21 ก.ย. 2568·3 นาที
แนวคิด CAP ของ Eric Brewer: ทำไมระบบกระจายต้องแลกเปลี่ยน
เรียนรู้ทฤษฎี CAP ของ Eric Brewer ในฐานะแบบคิดเชิงปฏิบัติ: ว่าความสอดคล้อง ความพร้อมใช้งาน และการแบ่งเครือข่ายมีผลต่อการตัดสินใจในระบบกระจายอย่างไร
ทำไม CAP จึงกลายเป็นกรอบความคิดยอดนิยม
เมื่อคุณเก็บข้อมูลชุดเดียวกันไว้บนมากกว่าหนึ่งเครื่อง คุณจะได้ความเร็วและความทนทานต่อความล้มเหลว—แต่คุณก็จะได้ปัญหาใหม่คือ: ความไม่ลงรอยกัน สองเซิร์ฟเวอร์อาจรับอัพเดตคนละชุด ข้อความอาจมาช้า หรือไม่มาถึงเลย และผู้ใช้แต่ละคนอาจได้คำตอบต่างกันขึ้นกับ replica ที่โดนติดต่อ CAP ได้รับความนิยมเพราะมันให้วิธีที่ชัดเจนในการพูดถึงความยุ่งเหยิงนั้นโดยไม่ต้องเว้าแหวง
Eric Brewer นักวิทยาการคอมพิวเตอร์และผู้ร่วมก่อตั้ง Inktomi นำเสนอแนวคิดหลักในปี 2000 ในฐานะคำอธิบายในทางปฏิบัติสำหรับระบบที่ทำสำเนาข้อมูลเมื่อเกิดความล้มเหลว แนวคิดนี้แพร่หลายเพราะมันตรงกับสิ่งที่ทีมเจอในโปรดักชัน: ระบบกระจายไม่ได้แค่ล่มโดยการดับ แต่ล้มเหลวโดยการ แยกส่วน
CAP คือเลนส์สำหรับความล้มเหลว ไม่ใช่เช็คลิสต์ฟีเจอร์
CAP มีประโยชน์ที่สุดเมื่อสิ่งต่าง ๆ ผิดพลาด—โดยเฉพาะเมื่อเครือข่ายไม่ทำงานตามที่คาด ในวันที่ปกติหลายระบบอาจดูทั้งสอดคล้องพอและพร้อมใช้งาน พิสูจน์จริงคือตอนที่เครื่องไม่สามารถสื่อสารกันได้อย่างเชื่อถือได้และคุณต้องตัดสินใจว่าจะทำอย่างไรกับการอ่านและเขียนในขณะที่ระบบแยกกัน
การใคร่ครวญแบบนี้คือเหตุผลที่ CAP กลายเป็นกรอบคิดที่ใช้ได้จริง: มันไม่ถกเถียงเรื่องแนวปฏิบัติที่ดีที่สุด แต่มันบังคับให้ตั้งคำถามชัดเจน—เราจะยอมเสียอะไรในช่วงที่ระบบแยกกัน?
สิ่งที่คุณจะตัดสินใจได้เมื่ออ่านจบ
เมื่อจบบทความนี้ คุณควรจะสามารถ:
- จำแนกได้ว่าคุณกำลังเผชิญสถานการณ์ CAP จริงหรือไม่ (การทำสำเนา + โอกาสการตัดการสื่อสาร)
- เลือกอย่างตั้งใจว่าระบบของคุณควรเน้น ความสอดคล้อง (ทุกคนเห็นความจริงเดียวกัน) หรือ ความพร้อมใช้งาน (ระบบยังคงตอบคำขอ) เมื่อ replica ไม่เห็นพ้องกัน
- เชื่อมการเลือกนั้นกับผลกระทบต่อผลิตภัณฑ์: ผู้ใช้จะเห็นอะไร ข้อผิดพลาดแบบไหนที่ต้องแสดง และต้องแก้ไขอะไรหลังจากระบบรวมตัวกันใหม่
CAP ยังคงมีค่าเพราะมันเปลี่ยนคำว่า “ระบบกระจายยาก” ให้เป็นการตัดสินใจที่ชัดเจนซึ่งคุณปกป้องได้
การตั้งค่า: การทำสำเนาและปัญหาความไม่ลงรอยกัน
ระบบกระจาย โดยง่ายคือ คอมพิวเตอร์หลายเครื่องพยายามทำงานเหมือนเครื่องเดียว คุณอาจมีเซิร์ฟเวอร์หลายตัวในแร็ค ภูมิภาค หรือโซนคลาวด์ต่างกัน แต่สำหรับผู้ใช้มันคือ “แอป” หรือ “ฐานข้อมูล” เดียว
ทำไมเราถึงทำสำเนาข้อมูล
เพื่อให้ระบบที่แชร์กันทำงานที่สเกลโลกจริง เรามักจะ ทำสำเนา: เก็บข้อมูลชุดเดียวกันไว้บนเครื่องหลายเครื่อง
การทำสำเนานิยมเพราะเหตุผลเชิงปฏิบัติสามข้อ:
- สเกล: เครื่องมากขึ้นรองรับทราฟฟิกได้มากขึ้น
- ประสิทธิภาพ: ผู้ใช้ถูกให้บริการจากสำเนาใกล้เคียง ลด latency
- ความเชื่อถือได้: หากเครื่องหนึ่งล้ม อีกเครื่องก็ยังให้บริการได้
จนถึงตรงนี้ การทำสำเนาดูเหมือนเป็นประโยชน์ชัดเจน จุดที่ล่อคือตอนที่การทำสำเนาสร้างงานใหม่ขึ้นมา: ต้องรักษาทุกสำเนาให้ตรงกัน
ความตึงเครียดหลัก: สำเนาอาจไม่ลงรอยกัน
ถ้าทุก replica คุยกันได้ทันที พวกมันจะประสานงานการอัพเดตและคงสถานะตรงกันได้ แต่เครือข่ายจริงไม่สมบูรณ์ ข้อความอาจช้า ถูกทิ้ง หรือถูกส่งอ้อมเมื่อเกิดความล้มเหลว
เมื่อการสื่อสารเป็นปกติ replica มักแลกเปลี่ยนอัพเดตและเข้าใกล้สถานะเดียวกัน แต่เมื่อการสื่อสารขาดหาย (แม้ชั่วคราว) คุณอาจได้ สองเวอร์ชันที่ดูถูกต้องของ “ความจริง”
ตัวอย่าง: ผู้ใช้เปลี่ยนที่อยู่จัดส่ง Replica A ได้รับอัพเดต Replica B ไม่ได้รับ ทีนี้ระบบต้องตอบคำถามที่ดูเรียบง่าย: ที่อยู่ปัจจุบันคืออะไร?
การทำงานปกติ vs การทำงานในภาวะล้มเหลว
นี่คือความต่างระหว่าง:
- การทำงานปกติ: replica ประสานงานได้; ความไม่ลงรอยเป็นปัญหาด้านเวลา
- การทำงานเมื่อเกิดความล้มเหลว: บาง replica สื่อสารกันไม่ได้; ความไม่ลงรอยกลายเป็นสิ่งเลี่ยงไม่ได้
การคิดแบบ CAP เริ่มตรงนี้: เมื่อมีการทำสำเนาแล้ว ความไม่ลงรอยเมื่อการสื่อสารล้มเหลวไม่ใช่กรณีพิเศษ—มันคือปัญหาการออกแบบหลัก
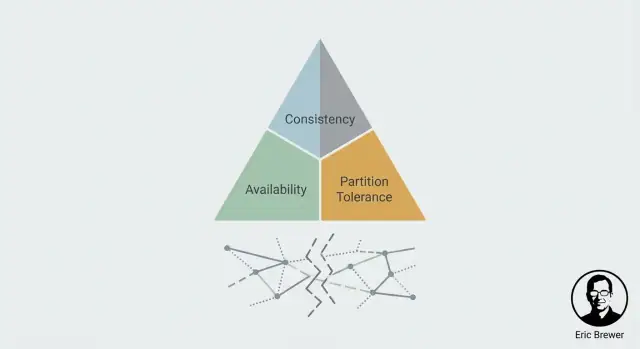
CAP แบบง่าย: C, A และ P
CAP เป็นกรอบความคิดสำหรับสิ่งที่ ผู้ใช้รู้สึกจริงๆ เมื่อระบบกระจายอยู่บนหลายเครื่อง (มักข้ามหลายตำแหน่ง) มันไม่ได้บอกว่าระบบไหน “ดี” หรือ “ไม่ดี”—แค่ชี้ความตึงเครียดที่คุณต้องจัดการ
ความสอดคล้อง (C): ฉันเห็นการเขียนล่าสุดหรือไม่?
ความสอดคล้องเกี่ยวกับการเห็นพ้องกัน หากคุณอัพเดตบางอย่าง การอ่านถัดไป (จากที่ไหนก็ได้) จะสะท้อนการอัพเดตนั้นหรือไม่
จากมุมผู้ใช้ มันคือความต่างระหว่าง “ฉันเพิ่งเปลี่ยนแล้ว ทุกคนเห็นค่าใหม่” กับ “บางคนยังเห็นค่าก่อนหน้าอยู่ชั่วคราว”
ความพร้อมใช้งาน (A): ฉันจะได้คำตอบหรือไม่?
ความพร้อมใช้งานหมายถึงระบบตอบคำขอ—อ่านและเขียน—ด้วยผลลัพธ์สำเร็จ ไม่ใช่ “เร็วที่สุดเท่าที่จะเป็นไปได้” แต่คือ “ไม่ปฏิเสธการให้บริการ”
ในช่วงปัญหา (เซิร์ฟเวอร์ลง, เฮ็ดดิ้งเครือข่าย) ระบบที่พร้อมใช้งานยังคงรับคำขอ แม้ต้องตอบด้วยข้อมูลที่อาจล้าหลังเล็กน้อย
ความทนทานต่อการแบ่งเครือข่าย (P): เกิดอะไรขึ้นเมื่อโหนดคุยกันไม่ได้?
พาร์ติชันคือเมื่อเครือข่ายแยก: เครื่องยังทำงาน แต่ข้อความระหว่างบางเครื่องไปไม่ถึง (หรือมาช้าจนใช้ไม่ได้) ในระบบกระจาย คุณไม่สามารถมองว่ามันเป็นไปไม่ได้—คุณต้องกำหนดพฤติกรรมเมื่อมันเกิด
เรื่องเล่าเรียบง่าย: สองร้านค้า สต็อกเดียวกัน
นึกภาพร้านค้าสองแห่งขายสินค้าชิ้นเดียวกันและแชร์ “สต็อก 1 ชิ้น” ลูกค้าคนหนึ่งซื้อชิ้นสุดท้ายที่ Shop A Shop A เขียน inventory = 0 ขณะเดียวกันพาร์ติชันทำให้ Shop B ฟังไม่รู้เรื่อง
ถ้า Shop B ยังคง พร้อมใช้งาน มันอาจขายสินค้าที่ไม่มี (รับคำสั่งในขณะที่พาร์ติชัน) ถ้า Shop B บังคับ ความสอดคล้อง มันอาจปฏิเสธการขายจนกว่าจะยืนยันสต็อกล่าสุดได้ (ปฏิเสธการให้บริการในช่วงแยก)
พาร์ติชันคืออะไรจริงๆ (และทำไมคุณจึงไม่ควรมองข้าม)
“พาร์ติชัน” ไม่ใช่แค่ “อินเทอร์เน็ตล่ม” มันคือสถานการณ์ที่บางส่วนของระบบไม่สามารถคุยกันได้อย่างเชื่อถือได้—แม้แต่ละส่วนยังรันได้ปกติ
ในระบบที่ทำสำเนา โหนดแลกเปลี่ยนข้อความตลอดเวลา: การเขียน คำยืนยัน heartbeats การเลือกผู้นำ คำขออ่าน พาร์ติชันคือสิ่งที่เกิดเมื่อข้อความพวกนั้นหยุดมาถึง (หรือมาช้าจนไร้ประโยชน์) สร้าง ความไม่ลงรอยเกี่ยวกับความจริง: “การเขียนเกิดขึ้นจริงหรือ?” “ใครเป็นผู้นำ?” “โหนด B ยังมีชีวิตอยู่ไหม?”
พาร์ติชันคือความล้มเหลวด้านการสื่อสาร
การสื่อสารล้มเหลวได้ในหลายรูปแบบละเอียดอ่อน:
- การสูญเสียแพ็กเก็ต ที่ทำให้เกิด retry และ timeout
- ปัญหา routing ที่ทำให้ทราฟฟิกอ้อมไกลหรือหายไป
- ลิงก์โอเวอร์โหลด (หรือ NIC อิ่ม) ทำให้เกิดความล่าช้า
- ไฟร์วอลล์/security group ตั้งค่าผิด บล็อกบางพอร์ตหรือทิศทาง
- DNS หรือการค้นหาบริการมีปัญหา ทำให้โหนดหากันไม่เจอ
ประเด็นสำคัญ: พาร์ติชันมักเป็นการ เสื่อมลง ไม่ใช่การดับแบบชัดเจน จากแอปมุมมอง “ช้าเกินไป” อาจเหมือน “ไม่ทำงาน”
ทำไมพาร์ติชันจึงเลี่ยงไม่ได้เมื่อขยายระบบ
เมื่อเพิ่มเครื่อง เพิ่มเครือข่าย เพิ่มภูมิภาค และชิ้นส่วนที่เคลื่อนไหวมากขึ้น ก็มีโอกาสที่การสื่อสารจะขาดหายมากขึ้น แม้องค์ประกอบแต่ละชิ้นเชื่อถือได้รวมกันแล้วระบบโดยรวมยังมีความล้มเหลวเพราะมีการพึ่งพามากขึ้นและการประสานข้ามโหนดมากขึ้น
คุณไม่จำเป็นต้องสมมติอัตราความล้มเหลวที่แน่นอนเพื่อยอมรับความจริง: ถ้าระบบคุณรันนานพอและครอบคลุมโครงสร้างพื้นฐานพอ พาร์ติชันจะเกิดขึ้นแน่นอน
“ทนทานต่อพาร์ติชัน” หมายถึงอะไรในทางปฏิบัติ
ความทนทานต่อพาร์ติชันหมายถึงระบบของคุณออกแบบให้ ยังทำงานต่อได้ระหว่างการแยก—แม้โหนดจะไม่เห็นพ้องหรือยืนยันสิ่งที่อีกฝั่งเห็นอยู่ก็ตาม นั่นบังคับให้ต้องเลือก: จะยังให้บริการ (เสี่ยงความไม่สอดคล้อง) หรือหยุด/ปฏิเสธบางคำขอ (รักษาความสอดคล้อง)
ช่วงเวลาสำคัญ: เลือกความสอดคล้องหรือความพร้อมใช้งานตอนพาร์ติชัน
ทดลองโดยไม่กลัว
ทดลองกับสถานการณ์ล้มเหลว แล้ว rollback อย่างรวดเร็วเมื่อแนวทางไม่เป็นไปตามคาด
เมื่อคุณมีการทำสำเนา พาร์ติชันคือการตัดการสื่อสาร: สองส่วนของระบบคุยกันไม่ได้นานพอ เซิร์ฟเวอร์ยังรัน ผู้ใช้ยังคลิกปุ่ม บริการยังรับคำขอ—แต่ replica ไม่สามารถตกลงกันได้เกี่ยวกับความจริงล่าสุด
นั่นคือความตึงเครียดของ CAP ในประโยคเดียว: ระหว่างพาร์ติชัน คุณต้องเลือกให้ความสำคัญกับ Consistency (C) หรือ Availability (A) คุณจะไม่ได้ทั้งสองพร้อมกัน
ถ้าเลือกความสอดคล้อง (C)
คุณกำลังบอกว่า: “ฉันขอถูกต้องมากกว่าสะดวก” เมื่อตัวระบบไม่สามารถยืนยันว่าคำขอจะทำให้ replica ทั้งหมดสอดคล้อง มันต้อง ล้มเหลวหรือรอ
ผลเชิงปฏิบัติ: ผู้ใช้บางคนจะเห็นข้อผิดพลาด เวลาเกิน หรือข้อความ “ลองอีกครั้ง” โดยเฉพาะการดำเนินการที่เปลี่ยนข้อมูล นี่เป็นเรื่องปกติเมื่อคุณเลือกปฏิเสธการชำระเงินมากกว่าการเสี่ยงชำระซ้ำ หรือปิดการจองที่นั่งมากกว่าการขายเกิน
ถ้าเลือกความพร้อมใช้งาน (A)
คุณกำลังบอกว่า: “ฉันขอตอบกลับมากกว่าปิดกั้น” แต่ละฝั่งของพาร์ติชันจะยังรับคำขอ แม้จะไม่สามารถประสานกันได้
ผลเชิงปฏิบัติ: ผู้ใช้ได้รับการตอบกลับสำเร็จ แต่ข้อมูลที่อ่านอาจ ล้าหลัง และการอัพเดตพร้อมกันอาจ ขัดแย้ง จากนั้นคุณต้องพึ่งการรวมผลภายหลัง (กฎผสาน, last-write-wins, ตรวจคน)
การเลือกอาจต่างกันตามการทำงาน
นี่ไม่ใช่การตั้งค่าระดับโลกเสมอไป หลายผลิตภัณฑ์ผสมกลยุทธ์:
- อ่าน vs เขียน: ให้การอ่านพร้อมใช้งาน แต่ทำให้การเขียนเข้มงวดขึ้น
- การกระทำสำคัญ vs ไม่สำคัญ: บังคับความสอดคล้องสำหรับเงิน ตัวตน สต็อก; ให้ความพร้อมใช้งานสำหรับฟีด การวิเคราะห์ “ไลก์” หรือโปรไฟล์แคช
ช่วงเวลาสำคัญคือการตัดสินใจ—ต่อการทำงาน—อะไรแย่กว่ากัน: ปิดกั้นผู้ใช้ตอนนี้ หรือแก้ความขัดแย้งของความจริงทีหลัง
ความเข้าใจผิดทั่วไป: เกินคำว่า “เลือกสองจากสาม”
สโลแกน “เลือกสอง” น่าจดจำ แต่บ่อยครั้งทำให้เข้าใจผิดว่่า CAP เป็นเมนูฟีเจอร์สามอย่างที่คุณเก็บไว้สองอย่างตลอดไป CAP เกี่ยวกับสิ่งที่จะเกิดขึ้น เมื่อเครือข่ายไม่ทำงานร่วมกัน: ในพาร์ติชัน (หรือสิ่งที่ดูเหมือนพาร์ติชัน) ระบบกระจายต้องเลือกระหว่างการคืนคำตอบที่ สอดคล้อง และการยัง ให้บริการ ทุกคำขอ
ความเข้าใจผิด 1: “ฉันจะเลือก C และ A แล้วหลีกเลี่ยงพาร์ติชัน”
ในระบบกระจายจริง พาร์ติชันไม่ใช่การตั้งค่าที่ปิดได้ ถ้าระบบของคุณข้ามเครื่อง แร็ค โซน หรือภูมิภาค ข้อความอาจช้า ถูกทิ้ง เรียงผิด หรือส่งผิดที่ นั่นคือพาร์ติชันจากมุมมองซอฟต์แวร์: โหนดไม่สามารถตกลงกันได้อย่างเชื่อถือได้
แม้เครือข่ายทางกายภาพจะดี ความล้มเหลวอื่น ๆ ก็ให้ผลเหมือนกัน—โหนดโอเวอร์โหลด, หยุด GC, เพื่อนบ้านเสียงดัง, DNS ผิดพลาด, load balancer ที่ไม่เสถียร ผลคือบางส่วนของระบบคุยกับอีกส่วนไม่พอที่จะประสาน
ความเข้าใจผิด 2: “พาร์ติชันเป็นกรณีขอบหายาก”
แอปไม่ประสบพาร์ติชันเป็นเหตุการณ์ไบนารีชัดเจน พวกมันประสบ การกระโดดของ latency และ timeout ถาคุณร้องขอ timeout ที่ 200 ms มันไม่สำคัญว่าพัสดุมาถึงที่ 201 ms หรือไม่มาถึงเลย: แอปต้องตัดสินใจต่อไป จากมุมแอป การสื่อสารช้าเป็นบ่อยครั้งไม่ต่างจากการล่ม
ความเข้าใจผิด 3: “ระบบเป็น CP หรือ AP อย่างใดอย่างหนึ่ง”
ระบบจริงหลายระบบ โดยมากสอดคล้อง หรือ โดยมากพร้อมใช้งาน ขึ้นกับการตั้งค่าและสภาพการทำงาน Timeout, นโยบาย retry, ขนาดควอรัม, ตัวเลือก “read your writes” สามารถเปลี่ยนพฤติกรรมได้
ในเงื่อนไขปก ฏ ิ ฐานข้อมูลอาจดูสอดคล้องมาก แต่ภายใต้ความเครียดหรือปัญหาระหว่างภูมิภาค มันอาจเริ่มปฏิเสธคำขอ (เน้น C) หรือคืนข้อมูลเก่า (เน้น A)
CAP ไม่ใช่การติดป้ายผลิตภัณฑ์ แต่เป็นการเข้าใจการแลกเปลี่ยนเมื่อความไม่ลงรอยเกิดขึ้น—โดยเฉพาะเมื่อเกิดจากความช้าธรรมดา
ตัวเลือกความสอดคล้องที่คุณเลือกได้จริง
การพูดถึง CAP มักทำให้ความสอดคล้องดูเป็นไบนารี: “สมบูรณ์แบบ” หรือ “ปล่อยไป” ระบบจริง ๆ ให้เมนูของการรับประกัน แต่ละแบบให้ประสบการณ์ผู้ใช้ต่างกันเมื่อตัวสำเนาไม่ลงรอยหรือเครือข่ายขาด
ความสอดคล้องแข็งแรง (และราคาที่ต้องจ่ายเมื่อล้มเหลว)
ความสอดคล้องแข็งแรง (มักเรียกว่า “linearizable”) หมายความว่าเมื่อการเขียนถูกยืนยัน การอ่านทุกครั้งหลังจากนั้น—ไม่ว่าติดต่อ replica ไหน—จะคืนการเขียนนั้น
ต้นทุน: ในพาร์ติชันหรือเมื่อสำเนาบางส่วนเข้าถึงไม่ได้ ระบบอาจ หน่วงหรือปฏิเสธการอ่าน/เขียน เพื่อหลีกเลี่ยงสถานะขัดแย้ง ผู้ใช้สังเกตได้เป็น timeout, “ลองอีกครั้ง”, หรือพฤติกรรมอ่าน-อย่างเดียวชั่วคราว
ความสอดคล้องในที่สุด (และสิ่งที่ผู้ใช้อาจสังเกต)
ความสอดคล้องในที่สุด รับประกันว่า ถ้าไม่มีการอัพเดตใหม่ สำเนาทั้งหมดจะรวมกัน มันไม่รับประกันว่าผู้ใช้สองคนอ่านพร้อมกันจะเห็นค่าเดียวกัน
ผู้ใช้อาจสังเกตได้ว่า: รูปโปรไฟล์ที่อัพเดตใหม่ “กลับไป” จำนวนตัวนับช้า หรือข้อความที่เพิ่งส่งยังไม่เห็นบนเครื่องอื่นชั่วคราว
การรับประกันกลางที่มีประโยชน์
คุณมักได้ประสบการณ์ที่ดีกว่าด้วยการรับประกันระดับกลางโดยไม่ต้องขอความสอดคล้องเต็ม:
- Read-your-writes: หลังจากคุณอัพเดต คุณจะไม่อ่านเวอร์ชันเก่าของข้อมูลของตัวเอง
- Monotonic reads: เมื่อคุณเห็นเวอร์ชัน N แล้ว คุณจะไม่เห็นเวอร์ชัน N-1 อีก
- Causal consistency: ถ้าเหตุการณ์ B ขึ้นกับ A (การตอบหลังอ่านข้อความ) ทุกคนเห็น A ก่อน B
การรับประกันเหล่านี้สอดคล้องกับความคิดของคนทั่วไป (“อย่าให้การเปลี่ยนของฉันหายไป”) และมักดูแลรักษาได้ง่ายกว่าในภาวะล้มเหลวบางแบบ
เลือกระดับความสอดคล้องตามความคาดหวัง
เริ่มจากคำสัญญาต่อผู้ใช้ ไม่ใช่คำศัพท์:
- ถ้าการอ่านผิดทำให้เกิดความเสียหายไม่สามารถย้อนกลับ (การโอนเงิน, การจองสต็อก, การเปลี่ยนสิทธิ์) ให้เอนเอียงไปที่ ความสอดคล้องที่เข้มกว่า และยอมรับการไม่พร้อมใช้งานชั่วคราว
- ถ้าฟีเจอร์ทนได้กับความไม่ลงรอยชั่วคราว (ไลก์, การนับ, การจัดอันดับฟีด) ความสอดคล้องแบบ eventual หรือ causal มักเหมาะ
- ถ้าความปวดใจหลักคือความสับสนส่วนตัว (“ฉันบันทึกแล้ว—ทำไมฉันไม่เห็น?”) ให้เน้น read-your-writes และ monotonic reads
ความสอดคล้องคือการตัดสินใจเชิงผลิตภัณฑ์: นิยามว่าอะไรคือ “ผิด” สำหรับผู้ใช้ แล้วเลือกการรับประกันที่อ่อนที่สุดที่ป้องกันความผิดนั้น
ความพร้อมใช้งานเป็นการตัดสินใจเชิงผลิตภัณฑ์ ไม่ใช่แค่ตัวเลข uptime
รักษาแหล่งที่มาของคุณไว้
สร้าง ทบทวน และส่งออกซอร์สโค้ดเพื่อคงการควบคุมสถาปัตยกรรมไว้ที่คุณ
ความพร้อมใช้งานใน CAP ไม่ใช่การโอ้อวด (“five nines”)—มันคือคำสัญญาที่คุณให้ผู้ใช้เกี่ยวกับสิ่งที่จะเกิดขึ้นเมื่อระบบไม่สามารถแน่ใจได้
ความสำเร็จที่เร็ว vs ความสำเร็จที่ถูกต้อง
เมื่อ replica ไม่เห็นพ้องกัน คุณมักเลือกระหว่าง:
- ความสำเร็จที่เร็ว: คืน บางอย่าง อย่างรวดเร็ว (แม้อาจล้าหลัง)
- ความสำเร็จที่ถูกต้อง: คืนเฉพาะเมื่อพิสูจน์ได้ว่าคำตอบเป็นปัจจุบัน
ผู้ใช้รับรู้เป็น “แอปใช้งานได้” เทียบกับ “แอปถูกต้อง” ไม่มีแบบไหนดีกว่าตลอดไป ขึ้นกับว่า “ผิด” มีความหมายอย่างไรในผลิตภัณฑ์ของคุณ ยอดคงเหลือที่ล้าหลังอาจทำให้เสียหาย ขณะที่ฟีดที่ล้าหลังแค่รบกวน
“ปิดเมื่อไม่แน่นอน” vs “เปิดเมื่อไม่แน่นอน”
สองพฤติกรรมที่พบบ่อยในช่วงความไม่แน่นอน:
- ปิดเมื่อไม่แน่นอน (Fail closed): ปฏิเสธคำขอ (error, timeout, โหมดอ่านอย่างเดียว). ปกป้องความถูกต้อง แต่ผู้ใช้อาจถูกบล็อก
- เปิดเมื่อไม่แน่นอน (Fail open): ให้ผลลัพธ์ตามความพยายาม (ข้อมูลแคช, replica ท้องถิ่น, queued write). ปกป้องการไหล แต่แสดงผลที่อาจไม่สอดคล้อง
นี่ไม่ใช่การตัดสินใจเชิงเทคนิคล้วน ผลิตภัณฑ์ต้องกำหนดว่าอะไรยอมรับได้และอะไรห้ามเดา
ความพร้อมใช้งานบางส่วนก็ยังนับว่าเป็นความพร้อมใช้งาน
ความพร้อมใช้งานไม่ค่อยเป็นแบบทั้งหมดหรือไม่มีเลย ในช่วงการแยก คุณอาจเห็น ความพร้อมใช้งานแบบบางส่วน: บางภูมิภาค เครือข่าย หรือกลุ่มผู้ใช้สำเร็จ ในขณะที่อื่นล้มเหลว นี่อาจเป็นการออกแบบโดยตั้งใจ (ให้บริการในที่ที่ replica ท้องถิ่นแข็งแรง) หรือเป็นผลข้างเคียง (routing ไม่สมดุล ขนาดควอรัมไม่เท่ากัน)
โหมดถดถอย: เก็บแกนหลักไว้ ลดความเสี่ยง
ทางสายกลางที่ใช้ได้จริงคือ โหมดถดถอย: ให้บริการการกระทำที่ปลอดภัยในขณะที่จำกัดการกระทำที่เสี่ยง ตัวอย่างเช่น อนุญาตการเรียกดูและค้นหา แต่ปิดการ “โอนเงิน” “เปลี่ยนรหัสผ่าน” หรือการดำเนินการอื่นที่ความถูกต้องและเอกลักษณ์สำคัญ
ตัวอย่างที่จับต้องได้: จับคู่การเลือก CAP กับกรณีใช้งาน
CAP มักดูเป็นนามธรรมจนกว่าคุณจะจับมันกับสิ่งที่ผู้ใช้เจอในช่วงการแยก: คุณต้องการให้ระบบยังตอบหรือให้หยุดและหลีกเลี่ยงการคืน/รับข้อมูลขัดแย้ง?
สต็อกและการสั่งซื้อ: ความเสี่ยงการขายเกิน vs การล่มของเช็คเอาต์
นึกภาพสองศูนย์ข้อมูลรับคำสั่งพร้อมกันขณะที่คุยกันไม่ได้
ถ้าคุณให้เช็คเอาต์ พร้อมใช้งาน แต่ละฝั่งอาจขายชิ้นสุดท้ายและคุณจะขายเกิน นี่อาจรับได้สำหรับของราคาต่ำ (คุณสั่งสินค้าขาดหรือขอโทษ) แต่เจ็บปวดสำหรับการวางจำหน่ายสินค้ามีจำกัด
ถ้าคุณเลือก เน้นความสอดคล้อง คุณอาจบล็อกคำสั่งใหม่เมื่อไม่สามารถยืนยันสต็อกทั่วโลก ผู้ใช้เห็น “ลองอีกครั้งภายหลัง” แต่คุณหลีกเลี่ยงการขายสินค้าที่ให้ไม่ได้
การชำระเงินและยอดคงเหลือ: รูปแบบเน้นถูกต้อง (และทำไม)
เงินคือโดเมนคลาสสิกที่ “ผิดแล้วแพง” ถ้าสอง replica ยอมรับการถอนพร้อมกันในช่วงพาร์ติชัน บัญชีอาจติดลบ
ระบบมักเลือก ความสอดคล้องในเขียนที่สำคัญ: ปฏิเสธหรือหน่วงการทำงานถ้าไม่สามารถยืนยันยอดล่าสุด คุณจะแลกความพร้อมใช้งานบางส่วนเพื่อความถูกต้อง การตรวจสอบ และความเชื่อถือ
แชท ฟีด การวิเคราะห์: พร้อมใช้งานกับข้อมูลช้าเป็นที่ยอมรับ
ในแชทและฟีดโซเชียล ผู้ใช้โดยมากทนต่อความไม่ลงรอยเล็กน้อย: ข้อความมาช้าหลายวินาที จำนวนไลก์เพี้ยน ตัวชี้วัดอัปเดตช้า
ที่นี่การออกแบบให้ เน้นความพร้อมใช้งาน มักเหมาะ ตราบใดที่คุณชัดเจนว่าส่วนไหนจะ “ถูกต้องในที่สุด” และสามารถรวมอัพเดตได้อย่างสะอาด
ข้อสรุป: การแลกเปลี่ยนคือการตัดสินใจเชิงธุรกิจ
การเลือก CAP ที่ “ถูกต้อง” ขึ้นกับ ต้นทุนของการผิดพลาด: คืนเงิน ความเสี่ยงทางกฎหมาย ความเชื่อใจผู้ใช้ หรือความโกลาหลในการปฏิบัติการ ตัดสินใจว่าคุณยอมรับความล่าช้าชั่วคราวที่ไหน และที่ไหนต้องปิดเมื่อไม่แน่นอน
รูปแบบการออกแบบที่ทำให้การแลกเปลี่ยนของคุณเป็นจริง
ดูพฤติกรรมในการรันใกล้ของจริง
ปรับใช้โปรโตไทป์และสังเกตว่าการตั้งค่า timeout และ fallback เปลี่ยนความรู้สึกของความพร้อมใช้งานอย่างไร
เมื่อคุณตัดสินใจว่าจะทำอย่างไรในช่วงพาร์ติชัน คุณต้องมีกลไกที่ทำให้การตัดสินใจนั้นเป็นจริง รูปแบบเหล่านี้พบได้ในฐานข้อมูล ระบบข้อความ และ API — แม้ผลิตภัณฑ์จะไม่เอ่ยถึง “CAP” ก็ตาม
ควอรัม: ข้อยุติของเสียงส่วนใหญ่
ควอรัมคือ “ส่วนใหญ่ของ replica เห็นด้วย” ถ้าคุณมีสำเนา 5 ตัว ส่วนใหญ่คือ 3
โดยการบังคับให้การอ่าน/เขียนต้องติดต่อ majority คุณลดโอกาสที่จะคืนข้อมูลล้าหลังหรือมีสถานะขัดแย้ง ตัวอย่าง: ถ้าการเขียนต้องได้รับการยืนยันจาก 3 replica จะยากที่สองกลุ่มแยกจากกันจะยอมรับความจริงต่างกัน
การแลกเปลี่ยนคือความเร็วและการเข้าถึง: ถ้าคุณเข้าถึง majority ไม่ได้ (เพราะพาร์ติชันหรือ outage) ระบบอาจปฏิเสธการทำงาน—เลือกความสอดคล้องมากกว่าความพร้อมใช้งาน
Timeout, retry และ backoff กำหนดความรู้สึกของความพร้อมใช้งาน
ปัญหาความพร้อมใช้งานหลายเรื่องไม่ใช่ล้มเหลวจริง แต่เป็นการตอบช้า การตั้ง timeout สั้นทำให้ระบบรู้สึกเร็ว แต่เพิ่มโอกาสที่คุณจะมองความสำเร็จที่ช้าเป็นความล้มเหลว
การ retry ช่วยกู้คืนจากปัญหาชั่วคราว แต่ retry เข้มข้นอาจท่วมบริการที่กำลังลำบาก Backoff (รอให้ยาวขึ้นระหว่าง retry) และ jitter (ความสุ่ม) ช่วยให้ retry ไม่กลายเป็นพายกระแทกทราฟฟิก
กุญแจคือตั้งค่าพวกนี้ให้สอดคล้องกับคำสัญญาของคุณ: “ตอบเสมอ” มักหมายถึง retry มากและ fallback ต่าง ๆ; “ไม่โกหก” มักหมายถึงขอบเขตเข้มและข้อความข้อผิดพลาดชัดเจน
การจัดการความขัดแย้งเมื่อคุณยอมให้เบี่ยงเบน
ถ้าคุณเลือกให้พร้อมใช้งานในพาร์ติชัน replica อาจรับอัพเดตต่างกันและคุณต้องรวมผลภายหลัง วิธีที่พบบ่อยได้แก่:
- Last-write-wins (LWW): เลือกอัพเดตที่มี timestamp ล่าสุด ง่ายแต่ทิ้งการเปลี่ยนแปลงที่ยังมีคุณค่าได้ถ้านาฬิกาไม่ตรง
- Version vectors (ภาพรวมระดับสูง): แนบ “ประวัติ” เล็กน้อยที่ช่วยตรวจสอบว่าการอัพเดตเป็น concurrent หรือถูกแทนที่
- กฎผสาน: กำหนดวิธีรวมการเปลี่ยนแปลง (เช่น union สำหรับตะกร้าสินค้า; ตัวนับบวก; โปรไฟล์เลือกช่องที่ไม่ว่าง) ซึ่งมักเวิร์กดีเมื่อออกแบบเข้าไปในโมเดลข้อมูลตั้งแต่แรก
Idempotency: ทำให้ retry ปลอดภัย
การ retry อาจก่อให้เกิดการทำซ้ำ เช่น เก็บเงินซ้ำหรือส่งคำสั่งซ้ำ Idempotency ป้องกันสิ่งนั้น
รูปแบบทั่วไปคือ idempotency key (request ID) ส่งมาพร้อมคำขอ เซิร์ฟเวอร์เก็บผลลัพธ์แรกและคืนผลเดิมสำหรับคำขอซ้ำ—ดังนั้น retry เพิ่มความพร้อมใช้งานโดยไม่ทำลายข้อมูล
วิธีตรวจสอบสมมติฐาน CAP ในชีวิตจริง
ทีมส่วนใหญ่ “เลือก” แนวทาง CAP บนไวท์บอร์ด—แล้วค้นพบในโปรดักชันว่าระบบทำงานต่างออกไป การตรวจสอบหมายถึงการสร้างเงื่อนไขที่ทำให้การแลกเปลี่ยน CAP ปรากฏ และตรวจว่าระบบตอบสนองตามที่ออกแบบหรือไม่
ทดสอบพาร์ติชันโดยตั้งใจ (อย่างปลอดภัย)
คุณไม่ต้องตัดสายเคเบิ้ลจริงเพื่อเรียนรู้ ใช้ fault injection ที่ควบคุมได้ในสเตจ (และระมัดระวังในโปรดักชัน) เพื่อจำลองพาร์ติชัน:
- Blackhole ทราฟฟิก ระหว่างบริการหรือโหนดที่เจาะจง (ทิ้งแพ็กเก็ตโดยไม่ปิดการเชื่อมต่อ) เพื่อเลียนแบบการแยกเงียบ
- ตัดลิงก์ โดยบล็อกพอร์ตหรือกฎ security group ระหว่าง replica/ภูมิภาค
- เพิ่ม latency และ packet loss ขั้นรุนแรง ให้ timeout และ retry ทำงานเหมือนพาร์ติชัน
- แยกผู้นำ (เช่น แยก primary ออกจาก quorum) เพื่อดูว่าคุณจะล้ม “สอดคล้อง” หรือ “พร้อมใช้งาน”
เป้าหมายคือตอบคำถามที่จับต้องได้: การเขียนถูกปฏิเสธหรือรับ? การอ่านให้ข้อมูลล้าหลังหรือไม่? ระบบกู้คืนเองได้เท่าไร และการรวมผลใช้เวลานานเท่าไร?
ถ้าต้องการตรวจพฤติกรรมแต่เนิ่น ๆ (ก่อนเสียเวลาต่อระบบจริงจัง) การสร้างโปรโตไทป์เล็ก ๆ ช่วยได้ ทีมที่ใช้ Koder.ai มักเริ่มจากการสร้างเซอร์วิสตัวอย่างอย่างรวดเร็ว (เช่น backend Go กับ PostgreSQL และ UI React) แล้วทดลองพฤติกรรมเช่น retry, idempotency key, และโฟลว์โหมดถดถอยในสภาพแวดล้อมแซนด์บอกซ์
มอนิเตอร์สัญญาณที่เผยความเจ็บของ CAP
การเช็ค uptime แบบเดิมจะไม่จับพฤติกรรม “พร้อมใช้งานแต่ผิด” ตรวจจับ:
- อัตราข้อผิดพลาดแยกตามชนิดการทำงาน (อ่าน vs เขียน vs การอัพเดตมีเงื่อนไข)
- ตัวชี้วัด stale-read (การละเมิด read-your-writes, เวอร์ชัน/ETag ไม่ตรง, lag)
- การเบี่ยงเบนของสำเนา (replication lag, failed apply counts, conflict rates)
- timeout และ retry (มักเป็นสัญญาณแรกของการแยกที่กำลังเกิด)
Runbook และการสื่อสารกับผู้ใช้
ผู้ปฏิบัติการต้องมีการตัดสินใจล่วงหน้าเมื่อพาร์ติชันเกิด: เมื่อจะ แช่การเขียน, เมื่อจะ fail over, เมื่อจะ ลดฟีเจอร์, และวิธี ตรวจสอบความปลอดภัยของการรวมผล
วางแผนข้อความต่อผู้ใช้ด้วย หากคุณเลือกความสอดคล้อง ข้อความอาจเป็น “เราไม่สามารถยืนยันการอัพเดตของคุณตอนนี้—กรุณาลองอีกครั้ง” ถ้าเลือกความพร้อมใช้งาน ให้ชัดเจน: “การอัพเดตของคุณอาจใช้เวลาสักครู่กว่าจะปรากฏทั่วระบบ” คำพูดชัดเจนลดภาระสนับสนุนและรักษาความเชื่อใจ
คำถามที่พบบ่อย
CAP ช่วยวิศวกรคิดถึงปัญหาอะไร?
CAP เป็นกรอบความคิดสำหรับ ระบบที่ทำสำเนาข้อมูลเมื่อเกิดความล้มเหลวในการสื่อสาร. มันมีประโยชน์ที่สุดเมื่อตัวเครือข่ายช้า สูญหาย หรือแบ่งกันไม่ได้ เพราะนั่นคือเวลาที่สำเนาไม่สามารถตกลงกันได้และคุณถูกบังคับให้เลือกระหว่าง:
- ความสอดคล้อง (Consistency): ทุกคนเห็นค่าล่าสุดเดียวกัน
- ความพร้อมใช้งาน (Availability): ระบบยังคงตอบคำขอสำเร็จ
มันช่วยเปลี่ยนคำพูดคลุมเครือว่า “ระบบกระจายยาก” ให้เป็นการตัดสินใจทางผลิตภัณฑ์และวิศวกรรมที่ชัดเจน.
เมื่อไหร่ที่ผมอยู่ในสถานการณ์ CAP จริงๆ?
สถานการณ์ CAP ที่แท้จริงต้องมี ทั้ง:
- การทำสำเนา (มากกว่าหนึ่งโหนดที่ให้บริการ/รับคำสั่งสำหรับข้อมูลเดียวกัน)
- โอกาสสมเหตุสมผลของ ความล้มเหลวในการสื่อสาร (พาร์ติชัน, timeout, ความล่าช้า)
ถ้าระบบของคุณเป็นโหนดเดียว หรือไม่ทำสำเนาสถานะ การแลกเปลี่ยน CAP จะไม่ใช่ประเด็นหลัก.
อะไรนับว่าเป็นพาร์ติชันในระบบจริง?
พาร์ติชันคือสถานการณ์ที่บางส่วนของระบบไม่สามารถสื่อสาร อย่างเชื่อถือได้หรือภายในเวลาที่ต้องการ — แม้ว่าแต่ละเครื่องยังทำงานได้ปกติ
เชิงปฏิบัติ “พาร์ติชัน” มักแสดงออกมาเป็น:
- ดีเลย์ของ latency ที่ทำให้เกิด timeout
- แพ็กเก็ตถูกทิ้ง/blackholed
- การตั้งค่า firewall หรือ routing ผิดพลาด
- โหนดล้นจนไม่ตอบสนองทันเวลา
จากมุมมองของแอป “ช้ามากพอ” อาจเท่ากับ “ล้มเหลว”.
ในเชิงผู้ใช้ ความแตกต่างระหว่างความสอดคล้องกับความพร้อมใช้งานคืออะไร?
ความสอดคล้อง (C) หมายถึงการอ่านสะท้อนการเขียนล่าสุดที่ได้รับการยอมรับจากทุกที่ ผู้ใช้จะเห็นเป็น “ฉันเปลี่ยนแล้ว และทุกคนเห็นค่าใหม่”
ความพร้อมใช้งาน (A) หมายถึงทุกคำขอจะได้รับการตอบกลับสำเร็จ (ไม่จำเป็นต้องเป็นข้อมูลใหม่ที่สุด) ผู้ใช้จะรู้สึกว่า “แอปยังทำงาน” แม้อาจได้ผลลัพธ์ที่เก่า
ในช่วงพาร์ติชัน คุณโดยทั่วไปไม่สามารถรับประกันทั้งสองพร้อมกันสำหรับทุกการทำงานได้.
ทำไมผมไม่สามารถเลือกทั้งความสอดคล้องและความพร้อมใช้งานแล้วเพิกเฉยพาร์ติชันได้?
เพราะพาร์ติชัน ไม่ใช่ตัวเลือก ในระบบกระจายที่มีหลายเครื่อง ถ้าคุณทำสำเนา คุณต้องกำหนดพฤติกรรมเมื่อโหนดไม่สามารถประสานกันได้
โดยปกติ “ยอมรับพาร์ติชัน” หมายถึง: เมื่อการสื่อสารพัง ระบบยังต้องมีวิธีชัดเจนจะทำงานต่อ—จะปฏิเสธ/พักการกระทำบางอย่าง (เน้นความสอดคล้อง) หรือจะให้ผลตอบแทนแบบพยายามดีที่สุด (เน้นความพร้อมใช้งาน).
การเลือกแบบเน้นความสอดคล้อง (CP) ในช่วงพาร์ติชันเป็นอย่างไร?
ถ้าคุณเลือก เน้นความสอดคล้อง คุณมักจะ:
- ปฏิเสธหรือหน่วงการดำเนินการเมื่อไม่สามารถยืนยันความเห็นพ้อง
- ต้องการ quorum/majority สำหรับการอ่าน/เขียน
- แสดงข้อผิดพลาดเช่น timeout, “ลองอีกครั้ง”, หรือโหมดอ่านอย่างเดียว
รูปแบบนี้พบได้บ่อยในงานที่ความผิดพลาดมีค่าแพง เช่น การเงิน การจองสต็อก หรือการเปลี่ยนสิทธิ์ ที่การถูกต้องสำคัญกว่าการให้บริการต่อเนื่อง.
การเลือกแบบเน้นความพร้อมใช้งาน (AP) ในช่วงพาร์ติชันเป็นอย่างไร?
ถ้าคุณเลือก เน้นความพร้อมใช้งาน คุณมักจะ:
- ยังคงรับอ่าน/เขียนในแต่ละฝั่งของพาร์ติชัน
- อนุญาตให้สำเนาเบี่ยงเบนชั่วคราว
- รวมผล/ปรับความขัดแย้งภายหลัง (กฎผสาน, การแก้ความขัดแย้ง, ตรวจคน)
ผู้ใช้จะเห็นข้อผิดพลาดน้อยลง แต่ข้อมูลอาจล้าหลัง เกิดเอฟเฟกต์ซ้ำหากไม่มี idempotency หรืออัพเดตขัดแย้งที่ต้องทำความสะอาดหลังเหตุการณ์.
ผมสามารถผสมการเลือกความสอดคล้องและความพร้อมใช้งานตามการทำงานได้ไหม?
ได้ — คุณสามารถเลือกต่างกันตาม endpoint หรือประเภทข้อมูล ยุทธศาสตร์ผสมที่พบบ่อย ได้แก่:
- อ่านยังคงพร้อม ใช้เขียนเข้มขึ้น (การเรียกดูทำงานได้; การอัพเดตเสี่ยงอาจล้มเหลว)
- การกระทำที่สำคัญถูกปิด (การชำระเงิน สต็อก การพิสูจน์ตัวตน) ในขณะที่ฟีเจอร์ความเสี่ยงต่ำเปิดไว้ (ฟีด, การวิเคราะห์)
- โหมดถดถอย: เปิดการกระทำที่ปลอดภัย และปิดการกระทำที่เสี่ยงชั่วคราว
วิธีนี้หลีกเลี่ยงการติดป้ายระบบเป็น AP/CP เพียงอย่างเดียว ซึ่งมักไม่สอดคล้องกับความต้องการของผลิตภัณฑ์จริง ๆ.
ผมเลือกการรับประกันความสอดคล้องอะไรได้บ้าง นอกเหนือจาก “แข็งแรง” และ “ในที่สุด”?
ตัวเลือกที่มีประโยชน์นอกจาก “แข็งแรง” กับ “สุดท้ายแล้วสอดคล้อง” ได้แก่:
ผมทดสอบและมอนิเตอร์พฤติกรรม CAP ในทางปฏิบัติอย่างไร?
ตรวจสอบโดยสร้างเงื่อนไขที่ทำให้ความไม่ลงรอยเห็นได้ชัด:
- จำลองพาร์ติชัน/ความหน่วงในสเตจ (และอย่างระมัดระวังในโปรดักชัน): blackhole ทราฟฟิก, บล็อกพอร์ต, เพิ่ม latency/packet loss
- ยืนยันพฤติกรรม: เขียนถูกปฏิเสธหรือยอมรับไหม? อ่านล้าหลังหรือเปล่า? การกู้คืน/การรวมผลทำงานอย่างไร?
- ตรวจวัดสัญญาณนอกการตรวจ uptime แบบเดิม:
- อัตราข้อผิดพลาดแยกตามชนิดการทำงาน (อ่าน vs เขียน)