Joe Armstrong และ Erlang: ปล่อยให้ล้มเหลวเพื่อแพลตฟอร์มที่เชื่อถือได้
ค้นพบว่า Joe Armstrong มีส่วนกำหนดแนวคิดของ Erlang อย่างไร ทั้งการทำงานพร้อมกัน การกำกับดูแล และแนวคิด 'ปล่อยให้ล้มเหลว'—แนวคิดที่ยังถูกนำมาใช้ในการสร้างบริการเรียลไทม์ที่เชื่อถือได้
หัวข้อที่โพสต์นี้ครอบคลุม (และทำไมยังสำคัญ)
Joe Armstrong ไม่ได้แค่ช่วยสร้าง Erlang—เขายังเป็นผู้ที่อธิบายแนวคิดของมันได้ชัดเจนที่สุด ผ่านการบรรยาย งานเขียน และมุมมองที่เน้นการปฏิบัติ เขาทำให้แนวคิดง่าย ๆ เป็นที่นิยม: หากคุณต้องการซอฟต์แวร์ที่ไม่ล่มบ่อย ให้คุณออกแบบเพื่อรองรับความล้มเหลวแทนการหวังว่าจะเลี่ยงได้
โพสต์นี้เป็นการพาทัวร์แนวคิดของ Erlang และเหตุผลที่มันยังสำคัญเมื่อต้องสร้างแพลตฟอร์มเรียลไทม์ที่เชื่อถือได้—เช่น ระบบแชท การสลับสาย การแจ้งเตือนสด การประสานงานผู้เล่นหลายคน และโครงสร้างพื้นฐานที่ต้องตอบสนองเร็วและสม่ำเสมอแม้ว่าส่วนหนึ่งจะทำงานผิดพลาด
“เรียลไทม์” พูดง่าย ๆ ว่าอย่างไร
เรียลไทม์ไม่ได้หมายความเสมอไปว่า “ไมโครวินาที” หรือ “กำหนดเวลาเข้มงวด” ในหลายผลิตภัณฑ์มันหมายถึง:
- การตอบสนองที่รวดเร็วที่ผู้ใช้รู้สึกได้ (ไม่มีการหยุดชะงักลึกลับ)
- พฤติกรรมที่คาดเดาได้เมื่อโหลดสูง (อาจช้าลง แต่ไม่ควรลุกลาม)
- บริการที่ยังทำงานได้ในระหว่างความล้มเหลวบางส่วน (คอมโพเนนต์ที่ไม่ดีไม่ควรลากทุกอย่างลงไปด้วย)
Erlang ถูกสร้างขึ้นสำหรับระบบโทรคมนาคมที่ความคาดหวังเหล่านี้ไม่สามารถลดทอน—และแรงกดดันนั้นได้หล่อหลอมแนวคิดสำคัญของมัน
เสาหลักสามข้อที่เราจะมุ่งเน้น
แทนที่จะลงลึกที่ไวยากรณ์ เราจะเน้นที่แนวคิดที่ทำให้ Erlang มีชื่อเสียงและยังคงปรากฏในงานออกแบบระบบสมัยใหม่:
- การขนานเป็นค่าเริ่มต้น: สร้างซอฟต์แวร์จากคนงานเล็ก ๆ แยกกันหลายตัว แทนที่จะเป็นไม่กี่โปรแกรมใหญ่
- การออกแบบเพื่อความทนทานต่อความผิดพลาด: สมมติว่าบั๊ก การหมดเวลา และการล้มเกิดขึ้นได้—แล้ววางแผนว่าจะเกิดอะไรต่อไป
- “ปล่อยให้ล้มเหลว”: อย่าป้องกันทุกบรรทัดโค้ดอย่างหนัก ให้ล้มเร็วแล้วกู้คืนอย่างสะอาดด้วยโครงสร้าง (ไม่ใช่ฮีโร่คนเดียว)
ระหว่างทาง เราจะเชื่อมโยงแนวคิดเหล่านี้กับโมเดลตัวแสดงและการส่งข้อความ อธิบายต้นไม้การกำกับดูแลและ OTP ในแบบเข้าใจง่าย และแสดงว่าทำไม BEAM VM ถึงทำให้แนวทางนี้ใช้งานได้จริง
แม้คุณจะไม่ได้ใช้ Erlang (และอาจไม่เคยใช้) ข้อสรุปยังคงเป็นจริง: กรอบคิดของ Armstrong ให้เช็คลิสต์ทรงพลังสำหรับการสร้างระบบที่ยังคงตอบสนองและมีความพร้อมเมื่อโลกภายนอกซับซ้อน
แรงจูงใจของ Joe Armstrong: สร้างระบบให้ไม่ล้ม
สวิตช์โทรคมนาคมและแพลตฟอร์มการสลับสายไม่สามารถ "ปิดเพื่อบำรุงรักษา" ได้เหมือนเว็บไซต์หลายแห่ง พวกมันถูกคาดหวังให้จัดการการโทร เหตุการณ์เรียกเก็บเงิน และการส่งสัญญาณตลอดเวลา—บ่อยครั้งมีความต้องการความพร้อมใช้งานและการตอบสนองที่คาดเดาได้
Erlang เริ่มต้นภายใน Ericsson ในปลายทศวรรษ 1980 เป็นความพยายามที่จะตอบความเป็นจริงเหล่านั้นด้วยซอฟต์แวร์ ไม่ใช่แค่ฮาร์ดแวร์เฉพาะ Joe Armstrong และเพื่อนร่วมงานไม่ได้ตามหาความงามทางทฤษฎีเพียงอย่างเดียว แต่พวกเขาพยายามสร้างระบบที่ผู้ปฏิบัติงานวางใจได้ภายใต้โหลดคงที่ ความล้มเหลวบางส่วน และสภาพจริงที่ยุ่งเหยิง
“น่าเชื่อถือ” หมายถึงอะไรในเชิงปฏิบัติ
การเปลี่ยนวิธีคิดสำคัญคือ ความน่าเชื่อถือไม่เท่ากับ “ไม่ล้มเลย” ในระบบขนาดใหญ่ที่ทำงานยาวนาน สิ่งต่าง ๆ จะล้ม: กระบวนการได้รับอินพุตไม่คาดคิด โหนดรีบูต ลิงก์เครือข่ายกระชาก หรือการพึ่งพาล้มเหลวชั่วคราว
ดังนั้นเป้าหมายจึงกลายเป็น:
- ให้บริการผู้ใช้ต่อไปแม้บางส่วนทำงานผิดพลาด
- ตรวจจับความล้มเหลวอย่างรวดเร็ว
- กู้คืนอัตโนมัติ โดยมีการแทรกแซงของมนุษย์น้อยที่สุด
- แยกข้อผิดพลาดเพื่อไม่ให้บั๊กหนึ่งตัวลากทุกอย่างลงไป
นี่คือกรอบคิดที่ทำให้แนวคิดอย่างต้นไม้การกำกับดูแลและ “ปล่อยให้ล้มเหลว” ฟังดูสมเหตุสมผล: คุณออกแบบให้ความล้มเหลวเป็นเหตุการณ์ปกติ ไม่ใช่หายนะพิเศษ
น้อยในเชิงตำนาน มากในเชิงแก้ปัญหา
เป็นเรื่องง่ายที่จะเล่าเรื่องราวว่าเป็นการค้นพบโดยผู้มองการณ์ไกลคนเดียว แต่ภาพที่มีประโยชน์กว่าคือ: ข้อจำกัดของโทรคมนาคมบังคับให้ต้องเลือกแนวทางต่างออกไป Erlang ให้ความสำคัญกับการขนาน การแยก และการกู้คืนเพราะนั่นคือเครื่องมือปฏิบัติที่ต้องใช้เพื่อให้บริการทำงานต่อเมื่อโลกเปลี่ยนไปรอบ ๆ พวกมัน
เฟรมคิดที่มุ่งแก้ปัญหานี้คือเหตุผลที่บทเรียนของ Erlang ยังแปลเป็นระบบสมัยใหม่ได้ดี—ที่ใดก็ตามที่เวลาออนไลน์และการกู้คืนเร็วสำคัญกว่าการป้องกันสมบูรณ์แบบ
การขนานเป็นค่าเริ่มต้น: คนงานเล็ก ๆ จำนวนมาก
แนวคิดหลักใน Erlang คือ “การทำหลายอย่างพร้อมกัน” ไม่ใช่ฟีเจอร์พิเศษที่เพิ่มทีหลัง แต่เป็นวิธีปกติในการจัดโครงสร้างระบบ
กระบวนการที่เบา อธิบายแบบเรียบง่าย
ใน Erlang งานจะแบ่งเป็น "กระบวนการ" ขนาดเล็กจำนวนมาก คิดว่าเป็นคนงานเล็ก ๆ แต่ละคนรับผิดชอบงานหนึ่งงาน: จัดการการโทร ติดตามเซสชันแชท ตรวจสอบอุปกรณ์ ลองชำระเงินใหม่ หรือเฝ้าคิว
มันเบา หมายความว่าคุณสามารถมีจำนวนมากโดยไม่ต้องใช้ฮาร์ดแวร์มหาศาล แทนที่จะให้คนงานหนักคนเดียวพยายามจัดการทุกอย่าง คุณจะได้ฝูงคนงานที่มุ่งเน้น สามารถเริ่ม หยุด และถูกแทนที่ได้เร็ว
ทำไม "โปรแกรมใหญ่หนึ่งตัว" ถึงพังในรูปแบบต่างกัน
หลายระบบถูกออกแบบเป็นโปรแกรมใหญ่อันเดียวที่มีหลายส่วนเชื่อมโยงแน่น เมื่อระบบแบบนั้นเจอบั๊กร้ายแรง ปัญหาหน่วยความจำ หรือการทำงานที่บล็อก ความล้มเหลวจะกระจายออกไป—เหมือนไฟฟ้ากระตุกแล้วตึกทั้งตึกดับ
Erlang ผลักไปทางตรงกันข้าม: แยกความรับผิดชอบ ถ้าคนงานเล็กตัวหนึ่งทำงานผิดพลาด คุณสามารถหยุดและแทนที่คนงานนั้นได้โดยไม่กระทบงานอื่นที่ไม่เกี่ยวข้อง
การส่งข้อความเหมือนการส่งโน้ต
คนงานเหล่านี้ประสานงานอย่างไร? พวกมันไม่แอบดูสถานะภายในซึ่งกันและกัน แต่ส่งข้อความ—เหมือนการส่งโน้ตแทนการเขียนบนไวท์บอร์ดร่วมกันที่ยุ่งเหยิง
คนงานหนึ่งอาจบอกว่า “มีคำขอใหม่” “ผู้ใช้คนนี้ตัดการเชื่อมต่อแล้ว” หรือ “ลองอีกครั้งใน 5 วินาที” ผู้รับอ่านโน้ตแล้วตัดสินใจว่าจะทำอย่างไร
ประโยชน์หลักคือการกักกัน: เพราะคนงานถูกแยกและสื่อสารผ่านข้อความ ความล้มเหลวจึงแพร่กระจายน้อยลงในระบบทั้งหมด
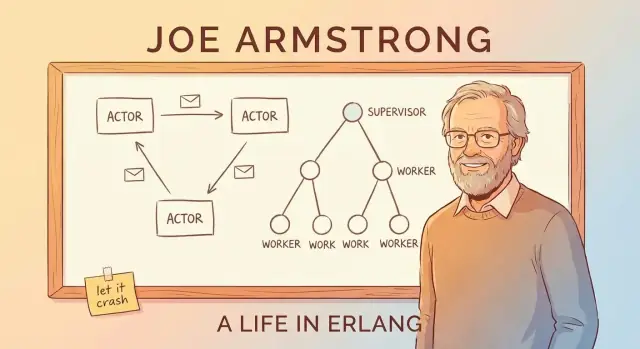
การส่งข้อความและโมเดลตัวแสดง (โดยไม่ใช้ศัพท์ไกลตัว)
วิธีง่าย ๆ ในการเข้าใจ "actor model" ของ Erlang คือจินตนาการระบบที่ประกอบด้วยคนงานเล็ก ๆ อิสระจำนวนมาก
ตัวแสดง: คนงานเล็กที่สื่อสารด้วยข้อความเท่านั้น
ตัวแสดง (actor) เป็นหน่วยปิดที่มีสถานะส่วนตัวและกล่องจดหมาย มันทำสามอย่างพื้นฐาน:
- รับข้อความ (ทีละข้อความ) จากกล่องจดหมายของมัน
- ปรับสถานะภายในของมันเอง
- ส่งข้อความไปยังตัวแสดงอื่น
แค่นั้นเอง ไม่มีตัวแปรแชร์ที่ซ่อนอยู่ ไม่มีการแอบแก้สถานะของคนงานอื่น ถ้าต้องการอะไรจากคนงานอื่น มันก็ขอผ่านข้อความ
ทำไมการหลีกเลี่ยงสถานะแชร์ช่วยตัดบั๊กได้มาก
เมื่อเธรดหลายตัวแชร์ข้อมูลเดียวกัน จะเกิด race conditions: สองอย่างเปลี่ยนค่าเดียวกันเกือบพร้อมกัน ผลลัพธ์ขึ้นกับจังหวะเวลา ซึ่งทำให้บั๊กเป็นแบบสลับซับซ้อนและยากจะทำซ้ำ
ด้วยการส่งข้อความ ตัวแสดงแต่ละตัวเป็นเจ้าของข้อมูลของตัวเอง ฝ่ายอื่นไม่สามารถแก้ไขได้โดยตรง แม้มันจะไม่กำจัดบั๊กทั้งหมด แต่ลดปัญหาจากการเข้าถึงพร้อมกันได้อย่างมาก
Back-pressure อธิบายเหมือนคิวที่ร้านกาแฟ
ข้อความไม่ได้มาฟรี ถ้าตัวแสดงได้รับข้อความเร็วกว่าที่จะประมวลผล กล่องจดหมายของมันจะโตขึ้น นั่นคือ back-pressure: ระบบกำลังบอกคุณโดยอ้อมว่า “ส่วนนี้มีภาระมากเกินไป”
ในการปฏิบัติ คุณตรวจสอบขนาดกล่องจดหมายและตั้งขีดจำกัด: ลดโหลด ทยอยส่ง ตัวอย่าง หรือนำงานไปให้คนงานเพิ่มขึ้น แทนที่จะปล่อยให้คิวโตไม่หยุด
ตัวอย่างชัดเจน: การแจ้งเตือนแชท
จินตนาการแอปแชท ผู้ใช้แต่ละคนอาจมีตัวแสดงที่รับผิดชอบการส่งการแจ้งเตือน เมื่อผู้ใช้หลุดออฟไลน์ ข้อความยังคงมาถึง—ทำให้กล่องจดหมายโตขึ้น ระบบที่ออกแบบดีอาจตั้งเพดานคิว ทิ้งการแจ้งเตือนที่ไม่สำคัญ หรือสลับเป็นโหมดสรุป แทนที่จะปล่อยให้ผู้ใช้ช้ารายเดียวทำให้บริการทั้งหมดช้าลง
“ปล่อยให้ล้มเหลว” อธิบาย: ล้มเร็ว กู้คืนให้เร็วกว่า
“ปล่อยให้ล้มเหลว” ไม่ใช่คำขวัญสำหรับวิศวกรรมแบบลวก ๆ มันคือกลยุทธ์ความน่าเชื่อถือ: เมื่อคอมโพเนนต์เข้าสู่สถานะไม่ดีหรือไม่คาดคิด มันควรหยุดอย่างรวดเร็วและชัดเจน แทนที่จะค่อย ๆ พะยุงให้รอด
ความหมายที่แท้จริง
แทนที่จะเขียนโค้ดเพื่อจัดการทุกขอบกรณีภายในกระบวนการเดียว Erlang ส่งเสริมให้คนงานแต่ละตัวเล็กและมุ่งเป้า หากคนงานพบสิ่งที่จัดการไม่ได้ (สถานะเสีย รูปแบบข้อมูลผิดสมมติ หรืออินพุตไม่คาดคิด) มันจะออกจากระบบ ส่วนอื่นของระบบมีหน้าที่เริ่มใหม่
นี่เปลี่ยนคำถามหลักจาก “จะป้องกันการล้มได้อย่างไร?” เป็น “จะกู้คืนอย่างสะอาดเมื่อเกิดการล้มได้อย่างไร?”
การแลกเปลี่ยน: ลดการตรวจสอบป้องกัน แต่ตรรกะชัดเจนขึ้น
การเขียนโค้ดป้องกันทุกที่สามารถเปลี่ยนการไหลง่าย ๆ ให้เป็นเขาวงกตของเงื่อนไข retries และสถานะกึ่งเสร็จ “ปล่อยให้ล้มเหลว” แลกเปลี่ยนความซับซ้อนเหล่านี้เป็น:
- เส้นทางโค้ดที่เรียบง่ายและอ่านง่ายขึ้น
- การตรวจจับสมมติฐานที่ผิดได้เร็วขึ้น
- การกู้คืนที่สม่ำเสมอ (เพราะรวมศูนย์)
แนวคิดใหญ่คือการทำให้การกู้คืนคาดเดาได้และทำซ้ำได้ ไม่ใช่การแก้ไขเฉพาะที่ในทุกฟังก์ชัน
เมื่อใช้ได้ดี และเมื่อไม่ควรใช้
วิธีนี้เหมาะเมื่อความล้มเหลวกู้คืนได้และถูกแยก: ปัญหาเครือข่ายชั่วคราว คำขอไม่ดี คนงานค้าง หรือการหมดเวลาเรียกบริการภายนอก
ไม่เหมาะเมื่อการล้มอาจก่อให้เกิดอันตรายที่ย้อนกลับไม่ได้ เช่น:
- สูญหายของข้อมูลโดยไม่มีแหล่งข้อมูลถาวร
- งานที่เกี่ยวข้องกับความปลอดภัยที่ "ลองอีกครั้ง" ไม่รับได้
การเริ่มใหม่ที่เร็วและสถานะที่แน่นอน
การล้มช่วยได้ก็ต่อเมื่อการกลับมาทำงานเร็วและปลอดภัย ในทางปฏิบัติ นั่นหมายถึงการเริ่มคนงานใหม่ในสถานะที่รู้ว่าดี—มักโดยการโหลดการตั้งค่าใหม่ สร้างแคชในหน่วยความจำจากสตอเรจถาวร และทำงานต่อโดยไม่อ้างว่าเหตุการณ์เสียไม่มีอยู่จริง
ต้นไม้การกำกับดูแล: ออกแบบเพื่อความล้มเหลวโดยเจตนา
แนวคิด “ปล่อยให้ล้มเหลว” ของ Erlang ได้ผลเพราะการล้มไม่ได้ปล่อยให้เกิดความสุ่ม ต้นแบบสำคัญคือ ต้นไม้การกำกับดูแล: ลำดับชั้นที่ supervisors ทำหน้าที่เหมือนผู้จัดการ และ workers ทำงานจริง (จัดการการโทร ติดตามเซสชัน บริโภคคิว ฯลฯ) เมื่อ worker ทำผิด ผู้จัดการสังเกตแล้วรีสตาร์ทมัน
ผู้จัดการที่รีสตาร์ทคนงาน
supervisor ไม่พยายาม “ซ่อม” worker ที่พังในที่เดียว แทนมันใช้กฎง่าย ๆ ที่ชัดเจน: ถ้าคนงานตาย ให้เริ่มหนึ่งใหม่ นั่นทำให้เส้นทางการกู้คืนคาดเดาได้และลดความจำเป็นในการกระจายโค้ดจัดการข้อผิดพลาดไปทั่วทั้งโปรเจกต์
สำคัญเท่ากันคือ supervisor สามารถตัดสินใจไม่รีสตาร์ทได้—หากบางอย่างล้มบ่อยเกินไป อาจบอกถึงปัญหาลึก และการรีสตาร์ทซ้ำ ๆ อาจทำให้แย่ลง
นโยบายการรีสตาร์ท (ภาพรวม)
การกำกับดูแลไม่ใช่แบบเดียวจบทุกอย่าง กลยุทธ์ทั่วไปได้แก่:
- One-for-one: รีสตาร์ทเฉพาะคนงานที่ล้ม เหมาะกับงานอิสระที่ความล้มเหลวหนึ่งอย่างไม่ควรกระทบคนอื่น
- Group restarts: ถ้าคนงานหนึ่งล้ม ชุดที่เกี่ยวข้องจะถูกรีสตาร์ทร่วม เหมาะกับคอมโพเนนต์ที่ต้องสอดคล้องกัน
การพึ่งพา: ส่วนที่ต้องคิดให้ละเอียด
การออกแบบ supervision ที่ดีเริ่มจากแผนผังการพึ่งพา: คอมโพเนนต์ไหนพึ่งพาอะไร และ “การเริ่มใหม่” มีความหมายอย่างไรสำหรับแต่ละตัว
ถ้าตัวจัดการเซสชันพึ่งพากระบวนการแคช การรีสตาร์ทเฉพาะตัวจัดการอาจทำให้มันเชื่อมต่อกับสถานะไม่ดี การรวมพวกมันภายใต้ supervisor ที่เหมาะสม (หรือรีสตาร์ทร่วมกัน) จะเปลี่ยนโหมดล้มเหลวที่ยุ่งให้เป็นการกู้คืนที่คาดเดาได้และทำซ้ำได้
OTP: บล็อกเครื่องมือที่ใช้ซ้ำได้สำหรับบริการที่เชื่อถือได้
ถ้า Erlang คือภาษา OTP (Open Telecom Platform) คือชุดชิ้นส่วนที่เปลี่ยน “ปล่อยให้ล้มเหลว” ให้เป็นสิ่งที่คุณสามารถรันใน production ได้เป็นปี
OTP เป็นกล่องเครื่องมือของรูปแบบพิสูจน์แล้ว
OTP ไม่ใช่ไลบรารีเดียว—มันคือชุดของข้อตกลงและคอมโพเนนต์พร้อมใช้งาน (เรียกว่า behaviours) ที่แก้ปัญหาส่วนที่น่าเบื่อแต่สำคัญของการสร้างบริการ:
gen_serverสำหรับ worker ระยะยาวที่เก็บสถานะและจัดการคำขอทีละรายการsupervisorสำหรับรีสตาร์ท worker ที่ล้มตามกฎชัดเจนapplicationสำหรับกำหนดวิธีการสตาร์ท หยุด และรวมเป็น release
นี่ไม่ใช่ “เวทมนตร์” แต่เป็นเทมเพลตที่มี callbacks ชัดเจน ทำให้โค้ดของคุณเข้าไปพอดีกับรูปแบบที่รู้จักได้ แทนที่จะคิดโครงสร้างใหม่ทุกโปรเจกต์
ทำไมรูปแบบมาตรฐานชนะเฟรมเวิร์กที่ทำเอง
ทีมมักสร้าง worker พื้นหลัง ฮุกมอนิเตอร์แบบบ้าน และตรรกะรีสตาร์ทที่ทำเอง มันใช้งานได้—จนกว่าจะไม่ ระบบที่ใช้ OTP ลดความเสี่ยงนั้นโดยผลักดันทุกคนไปสู่คำศัพท์และวงจรชีวิตเดียวกัน เมื่อวิศวกรคนใหม่เข้ามา เขาไม่ต้องเรียนรู้เฟรมเวิร์กเฉพาะของคุณก่อน แต่พึ่งพารูปแบบที่เข้าใจกันในชุมชน Erlang
OTP ชี้นำสถาปัตยกรรมในงานประจำวันอย่างไร
OTP กระตุ้นให้คิดในแง่ บทบาทของกระบวนการ และ ความรับผิดชอบ: อะไรเป็น worker อะไรเป็น coordinator อะไรควรรีสตาร์ทอะไร และอะไรไม่ควรรีสตาร์ทอัตโนมัติ
มันยังสนับสนุนระเบียบวินัย: การตั้งชื่อชัดเจน ลำดับการเริ่มต้นที่ชัดเจน การปิดตัวที่คาดเดาได้ และสัญญาณการมอนิเตอร์ในตัว ผลลัพธ์คือซอฟต์แวร์ที่ออกแบบมาให้รันต่อเนื่อง—บริการที่กู้คืนจากความผิดพลาด พัฒนาได้ตามเวลา และไม่ต้องการการคอยดูแลจากคนตลอดเวลา
BEAM VM: runtime ที่ทำให้โมเดลใช้งานได้จริง
แนวคิดใหญ่ของ Erlang—กระบวนการเล็ก การส่งข้อความ และ “ปล่อยให้ล้มเหลว”—จะยากขึ้นมากที่จะใช้ใน production หากไม่มี BEAM virtual machine BEAM คือ runtime ที่ทำให้รูปแบบเหล่านี้รู้สึกเป็นธรรมชาติ ไม่เปราะบาง
การตารางเวลา: ความเป็นธรรมมากกว่าการพึ่งพา "เธรดใหญ่"
BEAM ถูกสร้างมาเพื่อรันจำนวนมากของกระบวนการเบา แทนที่จะพึ่งพาเธรดของ OS ไม่กี่ตัวและหวังว่าแอปจะประพฤติดี BEAM จะตารางงานของกระบวนการ Erlang เอง
ประโยชน์ทางปฏิบัติคือการตอบสนองภายใต้โหลด: งานถูกแบ่งเป็นชิ้นเล็ก ๆ และหมุนเวียนไปอย่างยุติธรรม ดังนั้นไม่มีคนงานที่ทำงานหนักตัวเดียวควรถือระบบไว้เป็นเวลานาน นั่นเข้ากับบริการที่ประกอบจากงานอิสระหลายตัว—แต่ละตัวทำงานเล็ก ๆ แล้วยอมให้คิวอื่นได้ทำงานต่อ
การแยกและการเก็บขยะหน่วยความจำต่อกระบวนการ
แต่ละกระบวนการ Erlang มี heap ของตัวเองและมี garbage collection ของตัวเอง นั่นเป็นรายละเอียดสำคัญ: การเก็บขยะของกระบวนการหนึ่งไม่จำเป็นต้องหยุดโปรแกรมทั้งตัว
สำคัญเท่ากัน กระบวนการถูกแยก หากตัวหนึ่งล้ม มันไม่ทำลายหน่วยความจำของคนอื่น และ VM ยังคงอยู่ การแยกนี้คือรากฐานที่ทำให้ต้นไม้การกำกับดูแลเป็นไปได้จริง: ความล้มเหลวถูกกักกัน แล้วจัดการด้วยการรีสตาร์ทส่วนที่ล้ม แทนที่จะยกเลิกทุกอย่าง
การกระจาย: โหนดหลายตัวเป็นระบบเดียว
BEAM ยังรองรับการกระจายอย่างตรงไปตรงมา: คุณสามารถรันโหนด Erlang หลายตัว (instance ของ VM แยกกัน) และให้พวกมันสื่อสารด้วยการส่งข้อความ หากคุณเข้าใจว่า “กระบวนการสื่อสารด้วยข้อความ” การกระจายก็เป็นการขยายแนวคิดเดียวกัน—แค่บางกระบวนการอยู่บนโหนดอื่น
BEAM ไม่ได้สัญญาความเร็วสูงสุด แต่ทำให้การขนาน การกักกันความผิดพลาด และการกู้คืนเป็นค่าเริ่มต้น เพื่อให้เรื่องความน่าเชื่อถือเป็นเรื่องปฏิบัติได้ ไม่ใช่แค่ทฤษฎี
อัปเกรดโดยไม่หยุดระบบ (โค้ดร้อน แต่ระมัดระวัง)
หนึ่งในเทคนิคที่คนพูดถึงของ Erlang คือ hot code swapping: การอัปเดตส่วนของระบบที่รันอยู่โดยมีเวลาหยุดทำงานน้อยที่สุด (เมื่อ runtime และเครื่องมือรองรับ) คำมั่นสัญญาเชิงปฏิบัติไม่ใช่ "ไม่ต้องรีสตาร์ทอีกเลย" แต่เป็น "ส่งการแก้ไขโดยไม่เปลี่ยนเหตุการณ์เล็ก ๆ ให้กลายเป็นการหยุดใหญ่"
“โค้ดร้อน” หมายถึงอะไรจริง ๆ
ใน Erlang/OTP runtime สามารถโหลดโมดูลสองเวอร์ชันพร้อมกันได้ กระบวนการที่มีอยู่สามารถทำงานให้เสร็จด้วยเวอร์ชันเก่า ขณะที่การเรียกใหม่เริ่มใช้เวอร์ชันใหม่ นั่นให้ช่องทางแก้บั๊ก ปล่อยฟีเจอร์ หรือปรับพฤติกรรมโดยไม่ต้องเตะผู้ใช้ทุกคนออกจากระบบ
ถ้าทำดี นี่สนับสนุนเป้าหมายความเชื่อถือได้โดยตรง: รีสตาร์ทเต็มระบบน้อยลง หน้าต่างบำรุงรักษาสั้นลง และการแก้ปัญหาใน production ทำได้เร็วขึ้น
ข้อจำกัดที่ไม่ควรมองข้าม
ไม่ใช่การเปลี่ยนทั้งหมดปลอดภัยที่จะสลับสด ตัวอย่างของการเปลี่ยนที่ต้องระวัง (หรือจำเป็นต้องรีสตาร์ท) ได้แก่:
- การเปลี่ยนรูปแบบสถานะ (process คาดหวังข้อมูลคนละรูปแบบ แต่โค้ดใหม่คาดอีกแบบ)
- การเปลี่ยนโปรโตคอลหรือรูปแบบข้อความที่ต้องตรงกันข้ามบริการ
- การมิเกรตสคีมาที่ใช้เวลาหรือจำเป็นต้องประสานงาน
Erlang มีเครื่องมือสำหรับการเปลี่ยนที่ควบคุมได้ แต่คุณยังต้องออกแบบเส้นทางการอัปเกรด
มุมมอง: อัปเกรดและย้อนกลับเป็นเรื่องปกติ
การอัปเกรดสดทำงานได้ดีที่สุดเมื่อการอัปเกรดและย้อนกลับถือเป็นการปฏิบัติธรรมดา ไม่ใช่วิกฤตหายาก นั่นหมายถึงการวางแผนการทำเวอร์ชัน ความเข้ากันได้ และทาง “เลิกทำ” ตั้งแต่ต้น ในทางปฏิบัติ ทีมมักผสานเทคนิคอัปเกรดสดกับการปล่อยเป็นขั้น ๆ การตรวจสุขภาพ และการกู้คืนโดย supervision
แม้จะไม่เคยใช้ Erlang บทเรียนนี้ยังถ่ายทอดได้: ออกแบบระบบให้การเปลี่ยนแปลงอย่างปลอดภัยเป็นข้อกำหนดชั้นหนึ่ง ไม่ใช่เรื่องเสริมทีหลัง
จุดที่แนวคิดของ Erlang เปล่งประกายบนแพลตฟอร์มเรียลไทม์
แพลตฟอร์มเรียลไทม์ไม่ใช่เรื่องของการจับเวลาเป๊ะ ๆ เสมอไป แต่เป็นการรักษาการตอบสนองในขณะที่สิ่งต่าง ๆ ผิดพลาดอยู่ตลอดเวลา: เครือข่ายสั่นคลอน การพึ่งพาช้าลง และทราฟฟิกพุ่ง แนวทางของ Erlang—ที่ Joe Armstrong สนับสนุน—เข้ากับความเป็นจริงนี้เพราะมันสมมติความล้มเหลวและถือว่าการขนานเป็นเรื่องปกติ ไม่ใช่ข้อยกเว้น
กรณีใช้งานเรียลไทม์ที่มักเห็นแนวคิดของ Erlang
แนวคิดแบบ Erlang โผล่ได้ดีในที่ที่มีกิจกรรมอิสระจำนวนมากเกิดขึ้นพร้อมกัน เช่น:
- Messaging และแชท: การสนทนาเล็ก ๆ จำนวนมาก แต่ละรายการมีสถานะและการลองใหม่ของตัวเอง
- การสื่อสารเรียลไทม์: สัญญาณเสียง/วิดีโอ การอัปเดตสถานะการเชื่อมต่อ และการประสานเซสชัน
- การประสานงาน IoT: ฝูงอุปกรณ์เช็คอิน ออกจากระบบ และกลับมาอย่างไม่คาดคิด
- เวิร์กโฟลว์การชำระเงิน: กระบวนการหลายขั้นตอนที่บางก้าวช้า ไม่พร้อม หรือต้องมีการชดเชย
“soft real-time” มักหมายถึงอะไร
ผลิตภัณฑ์ส่วนใหญ่ไม่ต้องการการรับประกันเข้มงวดเช่น “ทุกการกระทำต้องเสร็จภายใน 10 มิลลิวินาที” แต่ต้องการ soft real-time: latency ต่ำสำหรับคำขอทั่วไป การกู้คืนเร็วเมื่อบางส่วนล้ม และความพร้อมใช้งานสูงจนผู้ใช้แทบไม่สังเกตเห็นเหตุการณ์ผิดปกติ
ความล้มเหลวเป็นเรื่องปกติ: ออกแบบเพื่อรองรับมัน
ระบบจริงเจอปัญหา เช่น:
- การตัดการเชื่อมต่อ (เครือข่ายมือถือ, handoff ของ Wi‑Fi)
- การหมดเวลา เมื่อบริการ downstream ช้า
- การล่มเป็นบางส่วน ที่ภูมิภาคหรือการพึ่งพาหนึ่งตัวแย่ลง
โมเดลของ Erlang ส่งเสริมการแยกกิจกรรมแต่ละชิ้น (เซสชันผู้ใช้ อุปกรณ์ ความพยายามชำระเงิน) เพื่อไม่ให้ความล้มเหลวแพร่กระจาย แทนที่จะสร้างคอมโพเนนต์ยักษ์เดียวที่พยายามจัดการทุกอย่าง ทีมสามารถคิดเป็นหน่วยเล็ก ๆ: คนงานแต่ละตัวทำงานหนึ่งอย่าง พูดคุยผ่านข้อความ และถ้ามันพัง มันก็ถูกรีสตาร์ทอย่างสะอาด
การเปลี่ยนนี้—จาก “ป้องกันทุกข้อผิดพลาด” เป็น “จำกัดและกู้คืนจากข้อผิดพลาดอย่างรวดเร็ว”—มักเป็นสิ่งที่ทำให้แพลตฟอร์มเรียลไทม์ยังคงเสถียรเมื่อเผชิญแรงกดดัน
ความเข้าใจผิดทั่วไปและขอบเขตจริง
ชื่อเสียงของ Erlang อาจฟังเหมือนคำสัญญา: ระบบที่ ไม่เคย ล่มเพราะแค่รีสตาร์ท แต่ความจริงเป็นเรื่องปฏิบัติและมีประโยชน์กว่า “ปล่อยให้ล้มเหลว” เป็นเครื่องมือในการสร้างบริการที่เชื่อถือได้ ไม่ใช่ใบอนุญาตให้มองข้ามปัญหาหนัก ๆ
การรีสตาร์ทไม่ใช่แผ่นปะ
ข้อผิดพลาดทั่วไปคือมอง supervision เป็นวิธีซ่อนบั๊กลึก ถ้ากระบวนการล้มทันทีหลังสตาร์ท supervisor อาจรีสตาร์ทมันจนเกิด crash loop—เผาผลาญ CPU, สแปมล็อก และอาจก่อให้เกิดเหตุการณ์ใหญ่กว่าบั๊กเดิม
ระบบที่ดีใส่ backoff ขีดจำกัดความถี่การรีสตาร์ท และพฤติกรรม “เลิกพยายามและยกระดับ” การรีสตาร์ทควรคืนการทำงานปกติ ไม่ใช่ปกปิดสมมติฐานที่แตกเสีย
คำถามที่พบบ่อย
Why is Joe Armstrong’s Erlang mindset still relevant today?
Erlang ช่วยแพร่หลายกรอบคิดเรื่องความน่าเชื่อถือที่เป็นไปได้จริง: สมมติว่าบางส่วนจะล้มเหลว แล้วออกแบบว่าจะเกิดอะไรขึ้นต่อไป
แทนที่จะพยายามป้องกันการล้มเหลวทั้งหมด มันเน้นที่ การแยกข้อผิดพลาด, การตรวจจับเร็ว, และ การกู้คืนอัตโนมัติ ซึ่งสอดคล้องกับแพลตฟอร์มเรียลไทม์ เช่น แชท การสลับสาย การแจ้งเตือน และบริการประสานงาน
What does “real-time” mean in the post’s plain terms?
ในบริบทนี้ “เรียลไทม์” มักหมายถึง soft real-time:
- คำตอบรู้สึกเร็วและสม่ำเสมอ
- พฤติกรรมยังคงคาดเดาได้เมื่อโหลดเพิ่ม
- ระบบยังทำงานได้แม้จะมีความล้มเหลวเป็นบางส่วน
ไม่ใช่เรื่องของไทม์ไลน์ระดับไมโครวินาที แต่เป็นการหลีกเลี่ยงการค้าง วงจรลุกลาม และการล่มเป็นลูกโซ่
What does “concurrency by default” mean in Erlang-style design?
หมายถึงการออกแบบระบบเป็น คนงานเล็ก ๆ หลายตัวแยกจากกัน แทนที่จะเป็นคอมโพเนนต์ใหญ่ไม่กี่ตัวที่เชื่อมกันแน่น
แต่ละคนงานรับผิดชอบหน้าที่เฉพาะ (เช่น เซสชัน อุปกรณ์ สายเรียก การลองใหม่) ซึ่งช่วยให้การสเกลและการจำกัดความเสียหายจากข้อผิดพลาดง่ายขึ้น
What are Erlang “lightweight processes,” and why do they matter?
Lightweight processes เป็นคนงานอิสระขนาดเล็กที่สร้างได้จำนวนมาก
ข้อดีเชิงปฏิบัติคือ:
- สามารถสร้างกระบวนการหนึ่งตัวต่อสิ่งที่เป็นหน่วยงาน (ผู้ใช้/เซสชัน/อุปกรณ์)
- ข้อผิดพลาดจะอยู่ในขอบเขตของคนงานเดียว
- การเริ่มใหม่ถูกและเร็วกว่ารีบูตโมโนลิธขนาดใหญ่
Why does Erlang prefer message passing over shared state?
การส่งข้อความคือการประสานงานโดย ส่งข้อความ แทนการแชร์สถานะที่เปลี่ยนแปลงได้
วิธีนี้ช่วยลดชนิดของบั๊กจากการใช้งานพร้อมกัน (เช่น race conditions) เพราะแต่ละคนงานเป็นเจ้าของสถานะภายในของตัวเอง ฝ่ายอื่นต้องขอผ่านข้อความแทนการแก้ไขโดยตรง
What is back-pressure in an actor/message system, and how do you handle it?
Back-pressure เกิดเมื่อคนงานรับข้อความเร็วกว่าเวลาที่ประมวลผลได้ ทำให้กล่องจดหมาย (mailbox) โตขึ้น
วิธีแก้ปัญหาเชิงปฏิบัติได้แก่:
- ตรวจสอบขนาด mailbox/คิว
- ตั้งขีดจำกัด (ทิ้ง บีบตัวอย่าง หรือตั้งเพดาน)
- กระจายภาระไปยังคนงานมากขึ้น
- ลดระดับการให้บริการอย่างสวยงาม (เช่น ส่งสรุปแทนการแจ้งเต็มรูปแบบ)
What does “let it crash” actually mean (and what doesn’t it mean)?
“Let it crash” คือ: ถ้าคนงานเจอสถานะที่ผิดพลาดหรือไม่คาดคิด ให้มัน ล้มอย่างรวดเร็ว แทนที่จะวนแก้ปัญหาไปเรื่อย ๆ
การกู้คืนถูกจัดการโดยโครงสร้าง (เช่น supervisor) ซึ่งทำให้เส้นทางการกู้คืนคาดเดาได้และโค้ดย่อกว่า — แต่ต้องแน่ใจว่าการเริ่มใหม่ปลอดภัยและเร็ว
What are supervision trees, and why are they central to fault tolerance?
ต้นไม้การกำกับดูแลเป็นลำดับชั้นที่ ผู้กำกับ (supervisors) ตรวจสอบคนงาน และรีสตาร์ทตามกฎที่กำหนดไว้
แทนการกระจายการกู้คืนแบบกระจัดกระจาย คุณรวมไว้ที่ศูนย์กลาง:
- ตัดสินใจว่าจะรีสตาร์ทอะไรเมื่อเกิดความล้มเหลว
- ป้องกันวงจรการล้มไหลด้วยการจำกัด/หน่วงเวลา
- รีสตาร์ทร่วมเมื่อคอมโพเนนต์ต้องสอดคล้องกัน
What is OTP, and how does it help build reliable services?
OTP คือชุดรูปแบบและข้อตกลงที่ช่วยให้แนวคิด “let it crash” ใช้งานได้ยาวนานในระบบการผลิต
บล็อกมาตรฐานที่พบบ่อยได้แก่:
gen_serverสำหรับคนงานระยะยาวที่เก็บสถานะและตอบคำขอทีละรายการsupervisorสำหรับนโยบายการรีสตาร์ทอัตโนมัติapplicationสำหรับกำหนดวิธีการสตาร์ท หยุด และรวมใน release
ข้อได้เปรียบคือมีวงจรชีวิตที่คนในทีมคุ้นเคย แทนการสร้างเฟรมเวิร์กเฉพาะโครงการ
How can I apply Erlang’s lessons if I’m not using Erlang?
คุณสามารถนำหลักการเดียวกันไปใช้ในสแต็กอื่นได้โดยทำให้ความล้มเหลวและการกู้คืนเป็นเรื่องปกติ:
- แยกงานที่เสี่ยงออก (processes/containers/services)
- ใส่ timeouts, retries พร้อม backoff, circuit breakers และ bulkheads
- อัตโนมัติการกู้คืน (health checks + restart-on-failure)
- ใช้คิว/สตรีมเพื่อแยกผู้ผลิตและผู้บริโภค
ดูตัวอย่างการบูรณาการแนวทางเหล่านี้ในเวิร์กโฟลว์ของ Koder.ai ที่ช่วยให้การวางแผน การปรับปรุง และการย้อนกลับเป็นไปอย่างปลอดภัย