22 ก.ย. 2568·3 นาที
Kafka คืออะไร และถูกใช้ในระบบสมัยใหม่อย่างไร?
เรียนรู้ว่า Apache Kafka คืออะไร วิธีการทำงานของ topics และ partitions และ Kafka อยู่ตรงไหนในระบบสมัยใหม่สำหรับเหตุการณ์เรียลไทม์ ล็อก และพายไลน์ข้อมูล
เรียนรู้ว่า Apache Kafka คืออะไร วิธีการทำงานของ topics และ partitions และ Kafka อยู่ตรงไหนในระบบสมัยใหม่สำหรับเหตุการณ์เรียลไทม์ ล็อก และพายไลน์ข้อมูล
Apache Kafka เป็นแพลตฟอร์มสตรีมอีเวนต์แบบกระจาย (distributed event streaming platform) ง่ายๆ คือ มันเป็น “ท่อ” ที่ใช้ร่วมกันและทนทาน ที่ให้หลายระบบเขียนข้อเท็จจริงเกี่ยวกับสิ่งที่เกิดขึ้น และให้ระบบอื่นอ่านข้อเท็จจริงเหล่านั้นได้—อย่างรวดเร็ว ในระดับใหญ่ และตามลำดับ
ทีมมักใช้ Kafka เมื่อข้อมูลต้องย้ายระหว่างระบบอย่างเชื่อถือได้โดยไม่ผูกติดแน่นเกินไป แทนที่จะให้แอปหนึ่งเรียกอีกแอปโดยตรง (ซึ่งจะล้มเหลวเมื่อถูกปิดหรือช้า) ผู้ผลิตจะเขียนเหตุการณ์ลง Kafka ผู้บริโภคจะอ่านเมื่อพร้อม Kafka เก็บเหตุการณ์ไว้ตามช่วงเวลาที่กำหนด ทำให้ระบบสามารถกู้คืนจากการขัดข้องและประมวลผลประวัติย้อนหลังได้
ไกด์นี้เหมาะกับวิศวกรที่คิดแบบผลิตภัณฑ์, คนด้านข้อมูล, และผู้นำทางเทคนิคที่ต้องการแบบจำลองความคิดใช้งานได้ของ Kafka
คุณจะได้เรียนรู้ส่วนประกอบหลัก (producers, consumers, topics, brokers), วิธีการขยายด้วยพาร์ติชัน, วิธีการเก็บและเล่นเหตุการณ์ซ้ำ, และที่ตั้งของ Kafka ในสถาปัตยกรรมขับเคลื่อนด้วยเหตุการณ์ เราจะครอบคลุมกรณีการใช้งานทั่วไป การรับประกันการส่งมอบ พื้นฐานความปลอดภัย การวางแผนการดำเนินงาน และเมื่อใดที่ Kafka เหมาะ (หรือไม่เหมาะ) เป็นเครื่องมือ
Kafka อธิบายง่ายที่สุดว่าเป็นล็อกเหตุการณ์ที่ใช้ร่วมกัน: แอปเขียนเหตุการณ์เข้าไป และแอปอื่นอ่านเหตุการณ์เหล่านั้นทีหลัง—บ่อยครั้งแบบเรียลไทม์ บางครั้งเป็นชั่วโมงหรือวันให้หลัง
Producers คือผู้เขียน ตัวอย่างเช่น producer อาจส่งเหตุการณ์ว่า “order placed”, “payment confirmed” หรือ “temperature reading” Producers ไม่ส่งเหตุการณ์ไปยังแอปเจาะจงโดยตรง—พวกเขาส่งไปยัง Kafka
Consumers คือผู้อ่าน ผู้บริโภคอาจขับแดชบอร์ด กระตุ้นเวิร์กโฟลว์จัดส่ง หรือนำข้อมูลเข้าไปยังระบบวิเคราะห์ Consumers ตัดสินใจว่าจะทำอะไรกับเหตุการณ์และอ่านได้ตามจังหวะของตัวเอง
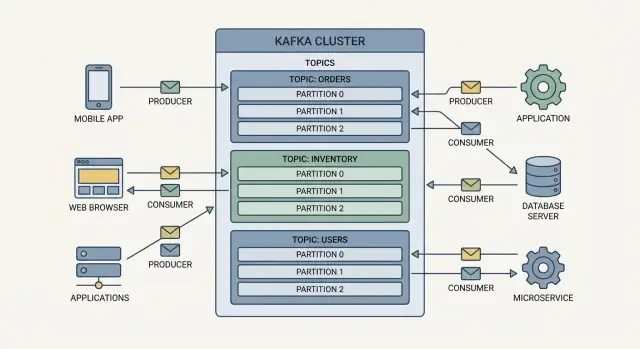
เหตุการณ์ใน Kafka ถูกจัดเป็น topics ซึ่งเป็นหมวดหมู่ที่ตั้งชื่อได้ เช่น:
orders สำหรับเหตุการณ์ที่เกี่ยวกับคำสั่งซื้อpayments สำหรับเหตุการณ์การชำระเงินinventory สำหรับการเปลี่ยนแปลงสต็อกหัวข้อกลายเป็น “สตรีมแหล่งข้อมูลจริง” สำหรับเหตุการณ์ชนิดนั้น ทำให้หลายทีมใช้ข้อมูลร่วมกันได้ง่ายขึ้นโดยไม่ต้องสร้างการผสานแบบเฉพาะกิจ
Broker คือเซิร์ฟเวอร์ Kafka ที่เก็บเหตุการณ์และให้บริการแก่ผู้บริโภค ในการใช้งานจริง Kafka รันเป็น คลัสเตอร์ (หลาย broker ร่วมกัน) เพื่อรองรับปริมาณงานมากขึ้นและยังทำงานได้แม้เครื่องบางตัวล้มเหลว
ผู้บริโภคมักรันใน consumer group Kafka จะแบ่งงานการอ่านไปยังกลุ่ม เพื่อให้สามารถเพิ่มอินสแตนซ์ผู้บริโภคเพื่อขยายการประมวลผลแบบขนาน—โดยที่ไม่ต้องให้ทุกอินสแตนซ์ทำงานเดียวกันทั้งหมด
Kafka ขยายตัวโดยการแบ่งงานเป็น topics (สตรีมของเหตุการณ์ที่เกี่ยวข้อง) แล้วแบ่งแต่ละหัวข้อเป็น partitions (ชิ้นย่อยอิสระของสตรีมนั้น)
หัวข้อที่มีพาร์ติชันเดียวอ่านได้โดยผู้บริโภคหนึ่งตัวภายใน consumer group เท่านั้น เพิ่มพาร์ติชันแล้วคุณสามารถเพิ่มผู้บริโภคเพื่อประมวลผลเหตุการณ์แบบขนานได้ นี่คือวิธีที่ Kafka รองรับการสตรีมอีเวนต์ปริมาณสูงและพายไลน์ข้อมูลเรียลไทม์โดยไม่ทำให้ระบบเป็นคอขวด
พาร์ติชันยังช่วยกระจายโหลดข้าม brokers แทนที่จะให้เครื่องเดียวจัดการการอ่าน/เขียนทั้งหมดของหัวข้อ โหนดหลายตัวสามารถโฮสต์พาร์ติชันต่างกันและแบ่งปันทราฟฟิกได้
Kafka รับประกัน การเรียงลำดับภายในพาร์ติชันเดียว หากเหตุการณ์ A, B, C ถูกเขียนในลำดับนั้นไปยังพาร์ติชันเดียวกัน ผู้บริโภคจะอ่านเป็น A → B → C
การเรียงลำดับข้ามพาร์ติชันไม่ได้รับประกัน หากต้องการการเรียงลำดับแบบเคร่งครัดสำหรับเอนทิตีเฉพาะ (เช่น ลูกค้าหรือคำสั่งซื้อ) โดยทั่วไปจะต้องมั่นใจว่าเหตุการณ์ทั้งหมดของเอนทิตีนั้นไปยังพาร์ติชันเดียวกัน
เมื่อ producers ส่งเหตุการณ์ พวกเขาสามารถใส่ key (เช่น order_id) Kafka จะใช้คีย์นั้นในการกำหนดเส้นทางให้เหตุการณ์ที่เกี่ยวข้องไปยังพาร์ติชันเดียวกันอย่างสม่ำเสมอ นั่นให้การเรียงลำดับที่คาดการณ์ได้สำหรับคีย์นั้น ขณะเดียวกันก็ยังให้หัวข้อขยายตัวได้ข้ามหลายพาร์ติชัน
แต่ละพาร์ติชันสามารถถูก จำลอง (replicate) ไปยัง brokers อื่นๆ หาก broker หนึ่งล้มเหลว อีก broker ที่มี replica สามารถรับหน้าที่แทนได้ การจำลองเป็นเหตุผลสำคัญที่ทำให้ Kafka ถูกเชื่อถือสำหรับ pub-sub messaging และระบบขับเคลื่อนด้วยเหตุการณ์ระดับองค์กร: มันเพิ่มความพร้อมใช้งานและรองรับความทนทานต่อความผิดพลาดโดยไม่ต้องให้แอปแต่ละตัวสร้างกลไก failover เอง
แนวคิดสำคัญของ Apache Kafka คือเหตุการณ์ไม่ได้แค่ส่งผ่านแล้วหายไป มันถูกเขียนลงดิสก์ในล็อกตามลำดับ ดังนั้นผู้บริโภคจึงอ่านได้ตอนนี้หรือภายหลัง ทำให้ Kafka มีประโยชน์ทั้งในการย้ายข้อมูลและเก็บประวัติที่ทนทานของสิ่งที่เกิดขึ้น
เมื่อ producer ส่งเหตุการณ์ไปยังหัวข้อ Kafka จะต่อท้ายเหตุการณ์นั้นไปยังการเก็บข้อมูลบน broker ผู้บริโภคอ่านจากล็อกที่เก็บไว้ตามจังหวะของตัวเอง หากผู้บริโภคดาวน์เป็นชั่วโมง เหตุการณ์ยังคงมีอยู่และสามารถตามทันได้เมื่อตัวมันกู้คืน
Kafka เก็บเหตุการณ์ตามนโยบาย retention:
การตั้ง retention เป็นระดับหัวข้อ ทำให้คุณจัดการหัวข้อ audit ให้ต่างจากหัวข้อเทเลเมทรีที่มีปริมาณมากได้
บางหัวข้อเป็นเหมือน changelog มากกว่าที่จะเป็นคลังประวัติ เช่น “การตั้งค่าลูกค้าปัจจุบัน” Log compaction จะเก็บอย่างน้อยเรคอร์ดล่าสุดต่อคีย์ ขณะที่เรคอร์ดเก่าที่ถูกแทนที่อาจถูกลบไป ทำให้คุณมีแหล่งความจริงของสถานะล่าสุดโดยไม่ให้ขนาดเติบโตไม่รู้จบ
เพราะเหตุการณ์ถูกเก็บไว้ คุณสามารถ เล่นซ้ำ เหตุการณ์เพื่อสร้างสถานะใหม่ได้ เช่น:
ในทางปฏิบัติ การเล่นซ้ำถูกควบคุมโดยตำแหน่งที่ผู้บริโภค “เริ่มอ่าน” (offset) ซึ่งให้ทีมมีเครื่อมือความปลอดภัยเมื่อต้องวิวัฒนาการระบบ
Kafka ถูกออกแบบมาให้ข้อมูลไหลต่อแม้บางส่วนของระบบจะล้ม มันทำได้โดยการ จำลอง, กฎชัดเจนว่าใครเป็น “หัวหน้า” ของพาร์ติชันแต่ละตัว, และการตั้งค่า acknowledgments ที่ปรับได้
แต่ละพาร์ติชันมี broker ตัวหนึ่งเป็น leader และมี follower หลายตัวบน brokers อื่น Producers และ consumers ติดต่อกับ leader ของพาร์ติชันนั้น
Followers คัดลอกข้อมูลจาก leader อย่างต่อเนื่อง หาก leader ล้ม Kafka สามารถโปรโมต follower ที่ทันข้อมูลมาเป็น leader ใหม่ ทำให้พาร์ติชันยังคงให้บริการได้
เมื่อ broker ล้ม พาร์ติชันที่มันเป็น leader อาจไม่พร้อมให้บริการชั่วขณะ คอนโทรลเลอร์ของ Kafka ตรวจจับความล้มเหลวและทริกเกอร์การเลือก leader ใหม่
ถ้ามี follower ที่ซิงค์เพียงพอ มันจะรับหน้าที่และไคลเอนต์จะกลับมาผลิต/บริโภคได้ หากไม่มี replica ที่ซิงค์ Kafka อาจหยุดเขียน (ขึ้นกับการตั้งค่า) เพื่อหลีกเลี่ยงการสูญเสียข้อมูลที่ถูกยืนยันแล้ว
สองตัวปรับหลักที่กำหนดความทนทานคือ:
โดยสรุป:
ทีมมักผสาน acks ที่ปลอดภัยกับ idempotent producers และการจัดการผู้บริโภคที่รัดกุมเพื่อลดการเกิดซ้ำเมื่อ retry
ความปลอดภัยสูงมักหมายถึงการรอการยืนยันมากกว่าและเก็บ replica ให้ซิงค์ ซึ่งอาจเพิ่มความล่าช้าและลด throughput สูงสุด
การตั้งค่าความหน่วงต่ำอาจเหมาะกับเทเลเมทรีหรือ clickstream ที่ยอมรับการสูญเสียบางส่วนได้ แต่ระบบชำระเงิน สต็อก และล็อกตรวจสอบมักคุ้มค่ากับการตั้งค่าความปลอดภัยสูงกว่า
สถาปัตยกรรมขับเคลื่อนด้วยเหตุการณ์ (EDA) คือการสร้างระบบที่สิ่งที่เกิดขึ้นในธุรกิจ—คำสั่งซื้อถูกวาง การชำระเงินยืนยัน พัสดุจัดส่ง—ถูกแทนด้วย เหตุการณ์ ให้ส่วนอื่นของระบบตอบสนอง
Kafka มักอยู่ตรงกลางของ EDA เป็น “สตรีมเหตุการณ์ร่วม” แทนที่ Service A จะเรียก Service B โดยตรง Service A เผยแพร่เหตุการณ์ (เช่น OrderCreated) ไปยังหัวข้อ Kafka บริการอื่นจำนวนมากสามารถ บริโภค เหตุการณ์นั้นและทำงาน—ส่งอีเมล จองสต็อก เริ่มการตรวจสอบการฉ้อโกง—โดยที่ Service A ไม่ต้องรู้ว่ามีใครอยู่
เพราะบริการสื่อสารผ่านเหตุการณ์ พวกมันไม่ต้องสร้าง API แบบ request/response สำหรับทุกการโต้ตอบ ลดการพึ่งพาแน่นระหว่างทีมและทำให้ง่ายขึ้นในการเพิ่มความสามารถใหม่: คุณสามารถเพิ่มผู้บริโภคใหม่สำหรับเหตุการณ์ที่มีอยู่โดยไม่ต้องเปลี่ยน producer
EDA เป็นแบบอะซิงโครนัส: producers เขียนเหตุการณ์เร็ว และ consumers ประมวลผลตามจังหวะของตัวเอง ระหว่างสปิค Kafka ช่วยบัฟเฟอร์การไหล ทำให้ระบบด้านล่างไม่พังทันที ผู้บริโภคสามารถขยายเพื่อไล่ตาม และถ้าผู้บริโภคตัวหนึ่งดาวน์ชั่วคราว มันจะกลับมาต่อจากที่ค้างไว้
คิดว่า Kafka เป็น “ฟีดกิจกรรม” ของระบบ ผู้ผลิตเผยแพร่ข้อเท็จจริง ผู้บริโภคสมัครรับข้อเท็จจริงที่สนใจ รูปแบบนี้ทำให้พายไลน์ข้อมูลเรียลไทม์และเวิร์กโฟลว์เชิงเหตุการณ์เป็นไปได้ ในขณะที่ยังคงทำให้บริการเรียบง่ายและอิสระกัน
Kafka จะปรากฏเมื่อทีมต้องย้าย "ข้อเท็จจริงที่เกิดขึ้น" จำนวนมากระหว่างระบบ—อย่างรวดเร็ว เชื่อถือได้ และให้หลายผู้บริโภคใช้ซ้ำได้
แอปมักต้องการประวัติแบบ append-only: การเข้าสู่ระบบของผู้ใช้ การเปลี่ยนแปลงสิทธิ์ การอัปเดตระเบียน หรือการกระทำของแอดมิน Kafka เหมาะเป็นสตรีมกลางของเหตุการณ์เหล่านี้ เพื่อให้เครื่องมือตรวจสอบ ความปลอดภัย และการส่งออกสำหรับการรายงาน/ยึดตามกฎสามารถอ่านแหล่งเดียวกันได้โดยไม่เพิ่มโหลดฐานข้อมูลการผลิต เพราะเหตุการณ์ถูกเก็บไว้นาน คุณยังสามารถเล่นซ้ำเพื่อสร้างมุมมอง audit ใหม่หลังเกิดบักหรือการเปลี่ยนสคีมา
แทนที่จะให้บริการเรียกกันโดยตรง พวกมันสามารถเผยแพร่เหตุการณ์ เช่น “order created” หรือ “payment received” บริการอื่นสมัครรับและตอบสนองตามเวลาของตัวเอง ลดการผูกมัด ช่วยให้ระบบทำงานในช่วงบางส่วนล้ม และทำให้เพิ่มความสามารถใหม่ง่ายขึ้น (เช่น ตรวจสอบการฉ้อโกง) โดยการบริโภคสตรีมที่มีอยู่
Kafka เป็นกระดูกสันหลังที่พบบ่อยสำหรับย้ายข้อมูลจากระบบปฏิบัติการไปยังแพลตฟอร์มวิเคราะห์ ทีมสามารถสตรีมการเปลี่ยนแปลงจากฐานข้อมูลแอปพลิเคชันและส่งไปยัง warehouse หรือ data lake ด้วยความหน่วงต่ำ และแยกงานวิเคราะห์หนักออกจากแอปการผลิต
เซนเซอร์ อุปกรณ์ และเทเลเมทรีของแอปมักมาถึงเป็นสปิค Kafka สามารถดูดซับการระเบิดของข้อมูล บัฟเฟอร์อย่างปลอดภัย และให้การประมวลผลด้านล่างไล่ตาม เหมาะสำหรับการมอนิเตอร์ แจ้งเตือน และการวิเคราะห์ระยะยาว
Kafka ไม่ได้มีแค่ brokers กับ topics ทีมส่วนใหญ่พึ่งพาเครื่องมือติดตั้งร่วมที่ทำให้ Kafka ใช้งานได้จริงสำหรับการย้ายข้อมูล การประมวลผลสตรีม และการดำเนินงาน
Kafka Connect เป็นกรอบงานสำหรับเชื่อมข้อมูล เข้า Kafka (sources) และ ออกจาก Kafka (sinks) แทนการสร้างพายไลน์แบบกำหนดเอง ให้รัน Connect และคอนฟิกคอนเน็กเตอร์
ตัวอย่างทั่วไปได้แก่ ดึงการเปลี่ยนแปลงจากฐานข้อมูล ดึงเหตุการณ์จาก SaaS หรือนำข้อมูล Kafka ไปยัง data warehouse หรือ object storage Connect ยังจัดการเรื่องการ retry, offsets, และการทำงานแบบขนาน
ถ้า Connect สำหรับอินทิเกรชัน Kafka Streams คือสำหรับการคำนวณ มันเป็นไลบรารีที่เพิ่มเข้าแอปของคุณเพื่อแปลงสตรีมแบบเรียลไทม์—กรอง เหมืองข้อมูล เสริมข้อมูล join ระหว่างสตรีม และสร้าง aggregate (เช่น “orders ต่อ นาที”)
เพราะ Streams แอปอ่านจากหัวข้อและเขียนกลับไปยังหัวข้อ มันจึงเข้ากันได้ดีกับระบบขับเคลื่อนด้วยเหตุการณ์และขยายได้โดยการเพิ่มอินสแตนซ์
เมื่อหลายทีมเผยแพร่เหตุการณ์ ความสอดคล้องมีความสำคัญ การจัดการสคีมา (มักผ่าน schema registry) กำหนดฟิลด์ของเหตุการณ์และวิธีวิวัฒนาการของมัน ช่วยป้องกันการพังเช่น producer เปลี่ยนชื่อฟิลด์ที่ consumer พึ่งพา
Kafka อ่อนไหวต่อการปฏิบัติการ ดังนั้นมอนิเตอร์พื้นฐานจึงจำเป็น:
ทีมส่วนใหญ่ยังใช้ UI สำหรับการจัดการและอัตโนมัติสำหรับการปรับใช้ การตั้งค่าหัวข้อ และนโยบายการควบคุมการเข้าถึง (ดู /blog/kafka-security-governance)
Kafka มักถูกอธิบายว่าเป็น “ล็อกที่ทนทาน + ผู้บริโภค” แต่สิ่งที่ทีมส่วนใหญ่สนใจจริงๆ คือ: เราจะประมวลผลแต่ละเหตุการณ์หนึ่งครั้งหรือไม่ และจะเกิดอะไรขึ้นเมื่อมีความล้มเหลว? Kafka ให้บล็อกก่อสร้างและคุณเลือกการแลกเปลี่ยนตามความต้องการ
At-most-once หมายความว่าอาจสูญเสียเหตุการณ์ แต่จะไม่ประมวลผลซ้ำ เกิดขึ้นเมื่อผู้บริโภคคอมมิตตำแหน่งก่อนและแครชก่อนจะทำงานให้เสร็จ
At-least-once หมายความว่าไม่สูญเสียเหตุการณ์ แต่เกิดซ้ำได้ (เช่น ผู้บริโภคประมวลผลเหตุการณ์ แครช แล้วประมวลผลซ้ำหลังรีสตาร์ท) นี่คือรูปแบบปกติ
Exactly-once มุ่งหลีกเลี่ยงทั้งการสูญหายและการซ้ำแบบ end-to-end ใน Kafka มักเกี่ยวข้องกับ transactional producers และการประมวลผลที่เข้ากันได้ (มักผ่าน Kafka Streams) มันทรงพลังแต่จำกัดมากกว่าและต้องตั้งค่าอย่างระมัดระวัง
ในทางปฏิบัติ หลายระบบรับ at-least-once และเพิ่มการป้องกัน:
Offset ของผู้บริโภคคือตำแหน่งของเรคอร์ดสุดท้ายที่ประมวลผลในพาร์ติชัน เมื่อคุณคอมมิต offset คุณกำลังบอกว่า “ฉันเสร็จถึงตรงนี้แล้ว” คอมมิตเร็วเกินไปเสี่ยงต่อการสูญหาย คอมมิตช้าเกินไปเพิ่มการซ้ำหลังความล้มเหลว
การ retry ควรมีขอบเขตและมองเห็นได้ รูปแบบทั่วไปคือ:
แนวทางนี้ป้องกันไม่ให้ "poison message" บล็อกทั้ง consumer group ในขณะที่ยังคงเก็บข้อมูลไว้สำหรับการแก้ไขภายหลัง
Kafka มักบรรทุกเหตุการณ์ระดับธุรกิจ (คำสั่งซื้อ การชำระเงิน กิจกรรมผู้ใช้) ซึ่งทำให้ความปลอดภัยและการกำกับดูแลเป็นส่วนหนึ่งของการออกแบบ ไม่ใช่เรื่องเพิ่มเติม
การยืนยันตัวตนตอบคำถามว่า “คุณคือใคร?” การอนุญาตตอบว่า “คุณทำอะไรได้บ้าง?” ใน Kafka การยืนยันตัวตนมักทำด้วย SASL (เช่น SCRAM หรือ Kerberos) ขณะที่การอนุญาตบังคับใช้ด้วย ACLs บนระดับหัวข้อ, consumer group และคลัสเตอร์
รูปแบบปฏิบัติคือ principle of least privilege: producers เขียนได้เฉพาะหัวข้อที่เป็นของพวกเขา และ consumers อ่านได้เฉพาะหัวข้อที่ต้องการ ลดการเปิดเผยข้อมูลโดยไม่ตั้งใจและจำกัดวงผลกระทบหากข้อมูลรับรองรั่ว
TLS เข้ารหัสข้อมูลระหว่างแอปกับ brokers และเครื่องมือ หากไม่มี TLS ข้อมูลอาจถูกดักฟังในเครือข่ายภายในได้ TLS ยังช่วยป้องกันการโจมตีแบบ man-in-the-middle โดยยืนยันตัวตนของ broker
เมื่อหลายทีมแชร์คลัสเตอร์ ต้องมี guardrails การตั้งชื่อหัวข้อที่ชัดเจน (เช่น <team>.<domain>.<event>.<version>) ทำให้เห็นเจ้าของชัดและช่วยให้เครื่องมือบังคับใช้นโยบายได้อย่างสม่ำเสมอ
จับคู่การตั้งชื่อกับโควต้าและเทมเพลต ACL เพื่อให้โหลดที่เสียงดังไม่แย่งทรัพยากรของคนอื่น และเพื่อให้บริการใหม่เริ่มต้นด้วยค่าเริ่มต้นที่ปลอดภัย
ถือ Kafka เป็นระบบบันทึกเหตุการณ์เมื่อตั้งใจจริง ๆ หากเหตุการณ์มี PII ให้ใช้การลดข้อมูล (ส่งเฉพาะ ID แทนโปรไฟล์เต็ม) พิจารณาการเข้ารหัสระดับฟิลด์ และเอกสารหัวข้อที่มีความอ่อนไหว
การตั้งค่า retention ควรสอดคล้องกับข้อกำหนดทางกฎหมายและธุรกิจ หากนโยบายบอกว่า “ลบหลัง 30 วัน” อย่าเก็บ 6 เดือน “กันไว้ก่อน” การทบทวนและตรวจสอบเป็นประจำจะช่วยให้คอนฟิกสอดคล้องเมื่อระบบเปลี่ยนไป
การรัน Apache Kafka ไม่ใช่แค่ "ติดตั้งแล้วลืม" มันทำหน้าที่เหมือนยูทิลิตี้ที่ใช้ร่วมกัน: หลายทีมพึ่งพา มาตรการเล็กน้อยอาจส่งผลกระทบต่อแอปด้านล่าง
ความจุของ Kafka เป็นปัญหาทางคณิตศาสตร์ที่ต้องทบทวนเป็นระยะ คันโยกหลักคือพาร์ติชัน (ความขนาน), throughput (MB/s เข้าและออก), และการเติบโตของที่เก็บข้อมูล (ระยะเวลาการเก็บ)
ถ้าการจราจรเพิ่มสองเท่า คุณอาจต้องพาร์ติชันเพิ่มเพื่อกระจายโหลดข้าม brokers, ดิสก์มากขึ้นเพื่อเก็บ retention และแบนด์วิดท์เผื่อสำหรับการจำลอง นิสัยปฏิบัติคือพยากรณ์อัตราเขียนสูงสุดและคูณด้วย retention เพื่อประมาณการเติบโตของดิสก์ แล้วเผื่อเพิ่มสำหรับการจำลองและ "ความสำเร็จที่ไม่คาดคิด"
คาดหวังงานประจำที่ไม่ใช่แค่ดูแลเซิร์ฟเวอร์:
ต้นทุนมาจาก ดิสก์, egress เครือข่าย, และจำนวน/ขนาดของ brokers Managed Kafka ช่วยลดภาระพนักงานและทำให้อัปเกรดง่ายขึ้น ขณะที่การโฮสต์เองอาจถูกกว่าเมื่อขยายใหญ่ถ้าคุณมีผู้ปฏิบัติการที่เชี่ยวชาญ ข้อแลกเปลี่ยนคือเวลาในการกู้คืนและภาระ on-call
ทีมมักมอนิเตอร์:
แดชบอร์ดและการแจ้งเตือนที่ดีทำให้ Kafka เปลี่ยนจาก “กล่องปริศนา” เป็นบริการที่เข้าใจได้
Kafka เหมาะเมื่อคุณต้องย้ายเหตุการณ์จำนวนมากอย่างเชื่อถือได้ เก็บไว้ซักระยะ และให้หลายระบบตอบสนองต่อข้อมูลเดียวกันตามจังหวะของตัวเอง โดยเฉพาะเมื่อจำเป็นต้องเล่นซ้ำข้อมูล (สำหรับ backfills, audits, หรือการสร้างบริการใหม่) และเมื่อต้องการเพิ่ม producers/consumers ในอนาคต
Kafka มักโดดเด่นเมื่อคุณมี:
Kafka อาจเกินความจำเป็นหากความต้องการเรียบง่าย:
ในกรณีเหล่านี้ ภาระการปฏิบัติการ (การกำหนดขนาดคลัสเตอร์, อัปเกรด, การมอนิเตอร์, on-call) อาจมากกว่าประโยชน์
Kafka ยังเสริม (ไม่ทดแทน) ฐานข้อมูล (system of record), แคช (อ่านเร็ว), และเครื่องมือ ETL แบบ batch (การแปลงครั้งใหญ่เป็นระยะ)
ถามตัวเอง:
ตอบ "ใช่" กับข้อส่วนใหญ่ Kafka มักเป็นตัวเลือกที่สมเหตุสมผล
Kafka เหมาะที่สุดเมื่อคุณต้องการ "แหล่งความจริง" ร่วมสำหรับสตรีมเหตุการณ์เรียลไทม์: ระบบหลายส่วนผลิตข้อเท็จจริง (OrderCreated, PaymentAuthorized, InventoryChanged) และระบบหลายส่วนบริโภคข้อเท็จเหล่านั้นเพื่อขับพายไลน์ วิเคราะห์ และฟีเจอร์ตอบสนอง
เริ่มจากฟลอโฟกัสแคบที่ให้มูลค่าสูง—เช่น เผยแพร่เหตุการณ์ “OrderPlaced” ให้บริการด้านล่าง (อีเมล, การตรวจจับการฉ้อโกง, การจัดส่ง) หลีกเลี่ยงการเปลี่ยน Kafka ให้เป็นคิวรวบรวมทุกอย่างตั้งแต่วันแรก
จด:
เก็บสคีมาเริ่มต้นให้เรียบง่ายและสม่ำเสมอ (timestamps, IDs, ชื่อเหตุการณ์ชัดเจน) ตัดสินใจว่าคุณจะบังคับใช้สคีมาแบบเข้มงวดตั้งแต่แรกหรือพัฒนาไปอย่างระมัดระวัง
Kafka สำเร็จเมื่อมีใครสักคนเป็นเจ้าของ:
เพิ่มการมอนิเตอร์ทันที (consumer lag, broker health, throughput, อัตราข้อผิดพลาด) ถ้าคุณยังไม่มีทีมแพลตฟอร์ม ให้เริ่มจากบริการที่จัดการให้และขีดจำกัดที่ชัดเจน
ผลิตเหตุการณ์จากระบบหนึ่ง บริโภคในที่เดียว และพิสูจน์วงจรแบบ end-to-end ก่อนจะขยายไปยังผู้บริโภค พาร์ติชัน และการเชื่อมต่ออื่นๆ
หากต้องการขยับจากไอเดียไปสู่บริการเหตุการณ์ที่ทำงานได้เร็ว เครื่องมืออย่าง Koder.ai สามารถช่วยสร้างต้นแบบแอปรอบๆ ได้เร็ว (React UI, Go backend, PostgreSQL) และเพิ่ม producers/consumers ของ Kafka ผ่านเวิร์กโฟลว์แบบแชท ช่วยในการสร้างแดชบอร์ดภายในและบริการขนาดเล็กที่บริโภคหัวข้อ พร้อมฟีเจอร์เช่นโหมดวางแผน, ส่งออกซอร์สโค้ด, การปรับใช้/โฮสต์ และสแน็ปชอตพร้อมการย้อนกลับ
ถ้าคุณจะแม็ปเป็นแนวทาง event-driven ให้ดูข้อความอ้างอิง /blog/event-driven-architecture และสำหรับการวางแผนต้นทุนและสภาพแวดล้อม ดู /pricing.
Kafka เป็นแพลตฟอร์มสตรีมอีเวนต์แบบกระจายที่เก็บเหตุการณ์ไว้ในล็อกแบบ append-only บนดิสก์
ผู้ผลิต (producers) เขียนเหตุการณ์ไปยังหัวข้อ (topics) และผู้บริโภค (consumers) อ่านเหตุการณ์เหล่านั้นอย่างอิสระ (บ่อยครั้งเป็นแบบเรียลไทม์ แต่ก็สามารถอ่านย้อนหลังได้) เพราะ Kafka เก็บข้อมูลตามระยะเวลาที่กำหนดไว้
ใช้ Kafka เมื่อระบบหลายส่วนต้องการสตรีมเหตุการณ์เดียวกัน คุณต้องการลดการผูกมัดระหว่างบริการ และอาจต้องการเล่นประวัติย้อนหลังได้
มันมีประโยชน์เป็นพิเศษสำหรับ:
หัวข้อ (topic) คือหมวดหมู่ของเหตุการณ์ที่ตั้งชื่อได้ (เช่น orders หรือ payments).
พาร์ติชันคือชิ้นย่อยของหัวข้อที่ช่วยให้:
Kafka ให้การรับประกันเรื่องลำดับเฉพาะภายในพาร์ติชันเดียวเท่านั้น
Kafka ใช้คีย์ของเรคอร์ด (เช่น order_id) เพื่อส่งเหตุการณ์ที่เกี่ยวข้องไปยังพาร์ติชันเดียวกันอย่างสม่ำเสมอ
กฎปฏิบัติ: หากต้องการลำดับต่อหน่วยธุรกิจ (เช่น คำสั่งซื้อหรือลูกค้าหนึ่งราย) ให้เลือกคีย์ที่แทนหน่วยนั้นเพื่อให้เหตุการณ์ทั้งหมดลงพาร์ติชันเดียวกัน
กลุ่มผู้บริโภค (consumer group) คือชุดของอินสแตนซ์ผู้บริโภคที่แบ่งงานกันอ่านหัวข้อ
ภายในกลุ่ม:
ถ้าต้องการให้สองแอปได้เหตุการณ์เดียวกันครบทุกเหตุการณ์ ให้ใช้คนละ consumer group
Kafka เก็บเหตุการณ์บนดิสก์ตามนโยบายของหัวข้อ เพื่อให้ผู้บริโภคสามารถตามทันเมื่อมีการดาวน์หรืออ่านประวัติได้
ประเภทการเก็บข้อมูลที่ใช้กันบ่อย:
การตั้ง retention เป็นระดับหัวข้อ ทำให้เก็บสตรีม audit ที่มีคุณค่าต่างจากสตรีมเทเลเมทรีที่มีปริมาณมากได้
การคอมแพคล็อก (log compaction) จะเก็บอย่างน้อยเรคอร์ดล่าสุดต่อคีย์ และลบเรคอร์ดเก่าที่ถูกแทนที่เมื่อเวลาผ่านไป
มันเหมาะกับสตรีมที่เป็น “changelog ของสถานะปัจจุบัน” (เช่น การตั้งค่าลูกค้าหรือโปรไฟล์) ที่คุณต้องการค่าล่าสุดต่อคีย์โดยไม่ให้ขนาดเติบโตไม่สิ้นสุด
รูปแบบที่พบบ่อยที่สุดในเชิงปฏิบัติคือ at-least-once: คุณจะไม่สูญเสียเหตุการณ์ แต่เกิดซ้ำได้
เพื่อจัดการอย่างปลอดภัย:
Offset คือ “ตำแหน่งบุ๊คมาร์ก” ของผู้บริโภคต่อพาร์ติชัน
ถ้าคอมมิต offset เร็วเกินไป คุณอาจสูญเสียงานเมื่อเกิดแครช; คอมมิตช้าเกินไปจะทำให้ต้องประมวลผลซ้ำเมื่อรีสตาร์ท
รูปแบบปฏิบัติการทั่วไปคือ retry แบบจำกัดพร้อม backoff แล้วส่งเรคอร์ดที่ล้มเหลวไปยัง dead-letter topic เพื่อให้บันทึกไม่มาขัดขวางกลุ่มผู้บริโภคทั้งหมด
Kafka Connect ย้ายข้อมูลเข้า/ออก Kafka โดยใช้คอนเน็กเตอร์ (source และ sink) แทนการเขียนโค้ดพายไลน์แบบกำหนดเอง
Kafka Streams เป็นไลบรารีที่ฝังในแอปเพื่อแปลงสตรีมแบบเรียลไทม์ (กรอง, เสริมข้อมูล, join, สร้าง aggregate) โดยอ่านจากหัวข้อและเขียนกลับไปที่หัวข้อ
สรุป: Connect สำหรับการเชื่อมต่อ/อินทิเกรชัน; Streams สำหรับการประมวลผลเชิงคำนวณ