23 ธ.ค. 2568·3 นาที
การจำกัดอัตรา API สำหรับ SaaS: รูปแบบ per-user, per-org และ per-IP
รูปแบบการจำกัดอัตรา API สำหรับ SaaS: ข้อจำกัดต่อผู้ใช้ ต่อองค์กร และต่อ IP พร้อมหัวข้อชัดเจน รูปร่างข้อความผิดพลาด และคำแนะนำการเปิดใช้งานที่ลูกค้าเข้าใจได้
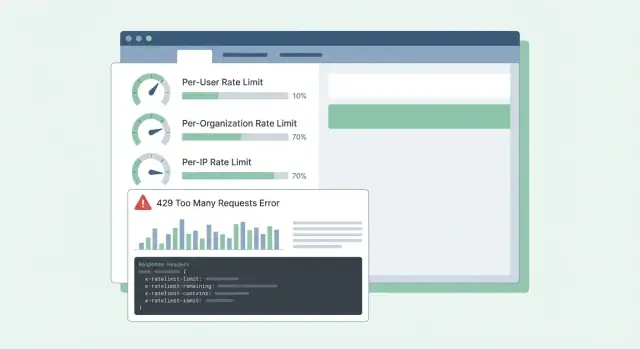
รูปแบบการจำกัดอัตรา API สำหรับ SaaS: ข้อจำกัดต่อผู้ใช้ ต่อองค์กร และต่อ IP พร้อมหัวข้อชัดเจน รูปร่างข้อความผิดพลาด และคำแนะนำการเปิดใช้งานที่ลูกค้าเข้าใจได้
Rate limits และ quotas ฟังดูคล้ายกัน จึงมักถูกมองว่าเป็นเรื่องเดียวกัน ความต่างคือ rate limit คือความเร็วที่เรียก API ได้ (คำขอต่อวินาทีหรือต่อนาที) ส่วน quota คือปริมาณการใช้งานในช่วงเวลาที่ยาวกว่า (ต่อวัน ต่อเดือน หรือรอบบิล) ทั้งสองแบบมีเหตุผล แต่จะดูสุ่มเมื่อกฎไม่โปร่งใส
คำร้องเรียนแบบคลาสสิกคือ: “เมื่อวานมันใช้ได้” การใช้งานแทบจะไม่คงที่ ช่วงสั้น ๆ ที่มีการระเบิดสามารถผลักใครบางคนเกินขอบเขตได้ แม้ว่ายอดรวมต่อวันจะดูปกติก็ตาม ลองนึกถึงลูกค้าที่รันรายงานวันละครั้ง แต่วันนี้งานรีทริยหลัง timeout ทำให้เรียก 10 เท่าใน 2 นาที API ก็จะบล็อก และสิ่งที่พวกเขาเห็นมีแค่ความล้มเหลวอย่างกะทันหัน
ความสับสนยิ่งมากขึ้นเมื่อข้อผิดพลาดไม่ชัดเจน ถ้า API คืน 500 หรือข้อความทั่วไป ลูกค้าจะคิดว่าบริการของคุณล่ม ไม่ใช่พวกเขาโดนขีดจำกัด พวกเขาจะเปิดตั๋วด่วน สร้างทางเลี่ยง หรือเปลี่ยนผู้ให้บริการ แม้แต่ 429 Too Many Requests ก็ทำให้หงุดหงิดได้ถ้าไม่บอกว่าจะทำอย่างไรต่อ
SaaS APIs ส่วนใหญ่จำกัดทราฟฟิกด้วยเหตุผล 2 แบบ:
การผสมเป้าหมายสองอย่างนี้มักนำไปสู่การออกแบบที่ไม่ดี การควบคุมการละเมิดมักเป็นแบบ per-IP หรือ per-token และอาจเข้มงวด ในขณะที่การปรับการใช้งานปกติเป็นแบบ per-user หรือ per-organization และควรมาพร้อมแนวทางชัดเจน: ข้อจำกัดใดถูกกระทบ, เมื่อใดจะรีเซ็ต, และจะหลีกเลี่ยงได้อย่างไร
เมื่อชัดเจน ลูกค้าจะวางแผนได้ เมื่อไม่ชัด ทุกครั้งที่มีสไปก์จะรู้สึกเหมือน API พัง
Rate limits ไม่ใช่แค่ตัวลดความเร็ว แต่เป็นระบบความปลอดภัย ก่อนเลือกตัวเลข ให้ชัดเจนว่าคุณพยายามปกป้องอะไร เพราะแต่ละเป้าหมายจะนำไปสู่ข้อจำกัดและความคาดหวังที่ต่างกัน
ความพร้อมใช้งานมักเป็นอันดับแรก ถ้าลูกค้าบางรายสามารถสไปก์ทราฟฟิกจนทำให้ API เกิด timeout ทุกคนจะได้รับผลกระทบ ข้อจำกัดในส่วนนี้ควรรักษาเซิร์ฟเวอร์ตอบสนองได้ในช่วงระเบิดและล้มเร็ว แทนปล่อยให้คำขอสะสม
ต้นทุนคือปัจจัยเงียบเบื้องหลัง API บางคำขอถูก บางคำขอแพง (การเรียก LLM, การประมวลผลไฟล์, การเขียนสตอเรจ, การเรียกบริการจ่ายเงินจากบุคคลที่สาม) ตัวอย่างเช่น บนแพลตฟอร์มอย่าง Koder.ai ผู้ใช้คนเดียวอาจเรียกโมเดลหลายครั้งผ่านการสร้างแอปแบบ chat ข้อจำกัดที่ติดตามการกระทำที่แพงสามารถป้องกันใบเรียกเก็บเงินที่ประหลาดใจได้
การละเมิดมีลักษณะแตกต่างจากการใช้งานที่ชอบด้วยกฎหมาย การยัด credential, การเดา token, และการสแครปมักเป็นคำขอจำนวนน้อยจาก IP หรือบัญชีที่จำกัด ในที่นี้คุณต้องการข้อจำกัดเข้มงวดและการบล็อกอย่างรวดเร็ว
ความยุติธรรมสำคัญในระบบ multi-tenant ลูกค้าที่เสียงดังคนเดียวไม่ควรทำให้คนอื่นแย่ ในทางปฏิบัติ นั่นมักหมายถึงการวางชั้นควบคุม: burst guard เพื่อรักษาสุขภาพ API นาทีต่อนาที, cost guard สำหรับ endpoints หรือการกระทำที่แพง, abuse guard มุ่งที่การยืนยันตัวและรูปแบบน่าสงสัย, และ fairness guard เพื่อไม่ให้องค์กรหนึ่งแย่งพื้นที่คนอื่น
การทดสอบง่าย ๆ ช่วยได้: เลือก endpoint หนึ่งแล้วถามว่า “ถ้าคำขอนี้เพิ่ม 10× สิ่งใดพังก่อน?” คำตอบจะบอกว่าควรให้ความสำคัญกับการป้องกันแบบใด และมิติใด (user, org, IP) ควรเป็นตัวเก็บขอบเขต
ทีมส่วนใหญ่เริ่มด้วยขีดจำกัดเดียวแล้วพบว่ามันทำร้ายคนผิด เป้าหมายคือเลือกมิติที่สอดคล้องกับการใช้งานจริง: ใครเรียก ใครจ่าย และอะไรดูเหมือนการละเมิด
มิติทั่วไปใน SaaS มีดังนี้:
ขีดจำกัดแบบ per-user คือความยุติธรรมภายใน tenant หากคนคนหนึ่งรันการส่งออกใหญ่ เขาควรรู้สึกถึงการชะลอมากกว่าคนอื่นในทีม
ขีดจำกัดแบบ per-org เกี่ยวกับงบประมาณและความจุ แม้สิบคนจะรันงานพร้อมกัน องค์กรไม่ควรสไปก์จนทำให้บริการหรือสมมติฐานด้านราคาเสียหาย
ขีดจำกัดแบบ per-IP ควรถูกมองเป็นตาข่ายนิรภัย ไม่ใช่เครื่องมือเรียกเก็บเงิน เพราะ IP อาจถูกแชร์ (NAT ออฟฟิศ ผู้ให้บริการมือถือ) ให้ขีดจำกัดนี้ค่อนข้างใจกว้างและใช้เพื่อหยุดการละเมิดที่ชัดเจน
เมื่อรวมมิติ ให้ตัดสินใจว่าอันไหน “ชนะ” เมื่อขีดจำกัดหลายอันใช้งานพร้อมกัน กฎปฏิบัติที่เป็นไปได้คือ: ปฏิเสธคำขอถ้าขีดจำกัดใด ๆ ที่เกี่ยวข้องถูกเกิน แล้วคืนเหตุผลที่ปฏิบัติได้ที่สุด ถ้า workspace เกินโควต้าของ org ก็อย่าโทษผู้ใช้หรือ IP
ตัวอย่าง: workspace ของ Koder.ai บนแผน Pro อาจอนุญาตการไหลของคำขอ build ต่อเนื่องต่อ org ในขณะเดียวกันก็จำกัด user เดียวไม่ให้ยิงเป็นร้อยคำขอต่อนาที หากการผนวกรวมของพาร์ทเนอร์ใช้ token ที่แชร์ ขีดจำกัด per-token สามารถหยุดไม่ให้มันกลบผู้ใช้แบบ interactive
ปัญหาส่วนใหญ่ของ rate limiting ไม่ได้อยู่ที่คณิตศาสตร์ แต่เป็นการเลือกพฤติกรรมที่ตรงกับวิธีที่ลูกค้าเรียก API แล้วทำให้มันคาดเดาได้ภายใต้โหลด
Token bucket เป็นค่าเริ่มต้นที่พบได้บ่อยเพราะยอมให้ burst สั้น ๆ ขณะบังคับค่าเฉลี่ยในระยะยาว ผู้ใช้ที่รีเฟรช dashboard อาจยิงคำขอเร็ว ๆ หลายคำ Token bucket อนุญาตให้หากมี token สะสมแล้วค่อยชะลอ
Leaky bucket เข้มงวดกว่า มันทำให้ทราฟฟิกไหลออกเป็นอัตราคงที่ ซึ่งช่วยเมื่อ backend ของคุณไม่สามารถรับมือกับสไปก์ได้ (เช่น การสร้างรายงานที่แพง) ข้อแลกเปลี่ยนคือผู้ใช้จะรู้สึกถึงข้อจำกัดเร็วขึ้น เพราะ burst จะกลายเป็นการคิวหรือการปฏิเสธ
เคาน์เตอร์แบบ window-based ง่ายแต่รายละเอียดสำคัญ หน้าต่างคงที่ (fixed windows) สร้างขอบชัดที่พรมแดน (ผู้ใช้สามารถระเบิดที่ 12:00:59 แล้วอีกครั้งที่ 12:01:00) Sliding window ให้ความรู้สึกยุติธรรมกว่าและลดการสไปก์ที่พรมแดน แต่ต้องการสถานะมากขึ้นหรือโครงสร้างข้อมูลที่ดีกว่า
กลุ่มขีดจำกัดอีกประเภทคือ concurrency (คำขอที่กำลังดำเนินการ) ซึ่งปกป้องคุณจากการเชื่อมต่อไคลเอนต์ที่ช้าและ endpoints ที่ใช้เวลานาน ลูกค้าอาจอยู่ในข้อจำกัด 60 คำขอต่อนาทีแต่ยังทำให้ระบบหนักเพราะมีคำขอเปิดค้าง 200 คำพร้อมกัน
ในระบบจริง ทีมมักรวมชุดควบคุมเล็ก ๆ: token bucket สำหรับอัตราคำขอทั่วไป, concurrency cap สำหรับ endpoints ช้า/หนัก, และงบประมาณแยกตามกลุ่ม endpoint (อ่านราคาถูก vs การส่งออกที่แพง) ถ้าใช้ขีดจำกัดแค่จำนวนคำขอเพียงอย่างเดียว endpoint หนึ่งที่แพงสามารถเบียดพื้นที่ทั้งหมดและทำให้ API รู้สึกพังแบบสุ่ม
โควต้าที่ดีต้องรู้สึกยุติธรรมและคาดเดาได้ ลูกค้าไม่ควรค้นพบกฎเมื่อถูกบล็อกแล้วเท่านั้น
แยกความชัดเจน:
หลายทีมใช้ทั้งสองแบบ: ขีดจำกัดระยะสั้นเพื่อหยุด burst บวกโควต้ารายเดือนผูกกับการคิดราคา
Hard vs soft limits เป็นการตัดสินใจเชิงซัพพอร์ตเป็นหลัก Hard limit บล็อกทันที ส่วน soft limit เตือนก่อนแล้วบล็อกทีหลัง Soft limit ลดจำนวนตั๋วโกรธเพราะให้โอกาสแก้บั๊กหรืออัปเกรดก่อนการผนวกรวมจะเสีย
เมื่อใครสักคนเกิน พฤติกรรมควรสอดคล้องกับสิ่งที่คุณป้องกัน การบล็อกเหมาะเมื่อการใช้งานเกินจะทำร้าย tenant อื่นหรือทำให้ต้นทุนพุ่ง ลดความสำคัญ (ช้าลงหรือความสำคัญต่ำกว่า) เหมาะเมื่อคุณต้องการให้การทำงานยังเดินต่อได้ “คิดเงินทีหลัง” เหมาะเมื่อการใช้งานคาดเดาได้และคุณมี flow การเรียกเก็บเงินอยู่แล้ว
การจำกัดตามชั้น (tier) ใช้งานได้ดีเมื่อแต่ละชั้นมีรูปแบบการใช้งานที่คาดหวังได้ ช่วงฟรีอาจให้โควต้ารายเดือนเล็ก ๆ และอัตรา burst ต่ำ ขณะที่ชั้นธุรกิจและองค์กรได้โควต้าและ burst ที่สูงขึ้นเพื่อให้งานแบ็กกราวด์เสร็จเร็ว นี่คล้ายกับวิธีที่แผน Free, Pro, Business, Enterprise ของ Koder.ai ตั้งความคาดหวังต่างกัน
การสนับสนุนขีดจำกัดเฉพาะลูกค้า (custom limits) ควรทำตั้งแต่ต้น โดยแนวทางสะอาดคือ “ค่าเริ่มต้นตามแผน, ลูกค้าสามารถ override ได้” เก็บการตั้งค่า override ต่อ org (และบางครั้งต่อ endpoint) และตรวจสอบให้แน่ใจว่ามันอยู่รอดเมื่อลูกค้าเปลี่ยนแผน นอกจากนี้ให้กำหนดว่าใครขอเปลี่ยนได้และมีผลเมื่อไร
ตัวอย่าง: ลูกค้านำเข้าข้อมูล 50,000 ระเบียนในวันสุดท้ายของเดือน ถ้าโควต้ารายเดือนของพวกเขาใกล้หมด การเตือนแบบ soft ที่ 80–90% ให้เวลาพักงาน ขีดจำกัดต่อวินาทีสั้น ๆ ป้องกันการนำเข้าที่ท่วม API และ override ที่อนุมัติให้กับ org (ชั่วคราวหรือถาวร) ทำให้ธุรกิจเดินต่อได้
เริ่มจากเขียนว่าคุณจะนับอะไรและเป็นใคร ส่วนใหญ่ทีมจะมี identity สามอย่าง: ผู้ใช้ที่ล็อกอิน, องค์กร (workspace), และ client IP
แผนปฏิบัติได้:
เมื่อกำหนดขีดจำกัด ให้คิดเป็นชั้นและกลุ่ม endpoint ไม่ใช่ตัวเลขรวมหนึ่งตัว ความล้มเหลวที่พบบ่อยคือพึ่งพาเคาน์เตอร์ in-memory ข้ามเซิร์ฟเวอร์หลายตัว เคาน์เตอร์จะไม่ตรงกันและผู้ใช้จะเห็น 429 แบบ "สุ่ม" โกดังที่ใช้ร่วมอย่าง Redis ทำให้ขีดจำกัดสเถียรและ TTL ช่วยเก็บข้อมูลให้เล็ก
การเปิดใช้งานสำคัญ เริ่มในโหมด “report only” (บันทึกสิ่งที่จะถูกบล็อก) แล้วบังคับกับกลุ่ม endpoint หนึ่ง จากนั้นขยาย นี่คือวิธีที่ช่วยหลีกเลี่ยงการตื่นมาพบกับตั๋วสนับสนุนจำนวนมาก
เมื่อผู้ใช้โดนขีดจำกัด ผลลัพธ์ที่แย่ที่สุดคือความสับสน: “API ล่มหรือฉันทำผิด?” การตอบที่ชัดเจนและสม่ำเสมอลดตั๋วสนับสนุนและช่วยคนปรับพฤติกรรมไคลเอนต์
ใช้ HTTP 429 Too Many Requests เมื่อคุณกำลังบล็อกคำขอ รักษารูปแบบ body ให้คาดเดาได้เพื่อ SDK และแดชบอร์ดจะอ่านได้
นี่คือตัวอย่างรูปแบบ JSON ที่ใช้งานได้ดีกับขีดจำกัด per-user, per-org, และ per-IP:
{
"error": {
"code": "rate_limit_exceeded",
"message": "Rate limit exceeded for org. Try again later.",
"limit_scope": "org",
"reset_at": "2026-01-17T12:34:56Z",
"request_id": "req_01H..."
}
}
Headers ควรอธิบายหน้าต่างปัจจุบันและสิ่งที่ไคลเอนต์สามารถทำต่อได้ ถ้าจะเพิ่มแค่ไม่กี่ตัว ให้เริ่มจาก: RateLimit-Limit, RateLimit-Remaining, RateLimit-Reset, Retry-After, และ X-Request-Id
ตัวอย่าง: งาน cron ของลูกค้ารันทุกนาทีแล้วเริ่มล้ม ถ้ามี 429 พร้อม RateLimit-Remaining: 0 และ Retry-After: 20 พวกเขาจะรู้ทันทีว่านี่คือขีดจำกัด ไม่ใช่การล่ม และสามารถหน่วงการลองใหม่ 20 วินาทีได้ ถ้าพวกเขาแชร์ X-Request-Id กับฝ่ายซัพพอร์ต คุณหากิจกรรมได้เร็ว
รายละเอียดอีกอย่าง: ให้ headers เดียวกันบนคำขอที่สำเร็จด้วย ลูกค้าจะได้เห็นว่าพวกเขาเข้าใกล้ขอบก่อนจะโดนบล็อก
ไคลเอนต์ที่ดีทำให้ข้อจำกัดรู้สึกยุติธรรม ไคลเอนต์ที่ไม่ดีทำให้ขีดจำกัดชั่วคราวกลายเป็นการล่มโดยการทุบหนักขึ้น
เมื่อได้ 429 ให้ถือว่าเป็นสัญญาณให้ชะลอ ถ้าคำตอบบอกเวลาที่จะลองใหม่ (เช่น ผ่าน Retry-After) ให้รออย่างน้อยเท่านั้น ถ้าไม่บอก ให้ใช้ exponential backoff และเพิ่ม jitter (ความสุ่ม) เพื่อไม่ให้ลูกค้าพันรายลองพร้อมกัน
จำกัดการ retry: กำหนดขอบเขตเวลาหน่วงระหว่างครั้ง (เช่น สูงสุด 30–60 วินาที) และขอบเขตเวลาทั้งหมดของการลองซ้ำ (เช่น หยุดหลัง 2 นาทีและแสดงข้อผิดพลาด) และบันทึกเหตุการณ์พร้อมรายละเอียดขีดจำกัดเพื่อให้นักพัฒนาปรับได้ทีหลัง
อย่า retry ทุกอย่าง ข้อผิดพลาดหลายอย่างจะไม่สำเร็จหากไม่เปลี่ยนแปลงหรือมีการกระทำจากผู้ใช้: 400 validation errors, 401/403 auth errors, 404 not found, และ 409 conflicts ที่สะท้อนกฎธุรกิจ
การ retry เสี่ยงสำหรับ endpoints ที่เขียน (create, charge, send email) หาก timeout แล้วไคลเอนต์ retry อาจสร้างรายการซ้ำ ใช้ idempotency keys: ไคลเอนต์ส่งคีย์เฉพาะต่อการกระทำเชิงตรรกะ และเซิร์ฟเวอร์ส่งผลลัพธ์เดิมสำหรับการเรียกซ้ำของคีย์นั้น
SDK ที่ดีสามารถช่วยโดยแสดงสิ่งที่นักพัฒนาต้องการ: สถานะ (429), เวลาที่ต้องรอ, ว่าคำขอนั้นปลอดภัยที่จะ retry หรือไม่, และข้อความเช่น “Rate limit exceeded for org. Retry after 8s or reduce concurrency.”
ตั๋วสนับสนุนส่วนใหญ่เกี่ยวกับข้อจำกัดไม่ใช่เรื่องขีดจำกัดเอง แต่เป็นความประหลาดใจ หากผู้ใช้คาดเดาไม่ได้ว่าเกิดอะไรต่อไป พวกเขาจะคิดว่า API พังหรือไม่เป็นธรรม
การใช้ขีดจำกัดแค่แบบ IP เป็นความผิดพลาดบ่อย ทีมหลายทีมอยู่เบื้องหลัง IP สาธารณะเดียว (Wi‑Fi ออฟฟิศ ผู้ให้บริการมือถือ NAT) ถ้าคุณตั้งเพดานตาม IP ลูกค้าคนหนึ่งที่วุ่นวายสามารถบล็อกทุกคนบนเครือข่ายเดียวกันได้ ให้ใช้ per-user และ per-org เป็นหลัก และใช้ per-IP เป็นตาข่ายนิรภัย
ปัญหาอีกอย่างคือการถือว่า endpoint ทุกตัวเท่ากัน GET ถูกและ export หนักไม่ควรแชร์งบเดียวกัน มิฉะนั้นลูกค้าจะใช้สิทธิโดยการท่องปกติแล้วถูกบล็อกเมื่อพยายามทำงานจริง แยก bucket ตามกลุ่ม endpoint หรือให้น้ำหนักคำขอตามต้นทุน
การตั้งเวลารีเซ็ตต้องชัดเจน “รีเซ็ตทุกวัน” ไม่เพียงพอ อยู่ในเขตเวลาไหน? rolling window หรือรีเซ็ตเที่ยงคืน? ถ้าคุณทำรีเซ็ตตามปฏิทิน ให้บอกเขตเวลา ถ้าทำ rolling window ให้บอกความยาวของหน้าต่าง
สุดท้าย ข้อผิดพลาดที่คลุมเครือสร้างความวุ่นวาย การคืน 500 หรือ JSON ทั่วไปทำให้คนพยายาม retry มากขึ้น ใช้ 429 และใส่ RateLimit headers เพื่อให้ไคลเอนต์ถอยอย่างชาญฉลาด
ตัวอย่าง: ถ้าทีมสร้างการผนวกรวม Koder.ai จากเครือข่ายองค์กรแชร์เดียว การจำกัดตาม IP อย่างเดียวสามารถบล็อกทั้งองค์กรและดูเหมือนการล่มแบบสุ่ม ขอบเขตที่ชัดเจนและการตอบ 429 ที่ชัดเจนป้องกันเรื่องนั้น
ก่อนเปิดใช้ขีดจำกัดกับทุกคน ให้ทำรอบสุดท้ายที่มุ่งเน้นความคาดเดาได้:
การตรวจสอบพื้นฐาน: ถ้าผลิตภัณฑ์คุณมีชั้น Free, Pro, Business, Enterprise (เช่น Koder.ai) คุณควรอธิบายเป็นภาษาธรรมดาได้ว่าลูกค้าปกติทำอะไรได้ต่อหนึ่งนาทีและต่อหนึ่งวัน และ endpoint ใดถูกปฏิบัติต่างกัน
ถ้าคุณอธิบาย 429 ไม่ได้ชัดเจน ลูกค้าจะคิดว่า API พัง ไม่ใช่การปกป้องบริการ
นึกภาพ B2B SaaS ที่คนทำงานใน workspace (org) ผู้ใช้ power บางคนรันการส่งออกหนัก และพนักงานหลายคนอยู่หลัง IP สาธารณะเดียว หากคุณจำกัดแค่ตาม IP จะบล็อกทั้งบริษัท หากจำกัดแค่ตาม user สคริปต์เดียวยังทำร้าย workspace ได้
ส่วนผสมที่ใช้งานได้จริงคือ:
เมื่อใครสักคนโดนขีดจำกัด ข้อความของคุณควรบอกว่ามันเกิดอะไรขึ้น ทำอย่างไรต่อ และเมื่อใดจะลองใหม่ ฝ่ายซัพพอร์ตควรยืนอยู่เบื้องหลังข้อความเช่น:
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
จับคู่ข้อความนั้นกับ Retry-After และ RateLimit headers ที่สอดคล้องกันเพื่อให้ลูกค้าไม่ต้องเดา
แผนการเปิดใช้งานที่หลีกเลี่ยงความประหลาดใจ: สังเกตเฉย ๆ ก่อน, จากนั้นเตือน (headers และ soft warnings), แล้วบังคับ (429 พร้อมเวลาลองใหม่ชัดเจน), ปรับแต่งค่าตามชั้น, แล้วทบทวนหลังการเปิดตัวใหญ่และการ onboard ลูกค้า
ถ้าคุณต้องการวิธีเร็ว ๆ ในการเปลี่ยนแนวคิดเหล่านี้เป็นโค้ดที่ทำงานได้ แพลตฟอร์ม vibe-coding อย่าง Koder.ai (koder.ai) สามารถช่วยร่างสเป็ค rate limit สั้น ๆ และสร้าง middleware ภาษา Go ที่บังคับใช้ได้อย่างสม่ำเสมอข้ามบริการ
ขอบเขตของ rate limit คือความเร็วในการเรียก API เช่น คำขอต่อวินาทีหรือต่อนาที ส่วน quota คือปริมาณการใช้งานรวมในช่วงเวลาที่ยาวขึ้น เช่น ต่อวัน ต่อเดือน หรือรอบบิล
ถ้าต้องการลดกรณี "มันทำงานเมื่อวาน" ให้แสดงทั้งสองอย่างอย่างชัดเจนและระบุเวลารีเซ็ตเพื่อให้ลูกค้าวางแผนได้
เริ่มจากปัญหาที่คุณต้องการป้องกัน ถ้าเกิดปัญหาเพราะการระเบิดของทราฟฟิกทำให้เกิด timeout คุณต้องมีมาตรการควบคุมการระเบิดในระยะสั้น หาก endpoint บางตัวทำให้ค่าใช้จ่ายพุ่ง คุณต้องมีงบประมาณตามต้นทุน และถ้าพบพฤติกรรม brute force หรือ scraping ให้ตั้งการควบคุมการใช้งานที่เข้มงวดกว่า
วิธีรวดเร็ว: ถามว่า “ถ้า endpoint นี้มีทราฟฟิกเพิ่ม 10× สิ่งใดพังก่อน: ความหน่วง, ต้นทุน, หรือความปลอดภัย?” แล้วออกแบบขอบเขตให้ตรงกับคำตอบ
ใช้ขีดจำกัด per-user เพื่อป้องกันไม่ให้คนเดียวลากทีมช้ามาก และใช้ per-org เพื่อกำหนดเพดานการใช้งานของ workspace ให้สอดคล้องกับแผนการคิดราคา เพิ่ม per-token เมื่อมีคีย์แบบแชร์สำหรับการผนวกรวมกับพาร์ทเนอร์
จำไว้ว่า per-IP ควรเป็นตาข่ายนิรภัยสำหรับพฤติกรรมที่ชัดเจน เพราะเครือข่ายที่แชร์อยู่เบื้องหลัง IP เดียวอาจทำให้ผู้ใช้บริสุทธิ์ถูกบล็อกได้
Token bucket มักเป็นค่าพื้นฐานที่ดีเพราะยอมให้เกิด burst สั้น ๆ ขณะยังบังคับค่าเฉลี่ยในระยะยาว เหมาะกับ UX เช่น dashboard ที่ยิงหลายคำขอพร้อมกัน
ถ้า backend ไม่ทนต่อการระเบิดเลย อาจใช้ leaky bucket หรือคิวที่เข้มงวดกว่า แต่จะตอบสนองลูกค้าน้อยกว่าในช่วง burst
เพิ่ม concurrency limit เมื่อปัญหามาจากคำขอที่เปิดค้างมากเกินไป ไม่ใช่แค่จำนวนคำขอ เช่น endpoints ที่ช้า, long polling, streaming หรือการส่งออกใหญ่ ๆ
concurrency cap ป้องกันไม่ให้ไคลเอนต์ “อยู่ในข้อจำกัด 60 คำขอต่อนาที” แต่ยังผูกการเชื่อมต่อเปิดไว้เป็นร้อย ๆ
ใช้ HTTP 429 เมื่อคุณกำลังบล็อกคำขอและให้ body ที่ชัดเจนว่าขอบเขตใดถูกกระทบ (user, org, IP, หรือ token) และเมื่อใดที่ไคลเอนต์จะลองใหม่อีกครั้ง หัวข้อเดียวที่มีประโยชน์ที่สุดคือ Retry-After เพราะมันบอกเวลาที่แน่นอนให้ไคลเอนต์รอ
นอกจากนี้ ให้ส่ง RateLimit headers บนคำขอที่สำเร็จด้วย เพื่อให้ลูกค้ารู้ว่ากำลังเข้าใกล้ขอบเขตก่อนที่จะถูกบล็อก
กฎง่าย ๆ: ถ้า Retry-After อยู่ในคำตอบ ให้รออย่างน้อยเท่านั้นก่อนลองใหม่ หากไม่ระบุ ให้ใช้ exponential backoff พร้อม jitter เพื่อไม่ให้ไคลเอนต์จำนวนมากลองพร้อมกัน
จำกัดการ retry: กำหนดช่วงเวลาหน่วงระหว่างครั้ง เช่น สูงสุด 30–60 วินาที และจำกัดเวลาทั้งหมดของการลองซ้ำ เช่น หยุดหลัง 2 นาที แล้วแสดงข้อผิดพลาด อย่าพยายาม retry กับข้อผิดพลาดที่ต้องการการแก้ไข เช่น 400, 401/403, 404, 409
ใช้ hard limits เมื่อการเกินจะทำร้ายลูกค้าคนอื่นหรือทำให้ต้นทุนพุ่งทันที ใช้ soft limits เมื่อคุณต้องการเตือนก่อน ให้เวลาลูกค้าแก้บั๊กหรืออัปเกรดก่อนจะบล็อกจริง
รูปแบบปฏิบัติได้: เตือนที่ระดับ 80–90% แล้วค่อยบังคับเมื่อเกิน เพื่อช่วยลดตั๋วเร่งด่วนโดยไม่ปล่อยการใช้งานวิ่งแบบไร้ขอบเขต
ตั้งค่า IP limits ให้ค่อนข้างโอ่าและใช้เป็นเครื่องมือจับพฤติกรรมที่เป็นการละเมิดเท่านั้น เพราะหลายบริษัทแชร์ IP สาธารณะเดียวกัน เช่น ผ่าน NAT ของคลาวด์หรือ Wi‑Fi ของออฟฟิศ หากจำกัดตาม IP อย่างเข้มงวด อาจบล็อกลูกค้าทั้งหมดโดยไม่ตั้งใจ
สำหรับการจัดการการใช้งานปกติ ให้ใช้ per-user และ per-org เป็นหลัก และใช้ per-IP เป็นตาข่ายนิรภัย
ปล่อยฟีเจอร์เป็นขั้นตอนเพื่อสังเกตผลก่อนที่ลูกค้าจะได้รับผลกระทบ เริ่มด้วย “report only” เพื่อบันทึกสิ่งที่จะถูกบล็อก จากนั้นบังคับใช้กับกลุ่ม endpoint เล็ก ๆ หรือกลุ่ม tenant ย่อย แล้วค่อยขยาย
ติดตามอัตรา 429, ความหน่วงที่เกิดจาก limiter, และตัวตน (keys) ที่ถูกบล็อกมากที่สุด; สัญญาณเหล่านี้จะบอกว่าค่าที่ตั้งไม่ถูกต้องก่อนจะกลายเป็นตั๋วสนับสนุนจำนวนมาก