31 ต.ค. 2568·3 นาที
การตัดสินใจตอนต้นของ Joe Beda ที่หล่อหลอม Kubernetes
มองชัด ๆ ถึงการตัดสินใจตอนแรกของ Joe Beda ใน Kubernetes—โมเดลเชิงประกาศ, control loops, Pods, Services และ labels—และวิธีที่สิ่งเหล่านี้หล่อหลอมแพลตฟอร์มแอปสมัยใหม่
ทำไมการตัดสินใจตอนต้นของ Joe Beda ยังคงสำคัญ
Joe Beda เป็นหนึ่งในคนสำคัญที่อยู่เบื้องหลังการออกแบบ Kubernetes ยุคแรก—ร่วมกับผู้ก่อตั้งคนอื่น ๆ ที่นำบทเรียนจากระบบภายในของ Google มาสู่แพลตฟอร์มแบบเปิด ผลกระทบของเขาไม่ได้อยู่ที่การตามหาฟีเจอร์ฮิต แต่เป็นการเลือก primitive ที่เรียบง่ายซึ่งทนต่อความยุ่งเหยิงในสภาพแวดล้อมการผลิตจริง และ ยังคงเข้าใจได้โดยทีมทั่วไป
การตัดสินใจในตอนแรกเหล่านี้คือเหตุผลที่ Kubernetes กลายเป็นมากกว่า "เครื่องมือคอนเทนเนอร์" มันกลายเป็นเคอร์เนลที่นำกลับมาใช้ใหม่ได้สำหรับแพลตฟอร์มแอปสมัยใหม่
การออร์เคสตราคอนเทนเนอร์ แบบง่าย ๆ
“การออร์เคสตราคอนเทนเนอร์” คือชุดกฎและการอัตโนมัติที่ทำให้แอปของคุณยังรันได้เมื่อเครื่องล้ม, ปริมาณทราฟฟิคพุ่งขึ้น, หรือคุณปล่อยเวอร์ชันใหม่ แทนที่จะให้คนคอยดูแลเซิร์ฟเวอร์ ระบบจะจัดตารางคอนเทนเนอร์ไปยังคอมพิวเตอร์ รีสตาร์ทเมื่อพวกมันล้ม กระจายเพื่อความทนทาน และจัดการเครือข่ายเพื่อให้ผู้ใช้เข้าถึงได้
ความยุ่งเหยิงก่อน Kubernetes
ก่อนที่ Kubernetes จะเป็นที่นิยม ทีมมักจะต่อเครื่องมือสคริปต์และเครื่องมือเฉพาะทางเข้าด้วยกันเพื่อแก้คำถามพื้นฐาน:
- ตอนนี้คอนเทนเนอร์นี้ควรจะรันที่ไหน?
- ถ้าโหนดล้มตอนตีสองจะเกิดอะไรขึ้น?
- เราปรับใช้ได้อย่างปลอดภัยโดยไม่หยุดทำงานอย่างไร?
ระบบ DIY เหล่านั้นใช้งานได้—จนกระทั่งไม่ใช่ ทุกแอปหรือทีมใหม่เพิ่มโลจิกจุดเดียว และความสอดคล้องด้านการปฏิบัติการก็ยากที่จะทำให้เกิดขึ้น
สิ่งที่โพสต์นี้ครอบคลุม
บทความนี้จะอธิบายการตัดสินใจการออกแบบ Kubernetes ตอนต้น (“รูปทรง” ของ Kubernetes) และเหตุผลที่สิ่งเหล่านี้ยังมีผลต่อแพลตฟอร์มสมัยใหม่: โมเดลเชิงประกาศ, controllers, Pods, labels, Services, API ที่แข็งแกร่ง, สถานะคลัสเตอร์ที่สอดคล้อง, การจัดตารางแบบ pluggable และความสามารถขยายได้ แม้คุณจะไม่รัน Kubernetes โดยตรง คุณก็น่าจะใช้แพลตฟอร์มที่สร้างบนแนวคิดเหล่านี้—หรือกำลังเจอปัญหาเดียวกัน
ปัญหาที่ Kubernetes พยายามแก้
ก่อน Kubernetes “การรันคอนเทนเนอร์” มักหมายถึงการรันไม่กี่คอนเทนเนอร์ ทีมต่อ bash scripts, cron jobs, golden images และเครื่องมือเฉพาะเพื่อให้สิ่งต่าง ๆ ถูกปรับใช้งาน เมื่อมีปัญหา การแก้ไขมักอยู่ในหัวของใครบางคน—หรือใน README ที่ไม่มีใครไว้ใจ งานปฏิบัติการคือการแทรกแซงเฉพาะหน้า: รีสตาร์ทกระบวนการ เปลี่ยนปลายทาง load balancer ทำความสะอาดดิสก์ และเดาว่าเครื่องไหนปลอดภัยที่จะเข้าไปแตะ
คอนเทนเนอร์ในระดับใหญ่สร้างรูปแบบการล้มเหลวใหม่
คอนเทนเนอร์ทำให้การแพ็กเกจง่ายขึ้น แต่ไม่ได้ลบส่วนที่ยุ่งยากของการผลิตออกไป เมื่อขยายขนาด ระบบจะล้มเหลวในหลายรูปแบบและบ่อยขึ้น: โหนดหาย เครือข่ายแบ่ง พิมพ์อิมเมจถูกปล่อยไม่สม่ำเสมอ และงานเปลี่ยนจากสิ่งที่คุณ คิดว่า รันอยู่ การปรับใช้ที่ดู “เรียบง่าย” อาจกลายเป็นโดมิโน—บางอินสแตนซ์อัปเดต บางตัวไม่, บางอันติดค้าง, บางอันยังดีแต่เข้าถึงไม่ได้
ปัญหาจริงไม่ใช่การเริ่มคอนเทนเนอร์ แต่คือการรักษาให้คอนเทนเนอร์ ที่ถูกต้อง ทำงานใน รูปร่างที่ถูกต้อง ท่ามกลางการเปลี่ยนแปลงอย่างต่อเนื่อง
โมเดลที่สอดคล้องข้ามโครงสร้างพื้นฐาน
ทีมต้องจัดการกับสภาพแวดล้อมที่ต่างกัน: ฮาร์ดแวร์ on‑prem, VMs, ผู้ให้บริการคลาวด์ยุคแรก และการตั้งค่าเครือข่ายและสตอเรจที่หลากหลาย แพลตฟอร์มแต่ละแห่งมีศัพท์และรูปแบบการล้มเหลวของตัวเอง โดยไม่มีโมเดลร่วม การย้ายแต่ละครั้งหมายถึงการเขียนเครื่องมือปฏิบัติการใหม่และฝึกคนใหม่
Kubernetes ตั้งใจจะให้วิธีการอธิบายแอปและความต้องการปฏิบัติการแบบเดียวกัน โดยไม่คำนึงว่าเครื่องจะอยู่ที่ไหน
ความคาดหวังของ “แพลตฟอร์ม” เป็นอย่างไร
นักพัฒนาต้องการ self-service: ปรับใช้โดยไม่ต้องขอชั่วตั๋ว, ขยายโดยไม่ต้องขอทรัพยากร และย้อนกลับโดยไม่มีดราม่า ทีม ops ต้องการความคาดเดาได้: การตรวจสุขภาพมาตรฐาน, การปรับใช้งานซ้ำได้, และแหล่งข้อมูลความจริงชัดเจนว่าควรจะรันอะไร
Kubernetes ไม่ได้พยายามเป็นเพียง scheduler หรู มันต้องการเป็นพื้นฐานของแพลตฟอร์มแอปที่เชื่อถือได้—ซึ่งเปลี่ยนความยุ่งเหยิงให้เป็นระบบที่คุณสามารถอธิบายเหตุผลได้
การตัดสินใจที่ 1: โมเดลเชิงประกาศ (Declarative)
หนึ่งในการเลือกที่มีอิทธิพลตั้งแต่ต้นคือการทำให้ Kubernetes เป็นเชิงประกาศ: คุณอธิบายสิ่งที่ต้องการ แล้วระบบก็ทำให้ความจริงตรงกับคำอธิบายนั้น
desired state อธิบายแบบเทอร์โมสตัท
เทอร์โมสตัทเป็นตัวอย่างประจำวันที่ดี คุณไม่ต้องเปิดปิดฮีตเตอร์ทุกไม่กี่นาที คุณตั้งอุณหภูมิที่ต้องการ—เช่น 21°C—แล้วเทอร์โมสตัทจะคอยตรวจและปรับฮีตเตอร์ให้ใกล้เคียงเป้าหมายนั้น
Kubernetes ทำงานในลักษณะเดียวกัน แทนที่จะบอกคลัสเตอร์ทีละขั้นตอนว่า “เริ่มคอนเทนเนอร์นี้บนเครื่องนั้น แล้วรีสตาร์ทถ้ามันล้ม” คุณประกาศผลลัพธ์: “ฉันต้องการให้รันแอปนี้ 3 สำเนา” Kubernetes จะตรวจสอบสิ่งที่รันจริงอย่างต่อเนื่องและแก้ไขการเบี่ยงเบน
ขั้นตอนน้อยลง ความประหลาดใจน้อยลง
การคอนฟิกเชิงประกาศลดเช็คลิสต์การปฏิบัติการที่มักซ่อนอยู่ในหัวของใครบางคนหรือใน runbook ที่อัปเดตไม่ครบ คุณนำคอนฟิกไปใช้ และ Kubernetes จัดการกลไก—การจัดวาง การรีสตาร์ท และการประสานการเปลี่ยนแปลง
นี่ยังทำให้การตรวจทานการเปลี่ยนแปลงง่ายขึ้น เพราะการเปลี่ยนแปลงปรากฏเป็น diff ของคอนฟิก ไม่ใช่ชุดคำสั่งแบบ ad-hoc
ทำซ้ำได้ข้ามสภาพแวดล้อม
เพราะ desired state ถูกเขียนลง คุณสามารถนำแนวทางเดียวกันไปใช้ใน dev, staging และ production ได้ สภาพแวดล้อมอาจต่างกัน แต่ เจตนา ยังคงเหมือนกัน ซึ่งทำให้การปรับใช้งานคาดเดาได้และตรวจสอบได้ง่ายขึ้น
ข้อแลกเปลี่ยน
ระบบเชิงประกาศมีแนวโน้มที่จะต้องเรียนรู้: คุณต้องคิดเป็น “อะไรที่ควรจะเป็นจริง” แทนที่จะเป็น “ฉันต้องทำอะไรทีถัดไป” และพวกมันขึ้นกับค่าเริ่มต้นที่ดีและคอนเวนชันที่ชัดเจน—หากไม่มี ทีมอาจสร้างคอนฟิกที่ทำงานได้แต่เข้าใจและดูแลยาก
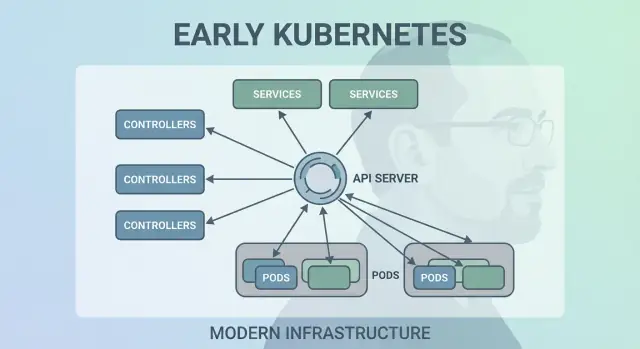
การตัดสินใจที่ 2: Control Loops (Controllers) เป็นเครื่องยนต์
Kubernetes ไม่ประสบความสำเร็จเพราะมันสามารถรันคอนเทนเนอร์ได้ครั้งหนึ่ง—แต่มันประสบความสำเร็จเพราะมันสามารถทำให้คอนเทนเนอร์รันได้อย่างถูกต้องตลอดเวลา การเคลื่อนไหวสำคัญคือการทำให้ “control loops” (controllers) เป็นแกนหลักของระบบ
Controller คืออะไร
Controller คือวงจรง่าย ๆ:
- ดูสถานะปัจจุบัน (สิ่งที่รันอยู่จริง)
- เปรียบเทียบกับ desired state (สิ่งที่คุณร้องขอ)
- ดำเนินการจนกว่าสองอย่างจะตรงกัน
มันไม่ใช่เหมือนงานครั้งเดียว แต่เหมือน autopilot คุณไม่ต้องคอยดูแล workloads; คุณประกาศสิ่งที่ต้องการและ controllers จะคอยปรับคลัสเตอร์กลับสู่ผลลัพธ์นั้น
จัดการการชน, การหายของโหนด และการเบี่ยงเบน
รูปแบบนี้คือเหตุผลที่ Kubernetes ทนเมื่อสิ่งจริงเกิดปัญหา:
- Container crashes: controller เห็นว่าสำเนาน้อยกว่าที่ต้องการและสร้างตัวทดแทน
- Node loss: เมื่อโหนดหาย controllers จะจัดตาราง pods ที่เหลือไปยังที่อื่นเพื่อคืนค่า
- Configuration drift: ถ้ามีใครเปลี่ยนหรือลบทรัพยากร controllers จะประสานความต่างและแก้ไข
แทนที่จะมองความล้มเหลวเป็นกรณีพิเศษ controllers มองเป็น “ความไม่ตรงกันของสถานะ” แล้วแก้เหมือนกันทุกครั้ง
ทำไมมันสเกลได้ดีกว่าสคริปต์
สคริปต์อัตโนมัติโบราณมักสมมติว่าสภาพแวดล้อมคงที่: ทำ A แล้ว B แล้ว C ในระบบกระจาย การสมมติเหล่านั้นพังบ่อย Controllers สเกลได้ดีกว่าเพราะพวกมัน idempotent (ปลอดภัยเมื่อรันซ้ำ) และ eventually consistent (จะพยายามจนกว่าจะถึงเป้าหมาย)
ตัวอย่างประจำวัน: Deployments และ ReplicaSets
ถ้าคุณใช้ Deployment คุณก็พึ่งพา control loops ใต้ผิว Kubernetes ใช้ controller ของ ReplicaSet เพื่อให้จำนวน pods ที่ร้องขอมีอยู่จริง—และมี Deployment controller เพื่อจัดการ rolling updates และ rollback อย่างคาดเดาได้
การตัดสินใจที่ 3: Pods เป็นหน่วยการจัดตารางขั้นพื้นฐาน
Kubernetes อาจจะเลือกจัดตารางเฉพาะ “คอนเทนเนอร์” แต่ทีมของ Joe Beda แนะนำ Pods ให้เป็นหน่วยที่เล็กที่สุดที่ระบบจะวางบนเครื่อง ความคิดสำคัญคือ: แอปจริงหลายตัวไม่ใช่กระบวนการเดียว แต่เป็น กลุ่มเล็ก ๆ ของกระบวนการที่ต้องอยู่ด้วยกัน
ทำไมเป็น Pods แทนคอนเทนเนอร์เดี่ยว?
Pod เป็นตัวห่อรอบหนึ่งหรือหลายคอนเทนเนอร์ที่มีชะตากรรมร่วมกัน: เริ่มพร้อมกัน รันบนโหนดเดียวกัน และ scale ด้วยกัน นี่ทำให้แพตเทิร์นอย่าง sidecars เป็นเรื่องธรรมชาติ—คิดถึง log shipper, proxy, reloader หรือเอเจนต์ความปลอดภัยที่ควรเดินไปกับแอปหลักเสมอ
แทนที่จะสอนให้ทุกแอปรวมตัวช่วยเหล่านั้นเข้าด้วยกัน Kubernetes ให้คุณบรรจุพวกมันเป็นคอนเทนเนอร์แยกต่างหากที่ยังทำงานร่วมกันเหมือนหน่วยเดียว
Pods ช่วยอะไรในเครือข่ายและสตอเรจ
Pods ทำให้ข้อสมมติสองอย่างเป็นไปได้:
- เครือข่าย: คอนเทนเนอร์ใน Pod แบ่งปันตัวตนเครือข่าย (IP และพอร์ต) หนึ่งเดียว แอปหลักสามารถคุยกับ sidecar ผ่าน
localhostซึ่งเรียบง่ายและเร็ว - สตอเรจ: คอนเทนเนอร์ใน Pod สามารถแชร์ volumes ได้ ตัวช่วยสามารถเขียนไฟล์ที่แอปหลักอ่านได้โดยไม่ต้องกระโดดไปยังระบบภายนอก
การเลือกเหล่านี้ลดความจำเป็นในการเขียนโค้ดเชื่อมต่อเฉพาะทาง ในขณะที่ยังคงแยกคอนเทนเนอร์ในระดับกระบวนการ
จุดที่ Pods ทำให้ผู้เริ่มสับสน
ผู้ใช้ใหม่มักคาดหวังว่า “คอนเทนเนอร์หนึ่งตัว = แอปหนึ่งตัว” แล้วสะดุดกับแนวคิดระดับ Pod: การรีสตาร์ท, IP และการสเกล หลายแพลตฟอร์มจะทำให้เรื่องนี้เรียบง่ายด้วยเทมเพลตมีความเห็นชอบ (เช่น “web service,” “worker,” หรือ “job”) ที่สร้าง Pods อยู่เบื้องหลัง—ทำให้ทีมได้รับประโยชน์จาก sidecars และทรัพยากรที่แชร์โดยไม่ต้องคิดเรื่องกลไก Pod ทุกวัน
การตัดสินใจที่ 4: Labels และ Selectors เพื่อการผูกแบบหลวม
ส่งมอบโดยไม่เสี่ยงกับการปรับใช้
ปรับใช้และโฮสต์แอปของคุณ แล้วรักษาความปลอดภัยของการเปลี่ยนแปลงด้วยสแนปชอตและการย้อนกลับ.
การตัดสินใจที่ทรงพลังและเงียบ ๆ ในตอนต้นคือการถือว่า labels เป็น metadata ชั้นหนึ่งและ selectors เป็นวิธีหลักในการ “ค้นหา” สิ่งต่าง ๆ แทนที่จะผูกความสัมพันธ์ไว้แน่น (เช่น “สามเครื่องนี้รันแอปของฉัน”) Kubernetes สนับสนุนให้คุณอธิบายกลุ่มโดยคุณลักษณะที่ใช้ร่วมกัน
Labels: แท็กยืดหยุ่นบนทุกอย่าง
Label คือคู่คีย์/ค่าเบา ๆ ที่คุณแนบกับทรัพยากร—Pods, Deployments, Nodes, Namespaces และอื่น ๆ มันทำหน้าที่เหมือน “แท็ก” ที่สืบค้นได้:
app=checkoutenv=prodtier=frontend
เพราะ labels เบาและกำหนดโดยผู้ใช้ คุณสามารถจำลองความเป็นจริงขององค์กรมาควบคุม: ทีม, ศูนย์ต้นทุน, โซนปฏิบัติตามข้อบังคับ, ช่องทางการปล่อย, หรือสิ่งที่สำคัญต่อวิธีการปฏิบัติการของคุณ
Selectors: ความสัมพันธ์โดยไม่ต้องผูกแน่น
Selectors คือการสืบค้นบน labels (ตัวอย่างเช่น “Pod ทั้งหมดที่ app=checkout และ env=prod”) นี่ดีกว่าการใช้รายการโฮสต์คงที่เพราะระบบสามารถปรับเมื่อ Pods ถูกย้าย สเกลขึ้น/ลง หรือถูกแทนที่ระหว่าง rollout คอนฟิกของคุณจะคงที่แม้ว่าตัวอย่างด้านล่างจะเปลี่ยนไปตลอดเวลา
การจัดกลุ่มไดนามิกเมื่อสเกล
การออกแบบนี้สเกลในเชิงปฏิบัติการ: คุณไม่ต้องจัดการตัวตนของหลายพันอินสแตนซ์—คุณจัดการชุดป้ายไม่กี่ชุดที่มีความหมาย นี่คือแก่นของการผูกแบบหลวม: คอมโพเนนต์เชื่อมต่อกับ กลุ่ม ที่สามารถเปลี่ยนสมาชิกได้อย่างปลอดภัย
Labels ให้พลังมากกว่าการจัดกลุ่ม
เมื่อ labels มีอยู่ มันกลายเป็นคำศัพท์ร่วมกันในแพลตฟอร์ม พวกมันถูกใช้สำหรับการกำหนดเส้นทางทราฟฟิค (Services), ขอบเขตนโยบาย (NetworkPolicy), ตัวกรองการสังเกตการณ์ (metrics/logs), และแม้กระทั่งการติดตามต้นทุนและการคิดค่าใช้จ่าย แนวคิดง่าย ๆ เดียว—ติดแท็กสิ่งต่าง ๆ ให้สม่ำเสมอ—ปลดล็อกระบบอัตโนมัติทั้งระบบ
การตัดสินใจที่ 5: Services เพื่อเครือข่ายที่เสถียร
Kubernetes ต้องการวิธีทำให้เครือข่ายรู้สึกคาดเดาได้แม้ว่าคอนเทนเนอร์จะไม่คงที่ Pods ถูกแทนที่ ย้ายที่ และสเกลขึ้น/ลง—ดังนั้น IP และเครื่องที่รันจะเปลี่ยนได้ ความคิดหลักของ Service คือ: ให้ประตูหน้า (front door) คงที่ไปยังชุด Pod ที่เปลี่ยนแปลงได้
การเข้าถึงที่เสถียรไปยัง Pods ที่เปลี่ยน
Service ให้ IP เสมือนและชื่อ DNS คงที่ (เช่น payments) Kubernetes จะติดตาม Pod ที่ตรงกับ selector ของ Service อยู่ตลอดและส่งทราฟฟิคไปยังพวกมัน ถ้า Pod ตายและมี Pod ใหม่ปรากฏ Service จะยังชี้ไปยังจุดหมายที่ถูกต้องโดยไม่ต้องเปลี่ยนการตั้งค่าของแอป
การค้นพบ Service ที่ทำให้คอนฟิกง่ายขึ้น
แนวทางนี้ลดการต่อสายด้วยมือหลายอย่าง แทนที่จะฝัง IP ลงในไฟล์คอนฟิก แอปสามารถพึ่งพาชื่อได้ คุณปรับใช้แอป ปรับใช้ Service แล้วคอมโพแนนต์อื่นสามารถค้นหาผ่าน DNS—ไม่ต้องมีรีจิสทรีเฉพาะ ไม่ต้องตั้ง endpoints แบบคงที่
การบาลานซ์โหลดในตัวเพื่อความน่าเชื่อถือ
Services ยังแนะนำพฤติกรรมการกระจายโหลดพื้นฐานข้าม endpoints ที่พร้อมใช้งาน นั่นหมายความว่าทีมไม่ต้องสร้าง (หรือสร้างใหม่) load balancer สำหรับไมโครเซอร์วิสภายในแต่ละตัว การกระจายทราฟฟิคลดผลกระทบจากความล้มเหลวของ Pod เดียวและทำให้การอัปเดตแบบหมุนเวียนมีความเสี่ยงน้อยลง
ข้อจำกัด—และวิธีที่ Ingress/Gateway ขยายมัน
Service ดีสำหรับทราฟฟิค L4 (TCP/UDP) แต่ไม่จำลองกฎการกำหนดเส้นทาง HTTP, การยุติ TLS, หรือโพลิซีที่ขอบ นั่นคือที่ที่ Ingress และ, ในปัจจุบัน, Gateway API เข้ามา: พวกมันวางอยู่บน Services เพื่อจัดการ hostnames, paths, และจุดเข้าออกภายนอกได้สะอาดขึ้น
การตัดสินใจที่ 6: API เป็นผิวผลิตภัณฑ์
หนึ่งในการเลือกที่ค่อนข้างปฏิวัติในตอนต้นคือการปฏิบัติ Kubernetes เป็น API ที่คุณสร้างต่อ—ไม่ใช่เครื่องมือโมโนลิธที่คุณ "ใช้" การยึด API เป็นหัวใจทำให้ Kubernetes รู้สึกน้อยกว่าเป็นผลิตภัณฑ์ที่คลิกผ่าน และมากกว่าเป็นแพลตฟอร์มที่คุณสามารถขยาย เขียนสคริปต์ และควบคุมได้
ทำไมการเป็น API-first เปลี่ยนการสร้างแพลตฟอร์ม
เมื่อ API เป็นพื้นผิว ทีมแพลตฟอร์มสามารถทำมาตรฐานใน วิธี ที่แอปถูกอธิบายและจัดการ โดยไม่ขึ้นกับ UI, pipeline, หรือพอร์ทัลภายในที่วางอยู่ด้านบน “การปรับใช้แอป” กลายเป็น “การส่งและอัปเดตวัตถุ API” (เช่น Deployments, Services, ConfigMaps) ซึ่งเป็นสัญญาที่สะอาดกว่าระหว่างทีมแอปและแพลตฟอร์ม
เครื่องมือ UI และอัตโนมัติโดยไม่ต้องเข้าถึงพิเศษ
เพราะทุกอย่างผ่าน API เดียวกัน การสร้างเครื่องมือใหม่ไม่จำเป็นต้องมี backdoor ที่มีสิทธิพิเศษ แดชบอร์ด, GitOps controllers, engines นโยบาย, และระบบ CI/CD สามารถทำงานเป็นไคลเอนต์ API ปกติโดยมีสิทธิจำกัดอย่างเหมาะสม
ความสมมาตรนี้สำคัญ: กฎ เดียวกัน การพิสูจน์ตัวตน การตรวจสอบ และ admission controls ใช้ได้ไม่ว่าจะเป็นคำขอจากคน สคริปต์ หรือ UI ภายใน
การเวอร์ชันและความเข้ากันได้สำหรับคลัสเตอร์ระยะยาว
การเวอร์ชัน API ทำให้สามารถพัฒนา Kubernetes โดยไม่ทำลายคลัสเตอร์หรือเครื่องมือทั้งหมดในชั่วข้ามคืน การยกเลิกใช้งานสามารถทำเป็นลำดับขั้น; ความเข้ากันได้สามารถทดสอบ; การอัปเกรดสามารถวางแผน สำหรับองค์กรที่รันคลัสเตอร์มาหลายปี นี่คือความแตกต่างระหว่าง “เราสามารถอัปเกรดได้” กับ “เราติดอยู่"
kubectl แสดงอะไรจริง ๆ
kubectl ไม่ใช่ Kubernetes—มันเป็น ลูกค้า หนึ่งตัว แบบคิดนี้ผลักดันให้ทีมคิดเป็นเวิร์กโฟลว์ API: คุณสามารถสลับ kubectl กับการอัตโนมัติ, เว็บ UI, หรือพอร์ทัลเฉพาะของคุณ และระบบยังคงสอดคล้องเพราะสัญญาคือ API เอง
การตัดสินใจที่ 7: สถานะคลัสเตอร์ศูนย์กลาง (etcd) และความสอดคล้อง
พัฒนาโดยคิดแบบ desired-state
สร้างบริการขนาดเล็กที่มี API เสถียร แล้วขัดเกลาเหมือนลูปตัวควบคุม.
Kubernetes ต้องการ “แหล่งความจริง” เดียวว่าคลัสเตอร์ควรมีหน้าตาอย่างไรตอนนี้: Pod ไหนมีอยู่ โหนดไหนมีสุขภาพดี Service ชี้ไปที่ไหน และวัตถุใดกำลังอัปเดต นั่นคือสิ่งที่ etcd ให้มา
etcd ทำอะไร (แบบเข้าใจง่าย)
etcd คือฐานข้อมูลของ control plane. เมื่อคุณสร้าง Deployment, ปรับขนาด ReplicaSet, หรืออัปเดต Service การกำหนดค่าที่ต้องการจะถูกเขียนลงใน etcd controllers และองค์ประกอบ control-plane อื่น ๆ จะเฝ้าดูสถานะที่เก็บไว้และพยายามทำให้ความจริงตรงกับมัน
ทำไมความสอดคล้องถึงสำคัญเมื่อทุกอย่างทำงานพร้อมกัน
คลัสเตอร์ Kubernetes เต็มไปด้วยส่วนที่เคลื่อนไหว: scheduler, controllers, kubelets, autoscalers, และ admission checks ต่างก็สามารถตอบสนองพร้อมกัน หากพวกเขาอ่านเวอร์ชันที่ต่างกันของ “ความจริง” คุณจะได้การแข่งขัน—เช่น สององค์ประกอบตัดสินใจขัดแย้งเกี่ยวกับ Pod เดียวกัน
ความสอดคล้องเข้มแข็งของ etcd ทำให้เมื่อ control plane บอกว่า “นี่คือสถานะปัจจุบัน” ทุกคนตรงกัน การสอดคล้องนั้นคือสิ่งที่ทำให้ control loops คาดเดาได้แทนที่จะเป็นความโกลาหล
มันส่งผลต่อการสำรอง การอัปเกรด และการกู้ภัยอย่างไร
เพราะ etcd ถือการกำหนดค่าคลัสเตอร์และประวัติการเปลี่ยนแปลง มันจึงเป็นสิ่งที่คุณต้องปกป้องเมื่อ:
- สำรองข้อมูล: ถ้าไม่มี snapshot ของ etcd จะไม่สามารถกู้คืนวัตถุคลัสเตอร์ได้อย่างเชื่อถือ
- อัปเกรด: สุขภาพ etcd ที่ระมัดระวังและการถ่ายสแนปชอตลดความเสี่ยงในการอัปเกรด
- กู้ภัย: การคืนค่า etcd มักเป็นทางที่เร็วที่สุดในการกู้ control plane ให้กลับมาพร้อมเจตนาเดิม
คำแนะนำเชิงปฏิบัติ
ปฏิบัติต่อสถานะ control-plane เหมือนข้อมูลสำคัญ จัดทำ สแนปชอต etcd เป็นประจำ ทดสอบการคืนค่า และเก็บสำรองนอกคลัสเตอร์ หากคุณใช้ Kubernetes แบบมีผู้ให้บริการ จงเรียนรู้ว่าผู้ให้บริการสำรองอะไรให้—และอะไรที่คุณยังต้องสำรองเอง (เช่น persistent volumes และข้อมูลระดับแอป)
การตัดสินใจที่ 8: การจัดตารางแบบ pluggable และการรับรู้ทรัพยากร
Kubernetes ไม่มองว่า “จะรันวอร์กโหลดที่ไหน” เป็นเรื่องรอง ตั้งแต่ต้น scheduler ถูกแยกเป็นคอมโพเนนต์ที่ชัดเจนด้วยงานหนึ่ง: จับคู่ Pods กับโหนดที่สามารถรันพวกมันได้ โดยใช้สถานะคลัสเตอร์ปัจจุบันและความต้องการของ Pod
ตัว scheduler จับคู่วอร์กโหลดกับโหนดอย่างไร
ในภาพรวม การจัดตารางคือการตัดสินใจสองขั้น:
- กรอง: ตัดโหนดที่ไม่ผ่านเงื่อนไขแข็ง (CPU/หน่วยความจำไม่พอ, ขาด labels ที่ต้องการ, taints ไม่เข้ากัน, พอร์ตถูกใช้แล้ว ฯลฯ)
- ให้คะแนน: จัดอันดับโหนดที่เหลือตามความชอบ (กระจายข้ามโซน, จัดบรรจุเพื่อประสิทธิภาพ, หลีกเลี่ยงเพื่อนบ้านที่ดัง, เคารพ affinity rules)
โครงสร้างนี้ทำให้สามารถพัฒนา scheduling ของ Kubernetes ต่อไปได้โดยไม่ต้องเขียนใหม่ทั้งหมด
การแยกความรับผิดชอบ: scheduler vs runtime vs networking
การตัดสินใจสำคัญคือการเก็บความรับผิดชอบให้ชัดเจน:
- scheduler ตัดสินใจเรื่อง การวางตำแหน่ง
- container runtime (และ kubelet) ทำการ รัน บนโหนดที่เลือก
- เลเยอร์เครือข่าย ให้ การเชื่อมต่อ เมื่อทุกอย่างรันแล้ว
เพราะความรับผิดชอบถูกแยก การปรับปรุงในด้านหนึ่ง (เช่น plugin CNI ใหม่) จะไม่บังคับให้เปลี่ยนโมเดล scheduling
ข้อจำกัดและลำดับความสำคัญเติบโตขึ้นเป็นธรรมชาติ
การรับรู้ทรัพยากรเริ่มจาก requests และ limits ให้สัญญาณที่มีความหมายแก่ scheduler แทนการเดา จากนั้น Kubernetes เพิ่มการควบคุมที่ร่ำรวยขึ้น—node affinity/anti-affinity, pod affinity, priorities and preemption, taints and tolerations, และการกระจายตาม topology—สร้างบนรากฐานเดียวกัน
ผลกระทบสมัยใหม่: multi-tenant และการวางที่คุ้มค่า
แนวทางนี้ช่วยให้เกิดคลัสเตอร์ที่แชร์กันในปัจจุบัน: ทีมสามารถแยกบริการสำคัญด้วย priorities และ taints ขณะเดียวกันทุกคนก็ได้ประโยชน์จากการใช้ทรัพยากรที่สูงขึ้น ด้วยการจัดบรรจุที่ดีขึ้นและการควบคุม topology แพลตฟอร์มสามารถวางวอร์กโหลดได้คุ้มค่ากว่าโดยไม่แลกกับความน่าเชื่อถือ
การตัดสินใจที่ 9: ขยายได้มากกว่าการบังคับ "วิธีในตัวเดียว"
เปลี่ยนความตั้งใจเป็นแอปที่รันได้
สร้างแอปจริงจากการแชทและดูว่าคุณสามารถวนรอบพัฒนาได้เร็วแค่ไหนกับ Koder.ai.
Kubernetes อาจส่งมาพร้อมประสบการณ์แพลตฟอร์มที่เต็มรูปแบบ—buildpacks, กฎการกำหนดเส้นทางแอป, งานพื้นหลัง, ขนบในการตั้งค่า ฯลฯ แต่ Joe Beda และทีมตอนแรกเลือกให้ core มุ่งสัญญาที่เล็กกว่า: รันและซ่อมแซมวอร์กโหลดอย่างน่าเชื่อถือ เปิดเผยพวกมัน และให้ API สอดคล้องเพื่ออัตโนมัติ
ทำไม Kubernetes ไม่พยายามเป็น PaaS เต็มตัว
PaaS ที่สมบูรณ์จะบังคับเวิร์กโฟลว์เดียวและชุดการแลกเปลี่ยนหนึ่งชุดแก่ทุกคน Kubernetes มุ่งสู่พื้นฐานที่กว้างกว่าเพื่อรองรับสไตล์แพลตฟอร์มหลากหลาย—แบบง่ายเหมือน Heroku, การกำกับดูแลองค์กร, pipeline สำหรับ batch + ML, หรือการควบคุมโครงสร้างพื้นฐานแบบเปลือย—โดยไม่ล็อกอินสู่ปรัชญาผลิตภัณฑ์เดียว
วิธีที่ส่วนขยายให้แพลตฟอร์มเพิ่มฟีเจอร์ได้อย่างปลอดภัย
กลไกการขยายของ Kubernetes สร้างวิธีการที่ควบคุมได้ในการเติบโตความสามารถ:
- CRDs (CustomResourceDefinitions) ให้คุณเพิ่มชนิด API ใหม่ (เช่น
CertificateหรือDatabase) ที่มีความรู้สึกเหมือนเนทีฟ - Controllers/operators ประสานทรัพยากรใหม่เหล่านั้นโดยใช้รูปแบบ desired-state เดียวกับส่วนประกอบในตัว
- Admission controllers/webhooks บังคับหรือตั้งค่านโยบายที่ขอบ API
นั่นหมายความว่าทีมแพลตฟอร์มภายในและผู้ขายสามารถส่งมอบฟีเจอร์เป็น add-on ขณะที่ยังใช้ primitives ของ Kubernetes เช่น RBAC, namespaces, และ audit logs
ข้อดี—และความเสี่ยงหลัก
สำหรับผู้ขาย มันทำให้สามารถสร้างผลิตภัณฑ์แตกต่างกันโดยไม่ต้องแตกโค้ด Kubernetes สำหรับทีมภายใน มันเปิดทางให้ “แพลตฟอร์มบน Kubernetes” ที่ปรับแต่งได้ตามความต้องการองค์กร
ข้อแลกเปลี่ยนคือการกระจายของระบบนิเวศ: CRDs มากเกินไป, เครื่องมือทับซ้อน, และขนบปฏิบัติที่ไม่สอดคล้องกัน การกำกับดูแล—มาตรฐาน ความเป็นเจ้าของ การเวอร์ชัน และกฎการยกเลิก—กลายเป็นงานส่วนหนึ่งของการสร้างแพลตฟอร์ม
การตัดสินใจเหล่านี้หล่อหลอมแพลตฟอร์มแอปสมัยใหม่อย่างไร
การเลือกตั้งต้นของ Kubernetes ไม่ได้สร้างเพียง scheduler คอนเทนเนอร์—แต่สร้าง เคอร์เนลแพลตฟอร์ม ที่นำกลับมาใช้ได้ นั่นคือเหตุผลที่แพลตฟอร์มพัฒนาภายในสมัยใหม่ (IDPs) หลายแห่งมีแกนกลางเป็น “Kubernetes บวกเวิร์กโฟลว์ที่มีความเห็นชอบ” โมเดลเชิงประกาศ controllers และ API ที่สอดคล้องกันทำให้เป็นไปได้สร้างผลิตภัณฑ์ระดับสูงขึ้นโดยไม่ต้องคิดใหม่เรื่องการปรับใช้ การประสาน และการค้นหาระบบทุกครั้ง
Kubernetes เป็น control plane ร่วม
เพราะ API คือพื้นผิวผลิตภัณฑ์ ผู้ขายและทีมแพลตฟอร์มสามารถทำมาตรฐานบน control plane เดียวและสร้างประสบการณ์ต่าง ๆ บนมัน: GitOps, การจัดการหลายคลัสเตอร์, นโยบาย, service catalogs, และการอัตโนมัติการปรับใช้ นี่เป็นเหตุผลสำคัญที่ Kubernetes กลายเป็นตัวส่วนร่วมสำหรับแพลตฟอร์ม cloud native: การผสานรวมมุ่งเป้าที่ API ไม่ใช่ UI ใด UI หนึ่ง
สิ่งที่ยังคงยาก (ความเป็นจริงของ Day-2)
แม้จะมีนามธรรมที่ชัดเจน งานที่ยากที่สุดยังคงเป็นการปฏิบัติการ:
- ความปลอดภัย: ตัวตน, network policy, ความลับ, และความเชื่อถือใน supply chain
- การอัปเกรด: เวอร์ชัน Kubernetes, CRDs, และ add-ons เคลื่อนไหวด้วยความเร็วต่างกัน
- ความน่าเชื่อถือ: การดีบัก controllers, การตั้งค่าผิดพลาด, และ noisy neighbors
วิธีประเมินแพลตฟอร์มที่ใช้ Kubernetes
ถามคำถามที่เปิดเผยความพร้อมปฏิบัติการ:
- การอัปเกรดจัดการอย่างไร และเรื่องการย้อนกลับเป็นอย่างไร?
- ส่วนใดเป็น Kubernetes มาตรฐาน กับส่วนใดเป็นส่วนขยายเฉพาะ?
- มี guardrails ใด (นโยบาย ค่าเริ่มต้น เทมเพลต) เพื่อป้องกันการยิงตัวเองหรือไม่?
- ระบบสังเกตการณ์เป็นอย่างไร (events, logs, audit trails) และใครเป็นผู้รับผิดชอบเหตุการณ์?
แพลตฟอร์มที่ดีลดภาระทางความคิดโดยไม่ซ่อน control plane พื้นฐานหรือทำให้ทางหนี (escape hatches) ยาก
เลนส์ปฏิบัติหนึ่ง: แพลตฟอร์มช่วยให้ทีมเปลี่ยนจาก “ไอเดีย → บริการที่รันอยู่” ได้โดยไม่บังคับให้ทุกคนเป็นผู้เชี่ยวชาญ Kubernetes ตั้งแต่วันแรกหรือไม่? เครื่องมือในกลุ่ม “vibe-coding”—เช่น Koder.ai—เน้นในจุดนี้โดยให้ทีมสร้างแอปจริงจากการแชท (เว็บใน React, backend ใน Go กับ PostgreSQL, มือถือใน Flutter) แล้ววนรอบอย่างรวดเร็วด้วยฟีเจอร์อย่างโหมดวางแผน, สแนปชอต, และการย้อนกลับ ไม่ว่าคุณจะเลือกเครื่องมือแบบนั้นหรือสร้างพอร์ทัลของตัวเอง เป้าหมายก็เหมือนกัน: รักษา primitives ที่แข็งแกร่งของ Kubernetes ในขณะลดภาระเวิร์กโฟลว์รอบ ๆ พวกมัน
ข้อสรุปสำคัญและบทเรียนเชิงปฏิบัติ
Kubernetes อาจดูซับซ้อน แต่ความประหลาดใจส่วนใหญ่ของมันเป็นเรื่องมีเจตนา: มันคือชุด primitive เล็ก ๆ ที่ออกแบบมาให้ประกอบกันเป็นแพลตฟอร์มหลายรูปแบบ
เคลียร์ความเข้าใจผิดสองประการ
แรก: “Kubernetes คือแค่การออร์เคสตรา Docker.” Kubernetes ไม่ได้หมายถึงการเริ่มคอนเทนเนอร์เป็นหลัก แต่มันคือการประสาน desired state (สิ่งที่คุณต้องการให้รัน) กับ actual state (สิ่งที่รันจริง) ต่อหน้าความล้มเหลว การ rollout และความต้องการที่เปลี่ยนแปลง
ที่สอง: “ถ้าเราใช้ Kubernetes ทุกอย่างจะกลายเป็น microservices.” Kubernetes รองรับ microservices แต่ก็รองรับ monoliths, batch jobs, และแพลตฟอร์มภายใน หน่วยต่าง ๆ (Pods, Services, labels, controllers, และ API) เป็นกลาง; การตัดสินใจสถาปัตยกรรมของคุณไม่ได้ถูกบังคับโดยเครื่องมือ
ความซับซ้อนมาจากตรงไหนจริง ๆ
ส่วนที่ยากมักไม่ใช่ YAML หรือ Pods—แต่เป็น เครือข่าย ความปลอดภัย และการใช้งานโดยหลายทีม: ตัวตนและการเข้าถึง, การจัดการความลับ, นโยบาย, ingress, การสังเกตการณ์, การควบคุม supply-chain, และการสร้าง guardrails เพื่อให้ทีมส่งมอบอย่างปลอดภัยโดยไม่ขัดกัน
ข้อสรุปเชิงการตัดสินใจที่ใช้ได้จริง
เมื่อวางแผน คิดในเชิงเดิมพันการออกแบบเดิม:
- ชอบเวิร์กโฟลว์แบบ เชิงประกาศ และการอัตโนมัติที่ปรับความเบี่ยงเบนได้
- ใช้ labels/selectors เพื่อลดการผูกกันระหว่างทีมและคอมโพเนนต์
- ปฏิบัติ API เป็นผลิตภัณฑ์: การเวอร์ชัน คอนเวนชัน และความเป็นเจ้าของสำคัญ
ขั้นตอนถัดไปเชิงปฏิบัติ
แมปความต้องการจริงของคุณไปยัง primitives และเลเยอร์แพลตฟอร์มของ Kubernetes:
-
Workloads → Pods/Deployments/Jobs
-
Connectivity → Services/Ingress
-
Operations → controllers, นโยบาย, และการสังเกตการณ์
ถ้าคุณกำลังประเมินหรือนำมาตรฐานมาใช้ ให้เขียนแผนที่นี้ลงแล้วทบทวนกับผู้มีส่วนได้ส่วนเสีย—แล้วสร้างแพลตฟอร์มของคุณทีละส่วนตามช่องว่าง ไม่ใช่ตามเทรนด์
ถ้าคุณต้องการเร่งด้านการ “สร้าง” ไม่ใช่แค่การ “รัน” ให้คิดว่าเวิร์กโฟลว์การส่งมอบของคุณเปลี่ยนเจตนาเป็นบริการที่ปรับใช้ได้อย่างไร สำหรับบางทีมคือชุดเทมเพลตที่คัดสรรไว้; สำหรับบางทีมคือเวิร์กโฟลว์ที่ช่วยด้วย AI อย่าง Koder.ai ที่สามารถสร้างบริการพื้นฐานได้อย่างรวดเร็วแล้วส่งออกซอร์สโค้ดเพื่อปรับแต่งต่อ—ขณะที่แพลตฟอร์มของคุณยังคงได้ประโยชน์จากการตัดสินใจเชิงออกแบบของ Kubernetes ข้างใต้
คำถามที่พบบ่อย
การออร์เคสตราคอนเทนเนอร์หมายถึงอะไรแบบง่าย ๆ?
Container orchestration คือการอัตโนมัติที่ทำให้แอปยังรันได้เมื่อเครื่องล้มเหลว ปริมาณทราฟฟิคเปลี่ยน หรือเกิดการปรับใช้ ในทางปฏิบัติจะจัดการ:
- การจัดตารางคอนเทนเนอร์ไปยังโหนด
- การรีสตาร์ทงานที่ล้มเหลว
- การปรับขนาดขึ้น/ลง
- การเชื่อมต่อเครือข่ายเพื่อให้บริการค้นหากันเจอ
- การอัปเดตแบบหมุนเวียนและการย้อนกลับ
Kubernetes ทำให้เกิดโมเดลที่สอดคล้องกันสำหรับการทำงานเหล่านี้ข้ามสภาพแวดล้อมโครงสร้างพื้นฐานที่ต่างกัน.
Kubernetes ในตอนแรกพยายามแก้ปัญหาอะไร?
ปัญหาหลักไม่ใช่การเริ่มคอนเทนเนอร์—แต่เป็นการรักษาให้คอนเทนเนอร์ที่ ถูกต้อง ทำงานในรูปร่างที่ ถูกต้อง ท่ามกลางการเปลี่ยนแปลงอย่างต่อเนื่อง ที่ระดับใหญ่ระบบจะล้มเหลวเป็นประจำและเกิดการเบี่ยงเบนจากสถานะที่คาดไว้ เช่น:
- โหนดหายหรือล้มเหลว
- การปรับใช้ถูกนำไปใช้ไม่ครบถ้วน
- IP เปลี่ยนเมื่อตัว Pod ถูกแทนที่
- มนุษย์แก้ไขสิ่งต่าง ๆ ในวิธีที่ไม่ได้ถูกบันทึก
Kubernetes มุ่งหมายที่จะทำให้งานปฏิบัติการทำซ้ำได้และคาดการณ์ได้ด้วยการให้ control plane และศัพท์กลางที่เป็นมาตรฐาน.
ทำไม Kubernetes ถึงเป็น “เชิงประกาศ” และ desired state ให้ประโยชน์อะไร?
ในระบบแบบ declarative คุณอธิบาย ผลลัพธ์ ที่ต้องการ (เช่น “ให้รัน 3 สำเนา”) แล้วระบบจะทำงานอย่างต่อเนื่องเพื่อให้ความจริงตรงกับความต้องการ
เวิร์กโฟลว์เชิงปฏิบัติ:
- ใส่เจตนาในคอนฟิก (YAML หรือ manifests ที่สร้างขึ้น)
- นำไปใช้ (
kubectl applyหรือ GitOps) - ให้ controllers ประสานงานเมื่อเกิดความผิดพลาดหรือการเบี่ยงเบน
นี่ช่วยลด “เช็คลิสต์ที่ซ่อนอยู่” และทำให้การเปลี่ยนแปลงตรวจสอบได้เป็น diff แทนคำสั่งแบบ ad-hoc.
Kubernetes controllers คืออะไร และทำไมถึงสำคัญต่อความน่าเชื่อถือ?
Controllers เป็นลูปควบคุมที่ทำซ้ำ:
- สังเกตสถานะปัจจุบัน
- เปรียบเทียบกับสถานะที่ต้องการ
- ดำเนินการจนกว่าจะตรงกัน
การออกแบบนี้ทำให้ความผิดพลาดทั่วไปกลายเป็นเรื่องปกติแทนที่จะเป็นกรณีพิเศษ ตัวอย่างเช่น ถ้า Pod ล้มเหลวหรือโหนดหาย ตัว controller ที่เกี่ยวข้องก็จะเห็นว่า “เรามีสำเนาน้อยกว่าที่ต้องการ” และสร้างตัวทดแทนขึ้นมาเอง.
ทำไม Kubernetes จึงใช้ Pods แทนการตารางคอนเทนเนอร์เดี่ยว?
Kubernetes ทำการจัดตารางเป็น Pod (ไม่ใช่คอนเทนเนอร์เดี่ยว) เพราะหลายงานจริงต้องการกระบวนการช่วยเหลือที่อยู่ใกล้เคียงกัน
Pods อำนวยความสะดวกให้รูปแบบเช่น:
- Sidecars (proxy, log shipper, config reloader)
- เครือข่ายร่วมกัน (
localhostระหว่างคอนเทนเนอร์) - การแชร์พื้นที่เก็บข้อมูลผ่าน volumes
กฎง่าย ๆ: รวมคอนเทนเนอร์เฉพาะที่ต้องแชร์วงจรชีวิต ตัวตนเครือข่าย หรือข้อมูลท้องถิ่นเข้าด้วยกันเท่านั้น.
ป้าย (labels) กับ selectors ช่วยลดการผูกกันแน่นใน Kubernetes อย่างไร?
Labels เป็นแท็ก key/value เบา ๆ (เช่น app=checkout, env=prod) ในขณะที่ selectors คือการสืบค้นจากป้ายเหล่านั้นเพื่อสร้างกลุ่มแบบไดนามิก
สิ่งนี้สำคัญเพราะตัวอย่างนั้นมีชีวิตสั้น: Pods เกิดและหายไประหว่างการย้ายและ rollout ด้วย labels/selectors ความสัมพันธ์ยังคงคงตัว (“Pod ทั้งหมดที่มีป้ายเหล่านี้”) แม้ว่าสมาชิกจะเปลี่ยนไป
เคล็ดลับเชิงปฏิบัติ: กำหนด taxonomy ป้ายเล็ก ๆ (app, team, env, tier) และบังคับใช้ด้วยนโยบายเพื่อหลีกเลี่ยงความสับสนในภายหลัง.
Kubernetes Service ทำอะไร และควรใช้เมื่อไร?
Service ให้ IP เสมือนและชื่อ DNS ที่คงที่ซึ่งชี้ไปยังกลุ่ม Pod ที่เปลี่ยนแปลงได้ตาม selector
ใช้ Service เมื่อ:
- เบื้องหลังมีการทำซ้ำและ Pod จะถูกแทนที่เป็นประจำ
- ลูกค้าควรพึ่งพาชื่อคงที่ ไม่ใช่ IP ของ Pod
- ต้องการการกระจายโหลดระหว่าง endpoints
สำหรับการกำหนดเส้นทาง HTTP, การยุติ TLS และกฎ edge มักจะวาง Ingress หรือ Gateway API บน Services อีกชั้นหนึ่ง.
ทำไมการออกแบบแบบ “API-first” ถึงสำคัญใน Kubernetes?
Kubernetes มอง API เป็นพื้นผิวผลิตภัณฑ์หลัก: ทุกอย่างเป็นวัตถุ API (Deployments, Services, ConfigMaps ฯลฯ) เครื่องมือทั้งหลาย—รวมถึง kubectl, CI/CD, GitOps, dashboard—เป็นแค่ไคลเอนต์ API
ประโยชน์เชิงปฏิบัติ:
- การพิสูจน์ตัวตน การตรวจสอบ และนโยบายที่สอดคล้องผ่าน API
- อัตโนมัติเคลื่อนไม่ต้องใช้ "ช่องทางพิเศษ"
- การเวอร์ชันและความเข้ากันได้สำหรับคลัสเตอร์ที่ใช้งานยาวนาน
ถ้าคุณกำลังสร้างแพลตฟอร์มภายใน ให้วางเวิร์กโฟลว์บนสัญญา API แทนที่จะยึดติดกับเครื่องมือ UI ตัวใดตัวหนึ่ง.
etcd คืออะไร และทีมควรทำอย่างไรกับการสำรองและกู้คืน?
etcd คือฐานข้อมูลของ control plane และแหล่งข้อมูลเดียวที่บอกว่าคลัสเตอร์ควรมีหน้าตาเป็นอย่างไร ตอนที่คุณสร้าง Deployment หรืออัปเดต Service การกำหนดค่าที่ต้องการจะถูกเขียนลงใน etcd และ controllers จะเฝ้ามองสถานะนั้นแล้วทำให้ความจริงตรงกับมัน
คำแนะนำเชิงปฏิบัติ:
- ปฏิบัติต่อ etcd เหมือนข้อมูลสำคัญ
- ทำสแนปชอตเป็นประจำ
- ทดสอบการกู้คืน ไม่ใช่แค่สำรองข้อมูล
ในบริการ Kubernetes แบบมีผู้จัดการ ให้เรียนรู้ว่าผู้ให้บริการสำรองอะไรให้คุณและอะไรที่คุณยังต้องสำรองเอง (เช่น persistent volumes และข้อมูลของแอป).
การขยายผ่าน CRDs/operators มีผลต่อแพลตฟอร์มสมัยใหม่อย่างไร และควรระวังอะไร?
Kubernetes เก็บแกนเล็กไว้และให้คุณเพิ่มความสามารถผ่านนามธรรมขยาย:
- CRDs เพื่อกำหนดชนิด API ใหม่
- Controllers/operators เพื่อประสานทรัพยากรเหล่านั้น
- Admission webhooks เพื่อบังคับหรือตั้งค่าเริ่มต้นนโยบาย
สิ่งนี้ทำให้เกิด “แพลตฟอร์มบน Kubernetes” แต่ก็อาจนำไปสู่การกระจุกของเครื่องมือและนิสัยที่ไม่สอดคล้องกัน
พิจารณาเมื่อประเมินแพลตฟอร์ม Kubernetes:
-
อะไรเป็น Kubernetes มาตรฐาน กับอะไรเป็นส่วนขยายเฉพาะ?
-
การอัปเกรดจัดการและย้อนกลับอย่างไร?
-
มีการป้องกันการตั้งค่าผิดพลาดอย่างไร?
-
ใครรับผิดชอบ day-2 operations (observability, incident response)?