10 พ.ย. 2568·3 นาที
การเปลี่ยนแปลงสคีมาและการโยกย้ายในระบบที่สร้างด้วย AI: คู่มือ
เรียนรู้วิธีที่ระบบที่สร้างด้วย AI จัดการการเปลี่ยนสคีมาอย่างปลอดภัย: เวอร์ชัน การเปิดตัวที่เข้ากันได้ย้อนหลัง การโยกย้ายข้อมูล การทดสอบ การมอนิเตอร์ และกลยุทธ์การย้อนกลับ
ความหมายของ “สคีมา” ในระบบที่สร้างด้วย AI
สคีมา คือข้อตกลงร่วมกันเกี่ยวกับ รูปแบบของข้อมูล และ ความหมายของแต่ละฟิลด์ ในระบบที่ใช้ AI ข้อตกลงนี้ไม่ได้อยู่แค่ในตารางฐานข้อมูลเท่านั้น—และมักเปลี่ยนบ่อยกว่าที่ทีมคาดคิด
สคีมาไม่ใช่แค่เรื่องฐานข้อมูล
คุณจะพบสคีมาอย่างน้อยในสี่ชั้นทั่วไป:
- ฐานข้อมูล: ชื่อเทเบิล/คอลัมน์ ชนิดข้อมูล ข้อจำกัด ดัชนี และความสัมพันธ์
- API: รูปร่าง JSON ของคำขอ/คำตอบ ฟิลด์ที่จำเป็นกับที่เป็นทางเลือก ค่า enum รูปแบบข้อผิดพลาด และแนวปฏิบัติการแบ่งหน้า
- อีเวนต์และข้อความ: เพย์โหลดที่ส่งผ่านสตรีม คิว และเว็บฮุก (มักจะเวอร์ชันโดยอ้อมผ่านผู้บริโภค)
- คอนฟิกและสัญญา: ฟีเจอร์แฟลก ตัวแปรแวดล้อม คอนฟิก YAML/JSON และ “สัญญาที่ซ่อนอยู่” เช่น รูปแบบไฟล์และคอนเวนชันการตั้งชื่อ
ถ้าสองส่วนของระบบแลกเปลี่ยนข้อมูล มีสคีมาอยู่—แม้จะไม่มีใครเขียนมันลงเป็นเอกสารก็ตาม
ทำไมระบบที่สร้างด้วย AI ถึงมีการเปลี่ยนแปลงสคีบ่อยขึ้น
โค้ดที่สร้างโดย AI เร่งการพัฒนาได้อย่างมาก แต่ก็เพิ่มอัตราการเปลี่ยนแปลงด้วย:
- โค้ดที่สร้างขึ้นสะท้อน prompt และบริบทล่าสุด การปรับ prompt เล็กน้อยอาจเปลี่ยนชื่อตัวแปร รูปแบบการจัดชั้น ค่าเริ่มต้น หรือการตรวจความถูกต้อง
- ความต้องการพัฒนาเร็วขึ้น เมื่อการสร้าง endpoint หรือขั้นตอนพายป์ไลน์ใหม่กลายเป็นเรื่องถูกและง่าย
- คอนเวนชันไม่สอดคล้องกัน (snake_case vs camelCase,
idvsuserId) ปรากฏเมื่อมีการสร้างหรือปรับโครงสร้างซ้ำจากหลายแหล่ง
ผลลัพธ์คือการเบี่ยงเบนของสัญญาระหว่างผู้ผลิตและผู้บริโภคเกิดขึ้นบ่อยขึ้น
ถ้าคุณใช้เวิร์กโฟลว์แบบ vibe-coding (เช่น สร้าง handler, ชั้นเข้าถึง DB และการเชื่อมต่อผ่านการแชท) ก็ควรใส่วินัยเรื่องสคีมาเข้าไปตั้งแต่วันแรก แพลตฟอร์มอย่าง Koder.ai ช่วยทีมเคลื่อนไหวเร็วโดยสร้างแอป React/Go/PostgreSQL และ Flutter จากอินเทอร์เฟซแชท—แต่ยิ่งส่งได้เร็วเท่าไร ยิ่งต้องเวอร์ชันอินเทอร์เฟซ ตรวจสอบ payload และปล่อยการเปลี่ยนแปลงอย่างรอบคอบมากขึ้นเท่านั้น
เป้าหมายของคู่มือนี้
บทความนี้เน้นวิธีปฏิบัติที่เป็นประโยชน์เพื่อรักษาเสถียรภาพ production ขณะยังวนปรับปรุงได้เร็ว: รักษาความเข้ากันได้ย้อนหลัง ปล่อยการเปลี่ยนแปลงอย่างปลอดภัย และโยกย้ายข้อมูลโดยไม่สร้างความประหลาดใจ
สิ่งที่เราจะไม่ลงลึก
เราไม่ลงรายละเอียดวิชาการเชิงลึก วิธีการเชิงรูปแบบ หรือฟีเจอร์เฉพาะผู้ขาย ความสำคัญอยู่ที่แพตเทิร์นที่ใช้ได้ข้ามสแตก—ไม่ว่าระบบของคุณจะเขียนมือ ช่วยด้วย AI หรือสร้างด้วย AI เป็นหลัก
ทำไมการเปลี่ยนสคีมาถึงเกิดบ่อยขึ้นกับโค้ดที่สร้างโดย AI
โค้ดที่สร้างโดย AI ทำให้การเปลี่ยนสคีมาดูเป็นเรื่องปกติ—ไม่ใช่เพราะทีมไม่ใส่ใจ แต่เพราะอินพุตของระบบเปลี่ยนบ่อยขึ้น เมื่อพฤติกรรมของแอปขับเคลื่อนบางส่วนโดย prompt เวอร์ชันของโมเดล และโค้ดเชื่อมที่สร้างขึ้น รูปร่างของข้อมูลจึงมีแนวโน้มจะเบี่ยงเบนเมื่อเวลาผ่านไป
ทริกเกอร์ทั่วไปที่เจอจริง
รูปแบบที่มักก่อให้เกิดการเปลี่ยนแปลงซ้ำ:
- ฟีเจอร์ใหม่: เพิ่มฟิลด์ใหม่ (เช่น
risk_score,explanation,source_url) หรือแยกแนวคิดเดิมออกเป็นหลายฟิลด์ (เช่น แยกaddressเป็นstreet,city,postal_code) - การเปลี่ยนแปลงผลลัพธ์จากโมเดล: โมเดลใหม่อาจให้โครงสร้างละเอียดขึ้น ค่าจาก enum ต่างไป หรือการตั้งชื่อเปลี่ยนเล็กน้อย ("confidence" vs "score")
- การปรับ prompt: ปรับ prompt เพื่อปรับปรุงคุณภาพแต่กลับเปลี่ยนฟอร์แมต ฟิลด์ที่จำเป็น หรือการจัดชั้นโดยไม่ได้ตั้งใจ
แบบที่เสี่ยงและทำให้ระบบเปราะบาง
โค้ดที่สร้างโดย AI มักจะ "ใช้งานได้" อย่างรวดเร็ว แต่สามารถฝังสมมติฐานเปราะบางไว้:
- สมมติฐานแฝง: โค้ดสมมติว่าฟิลด์มีอยู่เสมอ เป็นตัวเลขเสมอ หรืออยู่ในช่วงที่คาดไว้
- การผูกมัดที่ซ่อนอยู่: หนึ่งบริการพึ่งพาชื่อฟิลด์หรือลำดับของอีกบริการแทนที่จะใช้อินเทอร์เฟซที่กำหนด
- ฟิลด์ที่ไม่มีเอกสาร: โมเดลเริ่มปล่อย property ใหม่ แล้วโค้ด downstream เริ่มพึ่งพามันโดยไม่มีการตกลงอย่างชัดเจน
ทำไม AI ถึงขยายความถี่ของการเปลี่ยน
การสร้างโค้ดกระตุ้นการวนปรับเปลี่ยนอย่างรวดเร็ว: คุณอาจสร้าง handler, parser และเลเยอร์ DB ใหม่บ่อยครั้ง ความเร็วนั้นมีประโยชน์ แต่ก็ทำให้เปลี่ยนอินเทอร์เฟซเล็กน้อยซ้ำๆ ได้ง่าย—บางครั้งโดยไม่สังเกต
กรอบคิดที่ปลอดภัยคือถือว่า ทุกสคีมาเป็นสัญญา: ตารางฐานข้อมูล payload ของ API อีเวนต์ และแม้แต่ structured LLM responses ถ้าผู้บริโภคพึ่งพามัน ให้เวอร์ชันมัน ตรวจสอบมัน และเปลี่ยนมันอย่างตั้งใจ
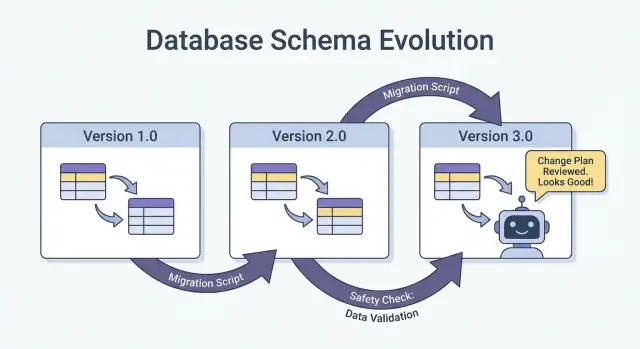
ประเภทการเปลี่ยนสคีมา: เชิงเพิ่ม (Additive) กับ เชิงทำลาย (Breaking)
การเปลี่ยนสคีมาไม่เหมือนกันทั้งหมด คำถามที่เป็นประโยชน์ที่สุดคือ: ผู้บริโภคเดิมจะยังทำงานโดยไม่ต้องแก้ไขหรือไม่? ถ้าใช่ มักเป็นการเพิ่ม ถ้าไม่ใช่ เป็นการทำลาย และต้องมีแผนการปล่อยที่ประสานกัน
การเปลี่ยนแบบเพิ่ม (โดยปกติปลอดภัย)
การเปลี่ยนแบบเพิ่มขยายสิ่งที่มีโดยไม่เปลี่ยนความหมายเดิม
ตัวอย่างในฐานข้อมูลทั่วไป:
- เพิ่มคอลัมน์ พร้อมค่าเริ่มต้นหรือให้เป็น NULL (เช่น
preferred_language) - เพิ่มตาราง หรือดัชนีใหม่
- เพิ่มฟิลด์เป็นทางเลือก ใน JSON ที่เก็บในคอลัมน์
ตัวอย่างไม่ใช่ฐานข้อมูล:
- เพิ่ม property ใหม่ในคำตอบ API (client ที่ละเลยฟิลด์ที่ไม่รู้จะยังทำงาน)
- เพิ่มฟิลด์ใหม่ในข้อความอีเวนต์
- เพิ่มค่าในฟีเจอร์แฟลกใหม่โดยยังคงพฤติกรรมเดิมเป็นค่าเริ่มต้น
การเพิ่มปลอดภัยก็ต่อเมื่อผู้บริโภคเก่าอดทน: ต้องละเลยฟิลด์ที่ไม่รู้จักและไม่ต้องการฟิลด์ใหม่
การเปลี่ยนแบบทำลาย (เสี่ยง)
การเปลี่ยนแบบทำลายแก้ไขหรือเอาสิ่งที่ผู้บริโภคพึ่งพาออก
ตัวอย่างการทำลายในฐานข้อมูล:
- เปลี่ยนชนิดคอลัมน์ (string → integer, ความละเอียด timestamp เปลี่ยน)
- เปลี่ยนชื่อฟิลด์/คอลัมน์ (โค้ดที่อ่านชื่อเดิมจะล้มเหลว)
- ลบคอลัมน์/ตาราง ที่ยังถูกเรียกใช้งาน
ตัวอย่างที่ไม่ใช่ฐานข้อมูล:
- เปลี่ยนชื่อ/ลบฟิลด์ JSON ในคำขอ/คำตอบ
- เปลี่ยนความหมายของอีเวนต์ (ชื่อฟิลด์เดิม ความหมายใหม่)
- แก้โครงสร้างเว็บฮุกโดยไม่ได้เพิ่มเวอร์ชัน
เขียนผลกระทบต่อผู้บริโภคเสมอ
ก่อน merge ให้บันทึก:
- ใครเป็นผู้บริโภค (บริการ, dashboard, พายป์ไลน์ข้อมูล, พาร์ตเนอร์)
- ความเข้ากันได้ (ย้อนหลัง/ไปข้างหน้า และเป็นเวลาเท่าไร)
- โหมดล้มเหลว (ข้อผิดพลาดการแยกวิเคราะห์ ข้อมูลเสียเงียบ หรือธุรกิจคำนวณผิด)
บันทึกสั้น ๆ นี้บังคับให้ชัดเจน—โดยเฉพาะเมื่อโค้ดที่สร้างโดย AI แอบเปลี่ยนสคีมาโดยไม่แจ้ง
ยุทธศาสตร์การเวอร์ชันสำหรับสคีมาและอินเทอร์เฟซ
การเวอร์ชันคือวิธีบอกระบบอื่น ๆ (และตัวคุณในอนาคต) ว่า “นี่เปลี่ยนแล้ว และนี่คือความเสี่ยง” เป้าหมายไม่ใช่เอกสารเยอะ แต่เพื่อป้องกันการเสียหายเงียบเมื่อไคลเอนต์ บริการ หรือพายป์ไลน์ข้อมูลอัพเดตไม่พร้อมกัน
กรอบคิด semantic versioning แบบภาษาธรรมดา
คิดเป็น major / minor / patch แม้จะไม่ต้องประกาศ 1.2.3 จริงๆ:
- Major: การเปลี่ยนที่ทำลาย ผู้บริโภคเก่าอาจล้มเหลวถ้าไม่แก้
- Minor: การเพิ่มที่ปลอดภัย ผู้บริโภคเก่ายังคงทำงาน; ผู้บริโภคใหม่ใช้ฟีเจอร์ใหม่ได้
- Patch: แก้บั๊กหรือชี้แจงโดยไม่เปลี่ยนความหมาย
กฎง่าย ๆ ที่ช่วยทีม: อย่าเปลี่ยนความหมายของฟิลด์ที่มีอยู่เงียบ ๆ ถ้า status="active" เคยหมายถึง “ลูกค้าที่จ่ายเงิน” อย่าเปลี่ยนให้หมายถึง “บัญชีมีอยู่” ให้เพิ่มฟิลด์ใหม่หรือเวอร์ชันใหม่แทน
Endpoint ที่มีเวอร์ชัน vs ฟิลด์ที่เวอร์ชัน
โดยปกติมีสองตัวเลือก:
1) Endpoint แบบมีเวอร์ชัน (เช่น /api/v1/orders และ /api/v2/orders):
ดีเมื่อการเปลี่ยนเป็นการทำลายหรือแพร่หลาย ชัดเจนแต่สร้างความซ้ำซ้อนและการดูแลรักษาหลายเวอร์ชัน
2) ฟิลด์เวอร์ชัน / การพัฒนาแบบเพิ่มเติม (เช่น เพิ่ม new_field รักษา old_field ไว้):
ดีเมื่อเปลี่ยนได้แบบเพิ่มเติม ไคลเอนต์เก่าจะละเลยสิ่งที่ไม่เข้าใจได้ ต่อมาค่อยประกาศเลิกใช้และเอาฟิลด์เก่าออกตามแผน
สคีมาอีเวนต์และเรจิสทรี
สำหรับสตรีม คิว และเว็บฮุก ผู้บริโภคมักอยู่นอกการควบคุมการปล่อยของคุณ schema registry (หรือแค็ตตาล็อกสคีมาแบบศูนย์กลางพร้อมการเช็กความเข้ากันได้) ช่วยบังคับกฎเช่น “อนุญาตเฉพาะการเพิ่ม” และทำให้เห็นชัดว่าผู้ผลิตและผู้บริโภคพึ่งพาเวอร์ชันใด
การปล่อยอย่างปลอดภัย: ขยาย/เติมข้อมูล/สวิตช์/บีบ (รูปแบบที่เชื่อถือได้ที่สุด)
วิธีที่ปลอดภัยที่สุดในการปล่อยการเปลี่ยนสคีมา—โดยเฉพาะเมื่อมีหลายบริการ งานแบตช์ และคอมโพเนนต์ที่สร้างด้วย AI—คือรูปแบบ expand → backfill → switch → contract มันลดเวลา downtime และหลีกเลี่ยงการปรับใช้แบบทั้งระบบที่หากมีผู้บริโภคล้าหลังจะทำให้ production พัง
สี่ขั้นตอน (และเหตุผลที่เวิร์ค)
1) Expand: แนะนำสคีมาใหม่ในทางที่เข้ากันได้ย้อนหลัง ผู้อ่านและผู้เขียนเดิมควรยังทำงานตามปกติ
2) Backfill: เติมฟิลด์ใหม่สำหรับข้อมูลเก่า (หรือประมวลผลข้อความย้อนหลัง) เพื่อให้ระบบสอดคล้องกัน
3) Switch: อัพเดตผู้เขียนและผู้อ่านให้ใช้ฟิลด์/ฟอร์แมตใหม่ สามารถทำแบบค่อยเป็นค่อยไป (canary, ปริมาณเปอร์เซ็นต์) เพราะสคีมารองรับทั้งสองแบบ
4) Contract: เอาฟิลด์/ฟอร์แมตเก่าออกหลังมั่นใจว่าไม่มีใครพึ่งพาแล้ว
การเปิดตัวแบบสองเฟส (expand → switch) และสามเฟส (expand → backfill → switch) ช่วยลด downtime เพราะหลีกเลี่ยงการผูกมัดแน่น: ผู้เขียนย้ายก่อน ผู้อ่านย้ายทีหลัง หรือในทางกลับกัน
ตัวอย่าง: เพิ่มคอลัมน์ เติมข้อมูล แล้วบังคับให้ต้องมี
สมมติอยากเพิ่ม customer_tier:
- Expand: เพิ่ม
customer_tierให้เป็น nullable โดยค่าเริ่มต้นเป็นNULL - Backfill: รันงานเพื่อคำนวณ tier สำหรับแถวเดิม
- Switch: อัพเดตแอปและพายป์ไลน์ให้เขียน
customer_tierเสมอ และให้ผู้อ่านใช้ฟิลด์นี้เป็นหลัก - Contract: หลังมอนิเตอร์แล้ว ทำให้เป็น NOT NULL (และอาจเอา logic แบบเก่าออก)
การประสานงาน: ผู้เขียนและผู้อ่านต้องตกลงกัน
ถือทุกสคีมาเป็นสัญญาระหว่างผู้ผลิต (writers) และผู้บริโภค (readers) ในระบบที่สร้างด้วย AI เรื่องนี้ง่ายจะพลาดเพราะโค้ดทางเลือกใหม่ปรากฏเร็ว ให้ทำการปล่อยอย่างชัดเจน: บันทึกว่าเวอร์ชันใดเขียนอะไร บริการใดอ่านทั้งสองแบบ และวันที่จะเอาฟิลด์เก่าออก
การโยกย้ายฐานข้อมูล: เปลี่ยนข้อมูลโดยไม่ทำลาย production
Plan your next schema change
ใช้โหมดวางแผนเพื่อร่างขั้นตอน expand-backfill-switch-contract ก่อนจะสร้างโค้ด
การโยกย้ายฐานข้อมูลคือ “คู่มือ” สำหรับย้ายข้อมูลและโครงสร้างจากสถานะปลอดภัยหนึ่งไปยังอีกสถานะหนึ่ง ในระบบที่สร้างด้วย AI ยิ่งสำคัญเพราะโค้ดที่สร้างอาจสมมติว่าคอลัมน์มีอยู่ เปลี่ยนชื่อไม่สอดคล้อง หรือตั้งข้อจำกัดใหม่โดยไม่พิจารณาแถวที่มีอยู่
ไฟล์มิเกรชัน vs auto-migrations
ไฟล์มิเกรชัน (เช็กเข้า source control) คือขั้นตอนชัดเจนเช่น “เพิ่มคอลัมน์ X”, “สร้างดัชนี Y”, หรือ “คัดลอกข้อมูลจาก A ไป B” มันตรวจสอบได้ รีวิวได้ และสามารถนำมารันซ้ำในสเตจและโปรดักชัน
Auto-migrations (ที่สร้างโดย ORM/framework) สะดวกในการพัฒนาเบื้องต้น แต่บางครั้งจะสร้างการดำเนินการที่เสี่ยง (เช่น ลบคอลัมน์ รีบิวด์ตาราง) หรือเรียงลำดับการเปลี่ยนแปลงผิดที่คุณไม่ตั้งใจ
กฎปฏิบัติ: ใช้ auto-migrations เป็นร่าง แล้วแปลงเป็นไฟล์มิเกรชันที่ผ่านรีวิวสำหรับงานที่แตะ production
idempotency และการจัดลำดับ
ทำให้มิเกรชัน idempotent เท่าที่เป็นไปได้: รันซ้ำไม่ควรทำให้ข้อมูลเสียหายหรือทำงานล้มครึ่งทาง ใช้คำสั่งแบบ “create if not exists” เพิ่มคอลัมน์เป็น nullable ก่อน และป้องกันการแปลงข้อมูลด้วยการเช็ก
และรักษา ลำดับที่ชัดเจน ทุกสภาพแวดล้อม (local, CI, staging, prod) ควรใช้ลำดับมิเกรชันเดียวกัน อย่าแก้ production ด้วย SQL แบบแมนนวลโดยไม่จับไว้ในมิเกรชันหลังจากนั้น
มิเกรชันที่รันนานโดยไม่ล็อกตาราง
การเปลี่ยนสคีมาใหญ่บางอย่างอาจล็อกตารางขนาดใหญ่และบล็อกการเขียน (หรือแม้แต่การอ่าน) วิธีลดความเสี่ยงโดยรวม:
- ใช้การดำเนินการแบบออนไลน์/ลดล็อกที่ฐานข้อมูลรองรับ (เช่น สร้างดัชนีแบบ concurrent)
- แยกการเปลี่ยนเป็นหลายขั้นตอน: สร้างโครงสร้างใหม่ก่อน เติมข้อมูลเป็นชุด แล้วสลับแอป
- วางงานหนักในช่วงที่ทราฟฟิกลดต่ำ พร้อมกำหนดค่า timeout และมอนิเตอร์
การตั้งค่ามัลติ-เทนแอนท์และชาร์ด
สำหรับฐานข้อมูลแบบ multi-tenant ให้รันมิเกรชันในลูปที่ควบคุมต่อ tenant พร้อมติดตามความคืบหน้าและลองรีไทรอย่างปลอดภัย สำหรับ shards ให้ถือแต่ละชาร์ดเป็นระบบ production แยก: ปล่อยมิเกรชันทีละชาร์ด ตรวจสอบสุขภาพ แล้วค่อยไปต่อ จำกัด blast radius และทำให้ rollback เป็นไปได้
Backfills และการประมวลผลซ้ำ: อัพเดตข้อมูลเก่า
Backfill คือการเติมฟิลด์ที่เพิ่มใหม่ (หรือค่าแก้ไข) ให้เรคอร์ดที่ มีอยู่แล้ว การ reprocessing คือการเอาข้อมูลย้อนหลังไหลผ่านพายป์ไลน์อีกครั้ง—มักเพราะกฎธุรกิจเปลี่ยน บั๊กถูกแก้ หรือฟอร์แมตผลลัพธ์ของโมเดลเปลี่ยน
ทั้งสองกรณีเจอบ่อยหลังการเปลี่ยนสคีมา: เขียนรูปแบบใหม่ให้ข้อมูลใหม่ได้ง่าย แต่ระบบ production มักพึ่งพาข้อมูลเมื่อวานให้สอดคล้องด้วย
วิธีการทั่วไป
Backfill แบบออนไลน์ (ใน production แบบค่อยเป็นค่อยไป). รันงานควบคุมที่อัพเดตเรคอร์ดเป็นแบตช์เล็ก ๆ ในขณะที่ระบบยังใช้งานได้ ปลอดภัยกว่าเพราะสามารถ throttle หยุดชั่วคราวและ resume ได้
Backfill แบบแบตช์ (ออฟไลน์หรือกำหนดเวลา). ประมวลผลเป็นก้อนใหญ่ในช่วงทราฟฟิกลด ใช้ง่ายแต่สร้างสไปก์ในโหลดและแก้ผิดได้ช้ากว่า
Lazy backfill เมื่ออ่าน. ขณะอ่านเรคอร์ดเก่า แอปคำนวณ/เติมฟิลด์ที่ขาดแล้วเขียนกลับ วิธีนี้กระจายค่าใช้จ่ายแต่ทำให้การอ่านครั้งแรกช้าลงและอาจทิ้งข้อมูลเก่าไม่แปลงอีกนาน
ในทางปฏิบัติ ทีมมักผสมกัน: lazy backfill สำหรับเรคอร์ดหางยาว และงานออนไลน์สำหรับข้อมูลที่เข้าถึงบ่อย
วิธีตรวจสอบความถูกต้องของ backfill
การตรวจสอบต้องชัดเจนและวัดได้:
- จำนวน: กี่แถว/อีเวนต์ควรถูกอัพเดต เทียบกับจำนวนที่อัพเดตแล้ว
- เช็คซัม/สรุป: เทียบยอดรวม (เช่น ผลรวมจำนวนเงิน, จำนวน ID เดียวกัน) ก่อน/หลัง
- การสุ่มตัวอย่าง: ตรวจสอบตัวอย่างที่เป็นตัวแทน รวมเคสขอบเขต
และตรวจ downstream ด้วย: dashboard, ดัชนีค้นหา, แคช และการส่งออกที่พึ่งฟิลด์ที่อัพเดต
ต้นทุน เวลา และเกณฑ์ยอมรับ
Backfill แลกความ เร็ว กับ ความเสี่ยงและต้นทุน (โหลด คอมพิวต์ และงานปฏิบัติการ) กำหนดเกณฑ์ยอมรับล่วงหน้า: ความหมายของ “เสร็จ” เวลาที่คาดหวัง อัตราความผิดพลาดสูงสุดที่รับได้ และจะทำอย่างไรถ้าตรวจสอบล้มเหลว (หยุด, รีไทร, หรือย้อนกลับ)
การพัฒนาอีเวนต์และสคีมาเมสเสจ (สตรีม คิว เว็บฮุก)
Evolve event schemas carefully
ออกแบบ payload ของอีเวนต์ให้ทนนต่อฟิลด์ที่ไม่รู้จักและหลีกเลี่ยงการทำให้ผู้บริโภคเสียหาย
สคีมาไม่ได้อยู่แค่ในฐานข้อมูล ทุกครั้งที่ระบบหนึ่งส่งข้อมูลไปยังอีกระบบ—Kafka, SQS/RabbitMQ, เว็บฮุก หรือแม้แต่ “อีเวนต์” ที่เขียนลง object storage—คุณสร้างสัญญา ผู้ผลิตและผู้บริโภคเคลื่อนไหวอิสระ ดังนั้นสัญญาเหล่านี้มักจะเปราะบางกว่าตารางภายในแอปเดียว
ค่าเริ่มต้นที่ปลอดภัย: พัฒนาอีเวนต์แบบเข้ากันได้ย้อนหลัง
สำหรับสตรีมและเว็บฮุก ให้เปลี่ยนแบบที่ผู้บริโภคเก่าสามารถละเลยได้และผู้บริโภคใหม่สามารถรับได้
กฎปฏิบัติ: เพิ่มฟิลด์ อย่าเอาออกหรือเปลี่ยนชื่อ ถ้าจำเป็นจะเลิกใช้ ให้ยังส่งมันสักพักและบันทึกว่า deprecated
ตัวอย่าง: ขยายเหตุการณ์ OrderCreated โดยเพิ่มฟิลด์เป็นทางเลือก
{
"event_type": "OrderCreated",
"order_id": "o_123",
"created_at": "2025-12-01T10:00:00Z",
"currency": "USD",
"discount_code": "WELCOME10"
}
ผู้บริโภคเก่าอ่าน order_id และ created_at แล้วละเลยที่เหลือ
สัญญาที่ขับเคลื่อนโดยผู้บริโภค (เวอร์ชันภาษาธรรมดา)
แทนที่จะให้ผู้ผลิตเดาว่าจะทำให้ใครล้มเหลวหรือไม่ ผู้บริโภคระบุสิ่งที่พวกเขาพึ่งพา (ฟิลด์ ชนิด กฎจำเป็น/ไม่จำเป็น) แล้วผู้ผลิตตรวจสอบการเปลี่ยนแปลงเทียบกับความคาดหวังเหล่านั้นก่อนปล่อย นี่มีประโยชน์มากในโค้ดเบสที่สร้างด้วย AI ซึ่งโมเดลอาจเปลี่ยนชื่อฟิลด์หรือชนิดได้เอง
จัดการฟิลด์ที่ไม่รู้จักอย่างปลอดภัย
ทำให้ parser อดทน:
- ละเลยฟิลด์ที่ไม่รู้จัก โดยค่าเริ่มต้น (อย่า fail แค่มีคีย์ใหม่)
- ถือฟิลด์ใหม่เป็น ทางเลือก จนกว่าจะต้องใช้จริง
- บันทึกฟิลด์ที่ไม่คาดคิดในระดับต่ำเพื่อสังเกตการนำไปใช้โดยไม่ต้องปลุกคนบน call list
เมื่อจำเป็นต้องมีการเปลี่ยนแบบทำลาย ให้ใช้ชื่อเหตุการณ์ใหม่หรือชื่อเวอร์ชัน (เช่น OrderCreated.v2) และรันทั้งสองควบคู่จนกว่าผู้บริโภคจะย้ายแล้ว
เอาต์พุตจาก AI เป็นสคีมา: Prompt, โมเดล และการตอบแบบมีโครงสร้าง
เมื่อเพิ่ม LLM เข้าไปในระบบ ผลลัพธ์ของมันจะกลายเป็นสคีมาที่ใช้งานจริง—แม้จะไม่มีสเปกเป็นทางการ โค้ด downstream เริ่มสมมติว่า “จะมีฟิลด์ summary” “บรรทัดแรกคือหัวข้อ” หรือ “บูลเล็ตคั่นด้วยเครื่องหมายขีด” สมมติฐานเหล่านี้จะแข็งตัว และการเปลี่ยนพฤติกรรมของโมเดลเล็กน้อยก็ทำให้ล้มแบบเดียวกับการเปลี่ยนชื่อคอลัมน์
จงชอบโครงสร้างที่ชัดเจน (และตรวจสอบมัน)
แทนที่จะ parse ข้อความสวย ๆ ให้ขอเอาต์พุตแบบมีโครงสร้าง (เช่น JSON) และตรวจความถูกต้องก่อนเข้าระบบ คิดแบบนี้เหมือนย้ายจาก “พยายามดีที่สุด” เป็นสัญญา
แนวทางปฏิบัติ:
- กำหนด JSON schema (หรืออินเทอร์เฟซแบบมี type) สำหรับการตอบของโมเดล
- ปฏิเสธหรือกักกันการตอบที่ไม่ผ่านการตรวจ (อย่าแก้ไขเงียบ ๆ)
- บันทึกข้อผิดพลาดการตรวจสอบเพื่อดูว่ามีอะไรเปลี่ยน
สิ่งนี้สำคัญโดยเฉพาะเมื่อผลจาก LLM ถูกใช้ในพายป์ไลน์ข้อมูล ออโตเมชัน หรือเนื้อหาที่แสดงต่อผู้ใช้
วางแผนสำหรับ model drift
แม้ใช้ prompt เดิม ผลลัพธ์อาจเปลี่ยนเมื่อเวลาผ่านไป: ฟิลด์ถูกละไว้ คีย์เพิ่มขึ้น ชนิดเปลี่ยน ("42" vs 42, อาร์เรย์ vs สตริง) ให้ถือเป็นเหตุการณ์วิวัฒนาการสคีมา
การลดความเสี่ยงที่ได้ผลดี:
- ทำให้ฟิลด์เป็นทางเลือกเมื่อสมเหตุสมผล และกำหนดค่าเริ่มต้นชัดเจน
- อนุญาตคีย์ที่ไม่รู้จักแต่ละเลยอย่างปลอดภัย (เว้นแต่ต้องเข้มงวดเรื่อง compliance)
- เพิ่มการตรวจ guardrails (เช่น ฟิลด์ที่ต้องมี ความยาวสูงสุด ค่า enum)
ปรับ prompt เหมือนการเปลี่ยน API
Prompt คืออินเทอร์เฟซ ถ้าคุณแก้ มันจงเวอร์ชันเก็บไว้ ให้มี prompt_v1, prompt_v2 และปล่อยทีละน้อย (feature flags, canaries, หรือต่อ tenant) ทดสอบกับชุดประเมินคงที่ก่อนโปรโมต และให้เวอร์ชันเก่ายังคงรันจนกว่าผู้บริโภค downstream จะปรับตัวเสร็จ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับกลไกการเปิดตัวอย่างปลอดภัย ให้ดูแนวทางการเปิดตัวแบบ expand/backfill/switch/contract
การทดสอบและการตรวจสอบความถูกต้องสำหรับการเปลี่ยนสคีมา
การเปลี่ยนสคีมามักพังในวิธีน่าเบื่อและแพง: คอลัมน์ใหม่หายไปในสภาพแวดล้อมหนึ่ง ผู้บริโภคยังคาดฟิลด์เก่า หรือมิเกรชันทำงานบนข้อมูลว่างแต่ time out ใน production การทดสอบช่วยเปลี่ยน "ความประหลาดใจ" เหล่านั้นให้เป็นงานที่คาดเดาได้และแก้ได้
สามระดับของการทดสอบ (และสิ่งที่แต่ละระดับจับได้)
Unit tests ปกป้องลอจิกภายใน: ฟังก์ชันแมปปิง serializer/deserializer validator และ query builder ถ้าชื่อฟิลด์เปลี่ยนหรือชนิดเปลี่ยน unit test ควรล้มใกล้กับโค้ดที่ต้องอัปเดต
Integration tests ตรวจว่าแอปยังทำงานกับ dependencies จริง: เอนจินฐานข้อมูลจริง เครื่องมือมิเกรชันจริง และรูปแบบข้อความจริง ที่นี่จับปัญหาเช่น "โมเดล ORM เปลี่ยนแต่มิเกรชันไม่ได้" หรือ "ชื่อดัชนีชนกัน"
End-to-end tests จำลองผลลัพธ์ของผู้ใช้หรือเวิร์กโฟลว์ข้ามบริการ: สร้างข้อมูล โยกย้าย อ่านกลับผ่าน API และยืนยันว่าผู้บริโภค downstream ยังคงทำงานถูกต้อง
Contract tests ระหว่างผู้ผลิตและผู้บริโภค
การวิวัฒนาการของสคีมามักพังที่พรมแดน: API ระหว่างบริการ สตรีม คิว และเว็บฮุก เพิ่ม contract tests ที่รันทั้งสองฝั่ง:
- ผู้ผลิตพิสูจน์ว่าส่งเหตุการณ์/การตอบที่ตรงตามสัญญาที่ตกลง
- ผู้บริโภคพิสูจน์ว่า parse ได้ทั้ง เวอร์ชันเก่า และ เวอร์ชันใหม่ ในระหว่างการปล่อย
การทดสอบมิเกรชัน: apply และ rollback บนสภาพแวดล้อมสะอาด
ทดสอบมิเกรชันเหมือนการ deploy:
- เริ่มจาก snapshot ฐานข้อมูลสะอาด
- ใช้มิเกรชันทั้งหมดตามลำดับ
- ยืนยันว่าแอปอ่าน/เขียนได้
- รัน rollback (ถ้ารองรับ) หรือมิเกรชัน "down" และยืนยันว่ากลับสู่สถานะทำงานได้
Fixtures สำหรับเวอร์ชันสคีมาเก่าและใหม่
เก็บชุด fixture เล็ก ๆ ที่เป็นตัวแทน:
- ข้อมูลที่เขียนตามสคีมาเดิม (แถว/อีเวนต์แบบเก่า)
- ข้อมูลที่เขียนตามสคีมาใหม่
fixture เหล่านี้ทำให้การ regressions โดดเด่น โดยเฉพาะเมื่อโค้ดที่สร้างโดย AI เปลี่ยนชื่อฟิลด์ ความเป็นทางเลือก หรือลำดับแบบเงียบ ๆ
Observability: ตรวจจับการเสียหายแต่เนิ่นๆ
Ship with rollback ready
ถ่าย snapshot ก่อนการโยกย้ายที่เสี่ยง เพื่อกู้คืนได้รวดเร็วเมื่อเกิดการเบี่ยงเบน
การเปลี่ยนสคีมามักไม่ล้มฉับพลันเมื่อนำขึ้น แต่จะแสดงเป็นสัญญาณอ่อน ๆ เช่น การเพิ่มขึ้นของข้อผิดพลาดการแยกวิเคราะห์ ข้อความเตือนฟิลด์ไม่รู้จัก ข้อมูลหาย หรืองานแบ็กกราวด์ตามไม่ทัน Observability ที่ดีเปลี่ยนอาการเหล่านั้นเป็นข้อมูลที่ทำให้หยุดการปล่อยหรือแก้ไขได้
ควรมอนิเตอร์อะไรระหว่างการปล่อย
เริ่มจากพื้นฐาน (สุขภาพแอป) แล้วเพิ่มสัญญาณเฉพาะสคีมา:
- ข้อผิดพลาด: สไปก์ของ 4xx/5xx แต่รวมถึงข้อผิดพลาดแบบ "อ่อน" เช่น การแยก JSON ล้มเหลว การ deserialization ล้มเหลว และการ retry
- ความหน่วง: p95/p99 และเวลาประมวลผลคิว การเปลี่ยนสคีมาอาจเพิ่ม joins payload ใหญ่ขึ้น หรือการตรวจสอบเพิ่มเติม
- สัญญาณคุณภาพข้อมูล: อัตรา null ในคอลัมน์สำคัญเพิ่มขึ้น ปริมาณอีเวนต์ลดลงอย่างผิดปกติ ค่าดีฟอลต์ใหม่ปรากฏบ่อยเกินไป หรือความไม่ตรงกันระหว่างการแสดงผลเก่าและใหม่
- ความล้าพายป์ไลน์: lag ของผู้บริโภคในสตรีม/คิว คิวเว็บฮุกค้าง และอัตราการประมวลผลของงานมิเกรชัน
สำคัญคือต้องเทียบ ก่อน vs หลัง และแยกตาม เวอร์ชันไคลเอนต์, เวอร์ชันสคีมา, และ เซกเมนต์ทราฟฟิก (canary vs stable)
แดชบอร์ดที่ช่วยได้จริง
สร้างสองมุมมองแดชบอร์ด:
-
แดชบอร์ดพฤติกรรมแอป
- อัตราคำขอ อัตราข้อผิดพลาด เวลาแฝง (RED)
- ข้อยกเว้นยอดนิยม (จัดกลุ่มตามข้อความ)
- จำนวน/ร้อยละข้อผิดพลาดการตรวจสอบ/การแยกวิเคราะห์
- การแจกแจงขนาดเพย์โหลด (จับ payload ที่ใหญ่ผิดปกติ)
-
แดชบอร์ดมิเกรชันและงานแบ็กกราวด์
- ความคืบหน้าของงานมิเกรชัน (% เสร็จ), แถวที่ประมวลผล/วินาที, ETA
- อัตราความล้มเหลวและจำนวน retry
- ความลึกของคิว / lag ของผู้บริโภค
- ปริมาณ dead-letter queue (ถ้ามี)
ถ้าคุณใช้การปล่อยแบบ expand/contract ให้มีพาเนลที่แสดง การอ่าน/เขียนแยกระหว่างสคีมาเก่าและใหม่ เพื่อเห็นว่าเมื่อใดปลอดภัยที่จะไปขั้นถัดไป
การแจ้งเตือนสำหรับความล้มเหลวเฉพาะสคีมา
ใช้การ page เมื่อเกิดปัญหาที่บ่งชี้ว่าข้อมูลถูกทิ้งหรืออ่านผิด:
- อัตราข้อผิดพลาดการตรวจสอบสคีมา สูงกว่าธริตที่ต่ำ (มัก \u003c0.1% ก็มีความหมาย)
- การล้มเหลวในการแยก/deserialize (โดยเฉพาะถ้าเกิดจากผู้ผลิต/ผู้บริโภคคนใดคนหนึ่ง)
- คำเตือนฟิลด์ที่ไม่คาดคิด / ฟิลด์ที่ต้องการหายไป ที่เพิ่มขึ้น
- งานมิเกรชันค้าง (ไม่มีความคืบหน้านาน N นาที) หรือ lag โตเร็วกว่าความเร็วการประมวลผล
หลีกเลี่ยงการแจ้งเตือนดังๆ จาก 500s ที่ไม่มีบริบท; ผูกการเตือนกับการปล่อยสคีมาโดยใช้แท็กอย่างเวอร์ชันสคีมาและ endpoint
บันทึกเวอร์ชันเพื่อดีบักเร็ว
ระหว่างการเปลี่ยน ให้รวมและบันทึก:
- เวอร์ชันสคีมา (เช่น header
X-Schema-Versionหรือฟิลด์ metadata ของข้อความ) - เวอร์ชันแอปของผู้ผลิต/ผู้บริโภค
- เวอร์ชันโมเดล / เวอร์ชัน prompt เมื่อเอาต์พุตจาก AI เข้าสู่ข้อมูลเชิงโครงสร้าง
รายละเอียดนี้ทำให้ "ทำไมเพย์โหลดนี้ถึงล้ม" ตอบได้ภายในไม่กี่นาที แทนที่จะเป็นวัน โดยเฉพาะเมื่อบริการหรือเวอร์ชันโมเดลต่างกันพร้อมกัน
ย้อนกลับ การกู้คืน และการจัดการการเปลี่ยน
การเปลี่ยนสคีมาล้มในสองทาง: ตัวการเปลี่ยนผิดเอง หรือระบบรอบ ๆ มันทำงานต่างจากที่คาด (โดยเฉพาะเมื่อโค้ดที่สร้างด้วย AI ฝังสมมติฐานเล็กน้อย) ไม่ว่าอย่างไร มิเกรชันทุกอันต้องมีเรื่องการย้อนกลับก่อนปล่อย—แม้ว่าแผนนั้นจะระบุว่า "ไม่มีย้อนกลับ"
เลือก "ไม่มีย้อนกลับ" อาจถูกต้องเมื่อการเปลี่ยนไม่สามารถกลับได้ (เช่น ลบคอลัมน์ แปลงแบบทำลาย หรือ deduplicate อย่างถาวร) แต่ "ไม่มีย้อนกลับ" ไม่เท่ากับไม่มีแผน; มันคือการตัดสินใจที่ย้ายแผนไปสู่ การแก้ไขแบบเดินหน้า, การคืนจากสำเนา, และ การกักกัน
ตัวเลือกการย้อนกลับที่ใช้ได้จริง
Feature flags / config gates: ห่อผู้อ่าน ผู้เขียน และฟิลด์ API ใหม่ไว้หลังแฟลกเพื่อปิดพฤติกรรมใหม่ได้โดยไม่ต้อง redeploy มีประโยชน์เมื่อโค้ดที่สร้างโดย AI ถูกต้องเชิงไวยากรณ์แต่ผิดเชิงความหมาย
ปิด dual-write: หากเขียนทั้งสคีมาเก่าและใหม่ในช่วง expand/contract ให้เก็บ kill switch ปิดเส้นทางเขียนใหม่เพื่อหยุดการเบี่ยงเบนเพิ่มเติมขณะสืบสวน
ย้อนผู้อ่าน (ไม่ใช่แค่ผู้เขียน): เหตุการณ์จำนวนมากเกิดเพราะผู้บริโภคเริ่มอ่านฟิลด์หรือเทเบิลใหม่เร็วเกินไป ทำให้ย้อนผู้บริการไปยังเวอร์ชันก่อนหน้าหรือให้ละเลยฟิลด์ใหม่ได้ง่าย
รู้ขีดจำกัดของการย้อนกลับ
มิเกรชันบางอย่างกลับไม่ได้สะอาด:
- การแปลงเชิงทำลาย (เช่น hashing, normalization ที่ทำให้ข้อมูลสูญ)
- การลบ/เปลี่ยนชื่อโดยไม่มีสำเนาสำรอง
- Backfill ที่เขียนทับค่าต้นทางของความจริง
สำหรับกรณีเหล่านี้ วางแผน กู้คืนจากแบ็กอัพ, replay จากอีเวนต์, หรือ คำนวณใหม่จากอินพุตดิบ—และยืนยันว่ายังมีอินพุตเหล่านั้นอยู่
เช็คลิสต์ก่อนปล่อย (pre-flight)
- ตัดสินใจเรื่อง rollback บันทึกไว้ ("revert", "forward fix", หรือ "no rollback + restore path")
- ปุ่มหยุดชัดเจน: แฟลกและ/หรือ kill switch สำหรับ dual-write
- ตรวจสอบแบ็กอัพ/สแนปชอต; ทดสอบการกู้คืนอย่างน้อยครั้งหนึ่ง
- มิเกรชันเป็น idempotent; การรันซ้ำไม่ทำให้ข้อมูลเสียหาย
- ตั้งมอนิเตอร์และการแจ้งเตือนสำหรับอัตราข้อผิดพลาด การตรวจสอบสคีมา และ lag
- ระบุความเป็นเจ้าของ: ใครอนุมัติ ใครรัน ใคร on-call ขณะปล่อย
การจัดการการเปลี่ยนที่ดีทำให้การย้อนกลับเกิดขึ้นไม่บ่อย—และเมื่อเกิด ก็เป็นเรื่องน่าเบื่อ (boring) ที่จัดการได้
ถ้าทีมคุณวนปรับอย่างรวดเร็วด้วยการพัฒนาแบบช่วยด้วย AI ให้จับแนวปฏิบัติเหล่านี้กับเครื่องมือที่สนับสนุนการทดลองอย่างปลอดภัย เช่น Koder.ai ที่มี โหมดวางแผน สำหรับออกแบบการเปลี่ยนล่วงหน้า และ สแนปชอต/การย้อนกลับ เพื่อกู้คืนเร็วเมื่อการเปลี่ยนที่สร้างโดย AI บิดเบือนสัญญา เมื่อใช้ร่วมกัน การสร้างโค้ดอย่างรวดเร็วและการพัฒนาสคีมาแบบมีวินัยช่วยให้เคลื่อนไหวเร็วขึ้น โดยไม่ ทำให้ production เป็นสนามทดสอบ