06 พ.ค. 2568·3 นาที
Key-Value Stores สำหรับการแคช เซสชัน และการค้นหาแบบเร็ว
เรียนรู้ว่า key-value store ช่วยจัดการการแคช เซสชัน และการค้นหาอย่างรวดเร็วอย่างไร—พร้อม TTL, การไล่ออก, ตัวเลือกการขยาย และข้อแลกเปลี่ยปฏิบัติที่ควรระวัง
เรียนรู้ว่า key-value store ช่วยจัดการการแคช เซสชัน และการค้นหาอย่างรวดเร็วอย่างไร—พร้อม TTL, การไล่ออก, ตัวเลือกการขยาย และข้อแลกเปลี่ยปฏิบัติที่ควรระวัง
เป้าหมายหลักของ key-value store นั้นเรียบง่าย: ลดความหน่วงให้ผู้ใช้และลดภาระบนฐานข้อมูลหลักของคุณ แทนที่จะรันคิวรีที่แพงซ้ำ ๆ หรือคำนวนผลลัพธ์ซ้ำ แอปของคุณสามารถดึงค่าที่คำนวณไว้ล่วงหน้าในขั้นตอนเดียวที่คาดเดาได้
Key-value store ถูกออกแบบรอบการทำงานหนึ่งอย่าง: “เมื่อมีคีย์ ให้คืนค่า” สมาธิที่แคบนี้ทำให้เส้นทางวิกฤตสั้นมาก
ในหลายระบบ การค้นหามักจะทำงานได้เร็วเพราะ:
ผลคือเวลาตอบกลับต่ำและสม่ำเสมอ—สิ่งที่คุณต้องการสำหรับการแคช การเก็บเซสชัน และการค้นหาความเร็วสูงอื่นๆ
แม้ว่าฐานข้อมูลของคุณจะปรับแต่งดี มันก็ยังต้องแยกวิเคราะห์คำสั่ง วางแผน อ่านดัชนี และประสานการทำงานร่วมกัน ถ้าคำขอหลายพันรายการถามถึงรายการ “สินค้าดัง” เดิม ๆ งานซ้ำนี้จะสะสม
แคชแบบ key-value จะย้ายการอ่านซ้ำไปจากฐานข้อมูลหลัก ฐานข้อมูลของคุณจะมีเวลามากขึ้นสำหรับคำขอที่ต้องการจริง ๆ: การเขียน การ join ที่ซับซ้อน การรายงาน และการอ่านที่ต้องการความสอดคล้อง
ความเร็วไม่ได้มาฟรี ๆ Key-value store มักสละความสามารถในการคิวรีที่หลากหลาย (การกรอง การ join) และอาจมีการรับประกันความคงทนและความสอดคล้องที่ต่างกันขึ้นอยู่กับการตั้งค่า
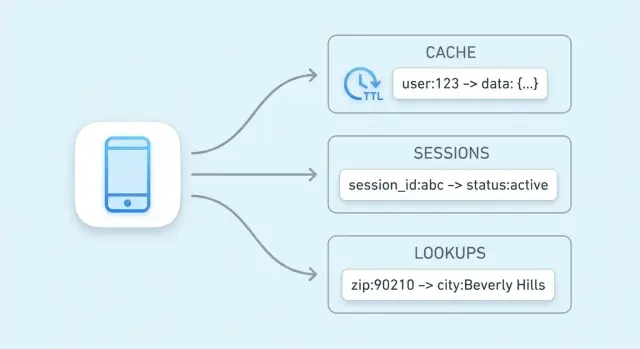
พวกมันเด่นเมื่อตัวข้อมูลสามารถตั้งชื่อด้วยคีย์ที่ชัดเจน (เช่น user:123, cart:abc) และคุณต้องการการดึงเร็ว ถ้าคุณมักจะต้อง “ค้นหาทุกไอเทมที่ X” ฐานข้อมูลเชิงสัมพันธ์หรือแบบเอกสารมักเป็นที่เก็บข้อมูลหลักที่ดีกว่า
Key-value store คือฐานข้อมูลชนิดที่เรียบง่ายที่สุด: คุณเก็บ ค่า (ข้อมูลบางอย่าง) ภายใต้ คีย์ ที่ไม่ซ้ำ และต่อมาคุณดึงค่าด้วยการให้คีย์
คิดว่าคีย์เป็นตัวระบุที่ง่ายต่อการเรียกซ้ำอย่างแม่นยำ และค่าคือสิ่งที่คุณต้องการคืนกลับ
คีย์มักเป็นสตริงสั้น ๆ (เช่น user:1234 หรือ session:9f2a...) ค่าสามารถเล็ก (ตัวนับ) หรือใหญ่กว่า (JSON blob)
Key-value store ถูกสร้างขึ้นสำหรับคำถาม “คืนค่าที่ตรงกับคีย์นี้” ภายใน หลายระบบใช้โครงสร้างคล้าย hash table: คีย์ถูกแปลงเป็นตำแหน่งที่สามารถหาค่าได้อย่างรวดเร็ว
นั่นเป็นสาเหตุที่คุณมักได้ยินคำว่า การค้นหาแบบเวลาเท่ากัน (มักเขียนเป็น O(1)): ประสิทธิภาพขึ้นกับ จำนวนคำขอที่คุณทำ มากกว่า จำนวนระเบียนทั้งหมด แม้มันจะไม่ใช่เวทมนตร์—การชนกันของแฮชและข้อจำกัดหน่วยความจำยังมีผล—แต่สำหรับการใช้งานเป็นแคช/เซสชันทั่วไป มันเร็วมาก
ข้อมูลฮอต คือส่วนเล็ก ๆ ของข้อมูลที่ถูกเรียกบ่อย (หน้าสินค้ายอดนิยม, เซสชันที่ใช้งาน, ตัวนับจำกัดอัตรา) การเก็บข้อมูลฮอตใน key-value store โดยเฉพาะในหน่วยความจำ จะหลีกเลี่ยงคิวรีฐานข้อมูลที่ช้ากว่าและทำให้เวลาตอบสนองคาดเดาได้เมื่อมีโหลดสูง
การแคชหมายถึงการเก็บสำเนาของข้อมูลที่ต้องใช้บ่อยไว้ที่ที่เข้าถึงได้เร็วกว่าแหล่งต้นฉบับ Key-value store เป็นที่นิยมเพราะสามารถคืนค่าได้ด้วยการค้นหาเดียวตามคีย์ บ่อยครั้งไม่กี่มิลลิวินาที
การแคชช่วยเมื่อคำถามเดียวกันถูกถามซ้ำ ๆ: หน้าที่เป็นที่นิยม, การค้นหาซ้ำ, คำเรียก API ทั่วไป, หรือการคำนวณที่แพง นอกจากนี้ยังมีประโยชน์เมื่อแหล่งจริงช้าหรือมีข้อจำกัดการเรียก เช่น ฐานข้อมูลหลักที่มีโหลดสูงหรือ API ภายนอกที่คิดค่าบริการต่อคำขอ
ตัวที่เหมาะ:
กฎง่ายๆ: แคช เอาต์พุต ที่คุณสามารถสร้างใหม่ได้ถ้าจำเป็น หลีกเลี่ยงการแคชข้อมูลที่เปลี่ยนบ่อยหรือจำเป็นต้องสอดคล้องทุกการอ่าน (เช่น ยอดเงินบัญชี)
ไม่มีการแคช การดูหน้าแต่ละครั้งอาจกระตุ้นหลายคิวรีฐานข้อมูลหรือการเรียก API ด้วยแคช แอปสามารถให้บริการคำขอจำนวนมากจาก key-value store และเพียง "fallback" ไปยังฐานข้อมูล/ API เมื่อเกิด cache miss นั่นลดปริมาณคิวรี ลดการแย่งเชื่อมต่อ และปรับปรุงความน่าเชื่อถือในช่วงทราฟฟิคพุ่ง
การแคชแลกความสดใหม่เพื่อความเร็ว ถ้าค่าที่แคชไม่อัปเดตเร็ว ผู้ใช้จะเห็นข้อมูลล้าสมัย ในระบบกระจายคำขออาจอ่านค่าต่างเวอร์ชันได้ชั่วคราว
คุณจัดการความเสี่ยงเหล่านี้โดยเลือก TTL ที่เหมาะสม ตัดสินใจว่าข้อมูลใดยอมให้เก่าได้บ้าง และออกแบบแอปให้รองรับ cache miss เป็นครั้งคราวหรือดีเลย์การรีเฟรช
รูปแบบแคชคือเวิร์กโฟลว์ที่ทำซ้ำได้สำหรับวิธีที่แอปของคุณอ่านและเขียนข้อมูลเมื่อมีแคช ตัวเลือกที่เหมาะไม่ขึ้นกับเครื่องมือ (Redis, Memcached ฯลฯ) เท่ากับว่าแหล่งข้อมูลเปลี่ยนบ่อยแค่ไหนและคุณยอมให้ข้อมูลเก่าได้มากแค่ไหน
กับ cache-aside แอปของคุณควบคุมแคชโดยตรง:
เหมาะกับข้อมูลที่อ่านบ่อยแต่เปลี่ยนไม่บ่อย (หน้าสินค้า, การตั้งค่า, โปรไฟล์สาธารณะ) และเป็นค่าเริ่มต้นที่ดีเพราะความผิดพลาดจะเสื่อมสภาพอย่างนุ่มนวล: ถ้าแคชว่าง คุณยังอ่านจากฐานข้อมูลได้
Read-through ให้ชั้นแคชดึงจากฐานข้อมูลเมื่อเกิด miss (โค้ดอ่านจาก "แคช" และแคชรู้วิธีโหลด) ทำให้โค้ดแอปเรียบง่าย แต่เพิ่มความซับซ้อนให้ชั้นแคช (ต้องมีตัวโหลด)
Write-through หมายถึงการเขียนทุกครั้งไปที่แคชและฐานข้อมูลแบบซิงโครนัส การอ่านมักจะเร็วและสอดคล้องกว่า แต่การเขียนช้าลงเพราะต้องทำสองงาน
เหมาะกับข้อมูลที่ต้องการลด cache miss และความสอดคล้องการอ่าน (การตั้งค่าผู้ใช้, ฟีเจอร์แฟล็ก) และยอมรับความหน่วงในการเขียนได้
กับ write-back แอปของคุณเขียนไปที่แคชก่อน แล้วแคชจะ flush การเปลี่ยนแปลงไปฐานข้อมูลทีหลัง (มักในรูปแบบแบตช์)
ข้อดี: เขียนเร็วมากและลดภาระฐานข้อมูล
ความเสี่ยงเพิ่มขึ้น: ถ้าโหนดแคชล้มก่อน flush คุณอาจสูญหายข้อมูล ใช้เมื่อยอมรับการสูญหายได้หรือมีกลไกความทนทานที่แข็งแรง
ถ้าข้อมูลเปลี่ยนไม่บ่อย cache-aside กับ TTL ที่สมเหตุสมผลก็มักเพียงพอ ถ้าข้อมูลเปลี่ยนบ่อยและการอ่านค่าล้าสมัยมีผลกระทบรุนแรง ให้พิจารณา write-through (หรือ TTL สั้นมากพร้อมกับการล้างแบบชัดเจน) ถ้าปริมาณการเขียนมากและยอมให้สูญหายได้บางครั้ง write-behind อาจคุ้มค่า
การรักษาแคชให้ “สดพอ” ส่วนใหญ่เกี่ยวกับการเลือกกลยุทธ์หมดอายุสำหรับแต่ละคีย์ เป้าหมายไม่ใช่ความถูกต้องสมบูรณ์—แต่เป็นการป้องกันไม่ให้ผลลัพธ์ล้าสมัยแปลกใจผู้ใช้ ในขณะเดียวกันยังได้ประโยชน์ด้านความเร็ว
TTL กำหนดเวลาหมดอายุอัตโนมัติให้กับคีย์เพื่อให้มันหายไปหลังระยะเวลาหนึ่ง TTL สั้นลดความล้าสมัยแต่เพิ่ม cache miss และโหลดกลับไปที่แบ็กเอนด์ TTL ยาวเพิ่มอัตราการถูกอ่านจากแคชแต่เสี่ยงให้บริการค่าล้าสมัย
วิธีปฏิบัติ:
TTL เป็นแบบพาสซีฟ เมื่อตอนที่คุณรู้ว่าข้อมูลเปลี่ยน มักดีกว่าที่จะล้างแบบแอ็กทีฟ: ลบคีย์เก่า หรือเขียนค่าใหม่ทันที
ตัวอย่าง: หลังผู้ใช้เปลี่ยนอีเมล ให้ลบ user:123:profile หรืออัปเดตมันในแคชทันที การล้างแบบแอ็กทีฟลดหน้าต่างความล้าสมัย แต่ต้องให้แอปของคุณทำการอัปเดตแคชอย่างเชื่อถือได้
แทนการลบคีย์เก่า ให้ใส่เวอร์ชันในชื่่อคีย์ เช่น product:987:v42 เมื่อสินค้าปรับเปลี่ยน ให้เพิ่มเวอร์ชันเป็น v43 แล้วเริ่มอ่าน/เขียนแบบใหม่ เวอร์ชันเก่าจะหมดอายุเองภายหลัง วิธีนี้หลีกเลี่ยงเรซที่เกิดจากเซิร์ฟเวอร์หนึ่งลบขณะที่อีกเครื่องกำลังเขียน
Stampede เกิดเมื่อคีย์ฮอตหมดอายุและคำขอจำนวนมากสร้างมันใหม่พร้อมกัน
การแก้ที่พบบ่อย:
ข้อมูลเซสชันคือพัสดุข้อมูลเล็ก ๆ ที่แอปต้องใช้เพื่อระบุเบราว์เซอร์หรือไคลเอนต์มือถือที่กลับมา อย่างน้อยคือ session ID (หรือ token) ที่แมปไปยังสถานะฝั่งเซิร์ฟเวอร์ ขึ้นกับผลิตภัณฑ์ อาจรวม user state (สถานะล็อกอิน, บทบาท, nonce ของ CSRF), การตั้งค่าชั่วคราว และข้อมูลที่ไวต่อเวลาเช่นตะกร้าสินค้าหรือขั้นตอนเช็คเอาต์
Key-value store เหมาะเพราะการอ่าน/เขียนเซสชันเรียบง่าย: ดึงด้วย token, อัปเดต และตั้งการหมดอายุได้ง่าย นอกจากนี้ยังทำให้ตั้ง TTL เพื่อให้เซสชันที่ไม่ใช้งานหายไปโดยอัตโนมัติ ช่วยให้พื้นที่เก็บสะอาดและลดความเสี่ยงเมื่อ token รั่ว
โฟลว์ทั่วไป:
ใช้คีย์ที่ชัดเจนและเก็บค่าขนาดเล็ก:
sess:<token> หรือ sess:v2:<token> (การเวอร์ชันช่วยการเปลี่ยนแปลงในอนาคต)user_sess:<userId> -> <token> เพื่อบังคับ "หนึ่งเซสชันต่อผู้ใช้" หรือล้างเซสชันตามผู้ใช้การ logout ควรลบคีย์เซสชันและดัชนีที่เกี่ยวข้อง (เช่น user_sess:<userId>) สำหรับการสลับ (แนะนำหลังล็อกอิน, การเปลี่ยนสิทธิ์, หรือเป็นช่วงเวลา) ให้สร้าง token ใหม่ เขียนเซสชันใหม่ แล้วลบคีย์เก่า เพื่อจำกัดหน้าต่างที่ token ถูกขโมยใช้งานได้
การแคชเป็นกรณีใช้งานที่พบบ่อยที่สุดของ key-value store แต่ไม่ใช่วิธีเดียวที่ช่วยเร่งระบบ หลายแอปต้องการการอ่านอย่างรวดเร็วสำหรับสถานะขนาดเล็กที่อ้างอิงบ่อย—สิ่งที่อยู่ใกล้ "source of truth" และต้องตรวจสอบอย่างรวดเร็วแทบทุกคำขอ
การตรวจสิทธิ์มักอยู่บนเส้นทางวิกฤต: ทุกการเรียก API อาจต้องตอบ "ผู้ใช้คนนี้ทำได้ไหม" การดึงสิทธิ์จากฐานข้อมูลเชิงสัมพันธ์ทุกคำขออาจเพิ่มความหน่วงและโหลดได้
Key-value store สามารถเก็บข้อมูลการอนุญาตที่กะทัดรัดเพื่อตรวจสอบอย่างรวดเร็ว เช่น:
perm:user:123 → รายการ/เซ็ตของโค้ดสิทธิ์entitlement:org:45 → ฟีเจอร์ที่เปิดใช้ตามแผนเหมาะเมื่อโมเดลสิทธิ์อ่านหนักและเปลี่ยนค่อนข้างไม่บ่อย เมื่อสิทธิ์เปลี่ยน คุณสามารถอัปเดตหรือล้างคีย์จำนวนน้อยเพื่อให้คำขอถัดไปสะท้อนกฎการเข้าถึงใหม่
ฟีเจอร์แฟล็กเป็นค่าขนาดเล็กที่อ่านบ่อยและต้องพร้อมใช้เร็วและสอดคล้องข้ามหลายบริการ รูปแบบทั่วไปคือเก็บ:
flag:new-checkout → true/falseconfig:tax:region:EU → JSON blob หรือการเวอร์ชันของการตั้งค่าKey-value store ทำงานได้ดีที่นี่เพราะการอ่านตรงไปตรงมา คาดเดาได้ และเร็วมาก คุณยังสามารถเวอร์ชันค่า (เช่น config:v27:...) เพื่อให้การม้วนออกปลอดภัยและย้อนกลับได้เร็ว
การจำกัดอัตรามักลดไปเป็นตัวนับต่อผู้ใช้ คีย์ หรือที่อยู่ IP Key-value store มักรองรับการดำเนินการอะตอม ซึ่งให้คุณเพิ่มตัวนับอย่างปลอดภัยแม้มีคำขอพร้อมกันจำนวนมาก
คุณอาจติดตาม:
rl:user:123:minute → เพิ่มทุกคำขอ หมดอายุหลัง 60 วินาทีrl:ip:203.0.113.10:second → ควบคุมระยะสั้นด้วย TTL บนแต่ละคีย์ ตัวนับจะรีเซ็ตอัตโนมัติโดยไม่ต้องงานแบ็กกราวด์ นี่เป็นพื้นฐานปฏิบัติสำหรับการหน่วงการพยายามล็อกอิน ปกป้อง endpoint ที่แพง หรือบังคับโควตาตามแผน
การชำระเงินและการดำเนินการ "ทำครั้งเดียว" ต้องการการป้องกันจากการลองใหม่ไม่ว่าจะเกิดจาก timeout, การลองซ้ำจากไคลเอนต์ หรือการส่งข้อความซ้ำ
Key-value store สามารถบันทึกคีย์ idempotency เช่น:
idem:pay:order_789:clientKey_abc → ผลลัพธ์หรือสถานะที่จัดเก็บในการร้องขอครั้งแรก คุณประมวลผลและจัดเก็บผลลัพธ์พร้อม TTL ในการลองซ้ำภายหลัง ให้คืนผลลัพธ์ที่จัดเก็บแทนการประมวลผลซ้ำ TTL ป้องกันการเติบโตไม่จำกัดในขณะที่ครอบคลุมหน้าต่างการลองซ้ำจริงจัง
การใช้งานเหล่านี้ไม่ใช่การแคชตามความหมายคลาสสิก แต่เกี่ยวกับการรักษาความหน่วงต่ำสำหรับการอ่านที่เกิดขึ้นบ่อยและกลไกประสานงานที่ต้องการความเร็วและอะตอมิก
"key-value store" ไม่ได้แปลว่า "ใส่สตริงเข้า ออกสตริงเสมอไป" หลายระบบเสนอโครงสร้างข้อมูลที่หลากหลายซึ่งช่วยให้คุณจำลองความต้องการทั่วไปได้ภายในสโตร์—มักเร็วกว่าการโยนทุกอย่างไปไว้ในโค้ดแอป
Hashes (เรียกอีกชื่อว่า maps) เหมาะเมื่อคุณมี "สิ่งเดียว" ที่มีแอตทริบิวต์หลายตัว แทนที่จะสร้างหลายคีย์เช่น user:123:name, user:123:plan, user:123:last_seen คุณสามารถเก็บไว้ด้วยกันภายใต้คีย์ user:123 พร้อมฟิลด์ต่าง ๆ
สิ่งนี้ลดการกระจายคีย์และให้คุณดึงหรือเปลี่ยนเฉพาะฟิลด์ที่ต้องการ—เป็นประโยชน์สำหรับโปรไฟล์ ฟีเจอร์แฟล็ก หรือบล็อบการตั้งค่าขนาดเล็ก
Sets เหมาะสำหรับคำถาม "X อยู่ในกลุ่มไหม?":
Sorted sets เพิ่มการเรียงลำดับด้วยสกอร์ เหมาะกับกระดานผู้นำ รายการ "top N" และการจัดอันดับตามเวลา/ความนิยม คุณสามารถเก็บสกอร์เป็นจำนวนการดูหรือ timestamp แล้วอ่านรายการบนสุดได้เร็ว
ปัญหาการพร้อมกันมักเกิดในฟีเจอร์เล็ก ๆ: ตัวนับ โควตา การกระทำหนึ่งครั้ง หากคำขอสองรายการมาถึงพร้อมกันและแอปทำ "อ่าน → บวก 1 → เขียน" คุณอาจสูญเสียอัปเดต
การดำเนินการอะตอมแก้ไขโดยทำการเปลี่ยนแปลงเป็นก้าวเดียวที่ไม่สามารถแบ่งแยกได้ภายในสโตร์:
ด้วยการเพิ่มแบบอะตอม คุณไม่ต้องใช้ล็อกหรือตัวประสานงานระหว่างเซิร์ฟเวอร์ นั่นหมายถึงเงื่อนไขการแข่งน้อยลง โค้ดทางเดินที่เรียบง่ายขึ้น และพฤติกรรมที่คาดเดาได้มากขึ้นภายใต้โหลด—โดยเฉพาะกับการจำกัดอัตราและโควตาที่ "ผิดพลาดนิดหน่อย" อาจกลายเป็นปัญหาต่อผู้ใช้ได้
เมื่อ key-value store เริ่มจัดการทราฟฟิคจริง ๆ การทำให้มันเร็วขึ้นมักหมายถึงการขยายแนวนอน: กระจายการอ่านและการเขียนข้ามโหนดหลายตัวในขณะที่ยังคงความคาดการณ์ได้เมื่อเกิดความล้มเหลว
Replication เก็บสำเนาของข้อมูลหลายชุด
Sharding แบ่ง keyspace ข้ามโหนด
การปรับใช้งานหลายรูปแบบมักรวมทั้งสอง: ชาร์ดเพื่อเพิ่ม Throughput และ replica ต่อชาร์ดเพื่อความพร้อมใช้งาน
“ความพร้อมใช้งานสูง” หมายถึงชั้นแคช/เซสชันยังคงให้บริการคำขอแม้โหนดจะล้ม
กับ client-side routing แอปของคุณ (หรือไลบรารี) คำนวณว่าโหนดใดถือคีย์ (เช่น consistent hashing) ซึ่งเร็ว แต่ไคลเอนต์ต้องรู้ทอพอโลยีเมื่อมีการเปลี่ยนแปลง
กับ server-side routing คุณส่งคำขอไปยังพร็อกซีหรือ endpoint คลัสเตอร์ที่ส่งต่อไปยังโหนดที่เหมาะสม วิธีนี้ทำให้ไคลเอนต์เรียบง่ายขึ้น แต่เพิ่มฮอปอีกหนึ่งครั้ง
วางแผนหน่วยความจำจากมุมมองบนลงล่าง:
Key-value store ให้ความรู้สึก "ทันที" เพราะเก็บข้อมูลฮอตในหน่วยความจำและปรับแต่งสำหรับการอ่าน/เขียนเร็ว ความเร็วนี้มีต้นทุน: คุณมักเลือกระหว่างประสิทธิภาพ ความทนทาน และความสอดคล้อง การเข้าใจข้อแลกเปลี่ยนตั้งแต่ต้นจะช่วยป้องกันปัญหาในภายหลัง
หลาย key-value store รันได้ในโหมดความคงทนต่างกัน:
เลือกโหมดที่ตรงกับวัตถุประสงค์ของข้อมูล: แคชยอมสูญหายได้; การเก็บเซสชันมักต้องระมัดระวังมากขึ้น
ในการจัดวางแบบกระจาย คุณอาจเห็น eventual consistency—การอ่านอาจคืนค่าเก่าหลังการเขียน โดยเฉพาะช่วง failover หรือ replication lag ความสอดคล้องที่แข็งแรงขึ้น (เช่น ต้องได้รับการยืนยันจากหลายโหนด) จะลดความผิดปกติแต่เพิ่มความหน่วงและอาจลดความพร้อมใช้งานเมื่อเครือข่ายมีปัญหา
แคชจะเต็ม นโยบาย eviction ตัดสินว่าตัวใดถูกลบ: least-recently-used, least-frequently-used, สุ่ม, หรือ "ไม่ไล่ออก" (ซึ่งทำให้หน่วยความจำเต็มกลายเป็นความล้มเหลวการเขียน) ตัดสินใจว่าคุณต้องการ missing cache entries หรือต้องการข้อผิดพลาดเมื่อกดดัน
สมมติว่าการหยุดทำงานจะเกิดขึ้น การ fallback ทั่วไปได้แก่:
การออกแบบพฤติกรรมเหล่านี้อย่างตั้งใจคือสิ่งที่ทำให้ระบบดูน่าเชื่อถือสำหรับผู้ใช้
Key-value store มักอยู่บน "เส้นทางร้อน" ของแอป ทำให้มันทั้งละเอียดอ่อน (อาจเก็บโทเค็นเซสชันหรือข้อมูลระบุตัวตน) และแพง (ใช้หน่วยความจำสูง) การตั้งค่าพื้นฐานให้ถูกต้องตั้งแต่ต้นช่วยป้องกันเหตุการณ์ที่เจ็บปวดในภายหลัง
เริ่มด้วยขอบเขตเครือข่ายที่ชัดเจน: วางสโตร์ใน subnet/VPC ส่วนตัว และอนุญาตการเข้าถึงเฉพาะจากบริการแอปที่ต้องการเท่านั้น
ใช้การพิสูจน์ตัวตนถ้าผลิตภัณฑ์รองรับ และทำตามหลัก least privilege: แยก credentials สำหรับแอป, ผู้ดูแล, และออโตเมชัน; หมุนรอบความลับ; และหลีกเลี่ยงโทเค็น "root" ที่ใช้ร่วมกัน
เข้ารหัสข้อมูลขณะส่ง (TLS) เมื่อเป็นไปได้—โดยเฉพาะถ้าทราฟฟิคข้ามโฮสต์หรือโซน การเข้ารหัสที่พักขึ้นกับผลิตภัณฑ์และการปรับใช้งาน; หากรองรับ ให้เปิดใช้สำหรับบริการจัดการและตรวจสอบการเข้ารหัสของแบ็กอัพด้วย
ชุดเมตริกเล็ก ๆ จะบอกว่าตัวแคชช่วยหรือทำร้าย:
ตั้งการแจ้งเตือนสำหรับการเปลี่ยนแปลงอย่างฉับพลัน ไม่ใช่แค่ค่าเกณฑ์อย่างเดียว และบันทึกการดำเนินการคีย์อย่างระมัดระวัง (หลีกเลี่ยงการบันทึกค่าที่ละเอียดอ่อน)
ปัจจัยหลักคือ:
คันโยกลดค่าใช้จ่ายที่ปฏิบัติได้คือการลดขนาดค่าและตั้ง TTL จริงจัง เพื่อให้สโตร์เก็บเฉพาะสิ่งที่มีประโยชน์จริง
เริ่มด้วยการทำให้ การตั้งชื่อคีย์ เป็นมาตรฐานเพื่อให้คีย์แคชและเซสชันคาดเดาได้ ค้นหาได้ และปลอดภัยเมื่อต้องปฏิบัติการเป็นกลุ่ม รูปแบบเช่น app:env:feature:id (ตัวอย่าง shop:prod:cart:USER123) ช่วยหลีกเลี่ยงการชนกันและทำให้ดีบักเร็วขึ้น
กำหนด กลยุทธ์ TTL ก่อนส่งขึ้น production ตัดสินใจว่าข้อมูลใดหมดอายุเร็วได้ (วินาที/นาที), อะไรต้องอยู่นานขึ้น (ชั่วโมง), และสิ่งใดไม่ควรถูกแคชเลย หากคุณแคชแถวฐานข้อมูล ให้จัด TTL ให้สอดคล้องกับความถี่ที่ข้อมูลในฐานข้อมูลเปลี่ยน
เขียนแผน การล้าง สำหรับแต่ละประเภทของรายการแคช:
product:v3:123) เมื่อคุณต้องการการล้างแบบ "ลบทุกอย่าง" ง่ายๆเลือกตัวชี้วัดไม่กี่อย่างและติดตามตั้งแต่วันแรก:
นอกจากนี้ให้ติดตามการนับการไล่ออกและการใช้หน่วยความจำเพื่อยืนยันว่าขนาดแคชพอดี
ค่าที่ใหญ่เกินไปเพิ่มเวลาเครือข่ายและแรงกดดันหน่วยความจำ—ชอบแคชชิ้นเล็ก ๆ ที่คำนวณไว้แล้ว หลีกเลี่ยงการลืมตั้ง TTL (ข้อมูลล้าสมัยและหน่วยความจำรั่ว) และ การเติบโตของคีย์แบบไม่จำกัด (เช่น แคชทุกคำค้นหาไว้ตลอดไป) ระวังการแคชข้อมูลเฉพาะผู้ใช้ภายใต้คีย์ที่ใช้ร่วมกัน
ถ้าคุณกำลังประเมินตัวเลือก ให้เปรียบเทียบแคชในกระบวนการ (in-process) กับแคชแบบกระจายและตัดสินใจว่าส่วนไหนที่ความสอดคล้องสำคัญที่สุด สำหรับรายละเอียดการนำไปปฏิบัติและคำแนะนำเชิงปฏิบัติการ ให้ทบทวน /docs ถ้าคุณต้องการสมมติฐานความจุหรือการประเมินราคา ให้ดู /pricing
ถ้าคุณกำลังสร้างผลิตภัณฑ์ใหม่ (หรือปรับปรุงที่มีอยู่) การออกแบบการแคชและการเก็บเซสชันเป็นเรื่องสำคัญตั้งแต่ต้น บน Koder.ai ทีมมักจะต้นแบบแอปแบบ end-to-end (React บนเว็บ, Go services กับ PostgreSQL, และ Flutter สำหรับมือถือเป็นทางเลือก) แล้วปรับปรุงประสิทธิภาพด้วยรูปแบบอย่าง cache-aside, TTL, และตัวนับจำกัดอัตรา ฟีเจอร์อย่างโหมดวางแผน สแนปชอต และการย้อนกลับช่วยให้ทดลองแบบปลอดภัยและส่งออกซอร์สโค้ดเมื่อคุณพร้อมจะรันในพายป์ไลน์ของคุณเอง.
Key-value stores จะปรับแต่งเพื่อทำงานหนึ่งอย่าง: เมื่อมีคีย์ ให้คืนค่าที่ตรงกับคีย์นั้น ขอบเขตที่แคบนี้ทำให้เส้นทางการเข้าถึงสั้นและเร็ว เช่น การใช้ดัชนีในหน่วยความจำและการแฮชโดยตรง โดยไม่ต้องมีการวางแผนคำสั่งที่ซับซ้อนเหมือนฐานข้อมูลทั่วไป。
นอกจากนี้ยังช่วยลดงานซ้ำบนระบบของคุณโดยการย้ายการอ่านที่ซ้ำกัน (หน้าเป็นที่นิยม, คำตอบ API ที่ใช้บ่อย) ออกจากฐานข้อมูลหลัก ทำให้ฐานข้อมูลเหลือเวลาจัดการเขียนและคิวรีที่ซับซ้อนมากขึ้น
คีย์คือรหัสประจำตัวที่ต้องการเรียกซ้ำได้แน่นอน (มักเป็นสตริงเช่น user:123 หรือ sess:<token>) ส่วนค่าคือสิ่งที่คุณต้องการคืนกลับ—อาจเป็นตัวนับขนาดเล็กหรือ JSON blob。
คีย์ที่ดีควรเป็น คงที่, แยกสโคปได้, และคาดเดาได้ ซึ่งทำให้การแคช เซสชัน และการค้นหาทำงานง่ายและตรวจสอบได้สะดวก
ให้แคชผลลัพธ์ที่ถูกอ่านบ่อยและ สามารถสร้างใหม่ได้ถ้าจำเป็น。
ตัวอย่างทั่วไป:
หลีกเลี่ยงการแคชข้อมูลที่ต้องทันสมัยสมบูรณ์ (เช่น ยอดเงินบัญชี) เว้นแต่คุณมีแผนการล้าง/อัปเดตที่รัดกุม
Cache-aside (โหลดแบบขี้เกียจ) มักเป็นค่าเริ่มต้น:
key จากแคชมันลดความเสี่ยงได้ดี: หากแคชว่างหรือใช้งานไม่ได้ คุณยังสามารถให้บริการจากฐานข้อมูลได้ (พร้อมมาตรการป้องกันที่เหมาะสม)
ใช้ read-through เมื่อคุณต้องการให้ชั้นแคชโหลดข้อมูลอัตโนมัติเมื่อเกิด miss (ทำให้โค้ดฝั่งแอปเรียบง่ายขึ้น แต่ต้องผนวกการโหลดเข้ากับชั้นแคช)
ใช้ write-through เมื่อคุณต้องการให้การอ่านมีความร้อนอยู่เสมอ เพราะการเขียนจะอัปเดตทั้งแคชและฐานข้อมูลแบบซิงโครนัส—แลกกับความหน่วงของการเขียนที่เพิ่มขึ้น
เลือกเมื่อคุณยอมรับความซับซ้อนเชิงปฏิบัติการของ read-through หรือต้องการยอมรับเวลาเขียนที่มากขึ้นสำหรับ write-through
TTL (time to live) จะตั้งอายุของคีย์ให้หมดอายุอัตโนมัติหลังระยะเวลาหนึ่ง TTL สั้นลดข้อมูลเก่าแต่เพิ่มอัตรา miss และโหลดกลับไปยังเบื้องหลัง ส่วน TTL ยาวเพิ่มอัตรา hit แต่เสี่ยงให้บริการค่าล้าสมัย
คำแนะนำปฏิบัติ:
Cache stampede เกิดเมื่อคีย์ฮอตหมดอายุและคำขอจำนวนมากพยายามสร้างมันใหม่พร้อมกัน
แนวทางบรรเทาที่ใช้บ่อย:
วิธีเหล่านี้จะลดการกระแทกพลังงานไปยังฐานข้อมูลหรือ API ภายนอก
เซสชันเป็นกรณีใช้งานที่เหมาะเพราะการเข้าถึงเรียบง่าย: อ่าน/เขียนตาม token และกำหนดเวลาให้หมดอายุได้ง่าย
แนวทางปฏิบัติที่ดี:
sess:<token> (การเวอร์ชันเช่น sess:v2:<token> ช่วยการเปลี่ยนแปลงในอนาคต)หลาย key-value store สนับสนุนการเพิ่มแบบอะตอม ซึ่งทำให้ตัวนับปลอดภัยเมื่อมีการร้องขอพร้อมกัน
รูปแบบทั่วไป:
rl:user:123:minute → เพิ่มค่าต่อคำขอเมื่อตัวนับเกินเกณฑ์ ให้หน่วงหรือปฏิเสธคำขอ TTL ทำให้ลิมิตรีเซ็ตอัตโนมัติโดยไม่ต้องมีงานแบ็กกราวด์
ข้อแลกเปลี่ยนสำคัญที่ควรวางแผน:
ออกแบบโหมดเสื่อมสภาพล่วงหน้า: เตรียมการข้ามแคช อ่านข้อมูลจากฐานข้อมูลโดยตรงเมื่อจำเป็น หรือยอมรับการให้บริการข้อมูลเล็กน้อยที่ล้าสมัยในกรณีที่ปลอดภัย