14 ต.ค. 2568·3 นาที
GraphQL คืออะไร? คู่มือชัดเจนสำหรับ API และการดึงข้อมูล
เรียนรู้ว่า GraphQL คืออะไร ทำงานของ queries, mutations และสคีมาเป็นอย่างไร เมื่อควรใช้แทน REST รวมถึงข้อดีข้อเสียและตัวอย่างเชิงปฏิบัติ
เรียนรู้ว่า GraphQL คืออะไร ทำงานของ queries, mutations และสคีมาเป็นอย่างไร เมื่อควรใช้แทน REST รวมถึงข้อดีข้อเสียและตัวอย่างเชิงปฏิบัติ
GraphQL เป็น ภาษา query และ runtime สำหรับ APIs กล่าวง่ายๆ: มันเป็นวิธีที่แอป (เว็บ, มือถือ หรือบริการอื่น) ขอข้อมูลจาก API โดยใช้คำขอที่ชัดเจนเป็นโครงสร้าง—และให้เซิร์ฟเวอร์คืนคำตอบที่ตรงตามคำขอนั้น
หลาย APIs บังคับให้ไคลเอนต์ยอมรับผลลัพธ์จาก endpoint ตายตัว ซึ่งมักก่อให้เกิดสองปัญหา:
กับ GraphQL ไคลเอนต์สามารถขอ เฉพาะฟิลด์ที่ต้องการ เท่านั้น ไม่มากไปและไม่น้อยไป ซึ่งมีประโยชน์มากเมื่อหน้าจอหรือแอปต่างกันต้องการ “ส่วนย่อย” ของข้อมูลชุดเดียวกันแตกต่างกัน
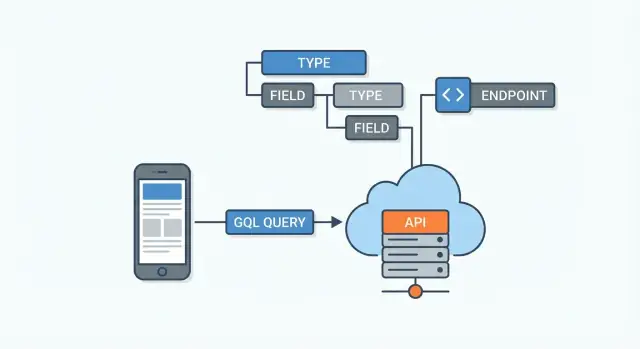
GraphQL โดยทั่วไปจะอยู่ ระหว่างแอปไคลเอนต์และแหล่งข้อมูลของคุณ แหล่งข้อมูลเหล่านี้อาจเป็น:
เซิร์ฟเวอร์ GraphQL จะรับ query ตรวจสอบว่าควรดึงแต่ละฟิลด์จากที่ไหน แล้วประกอบผลลัพธ์ JSON สุดท้าย
คิดว่า GraphQL เหมือนการ สั่งผลลัพธ์ในรูปทรงที่ต้องการ:
เพื่อความชัดเจน:
ถ้าจำคำจำกัดความหลักไว้ได้—ภาษา query + runtime สำหรับ APIs—คุณจะมีพื้นฐานที่ถูกต้องสำหรับเนื้อหาอื่นๆ ต่อไป
GraphQL ถูกสร้างขึ้นเพื่อตอบปัญหาทางผลิตภัณฑ์จริง: ทีมงานเสียเวลามากเกินไปในการปรับ API ให้พอดีกับหน้าจอ UI
API แบบ endpoint ดั้งเดิมมักบังคับให้เลือกระหว่างส่งข้อมูลที่ไม่จำเป็นหรือเรียกหลายครั้งเพื่อได้ข้อมูลที่ต้องการ เมื่อผลิตภัณฑ์เติบโต ความไม่สะดวกนี้จะทำให้หน้าโหลดช้าลง โค้ดฝั่งไคลเอนต์ซับซ้อนขึ้น และต้องประสานงานระหว่างทีม frontend/ backend มากขึ้น
Over-fetching เกิดเมื่อ endpoint คืนวัตถุ “เต็ม” แม้ว่าหน้าจอจะต้องการเพียงไม่กี่ฟิลด์ ตัวอย่างเช่น view โปรไฟล์บนมือถืออาจต้องการแค่ชื่อและอวาตาร์ แต่ API คืนที่อยู่, การตั้งค่า, ฟิลด์ audit และอื่นๆ นั่นเสียแบนด์วิดท์และทำร้ายประสบการณ์ผู้ใช้
Under-fetching ตรงข้าม: ไม่มี endpoint ใดมีข้อมูลครบถ้วนสำหรับมุมมองหนึ่งๆ ดังนั้นไคลเอนต์ต้องส่งคำขอหลายครั้งและประกอบผลลัพธ์เข้าด้วยกัน เพิ่ม latency และโอกาสเกิดความล้มเหลวบางส่วน
หลาย API แบบ REST ตอบต่อการเปลี่ยนแปลงด้วยการเพิ่ม endpoint ใหม่หรือใช้ versioning (v1, v2…) ซึ่งอาจจำเป็น แต่ก็สร้างงานบำรุงรักษายาวนาน: ลูกค้าเก่ายังคงใช้เวอร์ชันเก่า ขณะที่ฟีเจอร์ใหม่วางซ้อนไปที่อื่น
แนวทางของ GraphQL คือพัฒนาสคีมาโดยการเพิ่มฟิลด์และชนิดข้อมูลเมื่อเวลาผ่านไป ในขณะที่คงฟิลด์เดิมให้เสถียร นั่นมักลดแรงกดดันในการสร้าง “เวอร์ชันใหม่” เพียงเพื่อรองรับความต้องการ UI ใหม่
ผลิตภัณฑ์สมัยใหม่แทบไม่ค่อยมีผู้ใช้เพียงแบบเดียว เว็บ, iOS, Android และการผสานงานกับพาร์ทเนอร์ต่างต้องการรูปแบบข้อมูลที่ต่างกัน
GraphQL ถูกออกแบบให้แต่ละไคลเอนต์ขอเฉพาะฟิลด์ที่ต้องการ—โดยไม่ต้องให้ backend สร้าง endpoint แยกสำหรับแต่ละหน้าจอหรืออุปกรณ์
GraphQL API ถูกกำหนดด้วย สคีมา คิดว่ามันเป็นข้อตกลงระหว่างเซิร์ฟเวอร์และลูกค้าทุกคน: ระบุว่ามีข้อมูลอะไรบ้าง ถูกเชื่อมโยงอย่างไร และสามารถขอหรือเปลี่ยนแปลงอะไรได้ ลูกค้าไม่เดา endpoint—พวกเขาอ่านสคีมาและขอฟิลด์ที่ต้องการ
สคีมาประกอบด้วย types (เช่น User หรือ Post) และ fields (เช่น name หรือ title) ฟิลด์สามารถชี้ไปยังชนิดอื่นได้ ซึ่งเป็นวิธีที่ GraphQL โมเดลความสัมพันธ์
นี่คือตัวอย่างง่ายใน Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
เพราะสคีมาเป็น strongly typed GraphQL สามารถตรวจสอบคำขอก่อนรันได้ หากไคลเอนต์ขอฟิลด์ที่ไม่มีอยู่ (เช่น Post.publishDate เมื่อสคีมาไม่มีฟิลด์นั้น) เซิร์ฟเวอร์สามารถปฏิเสธหรือทำการตอบบางส่วนพร้อมข้อผิดพลาดที่ชัดเจน—โดยไม่เกิดพฤติกรรมแบบ “บางทีใช้งานได้”
สคีมาถูกออกแบบให้เติบโตได้ คุณสามารถ เพิ่มฟิลด์ใหม่ (เช่น User.bio) โดยไม่ทำให้ลูกค้าเดิมเสียหาย เพราะลูกค้าจะได้รับเฉพาะสิ่งที่พวกเขาขอ การลบหรือเปลี่ยนฟิลด์เป็นเรื่องที่ละเอียดอ่อนมากกว่า ทีมมักจะ deprecate ฟิลด์ก่อนแล้วย้ายลูกค้าไปทีละน้อย
GraphQL API มักถูกเปิดผ่าน endpoint เดียว (เช่น /graphql) แทนที่จะมีหลาย URL สำหรับทรัพยากรต่างๆ คุณส่ง query ไปที่ที่เดียวและอธิบายข้อมูลที่ต้องการกลับมาอย่างละเอียด
Query เปรียบเหมือน “รายการซื้อ” ของฟิลด์ คุณสามารถขอฟิลด์ง่ายๆ (เช่น id และ name) และข้อมูลซ้อน (เช่น โพสต์ล่าสุดของผู้ใช้) ในคำขอเดียว—โดยไม่ดาวน์โหลดฟิลด์เพิ่มเติมที่ไม่ต้องการ
นี่คือตัวอย่างเล็กๆ:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
การตอบของ GraphQL เป็น ทำนายได้: JSON ที่คุณได้รับจะสะท้อนโครงสร้างของ query นั่นทำให้ฝั่ง frontend ทำงานง่ายขึ้นเพราะไม่ต้องเดาว่าข้อมูลจะอยู่ที่ไหนหรือแยกแยะรูปแบบการตอบที่ต่างกัน
ตัวอย่างโครงร่างการตอบแบบย่ออาจเป็น:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
ถ้าคุณไม่ขอฟิลด์ มันจะไม่ถูกรวม ถ้าขอ คุณจะคาดหวังให้มันอยู่ในตำแหน่งที่ตรงกัน—ทำให้การคิวรี GraphQL เป็นวิธีที่สะอาดในการดึงสิ่งที่แต่ละหน้าจอหรือฟีเจอร์ต้องการ
Queries สำหรับการอ่าน; mutations คือวิธีที่คุณ เปลี่ยนข้อมูล ใน GraphQL API—สร้าง อัปเดต หรือ ลบเรคอร์ด
Mutation ส่วนใหญ่เดินตามรูปแบบเดียวกัน:
input object) เช่น ฟิลด์ที่ต้องการอัปเดตMutations มัก คืนข้อมูลโดยตั้งใจ แทนที่จะคืนแค่ success: true การคืนวัตถุที่อัปเดต (หรืออย่างน้อย id กับฟิลด์สำคัญ) ช่วยให้ UI:
รูปแบบที่พบบ่อยคือ type “payload” ที่รวมทั้ง entity ที่อัปเดตและข้อผิดพลาดใดๆ
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
สำหรับ API ที่ขับเคลื่อนด้วย UI กฎที่ดีคือ: คืนสิ่งที่คุณต้องการเพื่อเรนเดอร์สถานะถัดไป (เช่น user ที่อัปเดตพร้อม errors) นั่นทำให้ไคลเอนต์เรียบง่าย หลีกเลี่ยงการเดาว่าอะไรเปลี่ยน และทำให้จัดการความล้มเหลวง่ายขึ้น
สคีมาบอกว่าถามอะไรได้ ส่วน resolvers บอกว่าจะเอามันมาอย่างไร Resolver เป็นฟังก์ชันที่แนบกับฟิลด์ในสคีมา เมื่อไคลเอนต์ขอฟิลด์นั้น GraphQL จะเรียก resolver เพื่อดึงหรือคำนวณค่า
GraphQL รัน query โดยเดินตามรูปทรงที่ขอ สำหรับแต่ละฟิลด์ มันจะหา resolver ที่ตรงกันและเรียกใช้ บาง resolver แค่คืนค่าจากอ็อบเจกต์ในหน่วยความจำ บางตัวเรียกฐานข้อมูล เรียกบริการอื่น หรือรวมหลายแหล่งเข้าด้วยกัน
ตัวอย่าง: ถ้าสคีมามี User.posts resolver ของ posts อาจ query ตาราง posts ด้วย userId หรือเรียก Posts service แยกต่างหาก
Resolvers เป็นกาวเชื่อมระหว่างสคีมาและระบบจริงของคุณ:
การแมปนี้ยืดหยุ่น: คุณสามารถเปลี่ยนการใช้งานแบ็กเอนด์โดยไม่ต้องเปลี่ยนรูปแบบคำขอของไคลเอนต์—ตราบใดที่สคีมายังคงเหมือนเดิม
เพราะ resolvers อาจถูกรันต่อฟิลด์และต่อไอเท็มในลิสต์ มันง่ายที่จะเผลอเรียกหลายคำขอเล็กๆ (เช่น ดึงโพสต์สำหรับผู้ใช้ 100 คนด้วย 100 คำขอแยกกัน) รูปแบบ “N+1” นี้ทำให้การตอบช้า
การแก้ปัญหาทั่วไปรวมถึงการ batching และ caching (เช่น รวบรวม IDs แล้วดึงในคำขอเดียว) และระมัดระวังเกี่ยวกับฟิลด์ซ้อนที่สนับสนุนให้ไคลเอนต์ขอมากเกินไป
การอนุญาตมักบังคับใช้ใน resolvers (หรือตัวกลางร่วม) เพราะ resolvers รู้ว่า ใคร กำลังขอ (ผ่าน context) และ ข้อมูลอะไร ที่ถูกเข้าถึง การตรวจสอบรูปแบบข้อมูลมักเกิดสองระดับ: GraphQL จัดการการตรวจสอบประเภท/โครงสร้างอัตโนมัติ ในขณะที่ resolvers บังคับใช้กฎธุรกิจ (เช่น “เฉพาะ admin เท่านั้นที่ตั้งค่านี้ได้”)
สิ่งที่ใหม่กับ GraphQL อาจงงคือคำขอหนึ่งสามารถ “สำเร็จ” แต่ยังมีข้อผิดพลาดได้ นั่นเพราะ GraphQL เป็นมุมมองตามฟิลด์: ถ้าฟิลด์บางตัว resolve ได้และบางตัวไม่ได้ คุณอาจได้ข้อมูลบางส่วนกลับมา
การตอบ GraphQL แบบทั่วไปสามารถมีทั้ง data และอาเรย์ errors:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
สิ่งนี้มีประโยชน์: ไคลเอนต์ยังคงเรนเดอร์สิ่งที่มีได้ (เช่น โปรไฟล์ผู้ใช้) ขณะที่จัดการฟิลด์ที่หายไป
data มักเป็น nullเขียนข้อความข้อผิดพลาดสำหรับผู้ใช้ปลายทาง ไม่ใช่สำหรับดีบัก หลีกเลี่ยงการเปิดเผย stack trace, ชื่อฐานข้อมูล หรือ ID ภายใน รูปแบบที่ดีคือ:
message สั้นและปลอดภัยextensions.code แบบเครื่องอ่านได้และคงที่retryable: true)บันทึกรายละเอียดข้อผิดพลาดในฝั่งเซิร์ฟเวอร์พร้อม request ID เพื่อสืบสวนโดยไม่เปิดเผยข้อมูลภายใน
กำหนด “สัญญา” ข้อผิดพลาดเล็กๆ ที่เว็บและมือถือใช้ร่วมกัน: ค่าทั่วไปของ extensions.code (เช่น UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), เมื่อใดควรโชว์ toast vs ข้อผิดพลาดระดับฟิลด์แบบอินไลน์ และวิธีจัดการข้อมูลบางส่วน ความสม่ำเสมอช่วยป้องกันไม่ให้แต่ละไคลเอนต์คิดกฎข้อผิดพลาดของตัวเอง
Subscriptions คือวิธีของ GraphQL ในการ ผลักข้อมูลไปยังไคลเอนต์เมื่อมีการเปลี่ยนแปลง แทนที่จะให้ไคลเอนต์ถามซ้ำๆ มักส่งผ่านการเชื่อมต่อถาวร (โดยทั่วไปคือ WebSockets) เพื่อให้เซิร์ฟเวอร์ส่งเหตุการณ์ทันทีที่มีการเปลี่ยนแปลง
Subscription เหมือน query มาก แต่ผลลัพธ์ไม่ใช่การตอบครั้งเดียว มันเป็น สตรีมของผลลัพธ์—แต่ละรายการแทนเหตุการณ์หนึ่งรายการ
ทางเทคนิค ไคลเอนต์ “สมัครรับ” หัวข้อ (เช่น messageAdded ในแอปแชท) เมื่อเซิร์ฟเวอร์เผยแพร่เหตุการณ์ ผู้สมัครที่เชื่อมต่อจะได้รับ payload ที่ตรงกับ selection set ของ subscription
Subscriptions เหมาะเมื่อผู้ใช้คาดหวังการเปลี่ยนแปลงทันที:
การ polling คือไคลเอนต์ถามว่า “มีอะไรใหม่ไหม?” ทุก N วินาที มันเรียบง่าย แต่เปลืองคำขอเมื่อไม่มีการเปลี่ยนแปลงและยังรู้สึกหน่วง
กับ subscriptions เซิร์ฟเวอร์ส่งอัปเดตทันที วิธีนี้ลดทราฟิกที่ไม่จำเป็นและเพิ่มความรู้สึกว่าเร็ว—แต่แลกด้วยการต้องรักษาการเชื่อมต่อและจัดการโครงสร้างพื้นฐานเรียลไทม์
Subscriptions ไม่จำเป็นเสมอไป ถ้าการอัปเดตไม่บ่อย ไม่จำเป็นต้องทันที หรือสามารถรวมเป็นชุดได้ polling หรือการ re-fetch หลังการกระทำผู้ใช้ก็เพียงพอ
พวกมันยังเพิ่มภาระการดำเนินงาน: การสเกลการเชื่อมต่อ, การยืนยันตัวตนบน session ยาวนาน, การ retry, และการมอนิเตอริ่ง กฎที่ดีคือ: ใช้ subscriptions เมื่อ เรียลไทม์เป็นข้อกำหนดของผลิตภัณฑ์ ไม่ใช่แค่ฟีเจอร์เสริม
GraphQL มักถูกบรรยายว่า “ให้พลังแก่ไคลเอนต์” แต่พลังนั้นมีต้นทุน การรู้ข้อแลกเปลี่ยนล่วงหน้าช่วยตัดสินใจว่าเมื่อใด GraphQL เหมาะสม และเมื่อใดอาจเกินจำเป็น
ชัยชนะหลักคือ การดึงข้อมูลที่ยืดหยุ่น: ไคลเอนต์ร้องขอเฉพาะฟิลด์ที่ต้องการ ซึ่งลด over-fetching และทำให้การเปลี่ยนแปลง UI เร็วขึ้น
ข้อได้เปรียบอีกอย่างคือ สัญญาที่ชัดเจน จาก สคีมา GraphQL สคีมากลายเป็นแหล่งความจริงเดียวสำหรับ types และ operations ซึ่งช่วยการทำงานร่วมกันและเครื่องมือพัฒนา
ทีมมักเห็น ประสิทธิภาพการทำงานของไคลเอนต์ดีขึ้น เพราะนักพัฒนา frontend สามารถ iterate ได้โดยไม่ต้องรอ endpoint ใหม่ และเครื่องมือเช่น Apollo Client สร้าง types และช่วยให้การดึงข้อมูลเป็นระบบมากขึ้น
GraphQL อาจทำให้ การแคชซับซ้อนขึ้น ใน REST การแคชมักเป็น “ต่อ URL” แต่กับ GraphQL คิวรีหลายแบบใช้ endpoint เดียว ดังนั้นการแคชพึ่งพารูปร่างของ query, cache แบบ normalized, และการตั้งค่าฝั่งเซิร์ฟเวอร์/ไคลเอนต์อย่างรอบคอบ
ฝั่งเซิร์ฟเวอร์มี กับดักด้านประสิทธิภาพ คิวรีที่ดูเล็กอาจกระตุ้นการเรียกแบ็กเอนด์หลายรายการ ถ้าไม่ได้ออกแบบ resolvers ให้ดี (batching, หลีกเลี่ยง N+1, ควบคุมฟิลด์ที่แพง)
ยังมี learning curve: สคีมา, resolvers, และรูปแบบไคลเอนต์อาจไม่คุ้นเคยสำหรับทีมที่ชินกับ API แบบ endpoint
เพราะไคลเอนต์ขอข้อมูลได้มาก GraphQL API ควรกำหนด ขีดจำกัดความลึกและความซับซ้อนของคิวรี เพื่อต้านการร้องขอที่ใหญ่เกินไปทั้งโดยเจตนาและไม่ตั้งใจ
การยืนยันตัวตนและการอนุญาตควรถูกบังคับ ต่อฟิลด์ ไม่ใช่แค่ระดับ route เนื่องจากฟิลด์ต่างกันอาจมีนโยบายการเข้าถึงต่างกัน
ในเชิงการดำเนินงาน ลงทุนใน logging, tracing, และมอนิเตอริ่ง ที่เข้าใจ GraphQL: ติดตามชื่อ operation, ตัวแปร (อย่างระมัดระวัง), เวลา resolver, และอัตราข้อผิดพลาด เพื่อให้จับคิวรีช้าและ regression ได้เร็ว
GraphQL และ REST ต่างช่วยให้แอปคุยกับเซิร์ฟเวอร์ได้ แต่จัดโครงสร้างการสนทนาแตกต่างกันมาก
REST เป็นแบบ resource-based คุณดึงข้อมูลโดยเรียก endpoint ต่างๆ (เช่น /users/123 หรือ /orders?userId=123) แต่ละ endpoint คืนรูปแบบข้อมูลที่เซิร์ฟเวอร์ตัดสินใจไว้
REST ยังพึ่งพา semantic ของ HTTP: วิธีการเช่น GET/POST/PUT/DELETE, status codes, และกฎการแคช นั่นทำให้ REST เหมาะเมื่อทำ CRUD ธรรมดาหรือทำงานร่วมกับการแคชของเบราว์เซอร์/พร็อกซี
GraphQL เป็น schema-based แทนที่จะมีหลาย endpoint โดยปกติจะมี endpoint เดียว และไคลเอนต์ส่ง query ที่บอกฟิลด์ที่ต้องการ เซิร์ฟเวอร์ตรวจสอบคำขอนั้นกับ สคีมา และคืนผลตามรูปแบบที่ query ระบุ
การที่ไคลเอนต์เลือกฟิลด์เองนี่แหละทำให้ GraphQL ลด over-fetching และ under-fetching ได้ โดยเฉพาะสำหรับหน้าจอที่ต้องข้อมูลจากหลายโมเดลที่เกี่ยวข้อง
REST มักเหมาะกว่าเมื่อตอน:
หลายทีมผสมทั้งสอง:
คำถามเชิงปฏิบัติไม่ใช่ “อันไหนดีกว่า?” แต่คือ “อันไหนเหมาะกับกรณีใช้งานนี้โดยมีความซับซ้อนน้อยที่สุด?”
การออกแบบ GraphQL API ง่ายที่สุดเมื่อคุณมองมันเป็นผลิตภัณฑ์สำหรับคนที่สร้างหน้าจอ ไม่ใช่การสะท้อนฐานข้อมูล เริ่มเล็ก ยืนยันด้วยกรณีใช้งานจริง แล้วขยายตามความต้องการ
ลิสต์หน้าจอสำคัญ (เช่น “รายการสินค้า”, “รายละเอียดสินค้า”, “เช็คเอาต์”) สำหรับแต่ละหน้าจอจดฟิลด์ที่ต้องการและการโต้ตอบที่รองรับ
สิ่งนี้ช่วยหลีกเลี่ยง “god queries”, ลด over-fetching และชัดเจนว่าจุดที่ต้องมีการกรอง, การจัดเรียง, และการแบ่งหน้าอยู่ที่ไหน
กำหนด core types ก่อน (เช่น User, Product, Order) และความสัมพันธ์ของพวกมัน แล้วเพิ่ม:
ใช้ชื่อที่สื่อความหมายเชิงธุรกิจมากกว่าชื่อฐานข้อมูล “placeOrder” สื่อความหมายดีกว่า “createOrderRecord”.
เก็บชื่อให้สอดคล้อง: เอกพจน์สำหรับของชิ้น (product), พหูพจน์สำหรับคอลเลกชัน (products). สำหรับ pagination ปกติจะเลือกหนึ่งแบบ:
ตัดสินใจตั้งแต่ต้นเพราะมันกำหนดโครงสร้างการตอบของ API
GraphQL รองรับคำอธิบายโดยตรงในสคีมา—ใช้คำอธิบายเหล่านั้นสำหรับฟิลด์, อาร์กิวเมนต์ และกรณีขอบ แล้วเพิ่มตัวอย่างคัดลอกไปใช้ในเอกสาร (รวม pagination และสถานการณ์ข้อผิดพลาดทั่วไป) สคีมาที่อธิบายดีจะทำให้ introspection และ API explorer มีประโยชน์มากขึ้น
การเริ่มกับ GraphQL ส่วนใหญ่คือการเลือกเครื่องมือที่มีการสนับสนุนดีและตั้ง workflow ที่เชื่อถือได้ คุณไม่ต้องรับทุกอย่างพร้อมกัน—ทำให้ query หนึ่งทำงาน end-to-end แล้วค่อยขยาย
เลือกเซิร์ฟเวอร์ตามสแตกของคุณและว่าต้องการอะไรที่ "batteries included" มากแค่ไหน:
ก้าวปฏิบัติ: กำหนดสคีมาเล็กๆ (สองสาม type + หนึ่ง query), เขียน resolvers, และเชื่อมต่อแหล่งข้อมูลจริง (แม้จะเป็นรายการจำลองในหน่วยความจำ)
ถ้าคุณต้องการไปจากไอเดียสู่ API ที่ทำงานได้เร็วขึ้น แพลตฟอร์ม vibe-coding อย่าง Koder.ai สามารถช่วยสโฟลด์แอป full-stack เล็กๆ (React บน frontend, Go + PostgreSQL บน backend) และให้คุณ iterate บนสคีมา/ resolvers ผ่านแชท—แล้วส่งออกซอร์สโค้ดเมื่อพร้อมเป็นเจ้าของการติดตั้ง
บน frontend ทางเลือกมักขึ้นกับว่าต้องการนโยบายที่มีข้อกำหนดชัดเจนหรือความยืดหยุ่น:
ถ้าคุณย้ายจาก REST เริ่มด้วย GraphQL สำหรับหน้าจอหรือฟีเจอร์หนึ่ง และเก็บ REST สำหรับส่วนที่เหลือจนกว่าจะพิสูจน์แนวทางได้
ปฏิบัติเหมือนสคีมาเป็นสัญญา API ชั้นต่างๆ ของการทดสอบที่มีประโยชน์ได้แก่:
เพื่อเสริมความเข้าใจ ลองอ่านบทความเพิ่มเติมเช่น: graphql-vs-rest และ graphql-schema-design
GraphQL เป็น ภาษา query และ runtime สำหรับ APIs ลูกค้าส่ง query ที่บอกฟิลด์ที่ต้องการอย่างชัดเจน แล้วเซิร์ฟเวอร์ตอบกลับ JSON ที่สะท้อนโครงสร้างนั้น
ควรคิดว่าเป็นชั้นกลางระหว่างไคลเอนต์และแหล่งข้อมูลหลายชนิด (ฐานข้อมูล, บริการ REST, APIs ของบุคคลที่สาม, microservices).
GraphQL ช่วยจัดการกับ:
โดยให้ไคลเอนต์ร้องขอเฉพาะฟิลด์ที่ต้องการ (รวมถึงฟิลด์ซ้อน) GraphQL จึงลดการส่งข้อมูลส่วนเกินและทำให้โค้ดฝั่งไคลเอนต์เรียบง่ายขึ้น.
GraphQL ไม่ใช่:
ควรมองว่าเป็นสัญญา API + เอนจินรันไทม์ ไม่ใช่เวทมนตร์ด้านการจัดเก็บหรือประสิทธิภาพ.
API GraphQL ส่วนใหญ่เปิดผ่าน endpoint เดียว (มักเป็น /graphql). แทนที่จะมีหลาย URL คุณส่ง operation (query/mutation) ต่างกันไปยัง endpoint เดียว
ความหมายเชิงปฏิบัติ: การแคชและการสังเกตมักอิงจาก ชื่อ operation + ตัวแปร แทนที่จะเป็น URL.
สคีมาเป็นสัญญา API มันกำหนด:
User, Post)User.name)User.posts)เพราะเป็น เซิร์ฟเวอร์จึงสามารถตรวจสอบความถูกต้องของ query ก่อนรันและคืนข้อผิดพลาดที่ชัดเจนเมื่อฟิลด์ไม่มีอยู่จริง.
Queries เป็นการอ่านข้อมูล คุณระบุฟิลด์ที่ต้องการ แล้ว JSON ตอบกลับจะตรงตามโครงสร้างของ query
คำแนะนำ:
query GetUserWithPosts) เพื่อช่วยดีบักและมอนิเตอริ่งposts(limit: 2)).Mutations เป็นการเขียน/แก้ไขข้อมูล รูปแบบทั่วไปคือ:
input objectการคืนข้อมูล (ไม่ใช่แค่ success: true) ช่วยให้ UI อัปเดตทันทีและรักษา cache ให้สอดคล้อง.
Resolvers เป็น ฟังก์ชันระดับฟิลด์ ที่บอก GraphQL ว่าจะดึงหรือคำนวณค่าของแต่ละฟิลด์อย่างไร
ในทางปฏิบัติ resolvers อาจ:
โดยปกติการตรวจสอบสิทธิ์มักทำที่ resolvers (หรือตัวกลางที่แชร์ได้) เพราะ resolvers รู้ว่าผู้ขอคือใครและต้องการเข้าถึงข้อมูลอะไร.
รูปแบบ N+1 เกิดได้ง่าย (เช่น โหลดโพสต์แยกสำหรับผู้ใช้ 100 คน)
วิธีแก้ทั่วไป:
วัดเวลาของ resolver และสังเกตการเรียกลงไปยังบริการหลังบ้านซ้ำ ๆ ในการขอเดียวกัน.
GraphQL สามารถคืน ข้อมูลบางส่วน พร้อมกับอาเรย์ errors ซึ่งเกิดเมื่อบางฟิลด์ resolve ได้สำเร็จและบางฟิลด์ล้มเหลว (เช่น ฟิลด์ที่ถูกห้ามเข้าถึง หรือต่อบริการภายนอกแล้ว timeout)
การปฏิบัติที่ดี:
message สั้นและปลอดภัยสำหรับผู้ใช้extensions.code ที่อ่านโดยเครื่องได้และคงที่ (เช่น FORBIDDEN, BAD_USER_INPUT)ลูกค้าควรตัดสินใจว่าจะเรนเดอร์ข้อมูลบางส่วนเมื่อใดหรือถือว่าเป็นความล้มเหลวทั้งหมด.