไลน์ล็อกที่มีผลต่อต้นทุน, และ integration ที่ดึงข้อมูลอ่อนไหวควรมีขั้นตอนตรวจสอบวิธีที่เร็วที่สุดในการขยายคุณภาพคือแชร์สิ่งที่ได้ผล:\n
ถ้าคุณอยากให้สิ่งนี้ยึดติด ให้เส้นทางที่ถูกกำกับเป็นเส้นทางที่ง่ายกว่า—คลิกน้อยกว่า การตั้งค่ารวดเร็วกว่า และความเป็นเจ้าของชัดเจนกว่า
เมื่อ observability ทำตัวเหมือนแพลตฟอร์ม มันเริ่มตามเศรษฐศาสตร์แพลตฟอร์ม: ยิ่งทีมใช้งานมากเท่าไร telemetry ก็ยิ่งถูกผลิตมากขึ้น และมันก็ยิ่งมีประโยชน์มากขึ้น
นั่นสร้างวงจร:
ข้อแม้คือลูปเดียวกันเพิ่มต้นทุนมากขึ้น โฮสต์ คอนเทนเนอร์ ล็อก แทรซ สินค้าจำลอง และเมตริกกำหนดเองสามารถเติบโตเร็วกว่าบัดเจ็ตของคุณถ้าคุณไม่จัดการอย่างตั้งใจ
คุณไม่ต้อง “ปิดทุกอย่าง” เริ่มจากปรับรูปร่างข้อมูล:
ติดตามมาตรวัดเล็กๆ ที่บอกว่าพลตฟอร์มคุ้มค่าหรือไม่:
ทำเป็นรีวิวผลิตภัณฑ์ ไม่ใช่การตรวจสอบ นำเจ้าของแพลตฟอร์ม ทีมบริการบางทีม และการเงินมาร่วมทบทวน:\n
เป้าหมายคือความเป็นเจ้าของร่วม: ต้นทุนเป็นข้อมูลนำไปสู่การตัดสินใจ instrumentation ที่ดีขึ้น ไม่ใช่เหตุผลหยุดการสังเกต
ถ้า observability กำลังกลายเป็นแพลตฟอร์ม ชุดเครื่องมือของคุณจะหยุดเป็นการรวมของโซลูชันจุดเดียวและเริ่มทำหน้าที่เป็นโครงสร้างพื้นฐานร่วม การเปลี่ยนนี้ทำให้การกระจายเครื่องมือมากกว่าแค่เรื่องรำคาญ: มันสร้างการซ้ำซ้อนในการ instrumentation คำนิยามไม่สอดคล้องกัน (อะไรนับเป็นข้อผิดพลาด?) และโหลด on-call สูงขึ้นเพราะสัญญาณไม่ตรงกันระหว่างล็อก เมตริก แทรซ และเหตุการณ์
การรวมเครื่องมือไม่ได้หมายความว่า “ผู้ขายเดียวสำหรับทุกอย่าง” โดยอัตโนมัติ แต่มันหมายถึงมีระบบบันทึกไม่น้อยสำหรับ telemetry และการตอบสนอง ความเป็นเจ้าของชัดเจนกว่า และจำนวนจุดที่คนต้องมองตอนเกิด outage น้อยลง
การกระจายเครื่องมือซ่อนต้นทุนในสามที่: เวลาที่ใช้สลับ UI, การรวมที่เปราะบางที่ต้องบำรุงรักษา, และการกำกับดูแลที่กระจัดกระจาย (ชื่อ แท็ก การเก็บรักษา การเข้าถึง)
แนวทางแพลตฟอร์มที่รวมมากขึ้นสามารถลดการสลับบริบท ทำให้มุมมองบริการเป็นมาตรฐาน และทำให้เวิร์กโฟลว์เหตุการณ์ซ้ำได้
เมื่อประเมินสแตกของคุณ (รวม Datadog หรือทางเลือกอื่น) ทดสอบด้วยคำถามเหล่านี้:\n
เลือก 1–2 บริการ ที่มีทราฟฟิกจริง กำหนดเมตริกความสำเร็จเช่น “เวลาหาสาเหตุหลักลดจาก 30 นาทีเป็น 10” หรือ “ลดการแจ้งเตือนที่มีเสียงรบกวน 40%” ติดตั้ง instrumentation ที่จำเป็นเท่านั้น แล้วทบทวนผลหลังสองสัปดาห์
เก็บเอกสารภายในกลางไว้เพื่อให้การเรียนรู้ทบต้น—แนบ runbook พิลอต กฎแท็ก และแดชบอร์ดจากที่เดียว (เช่น /blog/observability-basics เป็นจุดเริ่มต้นภายใน)
คุณไม่ได้ “เปิด Datadog” ครั้งเดียว คุณเริ่มเล็ก กำหนดมาตรฐานตั้งแต่ต้น แล้วขยายสิ่งที่ได้ผล
วัน 0–30: นำเข้า (พิสูจน์คุณค่าเร็ว)
เลือก 1–2 บริการสำคัญและเส้นทางลูกค้าที่เห็นได้ชัด ติดตั้ง logs, metrics, traces ให้สม่ำเสมอ และเชื่อม integrations ที่คุณพึ่งพาอยู่แล้ว (cloud, Kubernetes, CI/CD, on-call)
วัน 31–60: มาตรฐาน (ทำให้ทำซ้ำได้)
เปลี่ยนสิ่งที่เรียนรู้เป็นค่าเริ่มต้น: การตั้งชื่อบริการ, แท็ก, เทมเพลตแดชบอร์ด, การตั้งชื่อมอนิเตอร์, และความเป็นเจ้าของ สร้างมุมมอง “golden signals” และชุด SLO ขั้นต่ำสำหรับ endpoint สำคัญ
วัน 61–90: ขยาย (นำเข้าโดยไม่เกิดความยุ่งเหยิง)
นำทีมเพิ่มเติมเข้าด้วยเทมเพลตเดียวกัน แนะนำการกำกับดูแล (กฎแท็ก ข้อมูลเมตาดาตาที่ต้องมี กระบวนการตรวจสอบมอนิเตอร์ใหม่) และเริ่มติดตามต้นทุนเทียบกับการใช้งานเพื่อให้แพลตฟอร์มอยู่ในสภาพดี
เมื่อคุณมอง observability เป็นแพลตฟอร์ม ปกติคุณจะอยากได้แอป “กาว” เล็กๆ รอบมัน: UI แคตตาล็อกบริการ, ฮับ runbook, หน้าติดตามไทม์ไลน์เหตุการณ์, หรือพอร์ทัลภายในที่เชื่อมเจ้าของ → แดชบอร์ด → SLOs → playbooks
นี่คือประเภทเครื่องมือภายในที่คุณสร้างได้เร็วด้วย Koder.ai—แพลตฟอร์ม vibe-coding ที่ให้คุณสร้างเว็บแอปผ่านแชท (มักเป็น React หน้า frontend, Go + PostgreSQL ฝั่ง backend) พร้อมส่งออกซอร์สโค้ดและรองรับการ deploy/hosting ทีมมักใช้มันเพื่อต้นแบบและส่งมอบพื้นผิวการปฏิบัติที่ทำให้การกำกับดูแลและเวิร์กโฟลว์ง่ายขึ้นโดยไม่ต้องถอดทีมผลิตภัณฑ์ออกจากโร้ดแมป
จัดสองเซสชัน 45 นาที: (1) “เราคิวรีอย่างไรที่นี่” กับรูปแบบคิวรีที่ใช้ร่วมกัน (ตาม service, env, region, version), และ (2) “Playbook การแก้ปัญหา” กับโฟลว์เรียบง่าย: ยืนยันผลกระทบ → ตรวจ deploy markers → จำกัดสู่บริการ → ตรวจ traces → ยืนยันสุขภาพการพึ่งพา → ตัดสิน rollback/mitigation
An observability tool คือสิ่งที่คุณเรียกดูเวลามีปัญหา (แดชบอร์ด ค้นหาล็อก คิวรี) แต่ An observability platform คือสิ่งที่คุณ “รัน” ต่อเนื่อง: มันมาตรฐานการเก็บ telemetry, การรวมระบบ, การเข้าถึง, ความเป็นเจ้าของ, การแจ้งเตือน และเวิร์กโฟลว์เหตุการณ์ข้ามทีม ทำให้ออกมาเป็นผลลัพธ์ที่วัดได้ (ตรวจจับและแก้ไขได้เร็วขึ้น).
เพราะผลลัพธ์ที่ได้มักมาจากการกระทำ ไม่ใช่แค่ภาพสวยๆ:
แดชบอร์ดช่วยให้เห็น แต่คุณต้องมีมาตรฐานร่วมและเวิร์กโฟลว์เพื่อจะลด MTTD/MTTR ได้อย่างสม่ำเสมอ.
เริ่มด้วยชุดพื้นฐานที่ทุกสัญญาณต้องมี:
serviceenv (prod, staging, dev)ฟิลด์ความเป็น high-cardinality (เช่น user_id, order_id, session_id) เหมาะสำหรับดีบักปัญหา “เกิดกับลูกค้ารายเดียว” แต่จะเพิ่มต้นทุนและทำให้คิวรีช้าถ้าใช้ทุกที่:
ทีมส่วนใหญ่ตั้งมาตรฐานบนชุดสัญญาณหลัก:
ค่าเริ่มต้นที่แนะนำคือ:
เลือกเส้นทางที่ตรงกับความต้องการการควบคุม แล้วบังคับใช้กฎการตั้งชื่อ/แท็กให้เหมือนกันข้ามทางเข้าเหล่านี้.
ทำทั้งสองอย่าง:
วิธีนี้ช่วยรักษาโมเมนตัมการนำไปใช้โดยไม่ปล่อยให้แต่ละทีมสร้างสคีมาของตัวเอง.
เพราะ integration ที่ดีมีมากกว่าแค่ท่อข้อมูล—มันรวมถึง:
ให้ความสำคัญกับ integration ที่ สองทาง ที่ทั้ง ingest สัญญาณและทำ action ได้ เพราะจะทำให้ observability เป็นส่วนของงานประจำ ไม่ใช่แค่ UI ปลายทาง.
ยึดที่ความสม่ำเสมอและการนำกลับมาใช้:
หลีกเลี่ยง vanity dashboards และ alerts ที่ทำครั้งเดียวแล้วลืม. ถ้าคิวรีสำคัญ ให้บันทึก, ตั้งชื่อ, และแนบเข้ากับมุมมองบริการที่คนอื่นหาพบได้.
แจ้งเตือนตาม burn rate (ความเร็วที่ใช้งบผิดพลาด) แทนที่จะแจ้งทุก spike ชั่วคราว รูปแบบที่ใช้บ่อยคือ:
เก็บชุดเริ่มต้นเล็กไว้ (2–4 SLO ต่อบริการ) แล้วขยายเมื่อทีมใช้งานจริง สำหรับพื้นฐาน ดู /blog/slo-monitoring-basics.
teamversion (เวอร์ชัน deploy หรือ git SHA)เพิ่ม tier (frontend, backend, data) ถ้าต้องการตัวกรองเพิ่มเติมที่ให้ผลเร็ว.
สำคัญคือทำให้สัญญาณเหล่านี้แชร์ context เดียวกัน (service/env/version/request ID) เพื่อให้การเชื่อมโยงรวดเร็ว.