18 ก.ค. 2568·4 นาที
วิธีที่ Observability และบันทึกคำสั่งช้าปกป้องโปรดักชัน
เรียนรู้ว่า observability และบันทึกคำสั่งช้าช่วยตรวจจับ วินิจฉัย และป้องกันการล่มในโปรดักชันอย่างไร พร้อมขั้นตอนปฏิบัติในการติดตั้งเตือน และปรับจูนคำสั่งอย่างปลอดภัย
เรียนรู้ว่า observability และบันทึกคำสั่งช้าช่วยตรวจจับ วินิจฉัย และป้องกันการล่มในโปรดักชันอย่างไร พร้อมขั้นตอนปฏิบัติในการติดตั้งเตือน และปรับจูนคำสั่งอย่างปลอดภัย
โปรดักชันไม่ค่อย “พัง” ในชั่วพริบตา มักจะเสื่อมลงอย่างเงียบ ๆ: บางคำขอเริ่มหมดเวลา งาน background ตกหล่น CPU เพิ่มขึ้นเรื่อย ๆ และลูกค้าเป็นคนแรกที่สังเกต—เพราะมอนิเตอร์ของคุณยังแสดงว่า “ทุกอย่างเป็นปกติ”.
รายงานจากผู้ใช้มักคลุมเครือ: “รู้สึกช้า” นั่นเป็นอาการที่อาจมาจากสาเหตุรากหลายอย่าง—การแย่งล็อกในฐานข้อมูล, แผนคิวรีใหม่, ขาดดัชนี, เพื่อนบ้านที่ใช้ทรัพยากรมาก, พายุการ retry, หรือการขึ้นต่อภายนอกที่ล้มเหลวเป็นพัก ๆ
ถ้าไม่มีการมองเห็นที่ดี ทีมมักเดา:\n
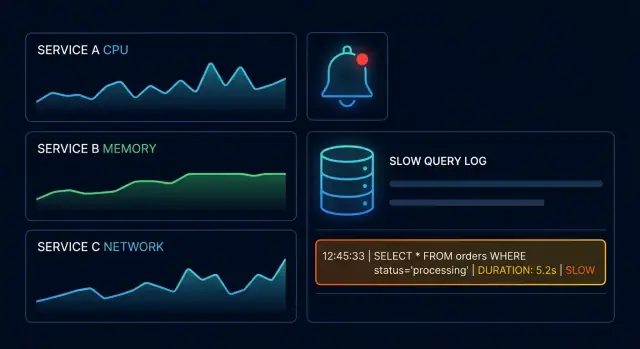
ทีมหลายแห่งติดตามค่าเฉลี่ย (latency เฉลี่ย, CPU เฉลี่ย) ค่าเฉลี่ยซ่อนความเจ็บปวด สัดส่วนเล็ก ๆ ของคำขอที่ช้ามากพอจะทำประสบการณ์ผู้ใช้แย่ลง ขณะที่เมตริกโดยรวมยังดูดี และหากคุณมอนิเตอร์แค่ “up/down” คุณจะพลาดช่วงยาว ๆ ที่ระบบยัง “ขึ้น” แต่ใช้งานจริงไม่ได้
Observability ช่วยให้คุณตรวจจับและแคบลงว่า ที่ไหน ระบบเริ่มเสื่อม (บริการไหน, endpoint ไหน, หรือตัวพึ่งพาใด) ส่วนบันทึกคำสั่งช้าช่วยพิสูจน์ว่า ฐานข้อมูลทำอะไร เมื่อคำขอหน่วง (คำสั่งไหน, ใช้เวลานานเท่าไร และบ่อยครั้งว่าทำงานแบบไหน)
คู่มือนี้เน้นปฏิบัติ: วิธีรับสัญญาณเตือนก่อน, เชื่อมหน่วงเวลาที่ผู้ใช้เจอกับงานในฐานข้อมูลเฉพาะ, และแก้ปัญหาอย่างปลอดภัย—โดยไม่พึ่งพาคำสัญญาเฉพาะ vendor
Observability หมายถึงความสามารถในการเข้าใจว่าสystem ทำอะไรจากสัญญาณที่มันผลิต—โดยไม่ต้องเดาหรือ “จำลองในเครื่อง” มันคือความต่างระหว่าง รู้ว่า ผู้ใช้รู้สึกช้า กับสามารถระบุ ที่ไหน ที่ช้าและ ทำไม มันเริ่ม
Metrics คือจำนวนตามเวลา (เปอร์เซ็นต์ CPU, อัตราคำขอ, อัตราข้อผิดพลาด, ความหน่วงของฐานข้อมูล) เรียกดูเร็วและดีสำหรับมองแนวโน้มและการพุ่งขึ้นอย่างฉับพลัน
Logs คือบันทึกเหตุการณ์พร้อมรายละเอียด (ข้อความผิดพลาด, ข้อความ SQL, รหัสผู้ใช้, เวลา timeout) ดีสุดสำหรับอธิบาย เกิดอะไรขึ้น ในรูปแบบที่มนุษย์อ่านได้
Traces ตามคำขอเดี่ยวเมื่อมันเคลื่อนผ่านบริการและการพึ่งพา (API → แอป → ฐานข้อมูล → cache) เหมาะสำหรับตอบคำถามว่า เวลาถูกใช้ไปที่ไหน และขั้นตอนใดที่ทำให้ช้า
โมเดลคิดที่มีประโยชน์: metrics บอกว่ามีปัญหา, traces บอกว่าที่ไหน, และ logs บอกว่าอะไรเกิดขึ้นแน่ ๆ
การตั้งค่าที่ดีช่วยให้คุณตอบตอนเกิดเหตุด้วยคำตอบชัดเจน:\n
Monitoring มักเกี่ยวกับเช็คและการเตือนที่กำหนดไว้ล่วงหน้า (“CPU \u003e 90%”) Observability ไปไกลกว่า: ให้คุณสอบสวนรูปแบบล้มเหลวที่ไม่คาดคิดโดยการหั่นและเชื่อมโยงสัญญาณ (เช่น เห็นว่าเฉพาะเซ็กเมนต์ลูกค้าหนึ่งประสบปัญหาเช็คเอาต์ช้า ผูกกับการเรียกฐานข้อมูลเฉพาะ)
ความสามารถในการตั้งคำถามใหม่ ๆ ระหว่างเหตุการณ์คือสิ่งที่เปลี่ยนเทเลเมทรีให้เป็นการแก้ปัญหาได้เร็วและใจเย็นขึ้น
บันทึกคำสั่งช้าคือบันทึกที่เน้นคำสั่งฐานข้อมูลที่เกินเกณฑ์ “ช้า” แตกต่างจากการล็อกคิวรีทั่วไป (ซึ่งอาจท่วมท้น) มันเน้นคำสั่งที่น่าจะทำให้เกิดความหน่วงที่ผู้ใช้เห็นและเหตุการณ์โปรดักชัน
ฐานข้อมูลส่วนใหญ่จับชุดฟิลด์หลักคล้ายกันได้:
บริบทนี้แปลงจาก “คำสั่งนี้ช้า” เป็น “คำสั่งนี้ช้าสำหรับบริการนี้ จาก pool การเชื่อมต่อนี้ ในเวลานี้เป๊ะ” ซึ่งสำคัญเมื่อหลายแอปแชร์ฐานข้อมูลเดียวกัน
บันทึกคำสั่งช้ามักไม่ใช่เรื่องของ “SQL แย่” เพียงอย่างเดียว แต่มันเป็นสัญญาณว่าฐานข้อมูลต้องทำงานเพิ่มหรือรอการทำงาน เหตุผลทั่วไปได้แก่:
กรอบความคิดที่ช่วย: บันทึกคำสั่งช้าจับทั้ง งาน (คิวรีหนัก CPU/I/O) และ การรอ (ล็อก, ทรัพยากรอิ่มตัว)
เกณฑ์เดียว (เช่น “บันทึกทุกอย่างเกิน 500ms”) ง่ายแต่บางครั้งมองข้ามความเจ็บปวดเมื่อ latency ปกติต่ำกว่ามาก พิจารณารวม:\n
บันทึกคำสั่งช้าอาจจับข้อมูลส่วนบุคคลโดยไม่ตั้งใจหากพารามิเตอร์ถูก inline (อีเมล, โทเคน, ID) ควรใช้ parameterized queries และการตั้งค่าที่บันทึกรูปร่างของคำสั่งแทนค่าจริง เมื่อหลีกเลี่ยงไม่ได้ ให้เพิ่มการมาสกิง/การปิดบังในท่อบันทึกก่อนเก็บหรือแชร์ระหว่างการตอบเหตุการณ์
คำสั่งช้ามักไม่คงอยู่แค่ “ช้า” เส้นทางทั่วไปคือ: หน่วงที่ผู้ใช้ → หน่วงที่ API → แรงกดดันที่ฐานข้อมูล → เวลา timeout ผู้ใช้รู้สึกก่อนว่าเพจค้างหรือหน้าจอหมุน แล้วไม่นานเมตริก API จะเริ่มแสดงเวลาเพิ่ม แม้โค้ดแอปจะไม่ได้เปลี่ยน
จากภายนอก ฐานข้อมูลช้ามักปรากฏเป็น “แอปช้า” เพราะเธรด API ถูกบล็อกรอคำสั่ง CPU และหน่วยความจำบนเซิร์ฟเวอร์แอปอาจดูปกติ แต่ p95 และ p99 เพิ่มขึ้น หากคุณดูแต่เมตริกระดับแอป คุณอาจตามล่าผิดตัว—เช่น HTTP handlers, cache หรือ deployment—ในขณะที่คอขวดจริงคือแผนคำสั่งเดียวที่ถอยหลัง
เมื่อคำสั่งช้า ระบบพยายามรับมือ และกลไกรับมือนั้นอาจขยายความเสียหาย:
สมมติ endpoint เช็คเอาต์เรียก SELECT ... FROM orders WHERE user_id = ? ORDER BY created_at DESC LIMIT 1 หลังการเติบโตของข้อมูล ดัชนีไม่ช่วยเพียงพอ คำสั่งจาก 20ms กลายเป็น 800ms ภายใต้ทราฟฟิกปกติมันน่ารำคาญ แต่ช่วงพีกคำขอ API รอ connection DB หมดเวลา 2 วินาที และไคลเอนต์ retry ในไม่กี่นาที คำสั่งช้าเล็ก ๆ กลายเป็นข้อผิดพลาดที่ผู้ใช้เห็นและเหตุการณ์โปรดักชันเต็มรูปแบบ
เมื่อฐานข้อมูลเริ่มมีปัญหา สัญญาณแรกมักอยู่ในชุดเมตริกเล็ก ๆ เป้าหมายไม่ใช่ติดตามทุกอย่าง—แต่จับการเปลี่ยนแปลงเร็ว แล้วแคบลงหาต้นตอ
สัญญาณสี่ตัวนี้ช่วยบอกว่าปัญหาเป็นของฐานข้อมูล แอป หรือทั้งคู่:
ชาร์ต DB เพียงไม่กี่รายการบอกได้ว่าคอขวดมาจากการรัน query, ความพร้อมกัน, หรือ storage:
จับคู่เมตริก DB กับสิ่งที่บริการเห็น:
ออกแบบแดชบอร์ดให้ตอบได้เร็ว:\n
เมื่อเมตริกเหล่านี้สอดคล้อง—หาง latency ขึ้น, timeout เพิ่ม, saturation เพิ่ม—คุณมีสัญญาณชัดเจนที่จะขยับไปดูบันทึกคำสั่งช้าและ tracing เพื่อระบุการทำงานที่แน่นอน
บันทึกคำสั่งช้าบอกคุณว่า อะไร ช้าใน DB ส่วน distributed tracing บอกว่า ใครขอ, มาจากไหน, และ ทำไมถึงสำคัญ
เมื่อมี tracing อยู่ การแจ้งเตือนว่า “DB ช้า” จะกลายเป็นเรื่องเล่า: endpoint ใด (หรืองาน background) ทริกเกอร์ลำดับการเรียก ซึ่งหนึ่งในนั้นใช้เวลาส่วนใหญ่รอการทำงานใน DB
ใน UI ของ APM ให้เริ่มจาก trace ที่ latency สูงและดู:
GET /checkout หรือ billing_reconcile_worker)SQL เต็มใน trace อาจเสี่ยง (PII, ความลับ, payload ใหญ่) วิธีปฏิบัติที่เป็นไปได้คือแท็ก span ด้วย ชื่อคำสั่ง/operation แทนคำสั่งเต็ม:
db.operation=SELECT และ db.table=ordersapp.query_name=orders_by_customer_v2feature_flag=checkout_upsellวิธีนี้ทำให้ trace ค้นหาได้และปลอดภัย ในขณะที่ชี้เส้นทางโค้ดได้
วิธีที่เร็วที่สุดในการเชื่อม “trace” → “app logs” → “entry ในบันทึกคำสั่งช้า” คือ identifier ร่วมกัน:
ตอนนี้คุณจะตอบคำถามมีค่าได้เร็วขึ้น:
บันทึกคำสั่งช้าจะมีประโยชน์ก็ต่อเมื่อยังคงอ่านได้และ actionable เป้าหมายไม่ใช่ “บันทึกทุกอย่างตลอดไป” แต่จับรายละเอียดพออธิบาย ทำไม คำสั่งช้าพอ โดยไม่เพิ่ม overhead ให้ระบบหรือค่าใช้จ่ายสูง
เริ่มจาก เกณฑ์คงที่ ที่สะท้อนความคาดหวังของผู้ใช้และบทบาทฐานข้อมูลของคำขอ
\u003e200ms สำหรับแอป OLTP หนัก, \u003e500ms สำหรับงานผสมแล้วเพิ่มมุมมอง สัมพันธ์ เพื่อให้ยังเห็นปัญหาเมื่อระบบช้าทั้งหมด (และคำสั่งข้ามเส้นคงที่น้อยลง)
การใช้ทั้งสองอย่างช่วยหลีกเลี่ยงจุดบอด: เกณฑ์คงที่จับคำสั่งที่แย่เสมอ ขณะที่เกณฑ์สัมพันธ์จับการถดถอยในช่วงที่ระบบยุ่ง
การบันทึกทุกคำสั่งช้าที่สุดในช่วงพีกอาจกระทบประสิทธิภาพและสร้างเสียงรบกวน ชอบ sampling (เช่น บันทึก 10–20% ของเหตุการณ์ช้า) และเพิ่ม sampling ชั่วคราวในตอนเกิดเหตุ
ให้แน่ใจว่าแต่ละเหตุการณ์มีบริบทที่คุณจะใช้จริง: duration, rows examined/returned, database/user, ชื่อแอป, และถ้าเป็นไปได้ request หรือ trace ID
ข้อความ SQL ดิบยุ่งเหยิง: ID และ timestamp ต่างกันทำให้คำสั่งเหมือนกันดูไม่เหมือนกัน ใช้ query fingerprinting (การทำให้เป็นรูปร่างปกติ) เพื่อรวม statement ที่คล้ายกัน เช่น WHERE user_id = ?
นี้ช่วยให้ตอบได้ว่า: “รูปร่างคำสั่งใดทำให้เกิด latency มากที่สุด?” แทนที่จะไล่ตัวอย่างครั้งเดียว
เก็บบันทึกคำสั่งช้าที่มีรายละเอียดนานพอที่จะเปรียบเทียบ “ก่อน vs หลัง” ในการสืบสวน—บ่อยครั้ง 7–30 วัน เป็นจุดเริ่มที่เหมาะสม
ถ้าพื้นที่เก็บข้อมูลเป็นปัญหา ให้ลดตัวอย่างข้อมูลเก่า (เก็บเฉพาะสรุปและ top fingerprints) ขณะที่เก็บบันทึกละเอียดสำหรับหน้าต่างล่าสุด
การเตือนควรสื่อว่า “ผู้ใช้กำลังจะรู้สึกเรื่องนี้” และบอกว่าจะดูที่ไหนก่อน วิธีที่ง่ายที่สุดคือเตือนทั้ง อาการ (ผลกระทบต่อผู้ใช้) และ สาเหตุ (สิ่งที่ขับเคลื่อนมัน) พร้อมการควบคุมเสียงรบกวน
เริ่มจากชุดตัวชี้วัดค่าสัญญาณสูงที่สัมพันธ์กับความเจ็บปวดผู้ใช้:
ถ้าเป็นไปได้ ให้กำหนดขอบเขตการเตือนสำหรับ “golden paths” (checkout, login, search) เพื่อไม่ให้เกิด page บน route ที่ไม่สำคัญ
จับคู่การเตือนอาการกับการเตือนเชิงสาเหตุที่ย่นเวลาในการวินิจฉัย:
การเตือนเชิงสาเหตุควรมี fingerprint ของคำสั่ง ตัวอย่างพารามิเตอร์ที่ถูก sanitize และลิงก์ตรงไปยังแดชบอร์ดหรือมุมมอง trace ที่เกี่ยวข้อง (ถ้ามี)
ใช้:
แต่ละ page ควรมี “ฉันต้องทำอะไรต่อ?” — อ้างอิง runbook เช่น /blog/incident-runbooks และระบุสามการตรวจสอบแรก (แผง latency, รายการคำสั่งช้า, กราฟล็อก/connection)
เมื่อ latency พุ่ง ความต่างระหว่างกู้คืนเร็วและเกิดเหตุยาวนานคือเวิร์กโฟลว์ที่ทำซ้ำได้ เป้าหมายคือย้ายจาก “อะไรบางอย่างช้า” ไปสู่คำสั่ง, endpoint และการเปลี่ยนแปลงที่ทำให้เกิดมัน
เริ่มจากอาการผู้ใช้: latency ของคำขอสูง, timeout, หรืออัตราข้อผิดพลาด
ยืนยันด้วยชุดตัวชี้วัดสัญญาณสูงเล็ก ๆ: p95/p99 latency, throughput, และสภาพ DB (CPU, การเชื่อมต่อ, คิว/เวลารอ) หลีกเลี่ยงการไล่ตามความผิดปกติของโฮสต์เดียว—มองหาแพทเทิร์นทั่วบริการ
แคบพื้นที่ผลกระทบ:
ขั้นตอนการกำหนดขอบเขตนี้ช่วยไม่ให้คุณไปปรับจูนสิ่งที่ผิด
เปิด distributed traces สำหรับ endpoint ที่ช้าและเรียงลำดับตามความยาว
มองหา span ที่กินเวลาส่วนใหญ่ของคำขอ: การเรียกฐานข้อมูล, การรอล็อก, หรือการเรียกหลายครั้งซ้ำ ๆ (พฤติกรรม N+1) เชื่อม trace กับแท็กบริบทเช่น version, tenant ID, และชื่อ endpoint เพื่อดูว่าความช้านั้นสัมพันธ์กับ deploy หรือโหลดเฉพาะไหม
ตอนนี้ตรวจสอบคิวรีที่สงสัยในบันทึกคำสั่งช้า
เน้นที่ “fingerprints” (query ปกติ) เพื่อหาตัวร้ายตามเวลาทั้งหมดและจำนวนครั้ง แล้วสังเกตตารางและ predicates ที่เกี่ยวข้อง (เช่น เงื่อนไขและ join) ที่นี่มักจะค้นพบดัชนีที่ขาด, join ใหม่, หรือการเปลี่ยนแปลงแผนคำสั่ง
เลือกการลดผลกระทบที่เสี่ยงน้อยที่สุดก่อน: ย้อนกลับ release, ปิด feature flag, ลดโหลด, หรือเพิ่ม limit ของ connection pool เฉพาะเมื่อแน่ใจว่าจะไม่เพิ่ม contention หากต้องเปลี่ยน query ให้ทำทีละน้อยและวัดผล
เคล็ดลับปฏิบัติ: ใน pipeline ที่รองรับ ให้ถือว่า “rollback” เป็นปุ่มสำคัญ ไม่ใช่การกระทำฮีโร่ แพลตฟอร์มอย่าง Koder.ai สนับสนุน snapshot และ workflow การ rollback ซึ่งช่วยลดเวลาไปสู่การบรรเทาเมื่อ release บังเอิญนำรูปแบบคำสั่งช้ามา
บันทึก: มีอะไรเปลี่ยน, ตรวจพบอย่างไร, fingerprint ที่แน่นอน, endpoint/tenant ที่ได้รับผล, และสิ่งที่แก้ไข แปลงเป็นติดตามผล: เพิ่มการเตือน, แผงแดชบอร์ด, และเกณฑ์รักษาประสิทธิภาพ (เช่น “ไม่มี fingerprint ใดเกิน X ms ที่ p95”)
เมื่อคำสั่งช้ากำลังส่งผลผู้ใช้ เป้าหมายคือหาทางลดผลกระทบก่อน แล้วปรับปรุงประสิทธิภาพ—โดยไม่ทำให้อุบัติการณ์แย่ลง ข้อมูล observability (ตัวอย่างคำสั่งช้า, trace, และเมตริก DB สำคัญ) บอกคุณว่าควรกดเลเวอร์ไหนที่ปลอดภัยสุด
เริ่มจากการเปลี่ยนที่ลดโหลดโดยไม่เปลี่ยนพฤติกรรมข้อมูล:
การบรรเทาเหล่านี้ควรแสดงการปรับปรุงทันทีใน p95 latency และเมตริก CPU/IO ของ DB
เมื่อเสถียรแล้ว แก้รูปแบบคำสั่งจริง:
EXPLAIN และตรวจว่าจำนวนแถวที่สแกนลดลงSELECT *, เพิ่ม predicate ที่คัดเลือกได้ดี, แทน subquery ที่เกี่ยวข้องด้วยวิธีอื่น)นำการเปลี่ยนแปลงขึ้นทีละน้อยและยืนยันการปรับปรุงโดยใช้ span/ fingerprint เดิมในการเปรียบเทียบ
ย้อนกลับเมื่อการเปลี่ยนเพิ่มข้อผิดพลาด, contention, หรือการกระจายโหลดที่ไม่คาดคิด ทำ hotfix เมื่อคุณแยกการเปลี่ยนได้ชัด (คำสั่งเดียว, endpoint เดียว) และมีเทเลเมทรีชัดเจนก่อน/หลังเพื่อยืนยันว่าปลอดภัย
เมื่อแก้คำสั่งช้าแล้ว ผลสำคัญคือทำให้แน่ใจว่ารูปแบบเดิมจะไม่กลับมาในรูปลักษณ์อื่น เกณฑ์ SLO ที่ชัดและเกราะบางอย่างจะเปลี่ยนอุบัติการณ์เดียวให้เป็นความน่าเชื่อถือถาวร
เริ่มจาก SLI ที่เชื่อมตรงกับประสบการณ์ลูกค้า:
ตั้ง SLO ให้สะท้อนประสิทธิภาพที่ยอมรับได้ ไม่ใช่สมบูรณ์ เช่น: “p95 checkout ต่ำกว่า 600ms สำหรับ 99.9% ของนาที” เมื่อ SLO ถูกคุกคาม คุณมีเหตุผลชัดเจนจะหยุด deploy เสี่ยงและมุ่งแก้ประสิทธิภาพ
เหตุการณ์ซ้ำมักมาจาก regression ทำให้มองเห็นง่ายโดยเปรียบเทียบ ก่อน/หลัง สำหรับแต่ละ release:
กุญแจคือดูการเปลี่ยนแปลงใน การแจกแจง (p95/p99) ไม่ใช่แค่ค่าเฉลี่ย
เลือกชุดเล็ก ๆ ของ endpoint ที่ “ห้ามช้า” และคำสั่งสำคัญของพวกเขา ใส่การเช็กประสิทธิภาพใน CI ที่ล้มเหลวเมื่อ latency หรือต้นทุนคำสั่งเกินเกณฑ์ (แม้เป็น baseline + drift ที่อนุญาต) วิธีนี้จับข้อผิดพลาด N+1, full table scan บังเอิญ, และ pagination ที่ไม่จำกัด ก่อนส่ง
ถ้าคุณสร้างบริการเร็ว (เช่น ด้วยตัวสร้างแอปที่ขับเคลื่อนด้วยแชทอย่าง Koder.ai, ที่สร้าง React frontend, Go backend, และสคีมา PostgreSQL ได้รวดเร็ว) เกราะเหล่านี้ยิ่งสำคัญ: ความเร็วเป็นฟีเจอร์ แต่ต้องฝังเทเลเมทรี (trace ID, fingerprint ของคำสั่ง, และการล็อกที่ปลอดภัย) ตั้งแต่รอบแรก
ให้การทบทวนคำสั่งช้าเป็นงานของใครสักคน ไม่ใช่เรื่องรอง:
เมื่อตั้ง SLO ว่า “ดีเป็นอย่างไร” และเกราะจับการถดถอยได้, ประสิทธิภาพจะหยุดเป็นภาวะฉุกเฉินซ้ำ ๆ และกลายเป็นส่วนที่จัดการได้ของการส่งมอบ
การตั้งค่า observability ที่เน้นฐานข้อมูลควรช่วยให้คุณตอบสองคำถามได้เร็ว: “ฐานข้อมูลคือคอขวดไหม?” และ “คำสั่งไหน (และผู้เรียกคนไหน) ทำให้เป็นเช่นนั้น?” การตั้งค่าที่ดีที่สุดทำให้คำตอบชัดเจนโดยไม่บังคับวิศวกรให้ค้นหาในล็อกจากชั่วโมง
เมตริกที่ต้องมี (แยกตาม instance, cluster, และบทบาท/replica ถ้าได้):
ฟิลด์ล็อกที่ต้องมี ในบันทึกคำสั่งช้า:
แท็กใน trace เพื่อเชื่อมคำขอกับคำสั่ง:
แดชบอร์ดและการเตือน ที่คุณควรคาดหวัง:
มันสามารถเชื่อมพุ่งของ endpoint latency กับ fingerprint ของคำสั่งและ version ของ release ได้ไหม? จัดการ sampling อย่างไรเพื่อให้เก็บคำสั่งแพงที่หายากได้? มัน dedupe คำสั่ง noisy (fingerprinting) และเน้นการถดถอยเมื่อเวลาผ่านไปหรือไม่?
มองหาการมี redaction ในตัว (PII และ literals), RBAC, และขีดจำกัดการเก็บข้อมูลที่ชัดเจน ตรวจสอบว่าการส่งออกข้อมูลไป warehouse/SIEM จะไม่ข้ามการควบคุมเหล่านั้น
ถ้าทีมคุณกำลังประเมินตัวเลือก การกำหนดข้อกำหนดล่วงหน้าช่วยได้—แชร์ shortlist ภายใน แล้วเชิญผู้ขายเข้ามา หากต้องการการเปรียบเทียบเร็วหรือคำแนะนำ ดู /pricing หรือ ติดต่อผ่าน /contact.
เริ่มจากดูที่ tail latency (p95/p99) ต่อ endpoint แทนการดูค่าเฉลี่ยเท่านั้น แล้วจับคู่กับ อัตรา timeout, อัตราการ retry และสัญญาณความอิ่มตัวของฐานข้อมูล (เช่น การรอ connection, การรอล็อก, CPU/I/O)
ถ้าตัวชี้วัดเหล่านี้ขึ้นพร้อมกัน ให้ย้ายไปดู trace เพื่อหา span ที่ช้า แล้วเข้าไปดูในบันทึกคำสั่งช้าเพื่อระบุ fingerprint ของคำสั่งนั้น
ค่าเฉลี่ยกลบจุดผิดปกติได้ง่าย ส่วนเล็ก ๆ ของคำขอที่ช้ามากอาจทำให้ผู้ใช้รู้สึกว่าผลิตภัณฑ์พังทั้งที่ค่าเฉลี่ยยังปกติ
ติดตาม:
สิ่งเหล่านี้จะเผยหางยาว (long tail) ที่ผู้ใช้สัมผัสจริง
ใช้ทั้งสองอย่างร่วมกันเป็น “where” + “what”.
การรวมกันนี้ช่วยย่นเวลาไปสู่สาเหตุรากได้อย่างมาก
โดยปกติจะมี:
ให้จัดลำดับความสำคัญของฟิลด์ที่ตอบคำถามได้ว่า: บริการใดทริกเกอร์ มันเกิดเมื่อไร และเป็นรูปแบบคำสั่งที่เกิดซ้ำหรือไม่?
เลือกเกณฑ์ตามประสบการณ์ผู้ใช้และบทบาทของฐานข้อมูลของคุณ
แนวทางปฏิบัติ:
ทำให้เป็น actionable; อย่าเก็บทุกอย่าง
ใช้ query fingerprinting (การทำให้เป็นรูปร่างปกติ) เพื่อรวมคำสั่งที่เหมือนกันแม้ค่าพารามิเตอร์ต่างกัน
ตัวอย่าง: WHERE user_id = ? แทน WHERE user_id = 12345.
แล้วจัดอันดับ fingerprint โดย:
อย่าเก็บตัวอักษรที่เป็นข้อมูลส่วนบุคคลแบบดิบ
แนวปฏิบัติที่ดี:
ลำดับเหตุการณ์ทั่วไปคือ:
การตัดวงจรมักหมายถึงลด retry คืนความพร้อม pool และแก้ fingerprint ของคำสั่งที่ช้า
ต้องเตือนทั้ง อาการ และ สาเหตุที่เป็นไปได้
อาการ (ผลกระทบต่อผู้ใช้):
สาเหตุ (จุดเริ่มต้นการสืบสวน):
เริ่มจากการผ่อนคลายความเสี่ยงแล้วค่อยแก้ query:
บรรเทาเร็ว:
จากนั้นแก้:
จะช่วยลดความเสี่ยงในการเปิดเผยข้อมูลผู้ใช้เวลาสืบสวน
ใช้ multi-window/burn-rate เพื่อลดเสียงรบกวน
EXPLAINยืนยันด้วย span ของ trace เดิมและ fingerprint ในบันทึกคำสั่งช้าก่อน/หลัง