24 ส.ค. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับการ onboard ผู้ใช้หลายขั้นตอน
เรียนรู้การออกแบบและพัฒนาเว็บแอปเพื่อสร้าง ติดตาม และปรับปรุงกระบวนการ onboarding แบบหลายขั้นตอน พร้อมขั้นตอนชัดเจน โมเดลข้อมูล และแนวทางการทดสอบ
เรียนรู้การออกแบบและพัฒนาเว็บแอปเพื่อสร้าง ติดตาม และปรับปรุงกระบวนการ onboarding แบบหลายขั้นตอน พร้อมขั้นตอนชัดเจน โมเดลข้อมูล และแนวทางการทดสอบ
การ onboarding หลายขั้นตอน คือชุดหน้าจอที่นำทางผู้ใช้ใหม่จากสถานะ “สมัครแล้ว” ไปสู่การ “พร้อมใช้งานผลิตภัณฑ์” แทนที่จะขอข้อมูลทั้งหมดในครั้งเดียว คุณจะแบ่งการตั้งค่าเป็นขั้นตอนย่อย ๆ ที่ผู้ใช้สามารถทำให้เสร็จในการนั่งครั้งเดียวหรือค่อย ๆ ทำเมื่อสะดวก
คุณต้องใช้ onboarding หลายขั้นตอนเมื่อการตั้งค่ามากกว่าแบบฟอร์มเดียว—โดยเฉพาะเมื่อต้องมีทางเลือก ข้อกำหนดล่วงหน้า หรือตรวจสอบการปฏิบัติตาม หากผลิตภัณฑ์ของคุณต้องการบริบท (อุตสาหกรรม บทบาท ความชอบ), การยืนยัน (อีเมล/โทรศัพท์/ตัวตน), หรือการกำหนดค่าเริ่มต้น (workspace, billing, integrations) การแยกเป็นขั้นตอนจะทำให้ทุกอย่างเข้าใจได้ง่ายและลดความผิดพลาด
Onboarding หลายขั้นตอนพบได้ทั่วไปเพราะรองรับงานที่เกิดขึ้นเป็นลำดับ เช่น:
การ onboarding ที่ดีไม่ใช่แค่ "หน้าจอเสร็จ" แต่คือการที่ผู้ใช้ได้รับคุณค่าอย่างรวดเร็ว กำหนดความสำเร็จด้วยตัวชี้วัดที่สอดคล้องกับผลิตภัณฑ์ของคุณ:
Flow ควรรองรับ การกลับมาต่อ: ผู้ใช้สามารถออกแล้วกลับมาโดยไม่เสียความคืบหน้า และพวกเขาควรไปยังขั้นตอนถัดไปที่สมเหตุสมผล
Onboarding หลายขั้นตอนล้มเหลวในรูปแบบที่คาดเดาได้:
เป้าหมายของคุณคือทำให้ onboarding รู้สึกเหมือนเส้นทางที่มีคนแนะนำ ไม่ใช่การทดสอบ: ให้แต่ละขั้นตอนมีจุดประสงค์ที่ชัดเจน การติดตามความคืบหน้าเชื่อถือได้ และวิธีที่ง่ายสำหรับผู้ใช้ในการกลับมาต่อ
ก่อนจะวาดหน้าจอหรือเขียนโค้ด ให้ตัดสินใจว่า onboarding พยายามทำอะไร—และสำหรับใคร Flow หลายขั้นตอนจะดีเฉพาะเมื่อมันพาผู้คนที่ถูกต้องไปยังสถานะสุดท้ายที่ถูกต้องโดยมีความสับสนน้อยที่สุด
ผู้ใช้ต่างคนต่างมาพร้อมบริบท สิทธิ์ และความเร่งด่วนที่ต่างกัน เริ่มจากตั้งชื่อ persona เข้าสู่ระบบหลักและสิ่งที่รู้เกี่ยวกับพวกเขา:
สำหรับแต่ละประเภท ให้ระบุข้อจำกัด (เช่น “แก้ชื่อบริษัทไม่ได้”), ข้อมูลที่ต้องการ (เช่น “ต้องเลือก workspace”), และช็อตคัตที่เป็นไปได้ (เช่น “ยืนยันแล้วผ่าน SSO”)
สถานะสุดท้ายของการ onboarding ควรชัดเจนและวัดค่าได้ “เสร็จ” ไม่ใช่แค่ “ทำทุกหน้าจอครบ” แต่เป็นสถานะพร้อมทางธุรกิจ เช่น:
เขียนเกณฑ์การเสร็จเป็นเช็กลิสต์ที่ backend สามารถประเมินได้ ไม่ใช่เป้าหมายที่คลุมเครือ
แผนที่ขั้นตอนว่าอันไหน จำเป็น และอันไหน เสริม แล้วจด dependencies (เช่น “เชิญเพื่อนร่วมทีมไม่ได้จนกว่า workspace จะมีอยู่”)
สุดท้าย นิยามกฎการข้ามอย่างชัดเจน: ขั้นตอนไหนข้ามได้ โดย user type ใด และภายใต้เงื่อนไขอะไร (เช่น “ข้ามการยืนยันอีเมลถ้าผ่าน SSO”) และขั้นตอนที่ข้ามสามารถกลับไปทำได้ภายหลังใน settings หรือไม่
ก่อนสร้างหน้าจอหรือ API ให้วาด onboarding เป็น flow map: แผนภาพเล็ก ๆ ที่แสดงทุกขั้นตอน ที่ผู้ใช้ไปต่อได้ และวิธีกลับมาทีหลัง
เขียนชื่อขั้นตอนเป็นสั้น ๆ และเน้นการกระทำ (คำกริยาช่วย): “สร้างรหัสผ่าน,” “ยืนยันอีเมล,” “เพิ่มรายละเอียดบริษัท,” “เชิญเพื่อนร่วมทีม,” “เชื่อม billing,” “เสร็จ” ให้พิจารณาง่าย ๆ ก่อน แล้วค่อยเพิ่มรายละเอียดอย่างฟิลด์ที่ต้องการและ dependencies (เช่น billing ต้องมีการเลือกแผนก่อน)
เช็คลิสต์ที่ช่วยได้: ทุกขั้นตอนควรตอบคำถามหนึ่งข้อ—“คุณคือใคร?” “คุณต้องการอะไร?” หรือ “ผลิตภัณฑ์ควรถูกกำหนดค่าอย่างไร?” ถ้าขั้นตอนพยายามตอบทั้งสาม ให้แยกออก
ผลิตภัณฑ์ส่วนใหญ่ได้ประโยชน์จาก backbone ที่เป็นเส้นตรงพร้อม สาขาเชิงเงื่อนไข เมื่อประสบการณ์แตกต่างจริง ๆ กฎสาขาทั่วไป:
จดเป็นบันทึก “if/then” บนแผนผัง (เช่น “If region = EU → show VAT step”) เพื่อให้ flow เข้าใจง่ายและหลีกเลี่ยงการสร้างเขาวงกต
ลิสต์ทุกที่ที่ผู้ใช้อาจเข้า flow:
/settings/onboarding)แต่ละจุดควรนำผู้ใช้ไปยัง ขั้นตอนถัดไปที่เหมาะสม ไม่ใช่กลับไปที่ขั้นตอนหนึ่งเสมอ
สมมติว่าผู้ใช้จะออกกลางขั้นตอน ตัดสินใจว่าตอนกลับมาจะเกิดอะไรขึ้น:
แผนผังของคุณควรแสดงเส้นทาง “resume” ให้ชัดเจนเพื่อให้ประสบการณ์รู้สึกเชื่อถือได้ ไม่ใช่เปราะบาง
การ onboarding ที่ดีควรรู้สึกเหมือนเส้นทางที่มีคนแนะนำ ไม่ใช่การทดสอบ เป้าหมายคือ ลดความเหนื่อยใจจากการตัดสินใจ ทำให้ความคาดหวังชัดเจน และช่วยผู้ใช้กู้คืนเมื่อเกิดปัญหาได้ง่าย
Wizard เหมาะเมื่อขั้นตอนต้องทำตามลำดับ (เช่น ตัวตน → billing → สิทธิ์) Checklist เหมาะเมื่อทำได้หลายขั้นตอนตามลำดับใดก็ได้ (เช่น “เพิ่มโลโก้,” “เชิญเพื่อนร่วมทีม,” “เชื่อมปฏิทิน”) Guided tasks (คำแนะนำฝังในผลิตภัณฑ์) ดีเมื่อการเรียนรู้เกิดจากการทำ ไม่ใช่การกรอกฟอร์ม
ถ้าไม่แน่ใจ ให้เริ่มด้วย checklist + deep links ไปยังแต่ละงาน แล้วบล็อกเฉพาะขั้นตอนที่จำเป็นจริง ๆ
การตอบกลับความคืบหน้าควรตอบว่า “เหลือเท่าไร?” ใช้หนึ่งในรูปแบบต่อไปนี้:
นอกจากนี้ให้เพิ่มสัญลักษณ์ “บันทึกและทำต่อทีหลัง” โดยเฉพาะสำหรับ flow ที่ยาว
ใช้ป้ายที่เข้าใจง่าย (“ชื่อธุรกิจ” ไม่ใช่ “Entity identifier”) เพิ่ม microcopy อธิบาย เหตุผล ที่ขอข้อมูล (“เราจะใช้ข้อมูลนี้เพื่อปรับใบแจ้งหนี้ให้ตรงกับคุณ”) หากเป็นไปได้ ให้เติมค่าเริ่มต้นจากข้อมูลที่มีอยู่และเลือกค่าที่ปลอดภัย
ออกแบบข้อผิดพลาดเป็นเส้นทางต่อไป: เน้นฟิลด์ที่ผิดอธิบายว่าต้องทำอย่างไร เก็บอินพุตของผู้ใช้ และโฟกัสที่ฟิลด์ที่ผิดพลาดแรก สำหรับความล้มเหลวฝั่งเซิร์ฟเวอร์ ให้แสดงตัวเลือก retry และเก็บความคืบหน้าเพื่อไม่ให้ผู้ใช้ทำซ้ำขั้นตอนที่เสร็จแล้ว
ทำให้เป้าหมายการแตะใหญ่ หลีกเลี่ยงฟอร์มหลายคอลัมน์ และเก็บปุ่มสำคัญให้มองเห็นได้ตลอด เรียนรู้การนำทางด้วยคีย์บอร์ดที่ครบถ้วน สถานะโฟกัสที่มองเห็นได้ และข้อความความคืบหน้าเป็นมิตรสำหรับหน้าจออ่าน (ไม่ใช่แถบภาพอย่างเดียว)
Flow onboarding ที่ราบรื่นขึ้นอยู่กับโมเดลข้อมูลที่ตอบคำถามสามข้อได้อย่างเชื่อถือได้: ผู้ใช้ควรเห็นอะไรต่อไป, พวกเขาให้ข้อมูลอะไรไปแล้ว, และ พวกเขากำลังใช้คำนิยามของ flow รุ่นใด
เริ่มจากชุดตาราง/คอลเลกชันเล็ก ๆ แล้วขยายเมื่อจำเป็น:
การแยกส่วนนี้ช่วยให้ “การกำหนดค่า” (Flow/Step) แยกจาก “ข้อมูลผู้ใช้” (StepResponse/Progress)
ตัดสินใจตั้งแต่ต้นว่า flow จะ มีเวอร์ชัน หรือไม่ ในผลิตภัณฑ์ส่วนใหญ่คำตอบคือใช่
เมื่อคุณแก้ไขขั้นตอน (เปลี่ยนชื่อ, จัดลำดับใหม่, เพิ่มฟิลด์บังคับ) คุณไม่ต้องการให้ผู้ใช้ที่กำลังทำงานอยู่ล้มเหลวแบบทันที วิธีง่าย ๆ คือ:
id และ version (หรือ flow_version_id ที่ไม่เปลี่ยนแปลง)flow_version_id เฉพาะเสมอสำหรับการบันทึกความคืบหน้า ให้เลือกระหว่าง autosave (บันทึกขณะพิมพ์) กับ บันทึกเมื่อกด Next หลายทีมผสมทั้งสอง: autosave เป็นร่าง แต่ทำเครื่องหมายขั้นตอนว่า “complete” เมื่อกด Next
ติดตาม timestamps เพื่อการรายงานและแก้ปัญหา: started_at, completed_at, และ last_seen_at (รวมถึง per-step saved_at) ฟิลด์เหล่านี้ช่วยขับเคลื่อนการวิเคราะห์ onboarding และช่วยทีมสนับสนุนเข้าใจว่าผู้ใช้ติดที่ไหน
Flow การ onboarding หลายขั้นตอนจะเข้าใจง่ายที่สุดเมื่อคุณมองเป็น state machine: เซสชัน onboarding ของผู้ใช้จะอยู่ใน “สถานะ” หนึ่งเสมอ (ขั้นตอนปัจจุบัน + สถานะ) และอนุญาตให้มีการเปลี่ยนสถานะเฉพาะเท่านั้น
แทนที่จะปล่อยให้ frontend กระโดดไปที่ URL ใดก็ได้ ให้กำหนดชุดสถานะต่อขั้นตอน (เช่น: not_started → in_progress → completed) และชุดการเปลี่ยนสถานะที่ชัดเจน (เช่น: start_step, save_draft, submit_step, go_back, reset_step)
นี่ให้พฤติกรรมที่คาดเดาได้:
ขั้นตอนจะถือว่า “completed” ก็ต่อเมื่อ ทั้งสองเงื่อนไข ผ่าน:
เก็บการตัดสินใจจากเซิร์ฟเวอร์ไว้พร้อมรหัสข้อผิดพลาดใด ๆ เพื่อหลีกเลี่ยงกรณีที่ UI คิดว่าขั้นตอนเสร็จ แต่ backend ไม่เห็นด้วย
ขอบเขตที่มักถูกมองข้าม: ผู้ใช้แก้ไขขั้นตอนก่อนหน้าและทำให้ขั้นตอนถัดไปผิด ตัวอย่าง: เปลี่ยน “ประเทศ” อาจทำให้ “รายละเอียดภาษี” หรือ “แผนที่ใช้ได้” ไม่ถูกต้อง
จัดการโดยติดตาม dependencies และประเมินผล downstream steps ใหม่หลังจากแต่ละครั้งที่ส่งผลลัพธ์ ผลลัพธ์ทั่วไป:
needs_review (หรือย้อนเป็น in_progress)ควรสนับสนุน “ย้อนกลับ” แต่ต้องปลอดภัย:
นี่ทำให้ประสบการณ์ยืดหยุ่นแต่ยังคงสภาพของเซสชันสอดคล้องและบังคับใช้ได้
API ฝั่งเซิร์ฟเวอร์คือ “แหล่งความจริง” ว่าผู้ใช้อยู่ที่ขั้นตอนไหนใน onboarding พวกเขาให้ข้อมูลอะไรแล้ว และพวกเขาทำอะไรต่อได้บ้าง API ที่ดีทำให้ frontend ง่าย: เรนเดอร์ขั้นตอนปัจจุบัน ส่งข้อมูลอย่างปลอดภัย และกู้คืนหลังรีเฟรชหรือปัญหาเครือข่าย
อย่างน้อยควรออกแบบสำหรับการกระทำเหล่านี้:
GET /api/onboarding → คืนค่า key ของขั้นตอนปัจจุบัน, เปอร์เซ็นต์ความคืบหน้า, และค่าร่างที่บันทึกไว้เพื่อเรนเดอร์ขั้นตอนPUT /api/onboarding/steps/{stepKey} พร้อม { "data": {…}, "mode": "draft" | "submit" }POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previousPOST /api/onboarding/complete (เซิร์ฟเวอร์ตรวจสอบว่าทุกขั้นตอนที่จำเป็นถูกตอบครบ)รักษาความสม่ำเสมอของการตอบกลับ ตัวอย่างเช่น หลังบันทึก ให้คืนค่าความคืบหน้าที่อัปเดตพร้อมขั้นตอนถัดไปที่เซิร์ฟเวอร์ตัดสินใจ:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
ผู้ใช้จะดับเบิลคลิก รีเทรย์เมื่อการเชื่อมต่อไม่ดี หรือ frontend บางครั้งอาจส่งคำขอซ้ำหลังหมดเวลา ทำให้การ “บันทึก” ปลอดภัยโดย:
Idempotency-Key สำหรับคำขอ PUT/POST และทำ deduplicate โดย (userId, endpoint, key)PUT /steps/{stepKey} เป็นการเขียนทับ payload ของขั้นตอนนั้นทั้งหมด (หรือระบุอย่างชัดเจนว่ากฎการ merge เป็นอย่างไร)version (หรือ etag) เพื่อป้องกันการเขียนทับข้อมูลใหม่ด้วย retry ที่ล้าสมัยคืนข้อความที่ปฏิบัติได้ UI สามารถแสดงถัดจากฟิลด์:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
นอกจากนี้ให้แยกความหมายของ 403 (ไม่อนุญาต), 409 (ข้อขัดแย้ง / ขั้นตอนผิด) และ 422 (validation) เพื่อให้ frontend ตอบสนองได้อย่างถูกต้อง
แยกความสามารถของผู้ใช้และผู้ดูแล:
GET /api/admin/onboarding/users/{userId} หรือการ override) ต้องถูกจำกัดสิทธิ์และมีการบันทึกขอบเขตนี้ป้องกันการรั่วไหลของสิทธิ์โดยไม่ตั้งใจ ในขณะที่ยังช่วยให้ทีมสนับสนุนและปฏิบัติการช่วยผู้ใช้ที่ติดปัญหาได้
งานของ frontend คือทำให้ onboarding รู้สึกลื่นไหลแม้เมื่อเครือข่ายไม่เสถียร นั่นหมายถึง routing ที่คาดเดาได้ พฤติกรรม resume ที่เชื่อถือได้ และการแจ้งสถานะชัดเจนเมื่อข้อมูลกำลังบันทึก
หนึ่ง URL ต่อขั้นตอน (เช่น /onboarding/profile, /onboarding/billing) มักเป็นวิธีที่ง่ายที่สุด เข้าใจได้ดี รองรับปุ่มย้อนกลับ/ไปข้างหน้าในเบราว์เซอร์ และทำให้การรีเฟรชไม่สูญเสียบริบท
หน้าเดียวที่จัดการสถานะภายใน อาจพอใช้ได้กับ flow ที่สั้นมาก แต่เพิ่มความเสี่ยงเมื่อรีเฟรช แอปขัดข้อง หรือการแชร์ลิงก์ให้คนอื่น หากใช้วิธีนี้ ต้องมีการเก็บข้อมูลที่แข็งแรงและการจัดการประวัติที่รอบคอบ
เก็บการเสร็จของขั้นตอนและข้อมูลล่าสุดบนเซิร์ฟเวอร์ ไม่ใช่แค่ local storage เมื่อโหลดหน้า ให้ดึงสถานะ onboarding ปัจจุบัน (ขั้นตอนปัจจุบัน ขั้นตอนที่เสร็จแล้ว และค่าร่างใด ๆ) แล้วเรนเดอร์จากข้อมูลนั้น
สิ่งนี้ทำให้เกิดคุณสมบัติ:
Optimistic UI ช่วยลด friction แต่ต้องมี guardrails:
เมื่อผู้ใช้กลับมา อย่าพาไปที่ขั้นตอนหนึ่งทันที ให้แสดงสิ่งแบบนี้: “คุณทำเสร็จ 60%—จะดำเนินการต่อจากที่ค้างไว้ไหม?” พร้อมสองการกระทำ:
/onboarding)สัมผัสเล็ก ๆ นี้ลดการทิ้งกลางคันในขณะเดียวกันก็เคารพผู้ใช้ที่ยังไม่พร้อมทำต่อ
การตรวจสอบความถูกต้องคือจุดที่ flow อาจทำให้ผู้ใช้รู้สึกลื่นไหลหรือหงุดหงิด เป้าหมายคือจับข้อผิดพลาดตั้งแต่เนิ่น ๆ ให้ผู้ใช้ดำเนินต่อได้ และยังปกป้องระบบเมื่อข้อมูลไม่สมบูรณ์หรือมีสัญญาณผิดปกติ
ใช้การตรวจสอบฝั่งไคลเอนต์เพื่อป้องกันข้อผิดพลาดชัดเจนก่อนจะส่งคำขอเครือข่าย สิ่งนี้ลดอัตราซ้ำและทำให้แต่ละขั้นตอนรู้สึกตอบสนอง
เช็กทั่วไปได้แก่ ฟิลด์บังคับ ข้อจำกัดความยาว รูปแบบเบื้องต้น (อีเมล/โทรศัพท์) และกฎข้ามฟิลด์ง่าย ๆ (ยืนยันรหัสผ่าน) ให้ข้อความเฉพาะเจาะจง (“กรอกอีเมลที่ใช้งานได้สำหรับงาน”) และวางใกล้ฟิลด์
ถือว่าการตรวจสอบฝั่งเซิร์ฟเวอร์เป็นแหล่งความจริง แม้ UI ตรวจสอบได้สมบูรณ์ ผู้ใช้ยังสามารถข้ามได้
การตรวจสอบฝั่งเซิร์ฟเวอร์ควรบังคับ:
คืนค่าข้อผิดพลาดแบบโครงสร้างต่อฟิลด์เพื่อให้ frontend เน้นที่ต้องแก้
การตรวจสอบบางอย่างพึ่งสัญญาณภายนอกหรือช้ากว่า เช่น ความไม่ซ้ำของอีเมล โค้ดเชิญ สัญญาณโกง หรือการตรวจสอบเอกสาร
จัดการสิ่งเหล่านี้ด้วยสถานะชัดเจน (เช่น pending, verified, rejected) และ UI ที่ชัดเจน หากการตรวจสอบยังคงรอ ให้อนุญาตให้ผู้ใช้ดำเนินต่อได้ในขอบเขตที่เหมาะสมและแจ้งเมื่อขั้นตอนจะปลดล็อก
Onboarding หลายขั้นตอนมักมีข้อมูลบางส่วนเป็นเรื่องปกติ ตัดสินใจต่อขั้นตอนว่าจะ:
แนวปฏิบัติที่เป็นไปได้คือ “บันทึกร่างเสมอ บล็อกเฉพาะเมื่อส่งเพื่อจบขั้นตอน” ซึ่งรองรับการกลับมาต่อโดยไม่ลดเกณฑ์คุณภาพข้อมูล
การวิเคราะห์สำหรับ onboarding หลายขั้นตอนควรตอบสองคำถาม: “ผู้คนติดอยู่ที่ไหน?” และ “การเปลี่ยนแปลงใดจะเพิ่มการเสร็จ?” สิ่งสำคัญคือเก็บเหตุการณ์ชุดเล็ก ๆ ที่สม่ำเสมอในทุกขั้นตอน และทำให้เปรียบเทียบได้แม้ flow จะเปลี่ยนรุ่น
ติดตามเหตุการณ์หลักเดียวกันสำหรับแต่ละขั้นตอน:
step_viewed (ผู้ใช้เห็นขั้นตอน)step_completed (ผู้ใช้ส่งและผ่านการตรวจสอบ)step_failed (ผู้ใช้พยายามส่งแต่ล้มเหลวจาก validation หรือการตรวจสอบเซิร์ฟเวอร์)flow_completed (ผู้ใช้ถึงสถานะความสำเร็จสุดท้าย)รวม payload บริบทขั้นต่ำที่เสถียรกับแต่ละเหตุการณ์: user_id, flow_id, flow_version, step_id, step_index, และ session_id (เพื่อแยกระหว่างการทำครั้งเดียวกับการทำข้ามหลายวัน). ถ้ารองรับ resume ให้ใส่ resume=true/false ใน step_viewed
เพื่อวัดการทิ้งกลางคันต่อขั้นตอน ให้เปรียบเทียบจำนวน step_viewed กับ step_completed สำหรับ flow_version เดียวกัน เพื่อวัดเวลาในแต่ละขั้นตอน ให้เก็บ timestamp และคำนวณ:
step_viewed → step_completedstep_viewed → next step_viewed (ใช้เมื่ผู้ใช้ข้าม)เก็บเมตริกเวลาแยกตามเวอร์ชัน มิฉะนั้นการปรับปรุงอาจหายไปเมื่อผสมเวอร์ชันเก่าและใหม่
หากทำ A/B test สำเนาหรือจัดเรียงขั้นตอน ให้ถือเป็นส่วนหนึ่งของข้อมูลวิเคราะห์:
experiment_id และ variant_id ในทุกเหตุการณ์step_id ให้คงที่แม้ข้อความแสดงผลเปลี่ยนstep_id เดิมและใช้ step_index เพื่อระบุตำแหน่งสร้างแดชบอร์ดง่าย ๆ ที่แสดงอัตราการเสร็จ จุดที่คนทิ้งกลางคันตามขั้นตอน ค่าเวลามัธยฐานต่อขั้นตอน และ “ฟิลด์ที่ล้มเหลวบ่อยสุด” (จาก step_failed metadata). เพิ่มการส่งออก CSV เพื่อให้ทีมต่าง ๆ ตรวจสอบความคืบหน้าในสเปรดชีตและแชร์รายงานโดยไม่ต้องเข้าถึงเครื่องมือวิเคราะห์โดยตรง
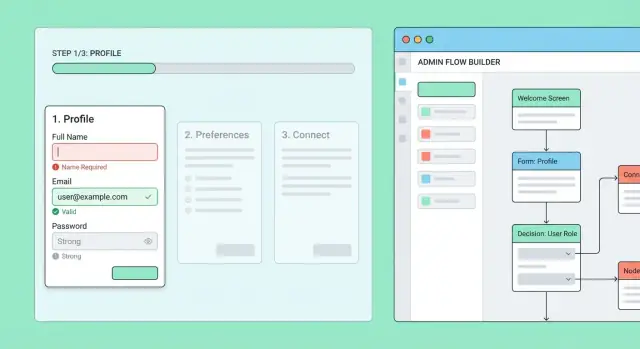
ระบบ onboarding หลายขั้นตอนจะต้องการการควบคุมเชิงปฏิบัติวันต่อวัน: การเปลี่ยนผลิตภัณฑ์ กรณีช่วยเหลือพิเศษ และการทดลองอย่างปลอดภัย การสร้างแผงภายในเล็ก ๆ ป้องกันไม่ให้วิศวกรเป็นคอขวด
เริ่มจากตัว “flow builder” ง่าย ๆ ที่ให้เจ้าหน้าที่ที่ได้รับอนุญาตสร้างและแก้ไข onboarding flows และขั้นตอนของพวกเขา
แต่ละขั้นตอนควรแก้ไขได้ด้วย:
เพิ่มโหมดพรีวิวที่เรนเดอร์ขั้นตอนเหมือนผู้ใช้จริง เพื่อจับคำพูดที่สับสน ฟิลด์ขาด หรือการ branching ที่เสียหายก่อนส่งให้ผู้ใช้จริง
หลีกเลี่ยงการแก้ไข flow ที่ใช้งานอยู่โดยตรง ให้เผยแพร่เป็นเวอร์ชัน:
การปล่อยใช้งานควรปรับได้ต่อเวอร์ชัน:
สิ่งนี้ลดความเสี่ยงและให้การเปรียบเทียบที่ชัดเจนเมื่อวัดการเสร็จและการทิ้งกลางคัน
ทีมสนับสนุนต้องการเครื่องมือเพื่อปลดล็อกผู้ใช้โดยไม่ต้องแก้ฐานข้อมูลด้วยมือ:
การกระทำของผู้ดูแลทุกอย่างควรถูกบันทึก: ใครเปลี่ยนอะไร เมื่อไหร่ และค่าก่อน/หลัง จำกัดการเข้าถึงด้วยบทบาท (ดูอย่างเดียว, editor, publisher, support override) เพื่อให้การกระทำที่สำคัญ—เช่น รีเซ็ตความคืบหน้า—ถูกควบคุมและตรวจสอบได้
ก่อนส่ง flow onboarding หลายขั้นตอน ให้สมมติสองอย่างจะเกิดขึ้น: ผู้ใช้จะเดินทางในเส้นทางที่ไม่คาดคิด และบางอย่างจะล้มเหลวกลางทาง (เครือข่าย, validation, สิทธิ์) เช็คลิสต์การเปิดตัวที่ดีพิสูจน์ว่า flow ถูกต้อง ปกป้องข้อมูลผู้ใช้ และให้สัญญาณเตือนเมื่อความเป็นจริงเบี่ยงเบนจากแผน
เริ่มด้วย unit tests สำหรับตรรกะเวิร์กโฟลว์ (สถานะและการเปลี่ยนสถานะ) การทดสอบเหล่านี้ควรยืนยันว่าแต่ละขั้นตอน:
แล้วเพิ่ม integration tests ที่ทดสอบ API ของคุณ: บันทึก payload ของขั้นตอน, resume ความคืบหน้า, และปฏิเสธการเปลี่ยนสถานะที่ไม่ถูกต้อง การทดสอบแบบบูรณาการจะจับปัญหา "ทำงานในเครื่องพัฒนา" เช่น ดัชนีหาย, บั๊กการ serialization, หรือความไม่ตรงกันของเวอร์ชันระหว่าง frontend และ backend
E2E tests ควรครอบคลุมอย่างน้อย:
เก็บสถานการณ์ E2E ให้สั้นแต่มีความหมาย—เน้นเส้นทางที่เป็นตัวแทนของผู้ใช้ส่วนใหญ่และเส้นทางที่มีผลต่อรายได้/activation
ใช้ least privilege: ผู้ดูแล onboarding ไม่ควรได้สิทธิ์เข้าถึงระเบียนผู้ใช้ทั้งหมดโดยอัตโนมัติ บัญชีเซอร์วิสควรเข้าถึงเฉพาะตารางและ endpoint ที่ต้องการ
เข้ารหัสข้อมูลที่สำคัญ (เช่น โทเคน, ตัวระบุที่อ่อนไหว, ฟิลด์ที่กฎควบคุม) และถือว่าการล็อกเป็นความเสี่ยงของการรั่วข้อมูล หลีกเลี่ยงการล็อก payload ของฟอร์มแบบดิบ; ให้ล็อกเฉพาะ step IDs, รหัสข้อผิดพลาด และเวลา หากต้องล็อกสเนิปเพ็ทของ payload เพื่อดีบัก ให้ทำการซ่อน (redact) ฟิลด์อย่างสม่ำเสมอ
ติดตั้งการวัด onboarding ทั้งในมุม funnel ของผลิตภัณฑ์และ API
ติดตามข้อผิดพลาดตามขั้นตอน ความหน่วงในการบันทึก (p95/p99) และความล้มเหลวของ resume ตั้งการแจ้งเตือนสำหรับการลดลงอย่างฉับพลันของอัตราการเสร็จ, การเพิ่มของ validation failures ในขั้นตอนเดียว, หรืออัตราข้อผิดพลาดของ API หลังการปล่อย นี่ช่วยให้คุณแก้ปัญหาขั้นตอนที่เสียก่อนที่ตั๋ว support จะท่วม
ถ้าคุณกำลังสร้างระบบ onboarding แบบขั้นตอนจากศูนย์ ส่วนใหญ่ของเวลาจะหมดกับบล็อกพื้นฐานที่อธิบายไว้ด้านบน: routing ขั้นตอน การเก็บข้อมูล การตรวจสอบ ตรรกะสถานะความคืบหน้า และแผงผู้ดูแลสำหรับเวอร์ชันและการปล่อยใช้งาน Koder.ai สามารถช่วยให้คุณออกโพรโตไทป์และส่งมอบชิ้นส่วนเหล่านี้ได้เร็วขึ้น โดยสร้างแอปแบบ full-stack จากข้อกำหนดที่ขับเคลื่อนด้วยแชท—มักประกอบด้วย frontend React, backend Go, และโมเดลข้อมูล PostgreSQL ที่แม็ปกับ flows, steps, และ step responses ได้อย่างชัดเจน
เพราะ Koder.ai รองรับการส่งออกซอร์สโค้ด โฮสติ้ง/การปรับใช้ และ snapshots พร้อม rollback มันยังมีประโยชน์เมื่อต้องวนเวียนกับเวอร์ชัน onboarding อย่างปลอดภัย (และกู้คืนได้เร็วหากการปล่อยใช้งานทำให้การเสร็จลดลง)
ใช้ multi-step flow เมื่อการตั้งค่ามากกว่าแค่ฟอร์มเดียว โดยเฉพาะถ้ามีข้อกำหนดล่วงหน้า (เช่น การสร้าง workspace), การยืนยันตัวตน (email/โทรศัพท์/KYC), การตั้งค่าต่าง ๆ (billing/integrations) หรือการแตกแขนงตามบทบาท/แผน/ภูมิภาค.
ถ้าผู้ใช้ต้องการบริบทเพื่อกรอกข้อมูลให้ถูกต้อง การแยกเป็นขั้นตอนช่วยลดข้อผิดพลาดและการยกเลิกกลางคัน
กำหนดความสำเร็จเป็นการที่ผู้ใช้เข้าถึงคุณค่าของผลิตภัณฑ์ ไม่ใช่แค่การจบหน้าจอเท่านั้น เมตริกทั่วไป:
ติดตามด้วย resume success (ผู้ใช้สามารถออกแล้วกลับมาต่อได้โดยไม่เสียความคืบหน้า)
เริ่มจากการระบุประเภทผู้ใช้ (เช่น ผู้ใช้สมัครด้วยตนเอง, ผู้ใช้ที่ถูกเชิญ, บัญชีที่สร้างโดยแอดมิน) และกำหนดสำหรับแต่ละประเภท:
จากนั้นเข้ารหัส กฎการข้าม เพื่อให้แต่ละบุคลิกลงที่ขั้นตอนถัดไปที่ถูกต้อง ไม่ใช่ขั้นตอนแรกเสมอไป
เขียนเงื่อนไข “เสร็จ” ให้เป็นเกณฑ์ที่ backend ตรวจสอบได้ ไม่ใช่แค่การจบหน้าจอ ตัวอย่างเช่น:
แบบนี้เซิร์ฟเวอร์สามารถตัดสินใจได้อย่างน่าเชื่อถือว่า onboarding เสร็จหรือไม่ แม้ UI จะเปลี่ยนแปลงไป
เริ่มด้วยแกนหลักเป็นเส้นตรง แล้วเพิ่มสาขาเชิงเงื่อนไขเมื่อประสบการณ์ต่างกันจริง ๆ (บทบาท, แผน, ภูมิภาค, กรณีการใช้งาน).
จดสาขาเป็นกฎ if/then ชัดเจน (เช่น “If region = EU → show VAT step”) และใช้ชื่อขั้นตอนที่เน้นการกระทำ (“Confirm email”, “Invite teammates”).
แนะนำให้ใช้ หนึ่ง URL ต่อหนึ่งขั้นตอน (เช่น /onboarding/profile) เมื่อ flow มีมากกว่าสองสามหน้าจอ เพราะช่วยเรื่องความปลอดภัยเมื่อรีเฟรช ลิงก์ลึกจากอีเมล และการใช้งานปุ่มย้อนกลับของเบราว์เซอร์.
ใช้หน้าเดียวที่จัดการสถานะภายในเฉพาะสำหรับ flow สั้น ๆ เท่านั้น และต้องมีการเก็บสถานะอย่างเข้มงวดเพื่อทนต่อการรีเฟรช/ขัดข้อง
ถือว่า เซิร์ฟเวอร์เป็นแหล่งข้อมูลที่เชื่อถือได้:
แบบนี้จะรองรับการรีเฟรช ข้ามอุปกรณ์ และความเสถียรเมื่อ flow ถูกปรับปรุง
โมเดลข้อมูลที่ใช้ง่ายและเพียงพอประกอบด้วย:
ทำเวอร์ชันของคำจำกัดความของ flow เพื่อไม่ให้ผู้ใช้ที่ยังทำไม่เสร็จเสียหายเมื่อมีการเพิ่ม/จัดเรียงขั้นตอนใหม่ Progress ควรอ้างอิง ที่ชัดเจน
มอง onboarding เป็น state machine ที่มีสถานะและการเปลี่ยนสถานะที่อนุญาต (เช่น start_step, save_draft, submit_step, go_back).
ขั้นตอนจะถือว่า "completed" ได้ก็ต่อเมื่อ:
เมื่อแก้ไขคำตอบก่อนหน้า ให้ประเมินซ้ำขั้นตอนถัดไปและกำหนดเป็น หรือกลับเป็น ตามความเหมาะสม
API พื้นฐานที่แข็งแรงควรมี:
GET /api/onboarding (current step + progress + drafts)PUT /api/onboarding/steps/{stepKey} พร้อม mode: draft|submitPOST /api/onboarding/complete (เซิร์ฟเวอร์ตรวจสอบความครบถ้วนของข้อกำหนด)เพิ่มความสามารถเรื่อง (เช่น ) เพื่อป้องกันการส่งซ้ำ/ดับเบิลคลิก และให้คืนค่าข้อผิดพลาดระดับฟิลด์แบบโครงสร้าง (ใช้ 403/409/422 อย่างเหมาะสม) เพื่อให้ UI ตอบสนองได้ถูกต้อง
flow_version_idneeds_reviewin_progressIdempotency-Key