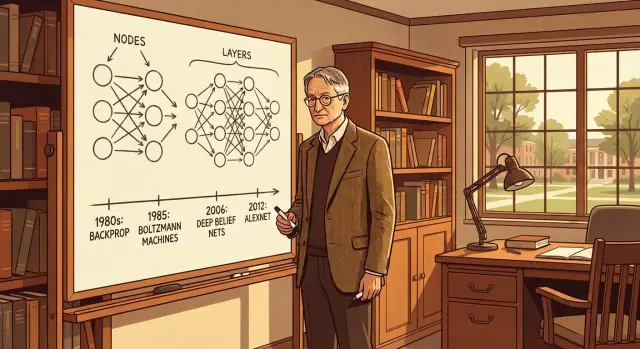
ทำไม Geoffrey Hinton ถึงสำคัญ
คู่มือนี้สำหรับผู้อ่านที่อยากรู้แต่ไม่เชิงเทคนิค ที่ได้ยินว่า “เครือข่ายประสาทเปลี่ยนทุกอย่าง” บ่อย ๆ และต้องการคำอธิบายที่ชัดเจนและยึดพื้นดินว่ามันหมายความว่าอย่างไร—โดยไม่ต้องใช้แคลคูลัสหรือการเขียนโปรแกรม
สิ่งที่คุณจะได้เรียนรู้ที่นี่
คุณจะได้ทัวร์แนวคิดเป็นภาษาเรียบง่ายที่ Geoffrey Hinton ผลักดันทำให้ก้าวหน้า, ทำไมมันสำคัญในเวลานั้น, และมันเชื่อมโยงกับเครื่องมือ AI ที่ผู้คนใช้ตอนนี้อย่างไร คิดมันเหมือนเรื่องราวเกี่ยวกับวิธีสอนคอมพิวเตอร์ให้รู้จุดรูปแบบ—คำ รูปภาพ เสียง—โดยเรียนจากตัวอย่าง
ทำไม Hinton สำคัญ (แบบไม่โอ้อวด)
Hinton ไม่ได้ “คิดค้น AI” และไม่มีคนเดียวที่สร้าง machine learning สมัยใหม่ ความสำคัญของเขาคือเขาช่วยทำให้เครือข่ายประสาท ใช้งานได้จริง หลายครั้งเมื่อหลายคนเชื่อว่ามันตัน เขามีส่วนในการเสนอแนวคิดหลัก การทดลอง และวัฒนธรรมการวิจัยที่ให้ความสำคัญกับการเรียนรู้ตัวแทน (คุณลักษณะภายในที่มีประโยชน์) เป็นปัญหาหลัก แทนที่จะเขียนกฎด้วยมือ
พรีวิวอย่างย่อของความก้าวหน้าที่จะครอบคลุม
ในส่วนถัดไป เราจะถอดรหัส:
- Backpropagation เป็นวิธีปฏิบัติที่ช่วยปรับปรุงเครือข่ายโดยเรียนรู้จากความผิดพลาด
- Boltzmann machines และการเรียนรู้แบบอิงพลังงานเป็นทางแรก ๆ ในการเรียนรู้โครงสร้างจากข้อมูล
- Representation learning และทำไม "คุณลักษณะที่ดี" สามารถเรียนรู้ได้ แทนที่จะถูกออกแบบ
- Deep belief networks, dropout และเทคนิคการฝึกที่ทำให้โมเดลลึกขึ้นเป็นไปได้
- AlexNet และช่วงเวลาที่เครือข่ายประสาทพิสูจน์ตัวเองในมาตราส่วนโลกจริง
อะไรนับเป็น "ความก้าวหน้า" ของเครือข่ายประสาท?
ในบทความนี้ ความก้าวหน้าหมายถึงการเปลี่ยนแปลงที่ทำให้เครือข่ายประสาทมีประโยชน์มากขึ้น: ฝึกได้เสถียรขึ้น, เรียนรู้คุณลักษณะภายในที่ดีกว่า, ทำนายข้อมูลใหม่ได้แม่นยำขึ้น หรือขยายไปสู่ภารกิจที่ใหญ่ขึ้น มันไม่ใช่แค่เดโมที่โดดเด่น แต่เป็นการเปลี่ยนแนวคิดให้เป็นวิธีที่เชื่อถือได้
ปัญหาที่เครือข่ายประสาทพยายามแก้
เครือข่ายประสาทไม่ได้ถูกคิดขึ้นมาเพื่อ "ทดแทนโปรแกรมเมอร์" สัญญาที่แท้จริงของพวกมันชัดเจนกว่า: สร้างเครื่องจักรที่ เรียนรู้ตัวแทนภายในที่มีประโยชน์ จากอินพุตโลกจริงที่ยุ่งเหยิง—ภาพ พูด และข้อความ—โดยไม่ต้องให้วิศวกรเขียนกฎทุกข้อ
จากอินพุตดิบสู่ความหมาย
ภาพถ่ายคือชุดค่าพิกเซลเป็นล้านค่า เสียงคือสตรีมของการวัดความดัน ความท้าทายคือต้องแปลงตัวเลขดิบเหล่านั้นให้เป็นแนวคิดที่ผู้คนสนใจ: ขอบ รูปร่าง โฟนิม คำ วัตถุ ความตั้งใจ
ก่อนที่เครือข่ายประสาทจะใช้งานได้ ระบบส่วนใหญ่พึ่งพาคุณลักษณะที่มนุษย์ออกแบบ—การวัดที่ออกแบบมาอย่างระมัดระวังเช่น "ตรวจจับขอบ" หรือ "พรรณนาเนื้อผิว" วิธีนี้ใช้ได้ในสถานการณ์จำกัด แต่พังได้เมื่อแสงเปลี่ยน สำเนียงต่างกัน หรือสภาพแวดล้อมซับซ้อนขึ้น
เครือข่ายประสาทตั้งใจแก้ปัญหานี้โดยการเรียนรู้คุณลักษณะโดยอัตโนมัติ ชั้นต่อชั้น จากข้อมูล ถ้าระบบค้นพบบล็อกก่อสร้างกลางทางที่ถูกต้องเองได้ มันจะทั่วไปได้ดีขึ้นและปรับไปยังงานใหม่ด้วยการขันน้อยลงจากมนุษย์
ทำไมจึงยากมานานหลายทศวรรษ
แนวคิดน่าสนใจ แต่มีอุปสรรคหลายอย่างที่ทำให้เครือข่ายไม่สามารถส่งมอบผลลัพธ์ได้นาน:
- คอมพิวต์: การฝึกต้องการการคำนวณจำนวนมหาศาล ในยุค 1980s และ 1990s ห้องทดลองส่วนใหญ่ไม่มีพลังประมวลผลพอสำหรับโมเดลขนาดใหญ่
- ข้อมูล: ชุดข้อมูลขนาดใหญ่ที่มีป้ายกำกับที่ทำให้การเรียนรู้เชื่อถือได้ยังไม่แพร่หลายจนถึงทศวรรษ 2000
- ความเสถียรในการฝึก: เครือข่ายหลายชั้นยุคแรกฝึกได้ยาก ความก้าวหน้าขึ้นกับอัลกอริทึมการเรียนรู้และทริกปฏิบัติที่ยังไม่บรรลุนิติภาวะ
ความมุ่งมั่นเป็นกลยุทธ์
แม้เมื่อเครือข่ายประสาทไม่เป็นที่นิยม—โดยเฉพาะช่วง 1990s และต้น 2000s—นักวิจัยอย่าง Geoffrey Hinton ยังคงผลักดันการเรียนรู้เชิงตัวแทน เขาเสนอแนวคิด (ตั้งแต่กลางทศวรรษ 1980 เป็นต้นไป) และกลับมาทบทวนแนวคิดเก่า ๆ (เช่น โมเดลอิงพลังงาน) จนฮาร์ดแวร์ ข้อมูล และวิธีการตามทัน
ความพากเพียรนั้นช่วยรักษาเป้าหมายหลักไว้: เครื่องจักรที่เรียนรู้ตัวแทนที่ ถูกต้อง ไม่ใช่แค่คำตอบสุดท้าย
Backpropagation อธิบายแบบเข้าใจง่าย
Backpropagation (มักย่อว่า "backprop") คือวิธีที่ช่วยให้เครือข่ายประสาทปรับปรุงโดย เรียนรู้จากความผิดพลาด เครือข่ายทำนาย เราวัดว่ามันผิดเท่าไร แล้วปรับ "ปุ่ม" ภายในของเครือข่าย (น้ำหนัก) เพื่อให้ดีขึ้นในครั้งต่อไป
เรียนรู้ด้วยการแก้ไขข้อผิดพลาด
ลองนึกภาพเครือข่ายพยายามระบุภาพว่าเป็น "แมว" หรือ "สุนัข" มันเดาว่า "แมว" แต่คำตอบจริงคือ "สุนัข" Backprop เริ่มจากความผิดพลาดขั้นสุดท้ายแล้วเดิน ย้อนกลับ ผ่านชั้นของเครือข่าย เพื่อหาว่าน้ำหนักแต่ละตัวมีส่วนทำให้เกิดคำตอบผิดอย่างไร
วิธีคิดเชิงปฏิบัติ:
- Forward pass: ทำนาย
- Loss: คำนวณความผิดพลาด (ว่าคลาดเคลื่อนมากแค่ไหน)
- Backward pass: แบ่ง "ความรับผิด" ผ่านชั้นต่าง ๆ
- Update: ขยับน้ำหนักเพื่อลดความผิดพลาดครั้งต่อไป
การขยับเหล่านั้นมักทำด้วยอัลกอริทึมที่เรียกว่า gradient descent ซึ่งหมายถึง "ก้าวเล็ก ๆ ลงเนินของความผิดพลาด"
Backprop ทำให้เกิดอะไรได้บ้าง
ก่อนที่ backprop จะถูกใช้อย่างแพร่หลาย การฝึกเครือข่ายหลายชั้นไม่เสถียรและช้า Backprop ทำให้การฝึก เครือข่ายลึกขึ้น เป็นไปได้ เพราะมันให้วิธีที่เป็นระบบและทำซ้ำได้ในการปรับชั้นจำนวนมากพร้อมกัน แทนที่จะปรับเฉพาะชั้นสุดท้ายหรือเดาสุ่ม
การเปลี่ยนแปลงนี้สำคัญสำหรับความก้าวหน้าที่ตามมา: เมื่อคุณฝึกหลายชั้นได้อย่างมีประสิทธิภาพ เครือข่ายสามารถเรียนรู้คุณลักษณะที่ลึกขึ้นได้ (เช่น ขอบ → รูปร่าง → วัตถุ)
ความเข้าใจผิดทั่วไป
Backprop ไม่ใช่เครือข่ายที่ "คิด" หรือ "เข้าใจ" เหมือนมนุษย์ มันคือฟีดแบ็กเชิงคณิตศาสตร์: วิธีปรับพารามิเตอร์ให้ตรงกับตัวอย่างมากขึ้น
นอกจากนี้ backprop ไม่ใช่โมเดลเดียว—มันคือ วิธีการฝึก ที่สามารถใช้กับเครือข่ายชนิดต่าง ๆ ได้
หากคุณต้องการลงลึกแบบอ่อนโยนเกี่ยวกับโครงสร้างเครือข่าย ดู /blog/neural-networks-explained.
Boltzmann Machines และการเรียนรู้แบบอิงพลังงาน
Boltzmann machines เป็นหนึ่งในก้าวสำคัญของ Geoffrey Hinton ในการทำให้เครือข่ายประสาท เรียนรู้ตัวแทนภายในที่มีประโยชน์ ไม่ใช่แค่ทำนายคำตอบ
แนวคิดพื้นฐาน: คะแนน "พลังงาน" สำหรับทุกความเป็นไปได้
Boltzmann machine เป็นเครือข่ายของหน่วยง่าย ๆ ที่สามารถเปิด/ปิดได้ (หรือในเวอร์ชันสมัยใหม่รับค่าเรียล) แทนที่จะทำนายผลลัพธ์โดยตรง มันจัดให้มี พลังงาน สำหรับการจัดวางหน่วยทั้งหมด พลังงานต่ำหมายถึง "การจัดวางนี้สมเหตุสมผล"
อนาล็อกที่ช่วยเข้าใจคือโต๊ะที่มีหลุมและหุบเล็ก ๆ ถ้าคุณปล่อยลูกกลิ้งบนพื้นผิว มันจะกลิ้งแล้ว หยุดอยู่ในหุบที่ต่ำ Boltzmann machines พยายามทำสิ่งคล้ายกัน: เมื่อได้รับข้อมูลบางส่วน (หน่วยที่เห็นได้ตั้งด้วยข้อมูล) เครือข่าย"ขยับ"หน่วยภายในจนกระทั่งลงที่สถานะที่มีพลังงานต่ำ—สถานะที่มันเรียนรู้ว่าเป็นไปได้
ทำไมมันถึงสำคัญ (แม้จะช้า)
การฝึก Boltzmann machines แบบคลาสสิกต้องทำการสุ่มหลายสถานะซ้ำ ๆ เพื่อประมาณสิ่งที่โมเดลเชื่อเทียบกับสิ่งที่ข้อมูลแสดง การสุ่มนี้ช้ามาก โดยเฉพาะสำหรับเครือข่ายใหญ่
ถึงกระนั้นแนวทางนี้มีอิทธิพลเพราะมัน:
- วางกรอบการเรียนรู้เป็นการ ปรับรูปร่างการแจกแจงความน่าจะเป็น ไม่ใช่แค่การฟิตป้ายกำกับ
- ผลักดันสาขาสู่ การเรียนรู้แบบไม่ต้องมีป้ายกำกับ (unsupervised learning)
- เป็นแรงบันดาลใจให้เกิดทางลัดปฏิบัติ เช่น contrastive divergence และแนวคิดอิงพลังงานในภายหลัง
เทียบกับเครือข่ายลึกยุคปัจจุบัน
วันนี้ผลิตภัณฑ์ส่วนใหญ่พึ่งพาเครือข่าย feedforward ที่ฝึกด้วย backprop เพราะเร็วและขยายได้ง่ายกว่า
มรดกของ Boltzmann machines จึงเป็นเชิงแนวคิดมากกว่าปฏิบัติ: แนวคิดที่ว่าโมเดลที่ดีเรียนรู้ "สถานะที่ชอบ" ของโลก—และการเรียนรู้สามารถมองว่าเป็นการย้ายมวลความน่าจะเป็นไปยังหุบพลังงานต่ำเหล่านั้น
Representation Learning: แนวคิดหลักเบื้องหลังความก้าวหน้า
เครือข่ายประสาทไม่ได้แค่เก่งขึ้นในการฟิตเส้นโค้ง—พวกมันเก่งขึ้นในการ คิดค้นคุณลักษณะที่เหมาะสม นั่นคือความหมายของ "representation learning": แทนที่จะให้คนออกแบบสิ่งที่ต้องมองหา โมเดลเรียนรู้คำอธิบายภายในที่ทำให้งานง่ายขึ้น
ตัวแทน (representations) คืออะไร
ตัวแทนคือวิธีที่โมเดลสรุปอินพุตดิบของตัวเอง มันยังไม่ใช่ป้ายกำกับเช่น "แมว" แต่เป็นโครงสร้างที่มีประโยชน์ บนทางไปสู่ ป้ายกำกับ—รูปแบบที่จับสิ่งที่มักมีความหมาย ชั้นต้นอาจตอบสนองต่อสัญญาณง่าย ๆ ในขณะที่ชั้นหลังรวมเป็นแนวคิดที่มีความหมายมากขึ้น
ทำไมมันเปลี่ยนการทำงานในโลกจริง
ก่อนการเปลี่ยนแปลงนี้ ระบบจำนวนมากพึ่งพาคุณลักษณะที่ออกแบบโดยผู้เชี่ยวชาญ: ตัวตรวจจับขอบสำหรับภาพ, สัญญาณเฉพาะสำหรับเสียง, หรือสถิติข้อความที่ออกแบบอย่างระมัดระวัง คุณลักษณะเหล่านั้นใช้ได้ดี แต่พังได้เมื่อเงื่อนไขเปลี่ยน (แสง สำเนียง การเลือกถ้อยคำ)
Representation learning ให้โมเดลปรับคุณลักษณะตามข้อมูลเอง ซึ่งปรับปรุงความแม่นยำและทำให้ระบบยืดหยุ่นมากขึ้นเมื่อต้องเจออินพุตโลกจริงที่ยุ่งเหยิง
แนวคิดเดียว หลายโดเมน
- วิสัน (Vision): พิกเซลกลายเป็นแนวคิดเชิงภาพที่มีโครงสร้างมากขึ้น
- เสียง: คลื่นเสียงกลายเป็นรูปแบบอันใกล้เคียงโฟนิม แล้วกลายเป็นคำ
- ภาษา: โทเคนกลายเป็นวลี ความหมาย และความสัมพันธ์ระหว่างแนวคิด
เส้นด้ายร่วมคือชั้นเชิงลำดับชั้น: รูปแบบเรียบง่ายรวมเป็นรูปแบบที่มีความหมายมากขึ้น
ตัวอย่างง่าย ๆ: ขอบ → รูปร่าง → วัตถุ
ในการจดจำภาพ เครือข่ายอาจเรียนรู้รูปแบบคล้ายขอบในชั้นแรก ถัดมามันรวมขอบเป็นมุมและความโค้ง แล้วกลายเป็นส่วนเช่นล้อหรือดวงตา และสุดท้ายเป็นวัตถุทั้งชิ้น เช่น "จักรยาน" หรือ "ใบหน้า"
ความก้าวหน้าของ Hinton ช่วยทำให้การสร้างคุณลักษณะแบบชั้นลึกนี้เป็นไปได้จริง—และนั่นคือสาเหตุสำคัญที่ deep learning เริ่มชนะงานที่ผู้คนใส่ใจจริง ๆ
Deep Belief Networks และเส้นทางสู่โมเดลที่ลึกขึ้น
เก็บโค้ดให้พกพาได้
รับซอร์สโค้ดเพื่อให้ทีมของคุณตรวจทาน แก้ไข และเป็นเจ้าของโครงการได้.
Deep belief networks (DBNs) เป็นขั้นตอนสำคัญในการเดินทางไปสู่เครือข่ายลึกที่คนรู้จักในปัจจุบัน ในมุมมองสูง ๆ DBN คือการซ้อนชั้นที่แต่ละชั้นเรียนรู้ที่จะเป็นตัวแทนของชั้นด้านล่าง—เริ่มจากอินพุตดิบแล้วค่อย ๆ สร้าง "แนวคิด" ที่เป็นนามธรรมมากขึ้น
DBN คืออะไร (เชิงแนวคิด)
ลองนึกถึงการสอนระบบรู้ตัวอักษรเขียนมือ แทนที่จะเรียนรู้ทุกอย่างพร้อมกัน DBN เริ่มจากเรียนรู้รูปแบบง่าย ๆ (เช่น ขอบและเส้น) แล้วรวมเป็นรูปแบบของเส้นและโค้ง และสุดท้ายเป็นรูปร่างที่คล้ายส่วนของตัวเลข
แนวคิดสำคัญคือแต่ละชั้นพยายามจำลองรูปแบบในอินพุตของมันโดยไม่ได้รับคำตอบที่ถูกต้องทันที จากนั้นเมื่อสแต็กเรียนรู้ตัวแทนที่มีประโยชน์มากขึ้นแล้ว คุณสามารถปรับทั้งเครือข่ายให้ทำงานเฉพาะเช่นการจำแนกได้
ทำไมการเทรนทีละชั้นจึงสำคัญ
เครือข่ายลึกในอดีตมักฝึกได้ยากเมื่อเริ่มแบบสุ่ม สัญญาณการฝึกอาจอ่อนหรือไม่เสถียรเมื่อส่งผ่านหลายชั้น และเครือข่ายอาจลงเอยที่การตั้งค่าที่ไม่ช่วย
การเทรนทีละชั้นให้โมเดล "จุดเริ่มต้นที่อบอุ่น" แต่ละชั้นเริ่มด้วยความเข้าใจที่เป็นเหตุเป็นผลของโครงสร้างในข้อมูล ทำให้ทั้งเครือข่ายไม่ต้องค้นหาอย่างมืดบอด
สิ่งนี้ทำให้โมเดลลึกเป็นไปได้ยังไง
การเทรนล่วงหน้าไม่ได้แก้ปัญหาทุกอย่าง แต่ทำให้ความลึกเป็นไปได้ในช่วงเวลาที่ข้อมูล กำลังประมวลผล และทริกการฝึกยังมีจำกัด DBNs แสดงให้เห็นว่าการเรียนรู้ตัวแทนหลายชั้นสามารถใช้ได้จริง และความลึกไม่ใช่แค่ทฤษฎี แต่เป็นเส้นทางที่ใช้ได้จริง
Dropout และการสู้กับ Overfitting
เครือข่ายประสาทบางครั้ง "สอบได้ดี" ในแบบที่แย่กว่าที่ควร: มันท่องจำข้อมูลฝึกแทนที่จะเรียนรู้รูปแบบพื้นฐาน ปัญหานี้เรียกว่า overfitting และเกิดได้ทุกครั้งที่โมเดลดูดีในการทดลองแต่แย่ในการใช้งานจริง
Overfitting กับตัวอย่างในชีวิตประจำวัน
ลองนึกถึงการเตรียมสอบขับรถโดยท่องเส้นทางที่ผู้สอนใช้ครั้งก่อน—ทุกเลี้ยว ทุกป้าย ทุกหลุม หากข้อสอบใช้เส้นทางเดิม คุณจะทำได้ดี แต่ถ้าเส้นทางเปลี่ยน คุณจะทำได้แย่เพราะคุณไม่ได้เรียนรู้ทักษะการขับรถทั่วไป แต่เรียนรู้สคริปต์หนึ่งเดียว
นั่นคือ overfitting: ความแม่นยำสูงในตัวอย่างที่คุ้นเคย แต่ผลลัพธ์อ่อนเมื่อเผชิญตัวอย่างใหม่
Dropout: ไอเดียง่าย ๆ ที่ได้ผล
Dropout ถูกทำให้เป็นที่นิยมโดย Geoffrey Hinton และผู้ร่วมงานเป็นทริกการฝึกที่เรียบง่ายอย่างน่าทึ่ง ในการฝึก เครือข่ายจะ สุ่มปิดหน่วยบางตัว ในแต่ละการส่งข้อมูลผ่าน
วิธีนี้บังคับให้โมเดลไม่พึ่งพาทางเดียวหรือชุดคุณลักษณะโปรด มันต้องแพร่ข้อมูลไปยังหลายการเชื่อมต่อและเรียนรู้รูปแบบที่ยังคงเป็นจริงแม้บางส่วนของเครือข่ายหายไป
โมเดลจำลองง่าย ๆ: เหมือนเรียนโดยบางครั้งไม่มีหน้ากระดาษโน้ตบางหน้า—คุณถูกบังคับให้เข้าใจแนวคิด ไม่ใช่จำวลีเฉพาะ
Dropout ช่วยอะไรบ้าง
ผลลัพธ์หลักคือ การทั่วไปที่ดีขึ้น: เครือข่ายเชื่อถือได้มากขึ้นกับข้อมูลที่ไม่เคยเห็น ในทางปฏิบัติ dropout ช่วยให้เครือข่ายขนาดใหญ่ฝึกได้โดยไม่ตกเป็นทาสของการท่องจำ และกลายเป็นเครื่องมือมาตรฐานในหลายการตั้งค่า deep learning
AlexNet: ช่วงเวลาที่ Deep Learning ไปสู่กระแสหลัก
สร้างจากแนวคิดง่ายๆ
เปลี่ยนสิ่งที่คุณเรียนรู้เกี่ยวกับ neural nets ให้เป็นแอปที่ใช้งานได้โดยอธิบายในแชท.
ทำไมเบนช์มาร์กภาพถึงสำคัญ
ก่อน AlexNet, "การจดจำภาพ" ไม่ใช่แค่โชว์เท่ ๆ แต่มันเป็นการแข่งขันที่วัดผลได้ เบนช์มาร์กอย่าง ImageNet ถามคำถามตรง ๆ: ให้ภาพสักภาพ ระบบของคุณตั้งชื่อสิ่งที่อยู่ในภาพได้ไหม?
ความยากอยู่ที่ขนาด: หลายล้านภาพและหลายพันประเภท ขนาดนี้สำคัญเพราะมันแยกแนวคิดที่ฟังดูดีในการทดลองเล็ก ๆ ออกจากวิธีการที่ทนต่อความยุ่งเหยิงของโลกจริง
ความก้าวหน้าบนกระดานผู้นำมักค่อยเป็นค่อยไป แล้ว AlexNet (สร้างโดย Alex Krizhevsky, Ilya Sutskever และ Geoffrey Hinton) มาแล้วทำให้ผลลัพธ์รู้สึกเหมือนก้าวกระโดดแทนที่จะปีนขึ้นทีละนิด
AlexNet แสดงอะไรจริง ๆ
AlexNet แสดงให้เห็นว่า เครือข่ายคอนโวลูชันลึก สามารถเอาชนะท่อทางการมองเห็นแบบดั้งเดิมได้เมื่อรวมสามส่วนนี้เข้าด้วยกัน:
- Convolutions (ชั้นพิเศษที่ใช้ประโยชน์จากโครงสร้างของภาพ)
- GPUs (เพื่อฝึกโมเดลใหญ่ในเวลาที่รับได้)
- ข้อมูลป้ายกำกับจำนวนมาก (ขนาดของ ImageNet)
นี่ไม่ใช่แค่ "โมเดลที่ใหญ่กว่า" แต่มันคือสูตรปฏิบัติสำหรับการฝึกเครือข่ายลึกอย่างมีประสิทธิภาพในงานโลกจริง
อธิบายการคอนโวลูชันแบบเห็นภาพ (ไม่มีคณิตศาสตร์)
ลองนึกถึงการเลื่อน "หน้าต่าง" ขนาดเล็กบนภาพ—เหมือนการเอาตราประทับส่งผ่านภาพ ภายในหน้าต่างนั้น เครือข่ายมองหารูปแบบง่าย ๆ: ขอบ มุม ลาย เส้นตรวจจับเดียวกันนี้ถูกใช้ซ้ำทั่วทั้งภาพ จึงสามารถค้นหา "สิ่งคล้ายขอบ" ได้ไม่ว่าจะอยู่ซ้าย ขวา บน หรือล่าง
ซ้อนชั้นเหล่านี้พอเพียงและคุณจะได้ลำดับชั้น: ขอบกลายเป็นผิวผ้า, ผิวผ้ากลายเป็นส่วน, ส่วนกลายเป็นวัตถุ
ทำไมมันเปลี่ยนทิศทางอุตสาหกรรม
AlexNet ทำให้ deep learning ดูน่าเชื่อถือและคุ้มค่าลงทุน หากเครือข่ายลึกชนะบนเบนช์มาร์กที่ยาก งานเหล่านี้ก็นำไปสู่ผลิตภัณฑ์ที่ดีขึ้น—ค้นหา การติดแท็กภาพ ฟีเจอร์กล้อง เครื่องมือช่วยการเข้าถึง และอื่น ๆ
มันช่วยเปลี่ยนเครือข่ายประสาทจาก "งานวิจัยที่น่าสนใจ" เป็นทิศทางที่ชัดเจนสำหรับทีมสร้างระบบจริง
สิ่งที่เปลี่ยนไป: ข้อมูล, กำลังประมวลผล, และการฝึกที่ใช้งานได้จริง
Deep learning ไม่ได้ "มาถึงในชั่วข้ามคืน" แต่มันเริ่มเห็นผลชัดเมื่อตัวแปรสำคัญบางอย่างมารวมกัน—หลังจากหลายปีของงานก่อนหน้าที่แสดงแนวคิดแต่ยากจะขยาย
สามส่วนที่ทำให้สำเร็จ
ข้อมูลมากขึ้น. เว็บ สมาร์ทโฟน และชุดข้อมูลป้ายกำกับขนาดใหญ่ (เช่น ImageNet) ทำให้เครือข่ายเรียนจากล้านตัวอย่างได้แทนที่จะเป็นพัน กับชุดข้อมูลเล็ก โมเดลใหญ่ส่วนใหญ่จะท่องจำ
กำลังประมวลผลมากขึ้น (โดยเฉพาะ GPUs). การฝึกเครือข่ายลึกหมายถึงการทำคณิตศาสตร์ซ้ำพันล้านครั้ง GPUs ทำให้เรื่องนี้ถูกและเร็วพอที่จะทดลองได้มากขึ้น สิ่งที่เคยใช้เวลาหลายสัปดาห์อาจเหลือเป็นวันหรือชั่วโมง
ทริกการฝึกที่ดีขึ้น. การปรับปรุงเชิงปฏิบัติทำให้ความเป็นไปได้สูงขึ้น:
- การเริ่มค่าที่ดีกว่าและการเลือกออปติไมเซชันที่ดีขึ้น
- การทำ normalization และ pipeline อินพุตที่สะอาดขึ้น
- วิธี regularization อย่าง dropout เพื่อลด overfitting
- ฟังก์ชัน activation และรูปแบบสถาปัตยกรรมที่ดีขึ้น
สิ่งเหล่านี้ไม่ได้เปลี่ยนแนวคิดหลักของเครือข่ายประสาท; แต่มันเปลี่ยนความน่าเชื่อถือของการทำให้พวกมันทำงานได้จริง
ทำไมความก้าวหน้าถึงดูรวดเร็ว
เมื่อคอมพิวต์และข้อมูลถึงระดับหนึ่ง การปรับปรุงเริ่มทับซ้อนกัน ผลลัพธ์ที่ดีกว่าดึงการลงทุนเพิ่ม ซึ่งเอื้อให้มีชุดข้อมูลใหญ่และฮาร์ดแวร์ที่เร็วขึ้น ผลลัพธ์เลยดีขึ้นอีก จากภายนอกดูเหมือนก้าวกระโดด แต่จากภายในมันคือการทบต้น
ทางแลกเปลี่ยน: โมเดลใหญ่ขึ้น ค่าใช้จ่ายมากขึ้น
การขยายขนาดนำมาซึ่งต้นทุนจริง: ใช้พลังงานมากขึ้น การฝึกแพงขึ้น และความพยายามมากขึ้นในการนำโมเดลไปใช้งานอย่างมีประสิทธิภาพ นอกจากนี้ยังขยายช่องว่างระหว่างสิ่งที่ทีมเล็กทำต้นแบบได้กับสิ่งที่ห้องทดลองทุนหนาสามารถฝึกตั้งแต่ต้นได้
แนวคิดเหล่านี้ปรากฏในผลิตภัณฑ์ที่คนใช้ยังไง
แนวคิดหลักของ Hinton—การเรียนรู้ตัวแทนที่มีประโยชน์จากข้อมูล, การฝึกเครือข่ายลึกอย่างเชื่อถือได้, และการป้องกันการ overfitting—ไม่ได้เป็น "ฟีเจอร์" ที่ชี้ตรง ๆ ในแอป แต่เป็นเหตุผลว่าทำไมฟีเจอร์รายวันหลายอย่างรู้สึกเร็ว แม่นยำ และน้อยก่อกวน
การค้นหาและการแนะนำ
ระบบค้นหายุคใหม่ไม่ได้จับคู่คำค้นแบบตรงตัว พวกมันเรียนรู้ตัวแทนของคำค้นและเนื้อหา ดังนั้นคำว่า “best noise-canceling headphones” จะนำหน้าเพจที่ไม่จำเป็นต้องมีวลีตรง ๆ งานเดียวกันช่วยฟีดคำแนะนำเข้าใจว่าสินค้าสองอย่างเหมือนกันแม้คำอธิบายต่างกัน
การแปลและเครื่องมือข้อความ
การแปลดีขึ้นอย่างมากเมื่อโมเดลเรียนรู้ลำดับชั้นของรูปแบบ (จากตัวอักษรเป็นคำเป็นความหมาย) แม้ว่าโมเดลพื้นฐานอาจพัฒนาไป แต่หลักการฝึก—ชุดข้อมูลใหญ่ การปรับแต่งอย่างระมัดระวัง และแนวคิด regularization ที่เติบโตจาก deep learning—ยังคงชี้แนะการสร้างคุณลักษณะภาษา
เสียงและการถอดคำ
ผู้ช่วยด้วยเสียงและการพิมพ์ด้วยเสียงพึ่งพาเครือข่ายที่แม็พเสียงที่ยุ่งเหยิงไปสู่ข้อความชัดเจน Backpropagation คือเครื่องจักรหลักที่ปรับแต่งโมเดลเหล่านี้ ขณะที่เทคนิคอย่าง dropout ช่วยไม่ให้พวกมันท่องจำลักษณะเฉพาะของผู้พูดหรือไมโครโฟนบางตัว
รูปถ่าย: การติดแท็ก การจัดกลุ่ม และ "ค้นหาด้วยภาพ"
แอปภาพสามารถรู้จักใบหน้า จัดกลุ่มฉากที่คล้ายกัน และให้คุณค้นหา "ชายหาด" โดยไม่ต้องมีการติดแท็กด้วยมือ นั่นคือ representation learning: ระบบเรียนรู้คุณลักษณะภาพ (ขอบ → ผิว → วัตถุ) ที่ทำให้การติดแท็กและการดึงข้อมูลทำงานได้ในระดับใหญ่
ทีมงานยังใช้แนวคิดเหล่านี้อย่างไร
แม้คุณจะไม่ฝึกโมเดลเองตั้งแต่ต้น หลักการเหล่านี้ปรากฏในงานประจำวันของการสร้างผลิตภัณฑ์: เริ่มจากตัวแทนที่แข็งแรง (มักเป็นโมเดลที่เทรนไว้ล่วงหน้า), ทำให้การฝึกและการประเมินคงที่, และใช้ regularization เมื่อระบบเริ่ม "ท่องจำเกณฑ์"
นี่คือเหตุผลที่เครื่องมือ "vibe-coding" รุ่นปัจจุบันอาจรู้สึกมีประสิทธิภาพ แพลตฟอร์มอย่าง Koder.ai วางอยู่บน LLM เจนเนอเรชันปัจจุบันและเวิร์กโฟลว์เอเจนท์เพื่อช่วยทีมแปลงสเปคภาษาธรรมชาติเป็นเว็บ แบ็กเอนด์ หรือแอปมือถือได้เร็วขึ้น ขณะที่ยังให้คุณส่งออกซอร์สโค้ดและดีพลอยตามกระบวนการปกติของทีมวิศวกรรม
หากคุณต้องการสรุปสั้น ๆ ของสัญชาตญาณการฝึก ดู /blog/backpropagation-explained.
ความเชื่อผิด ๆ ทั่วไปเกี่ยวกับ Hinton และเครือข่ายประสาท
ทำให้โปรเจกต์เป็นแบรนด์
เพิ่มโดเมนที่กำหนดเองให้เดโมของคุณรู้สึกเหมือนผลิตภัณฑ์จริง.
ความก้าวหน้าครั้งใหญ่ถูกย่อเป็นเรื่องราวง่าย ๆ ซึ่งจำง่าย—แต่ก็สร้างความเชื่อผิดที่ซ่อนเรื่องที่เกิดขึ้นจริงและสิ่งที่ยังสำคัญจนถึงวันนี้
ความเชื่อผิด: “คนเดียวคิด AI สมัยใหม่ขึ้นมา”
Hinton เป็นบุคคลสำคัญ แต่เครือข่ายประสาทสมัยใหม่เกิดจากผลงานหลายทศวรรษจากกลุ่มต่าง ๆ: นักวิจัยที่พัฒนาออปติไมเซชัน, คนที่สร้างชุดข้อมูล, วิศวกรที่ทำให้ GPUs ใช้ฝึกได้จริง, และทีมที่พิสูจน์แนวคิดในมาตราส่วน แม้ภายใต้ผลงานของ Hinton นักศึกษาและผู้ร่วมงานของเขาก็มีบทบาทใหญ่ เรื่องจริงคือสายโซ่ของการมีส่วนร่วมหลายส่วนที่พอดีกัน
ความเชื่อผิด: “เครือข่ายประสาทเป็นของใหม่เอี่ยม”
เครือข่ายประสาทถูกร研究มาตั้งกลางศตวรรษที่ 20 มีช่วงเวลาที่ตื่นเต้นและผิดหวัง สิ่งที่เปลี่ยนไม่ใช่การมีอยู่ของแนวคิด แต่เป็นความสามารถในการฝึกโมเดลขนาดใหญ่ได้อย่างเชื่อถือและแสดงผลลัพธ์ชัดเจนในปัญหาจริง ยุค "deep learning" จึงเป็นการกลับมามากกว่าการประดิษฐ์ใหม่
ความเชื่อผิด: “ชั้นมาก ๆ ชนะเสมอ”
โมเดลลึกอาจช่วย แต่ไม่ใช่เวทมนตร์ เวลาในการฝึก ค่าใช้จ่าย คุณภาพข้อมูล และผลตอบแทนที่ลดลงเป็นข้อจำกัดจริง บางครั้งโมเดลเล็กชนะโมเดลใหญ่เพราะปรับแต่งง่ายกว่า ทนต่อเสียงรบกวนน้อยกว่า หรือตรงกับงานมากกว่า
ความเชื่อผิด: “Backprop คือการเรียนรู้แบบมนุษย์”
Backpropagation เป็นวิธีปรับพารามิเตอร์โดยใช้ฟีดแบ็กจากป้ายกำกับ มนุษย์เรียนรู้จากตัวอย่างน้อยกว่า ใช้ความรู้เดิมมาก และไม่พึ่งพาสัญญาณข้อผิดพลาดแบบเดียวกัน มนุษย์อาจได้แรงบันดาลใจจากชีววิทยา แต่เครือข่ายไม่ใช่สำเนาที่แม่นยำของสมอง
บทเรียนที่ควรนำไปใช้
เรื่องราวของ Hinton ไม่ใช่แค่รายการผลงาน แต่มันเป็นรูปแบบ: เก็บแนวคิดการเรียนรู้ง่าย ๆ ทดลองอย่างต่อเนื่อง และอัปเกรดส่วนประกอบรอบ ๆ (ข้อมูล คอมพิวต์ และทริกการฝึก) จนมันทำงานได้ในมาตราส่วน
พฤติกรรมที่ผู้สร้างวันนี้ควรเลียนแบบ
นิสัยที่ถ่ายโอนได้มากที่สุดเป็นเชิงปฏิบัติ:
- ทดลองในลูปสั้น ๆ. ให้แต่ละการรันเป็นการทดลองเล็ก ๆ: เปลี่ยนเรื่องเดียว บันทึกผล แล้วทำซ้ำ
- วัดสิ่งที่สำคัญ. ติดตามเมตริกชัดเจน (ความแม่นยำ อัตราความผิด พิงเวลา ต้นทุนต่อคิวรี) และเปรียบเทียบกับฐาน หากบอกว่า "ดีกว่า" ต้องมีตัวเลขรองรับ
- อธิบายให้เรียบง่าย. ถ้าคุณอธิบายเป้าหมาย อินพุต และโหมดล้มเหลวให้เพื่อนที่ไม่ใช่ผู้เชี่ยวชาญไม่ได้ มีโอกาสสูงที่คุณจะส่งสินค้าไม่ได้อย่างปลอดภัย
สิ่งที่ไม่ควรเลียนแบบ
ล่อลวงให้สรุปบทเรียนเป็นว่า "โมเดลใหญ่ชนะ" ซึ่งไม่ครบถ้วน
ไล่ตามขนาดโดยไม่มีเป้าหมายชัดเจนอาจนำไปสู่:
- ต้นทุนสูงโดยไม่เห็นการปรับปรุงที่ผู้ใช้รับรู้
- การดีบักยากขึ้นเมื่อเกิดปัญหา
- ทีมที่ปรับแต่งเบนช์มาร์กมากกว่าผลิตภัณฑ์
ค่าเริ่มต้นที่ดีกว่าคือ: เริ่มเล็ก พิสูจน์คุณค่า แล้วขยาย—และขยายเฉพาะส่วนที่พิสูจน์แล้วว่าจำกัดประสิทธิภาพ
อ่านต่อที่แนะนำ
ถ้าคุณอยากนำบทเรียนเหล่านี้ไปใช้ในงานประจำวัน นี่คือบทความต่อเนื่องที่น่าสนใจ:
- /blog/ai-model-evaluation
- /blog/how-to-reduce-overfitting
- /blog/representation-learning-explained
เรื่องเล่าหนึ่งที่ควรจำ
จากกฎการเรียนรู้พื้นฐานของ backprop, สู่ตัวแทนที่จับความหมาย, ถึงทริกปฏิบัติอย่าง dropout, จนถึงเดโมก้าวกระโดดอย่าง AlexNet—เส้นเรื่องสม่ำเสมอ: เรียนรู้คุณลักษณะที่มีประโยชน์จากข้อมูล, ทำให้การฝึกเสถียร, และยืนยันความก้าวหน้าด้วยผลลัพธ์จริง
นั่นคือ playbook ที่คุ้มค่าที่จะรักษาไว้.