ทำไมการจัดการหน่วยความจำถึงมีผลต่อประสิทธิภาพและความปลอดภัย
การจัดการหน่วยความจำคือชุดกฎและกลไกที่โปรแกรมใช้ในการขอหน่วยความจำ ใช้งาน และคืนหน่วยความจำ โปรแกรมที่กำลังรันต้องการหน่วยความจำสำหรับตัวแปร ข้อมูลผู้ใช้ บัฟเฟอร์เครือข่าย รูปภาพ และผลลัพธ์ชั่วคราวต่าง ๆ เพราะหน่วยความจำมีจำกัดและต้องแชร์กับระบบปฏิบัติการและแอปอื่น ๆ ภาษาจึงต้องตัดสินใจว่า ใคร เป็นผู้รับผิดชอบการคืนหน่วยความจำและ เมื่อไหร่ ที่จะคืน
การตัดสินใจเหล่านี้กำหนดผลสองอย่างที่คนส่วนใหญ่สนใจ: โปรแกรมตอบสนองเร็วแค่ไหน และทำงานได้เชื่อถือได้เมื่อมีแรงกดดัน
“ประสิทธิภาพ” ในที่นี้หมายถึงอะไร
ประสิทธิภาพไม่ได้เป็นตัวเลขเดียว การจัดการหน่วยความจำส่งผลต่อ:
- อัตราผ่านงาน (Throughput): งานที่ทำได้ต่อวินาที (คำขอที่ตอบได้ เฟรมที่เรนเดอร์ ไฟล์ที่ประมวลผล)\n- ความหน่วง (Latency): เวลาที่ใช้ในแต่ละการดำเนินการ โดยเฉพาะการกระโดดขึ้นของ tail latency จากการหยุดชั่วคราวหรือการจัดสรรช้า\n- รอยเท้าหน่วยความจำ (Memory footprint): แรมที่โปรแกรมถือขณะรัน ซึ่งมีผลต่อค่าใช้จ่าย แบตเตอรี่ และความถี่ที่ OS เริ่มใช้ swap
ภาษาหนึ่งที่จัดสรรเร็วแต่บางครั้งหยุดเพื่อทำความสะอาดอาจดูดีในเบนช์มาร์กแต่รู้สึกกระตุกในแอปโต้ตอบ อีกโมเดลที่หลีกเลี่ยงการหยุดอาจต้องออกแบบรอบคอบเพื่อป้องกันการรั่วและข้อผิดพลาดเรื่องอายุของข้อมูล
“ความปลอดภัย” หมายถึงอะไร
ความปลอดภัยคือการป้องกันความล้มเหลวที่เกี่ยวกับหน่วยความจำ เช่น:
- การล่มของโปรแกรม (เข้าถึงหน่วยความจำที่ไม่ถูกต้อง)\n- การเสียหายของข้อมูล (เขียนผิดที่)\n- ช่องโหว่ด้านความปลอดภัย (บั๊กที่ผู้โจมตีสามารถแปรเป็นช่องโหว่ได้)
ปัญหาด้านความปลอดภัยหลายกรณีเกิดจากข้อผิดพลาดเรื่องหน่วยความจำ เช่น use-after-free หรือ buffer overflow
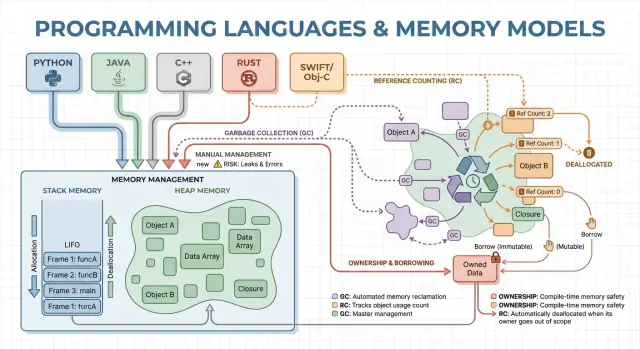
คำแนะนำนี้เป็นทัวร์แบบไม่เชิงเทคนิคของโมเดลหน่วยความจำหลักที่ใช้ในภาษายอดนิยม สิ่งที่พวกมันเน้น และการแลกเปลี่ยนที่คุณยอมรับเมื่อเลือกภาษา
แนวคิดหลัก: สแตก ฮีพ และอายุของอ็อบเจ็กต์
หน่วยความจำคือที่ที่โปรแกรมเก็บข้อมูลขณะที่รัน ส่วนใหญ่ภาษาจะจัดระเบียบรอบสองพื้นที่หลัก: สแตก และ ฮีพ
สแตก: ที่เก็บชั่วคราวและเร็ว
คิดว่าสแตกเป็นกองโพสต์อิทที่เรียบร้อย ใช้สำหรับงานตอนนี้ เมื่อฟังก์ชันเริ่ม จะได้ “เฟรม” เล็ก ๆ บนสแตกสำหรับตัวแปรท้องถิ่น เมื่อฟังก์ชันจบ เฟรมทั้งหมดถูกเอาออกทันที
วิธีนี้เร็วและคาดเดาได้—แต่ใช้ได้กับค่าที่ขนาดเป็นที่รู้และอายุสิ้นสุดพร้อมกับการเรียกฟังก์ชันเท่านั้น
ฮีพ: ที่เก็บยืดหยุ่นและอายุยาวกว่า
ฮีพเหมือนห้องเก็บของที่คุณเก็บอ็อบเจ็กต์ได้นานเท่าที่ต้องการ เหมาะสำหรับรายการที่ขนาดเปลี่ยนแปลงได้ ข้อความ หรืออ็อบเจ็กต์ที่แชร์ข้ามส่วนต่าง ๆ ของโปรแกรม
เพราะอ็อบเจ็กต์บนฮีพอาจมีอายุนานกว่าฟังก์ชันเดียว คำถามสำคัญคือ: ใครเป็นผู้รับผิดชอบปล่อยมัน และเมื่อไหร่? นั่นคือโมเดลการจัดการหน่วยความจำของภาษา
อายุของอ็อบเจ็กต์ และทำไมพอยน์เตอร์/รีเฟอเรนซ์จึงสำคัญ
พอยน์เตอร์ หรือ รีเฟอเรนซ์ คือวิธีเข้าถึงอ็อบเจ็กต์ทางอ้อม—เหมือนมีเบอร์ชั้นวางของสำหรับกล่องในห้องเก็บ หากกล่องถูกทิ้งแต่คุณยังมีเบอร์ชั้นวาง อาจอ่านข้อมูลขยะหรือโปรแกรมล้มเหลว (use-after-free)
ตัวอย่างสถานการณ์ง่าย ๆ
ลองจินตนาการลูปที่สร้างเรคคอร์ดลูกค้า ฟอร์แมตรายการข้อความ แล้วทิ้งมัน:
- บนสแตก: ตัวแปรชั่วคราวขนาดเล็กที่ใช้ระหว่างฟอร์แมต\n- บนฮีพ: เรคคอร์ดลูกค้าและข้อความ (ขนาดเปลี่ยนได้)
บางภาษาซ่อนรายละเอียดนี้ (ทำความสะอาดอัตโนมัติ) ขณะที่บางภาษาเปิดเผย (คุณต้องปล่อยหน่วยความจำเอง หรือปฏิบัติตามกฎ ownership) ส่วนที่เหลือของบทความนี้จะสำรวจว่า การตัดสินใจเหล่านั้นมีผลต่อความเร็ว การหยุด และความปลอดภัยอย่างไร
การจัดการหน่วยความจำด้วยตนเอง: ควบคุมแต่เสี่ยง
การจัดการด้วยตนเองหมายความว่าโปรแกรม (และนักพัฒนา) ขอหน่วยความจำและปล่อยมันในภายหลัง ในเชิงปฏิบัติจะเห็นได้ใน malloc/free ของ C หรือ new/delete ของ C++ ยังคงใช้บ่อยในระบบที่ต้องการการควบคุมอย่างแม่นยำว่าเมื่อใดหน่วยความจำถูกได้มาและคืน
ใช้การจัดสรร/ปล่อยแบบชัดเจนเมื่อใด
คุณมักจะจัดสรรเมื่ออ็อบเจ็กต์ต้องมีอายุต่อเนื่องนอกการเรียกฟังก์ชันปัจจุบัน เติบโตแบบไดนามิก หรือต้องมีเลย์เอาต์พิเศษเพื่อทำงานร่วมกับฮาร์ดแวร์ OS หรือโปรโตคอลเครือข่าย
ข้อดีด้านประสิทธิภาพ: ค่าใช้จ่ายคาดเดาได้ (เมื่อทำดี)
เมื่อไม่มี garbage collector ทำงานอยู่เบื้องหลัง จะมีการหยุดที่คาดไม่ถึงน้อยลง การจัดสรรและการปล่อยสามารถทำให้คาดเดาได้สูงโดยเฉพาะเมื่อจับคู่กับตัวจัดสรรแบบกำหนดเอง พูล หรือบัฟเฟอร์ตายตัว
การควบคุมด้วยมือยังลดโอเวอร์เฮด: ไม่มีขั้นตอน tracing ไม่มี write barriers และมักมีเมตาดาต้าน้อยต่ออ็อบเจ็กต์ เมื่อโค้ดออกแบบดี คุณสามารถทำให้บรรลุเป้าหมายความหน่วงที่เข้มงวดและรักษาการใช้หน่วยความจำภายในขอบเขตที่เข้มงวด
ความเสี่ยงด้านความปลอดภัย: โหมดความล้มเหลวยอดนิยม
การแลกเปลี่ยนคือโปรแกรมอาจทำผิดพลาดที่ runtime จะไม่ป้องกันให้อัตโนมัติ:
- การรั่วของหน่วยความจำ (ลืมปล่อย)
- การปล่อยซ้ำ (double-free)
- use-after-free (เข้าถึงหลังปล่อย)
บั๊กเหล่านี้ทำให้เกิดการล่มของโปรแกรม ข้อมูลเสียหาย และช่องโหว่ด้านความปลอดภัย
การบรรเทาทั่วไป
ทีมงานลดความเสี่ยงโดยจำกัดจุดที่อนุญาตให้ใช้การจัดสรรดิบและพึ่งรูปแบบเช่น:
- RAII ใน C++ (ทรัพยากรถูกปล่อยอัตโนมัติเมื่ออ็อบเจ็กต์ออกจากสโคป)
- สมาร์ทพอยน์เตอร์ (เช่น
std::unique_ptr) เพื่อเข้ารหัส ownership
- มาตรฐานการเขียนโค้ด, รายการตรวจโค้ด, sanitizers, และการวิเคราะห์แบบสแตติก
เมื่อตอบโจทย์
การจัดการด้วยตนเองมักเหมาะกับซอฟต์แวร์ฝังตัว ระบบเรียลไทม์ คอมโพเนนต์ของ OS และไลบรารีที่ต้องการประสิทธิภาพสูง—ที่การควบคุมและความหน่วงที่คาดเดาได้สำคัญกว่าความสะดวกของนักพัฒนา
Garbage Collection: ผลผลิตและความปลอดภัยที่คาดเดาได้
Garbage collection (GC) คือการทำความสะอาดหน่วยความจำอัตโนมัติ: แทนที่จะให้คุณต้อง free เอง runtime จะติดตามอ็อบเจ็กต์และคืนหน่วยความจำที่ไม่สามารถเข้าถึงได้ ในทางปฏิบัติหมายความว่าคุณสามารถมุ่งที่พฤติกรรมและการไหลของข้อมูลในขณะที่ระบบจัดการการจัดสรรและการคืนให้
GC หาวัตถุที่ไม่ถูกใช้ยังไง
ตัวเก็บขยะส่วนใหญ่หา อ็อบเจ็กต์ที่ยังมีชีวิต ก่อนแล้วจึงคืนพื้นที่ที่เหลือ
Tracing GC เริ่มจาก “roots” (เช่น ตัวแปรบนสแตก อ้างอิงระดับโลก รีจิสเตอร์) ติดตามการอ้างอิงเพื่อทำเครื่องหมายทุกสิ่งที่เข้าถึงได้ แล้วสแกนฮีพเพื่อลบอ็อบเจ็กต์ที่ไม่ได้ทำเครื่องหมาย หากไม่มีอะไรชี้ไปยังอ็อบเจ็กต์ มันจะมีสิทธิ์ถูกเก็บ
รูปแบบ GC ที่พบบ่อย (ภาพรวม)
Generational GC อิงจากข้อสังเกตว่าหลายอ็อบเจ็กต์ตายเร็ว แบ่งฮีพเป็นรุ่นต่าง ๆ และเก็บรุ่นเยาว์บ่อย ๆ ซึ่งมักถูกกว่าและช่วยเพิ่มประสิทธิภาพโดยรวม
Concurrent GC รันส่วนของการเก็บพร้อม ๆ กับเธรดของแอปพลิเคชัน เพื่อลดการหยุดยาว ๆ อาจต้องทำ bookkeeping เพิ่มเมื่อมองหน่วยความจำในขณะที่โปรแกรมยังทำงาน
การแลกเปลี่ยนด้านประสิทธิภาพ
GC มักแลก การควบคุมด้วยมือ กับ งานที่ทำใน runtime บางระบบเน้น throughput สูง (งานมากต่อวินาที) แต่อาจมี pause แบบ stop-the-world บ้าง บางระบบลด pause สำหรับแอปที่ไวต่อหน่วงเวลาแต่เพิ่มโอเวอร์เฮดระหว่างการทำงานปกติ
ทำไมนักพัฒนาชอบมัน
GC กำจัดชั้นของบั๊กเรื่อง lifetime (โดยเฉพาะ use-after-free) เพราะอ็อบเจ็กต์จะไม่ถูกเรียกคืนเมื่อยังเข้าถึงได้ นอกจากนี้ยังลดการรั่วที่เกิดจากการลืมปล่อย แม้จะยัง “รั่ว” ได้จากการเก็บอ้างอิงไว้นานเกินไป ในโค้ดเบสใหญ่ที่ ownership ยากจะตาม GC มักช่วยให้วงจรการพัฒนาเร็วขึ้น
จะเจอ GC ที่ไหน
รันไทม์ที่มี GC พบได้บ่อยใน JVM (Java, Kotlin), .NET (C#, F#), Go และเอนจิน JavaScript ในเบราว์เซอร์และ Node.js
การนับการอ้างอิง: การคืนทันทีแต่ต้องแลก
Reference counting คือกลยุทธ์ที่แต่ละอ็อบเจ็กต์ติดตามจำนวน “เจ้าของ” (รีเฟอเรนซ์) ที่ชี้มาหา เมื่อค่านับลดลงเหลือศูนย์ อ็อบเจ็กต์จะถูกปล่อยทันที ความทันทีนี้ทำให้เข้าใจง่าย: ทันทีที่ไม่มีใครเข้าถึงอ็อบเจ็กต์ หน่วยความจำจะคืน
ทำงานอย่างไรและน่าสนใจตรงไหน
เมื่อคุณคัดลอกหรือเก็บรีเฟอเรนซ์ runtime จะเพิ่มเคาน์เตอร์; เมื่อรีเฟอเรนซ์หายไปจะลด เมื่อแตะศูนย์จะทริกเกอร์การทำความสะอาดทันที
วิธีนี้ทำให้การจัดการทรัพยากรง่าย: อ็อบเจ็กต์มักปล่อยหน่วยความจำใกล้กับช่วงเวลาที่หยุดใช้งาน ซึ่งลดการใช้หน่วยความจำสูงสุดและหลีกเลี่ยงการคืนล่าช้า
ลักษณะประสิทธิภาพ
การนับการอ้างอิงมีโอเวอร์เฮดแบบสม่ำเสมอ: การเพิ่ม/ลดเกิดขึ้นบนการกำหนดค่าและการเรียกฟังก์ชันหลายครั้ง โอเวอร์เฮดมักเล็กแต่เกิดทุกที่
ข้อดีคือโดยทั่วไปจะไม่มีการหยุดโลกแบบใหญ่ ๆ ที่บาง tracing GC ทำให้เกิด ความหน่วงมักเรียบขึ้น แต่ยังอาจเห็นการระเบิดของการปล่อยเมื่อกราฟออบเจ็กต์ขนาดใหญ่สูญเสียเจ้าของคนสุดท้าย
กับดักใหญ่: วงจร
การนับการอ้างอิงไม่สามารถคืนอ็อบเจ็กต์ที่อยู่ในวงจรได้ หาก A อ้าง B และ B อ้าง A ทั้งคู่จะรักษาค่าการนับไว้สูงกว่าศูนย์แม้ไม่มีใครเข้าถึงพวกมัน—ทำให้เกิดการรั่ว
ระบบจัดการด้วยวิธีต่าง ๆ:
- weak references เพื่อทำลายวงจรในรูปแบบที่พบบ่อย
- การตรวจจับวงจร ชั้นบนของการนับการอ้างอิง (pass tracing) เพื่อเก็บวงจรที่ไม่สามารถเข้าถึงได้
จะเจอที่ไหน
- Swift / Objective-C ใช้ ARC (Automatic Reference Counting) พร้อม strong/weak/unowned เพื่อจัดการวงจร
- Python ใช้ reference counting สำหรับการคืนทันที พร้อมตัวตรวจจับวงจรเพื่อเก็บขยะแบบ cyclic
Ownership และ Borrowing: ความปลอดภัยที่ตรวจได้ตอนคอมไพล์
Ownership และ borrowing เป็นโมเดลที่เชื่อมโยงกับ Rust ไอเดียคือคอมไพเลอร์บังคับกฎที่ทำให้ยากจะสร้าง dangling pointer double-free และหลาย data race โดยไม่ต้องพึ่ง GC ที่รันไทม์
Ownership: เจ้าของเดียวชัดเจนและการทำความสะอาดแบบกำหนดได้
แต่ละค่ามี “เจ้าของ” เพียงคนเดียว เมื่อเจ้าของออกจากสโคป ค่านั้นจะถูกทำความสะอาดทันที ทำให้มีการจัดการทรัพยากรแบบกำหนดได้ (หน่วยความจำ ไฟล์ ซ็อกเก็ต) คล้ายการจัดการด้วยมือแต่มีหนทางผิดพลาดน้อยลง
Ownership ยังย้ายได้: การกำหนดให้ตัวแปรใหม่หรือการส่งเข้าไปในฟังก์ชันอาจโอนความรับผิดชอบ หลังจากย้าย binding เก่าไม่สามารถใช้ได้ ซึ่งป้องกัน use-after-free โดยโครงสร้าง
Borrowing: เข้าถึงชั่วคราวโดยไม่เอาเจ้าของ
Borrowing ให้คุณใช้ค่าโดยไม่เป็นเจ้าของ
shared borrow อนุญาตอ่านอย่างเดียวและสามารถคัดลอกได้
mutable borrow อนุญาตอัปเดต แต่ต้องเป็นแบบเฉพาะเจาะจง: ขณะที่มี mutable borrow อยู่ จะไม่มีใครอ่านหรือเขียนค่าเดียวกันได้ กฎ “หนึ่งคนเขียนหรือหลายคนอ่าน” นี้ถูกตรวจตอนคอมไพล์
ประโยชน์ด้านความปลอดภัย—และต้นทุน
เพราะ lifetimes ถูกติดตาม คอมไพเลอร์จะปฏิเสธโค้ดที่จะอ้างถึงข้อมูลที่อาจหมดอายุ ทำให้ลดหลาย dangling-reference ได้ กฎเดียวกันยังลด data races ในโค้ดพร้อมกัน
การแลกเปลี่ยนคือมี kurva การเรียนรู้และข้อจำกัดด้านการออกแบบ คุณอาจต้องปรับการไหลของข้อมูล แบ่งขอบเขต ownership ให้ชัดเจน หรือใช้ชนิดพิเศษสำหรับสถานะที่แชร์และเปลี่ยนแปลงได้
จุดที่เด่น
โมเดลนี้เหมาะกับโค้ดระบบ—บริการ ฝังตัว เครือข่าย และคอมโพเนนต์ที่ต้องการประสิทธิภาพ—ที่ต้องการการทำความสะอาดที่คาดเดาได้และหน่วงต่ำโดยไม่มีการหยุด GC
Arena, Region, Pool: รูปแบบการจัดสรรที่เร็ว
เมื่อคุณสร้างอ็อบเจ็กต์ชั่วคราวจำนวนมาก—โหนด AST ใน parser เอนทิตีในเฟรมเกม หรือข้อมูลชั่วคราวระหว่างคำขอเว็บ ค่าใช้จ่ายในการจัดสรรและปล่อยทีละอ็อบเจ็กต์สามารถกลายเป็นตัวกำหนดเวลารันไทม์ได้ Arena (region) และ pool เป็นรูปแบบที่แลกการปล่อยทีละชิ้นเพื่อการจัดการเป็นกลุ่มที่เร็ว
Arena/region คืออะไร
Arena เป็น “โซน” หน่วยความจำที่คุณจัดสรรอ็อบเจ็กต์จำนวนมาก แล้วปล่อย ทั้งหมดพร้อมกัน ด้วยการรีเซ็ตหรือทิ้ง arena
แทนการติดตามอายุของอ็อบเจ็กต์ทีละชิ้น คุณผูกอายุเข้ากับขอบเขตชัดเจน: “ทุกอย่างที่จัดสรรสำหรับคำขอนี้” หรือ “ทุกอย่างที่สร้างระหว่างการคอมไพล์ฟังก์ชันนี้”
ทำไมมันเร็ว
Arena มักเร็วเพราะ:
- ลดการเรียก allocator (บ่อยเป็นการ bump pointer)
- หลีกเลี่ยงค่าใช้จ่ายการ free ต่ออ็อบเจ็กต์
- ปรับปรุง locality ของแคชโดยเก็บอ็อบเจ็กต์ที่เกี่ยวข้องใกล้กัน
สิ่งนี้ช่วยเพิ่ม throughput และลดการกระโดดของ latency ที่เกิดจาก free บ่อยหรือการแย่ง allocator
กรณีการใช้งานทั่วไป
Arena และ pool พบได้ใน:
- parser และคอมไพเลอร์ (syntax tree, symbol table)
- ข้อมูลที่มีขอบเขตต่อคำขอ (allocate ระหว่างคำขอ ปล่อยเมื่อจบ)
- เกม (การจัดสรรต่อเฟรมรีเซ็ตทุกเฟรม)
- การจำลองและงานแบตช์
พิจารณาด้านความปลอดภัย
กฎหลักคือ: อย่าให้การอ้างอิงหนีออกจาก region ที่เป็นเจ้าของหน่วยความจำนั้น หากสิ่งที่จัดสรรใน arena ถูกเก็บเป็น global หรือคืนออกไปนอกอายุของ arena คุณเสี่ยงต่อ use-after-free
ภาษาหรือไลบรารีจัดการเรื่องนี้ต่างกัน: บางระบบพึ่งวินัยและ API อื่น ๆ อาจเข้ารหัสขอบเขต region ลงในชนิดข้อมูล
การเสริมกับแนวทางอื่น
Arena และ pool ไม่ใช่ทางเลือกแทน GC หรือ ownership—มักใช้ร่วมกัน GC language ใช้ pool ใน hot path; ภาษา ownership ใช้ arena เพื่อรวมการจัดสรรและทำให้อายุชัดเจน หากใช้ระมัดระวัง จะให้การจัดสรร "เร็วโดยค่าเริ่มต้น" โดยไม่เสียความชัดเจนว่าเมื่อใดหน่วยความจำจะถูกคืน
การปรับแต่งคอมไพเลอร์และรันไทม์ที่เปลี่ยนเกม
โมเดลหน่วยความจำของภาษาเป็นส่วนหนึ่งของเรื่องประสิทธิภาพและความปลอดภัย คอมไพเลอร์และรันไทม์สมัยใหม่จะเขียนโปรแกรมของคุณใหม่เพื่อลดการจัดสรร คืนเร็วขึ้น และหลีกเลี่ยง bookkeeping เพิ่ม นั่นคือเหตุผลที่คำกล่าวทั่วไปอย่าง “GC ช้า” หรือ “การจัดการด้วยมือเร็วสุด” มักล้มเหลวเมื่อใช้กับแอปจริง
การวิเคราะห์ว่าหนีไปที่ไหน (Escape analysis)
การจัดสรรหลายอย่างมีอยู่เพื่อส่งข้อมูลระหว่างฟังก์ชัน ด้วย escape analysis คอมไพเลอร์สามารถพิสูจน์ว่าออบเจ็กต์ไม่อยู่นอกสโคปปัจจุบันแล้วเก็บไว้บน สแตก แทนฮีพ
นั่นสามารถลบการจัดสรรบนฮีพได้ทั้งหมด รวมทั้งค่าใช้จ่ายที่เกี่ยวข้อง (การติดตาม GC, การอัปเดต reference count, locks ของ allocator) ในภาษาที่มีการจัดการ การวิเคราะห์แบบนี้เป็นเหตุผลสำคัญที่ออบเจ็กต์เล็ก ๆ อาจถูกจัดการถูกกว่าที่คาด
การอินไลน์และการลบการจัดสรร
เมื่อคอมไพเลอร์ inline ฟังก์ชัน มันอาจเห็นผ่านชั้นของนามธรรม ทำให้เกิดการปรับแต่งเช่น:
- กำจัดอ็อบเจ็กต์ชั่วคราว
- scalar replacement (เปลี่ยนอ็อบเจ็กต์เป็นตัวแปรท้องถิ่นไม่กี่ตัว)
- ลบ traffic ของ reference-count เมื่ออายุชัดเจน
API ที่ออกแบบดีอาจกลายเป็น "zero-cost" หลังการปรับแต่ง แม้มันจะดูเหมือนหนักในซอร์สโค้ด
JIT vs การคอมไพล์ล่วงหน้า (AOT)
JIT สามารถปรับโดยใช้ข้อมูลการผลิตจริง: เส้นทางโค้ดที่ฮอต ขนาดออบเจ็กต์ที่เห็นบ่อย รูปแบบการจัดสรร ซึ่งมักปรับปรุง throughput แต่เพิ่มเวลาตั้งต้นและบางครั้งมีการหยุดสำหรับการคอมไพล์ใหม่หรือ GC
AOT ต้องเดามากขึ้นก่อนหน้า แต่ให้การเริ่มต้นที่คาดเดาได้และ latency ที่มั่นคงกว่า
ตัวปรับแต่งรันไทม์ (และเมื่อควรแตะ)
รันไทม์ที่ใช้ GC มักมีการตั้งค่าเช่นขนาด heap เป้าหมายของเวลา pause และเกณฑ์ของรุ่น ปรับเมื่อคุณมีการวัด (เช่น ความหน่วงที่สูงหรือแรงกดดันของหน่วยความจำ) ไม่ใช่เป็นขั้นตอนแรก
ทำไมอัลกอริทึมเดียวกันทำงานต่างกัน
สองการใช้งานของ "อัลกอริทึมเดียวกัน" อาจต่างกันในจำนวนการจัดสรรชั่วคราว จำนวนออบเจ็กต์ชั่วคราว และการค้นชี้พอยน์เตอร์ ความต่างเหล่านี้รวมกับ optimizer allocator และพฤติกรรมแคช ทำให้การเปรียบเทียบประสิทธิภาพต้องการการโปรไฟล์ ไม่ใช่สมมติฐาน
การแลกเปลี่ยนด้านประสิทธิภาพ: Throughput, Latency, และการใช้หน่วยความจำ
การเลือกการจัดการหน่วยความจำไม่เพียงเปลี่ยนวิธีเขียนโค้ด แต่ยังเปลี่ยน เมื่อ งานเกิดขึ้น ขนาดหน่วยความจำที่ต้องสำรอง และความสม่ำเสมอของประสิทธิภาพต่อผู้ใช้
Throughput vs latency (ตัวอย่างชัดเจน)
Throughput คือ "งานต่อหน่วยเวลา" นึกถึงงานแบตช์กลางคืนที่ประมวลผล 10 ล้านระเบียน: หาก GC หรือ reference counting เพิ่มค่าใช้จ่ายเล็กน้อยแต่ทำให้นักพัฒนาเร็ว คุณอาจเสร็จได้เร็วที่สุดโดยรวม
Latency คือ "เวลาที่งานหนึ่งงานใช้จนครบ" สำหรับคำขอเว็บ การตอบช้าหนึ่งครั้งทำประสบการณ์ผู้ใช้แย่ แม้ว่าค่าเฉลี่ย throughput จะสูง runtime ที่บางครั้งหยุดเพื่อเก็บหน่วยความจำอาจใช้ได้ในการประมวลผลแบตช์ แต่รู้สึกได้ในแอปโต้ตอบ
รอยเท้าหน่วยความจำ: ค่าใช้จ่ายและความเร็ว
รอยเท้าหน่วยความจำที่ใหญ่ขึ้นเพิ่มค่าใช้จ่ายคลาวด์และอาจชะลอโปรแกรม เมื่อ working set ไม่พอดีในแคช CPU ความเร็วจะช้าลง บางกลยุทธ์แลกหน่วยความจำเพิ่มเพื่อความเร็ว (เช่น เก็บอ็อบเจ็กต์ไว้ใน pool) ขณะที่บางอย่างลดหน่วยความจำแต่เพิ่ม bookkeeping
การกระจายตัวและ locality ของแคช (อธิบายง่าย)
Fragmentation เกิดเมื่อหน่วยความจำว่างกระจัดกระจายเป็นช่องเล็ก ๆ—เหมือนพยายามจอดรถตู้ในลานที่มีช่องเล็ก ๆ กระจัดกระจาย ตัวจัดสรรอาจใช้เวลาค้นหาพื้นที่และหน่วยความจำอาจโตขึ้นแม้ว่ายังมีพื้นที่เพียงพอ
Cache locality หมายถึงข้อมูลที่เกี่ยวข้องนั่งใกล้กัน การจัดสรรแบบ pool/arena มักปรับปรุง locality ขณะที่ฮีพที่มีออบเจ็กต์ยาวผสมขนาดต่าง ๆ อาจลอยไปสู่เลย์เอาต์ที่ไม่เป็นมิตรต่อแคช
ข้อกำหนดเรื่องเวลาที่คาดเดาได้
ถ้าคุณต้องการเวลาตอบสนองสม่ำเสมอ—เกม แอปเสียง ระบบซื้อขาย ฝังตัวหรือตัวควบคุมเรียลไทม์—"เร็วโดยมากแต่บางครั้งช้า" อาจแย่กว่าการ "ช้ากว่าเล็กน้อยแต่สม่ำเสมอ" นี่คือที่ที่การปล่อยที่คาดเดาได้และการควบคุมการจัดสรรเข้มงวดมีความสำคัญ
เช็คลิสต์การวัด
- เบนช์มาร์กทั้ง throughput (งาน/วินาที) และ tail latency (p95/p99)
- โปรไฟล์การจัดสรร: อัตราการจัดสรร เวลา pause และเวลาใน alloc/free
- ใช้ โหลดตัวแทน (รูปแบบทราฟฟิกจริง ขนาดข้อมูล ความขนาน)
- ติดตามหน่วยความจำ: peak RSS ขนาด heap ข้อบ่งชี้ fragmentation (ถ้ามี)
- ทำซ้ำการรันเพื่อจับความแปรปรวน (ผลอุ่นเครื่อง วงจร GC พื้นหลัง)
ความปลอดภัยและการรักษาความปลอดภัย: โมเดลหน่วยความจำป้องกันบั๊กทั่วไปอย่างไร
ข้อผิดพลาดหน่วยความจำไม่ใช่แค่ "ความผิดพลาดของโปรแกรมเมอร์" ในหลายระบบจริง มันกลายเป็นปัญหาด้านความปลอดภัย: การล่มแบบฉับพลัน (DoS), การเปิดเผยข้อมูลโดยไม่ได้ตั้งใจ (อ่านหน่วยความจำที่ถูกปล่อยหรือยังไม่ได้กำหนดค่า), หรือเงื่อนไขที่ผู้โจมตีบังคับให้โปรแกรมรันโค้ดที่ไม่ตั้งใจ
บั๊กเชื่อมกับโมเดลหน่วยความจำอย่างไร
กลยุทธ์การจัดการหน่วยความจำต่าง ๆ มักล้มเหลวในรูปแบบต่างกัน:
- การจัดการด้วยตนเอง (C/C++) เสี่ยง use-after-free, double free, และ buffer overflow—ซึ่งสามารถทำให้หน่วยความจำเสียหายและถูกใช้ประโยชน์ได้
- Garbage collection กำจัดข้อผิดพลาดสไตล์ UAF ส่วนใหญ่เพราะอ็อบเจ็กต์ไม่ถูกคืนเมื่อยังเข้าถึงได้ แต่ยังได้ผลกับ การรั่ว (เก็บอ้างอิงไว้นานเกินไป) และความเสี่ยงในการทำงานร่วมกับ native code
- Reference counting ช่วยการคืนทรัพยากรแบบทันที แต่มีปัญหา วงจร (รั่ว) และประเด็นเรื่องอายุเมื่อผสมกับสถานะที่แชร์และเปลี่ยนแปลงได้
- Ownership/borrowing (เช่น Rust) ป้องกันหลายคลาสของ UAF และ data race ตอนคอมไพล์โดยทำให้ยากที่จะมี dangling reference หรือการแก้ไขพร้อมกันโดยไม่มีการซิงโครไนซ์
ความปลอดภัยในเธรดและความพร้อมกัน
การพร้อมกันเปลี่ยนแบบจำลองภัยคุกคาม: หน่วยความจำที่ "ปลอดภัย" ในเธรดหนึ่งอาจเป็นอันตรายในอีกเธรดหนึ่งเมื่อตัวอื่นปล่อยหรือแก้ไข โมเดลที่บังคับกฎการแชร์ (หรือร้องขอการซิงโครไนซ์ชัดเจน) ลดโอกาสเกิด race condition ที่นำไปสู่ข้อมูลเสียหาย การรั่ว หรือการล่มแบบเป็นครั้งคราว
ยังคงต้องมีการป้องกันหลายชั้น
ไม่มีโมเดลหน่วยความจำใดกำจัดความเสี่ยงทั้งหมด—บั๊กเชิงตรรกะ (การพิสูจน์ตัวตนผิด ค่าเริ่มต้นไม่ปลอดภัย การตรวจสอบไม่เพียงพอ) ยังคงเกิดขึ้น ทีมที่แข็งแกร่งวางการป้องกันหลายชั้น: sanitizers ในการทดสอบ ไลบรารีมาตรฐานที่ปลอดภัย การรีวิวโค้ดอย่างเข้มงวด fuzzing และขอบเขตที่ชัดเจนของโค้ด unsafe/FFI ความปลอดภัยของหน่วยความจำลดพื้นผิวการโจมตีใหญ่ แต่ไม่ใช่การันตี
เครื่องมือและเทคนิคเพื่อค้นหาปัญหาหน่วยความจำเร็วขึ้น
ปัญหาหน่วยความจำแก้ได้ง่ายเมื่อจับได้ใกล้กับการเปลี่ยนแปลงที่ทำให้เกิดมัน คีย์คือวัดก่อน แล้วจำกัดปัญหาด้วยเครื่องมือที่เหมาะสม
พื้นฐานการโปรไฟล์: วัดอะไรและเมื่อไร
เริ่มโดยตัดสินว่าตามล่า ความเร็ว หรือ การเติบโตของหน่วยความจำ สำหรับประสิทธิภาพ ให้วัดเวลาจริง CPU อัตราการจัดสรร (bytes/sec) และเวลา GC หรือ allocator สำหรับหน่วยความจำ ให้ติดตาม peak RSS steady-state RSS และจำนวนอ็อบเจ็กต์เมื่อเวลาผ่านไป รันด้วยข้อมูลนำเข้าเดียวกัน; ความแปรผันเล็กน้อยอาจซ่อนการสั่นของการจัดสรร
หมวดเครื่องมือ (แต่ละอย่างหาอะไรได้)
- โปรไฟล์ CPU + การจัดสรร: แสดงว่าจำเวลาและเส้นทางเรียกใดจัดสรรมาก เหมาะกับการหาการจัดสรรเล็ก ๆ จำนวนมาก
- เครื่องมือตรวจจับการรั่ว: รายงานหน่วยความจำที่จัดสรรแต่ไม่ถูกปล่อยหรือไม่ถูกเข้าถึงอีก
- Sanitizers: จับ use-after-free, buffer overflow, data race, undefined behavior ในการทดสอบ
- Fuzzing: ป้อนอินพุตไม่คาดคิดเพื่อตรวจหาการล่มและการเสียหายของหน่วยความจำที่เทสต์ปกติอาจพลาด
หา hotspot ของการจัดสรรและลดการ churn
สัญญาณทั่วไป: คำขอหนึ่ง ๆ จัดสรรมากกว่าที่คาด หรือหน่วยความจำเพิ่มขึ้นตามทราฟฟิกแม้ throughput คงที่ แก้ได้โดยการใช้บัฟเฟอร์ซ้ำ ใช้ arena/pool สำหรับอ็อบเจ็กต์ชั่วคราว และทำให้ออบเจ็กต์อยู่รอดง่ายขึ้นข้ามรอบการเก็บ
เวิร์กโฟลว์ปฏิบัติสำหรับการรั่วและการล่ม
ทำซ้ำด้วยอินพุตน้อยสุด เปิดการตรวจสอบรันไทม์เข้มงวด (sanitizers/GC verification) แล้วจับ:
- โปรไฟล์ (CPU + การจัดสรร), 2) snapshot heap หรือรายงานการรั่ว, 3) stack trace ตอนเกิดความล้มเหลว
ถือการแก้ครั้งแรกเป็นการทดลอง; รันการวัดอีกครั้งเพื่อยืนยันว่าการเปลี่ยนแปลงลดการจัดสรรหรือทำให้หน่วยความจำเสถียร—โดยไม่โยกปัญหาไปที่อื่น สำหรับข้อมูลเพิ่มเติมด้านการตีความการแลกเปลี่ยน ดู /blog/performance-trade-offs-throughput-latency-memory-use.
การเลือกภาษา: จับคู่โมเดลหน่วยความจำกับเป้าหมายของคุณ
การเลือกภาษาไม่ใช่แค่เรื่องไวยากรณ์หรือระบบนิเวศ—โมเดลหน่วยความจำกำหนดความเร็วในการพัฒนา ความเสี่ยงการปฏิบัติการ และความคาดเดาได้ของประสิทธิภาพภายใต้ทราฟฟิกจริง
เริ่มจากความต้องการ ไม่ใช่ความชอบ
แมปความต้องการผลิตภัณฑ์ของคุณกับกลยุทธ์หน่วยความจำโดยตอบคำถามเหล่านี้:
- ทักษะทีมและความทนต่อความซับซ้อน: ผู้ร่วมงานส่วนใหญ่พอจะคิดเรื่อง lifetime และ ownership ไหม หรือต้องการให้ runtime ดูแลให้
- ความหน่วง vs throughput: คุณต้องการ tail latency ที่สม่ำเสมอหรือ throughput เป็นหลัก
- ข้อจำกัดการปรับใช้: รันในสภาพแวดล้อมหน่วยความจำจำกัดหรือไม่ (ฝังตัว มือถือ) หรือมีพื้นที่สำหรับ runtime และ heap ที่ใหญ่
"เหมาะสม" ทั่วไป
- Garbage collection (GC): มักเหมาะกับบริการ backend และแอปที่เน้นผลิตภัณฑ์ ที่ความเร็วในการพัฒนากับความปลอดภัยสำคัญกว่าการหยุดระดับไมโครวินาที
- Ownership/borrowing (เช่น Rust): เหมาะกับซอฟต์แวร์ระบบ คอมโพเนนต์ที่ต้องการประสิทธิภาพ และโค้ดที่ต้องการความปลอดภัยสูง
- Reference counting (RC): มักเหมาะกับแอปเดสก์ท็อป/มือถือและ UI ที่ได้ประโยชน์จากการคืนทรัพยากรที่คาดเดาได้ โดยยอมรับการจัดการวงจรและโอเวอร์เฮดต่อการกำหนดค่า
การย้ายและการทำงานร่วมกัน
ถ้าคุณเปลี่ยนโมเดล วางแผนรับแรงเสียดทาน: FFI ไลบรารีเดิม ข้อตกลงหน่วยความจำผสม เครื่องมือ และตลาดการจ้างงาน โปรโทไทป์ช่วยเปิดเผยต้นทุนที่ซ่อนอยู่ (การหยุด การเติบโตของหน่วยความจำ โอเวอร์เฮด CPU) เร็วกว่าที่คิด ทีมมักทำการประเมิน "แอปเปิลต่อแอปเปิล" ด้วย Koder.ai: คุณสามารถรวบรวม front end React เล็ก ๆ บวก backend Go + PostgreSQL แล้ววนการทดลองรูปแบบคำขอและโครงสร้างข้อมูลเพื่อดูว่าเซอร์วิสแบบ GC ทำงานอย่างไรภายใต้ทราฟฟิกจริง (และส่งออกซอร์สโค้ดเมื่อต้องการต่อยอด)
กรอบการตัดสินใจแบบเบา ๆ
กำหนด 3–5 ข้อจำกัดสูงสุด สร้างโปรโทไทป์บาง ๆ และ วัด การใช้หน่วยความจำ tail latency และโหมดความล้มเหลว
| Model | Safety by default | Latency predictability | Developer speed | Typical pitfalls |
|---|
| Manual | Low–Medium | High | Medium | leaks, use-after-free |
| GC | High | Medium | High | pauses, heap growth |
| RC | Medium–High | High | Medium | cycles, overhead |
| Ownership | High | High | Medium | learning curve |