08 มิ.ย. 2568·2 นาที
การการันตีแบบ ACID กับระบบธุรกรรมที่เชื่อถือได้
เรียนรู้ว่า การการันตีแบบ ACID มีผลต่อการออกแบบฐานข้อมูลและพฤติกรรมแอปอย่างไร สำรวจ atomicity, consistency, isolation, durability ข้อแลกเปลี่ยน และตัวอย่างจริง
เรียนรู้ว่า การการันตีแบบ ACID มีผลต่อการออกแบบฐานข้อมูลและพฤติกรรมแอปอย่างไร สำรวจ atomicity, consistency, isolation, durability ข้อแลกเปลี่ยน และตัวอย่างจริง
order.customer_id ต้องชี้ไปยังลูกค้าที่มีอยู่\n- Unique constraints: ไม่มีผู้ใช้สองคนที่มีอีเมลเดียวกัน\n- Check constraints / invariants: ยอดบัญชีไม่สามารถติดลบ หรือจำนวนสินค้าไม่สามารถเป็นลบได้\n\nถ้ากฎเหล่านี้มีอยู่ ฐานข้อมูลจะปฏิเสธทรานแซคชันที่ละเมิดกฎเหล่านี้—ดังนั้นคุณจะไม่จบลงด้วยข้อมูลที่ “ครึ่งถูกครึ่งผิด”\n\n### การตรวจสอบในแอป vs ข้อจำกัดในฐานข้อมูล\n\nการตรวจสอบทางฝั่งแอปสำคัญ แต่ไม่เพียงพอ:\n\n- การตรวจสอบในแอป ช่วย UX (ข้อความผิดพลาดชัดเจน feedback เร็ว) และบังคับกฎธุรกิจซับซ้อนได้\n- ข้อจำกัดฐานข้อมูล เป็นประตูสุดท้าย—โดยเฉพาะเมื่อหลายบริการ งานแบ็คกราวด์ นำเข้า หรือเครื่องมือแอดมินเขียนเข้าตารางเดียวกัน\n\nโหมดล้มเหลวคลาสสิกคือเช็กในแอปว่า “อีเมลว่าง” แล้วแทรกแถว ภายใต้ concurrency คำขอสองรายการอาจผ่านการเช็กพร้อมกันได้ unique constraint ในฐานข้อมูลเท่านั้นที่รับรองว่าแทรกได้เพียงครั้งเดียว\n\n### Consistency ในการปฏิบัติ\n\nถ้าคุณเข้ารหัสว่า “ยอดไม่ติดลบ” เป็นข้อจำกัด (หรือบังคับอย่างเชื่อถือได้ภายในทรานแซคชันเดียว) การโอนที่ทำให้ยอดติดลบต้องล้มเหลวทั้งหมด ถ้าคุณไม่เข้ารหัสกฎนั้นที่ไหนเลย ACID จะไม่สามารถปกป้องได้—เพราะไม่มีอะไรให้บังคับ\n\nConsistency สรุปคือการระบุชัดเจน: นิยามกฎ แล้วปล่อยให้ทรานแซคชันรักษากฎเหล่านั้นไม่ให้ถูกละเมิด\n\n## Isolation: ทำงานอย่างปลอดภัยท่ามกลางการทำพร้อมกัน\n\nIsolation ทำให้แน่ใจว่าทรานแซคชันจะไม่เหยียบเท้ากัน ขณะที่ทรานแซคชันหนึ่งกำลังทำงาน ทรานแซคชันอื่นไม่ควรเห็นงานที่ยังไม่เสร็จหรือบังตัดกันโดยไม่ตั้งใจ เป้าหมายคือให้แต่ละทรานแซคชันทำงานเหมือนรันคนเดียว ถึงแม้ว่าจะมีผู้ใช้จำนวนมากพร้อมกัน\n\n### ทำไมการทำงานพร้อมกันทำให้เรื่องยาก\n\nระบบจริงมีความยุ่ง: ลูกค้าสั่งซื้อ ตัวแทนบริการลูกค้าอัปเดตโปรไฟล์ งานแบ็คกราวด์ปรับยอด—ทั้งหมดเกิดขึ้นพร้อมกัน การทำงานเหล่านี้มักแตะแถวเดียวกัน (ยอดบัญชี จำนวนสต็อก หรือช่องการจอง)\n\nถ้าไม่มี isolation เวลาจะกลายเป็นส่วนหนึ่งของตรรกะธุรกิจ การอัปเดต “หักสต็อก” อาจแข่งกับการเช็กเอาต์อีกอัน หรือรายงานอาจอ่านข้อมูลขณะที่กำลังเปลี่ยนและแสดงตัวเลขที่ไม่เคยมีสถานะคงที่จริงๆ\n\n### Isolation มักตั้งค่าได้\n\nการทำ Isolation แบบเต็ม (“ทำเหมือนอยู่คนเดียว”) อาจมีค่าใช้จ่ายสูง มันอาจลด throughput เพิ่มการรอ (ล็อก) หรือต้อง retry บ่อย ขณะเดียวกันหลายงานก็ไม่ต้องการการป้องกันที่เข้มงวดที่สุด—การอ่าน analytics เมื่อวานสามารถทนความไม่สอดคล้องเล็กน้อยได้\n\nนั่นคือเหตุผลที่ฐานข้อมูลให้ ระดับ isolation ที่ตั้งค่าได้: คุณเลือกได้ว่ารับความเสี่ยงการทำพร้อมกันมากแค่ไหนเพื่อแลกกับประสิทธิภาพและความขัดแย้งที่น้อยลง\n\n### พรีวิวสั้น ๆ: ความผิดปกติที่ isolation ป้องกัน (หรือยอมให้)\n\nเมื่อ isolation อ่อนเกินไปสำหรับงานของคุณ คุณจะเจอความผิดปกติคลาสสิกเหล่านี้:\n\n- Dirty reads: อ่านการเปลี่ยนแปลงที่อีกทรานแซคชันยังไม่ commit\n- Lost updates: สองทรานแซคชันเขียนทับกันและการเปลี่ยนแปลงชุดหนึ่งหายไป\n- Phantom reads: รันคิวรีเดิมแล้วได้ชุดแถวต่างกันเพราะอีกทรานแซคชันเพิ่มหรือลบแถวที่ตรงเงื่อนไข\n\nเข้าใจรูปแบบความผิดพลาดเหล่านี้จะช่วยให้เลือกระดับ isolation ที่สอดคล้องกับคำสัญญาของผลิตภัณฑ์ของคุณได้ง่ายขึ้น\n\n## ความผิดปกติทั่วไปที่ Isolation ป้องกัน (หรือยอมให้)\n\nIsolation กำหนดว่าคุณจะเห็นการกระทำของทรานแซคชันอื่นระหว่างที่ของคุณกำลังรันหรือไม่ เมื่อ isolation อ่อนเกินไป คุณอาจเจอพฤติกรรมที่เป็นไปได้แต่ทำให้ผู้ใช้ประหลาดใจ\n\n### ความผิดปกติในการอ่าน\n\nDirty read เกิดเมื่อคุณอ่านข้อมูลที่ทรานแซคชันอื่นเขียนแต่ยังไม่ commit\n\nสถานการณ์: Alex โอน $500 ออกจากบัญชี ยอดชั่วคราวกลายเป็น $200 และคุณอ่านว่า $200 ก่อนที่การโอนของ Alex จะล้มเหลวและ rollback\n\nผลลัพธ์ต่อผู้ใช้: ลูกค้าเห็นยอดผิดพลาด, กฎตรวจจับการฉ้อโกงทำงานผิด, หรือเจ้าหน้าที่ตอบคำถามผิด\n\nNon-repeatable read หมายถึงคุณอ่านแถวเดียวกันสองครั้งแล้วได้ค่าต่างกันเพราะทรานแซคชันอื่น commit ระหว่างนั้น\n\nสถานการณ์: คุณโหลดยอดรวมคำสั่งซื้อ ($49.00) แล้วรีเฟรชอีกครั้งเห็น $54.00 เพราะบรรทัดส่วนลดถูกลบ\n\nผลต่อผู้ใช้: “ยอดของฉันเปลี่ยนขณะเช็กเอาต์” ทำให้สูญเสียความเชื่อมั่นหรือยกเลิกตะกร้า\n\nPhantom read คล้าย non-repeatable read แต่เกี่ยวกับชุดของแถว: คิวรีครั้งที่สองคืนค่าแถวเพิ่มหรือลดเพราะมีการแทรก/ลบจากทรานแซคชันอื่น\n\nสถานการณ์: การค้นหาห้องพักแสดง “มี 3 ห้อง” แล้วระหว่างจองระบบเช็กใหม่พบว่าไม่มีเพราะมีการจองเพิ่มเข้ามา\n\nผลต่อผู้ใช้: พยายามจองซ้ำ ข้อมูลสต็อกไม่สอดคล้อง หรือขายเกิน\n\n### ความผิดปกติในการเขียน (บั๊กจริงในโลกธุรกิจ)\n\nLost update เกิดเมื่อตรวจค่าเดียวกันและทั้งคู่เขียนอัปเดต โดยการเขียนทีหลังเขียนทับการเขียนก่อน\nสถานการณ์: สองแอดมินแก้ราคาสินค้าเดียวกัน ทั้งคู่เริ่มจาก $10; คนหนึ่งบันทึก $12 อีกคนบันทึก $11 ทีหลัง\n\nผลต่อผู้ใช้: การเปลี่ยนแปลงของคนหนึ่งหายไป totals และรายงานผิด \n\n เกิดเมื่อสองทรานแซคชันแต่ละอันทำการเปลี่ยนแปลงที่ถูกต้องเป็นรายบุคคล แต่รวมกันแล้วละเมิดกฎ\n\nสถานการณ์: กฎ: “ต้องมีแพทย์ on-call อย่างน้อยหนึ่งคน” สองแพทย์ต่างคนต่างลงชื่อออกหลังเช็กว่าอีกคนยัง on-call ทั้งคู่ผ่านการเช็ก แต่สุดท้ายไม่มีคนคุ้มครอง\n\nผลต่อผู้ใช้: เสียการดูแล แม้แต่ละทรานแซคชันจะ “ผ่าน” การตรวจสอบของตนเอง\n\n### ทำไมไม่ใช้ isolation ที่เข้มงวดที่สุดเสมอไป?\n\nIsolation ที่เข้มงวดกว่าจะลดความผิดพลาด แต่เพิ่มการรอ การ retry และต้นทุนภายใต้การทำงานพร้อมกันสูง ระบบหลายแห่งเลือก isolation ที่อ่อนกว่าในการอ่านเชิงวิเคราะห์ ในขณะที่ใช้การตั้งค่าที่เข้มงวดสำหรับการโอนเงิน การจอง และฟลูว์ที่ต้องถูกต้องสูง\n\n## ระดับ Isolation: เลือกระดับความปลอดภัยที่เหมาะสม\n\nIsolation เกี่ยวกับสิ่งที่ทรานแซคชันของคุณ “มองเห็น” ขณะที่คนอื่นทำงาน ฐานข้อมูลแสดงสิ่งนี้เป็น : ระดับสูงลดพฤติกรรมที่น่าประหลาดใจ แต่มีค่าใช้จ่ายต่อ throughput หรือความรอคอย\n\n### ระดับ isolation ที่พบบ่อย\n\n- : อาจอ่านการเปลี่ยนแปลงที่ยังไม่ commit (“dirty reads”) เกือบไม่มีอะไรถูกป้องกัน\n- : อ่านเฉพาะข้อมูลที่ commit แล้วเท่านั้น จึง ได้ แต่ถ้ารันคิวรีเดิมสองครั้งคุณอาจได้ผลต่างกันเพราะมีคนอื่น commit ระหว่างนั้น (“non-repeatable reads”)\n- : การอ่านที่คุณทำไว้แล้วจะคงที่ในทรานแซคชัน ดังนั้น ขึ้นกับ engine คุณอาจยังเห็น “phantom” หรือไม่ก็ได้\n- : ทรานแซคชันทำงานราวกับว่าถูกรันทีละรายการ นี่คือการตั้งค่าที่เข้มงวดที่สุด ปกติจะป้องกัน และลดความผิดปกติในการเขียนหลายอย่าง\n\n### เลือกระดับ: throughput vs ความถูกต้อง\n\nทีมมักเลือก เป็นค่าเริ่มต้นสำหรับแอปที่มี user-facing: ประสิทธิภาพดีและการไม่อ่านข้อมูลที่ยังไม่ commit ตรงกับความคาดหวังส่วนใหญ่\n\nใช้ เมื่อคุณต้องการผลลัพธ์คงที่ภายในทรานแซคชัน (เช่น สร้างใบแจ้งหนี้) และยอมรับต้นทุนเพิ่มได้\n\nใช้ เมื่อความถูกต้องสำคัญกว่าการทำพร้อมกัน (เช่น บังคับ invariant ซับซ้อนอย่าง “ไม่ขายเกิน”) หรือเมื่อคุณไม่สามารถคิดเงื่อนไขการแข่งได้ในโค้ดแอปง่ายๆ\n\n หายากในระบบ OLTP; บางครั้งใช้สำหรับมอนิเตอร์หรือรายงานประมาณการที่ยอมรับการอ่านผิดเป็นครั้งคราวได้\n\n### คำเตือนสำคัญ: พฤติกรรมแตกต่างกันไป\n\nชื่อต่างๆ ถูกมาตรฐานไว้ แต่ (และบางครั้งขึ้นกับการตั้งค่า) ยืนยันกับเอกสารของฐานข้อมูลและทดสอบความผิดปกติที่สำคัญต่อธุรกิจของคุณ\n\n## Durability: ทำให้การ commit ยึดติด\n\nDurability หมายความว่าทันทีที่ทรานแซคชัน ผลลัพธ์ควรจะรอดจากการล้มเหลว—ไฟดับ รีสตาร์ทโปรเซส หรือล้างเครื่อง หากแอปบอกลูกค้าว่า “ชำระเงินสำเร็จ” durability คือสัญญาว่าฐานข้อมูลจะไม่ “ลืม” เรื่องนั้นหลังเหตุล้มเหลว\n\n### ฐานข้อมูลทำให้ commit รอดพ้นจากการล้มเหลวอย่างไร\n\nฐานข้อมูลเชิงสัมพันธ์ส่วนใหญ่บรรลุ durability โดยใช้ โดยสรุปคือฐานข้อมูลจะเขียน “ใบเสร็จ” ลำดับการเปลี่ยนแปลงไปยังล็อกบนดิสก์ จะถือว่าทรานแซคชันเป็น commit ถ้าฐานข้อมูลล้มเหลว มันสามารถ replay ล็อกตอนสตาร์ทขึ้นมาเพื่อกู้คืนการเปลี่ยนแปลงที่ commit แล้ว\n\nเพื่อให้เวลาในการกู้คืนไม่ยาวเกินไป ฐานข้อมูลยังสร้าง จุดหนึ่งที่ฐานข้อมูลแน่ใจว่าการเปลี่ยนแปลงล่าสุดจำนวนมากถูกเขียนลงไฟล์ข้อมูลหลัก เพื่อให้การกู้คืนไม่จำเป็นต้อง replay ประวัติล็อกไม่จำกัด\n\n### Durability ขึ้นกับสตอเรจและการตั้งค่า\n\nDurability ไม่ใช่สวิตช์เปิดปิดเดียว; มันขึ้นกับความเข้มข้นในการบังคับให้ข้อมูลไปยังสตอเรจที่มั่นคง\n\n- ด้วยการตั้งค่า ฐานข้อมูลรอให้ล็อกถูก flush (มักผ่าน ) ก่อนจะยืนยัน commit ซึ่งปลอดภัยกว่าแต่เพิ่มความหน่วง\n- ด้วยการตั้งค่า ฐานข้อมูลอาจยืนยัน commit ก่อนที่ล็อกจะอยู่บนสตอเรจถาวร ประสิทธิภาพดีขึ้น แต่การล้มเหลวอาจทำให้สูญเสียทรานแซคชันที่เพิ่ง commit ได้\n\nฮาร์ดแวร์พื้นฐานก็สำคัญเช่นกัน: SSD, RAID controller ที่มี write cache และ volumes ในคลาวด์อาจทำงานต่างกันเมื่อเกิดความผิดพลาด\n\n### การสำรองข้อมูลและการจำลองข้อมูลเกี่ยวข้องแต่ต่างกัน\n\nการสำรองและ replication ช่วยให้คุณ หรือ แต่ไม่ใช่ตัวเดียวกับ durability ทรานแซคชันอาจ durable บน primary แม้มันยังไม่ถึง replica และ backup มักเป็น snapshot ตามช่วงเวลา ไม่ใช่การการันตีทีละ commit\n\n## ฐานข้อมูลบังคับ ACID อย่างไรเบื้องหลัง\n\nเมื่อคุณ ทรานแซคชันแล้วต่อมา ฐานข้อมูลจะประสานหลายส่วน: ใครอ่านแถวไหน ใครอัปเดต และจะเกิดอะไรขึ้นถ้าสองคนพยายามเปลี่ยนแถวเดียวกันพร้อมกัน\n\n### การควบคุมการแข่งขันแบบ pessimistic vs optimistic\n\nการเลือกสำคัญคือจะจัดการความขัดแย้งอย่างไร:\n\n- สมมติว่าความขัดแย้งน่าจะเกิด เมื่อทรานแซคชันอัปเดตแถว ฐานข้อมูล มันเพื่อให้ทรานแซคชันอื่นต้องรอ ป้องกันความผิดพลาดหลายอย่างแต่ทำให้เกิดการบล็อก\n- สมมติว่าความขัดแย้งน้อย ทรานแซคชันดำเนินไปโดยไม่ล็อกมาก และฐานข้อมูล ที่เวลาคอมมิต (หรือผ่านการเช็ก) และอาจปฏิเสธทรานแซคชันหนึ่งเพื่อให้ลองใหม่\n\nหลายระบบผสมทั้งสองแนวทางตามงานและระดับ isolation\n\n### MVCC: ผู้อ่านไม่ขัดขวางผู้เขียน\n\nฐานข้อมูลสมัยใหม่มักใช้ : แทนที่จะเก็บสำเนาแถวเดียว ฐานข้อมูลเก็บ \n\n- ผู้อ่านเห็น snapshot ที่สอดคล้องกัน (เวอร์ชันเก่า) โดยไม่ต้องรอ\n- ผู้เขียนสร้างเวอร์ชันใหม่ขณะที่การอ่านยังดำเนินอยู่\n\nนี่เป็นเหตุผลสำคัญว่าทำไมบางฐานข้อมูลจึงจัดการการอ่านและเขียนพร้อมกันได้ดีโดยไม่บล็อกมาก—แม้ว่าความขัดแย้งเขียน/เขียนยังต้องแก้ไขอยู่\n\n### Deadlocks: เมื่อการรอกันเป็นวงวน\n\nล็อกอาจนำไปสู่ : ทรานแซคชัน A รอล็อกที่ B ถืออยู่ ขณะที่ B รอล็อกที่ A ถืออยู่\n\nฐานข้อมูลมักแก้ปัญหานี้โดยตรวจจับวงจรและ (“deadlock victim”) แล้วส่งคืนข้อผิดพลาดเพื่อให้แอปลองใหม่\n\n### สัญญาณเชิงปฏิบัติที่บอกว่ามีปัญหา\n\nถ้าการบังคับ ACID สร้างแรงเสียดทาน คุณมักเห็น:\n\n- ตอน peak\n- (คิวรีล้มเหลวหลังรอนาน)\n- (ไม่กี่แถว/ตารางถูกอัปเดตบ่อย เช่น counters หรือฟิลด์ "last seen")\n\nอาการเหล่านี้มักหมายความว่าถึงเวลาต้องทบทวนขนาดทรานแซคชัน ดัชนี หรือกลยุทธ์ isolation/locking ที่เหมาะกับงาน\n\n## วิธีที่ ACID มีผลต่อการออกแบบแอปพลิเคชัน\n\nการการันตี ACID ไม่ใช่แค่ทฤษฎีฐานข้อมูล—มันมีผลต่อการออกแบบ API งานแบ็คกราวด์ และแม้กระทั่งการไหลของ UI แนวคิดหลักคือ: ตัดสินใจว่าสเต็ปไหนต้องสำเร็จพร้อมกัน แล้วห่อเฉพาะสเต็ปพวกนั้นในทรานแซคชัน\n\n### ออกแบบ API รอบ “การเปลี่ยนแปลงทางธุรกิจหนึ่งอย่าง”\n\nAPI ทรานแซคชันที่ดีมักแมปกับการกระทำทางธุรกิจเดียว แม้จะแตะหลายตารางก็ตาม ตัวอย่าง อาจ: สร้างคำสั่งซื้อ จองสต็อก และบันทึก payment intent การเขียนฐานข้อมูลเหล่านี้ควรอยู่ในทรานแซคชันเดียวกันเพื่อ commit พร้อมกัน (หรือ rollback พร้อมกัน) ถ้ามีการตรวจสอบล้มเหลว\n\nรูปแบบทั่วไปคือ:\n\n- ทำการตรวจสอบข้อมูลนำเข้า เปิดทรานแซคชัน\n- เปิดทรานแซคชัน\n- ทำการอ่าน/เขียนที่จำเป็นน้อยที่สุด\n- Commit\n\nวิธีนี้รักษา atomicity และ consistency ขณะหลีกเลี่ยงทรานแซคชันช้าและเปราะบาง\n\n### ขอบเขตทรานแซคชันในคำขอ บริการ และงาน\n\nที่วางขอบเขตทรานแซคชันขึ้นอยู่กับความหมายของ “หน่วยงานของงาน”:\n\n- เก็บทรานแซคชันให้สั้น—ไอเดียคือไม่กี่คิวรี หลีกเลี่ยงการถือล็อกขณะเรนเดอร์วิวหรือรอการตอบจากระบบภายนอก\n- ถือแต่ละการพยายามของงานเป็นหน่วยของงาน ถางงานประมวลผล 10,000 ระเบียน ให้ commit เป็นแบตช์เพื่อให้ restart ได้อย่างปลอดภัย\n- ควรเก็บทรานแซคชันไว้ภายในฐานข้อมูลของบริการเดียว ข้ามบริการมักต้องแนวทางอื่น (เช่น outbox) เพราะทรานแซคชัน ACID เดียวครอบคลุมหลายฐานข้อมูลได้ยาก\n\n### การจัดการข้อผิดพลาด: rollback, retry และการเล่นซ้ำอย่างปลอดภัย\n\nACID ช่วยได้ แต่แอปยังต้องจัดการความล้มเหลวอย่างถูกต้อง:\n\n- ถ้าขั้นตอนใดล้มเหลว ให้ยกเลิกทรานแซคชันเพื่อไม่ให้การอัปเดตบางส่วนรั่วไหล\n- serialization failures และ deadlocks เป็นเรื่องปกติภายใต้ concurrency การลองใหม่ทั้งทรานแซคชันมักเป็นวิธีแก้ที่ถูกต้อง\n- ถ้าคำขอถูกลองซ้ำ ควรสามารถเล่นซ้ำได้อย่างปลอดภัยโดยไม่คิดเงินหรือส่งของซ้ำ—ใช้ idempotency keys และข้อจำกัด unique\n\n### รูปแบบต่อต้านที่ควรหลีกเลี่ยง\n\nหลีกเลี่ยง และ (เช่น “ล็อกแถวตะกร้าแล้วรอการยืนยันจากผู้ใช้”) เหล่านี้เพิ่ม contention และทำให้เกิดปัญหา isolation ง่ายขึ้น\n\n### เมื่อเครื่องมือช่วยได้ (โดยไม่เปลี่ยนพื้นฐาน)\n\nถ้าคุณกำลังสร้างระบบทรานแซคชันอย่างรวดเร็ว ความเสี่ยงใหญ่ที่สุดไม่ใช่ “ไม่รู้ ACID” แต่คือการกระจายการกระทำทางธุรกิจหนึ่งอย่างไปยังหลาย endpoint งาน หรือหลายตารางโดยไม่มีขอบเขตทรานแซคชันชัดเจน\n\nแพลตฟอร์มอย่าง ช่วยให้คุณเดินเร็วขึ้นขณะยังออกแบบรอบ ACID: คุณอธิบายเวิร์กโฟลว์ (เช่น “checkout พร้อมจองสต็อกและ payment intent”) ในแชทแบบวางแผน สร้าง UI React พร้อมแบ็กเอนด์ Go + PostgreSQL และทำซ้ำด้วย snapshot/rollback ถ้าต้องเปลี่ยนสคีมา หรือขอบเขตทรานแซคชัน ค่าเทคนิคยังคงถูกบังคับโดยฐานข้อมูล คุณค่าคือเร่งเส้นทางจากการออกแบบที่ถูกต้องไปสู่การติดตั้งที่ใช้งานได้
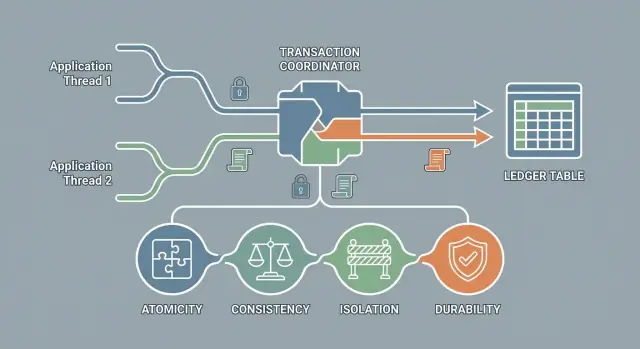
ACID คือชุดการการันตีของทรานแซคชันที่ช่วยให้ฐานข้อมูลทำงานคาดเดาได้ในกรณีล้มเหลวและการทำงานพร้อมกัน:
ทรานแซคชันคือ “หน่วยงานของงาน” หนึ่งหน่วยที่ฐานข้อมูลถือเป็นแพ็กเกจเดียว แม้ว่าจะมีหลายคำสั่ง SQL (เช่น สร้างคำสั่งซื้อ หักสต็อก บันทึก payment intent) ผลลัพธ์มีเพียงสองอย่างเท่านั้น:
การอัปเดตไม่สมบูรณ์สร้างความขัดแย้งในโลกจริงที่แก้ไขได้ยาก ตัวอย่างเช่น:
ACID (โดยเฉพาะ atomicity + consistency) ป้องกันสถานะ “ครึ่งทำเสร็จ” เหล่านี้ไม่ให้เป็นความจริงที่ปรากฏ
Atomicity ทำให้ฐานข้อมูลไม่เปิดเผยทรานแซคชันที่ “ทำเสร็จครึ่งทาง” ถ้าเกิดข้อผิดพลาดก่อน commit — เช่น แอป crash, การเชื่อมต่อเครือข่ายขาด, หรือ DB รีสตาร์ท — ระบบจะ rollback เพื่อไม่ให้ขั้นตอนก่อนหน้ารั่วไหลเข้าสู่สถานะถาวร
ในทางปฏิบัติ atomicity ทำให้การเปลี่ยนหลายขั้นตอน (เช่น การโอนเงินที่อัปเดตยอดสองบัญชี) ปลอดภัย
คุณอาจไม่แน่ใจว่าการ commit เกิดขึ้นหรือไม่ถ้าลูกค้าไม่ได้รับคำตอบ (เช่น การหมดเวลาเครือข่ายหลัง commit) ดังนั้นควรผสมผสาน ACID กับ:
วิธีนี้ป้องกันทั้งการอัปเดตครึ่งทางและการคิดเงินซ้ำ
ใน ACID “consistency” หมายความว่าทรานแซคชันต้องย้ายฐานข้อมูลจากสถานะที่ ถูกต้อง หนึ่งไปยังสถานะที่ถูกต้องอีกหนึ่ง ตามกฎที่คุณกำหนด—ข้อจำกัด, foreign keys, unique, หรือ check constraints
ถ้าคุณไม่เขียนกฎ (เช่น “ยอดบัญชีไม่ให้ติดลบ”) ACID จะไม่สามารถบังคับได้โดยอัตโนมัติ ฐานข้อมูลต้องมี invariant ที่ชัดเจนเพื่อคุ้มครอง
การตรวจสอบที่ฝั่งแอปช่วย UX และสามารถบังคับกฎธุรกิจซับซ้อนได้ แต่ไม่เพียงพอภายใต้การทำงานพร้อมกัน (concurrency)
ตัวอย่างคลาสสิก: แอปเช็กว่า “อีเมลว่าง” แล้วแทรกแถว; ภายใต้ concurrency สองคำขออาจผ่านการเช็กพร้อมกันได้ และ unique constraint ใน DB เป็นสิ่งที่รับประกันว่าแทรกได้แค่ครั้งเดียว
Isolation กำหนดสิ่งที่ทรานแซคชันของคุณสามารถมองเห็นขณะที่อื่นๆ กำลังรันอยู่ เมื่อ isolation อ่อนเกินไปจะเกิดความผิดปกติเหล่านี้:
ระดับ isolation ให้คุณแลกเปลี่ยนประสิทธิภาพกับการป้องกันปัญหาเหล่านี้
แนวทางปฏิบัติทั่วไปคือใช้ Read Committed เป็นค่าเริ่มต้นสำหรับแอป OLTP หลายๆ ตัว เพราะป้องกัน dirty reads และให้ประสิทธิภาพดี ขยับขึ้นไปเมื่อจำเป็น:
เสมอทดสอบกับ engine ของฐานข้อมูลจริง เพราะรายละเอียดแตกต่างกันได้
Durability คือการรับประกันว่าหลังจากทรานแซคชัน commit ผลลัพธ์จะยังคงอยู่หลังการล้มเหลว เช่น ไฟดับ รีบูต หรือกระบวนการหยุด ถ้าแอปบอกลูกค้าว่า “ชำระเงินสำเร็จ” durability คือสัญญาว่าฐานข้อมูลจะไม่ลืมเรื่องนี้หลังเหตุการณ์ล้มเหลว
โดยทั่วไป DB ใช้ write-ahead logging (WAL): เขียนบันทึกลำดับการเปลี่ยนแปลงลงดิสก์ก่อนถือเป็น commit แล้วสามารถ replay ระหว่างการกู้คืนได้ นอกจากนี้มี checkpoint เพื่อจำกัดเวลาการกู้คืนไม่ให้ยาวเกินไป
fsyncBEGINCOMMIT/checkout