27 ก.ค. 2568·3 นาที
เมื่อภาษา ฐานข้อมูล และเฟรมเวิร์กทำงานเป็นระบบเดียว
เรียนรู้ว่าภาษา ฐานข้อมูล และเฟรมเวิร์กทำงานร่วมกันอย่างไร — เปรียบเทียบข้อแลกเปลี่ยน จุดเชื่อมต่อ และแนวทางปฏิบัติในการเลือกชุดเทคโนโลยีที่สอดคล้องกัน
เรียนรู้ว่าภาษา ฐานข้อมูล และเฟรมเวิร์กทำงานร่วมกันอย่างไร — เปรียบเทียบข้อแลกเปลี่ยน จุดเชื่อมต่อ และแนวทางปฏิบัติในการเลือกชุดเทคโนโลยีที่สอดคล้องกัน
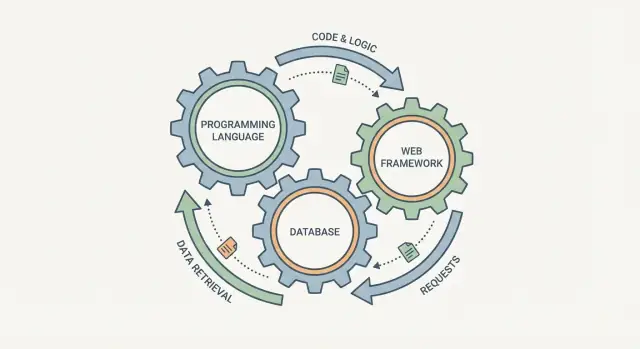
มันน่าดึงดูดที่จะเลือกภาษาโปรแกรม ฐานข้อมูล และเว็บเฟรมเวิร์กเป็นสามช่องทำเครื่องหมายแยกกัน แต่ในทางปฏิบัติพวกมันทำงานเหมือนเฟืองที่เชื่อมต่อกัน: เปลี่ยนชิ้นหนึ่ง ชิ้นอื่นก็รู้สึกได้
เฟรมเวิร์กเว็บกำหนดรูปร่างของการจัดการคำขอ วิธีการตรวจสอบข้อมูล และการแสดงข้อผิดพลาด ฐานข้อมูลกำหนดว่า "เก็บได้ง่าย" เป็นอย่างไร วิธีการคิวรีข้อมูล และการรับประกันเมื่อผู้ใช้หลายคนทำงานพร้อมกัน ส่วนภาษานั่งอยู่ตรงกลาง: มันกำหนดว่าคุณแสดงกฎได้ปลอดภัยแค่ไหน คุณจัดการความขนานอย่างไร และไลบรารีกับเครื่องมือที่ทีมคุณพึ่งพาได้มีอะไรบ้าง
การมองสแตกเป็นระบบเดียวหมายความว่าคุณไม่ปรับจูนแต่ละส่วนแยกกัน แต่เลือกชุดที่:
บทความนี้เน้นความปฏิบัติและตั้งใจไม่ลงลึกทางเทคนิค คุณไม่ต้องท่องทฤษฎีฐานข้อมูลหรือโครงสร้างภายในของภาษา—แค่มองเห็นว่าการเลือกหนึ่งอย่างมีผลกระทบอย่างไรทั่วทั้งแอป
ตัวอย่างสั้น ๆ: การใช้ฐานข้อมูลแบบไม่มีกฎสคีมาในโดเมนข้อมูลธุรกิจที่มีโครงสร้างชัดเจนและต้องรายงานหนัก มักนำไปสู่ "กฎ" กระจัดกระจายในโค้ดแอปและการวิเคราะห์ที่สับสนในภายหลัง ทางเลือกที่ดีกว่าคือใช้ฐานข้อมูลเชิงสัมพันธ์และเฟรมเวิร์กที่ส่งเสริมการตรวจสอบอย่างสม่ำเสมอและมิเกรชัน เพื่อให้ข้อมูลของคุณคงความสอดคล้องเมื่อผลิตภัณฑ์เติบโต
เมื่อคุณวางแผนสแตกพร้อมกัน คุณกำลังออกแบบชุดข้อแลกเปลี่ยนเดียว—ไม่ใช่การเดิมพันแยกสามครั้ง
วิธีคิดที่ช่วยได้คือมองสแตกเป็นท่อเดียว: คำขอผู้ใช้เข้า ระบบ และผลลัพธ์ (พร้อมข้อมูลที่บันทึก) ออก ภาษาที่คุณใช้ เฟรมเวิร์กเว็บ และฐานข้อมูลไม่ใช่การเลือกอิสระ—แต่เป็นสามส่วนของการเดินทางเดียวกัน
ลองนึกภาพลูกค้าปรับที่อยู่จัดส่ง
/account/address). Validation ตรวจสอบว่าข้อมูลครบถ้วนและสมเหตุสมผลเมื่อทั้งสามสอดคล้อง คำขอจะไหลอย่างราบรื่น เมื่อไม่สอดคล้อง คุณจะเจอแรงเสียดทาน: การเข้าถึงข้อมูลลำบาก การตรวจสอบที่รั่วไหล และบั๊กความสอดคล้องที่ซับซ้อน
การถกเถียงเรื่องสแตกมักเริ่มจากแบรนด์ภาษา หรือฐานข้อมูล จุดเริ่มต้นที่ดีกว่าคือโมเดลข้อมูลของคุณ—เพราะมันเป็นตัวกำหนดเงียบ ๆ ว่าสิ่งใดจะรู้สึกเป็นธรรมชาติ (หรือเจ็บปวด) ในทุกส่วน: validation, คิวรี, API, มิเกรชัน และแม้แต่เวิร์กโฟลว์ทีม
แอปมักจัดการสี่รูปแบบพร้อมกัน:
การจับคู่ที่ดีคือเมื่อคุณไม่ต้องแปลรูปแบบเหล่านี้ตลอดเวลา ถ้าข้อมูลหลักของคุณเชื่อมโยงกันมาก (ผู้ใช้ ↔ คำสั่ง ↔ สินค้า) แถวและ join จะทำให้ตรรกะเรียบง่าย ถ้าข้อมูลของคุณเป็น “ก้อนเดียวต่อเอนทิตี” ที่มีฟิลด์เปลี่ยนแปลง เอกสารจะลดความยุ่งยาก—จนกว่าความต้องการรายงานข้ามเอนทิตีจะเพิ่มขึ้น
เมื่อฐานข้อมูลมีสคีมาเข้มข้น หลายกฎสามารถอยู่ใกล้ข้อมูล: ชนิดข้อมูล ข้อจำกัด foreign key ความเป็นเอกลักษณ์ นั่นมักลดการตรวจสอบซ้ำระหว่างบริการ
กับโครงสร้างยืดหยุ่น กฎจะเลื่อนไปสู่แอป: โค้ด validation, payload เวอร์ชัน, backfill, และตรรกะการอ่านที่ระมัดระวัง (“ถ้ามีฟิลด์นี้ ให้...”). วิธีนี้เหมาะเมื่อ requirement เปลี่ยนเร็ว แต่มันเพิ่มภาระให้เฟรมเวิร์กและการทดสอบ
โมเดลของคุณจะกำหนดว่าโค้ดส่วนใหญ่จะเป็นแบบ:
นั่นจะส่งผลต่อความต้องการของภาษาและเฟรมเวิร์ก: การพิมพ์เข้มข้นช่วยป้องกันการเบี่ยงของฟิลด์ JSON ขณะที่เครื่องมือมิเกรชันที่โตเต็มที่จะสำคัญเมื่อสคีมาเปลี่ยนบ่อย
เลือกโมเดลก่อน; ตัวเลือกเฟรมเวิร์กและฐานข้อมูลที่ “ใช่” มักชัดเจนขึ้นหลังจากนั้น
ทรานแซคชันคือการรับประกัน "ทั้งหมดหรือไม่มีเลย" ที่แอปของคุณพึ่งพาแบบเงียบ ๆ เมื่อการชำระเงินสำเร็จ คุณคาดหวังว่าบันทึกคำสั่ง สถานะการชำระเงิน และการอัปเดตสต็อกจะเกิดขึ้นทั้งหมด—หรือไม่เกิดเลย หากไม่มีคำมั่นนี้ คุณจะเจอบั๊กชนิดที่ยากที่สุด: เกิดไม่บ่อย แพง และจำลองยาก
ทรานแซคชันรวมการดำเนินการหลายอย่างบนฐานข้อมูลเป็นหน่วยเดียวของงาน หากมีสิ่งใดผิดพลาดกลางคัน (ข้อผิดพลาด validation, timeout, กระบวนการล่ม) ฐานข้อมูลสามารถม้วนกลับไปยังสถานะที่ปลอดภัยก่อนหน้าได้
สิ่งนี้สำคัญไม่ใช่แค่กับเงิน: การสร้างบัญชี (แถวผู้ใช้ + แถวโปรไฟล์), การเผยแพร่เนื้อหา (โพสต์ + แท็ก + ตัวชี้ดัชนีค้นหา), หรืองานใด ๆ ที่แตะมากกว่าหนึ่งตาราง
ความสอดคล้องหมายถึง “การอ่านตรงกับความเป็นจริง” ความเร็วหมายถึง “ส่งกลับอะไรเร็ว ๆ” หลายระบบแลกเปลี่ยนสองสิ่งนี้:
รูปแบบความล้มเหลวที่พบบ่อยคือเลือกสถาปัตยกรรม eventual แต่โค้ดยังเขียนราวกับว่าเป็น strong consistency
เฟรมเวิร์กและ ORM ไม่ได้สร้างทรานแซคชันให้โดยอัตโนมัติเพียงเพราะคุณเรียกหลายครั้งที่เป็น "save" บางตัวต้องบล็อกทรานแซคชันอย่างชัดเจน; บางตัวเริ่มทรานแซคชันต่อคำขอ ซึ่งอาจซ่อนปัญหาประสิทธิภาพ
การ retry ก็ซับซ้อน: ORM อาจ retry ใน deadlock หรือความล้มเหลวชั่วคราว แต่โค้ดของคุณต้องปลอดภัยเมื่อนำไปรันซ้ำ
การเขียนบางส่วนเกิดขึ้นเมื่อคุณอัปเดต A แล้วล้มเหลวก่อนอัปเดต B การทำงานซ้ำซ้อนเกิดเมื่อคำขอถูก retry หลัง timeout—โดยเฉพาะถ้าคุณเก็บเงินหรือส่งอีเมลก่อนทรานแซคชัน commit
กฎง่าย ๆ ที่ช่วยได้: ให้ side effects (อีเมล, webhook) เกิด หลัง commit ของฐานข้อมูล และออกแบบการกระทำให้ idempotent โดยใช้ข้อจำกัดความเป็นเอกลักษณ์หรือ idempotency keys
นี่คือ “เลเยอร์แปลความ” ระหว่างโค้ดแอปและฐานข้อมูล การเลือกที่นี่มักสำคัญมากในงานประจำวันกว่าตัวแบรนด์ฐานข้อมูลเอง
ORM (Object-Relational Mapper) ให้คุณทำกับตารางเหมือนอ็อบเจ็กต์: สร้าง User, อัปเดต Post, และ ORM สร้าง SQL ให้เบื้องหลัง มันเพิ่มผลผลิตเพราะเป็นมาตรฐานงานทั่วไปและซ่อนปลั๊กอินที่ซ้ำซาก
Query builder ชัดเจนกว่า: คุณสร้างคำสั่งที่คล้าย SQL ด้วยโค้ด (chain หรือฟังก์ชัน). คุณยังคิดเป็น "join, filter, group" แต่ได้ความปลอดภัยพารามิเตอร์และความประกอบได้
Raw SQL คือเขียน SQL จริง ๆ ด้วยตัวเอง ชัดเจนที่สุดสำหรับรายงานซับซ้อน—แต่ต้องทำงานด้วยมือและออกแบบข้อตกลงให้ดี
ภาษาที่มีการพิมพ์เข้มข้น (TypeScript, Kotlin, Rust) มักผลักดันให้คุณใช้เครื่องมือที่สามารถตรวจสอบคำสั่งและรูปทรงผลลัพธ์ตั้งแต่ต้น นั่นลดปัญหาเวลารัน แต่ก็กดดันทีมให้รวมเลเยอร์เข้าถึงข้อมูลกลาง ๆ
ภาษาที่เมตาพร็อกกรามยืดหยุ่น (Ruby, Python) มักทำให้ ORM รู้สึกเป็นธรรมชาติและเร็วในการทดลอง—จนกว่าคำสั่งลับ ๆ หรือลักษณะพฤติกรรมแฝงจะยากจะเข้าใจ
มิเกรชันคือสคริปต์เปลี่ยนแปลงเวอร์ชันของสคีมา: เพิ่มคอลัมน์ สร้างดัชนี backfill ข้อมูล เป้าหมายคือใครก็ deploy แอปแล้วได้โครงสร้างฐานข้อมูลเหมือนกัน จงปฏิบัติต่อมิเกรชันเหมือนโค้ดที่ต้อง review ทดสอบ และ rollback ได้เมื่อจำเป็น
ORM อาจสร้าง N+1 queries โดยเงียบ ๆ, ดึงแถวมหาศาลที่คุณไม่ต้องการ, หรือทำให้ join ยาก Query builder อาจกลายเป็น chain ที่อ่านไม่รู้เรื่อง Raw SQL อาจซ้ำและไม่สอดคล้อง
กฎที่ดี: ใช้เครื่องมือที่ง่ายที่สุดที่ยังทำให้เจตนาเห็นได้ชัด—และสำหรับเส้นทางวิกฤต ให้ตรวจสอบ SQL ที่รันจริงเสมอ
คนมักโทษ "ฐานข้อมูล" เมื่อหน้าเว็บช้าจริง ๆ แต่ความหน่วงที่ผู้ใช้เห็นส่วนใหญ่เป็นผลรวมของการรอเล็ก ๆ หลายช่วงตลอดเส้นทางคำขอ
คำขอหนึ่งครั้งมักจ่ายค่า:
แม้ DB ตอบใน 5 ms ถ้าแอปทำ 20 คิวรีต่อคำขอ บล็อก I/O และใช้ 30 ms ในการซีเรียไลซ์คำตอบขนาดใหญ่ หน้าก็ยังรู้สึกช้า
การเปิด connection ใหม่มีต้นทุนสูงและอาจท่วม DB เมื่อโหลดสูง connection pool ช่วยนำ connection ที่มีมาใช้ใหม่เพื่อไม่ให้คำขอต้องจ่ายค่าตั้งต้นซ้ำ ๆ
ข้อจำกัด: ขนาดพูลที่ “เหมาะสม” ขึ้นกับโมเดล runtime ของคุณ เซิร์ฟเวอร์ async ที่มี concurrency สูงอาจเรียกร้อง connection จำนวนมาก; หากไม่จำกัดพูลจะเกิดการคิวและ timeout แต่ถ้าจำกัดแน่นเกินไป แอปจะกลายเป็นคอขวด
แคชสามารถอยู่ที่เบราว์เซอร์, CDN, แคชในโปรเซส, หรือแคชแชร์ (เช่น Redis). มันช่วยเมื่อคำขอจำนวนมากต้องการผลลัพธ์ เดียวกัน
แต่แคชไม่ช่วยเรื่อง:
Runtime ของภาษากำหนด throughput โมเดล thread-per-request อาจเสียทรัพยากรขณะรอ I/O; โมเดล async เพิ่ม concurrency แต่ทำให้ backpressure (เช่น ขีดจำกัดพูล) เป็นสิ่งสำคัญ เหตุนี้การปรับจูนประสิทธิภาพจึงเป็นการตัดสินใจร่วมของสแตก ไม่ใช่ปัญหาของฐานข้อมูลเพียงอย่างเดียว
ความปลอดภัยไม่ใช่สิ่งที่คุณ "เพิ่ม" ด้วยปลั๊กอินเฟรมเวิร์กหรือการตั้งค่าฐานข้อมูล มันเป็นข้อตกลงระหว่าง runtime/ภาษา เฟรมเวิร์กเว็บ และฐานข้อมูลเกี่ยวกับสิ่งที่ต้องเป็นจริงเสมอ—แม้เมื่อมีนักพัฒนาทำผิดหรือเพิ่ม endpoint ใหม่
การพิสูจน์ตัวตน (ใครคือผู้ใช้?) ปกติอยู่ที่ขอบของเฟรมเวิร์ก: sessions, JWT, OAuth callbacks, middleware. การอนุญาต (ทำอะไรได้บ้าง?) ต้องบังคับใช้อย่างสม่ำเสมอทั้งในตรรกะแอปและกฎข้อมูล
รูปแบบที่พบบ่อย: แอปตัดสินใจเจตนา (“ผู้ใช้แก้ไขโปรเจกต์นี้ได้ไหม”) และฐานข้อมูลบังคับขอบเขต (tenant IDs, ownership constraints, และถ้าสมเหตุสมผล row-level policies). ถ้าการอนุญาตมีเพียงใน controller งาน background และสคริปต์ภายในอาจหลุดผ่านได้โดยไม่ตั้งใจ
การตรวจสอบในเฟรมเวิร์กให้ฟีดแบ็กเร็วและข้อความชัดเจน ข้อจำกัดในฐานข้อมูลให้ตาข่ายนิรภัยสุดท้าย
ใช้ทั้งสองเมื่อสำคัญ:
CHECK constraints, NOT NULLวิธีนี้ลด "สถานะที่เป็นไปไม่ได้" ที่เกิดเมื่อคำขอแข่งกันหรือบริการใหม่เขียนข้อมูลต่างออกไป
ความลับควรถูกจัดการโดย runtime และเวิร์กโฟลว์การปรับใช้ (env vars, secret managers), ไม่ควรฝังในโค้ดหรือมิเกรชัน การเข้ารหัสอาจเกิดในแอป (field-level encryption) และ/หรือในฐานข้อมูล (at-rest encryption, managed KMS) แต่ต้องชัดเจนว่าใครหมุนกุญแจและวิธีการกู้คืน
การตรวจสอบ (auditing) ก็เป็นความรับผิดชอบร่วม: แอปควรปล่อย event ที่มีความหมาย; ฐานข้อมูลควรเก็บล็อกแบบไม่เปลี่ยนแปลงเมื่อจำเป็น (เช่น ตาราง audit แบบ append-only ที่จำกัดการเข้าถึง)
การไว้ใจตรรกะแอปมากเกินไปเป็นรูปแบบคลาสสิก: ขาดข้อจำกัด, null ที่เงียบ, ธง "admin" เก็บโดยไม่มีการตรวจสอบ วิธีแก้คือสมมติว่าบั๊กจะเกิดขึ้น และออกแบบสแตกให้ฐานข้อมูลปฏิเสธการเขียนที่ไม่ปลอดภัย—แม้จากโค้ดของเราเอง
การปรับขนาดไม่ค่อยล้มเพราะ "ฐานข้อมูลรับไม่ได้" แต่มักล้มเพราะทั้งสแตกตอบสนองไม่ดีเมื่อโหลดเปลี่ยนรูปแบบ: endpoint หนึ่งฮิตบ่อย คิวรีหนึ่งร้อน ตรรกะงานหนึ่งเริ่ม retry
ทีมส่วนใหญ่เจอคอขวดเริ่มต้นเดียวกัน:
ความสามารถในการตอบเร็วขึ้นอยู่กับว่าเฟรมเวิร์กและเครื่องมือ DB เปิดเผยแผนคำสั่ง, มิเกรชัน, การจัดพูลการเชื่อมต่อ และรูปแบบแคชอย่างไร
การเคลื่อนไหวในการปรับขนาดที่พบบ่อยมักมาทีละขั้น:
สแตกที่ขยายได้ต้องมีการสนับสนุนงานพื้นหลัง การจัดตาราง และ retry ที่ปลอดภัยเป็นฟีเจอร์หลัก
ถ้าระบบงานของคุณไม่สามารถบังคับ idempotency (งานเดียวกันรันสองครั้งโดยไม่คิดเงินสองครั้งหรือส่งซ้ำ) คุณจะ "ขยาย" ไปสู่การเสียรูปของข้อมูล การเลือกตอนต้น—เช่น พึ่งพาทรานแซคชันแฝง ข้อจำกัดความเป็นเอกลักษณ์อ่อน หรือพฤติกรรม ORM ที่ปิดบัง—อาจปิดทางที่จะนำ pattern อย่าง outbox หรือ workflow แบบ exactly-once-ish เข้ามาทีหลัง
การจัดแนวตั้งแต่ต้นให้ผลตอบแทน: เลือกฐานข้อมูลที่ตรงกับความต้องการความสอดคล้อง และเฟรมเวิร์กที่ทำให้ก้าวถัดไป (replica, queue, partitioning) เป็นเส้นทางที่รองรับ ไม่ใช่การเขียนใหม่ทั้งหมด
สแตกรู้สึก "ง่าย" เมื่อการพัฒนาและการปฏิบัติการแบ่งปันสมมติฐานเดียวกัน: วิธีสตาร์ทแอป วิธีการเปลี่ยนแปลงข้อมูล วิธีรันเทสต์ และวิธีรู้ว่าเกิดอะไรขึ้นเมื่อมีปัญหา หากชิ้นเหล่านี้ไม่ตรงกัน ทีมจะเสียเวลาในการเขียนโค้ดเชื่อม สคริปต์เปราะบาง และ runbook แบบแมนนวล
การตั้งค่าในเครื่องที่เร็วคือฟีเจอร์ เลือกเวิร์กโฟลว์ที่เพื่อนร่วมทีมใหม่สามารถ clone ติดตั้ง รันมิเกรชัน และมีข้อมูลตัวอย่างสมจริงในไม่กี่นาที—ไม่ใช่หลายชั่วโมง
นั่นมักหมายถึง:
ถ้าเครื่องมือมิเกรชันของเฟรมเวิร์กต่อสู้กับการเลือกฐานข้อมูล ทุกการเปลี่ยนสคีมาจะกลายเป็นโปรเจกต์เล็ก ๆ
สแตกของคุณควรเอื้อต่อการเขียน:
รูปแบบความผิดพลาดทั่วไป: ทีมพึ่งพา unit tests มากเพราะ integration tests ช้า/ยุ่งยาก นั่นมักเป็นความไม่ลงรอยกันของสแตก/ปฏิบัติการ—การ provisioning DB สำหรับเทสต์ มิเกรชัน และ fixtures ควรลื่นไหล
เมื่อความหน่วงพุ่งขึ้น คุณต้องตามคำขอหนึ่งคำขอจากเฟรมเวิร์กเข้าไปในฐานข้อมูล
มองหา logs แบบมีโครงสร้าง, metrics พื้นฐาน (อัตราคำขอ, ข้อผิดพลาด, เวลา DB), และ traces ที่รวมเวลา query เข้าไปได้ แม้แค่ correlation ID ที่ปรากฏทั้งใน log ของแอปและฐานข้อมูลก็เปลี่ยนการเดาเป็นการค้นพบได้
การปฏิบัติการไม่แยกจากการพัฒนา; มันคือการต่อเนื่องของมัน
เลือกเครื่องมือที่สนับสนุน:
ถ้าคุณไม่สามารถซ้อมการกู้คืนหรือมิเกรชันในเครื่องได้ คุณจะทำมันไม่ดีเมื่อต้องเจอความกดดันจริง
การเลือกสแตกไม่ใช่การหาตัวเครื่องมือที่ "ดีที่สุด" แต่คือการเลือกเครื่องมือที่เข้ากันภายใต้ข้อจำกัดจริงของคุณ ใช้เช็คลิสต์นี้เพื่อบังคับการจัดแนวตั้งแต่ต้น
จำกัดเวลาเป็น 2–5 วัน สร้าง vertical slice บาง ๆ: workflow แกนหนึ่ง, งานพื้นหลังหนึ่งงาน, คิวรีรายงานหนึ่งรายการ, และ auth พื้นฐาน วัดความเสียดทานของนักพัฒนา, ความสะดวกมิเกรชัน, ความชัดเจนของคิวรี, และความง่ายในการทดสอบ
ถ้าต้องการเร่งขั้นตอนนี้ เครื่องมืออย่าง Koder.ai สามารถช่วยสร้าง vertical slice ทำงานได้เร็วจากสเปกที่ขับเคลื่อนด้วยแชท—แล้วปรับด้วย snapshots/rollback และส่งออกซอร์สโค้ดเมื่อพร้อมยึดทิศทาง
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
แม้ทีมที่แข็งแกร่งก็ยังจบด้วยความไม่ลงรอยในสแตก—การเลือกที่ดูโอเคแยกกันแต่สร้างแรงเสียดทานเมื่อระบบขึ้น บทดีคือ: ส่วนใหญ่คาดเดาได้ และคุณเลี่ยงได้ด้วยการเช็กไม่กี่อย่าง
กลิ่นคลาสสิกคือเลือกฐานข้อมูลหรือเฟรมเวิร์กเพราะมันกำลังเทรนด์ ในขณะที่โมเดลข้อมูลยังไม่ชัด หรือการปรับขนาดก่อนเวลา: ปรับเพื่อผู้ใช้ล้านคนก่อนจัดการผู้ใช้หลักร้อย ซึ่งมักนำไปสู่โครงสร้างพื้นฐานเพิ่มและโหมดล้มเหลวมากขึ้น
สังเกตด้วยสำหรับสแตกที่ทีมอธิบายไม่ได้ว่าชิ้นใหญ่อยู่ทำไม ถ้าคำตอบคือ “เพราะทุกคนใช้” คุณกำลังสะสมความเสี่ยง
ปัญหาจำนวนมากแสดงออกที่รอยต่อ:
สิ่งเหล่านี้ไม่ใช่ "ปัญหาของฐานข้อมูล" หรือ "ปัญหาของเฟรมเวิร์ก"—แต่เป็นปัญหาระบบ
ชอบชิ้นส่วนที่น้อยลงและเส้นทางเดียวชัดเจนสำหรับงานทั่วไป: วิธีมิเกรชันเดียว, สไตล์คิวรีหนึ่งแบบสำหรับฟีเจอร์ส่วนใหญ่, และคอนเวนชันเดียวกันข้ามบริการ หากเฟรมเวิร์กส่งเสริมรูปแบบ (lifecycle คำขอ, dependency injection, pipeline งาน) ให้ยึดตามมันแทนผสมสไตล์
ทบทวนเมื่อคุณเห็น incident ใน production ซ้ำ ๆ, ความเสียดทานของนักพัฒนาที่เรื้อรัง, หรือเมื่อความต้องการผลิตภัณฑ์เปลี่ยนรูปแบบการเข้าถึงข้อมูลอย่างมีนัยสำคัญ
เปลี่ยนอย่างปลอดภัยโดยแยกรอยต่อ: แนะนำชั้น adapter, ย้ายแบบค่อยเป็นค่อยไป (dual-write หรือ backfill เมื่อจำเป็น), และพิสูจน์ความเทียบเท่าด้วยเทสต์อัตโนมัติก่อนสลับทราฟฟิก
การเลือกภาษาโปรแกรม เฟรมเวิร์กเว็บ และฐานข้อมูลไม่ใช่การตัดสินใจสามอย่างแยกกัน แต่มันคือการออกแบบระบบที่แสดงออกในสามที่ ตัวเลือกที่ "ดีที่สุด" คือชุดที่สอดคล้องกับรูปแบบข้อมูลของคุณ ความต้องการความสอดคล้อง เวิร์กโฟลว์ของทีม และแนวทางการเติบโตของผลิตภัณฑ์
เขียนเหตุผลข้างหลังการเลือกของคุณ: รูปแบบทราฟฟิกที่คาด, ความหน่วงที่ยอมรับได้, นโยบายการเก็บข้อมูล, โหมดล้มเหลวที่ยอมรับได้, และสิ่งที่คุณ ไม่ ปรับแต่งในตอนนี้ การทำให้ข้อแลกเปลี่ยนมองเห็นได้ช่วยให้เพื่อนร่วมงานในอนาคตเข้าใจ "ทำไม" และป้องกันการเบี่ยงสถาปัตยกรรมโดยไม่ตั้งใจเมื่อความต้องการเปลี่ยน
รันการตั้งค่าปัจจุบันของคุณผ่านเช็คลิสต์ด้านบนและจดจุดที่การตัดสินใจไม่สอดคล้องกัน (เช่น สคีมาที่ขัดกับ ORM, หรือเฟรมเวิร์กที่ทำงานพื้นหลังเกะกะ)
ถ้าคุณกำลังสำรวจทิศทางใหม่ เครื่องมืออย่าง Koder.ai ยังช่วยให้คุณเปรียบเทียบสมมติฐานสแตกอย่างรวดเร็วโดยสร้างแอปพื้นฐาน (เช่น React บนเว็บ, Go services กับ PostgreSQL, และ Flutter สำหรับมือถือ) ที่คุณสามารถตรวจสอบ ส่งออก และพัฒนาต่อได้—โดยไม่ต้องผูกมัดกับการสร้างยาวนาน
สำหรับการติดตามที่ลงลึกขึ้น ให้ดูคำแนะนำที่เกี่ยวข้องใน /blog, ค้นหารายละเอียดการใช้งานใน /docs, หรือเปรียบเทียบตัวเลือกการสนับสนุนและการปรับใช้ใน /pricing.
มองพวกมันเป็นท่อเดียวสำหรับทุกคำขอ: framework → โค้ด (ภาษา) → ฐานข้อมูล → การตอบกลับ ถ้าชิ้นใดชิ้นหนึ่งส่งเสริมรูปแบบที่ชิ้นอื่นต่อต้าน (เช่น สตอเรจแบบไม่มีสคีมา + งานรายงานหนัก) คุณจะเสียเวลาไปกับโค้ดเชื่อม, กฎที่ซ้ำกัน และบั๊กความสอดคล้องที่ยากจะหาเหตุผลออกมา
เริ่มจาก โมเดลข้อมูลหลัก และการดำเนินการที่คุณจะทำบ่อยที่สุด:
เมื่อโมเดลชัดเจน ฟีเจอร์ฐานข้อมูลและเฟรมเวิร์กที่คุณต้องการมักจะชัดเจนตามมา
ถ้าฐานข้อมูลบังคับสคีมาเข้มข้น หลายกฎจะอยู่ใกล้ข้อมูล:
NOT NULL, ความเป็นเอกลักษณ์CHECK constraints สำหรับช่วงหรือสถานะที่ถูกต้องกับโครงสร้างยืดหยุ่น กฎจะย้ายขึ้นไปยังโค้ดแอป (validation, payload เวอร์ชัน, backfill) ซึ่งเร่งการทดลองได้ แต่เพิ่มภาระการทดสอบและความเสี่ยงที่บริการต่าง ๆ จะเบี่ยงเบนกัน
ใช้ทรานแซคชันเมื่อการเขียนหลายอย่างต้องสำเร็จหรือยกเลิกพร้อมกัน (เช่น คำสั่งซื้อ + สถานะการจ่ายเงิน + การปรับสต็อก). หากไม่ใช้ทรานแซคชัน คุณจะพบ:
นอกจากนี้ให้ทำ side effects (อีเมล/webhook) หลังการ commit และออกแบบการกระทำให้ idempotent (ปลอดภัยต่อการรันซ้ำ)
เลือกเครื่องมือที่ง่ายที่สุดที่ยังบอกเจตนาได้ชัด:
สำหรับ endpoint สำคัญ ให้ตรวจสอบ SQL ที่รันจริงเสมอ
เก็บสคีมาและโค้ดให้สอดคล้องด้วยมิเกรชันที่ปฏิบัติเสมือนโค้ดโปรดักชัน:
ถ้ามิเกรชันทำด้วยมือหรือไม่เสถียร สภาพแวดล้อมจะเบี่ยงและการปรับใช้จะเสี่ยง
โปรไฟล์เส้นทางของคำขอทั้งหมด ไม่ใช่แค่ฐานข้อมูล:
ฐานข้อมูลตอบกลับใน 5 ms จะไม่ช่วยถ้าแอปทำ 20 คำสั่งหรือบล็อก I/O อยู่
ใช้ connection pool เพื่อลดต้นทุนการเปิด connection และปกป้อง DB ตอนโหลดสูง. คำแนะนำเชิงปฏิบัติ:
พูลที่ตั้งไม่ดีมักแสดงอาการเป็น timeouts และล้มเหลวเสียงดังตอนพีก
ใช้ทั้งสองชั้น:
NOT NULL, CHECK)วิธีนี้ลดสถานะที่เป็นไปไม่ได้เมื่อคำขอแข่งกัน วิ่งงานพื้นหลังเขียนข้อมูล หรือมี endpoint ใหม่ที่ลืมเช็ก
ตั้งเวลาทำ Proof of Concept แบบจำกัดเวลา (2–5 วัน) ที่ทดสอบรอยต่อจริง ๆ:
แล้วเขียนบันทึกการตัดสินใจหน้าเดียวเพื่อให้การเปลี่ยนแปลงในอนาคตเป็นไปโดยตั้งใจ (ดูแนวทางที่เกี่ยวข้องที่ /docs และ /blog)