09 ส.ค. 2568·4 นาที
การรั่วไหลของนามธรรมของเฟรมเวิร์กเมื่อระบบขยายตัว
เรียนรู้ว่าทำไมนามธรรมระดับสูงของเฟรมเวิร์กจึงพังเมื่อสเกลเพิ่มขึ้น รูปแบบการรั่วที่พบบ่อย อาการที่ควรจับตา และการแก้ทั้งเชิงออกแบบและปฏิบัติการ
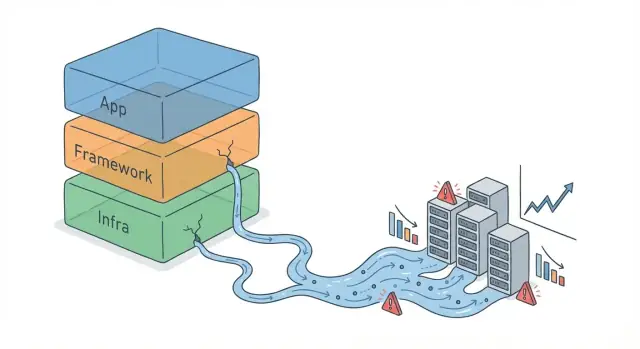
เรียนรู้ว่าทำไมนามธรรมระดับสูงของเฟรมเวิร์กจึงพังเมื่อสเกลเพิ่มขึ้น รูปแบบการรั่วที่พบบ่อย อาการที่ควรจับตา และการแก้ทั้งเชิงออกแบบและปฏิบัติการ
นามธรรมคือชั้นที่ทำให้สิ่งต่าง ๆ ง่ายขึ้น: API ของเฟรมเวิร์ก, ORM, client ของ message queue หรือแม้แต่ helper การแคชหนึ่งบรรทัด มันช่วยให้คุณคิดในแนวความหมายระดับสูง ("บันทึกอ็อบเจ็กต์นี้", "ส่งอีเวนต์นี้") โดยไม่ต้องจัดการกับกลไกระดับต่ำซ้ำแล้วซ้ำเล่า
การ รั่วไหลของนามธรรม เกิดเมื่อรายละเอียดที่ถูกซ่อนไว้เริ่มส่งผลต่อผลลัพธ์จริง—คุณถูกบังคับให้เข้าใจและจัดการสิ่งที่นามธรรมพยายามซ่อน รหัสยังคง “ทำงานได้” แต่โมเดลที่เรียบง่ายไม่สามารถทำนายพฤติกรรมจริงได้อีกต่อไป
การเติบโตในระยะแรกให้อภัยได้ ด้วยทราฟฟิกต่ำและชุดข้อมูลขนาดเล็ก ความไร้ประสิทธิภาพถูกซ่อนโดย CPU ที่เหลือ, แคชที่ว่าง, และคิวรีที่เร็ว การเกิดสไปก์ของหน่วงเวลาไม่บ่อย การ retry ไม่สะสม และการบันทึกที่เปลืองเล็กน้อยก็ไม่สำคัญ
เมื่อปริมาณเพิ่มขึ้น ช็อตคัตเดิมจะขยายผล:\n
นามธรรมที่รั่วมักแสดงผลในสามด้าน:\n
ต่อไปเราจะมุ่งไปที่สัญญาณเชิงปฏิบัติที่บอกว่านามธรรมกำลังรั่ว, วิธีวินิจฉัยสาเหตุพื้นฐาน (ไม่ใช่แค่ปรากฏการณ์), และตัวเลือกการลดความเสี่ยงตั้งแต่การปรับค่าไปจนถึงการ “ลดระดับ” ลงเมื่อนามธรรมไม่สอดคล้องกับสเกลของคุณอีกต่อไป
ซอฟต์แวร์จำนวนมากเดินตามเส้นทางเดียวกัน: ต้นแบบพิสูจน์ไอเดีย, สินค้าถูกส่งออก, แล้วการใช้งานเติบโตเร็วกว่าสถาปัตยกรรมเดิม ตอนแรกเฟรมเวิร์กรู้สึกเหมือนเวทมนตร์เพราะดีฟอลต์ช่วยให้คุณเคลื่อนที่เร็ว—routing, การเข้าถึงฐานข้อมูล, การบันทึก, retry และงานแบ็กกราวด์ได้มา “ฟรี”
เมื่อสเกล คุณยังต้องการประโยชน์เหล่านั้น—แต่ดีฟอลต์และ API ที่สะดวกเริ่มทำหน้าที่เป็นข้อสมมติฐาน
ดีฟอลต์ของเฟรมเวิร์กมักสมมติว่า:\n
สเกลไม่ใช่แค่ “ผู้ใช้มากขึ้น” แต่คือปริมาณข้อมูลที่สูงขึ้น, ทราฟฟิกกระแทก, และงานพร้อมกันที่มากขึ้น สิ่งเหล่านี้กดบนส่วนที่นามธรรมซ่อนไว้: connection pool, การจัดกำหนดเวลาเธรด, ความลึกคิว, แรงกดดันหน่วยความจำ, ขีดจำกัด I/O, และข้อจำกัดอัตราจากการพึ่งพา
เฟรมเวิร์กมักเลือกการตั้งค่าที่ปลอดภัยและทั่วไป (ขนาด pool, timeout, พฤติกรรม batching) ภายใต้โหลด การตั้งค่าเหล่านั้นอาจกลายเป็น contention, ความหน่วงหางยาว, และความล้มเหลวเป็นลูกโซ่—ปัญหาที่ไม่ปรากฏเมื่อทุกอย่างพอดีกับขอบเขต
สเตจจิ้งมักไม่สะท้อนเงื่อนไขจริงของโปรดักชัน: ชุดข้อมูลเล็กกว่า, บริการน้อยกว่า, พฤติกรรมแคชต่างกัน และกิจกรรมผู้ใช้ที่ไม่ “เรียบร้อย” ในโปรดักชันคุณยังเจอความแปรปรวนของเครือข่าย, noisy neighbors, การดีพลอยแบบหมุน และความล้มเหลวบางส่วน นั่นคือเหตุผลที่นามธรรมที่ดูแน่นหนาในการทดสอบอาจเริ่มรั่วเมื่อสภาวะแวดล้อมจริงกดดัน
เมื่อ abstraction ของเฟรมเวิร์กรั่ว อาการไม่ค่อยมาเป็นข้อความผิดพลาดที่ชัดเจน แต่เป็นรูปแบบ: พฤติกรรมที่ดีที่โหลดต่ำกลายเป็นไม่แน่นอนหรือมีค่าใช้จ่ายเพิ่มเมื่อปริมาณสูงขึ้น
นามธรรมที่รั่วมักประกาศตัวผ่านความหน่วงที่เห็นได้จากผู้ใช้:\n
นี่เป็นสัญญาณคลาสสิกว่ามีนอตที่นามธรรมซ่อนไว้ซึ่งคุณไม่สามารถปลดได้โดยไม่ลดระดับลง (เช่น ตรวจสอบคิวรีจริง, การใช้ connection, หรือพฤติกรรม I/O)
บางการรั่วปรากฏในใบแจ้งหนี้ก่อนในแดชบอร์ด:\n
ถ้าการเพิ่มโครงสร้างพื้นฐานไม่คืนประสิทธิภาพเป็นสัดส่วน มักไม่ใช่แค่กำลังดิบ แต่เป็นโอเวอร์เฮดที่คุณไม่รู้ว่าต้องจ่าย
การรั่วกลายเป็นปัญหาความน่าเชื่อถือเมื่อมันปฏิสัมพันธ์กับ retry และโซ่ของ dependency:\n
ใช้สิ่งนี้เพื่อตรวจสอบก่อนซื้อความจุเพิ่ม:\n
ถ้าอาการรวมตัวกันที่ dependency ใด dependency หนึ่งและไม่ตอบสนองอย่างคาดเดื่อนได้ต่อการเพิ่ม "เซิร์ฟเวอร์มากขึ้น" นั่นเป็นสัญญาณชัดว่าคุณต้องมองลึกลงไปใต้ชั้นนามธรรม
ORM ดีในการตัดบรรทัดโค้ดที่น่าเบื่อ แต่ก็ทำให้ลืมได้ง่ายว่าทุกอ็อบเจ็กต์ในท้ายที่สุดจะกลายเป็นคิวรี SQL ในสเกลเล็กการแลกเปลี่ยนนี้แทบไม่เห็น แต่เมื่อปริมาณสูง ฐานข้อมูลมักเป็นที่แรกที่นามธรรมที่ดูสะอาดเริ่มคิดดอกเบี้ย
N+1 เกิดเมื่อคุณโหลดลิสต์ของเรกคอร์ดพาเรนท์ (1 คิวรี) แล้วข้างในลูปโหลดเรกคอร์ดที่สัมพันธ์กับแต่ละพาเรนท์ (อีก N คิวรี) ในการทดสอบท้องถิ่นมันดูโอเค—อาจเป็น N=20 ในโปรดักชัน N กลายเป็น 2,000 และแอปของคุณแปลงคำขอหนึ่งเป็นหลายพันรอบเดินทาง
ส่วนที่ยุ่งยากคือไม่มีอะไร “พัง” ทันที; ความหน่วงค่อย ๆ เพิ่ม, connection pool เต็ม, และ retry ขยายโหลด
นามธรรมมักสนับสนุนการดึงอ็อบเจ็กต์เต็มโดยดีฟอลต์ แม้ว่าคุณต้องการแค่สองฟิลด์ นั่นเพิ่ม I/O หน่วยความจำ และการถ่ายโอนเครือข่าย
ในเวลาเดียวกัน ORM อาจสร้างคิวรีที่ข้ามดัชนีที่คุณคิดว่าจะถูกใช้ (หรือดัชนีนั้นไม่มีอยู่) ดัชนีที่ขาดเพียงอันเดียวสามารถเปลี่ยน lookup ให้เป็น table scan ได้
การ join เป็นต้นทุนที่ซ่อนอีกอย่าง: สิ่งที่ดูเหมือน "รวม relation" อาจกลายเป็นคิวรีหลาย join ที่มีผลลัพธ์กลางขนาดใหญ่
ภายใต้โหลด การเชื่อมต่อฐานข้อมูลเป็นทรัพยากรที่หายาก หากแต่ละคำขอขยายเป็นหลายคิวรี pool จะถึงขีดจำกัดเร็วและแอปของคุณเริ่มคิวงาน
ทรานแซกชันยาว (บางครั้งโดยไม่ได้ตั้งใจ) ยังทำให้เกิด contention—ล็อกอยู่ได้นานขึ้น และการขนานลดลง
EXPLAIN และถือว่าดัชนีเป็นส่วนหนึ่งของการออกแบบแอป ไม่ใช่หน้าที่ของ DBA ทีหลังการขนานงานคือที่ที่นามธรรมสามารถดู "ปลอดภัย" ในการพัฒนาแล้วล้มเหลวดังในโหลดจริง โมเดลดีฟอลต์ของเฟรมเวิร์กมักซ่อนข้อจำกัดจริง: คุณไม่ได้แค่ให้บริการคำขอ—คุณกำลังจัดการ contention สำหรับ CPU, เธรด, socket และความจุของ downstream
Thread-per-request (พบบ่อยในเว็บสแตกคลาสสิก) ง่าย: แต่ละคำขอได้เธรดงาน มันล้มเมื่อ I/O ช้าทำให้เธรดกองพะเนิน เมื่อ pool เธรดหมด คำขอใหม่จะคิว, ความหน่วงพุ่ง, และในที่สุดเกิด timeout—ในขณะที่เซิร์ฟเวอร์ยัง “ยุ่ง” แต่แท้จริงแล้วรอ
Async/event-loop จัดการคำขอจำนวนมากด้วยเธรดน้อย จึงดีในความขนานสูง แต่มันล้มต่างออกไป: การเรียกบล็อกตัวเดียว (ไลบรารี synchronous, การ parse JSON ช้า, การบันทึกหนัก) สามารถทำให้ event loop ติดขัด เปลี่ยน "คำขอช้าหนึ่งคำขอ" เป็น "ทุกอย่างช้า" Async ยังทำให้ง่ายต่อการสร้างการขนานมากเกินไป ทำให้ท่วม dependency ได้เร็วกว่าขีดจำกัดเธรด
Backpressure คือระบบบอกผู้เรียกว่า "ชะลอ; ฉันรับไม่ได้อีก" หากขาดมัน dependency ที่ช้าจะไม่เพียงทำให้การตอบช้า แต่จะเพิ่มงานที่กำลังดำเนินอยู่, การใช้หน่วยความจำ, และความยาวคิว งานที่เพิ่มขึ้นนี้ทำให้ dependency ช้าลงยิ่งขึ้น ทำให้เกิดวงจรป้อนกลับ
ต้องมีการตั้ง timeout อย่างชัดเจนและเป็นชั้น: client, service, และ dependency หาก timeout ยาวเกิน คิวจะโตและการฟื้นตัวช้าลง หาก retry อัตโนมัติรุนแรง คุณอาจกระตุ้น พายุ retry: dependency ช้าลง, คอล timeout, ผู้เรียก retry, โหลดเพิ่ม, และ dependency ยุบ
เฟรมเวิร์กทำให้การเรียกเครือข่ายดูเหมือน "แค่เรียก endpoint" ภายใต้โหลด นามธรรมมักรั่วผ่านงานที่มิดเดิลแวร์ทำอยู่เบื้องหลัง, การซีเรียไลซ์, และการจัดการเพย์โหลด
แต่ละชั้น—API gateway, auth middleware, rate limiting, การตรวจสอบคำขอ, observability hooks, retry—เพิ่มเวลาเล็กน้อย มิลลิวินาทีนึงไม่ค่อยมีผลในการพัฒนา แต่ที่สเกล มิดเดิลแวร์หลายชั้นสามารถเปลี่ยนคำขอ 20 ms ให้กลายเป็น 60–100 ms โดยเฉพาะเมื่อคิวเกิด
จุดสำคัญคือความหน่วงไม่ได้แค่บวก มันขยาย: ความล่าช้าเล็กน้อยเพิ่มการขนาน (คำขอที่กำลังดำเนินอยู่มากขึ้น) ซึ่งเพิ่ม contention (thread pool, connection pool) ซึ่งเพิ่มความล่าช้าอีกครั้ง
JSON สะดวก แต่การเข้ารหัส/ถอดรหัสเพย์โหลดขนาดใหญ่สามารถโดมินเนต CPU การรั่วปรากฏเป็นความช้า “เครือข่าย” ที่แท้จริงคือเวลา CPU ของแอป รวมถึงการกระทบหน่วยความจำจากบัฟเฟอร์
เพย์โหลดใหญ่ชะลอทุกอย่างรอบตัว:\n
เฮดเดอร์สามารถบวมคำขออย่างเงียบ ๆ (คุกกี้, token ยืนยันตัวตน, tracing headers) ขนาดบวมนี้ถูกคูณกับทุกการเรียกและทุกฮอป
การบีบอัดเป็นการแลกเปลี่ยน: ประหยัดแบนด์วิดท์แต่ใช้ CPU และอาจเพิ่มความหน่วง—โดยเฉพาะเมื่อบีบอัดเพย์โหลดเล็ก ๆ หรือบีบอัดซ้ำผ่านพร็อกซีหลายชั้น
สุดท้าย การสตรีมกับการบัฟเฟอร์สำคัญ หลายเฟรมเวิร์กบัฟเฟอร์บอดี้ทั้งก้อนโดยดีฟอลต์ (เพื่อรองรับ retry, logging, หรือคำนวณ content-length) สะดวก แต่ที่ปริมาณสูงมันเพิ่มการใช้หน่วยความจำและสร้าง head-of-line blocking การสตรีมช่วยให้หน่วยความจำคาดเดาได้และลดเวลาไปถึงไบต์แรก แต่ต้องจัดการข้อผิดพลาดอย่างระมัดระวัง
ถือขนาดเพย์โหลดและความลึกมิดเดิลแวร์เป็นงบประมาณ ไม่ใช่เรื่องย่อย:\n
การแคชมักถูกมองว่าเป็นสวิตช์ง่าย: ใส่ Redis (หรือ CDN), ความหน่วงลด, แล้วจบ ในโหลดจริง การแคชเป็นนามธรรมที่รั่วได้อย่างรุนแรง—เพราะมันเปลี่ยนที่ที่งานเกิดขึ้น, เวลาเกิดงาน, และวิธีที่ความล้มเหลวแพร่กระจาย
แคชเพิ่มฮอปเครือข่าย, การซีเรียไลซ์, และความซับซ้อนเชิงปฏิบัติการ มันยังนำแหล่งความจริงที่สองที่อาจล้าสมัย ถูกเติมไม่เต็ม หรือไม่พร้อมใช้งาน เมื่อสิ่งผิดพลาด ระบบไม่ได้แค่ช้าลง—มันอาจมีพฤติกรรมต่างกัน (ให้ข้อมูลเก่า, ขยายการ retry, หรือท่วมฐานข้อมูล)
Cache stampedes เกิดเมื่อหลายคำขอพลาดแคชพร้อมกัน (มักหลังการหมดอายุ) และรีบไปสร้างค่าตัวเดียวกันใหม่พร้อมกัน ที่สเกล อัตราการ miss เล็ก ๆ อาจกลายเป็นสไปก์ฐานข้อมูล
การออกแบบคีย์ที่ไม่ดี เป็นอีกปัญหาเงียบ: หากคีย์กว้างเกินไป (เช่น user:feed โดยไม่รวมพารามิเตอร์) คุณอาจให้ข้อมูลผิด หากคีย์เฉพาะเกินไป (รวม timestamp, ID แบบสุ่ม, หรือพารามิเตอร์ที่ไม่มีลำดับ) คุณจะได้อัตราการโดนใกล้ศูนย์และจ่ายโอเวอร์เฮดฟรี
การ invalidation คือตำแหน่งหักมุม: การอัปเดตฐานข้อมูลง่าย แต่การรับประกันว่า view แคชทุกอันถูกรีเฟรชไม่ง่าย ข้อบกพร่องจากการ invalidation เป็นสาเหตุของบั๊ก "สำหรับฉันมันแก้แล้ว" และการอ่านที่ไม่สอดคล้อง
ทราฟฟิกจริงไม่กระจายเท่ากัน โปรไฟล์คนดัง, สินค้ายอดนิยม, หรือตอน config ร่วมอาจกลายเป็น hot key รวมทราฟฟิกไว้ที่คีย์เดียวและ backing store ของมัน ถึงแม้อัตราเฉลี่ยจะดูโอเค แต่ความหน่วงหางและแรงกดดันระดับโหนดอาจพุ่ง
เฟรมเวิร์กมักทำให้หน่วยความจำรู้สึกว่า “จัดการได้” ซึ่งสบายใจ—จนกว่าทราฟฟิกจะเพิ่มและความหน่วงเริ่มพุ่งในแบบที่ไม่สอดคล้องกับกราฟ CPU ค่าเริ่มต้นหลายอย่างถูกปรับมาสำหรับความสะดวกของนักพัฒนา ไม่ใช่สำหรับกระบวนการที่รันยาวภายใต้โหลดต่อเนื่อง
เฟรมเวิร์กระดับสูงมักจัดสรรอ็อบเจ็กต์ชั่วคราวต่อคำขอ: wrapper คำขอ/การตอบ, context middleware, ต้นไม้ JSON, regex matchers, และสตริงชั่วคราว ทีละอันเล็ก ๆ แต่ที่สเกลมันสร้างแรงกดดันการจัดสรรต่อเนื่อง บังคับ runtime ให้รัน GC บ่อยขึ้น
การหยุดชั่วคราวของ GC อาจปรากฏเป็นสไปก์ความหน่วงสั้น ๆ แต่บ่อยๆ ขณะที่ heap โต การหยุดมักยาวขึ้น—ไม่จำเป็นต้องเพราะคุณรั่ว แต่เพราะ runtime ต้องใช้เวลามากขึ้นในการสแกนและจัดเรียงหน่วยความจำ
ภายใต้โหลด บริการอาจโปรโมตอ็อบเจ็กต์ไปยัง generation เก่า (หรือบริเวณที่เก็บยาว) เพียงเพราะมันรอดจากรอบ GC สองสามรอบขณะรอในคิว, บัฟเฟอร์, pool หรือคำขอที่กำลังดำเนิน นี่อาจบวม heap แม้แอปจะ “ถูกต้อง”\n การแตกสลายของพื้นที่ (fragmentation) เป็นต้นทุนที่ซ่อนอีกอย่าง: หน่วยความจำอาจว่างแต่ไม่สามารถใช้ซ้ำสำหรับขนาดที่ต้องการ ทำให้กระบวนการขอพื้นที่จาก OS เพิ่ม
การรั่วจริงคือการเติบโตที่ไม่จำกัด: หน่วยความจำขึ้นต่อเนื่อง ไม่ลงมา และในที่สุดทำให้ OOM หรือ GC thrash อย่างรุนแรง การใช้หน่วยความจำสูงแต่คงที่ต่างกัน: หน่วยความจำขึ้นจนคงที่หลังการอุ่นระบบ แล้วคงที่ประมาณหนึ่ง
เริ่มด้วยการโปรไฟล์ (heap snapshots, allocation flame graphs) เพื่อหาเส้นทางการจัดสรรที่ร้อนและอ็อบเจ็กต์ที่ถูกเก็บ\n ระวังการใช้ pooling: ช่วยลดการจัดสรรได้ แต่ pool ที่ตั้งค่าผิดอาจตรึงหน่วยความจำและทำให้ fragmentation แย่ลง เลือกลดการจัดสรรก่อน (สตรีมแทนบัฟเฟอร์, หลีกเลี่ยงการสร้างอ็อบเจ็กต์ไม่จำเป็น, จำกัดแคชต่อคำขอ) แล้วค่อยเพิ่ม pooling เมื่อการวัดแสดงผลชัดเจน
เครื่องมือ observability มักดู "ฟรี" เพราะเฟรมเวิร์กให้ดีฟอลต์ที่สะดวก: log ต่อคำขอ, metrics อัตโนมัติ, และ tracing แบบ one-line ภายใต้ทราฟฟิกจริง ดีฟอลต์เหล่านั้นอาจกลายเป็นส่วนหนึ่งของงานที่คุณพยายามสังเกต
การบันทึกต่อคำขอเป็นตัวอย่างคลาสสิก หนึ่งบรรทัดต่อคำขอดูไม่เป็นไร—จนกระทั่งคุณมีคำขอหลายพันต่อวินาที แล้วคุณต้องจ่ายค่าการฟอร์แมตสตริง, การเข้ารหัส JSON, การเขียนลงดิสก์หรือเครือข่าย และการ ingest ลง backend การรั่วปรากฏเป็นความหน่วงหาง, การพุ่งของ CPU, ท่อ log ที่ตามไม่ทัน, และบางครั้งคำขอ timeout เพราะการ flush log แบบ synchronous
Metrics อาจโอเวอร์โหลดระบบแบบเงียบ ๆ counters และ histogram ถูกใจเมื่อมีจำนวน time series น้อย แต่เฟรมเวิร์กมักกระตุ้นให้เพิ่ม tag/label อย่าง user_id, email, path, หรือ order_id นำไปสู่การระเบิดของ cardinality: แทนที่จะเป็น metric เดียว คุณสร้างซีรีส์เอกลักษณ์เป็นล้าน ผลคือหน่วยความจำไคลเอนท์ metric และ backend พอง, การค้นหาแดชบอร์ดช้าลง, ตัวอย่างถูกทิ้ง, และบิลที่เซอร์ไพรส์
การ tracing กระจายเพิ่มภาระเก็บและคำนวณที่โตตามทราฟฟิกและจำนวน span ต่อคำขอ หากคุณ trace ทุกอย่างโดยดีฟอลต์ คุณอาจจ่ายสองครั้ง: ครั้งแรกในโอเวอร์เฮดแอป (สร้าง span, แพร่ context) และครั้งที่สองใน backend ของ tracing (ingest, index, retention)
Sampling คือวิธีทีมคืนการควบคุม—แต่ง่ายที่จะทำผิด การ sample มากเกินไปจะซ่อนความล้มเหลวหายาก; sampling น้อยเกินไปทำให้ tracing มีค่าใช้จ่ายสูง วิธีปฏิบัติได้คือ sample มากขึ้นสำหรับข้อผิดพลาดและคำขอที่ความหน่วงสูง และน้อยลงสำหรับพาธที่เร็วและสุขภาพดี
หากคุณต้องการฐานว่าควรเก็บอะไร (และควรหลีกเลี่ยงอะไร) ดู /blog/observability-basics.
ปฏิบัติต่อ observability เป็นทราฟฟิกโปรดักชัน: ตั้งงบ (ปริมาณ log, จำนวนซีรีส์ metric, การ ingest trace), ทบทวน tags สำหรับความเสี่ยง cardinality, และทดสอบโหลดโดยเปิด instrumentation เป้าหมายไม่ใช่ "ลด observability" แต่เป็น observability ที่ยังใช้งานได้เมื่อระบบอยู่ภายใต้แรงกดดัน
เฟรมเวิร์กมักทำให้การเรียกบริการอื่นดูเหมือนเรียกฟังก์ชันในเครื่อง: userService.getUser(id) คืนค่าเร็ว, ข้อผิดพลาดเป็น "แค่ exceptions", และ retry ดูไร้พิษภัย ในสเกลเล็กภาพลวงตานั้นยังใช้ได้ แต่ที่สเกลใหญ่ นามธรรมรั่วเพราะการเรียกแบบ "เรียบง่าย" แต่ละครั้งมีการผูกมัดที่ซ่อนอยู่: ความหน่วง, ขีดจำกัดความจุ, ความล้มเหลวบางส่วน, และการไม่ตรงกันของเวอร์ชัน
การเรียกรีโมทผูกสองทีมเข้าด้วยกันในรอบการปล่อย, โมเดลข้อมูล, และเวลาพร้อมใช้งาน หาก Service A สมมติว่า Service B พร้อมใช้งานและเร็ว พฤติกรรมของ A ไม่ถูกกำหนดด้วยโค้ดของมันเองอีกต่อไป—แต่ถูกกำหนดโดยวันที่แย่ที่สุดของ B นี่คือวิธีที่ระบบกลายเป็นผูกมัดแน่นแม้โค้ดจะดูโมดูลาร์
ธุรกรรมกระจายเป็นกับดักทั่วไป: สิ่งที่ดูเหมือน "บันทึกผู้ใช้ แล้วเรียกเก็บเงิน" กลายเป็นเวิร์กโฟลว์หลายขั้นตอนข้ามฐานข้อมูลและบริการ two-phase commit แทบไม่ง่ายในโปรดักชัน หลายระบบจึงเปลี่ยนเป็น eventual consistency (เช่น "การชำระเงินจะยืนยันภายหลัง") การเปลี่ยนนี้บังคับให้คุณออกแบบเพื่อรองรับ retry, ผลซ้ำ, และอีเวนต์ที่มาจำหน่าย
Idempotency สำคัญมาก: หากคำขอถูก retry เพราะ timeout มันต้องไม่สร้างการเรียกเก็บเงินซ้ำหรือการจัดส่งซ้ำ ตัวช่วย retry ของเฟรมเวิร์กสามารถขยายปัญหา เว้นแต่ endpoint ของคุณจะปลอดภัยต่อการทำซ้ำอย่างชัดเจน
Dependency ช้าหนึ่งตัวสามารถกินเธรด pool, connection pool, หรือคิวจนหมด ทำให้ผลกระทบเป็นลูกโซ่: timeout กระตุ้น retry, retry เพิ่มโหลด, และในไม่ช้าจุดที่ไม่เกี่ยวข้องจะเสื่อมลง การ "เพิ่มอินสแตนซ์" อาจทำให้พายุแย่ลงหากทุกคน retry พร้อมกัน
กำหนดสัญญาชัดเจน (schema, รหัสข้อผิดพลาด, และการเวอร์ชัน), ตั้ง timeout และงบต่อการเรียกแต่ละครั้ง, และใช้ fallback (อ่านจากแคช, ตอบแบบ degrade) เมื่อเหมาะสม
สุดท้าย ตั้ง SLO สำหรับแต่ละ dependency และบังคับใช้: หาก Service B ทำ SLO ไม่ได้, Service A ควร fail fast หรือ degrade อย่างชัดเจน แทนที่จะลากทั้งระบบลงอย่างเงียบ ๆ
เมื่อ abstraction รั่วที่สเกล มันมักปรากฏเป็นอาการคลุมเครือ (timeout, CPU พุ่ง, คิวรีช้า) ที่ยั่วให้ทีมรีไรท์เร็วเกินไป วิธีที่ดีกว่าคือเปลี่ยนความสงสัยให้เป็นหลักฐาน
1) ทำให้เกิดซ้ำ (reproduce). \nจับสถานการณ์เล็กสุดที่ยังทริกเกอร์ปัญหา: endpoint, งานแบ็กกราวด์, หรือฟลูว์ผู้ใช้ ทำให้เกิดซ้ำในเครื่องหรือสเตจจิ้งด้วยการตั้งค่าที่คล้ายโปรดักชัน (feature flags, timeout, connection pool)\n 2) วัด (pick two or three signals). \nเลือกเมตริกไม่กี่อย่างที่บอกได้ว่า เวลาและทรัพยากรถูกใช้ที่ไหน: p95/p99 latency, อัตราข้อผิดพลาด, CPU, memory, เวลา GC, เวลา query DB, ความลึกคิว หลีกเลี่ยงการเพิ่มกราฟจำนวนมากในระหว่าง incident\n 3) แยกตัวปัญหา (isolate). \nใช้เครื่องมือเพื่อแยก "โอเวอร์เฮดของเฟรมเวิร์ก" ออกจาก "โค้ดของคุณ":\n
ใช้ ขนาดข้อมูลจริง (จำนวนแถว, ขนาดเพย์โหลด) และ การขนานที่สมจริง (บัสท์, หางยาว, ไคลเอนต์ช้า) หลายการรั่วปรากฏเมื่อแคชเย็น, ตารางใหญ่, หรือ retry ขยายโหลด
การรั่วของนามธรรมไม่ใช่ความล้มเหลวทางศีลธรรมของเฟรมเวิร์ก—แต่เป็นสัญญาณว่าความต้องการของระบบของคุณโตเกินเส้นทางดีฟอลต์ เป้าหมายไม่ใช่ทิ้งเฟรมเวิร์ก แต่ต้องตั้งใจว่าจะปรับมันเมื่อไหร่และจะข้ามมันเมื่อใด
อยู่ในเฟรมเวิร์กเมื่อปัญหาเป็นเรื่องการตั้งค่าหรือการใช้งาน มากกว่าความไม่เข้ากันเชิงพื้นฐาน ตัวอย่างที่เหมาะ:\n
เฟรมเวิร์กที่โตแล้วมักมีวิธีออกจากนามธรรมโดยไม่ต้องรีไรท์ทั้งระบบ รูปแบบทั่วไป:\n
นี่ช่วยให้เฟรมเวิร์กเป็นเครื่องมือ ไม่ใช่การพึ่งพาที่กำหนดสถาปัตยกรรม
การลดความเสี่ยงเป็นเรื่องปฏิบัติมากเท่ากับโค้ด:\n
ลดระดับเมื่อ (1) ปัญหาอยู่บนเส้นทางวิกฤต, (2) คุณวัดผลชนะได้, และ (3) การเปลี่ยนแปลงไม่สร้างภาระการบำรุงรักษาระยะยาวที่ทีมรับไม่ได้ หากมีเพียงคนเดียวที่เข้าใจการบายพาส นั่นไม่ใช่การแก้—มันเปราะบาง
เมื่อคุณล่าการรั่ว ความเร็วสำคัญ—แต่การทำให้การเปลี่ยนแปลงย้อนกลับได้ก็สำคัญ ทีมมักใช้ Koder.ai เพื่อสร้างการทำซ้ำปัญหาโปรดักชันขนาดเล็กอย่างรวดเร็ว (UI React เล็ก ๆ, เซอร์วิส Go, สคีมาฐานข้อมูล PostgreSQL, และ harness ทดสอบโหลด) โดยไม่ต้องเสียเวลาสร้างโครงรากหลุม days โหมด planning ช่วยบันทึกสิ่งที่คุณกำลังเปลี่ยนและทำไม ในขณะที่ snapshots และ rollback ทำให้ปลอดภัยในการลองทดลองแบบ “ลดระดับ” (เช่นสลับคิวรี ORM หนึ่งคำสั่งเป็น raw SQL) แล้วย้อนกลับอย่างสะดวกถ้าข้อมูลไม่สนับสนุน
ถ้าคุณทำงานนี้ข้ามสภาพแวดล้อม Koder.ai มีการดีพลอย/โฮสติ้งในตัวและการส่งออกซอร์สโค้ดที่ช่วยเก็บหลักฐานการวินิจฉัย (benchmark, repro app, dashboard ภายใน) เป็นซอฟต์แวร์จริงที่มีเวอร์ชัน แบ่งปันได้ และไม่ติดอยู่ในโฟลเดอร์เครื่องใครคนใดคนหนึ่ง
เลเยอร์ที่รั่วคือชั้นที่พยายามซ่อนความซับซ้อนไว้ (เช่น ORM, ตัวช่วย retry, wrapper ของการแคช, middleware) แต่เมื่อโหลดเพิ่มขึ้น รายละเอียดที่ถูกซ่อนไว้กลับไปเปลี่ยนผลลัพธ์จริง
ในทางปฏิบัติ นั่นหมายถึงโมเดลเชิงความคิดที่เรียบง่ายของคุณไม่สามารถทำนายพฤติกรรมจริงได้อีกต่อไป และคุณต้องเข้าใจเรื่องเช่น แผนการคิวรี (query plans), connection pool, ความลึกของคิว, GC, ระยะเวลา timeout และการ retry
ระบบช่วงเริ่มต้นมักมีทรัพยากรเหลือ: ตารางเล็ก ๆ, การขนานต่ำ, แคชที่อุ่นอยู่แล้ว และปฏิสัมพันธ์ของความล้มเหลวน้อย
เมื่อปริมาณเพิ่มขึ้น ค่าใช้จ่ายเล็ก ๆ จะกลายเป็นคอยล์คอยสะสม และขอบเขตข้อยกเว้นที่เคยเกิดขึ้นเป็นครั้งคราวจะกลายเป็นเรื่องปกติ นั่นคือช่วงที่ต้นทุนและข้อจำกัดที่ถูกซ่อนโดยนามธรรมเริ่มปรากฏในพฤติกรรมของโปรดักชัน
มองหาลักษณะที่ไม่ดีขึ้นอย่างคาดเดาได้เมื่อคุณเพิ่มทรัพยากร:
การเพิ่มทรัพยากรมักจะทำให้ระบบตอบสนองขึ้นแบบ เชิงเส้น หากเป็นปัญหา underprovisioning
สัญญาณของการรั่วมักเป็น:
ใช้เช็คลิสต์จากบทความ: หากการเพิ่มทรัพยากรสองเท่าไม่แก้ปัญหาเป็นสัดส่วน ให้สงสัยการรั่ว
ORM ซ่อนว่าการดำเนินการกับอ็อบเจ็กต์จะกลายเป็น SQL ในที่สุด ปัญหาทั่วไปได้แก่:
เริ่มแก้ด้วย eager loading อย่างรอบคอบ, เลือกคอลัมน์ที่ต้องการเท่านั้น, pagination, การทำงานเป็นกลุ่ม (batch) และตรวจสอบ SQL ที่ ORM สร้างด้วย EXPLAIN
Connection pool จำกัดการขนานงานเพื่อปกป้อง DB แต่การกระจายคิวรีที่ซ่อนอยู่สามารถทำให้ pool หมดได้
เมื่อ pool เต็ม คำขอจะรอในแอป เพิ่มความหน่วงและยืดเวลาทรานแซกชันที่ล็อกทรัพยากร
การแก้ปัญหาเชิงปฏิบัติ:
Thread-per-request ล้มเหลวเมื่ I/O ช้าเพราะหมดเธรด ทุกอย่างติดคิวและเกิด timeout
async/event-loop ล้มเหลวเมื่อมีการเรียกแบบบล็อกที่ทำให้ loop หยุดหรือเมื่อสร้างการขนานงานมากเกินไปจนท่วม dependencies
ทั้งสองแบบทำให้นามธรรมเรื่องการจัดการ concurrency รั่วเข้าสู่ความจำเป็นในการกำหนดขอบเขต, timeout และ backpressure
Backpressure คือกลไกที่บอกผู้เรียกว่า “ชะลอความเร็ว” เมื่อตัวประกอบรับงานไม่ไหว
หากไม่มี backpressure, dependency ที่ช้าจะเพิ่มคำขอที่กำลังดำเนินอยู่, การใช้หน่วยความจำ และความยาวของคิว—ทำให้ dependency ช้าลงยิ่งขึ้น (วงจรป้อนกลับ)
เครื่องมือที่ใช้บ่อย:
การ retry อัตโนมัติสามารถเปลี่ยนการชะลอเป็นการล่มได้:
บรรเทาด้วย:
การสังเกตการณ์ทำงานจริงเมื่อมีทราฟฟิกสูง:
user_id, email) ทำให้จำนวน time series ระเบิดและค่าใช้จ่ายเพิ่มการควบคุมเชิงปฏิบัติ: