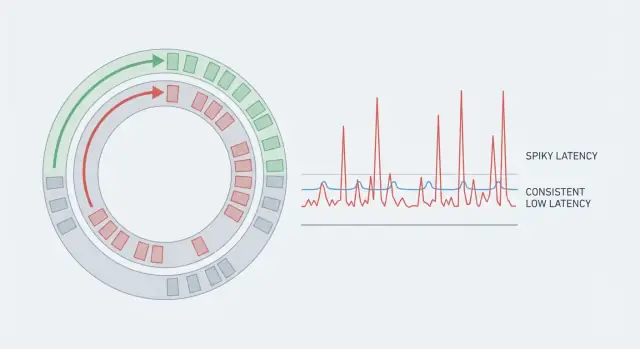
ทำไมแอปเรียลไทม์จึงรู้สึกช้าแม้โค้ดจะเร็ว\n\nความเร็วมีสองด้าน: throughput และ latency. Throughput คือจำนวนงานที่คุณทำได้ต่อวินาที (คำขอ ข้อความ เฟรม) ส่วน latency คือเวลาที่งานหนึ่งชิ้นใช้ตั้งแต่เริ่มจนเสร็จ\n\nระบบหนึ่งอาจมี throughput ดีแต่ยังรู้สึกช้าได้ถ้าบางคำขอใช้เวลานานกว่าคนอื่นๆ นั่นเป็นเหตุผลที่ค่าเฉลี่ยทำให้เข้าใจผิด ถ้า 99 งานใช้ 5 ms และงานหนึ่งใช้ 80 ms ค่าเฉลี่ยอาจดูโอเค แต่ผู้ใช้คนที่เจอเคส 80 ms จะรู้สึกถึงการกระตุก ในระบบเรียลไทม์ สไปก์เหล่านั้นคือเรื่องทั้งหมดเพราะมันทำลายจังหวะ\n\nความหน่วงที่คาดการณ์ได้ไม่ได้หมายถึงแค่หวังค่าเฉลี่ยต่ำ แต่หมายถึงความสม่ำเสมอ เพื่อให้การทำงานส่วนใหญ่จบภายในช่วงเวลาที่แคบ นั่นคือเหตุผลที่ทีมมักดูหาง (p95, p99) — จุดที่การหยุดชะงักซ่อนอยู่\n\nสไปก์ 50 ms อาจมีผลในด้านเสียงและวิดีโอ (เสียงกระตุก), เกมหลายผู้เล่น (rubber-banding), การเทรดแบบเรียลไทม์ (พลาดราคา), การมอนิเตอร์ในอุตสาหกรรม (สัญญาณเตือนช้า), และแดชบอร์ดสด (ตัวเลขกระโดด, การแจ้งเตือนไม่น่าเชื่อถือ)\n\nยกตัวอย่างง่ายๆ: แอปแชทอาจส่งข้อความได้เร็วเกือบทุกครั้ง แต่ถ้าการหยุดชะงักเบื้องหลังทำให้ข้อความหนึ่งมาช้ากว่า 60 ms ตัวบ่งชี้การพิมพ์จะกระพริบและบทสนทนาจะรู้สึกหน่วง แม้เซิร์ฟเวอร์จะดู “เร็ว” โดยค่าเฉลี่ย\n\nถ้าคุณอยากให้เรียลไทม์รู้สึกเป็นเรียลไทม์ คุณต้องมีสิ่งน้อยลงที่ทำให้ประหลาดใจ ไม่ใช่แค่โค้ดที่เร็วกว่า\n\n## พื้นฐานของความหน่วง: เวลาไปอยู่ที่ไหนจริงๆ\n\nระบบเรียลไทม์ส่วนใหญ่ไม่ช้าจากว่า CPU ทำงานไม่ทัน แต่รู้สึกช้าจากการที่งานใช้เวลาส่วนใหญ่ไปกับการรอ: รอการจัดตาราง, รอในคิว, รอเครือข่าย, หรือรอที่เก็บข้อมูล\n\nend-to-end latency คือเวลาทั้งหมดจาก “บางอย่างเกิดขึ้น” ถึง “ผู้ใช้เห็นผล” แม้ตัวจัดการของคุณจะทำงานใน 2 ms คำขอยังอาจใช้ 80 ms หากมันถูกพักรอในห้าจุดต่างกัน\n\nวิธีแบ่งเส้นทางที่เป็นประโยชน์คือ:\n\n- เวลาเครือข่าย (จากไคลเอนต์ถึง edge, บริการต่อบริการ, การลองใหม่)\n- เวลาในการจัดตาราง (เธรดของคุณรอเพื่อรัน)\n- เวลาในคิว (งานรอหลังงานอื่น)\n- เวลาในที่เก็บ (ดิสก์, ล็อกฐานข้อมูล, cache miss)\n- เวลาในการซีเรียไลซ์ (การเข้ารหัสและถอดรหัสข้อมูล)\n\nการรอเหล่านี้ทับถมกันได้ หลายมิลลิวินาทีในแต่ละจุดทำให้เส้นทางโค้ดที่ “เร็ว” กลายเป็นประสบการณ์ช้า\n\nหางความหน่วงคือที่ผู้ใช้เริ่มบ่น ค่าเฉลี่ยอาจดูดี แต่ p95 หรือ p99 คือคำขอช้าที่สุด 5% หรือ 1% ค่าที่เป็น outlier มักมาจากการหยุดชะงักที่หาได้ยาก: รอบ GC, เพื่อนบ้านเสียงดังบนโฮสต์, การแย่งล็อกสั้นๆ, การเติม cache หรือระเบิดที่สร้างคิว\n\nตัวอย่างชัดเจน: อัพเดตราคามาถึงทางเครือข่ายภายใน 5 ms รอ 10 ms เพราะ worker ยุ่ง, ใช้เวลา 15 ms รอหลังเหตุการณ์อื่น แล้วเจอการหยุดชะงักฐานข้อมูล 30 ms โค้ดยังรันใน 2 ms แต่ผู้ใช้รอรวม 62 ms เป้าหมายคือทำให้ทุกขั้นตอนคาดการณ์ได้ ไม่ใช่แค่การคำนวณให้เร็ว\n\n## แหล่งที่มาของจิตเตอร์นอกจากความเร็วโค้ด\n\nอัลกอริทึมที่เร็วยังรู้สึกช้าได้ถ้าค่าเวลาแต่ละคำขอผันผวน ผู้ใช้สังเกตการสไปก์ไม่ใช่ค่าเฉลี่ย การผันผวนนี้คือจิตเตอร์ และมักมาจากสิ่งที่โค้ดของคุณควบคุมได้ไม่เต็มที่\n\nแคชของ CPU และพฤติกรรมหน่วยความจำเป็นต้นทุนที่ซ่อนอยู่ ถ้าข้อมูลร้อนไม่พอดีในแคช CPU จะหยุดรอ RAM โครงสร้างที่มีวัตถุหนาจัด หน่วยความจำกระจัดกระจาย และ “การค้นหาอีกครั้ง” อาจกลายเป็น cache miss ซ้ำๆ\n\nการจัดสรรหน่วยความจำเพิ่มความสุ่มของตัวเอง การสร้างวัตถุอายุสั้นจำนวนมากเพิ่มแรงกดบน heap ซึ่งต่อมาจะแสดงเป็นการหยุดชะงัก (garbage collection) หรือการแย่งตัวจัดสรร แม้ไม่มี GC การจัดสรรบ่อยๆ ก็สามารถทำให้หน่วยความจำแตกชิ้นและทำให้ locality แย่ลง\n\nการจัดตารางเธรดเป็นสาเหตุทั่วไปอีกอย่าง เมื่อเธรดถูก deschedule คุณจ่ายค่า context switch และสูญเสียความร้อนแคช บนเครื่องที่มีงานหนาแน่น เธรด “เรียลไทม์” ของคุณอาจรอหลังงานที่ไม่เกี่ยวข้อง\n\nการแย่งล็อกคือจุดที่ระบบที่คาดการณ์ได้มักล่มสลาย ล็อกที่ “มักจะว่าง” อาจกลายเป็น convoy: เธรดตื่น แข่งขันล็อก และผลักกันกลับไปนอน งานยังเสร็จแต่หาง latency ยืดออก\n\nการรอ I/O สามารถกลบทุกอย่างได้ การเรียกระบบเดียว บัฟเฟอร์เครือข่ายเต็ม, การจับมือ TLS, การ flush ดิสก์, หรือการค้นหา DNS ช้าสามารถสร้างสไปก์แหลมที่ไม่นโยบายจิ๋วจะซ่อมได้\n\nหากคุณล่าจิตเตอร์ ให้เริ่มจากมองหา cache miss (มักเกิดจากโครงสร้างชี้เยอะและการเข้าถึงแบบสุ่ม), การจัดสรรบ่อย, context switch จากเธรดมากเกินไปหรือเพื่อนบ้านเสียงดัง, การแย่งล็อก และ I/O ที่บล็อกใดๆ (เครือข่าย ดิสก์ การล็อกบันทึก การเรียกซิงโครนัส)\n\nตัวอย่าง: บริการติ๊กเกอร์ราคาอาจคำนวณอัพเดตในไมโครวินาที แต่การเรียก logger แบบ synchronized หรือการแย่งล็อกเมตริกที่คับคั่งอาจเพิ่มเป็นสิบมิลลิวินาทีเป็นครั้งคราว\n\n## Martin Thompson และ Disruptor คืออะไร\n\nMartin Thompson เป็นที่รู้จักในวงการวิศวกรรมความหน่วงต่ำในด้านการให้ความสำคัญกับพฤติกรรมของระบบภายใต้ความกดดัน: ไม่ใช่แค่ความเร็วเฉลี่ย แต่ความเร็วที่คาดการณ์ได้ เขาและทีม LMAX ช่วยทำให้แพตเทิร์น Disruptor เป็นที่รู้จัก — วิธีอ้างอิงสำหรับขยับเหตุการณ์ผ่านระบบด้วยความหน่วงเล็กและคงที่\n\nแนวทาง Disruptor เกิดจากการตอบโจทย์สิ่งที่ทำให้แอปที่ “เร็ว” หลายตัวไม่คาดเดาได้: การแย่งและการประสานงาน คิวทั่วไปมักพึ่งล็อกหรืออะตอมหนัก ปลุกเธรดขึ้นลง และสร้างการรอเมื่อผู้ผลิตและผู้บริโภคแข่งกันบนโครงสร้างร่วม\n\nแทนที่จะใช้คิวแบบธรรมดา Disruptor ใช้วงแหวนบัฟเฟอร์: อาร์เรย์วงกลมขนาดคงที่ที่เก็บเหตุการณ์ในสล็อต ผู้ผลิตอ้างสิทธิ์สล็อตถัดไป เขียนข้อมูล แล้วเผยแพร่หมายเลขลำดับ ผู้บริโภคอ่านตามลำดับโดยติดตามลำดับนั้น เพราะบัฟเฟอร์ถูกจัดสรรล่วงหน้า คุณจึงหลีกเลี่ยงการจัดสรรบ่อยและลดแรงกดบน garbage collector\n\nแนวคิดหลักคือหลักการผู้เขียนคนเดียว: ให้ส่วนเดียวเป็นผู้รับผิดชอบสเตตที่แชร์ (เช่น cursor ที่ขยับผ่านวงแหวน) ผู้เขียนน้อยลงหมายถึงช่วงเวลาที่ต้องตัดสินใจว่า “ใครไปต่อ?” น้อยลง\n\nการควบคุมแรงดัน (backpressure) เป็นสิ่งที่ชัดเจน เมื่อผู้บริโภคล่าช้า ผู้ผลิตจะไปถึงสล็อตที่ยังถูกใช้งาน ในจุดนั้นระบบต้องรอ หย่อน หรือชะลอ แต่มันทำในทางที่ควบคุมได้และมองเห็นได้ แทนที่จะแอบซ่อนปัญหาไว้ในคิวที่ยาวขึ้นเรื่อยๆ\n\n## แนวคิดการออกแบบหลักที่รักษาความหน่วงให้คงที่\n\nสิ่งที่ทำให้การออกแบบสไตล์ Disruptor เร็วไม่ใช่ไมโคร-ออปติไมเซชัน แต่เป็นการเอาการหยุดชะงักที่ไม่คาดคิดออกเมื่อระบบต่อสู้กับองค์ประกอบของตัวเอง: การจัดสรร การเสียแคช การแย่งล็อก และงานช้าที่ผสมในเส้นทางร้อน\n\nโมเดลคิดที่มีประโยชน์คือสายการประกอบ เหตุการณ์เคลื่อนผ่านเส้นทางคงที่พร้อมการส่งมอบที่ชัดเจน สิ่งนี้ลดสเตตที่แชร์และทำให้แต่ละขั้นตอนง่ายต่อการเก็บให้เรียบง่ายและวัดผลได้\n\n### รักษาหน่วยความจำและข้อมูลให้คาดการณ์ได้\n\nระบบที่เร็วหลีกเลี่ยงการจัดสรรที่ทำให้ประหลาดใจ หากคุณจัดสรรบัฟเฟอร์ล่วงหน้าและนำวัตถุข้อความกลับมาใช้ใหม่ คุณจะลดสไปก์ที่เกิดจาก garbage collection, การเติบโตของ heap, และการแย่งตัวจัดสรร\n\nยังช่วยให้ข้อความเล็กและคงที่ด้วย เมื่อข้อมูลที่คุณแตะต่อเหตุการณ์พอดีในแคชของ CPU คุณจะใช้เวลารอน้อยลงจริงๆ\n\nในทางปฏิบัติ นิสัยที่สำคัญคือ: นำวัตถุกลับมาใช้แทนการสร้างใหม่ต่อเหตุการณ์ เก็บข้อมูลเหตุการณ์ให้กะทัดรัด ใช้ผู้เขียนคนเดียวสำหรับสเตตที่แชร์ และแบตช์อย่างระมัดระวังเพื่อจ่ายค่า coordination น้อยลงบ่อยครั้งกว่าแต่ละครั้ง\n\n### ทำให้เส้นทางช้าเห็นได้ชัด\n\nแอปเรียลไทม์มักต้องการสิ่งเสริมเช่น logging, metrics, retries, หรือการเขียนฐานข้อมูล แนวคิด Disruptor คือแยกสิ่งเหล่านี้ออกจากลูปหลักเพื่อที่พวกมันจะไม่บล็อกมัน\n\nในฟีดราคาสด เส้นทางร้อนอาจแค่ตรวจความถูกต้องของ tick และเผยแพร่ snapshot ราคาถัดไป อะไรก็ตามที่อาจชะงัก (ดิสก์, การเรียกเครือข่าย, การซีเรียไลซ์หนัก) ย้ายไปยังผู้บริโภคแยกหรือช่องทางข้างเคียง เพื่อให้เส้นทางที่คาดการณ์ได้ยังคงเป็นเส้นทางที่คาดการณ์ได้\n\n## ทางเลือกสถาปัตยกรรมเพื่อความหน่วงที่คาดการณ์ได้\n\nความหน่วงที่คาดการณ์ได้เป็นปัญหาส่วนใหญ่ของสถาปัตยกรรม คุณอาจมีโค้ดเร็วแต่ยังได้สไปก์ถ้าเธรดหลายตัวแข่งกันบนข้อมูลเดียว หรือข้อความเด้งข้ามเครือข่ายโดยไม่จำเป็น\n\nเริ่มจากการตัดสินใจว่ามีผู้เขียนและผู้อ่านกี่คนที่แตะคิวหรือบัฟเฟอร์เดียวกัน ผู้ผลิตเดี่ยวง่ายต่อการรักษาความราบรื่นเพราะหลีกเลี่ยงการประสานงาน การตั้งค่าผู้ผลิตหลายคนอาจเพิ่ม throughput แต่บ่อยครั้งเพิ่มการแย่งและทำให้เวลาแย่ที่สุดคาดเดาได้น้อยลง ถ้าคุณต้องการผู้ผลิตหลายคน ให้ลดการเขียนร่วมโดยการแบ่งชาร์ดเหตุการณ์ตามคีย์ (เช่น userId หรือ instrumentId) เพื่อให้แต่ละชาร์ดมีเส้นทางร้อนของตัวเอง\n\nด้านผู้บริโภค ผู้บริโภคเดี่ยวให้เวลาที่เสถียรที่สุดเมื่อการเรียงลำดับสำคัญ เพราะสเตตจะอยู่ท้องถิ่นต่อเธรดเดียว พูลงานช่วยได้เมื่องานเป็นอิสระจริงๆ แต่เพิ่มความล่าช้าในการจัดตารางและสามารถเปลี่ยนลำดับงานได้ถ้าคุณไม่ระวัง\n\nการแบตช์เป็นการแลกเปลี่ยนอีกแบบ หน่วยเล็กๆ ลด overhead (ปลุกน้อยลง, cache miss น้อยลง) แต่การแบตช์อาจเพิ่มการรอถ้าคุณถือเหตุการณ์เพื่อเติมชุด ถ้าแบตช์ในระบบเรียลไทม์ ให้จำกัดเวลารอ (เช่น “สูงสุด 16 เหตุการณ์หรือ 200 ไมโครวินาที ใดมาก่อน”)\n\nขอบเขตของบริการก็สำคัญ การส่งข้อความในกระบวนการเดียวมักดีที่สุดเมื่อคุณต้องการความหน่วงแน่น การกระโดดผ่านเครือข่ายอาจคุ้มค่าสำหรับการสเกล แต่แต่ละ hop เพิ่มคิว การลองใหม่ และความล่าช้าที่ผันผวน ถ้าคุณต้องมีการกระโดด ให้เก็บโปรโตคอลให้เรียบง่ายและหลีกเลี่ยง fan-out ในเส้นทางร้อน\n\nชุดกฎปฏิบัติ: เก็บเส้นทางผู้เขียนคนเดียวต่อชาร์ดเมื่อทำได้, ขยายด้วยการแบ่งชาร์ดคีย์แทนการแชร์คิวร้อนเดียว, แบตช์เฉพาะเมื่อมีการจำกัดเวลาเข้มงวด, เพิ่มพูลงานเฉพาะเมื่องานขนานได้จริง, และถือว่าทุกการกระโดดเครือข่ายเป็นแหล่งจิตเตอร์จนกว่าคุณจะวัดมันได้\n\n## ขั้นตอนทีละขั้น: ออกแบบพายไลน์ที่ jitter ต่ำ\n\nเริ่มด้วยงบความหน่วงเป็นตัวเขียนก่อนแตะโค้ด เลือกเป้าหมาย (สิ่งที่รู้สึกว่า “ดี”) และ p99 (สิ่งที่ต้องอยู่ต่ำกว่า) แบ่งตัวเลขนั้นข้ามขั้นตอนเช่นการรับเข้า การตรวจความถูกต้อง การจับคู่ การเก็บถาวร และการอัปเดตออกไป หากขั้นตอนใดไม่มีงบ มันก็ไม่มีขอบเขต\n\nถัดไป วาดการไหลข้อมูลเต็มรูปแบบและมาร์กทุกการส่งต่อ: พรมแดนเธรด, คิว, การกระโดดเครือข่าย, และการเรียกที่เก็บ ทุกการส่งต่อคือที่ซ่อนจิตเตอร์ เมื่อคุณเห็นมัน คุณจะลดมันได้\n\nเวิร์กโฟลว์ที่ช่วยให้การออกแบบตรงไปตรงมามีดังนี้:\n\n- เขียนงบต่อขั้นตอน (เป้าหมายและ p99) พร้อมบัฟเฟอร์เล็กๆ สำหรับสิ่งไม่คาดคิด\n- แมปพายไลน์และติดป้ายคิว ล็อก การจัดสรร และการเรียกที่บล็อก\n- เลือกรูปแบบความขนานที่คุณวิเคราะห์ได้ (ผู้เขียนเดี่ยว, แบ่งชาร์ดโดยคีย์, หรือเธรด I/O เฉพาะ)\n- กำหนดรูปร่างข้อความตั้งแต่ต้น: สคีมาที่คงที่, เพย์โหลดกะทัดรัด, และการคัดลอกน้อยที่สุด\n- ตัดสินกฎ backpressure ล่วงหน้า: drop, delay, degrade, หรือ shed load ทำให้มองเห็นได้และวัดได้\n\nจากนั้นตัดสินใจว่าอะไรสามารถเป็นอะซิงโครนัสโดยไม่ทำลายประสบการณ์ผู้ใช้ กฎง่ายๆ: อะไรก็ตามที่เปลี่ยนสิ่งที่ผู้ใช้เห็น "ตอนนี้" ให้คงบนเส้นทางวิกฤต ทุกอย่างอื่นย้ายออก\n\nการวิเคราะห์, บันทึก audit, และดัชนีรองมักปลอดภัยที่จะย้ายออกจากเส้นทางร้อน ขณะที่การตรวจความถูกต้อง การเรียงลำดับ และขั้นตอนที่ต้องใช้เพื่อผลิตสถานะถัดไปมักไม่สามารถย้ายได้\n\n## ตัวเลือก runtime และ OS ที่มีผลต่อหาง latency\n\nโค้ดเร็วอาจยังรู้สึกช้าเมื่อ runtime หรือ OS หยุดงานของคุณในช่วงเวลาที่ไม่เหมาะ เป้าหมายไม่ใช่แค่ throughput สูง แต่เป็นการลดความประหลาดใจใน 1% ช้าที่สุด\n\n runtime ที่มี garbage collection (JVM, Go, .NET) ดีด้านผลิตภาพ แต่สามารถสร้างการหยุดชะงักเมื่อหน่วยความจำต้องทำความสะอาด ตัวเก็บขยะสมัยใหม่ดีขึ้นมากแล้ว แต่หาง latency ยังอาจกระโดดถ้าคุณสร้างวัตถุอายุสั้นจำนวนมากภายใต้โหลด ภาษาไม่มี GC (Rust, C, C++) หลีกเลี่ยงการหยุด GC แต่ผลของมันย้ายไปสู่การจัดการเจ้าของและวินัยการจัดสรร แพทเทิร์นหน่วยความจำสำคัญพอๆ กับความเร็ว CPU\n\nนิสัยปฏิบัติ: หาแหล่งที่การจัดสรรเกิดขึ้นแล้วทำให้มันน่าเบื่อ นำวัตถุกลับมาใช้ ขนาดบัฟเฟอร์ล่วงหน้า และหลีกเลี่ยงการเปลี่ยนข้อมูลร้อนเป็นสตริงหรือแผนที่ชั่วคราว\n\nการเลือกเธรดก็แสดงอาการเป็นจิตเตอร์ ทุกคิวพิเศษ การกระโดด async หรือการส่งต่อพูลเธรดเพิ่มการรอและความแปรปรวน เลือกจำนวนเธรดน้อยและมีอายุยาว เก็บขอบเขตผู้ผลิต-ผู้บริโภคชัดเจน และหลีกเลี่ยงการเรียกที่บล็อกบนเส้นทางร้อน\n\nการตั้งค่า OS และคอนเทนเนอร์บางอย่างมักตัดสินว่าหางของคุณสะอาดหรือเป็นสไปก์ การจำกัด CPU แน่น เงื่อนไขเพื่อนบ้านเสียงดังบนโฮสต์ที่แชร์ และ logging/metrics ที่วางไม่ดีสามารถสร้างความช้าขึ้นทันที หากเปลี่ยนอย่างเดียว ให้เริ่มด้วยการวัดอัตราการจัดสรรและ context switch ระหว่างที่เกิดสไปก์ของ latency\n\n## ข้อมูล ที่เก็บ และพรมแดนบริการโดยไม่มีการหยุดชะงักที่ไม่คาดคิด\n\nหลายสไปก์ไม่ใช่ "โค้ดช้า" แต่เป็นการรอที่คุณไม่ได้วางแผนไว้: ล็อกฐานข้อมูล, พายุการลองใหม่, การเรียกข้ามบริการที่ติดค้าง, หรือ cache miss ที่กลายเป็นรอบเต็ม\n\nเก็บเส้นทางวิกฤตให้สั้น ทุกการกระโดดเพิ่มการจัดตาราง การซีเรียไลซ์ คิวเน็ตเวิร์ก และที่ซ่อนการบล็อก หากคุณตอบคำขอจากกระบวนการเดียวและที่เก็บข้อมูลเดียวได้ ให้ทำแบบนั้นก่อน แยกเป็นบริการมากขึ้นเมื่อแต่ละการเรียกเป็นทางเลือกหรือมีขอบเขตที่เข้มงวด\n\nการรอแบบมีขอบเขตคือความแตกต่างระหว่างค่าเฉลี่ยที่เร็วและความหน่วงที่คาดการณ์ได้ ตั้ง timeout อย่างเข้มงวดในการเรียกระยะไกล และล้มเหลวอย่างรวดเร็วเมื่อ dependency ไม่สมบูรณ์ ตัวตัดวงจร (circuit breakers) ไม่ใช่แค่ปกป้องเซิร์ฟเวอร์ แต่จำกัดเวลาที่ผู้ใช้จะต้องติดค้าง\n\nเมื่อการเข้าถึงข้อมูลบล็อก ให้แยกเส้นทาง การอ่านมักอยากได้รูปแบบที่ indexed, denormalized, และเป็นมิตรกับ cache การเขียนอยากได้ความทนทานและการเรียงลำดับ การแยกพวกนี้สามารถลดการแย่งและลดเวลาล็อก หากความต้องการความสอดคล้องของคุณยอมได้ บันทึกแบบ append-only (log เหตุการณ์) มักคาดการณ์พฤติกรรมได้ดีกว่าการอัพเดตในที่ซึ่งกระตุ้น hot-row locking หรืองานซ่อมเบื้องหลัง\n\nกฎง่ายๆ สำหรับแอปเรียลไทม์: การยืนยันข้อมูลไม่ควรอยู่บนเส้นทางวิกฤตเว้นแต่คุณจำเป็นต้องใช้เพื่อความถูกต้อง รูปแบบที่ดีมักเป็น: อัพเดตในหน่วยความจำ, ตอบกลับ, แล้ว persist แบบอะซิงโครนัสพร้อมกลไก replay (เช่น outbox หรือ write-ahead log)\n\nในพายไลน์วงแหวนบัฟเฟอร์ทั่วไป สิ่งนี้จบลงเป็น: เผยแพร่ไปยังบัฟเฟอร์ในหน่วยความจำ, อัพเดตสเตต, ตอบกลับ, แล้วให้ผู้บริโภคแยกแบตช์การเขียนไปยัง PostgreSQL\n\n## ตัวอย่างเป็นจริง: อัพเดตเรียลไทม์ที่คาดการณ์ได้\n\nลองนึกภาพแอปทำงานร่วมกันแบบสด (หรือเกมมัลติเพลเยอร์เล็กๆ) ที่ผลักอัพเดตทุก 16 ms (ประมาณ 60 ครั้งต่อวินาที) เป้าหมายไม่ใช่ “เร็วโดยเฉลี่ย” แต่เป็น “มักจะต่ำกว่า 16 ms” แม้เมื่อการเชื่อมต่อของผู้ใช้บางคนแย่\n\nพายไลน์สไตล์ Disruptor แบบง่ายๆ เป็นดังนี้: อินพุตผู้ใช้กลายเป็นเหตุการณ์ขนาดเล็ก เผยแพร่ลงในวงแหวนบัฟเฟอร์ที่จัดสรรล่วงหน้า แล้วประมวลผลโดยชุด handler คงที่ตามลำดับ (validate -> apply -> prepare outbound messages) และสุดท้ายกระจายไปยังไคลเอนต์\n\nการแบตช์ช่วยที่ขอบได้ เช่น แบตช์การเขียนออกสำหรับไคลเอนต์ต่อคนในแต่ละ tick เพื่อลดการเรียกเลเยอร์เครือข่าย แต่อย่าแบตช์ภายในเส้นทางร้อนแบบที่รอ “อีกหน่อย” เพื่อรอเหตุการณ์เพิ่ม การรอคือสาเหตุที่คุณพลาด tick\n\nเมื่อบางอย่างช้าลง ให้จัดการเป็นปัญหาการกักกัน หาก handler ใดช้าลง แยกมันไว้หลังบัฟเฟอร์ของตัวเองและเผยแพร่รายการงานน้ำหนักเบาแทนการบล็อกลูปหลัก หากไคลเอนต์ใดช้า อย่าให้มันสำรองตัวกระจาย; ให้แต่ละไคลเอนต์มีคิวส่งขนาดเล็กและทิ้งหรือรวมอัพเดตเก่าเพื่อให้ได้สถานะล่าสุด หากความลึกบัฟเฟอร์เพิ่มขึ้น ให้ใช้ backpressure ที่ขอบ (หยุดรับอินพุตเพิ่มสำหรับ tick นั้น หรือถอดฟีเจอร์บางอย่างออก)\n\nคุณจะรู้ว่ามันทำงานเมื่อค่าตัวเลขน่าเบื่อ: ความลึกคอยด์เฉลี่ยใกล้ศูนย์ เหตุการณ์ที่ทิ้ง/รวมหายากและอธิบายได้ และ p99 อยู่ต่ำกว่างบ tick ในภาระงานสมจริง\n\n## ความผิดพลาดที่พบบ่อยซึ่งสร้างสไปก์ความหน่วง\n\nสไปก์ส่วนใหญ่เกิดจากตัวเราเอง โค้ดอาจเร็ว แต่ระบบยังหยุดชะงักเมื่อรอเธรดอื่น OS หรืออะไรที่อยู่นอกแคช CPU\n\nข้อผิดพลาดที่มักเจอคือ:\n\n- ใช้ล็อกแชร์ทั่วเพราะรู้สึกเรียบง่าย หนึ่งล็อกที่แย่งกันอาจทำให้หลายคำขอหยุดชะงัก\n- ผสม I/O ช้าบนเส้นทางร้อน เช่น logging ซิงโครนัส, เขียนฐานข้อมูล, หรือการเรียกระยะไกล\n- เก็บคิวไม่จำกัด พวกมันซ่อนการโอเวอร์โหลดจนคุณมีแบ็คล็อกเป็นวินาที\n- ดูแต่ค่าเฉลี่ยแทน p95 และ p99\n- ปรับแต่งมากเกินไปเร็วเกินไป การปักเธรดจะไม่ช่วยถ้าการหน่วงมาจาก GC, การแย่ง, หรือการรอซ็อกเก็ต\n\nวิธีด่วนเพื่อลดสไปก์คือทำให้การรอเห็นได้และมีขอบเขต ย้ายงานช้าที่สุดไปเส้นทางแยก จำกัดคิว และตัดสินใจว่าจะทำอย่างไรเมื่อเต็ม (ทิ้ง ลดฟีเจอร์ หรือให้ backpressure)\n\n## เช็คลิสต์ด่วนสำหรับความหน่วงที่คาดการณ์ได้\n\nมองความหน่วงที่คาดการณ์ได้เหมือนฟีเจอร์ของผลิตภัณฑ์ ไม่ใช่อุบัติเหตุ ก่อนจูนโค้ด ให้แน่ใจว่าระบบมีเป้าหมายและแนวป้องกันชัดเจน\n\n- ตั้งเป้า p99 ชัดเจน (และ p99.9 ถ้าจำเป็น) แล้วเขียนงบความหน่วงต่อขั้นตอน\n- เก็บเส้นทางร้อนให้ปราศจาก I/O ที่บล็อก หากต้องมี I/O ให้ย้ายออกและกำหนดพฤติกรรมเมื่อมันช้าลง\n- ใช้คิวที่มีขอบเขตและกำหนดพฤติกรรมเมื่อโอเวอร์โหลด (drop, shed load, coalesce, หรือ backpressure)\n- วัดอย่างต่อเนื่อง: ความลึกคิว เวลาต่อขั้น และหางของ latency\n- ลดการจัดสรรในลูปร้อนและทำให้มองเห็นได้ง่ายในโปรไฟล์\n\nการทดสอบง่ายๆ: จำลองการระเบิด (บัฟเฟิล 10 เท่าจากปกติเป็นเวลา 30 วินาที) หาก p99 พุ่ง ถามว่าการรอเกิดที่ไหน: คิวโตขึ้น, ผู้บริโภคช้า, รอบ GC, หรือทรัพยากรแชร์ที่ถูกบล็อก\n\n## ขั้นตอนถัดไป: นำไปใช้ในแอปของคุณ\n\nมองแพตเทิร์น Disruptor เป็นเวิร์กโฟลว์ ไม่ใช่แค่ตัวเลือกไลบรารี พิสูจน์ความหน่วงที่คาดการณ์ได้ด้วยชิ้นบางก่อนเพิ่มฟีเจอร์\n\nเลือกการกระทำของผู้ใช้หนึ่งอย่างที่ต้องรู้สึกทันที (เช่น “ราคามาใหม่ UI อัพเดต”) เขียนงบ end-to-end แล้ววัด p50, p95 และ p99 ตั้งแต่วันแรก\n\nลำดับที่มักได้ผล:\n\n- สร้างพายไลน์บางๆ หนึ่งอินพุต หนึ่งลูปหลัก หนึ่งเอาต์พุต วัด p99 ภายใต้โหลดเร็วๆ\n- กำหนดความรับผิดชอบชัด (ใครเป็นเจ้าของสเตต ใครเผยแพร่ ใครบริโภค) และเก็บสเตตที่แชร์ให้เล็ก\n- เพิ่มความขนานและการบัฟเฟอร์ทีละเล็กทีละน้อย และทำให้เปลี่ยนกลับได้\n- ปรับใช้ใกล้ผู้ใช้เมื่องบแน่น แล้ววัดซ้ำภายใต้โหลดสมจริง (ขนาดเพย์โหลดเดียวกัน รูปแบบระเบิดเดียวกัน)\n\nถ้าคุณสร้างบน Koder.ai (koder.ai) มันช่วยได้ถ้าร่างการไหลเหตุการณ์ก่อนในโหมด Planning เพื่อให้คิว ล็อก และพรมแดนบริการไม่ปรากฏขึ้นโดยบังเอิญ Snapshot และ rollback ยังทำให้รันการทดลองความหน่วงซ้ำๆ และย้อนกลับการเปลี่ยนที่เพิ่ม throughput แต่ทำให้ p99 แย่ลงได้ง่ายขึ้น\n\nรักษาการวัดให้ตรงไปตรงมา ใช้สคริปต์ทดสอบคงที่ อุ่นระบบ แล้วบันทึกทั้ง throughput และ latency เมื่อ p99 กระโดดภายใต้โหลด อย่าเริ่มจากการ “ออปติไมซ์โค้ด” ก่อน ให้มองหาการหยุดชะงักจาก GC, เพื่อนบ้านเสียงดัง, การระเบิดของ logging, การจัดตารางเธรด, หรือการเรียกที่บล็อกซ่อนเร้น