03 ต.ค. 2568·2 นาที
ข้อมูลภายนอก vs ภายใน — บทเรียนจาก Pat Helland สำหรับแอป
เรียนรู้แนวคิด "ข้อมูลภายนอก vs ภายใน" ของ Pat Helland เพื่อกำหนดขอบเขตชัดเจน ออกแบบการเรียกให้ idempotent และคืนสถานะเมื่อเครือข่ายล้มเหลว
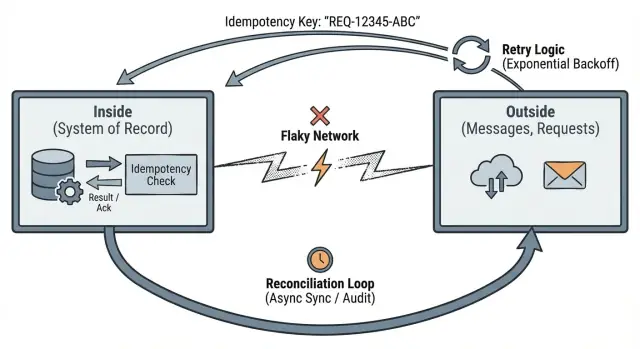
ความหมายของ “ภายนอก vs ภายใน” แบบเข้าใจง่าย
เมื่อคุณสร้างแอป มันง่ายที่จะจินตนาการว่าคำขอเข้ามาเรียงกันเป็นระเบียบ ทีละรายการ ตามลำดับที่ถูกต้อง แต่เครือข่ายจริงไม่ได้ทำงานแบบนั้น ผู้ใช้กด "ชำระเงิน" สองครั้งเพราะหน้าจอค้าง การเชื่อมต่อมือถือขาดหลังจากกดปุ่ม เว็บฮุคมาช้าหรือมาซ้ำ หรือบางครั้งก็ไม่มาถึงเลย
แนวคิดของ Pat Helland เรื่อง ข้อมูลภายนอก vs ภายใน คือวิธีคิดที่ชัดเจนเพื่อจัดการความยุ่งเหยิงนั้น
ภายนอกเป็นอย่างไร
“ภายนอก” คือทุกอย่างที่ระบบของคุณไม่ควบคุม มันคือพื้นที่ที่คุณสื่อสารกับคนและระบบอื่น และการส่งมอบมีความไม่แน่นอน: คำขอ HTTP จากเบราว์เซอร์และแอปมือถือ ข้อความจากคิว เว็บฮุคจากบริการภายนอก (การชำระเงิน อีเมล การจัดส่ง) และการ retry ที่เกิดขึ้นจากไคลเอนต์ พร็อกซี หรือ background job
ที่ฝั่งภายนอก ให้ถือว่าข้อความอาจถูกหน่วง มาซ้ำ หรือมาถึงไม่เรียงลำดับ แม้บางอย่างจะ "โดยปกติแล้วเชื่อถือได้" ก็ต้องออกแบบเผื่อวันที่มันไม่เชื่อถือได้
ภายในหมายถึงอะไร
“ภายใน” คือสิ่งที่ระบบของคุณทำให้เชื่อถือได้ มันคือสถานะที่ทนทานที่คุณเก็บ กฎที่คุณบังคับใช้ และข้อเท็จจริงที่คุณสามารถพิสูจน์ได้ภายหลัง:
- ระเบียนฐานข้อมูลและประวัติของมัน
- กฎธุรกิจ (เช่น: “คำสั่งซื้อหนึ่งใบจ่ายได้ครั้งเดียว”)\n- แหล่งความจริงสำหรับสถานะ (pending, paid, canceled)
ภายในคือที่ที่คุณปกป้อง invariants หากคุณสัญญา "หนึ่งการชำระต่อคำสั่งซื้อ" คำสัญญานั้นต้องถูกบังคับใช้ในฝั่งภายใน เพราะภายนอกไม่เชื่อถือได้
การเปลี่ยนกรอบความคิดง่าย ๆ คือ: อย่าสมมติการส่งมอบหรือการจัดลำดับที่สมบูรณ์แบบ ปฏิบัติต่อการโต้ตอบภายนอกทุกครั้งเป็นข้อเสนอที่ไม่เชื่อถือได้ซึ่งอาจถูกส่งซ้ำ และทำให้ฝั่งภายในตอบสนองอย่างปลอดภัย
เรื่องนี้สำคัญแม้สำหรับทีมเล็กและแอปง่าย ๆ ครั้งแรกที่บั๊กเครือข่ายสร้างค่าธรรมเนียมซ้ำหรือคำสั่งซื้อค้าง มันจะไม่ใช่ทฤษฎีอีกต่อไป แต่มันคือการคืนเงิน ตั๋วซัพพอร์ต และการสูญเสียความไว้วางใจ
ตัวอย่างชัดเจน: ผู้ใช้กด "สั่งซื้อ" แอปส่งคำขอ และการเชื่อมต่อขาด ผู้ใช้ลองอีกครั้ง ถ้าฝั่งภายในของคุณไม่มีวิธีจดจำว่า "นี่คือความพยายามเดียวกัน" คุณอาจสร้างคำสั่งซื้อสองรายการ สำรองสต็อกสองครั้ง หรือส่งอีเมลยืนยันสองฉบับ
บทเรียนหลักจาก Pat Helland
Helland พูดชัดเจน: โลกภายนอกไม่แน่นอน แต่ภายในระบบของคุณต้องคงสภาพสอดคล้อง เครือข่ายสูญเสียแพ็กเก็ต โทรศัพท์หลุด นาฬิกาเบี้ยว ผู้ใช้กดรีเฟรช แอปของคุณควบคุมสิ่งนั้นไม่ได้ สิ่งที่ควบคุมได้คือสิ่งที่คุณยอมรับว่าเป็น "จริง" เมื่อข้อมูลข้ามขอบเขตที่ชัดเจน
เวลาและความไม่แน่นอนในเหตุการณ์ประจำวัน
ลองนึกภาพคนสั่งกาแฟผ่านมือถือขณะเดินในอาคารที่สัญญาณ Wi‑Fi แย่ พวกเขากด "ชำระ" วงหมุนปรากฏ การเชื่อมต่อตัด พวกเขากดอีกครั้ง
บางทีคำขอแรกถึงเซิร์ฟเวอร์ของคุณแล้วแต่การตอบกลับไม่ถึงผู้ใช้ หรือบางทีมทั้งสองคำขอไม่ถึง จากมุมมองของผู้ใช้ ทั้งสองความเป็นไปได้นั้นดูเหมือนกัน
นั่นคือเวลาและความไม่แน่นอน: คุณยังไม่รู้ว่าเกิดอะไรขึ้น และอาจรู้ภายหลัง ระบบของคุณต้องทำตัวสมเหตุสมผลในขณะที่รอ
การ retry, การมาซ้ำ, และการมาผิดลำดับ
เมื่อยอมรับว่าภายนอกไม่เชื่อถือได้ พฤติกรรม "แปลก" บางอย่างจะกลายเป็นเรื่องปกติ:\n
- การ retry ทำให้เกิดการซ้ำ (คำขอ "ชำระ" สองครั้ง)\n- ข้อความมาถึงผิดลำดับ (เช่น "ยกเลิก" มาก่อน "ชำระ")\n- คำขอถูกประมวลผล แต่ไคลเอนต์ไม่เห็นการตอบกลับ
ข้อมูลจากภายนอกเป็นคำกล่าว ไม่ใช่ข้อเท็จจริง "ฉันชำระแล้ว" เป็นเพียงข้อความที่ส่งผ่านช่องทางที่ไม่เชื่อถือได้ มันกลายเป็นข้อเท็จจริงก็ต่อเมื่อคุณบันทึกมันไว้ภายในระบบในแบบทนทานและสอดคล้อง
สิ่งนี้ชี้ให้คุณไปสู่สามนิสัยเชิงปฏิบัติ: กำหนดขอบเขตให้ชัด ทำให้การ retry ปลอดภัยด้วย idempotency และวางแผนการคืนสถานะเมื่อความเป็นจริงไม่ตรงกัน
ขอบเขตที่ชัดเจน: อะไรที่ระบบของคุณเป็นเจ้าของและอะไรที่ไม่ใช่
แนวคิด "ภายนอก vs ภายใน" เริ่มจากคำถามปฏิบัติ: ความจริงของระบบคุณเริ่มและจบที่ไหน?
ภายในขอบเขต คุณสามารถให้การรับประกันที่แข็งแรงได้เพราะคุณควบคุมข้อมูลและกฎ ภายนอกขอบเขต ให้ทำดีที่สุดและสมมติว่าข้อความอาจหาย ซ้ำ หน่วง หรือมาถึงไม่เรียงลำดับ
ในแอปจริง ขอบเขตนั้นมักปรากฏที่จุดต่างๆ เช่น:
- Endpoint API ที่เขียนระเบียนลงฐานข้อมูล\n- ตัวบริโภคคิวที่เปลี่ยนอีเวนต์เป็นการเปลี่ยนแปลงที่ถูกเก็บ\n- ตัวจัดการ callback ที่บันทึกสิ่งที่ผู้ให้บริการอ้างว่าเกิดขึ้น\n- ตัวส่งที่แจ้งระบบอื่นหลังจากที่คุณ commit สถานะของตัวเอง
เมื่อคุณวาดเส้นนั้นแล้ว ให้ตัดสินใจว่า invariant ไหนที่ไม่ต่อรองภายใน เช่น:\n
- รหัสคำสั่งซื้อต้องไม่ซ้ำในฐานข้อมูล\n- ยอดคงเหลือไม่ควรติดลบ\n- สถานะต้องเดินหน้าเท่านั้น (created -> paid -> shipped)\n- ทุกคำขอภายนอกที่ยอมรับต้องมี audit trail เก็บไว้
ขอบเขตต้องมีภาษาชัดเจนสำหรับ "ตำแหน่งปัจจุบัน" ความล้มเหลวจำนวนมากเกิดในช่องว่างระหว่าง "เราได้ยินคุณแล้ว" กับ "เราทำเสร็จแล้ว" รูปแบบที่เป็นประโยชน์คือแยกสามความหมาย:\n
- Received: ข้อความมาถึงที่ edge ของคุณ (อาจยังไม่ได้บันทึก)\n- Accepted: คุณบันทึกมันแล้วและสามารถ retry งานนั้นได้อย่างปลอดภัยภายหลัง\n- Processed: งานที่ตั้งใจเสร็จสิ้นและคุณบันทึกผลลัพธ์แล้ว
เมื่อทีมข้ามขั้นตอนนี้ พวกเขาจะเจอบั๊กที่โผล่เฉพาะตอนมีโหลดหรือระหว่างการล่มบางส่วน ระบบหนึ่งใช้คำว่า "paid" เพื่อหมายถึงเงินถูกเก็บ ขณะที่อีกระบบหมายถึงการเริ่มต้นการชำระ นั่นสร้างการซ้ำ คำสั่งซื้อค้าง และตั๋วซัพพอร์ตที่ไม่มีใครทำซ้ำได้
Idempotency: ทำให้การ retry ปลอดภัย
Idempotency หมายถึง: ถ้าคำขอเดียวกันถูกส่งสองครั้ง ระบบจะถือเป็นคำขอเดียวและคืนผลลัพธ์เดิม
การ retry เป็นเรื่องปกติ เวลา timeout เกิดขึ้น ไคลเอนต์ส่งซ้ำ หากภายนอกสามารถส่งซ้ำ ฝั่งภายในต้องเปลี่ยนสิ่งนั้นเป็นการเปลี่ยนสถานะที่มีเสถียรภาพ
ตัวอย่างง่าย: แอปมือถือส่ง "pay $20" แล้วการเชื่อมต่อขาด แอป retry หากไม่มี idempotency ลูกค้าอาจถูกเรียกเก็บเงินสองครั้ง หากมี idempotency คำขอที่สองจะคืนผลเดียวกับครั้งแรก
วิธีที่ใช้บ่อยในการทำ idempotency
ทีมส่วนใหญ่ใช้แนวทางหนึ่งในนี้ (บางครั้งผสมกัน):\n
- Idempotency key: ไคลเอนต์ส่งคีย์เฉพาะต่อการกระทำที่ตั้งใจ (เช่น
Idempotency-Key: ...) เซิร์ฟเวอร์บันทึกคีย์และการตอบกลับสุดท้าย\n- ตาราง de-duplication: เก็บแถวที่มีคีย์ (client_id, key) หรือ (order_id, operation) แล้วปฏิเสธ side effect ครั้งที่สอง\n- คีย์ทางธุรกิจ (Natural keys): ใช้ตัวระบุทางธุรกิจที่ไม่ซ้ำอยู่แล้ว ทำให้ "create payment" เกิดขึ้นได้เพียงครั้งเดียว
เมื่อมีการซ้ำเข้ามา พฤติกรรมที่ดีที่สุดโดยทั่วไปไม่ใช่การคืน "409 conflict" หรือ error ทั่วไป แต่คือการคืนผลเดียวกับที่เคยคืนครั้งแรก รวมทั้ง resource ID และสถานะ นั่นแหละที่ทำให้การ retry ปลอดภัยสำหรับไคลเอนต์และงานแบ็กกราวด์
เก็บระเบียนไว้ที่ไหน (และเก็บนานแค่ไหน)
ระเบียน idempotency ต้องอยู่ภายในขอบเขตของคุณใน storage ที่ทนทาน ไม่ใช่ในหน่วยความจำ หาก API ของคุณรีสตาร์ทแล้วลืม การรับประกันจะหายไป
เก็บระเบียนไว้นานพอที่จะครอบคลุมการ retry และการส่งล่าช้าที่สมเหตุสมผล หน้าต่างเวลาจะขึ้นกับความเสี่ยงทางธุรกิจ: นาทีถึงชั่วโมงสำหรับการสร้างความเสี่ยงต่ำ วันหลายวันสำหรับการชำระเงิน/อีเมล/การจัดส่งที่การซ้ำมีต้นทุน และนานกว่านั้นหากพาร์ทเนอร์สามารถ retry เป็นระยะเวลานานได้
หลีกเลี่ยงกับดัก "distributed transaction"
ออกแบบสถานะก่อนเริ่มโค้ด
ใช้โหมดวางแผนเพื่อแม็ปขอบเขต สถานะ และเส้นทางความล้มเหลวก่อนสร้างโค้ด
Distributed transactions ฟังดูปลอดภัย: commit ครั้งเดียวข้ามบริการ คิว และฐานข้อมูล แต่ในทางปฏิบัติ มักไม่มีให้บริการ ช้า หรือเปราะบางเกินจะพึ่งพา เมื่อมีการข้ามเครือข่าย คุณจะไม่สามารถสมมติได้ว่าทุกอย่าง commit พร้อมกัน
กับดักทั่วไปคือการสร้าง workflow ที่ใช้ได้เฉพาะเมื่อทุกขั้นตอนสำเร็จทันที: บันทึกคำสั่งซื้อ เก็บบัตรเครดิต สำรองสต็อก ส่งการยืนยัน ถ้าขั้นตอน 3 timeout มันล้มเหลวหรือสำเร็จ? ถ้าคุณ retry จะทำให้ซ้ำค่าหรือสำรองเกินหรือไม่?
สองแนวทางปฏิบัติหลีกเลี่ยงปัญหานี้:\n
- Outbox/inbox: เขียนเจตนาแบบทนทานในฐานข้อมูล (แถว outbox) ในทรานแซคชันเดียวกับการเปลี่ยนแปลงสถานะของคุณ แล้วให้ worker ส่งข้อความ ฝั่งรับเก็บ inbox โดยใช้ message ID เพื่อให้การจัดการปลอดภัยหากข้อความเดียวกันมาซ้ำ\n- Saga-style กับการชดเชย: แยก workflow เป็นขั้นตอนย่อยที่สมบูรณ์ได้เอง หากขั้นตอนหลังล้มเหลว ให้รันการชดเชย (เช่น ปล่อยสต็อกคืน หรือยกเลิกคำสั่งซื้อที่ยังไม่ได้จ่าย) แทนการพยายามย้อนประวัติ
เลือกสไตล์เดียวต่อ workflow แล้วปฏิบัติตาม การผสมผสานระหว่าง "บางครั้งเราใช้ outbox" กับ "บางครั้งสมมติ synchronous สำเร็จ" จะสร้าง edge case ที่ทดสอบยาก
กฎง่าย ๆ: ถ้าคุณไม่สามารถ commit ข้ามขอบเขตแบบอะตอมได้ ออกแบบให้รองรับ retry ซ้ำ และความล่าช้า
การคืนสถานะ: ระบบจริงกู้คืนจากความไม่ตรงกันอย่างไร
Reconciliation ยอมรับความจริงพื้นฐาน: เมื่อแอปของคุณพูดคุยกับระบบอื่นบนเครือข่าย บางครั้งคุณจะไม่เห็นด้วยกันเกี่ยวกับสิ่งที่เกิดขึ้น คำขอ timeout callbacks มาถึงช้า ผู้คน retry การทำ reconciliation คือวิธีที่คุณตรวจจับความไม่ตรงกันและแก้ไขมันเมื่อเวลาผ่านไป
ถือว่าระบบภายนอกเป็นแหล่งความจริงอิสระ แอปของคุณเก็บระเบียนภายใน แต่ยังต้องมีวิธีเปรียบเทียบระเบียนนั้นกับสิ่งที่พาร์ทเนอร์ ผู้ให้บริการ และผู้ใช้ทำจริง
กลไกการคืนสถานะทั่วไป
ทีมส่วนใหญ่ใช้ชุดเครื่องมือเรียบง่าย (เรียบแต่ดี): worker ที่ retry งานค้างและตรวจสอบสถานะภายนอก งานที่รันตามกำหนดเพื่อตรวจหาความไม่สอดคล้อง และ action เล็กๆ ของแอดมินให้ซัพพอร์ต retry ยกเลิก หรือมาร์กว่า "ตรวจแล้ว"
เปรียบเทียบอะไรและบันทึกอะไร
การคืนสถานะทำงานได้ก็ต่อเมื่อคุณรู้ว่าจะเปรียบเทียบอะไร: สมุดบัญชีภายใน vs สมุดบัญชีผู้ให้บริการ (การชำระเงิน), สถานะคำสั่งซื้อ vs สถานะการจัดส่ง (การปฏิบัติ) หรือสถานะการสมัคร vs การเรียกเก็บเงิน
ทำให้สถานะสามารถซ่อมแซมได้ แทนที่จะกระโดดจาก "created" เป็น "completed" ให้ใช้สถานะกักเก็บเช่น pending, on hold, หรือ needs review วิธีนี้ทำให้พูดว่า "เราไม่แน่ใจ" ได้อย่างปลอดภัย และให้จุดที่ชัดเจนสำหรับ reconciliation จะมาลงจอด
จับ audit trail เล็ก ๆ บนการเปลี่ยนแปลงสำคัญ:\n
- เมื่อคุณส่งคำขอและเมื่อคุณได้ยินกลับล่าสุด\n- Correlation IDs ที่ผูกระเบียนของคุณกับอ้างอิงภายนอก\n- สถานะภายนอกล่าสุด (และที่มาของมัน)\n- ฟิลด์เหตุผลสำหรับการแก้ไขด้วยมือ (ใคร อะไร ทำไม)
ตัวอย่าง: ถ้าแอปของคุณขอป้ายจัดส่งแล้วเครือข่ายขาด คุณอาจมีสถานะว่า "ไม่มีป้าย" ภายในแต่ผู้ขนส่งอาจสร้างป้ายแล้ว worker recon สามารถค้นหาตาม correlation ID หาเจอป้ายและเลื่อนสถานะคำสั่งซื้อไปข้างหน้า (หรือมาร์กเพื่อตรวจสอบถ้ารายละเอียดไม่ตรงกัน)
ทีละขั้นตอน: ออกแบบ workflow ที่รอดจากความล้มเหลวของเครือข่าย
ติดตาม intent เดียวแบบ end-to-end
เพิ่ม correlation IDs ข้าม API, worker และ webhook เพื่อการดีบักที่ง่ายขึ้น
เมื่อคุณสมมติว่าเครือข่ายจะล้มเหลว เป้าหมายจะเปลี่ยน คุณไม่ได้พยายามทำให้ทุกขั้นตอนสำเร็จในการลองครั้งเดียว แต่พยายามทำให้ทุกขั้นตอนปลอดภัยต่อการทำซ้ำและง่ายต่อการซ่อมแซม
Workflow เชิงปฏิบัติ
- เขียนประโยคสั้น ๆ เกี่ยวกับขอบเขต ระบุชัดว่าระบบของคุณเป็นเจ้าของอะไร สำเนาอะไร และขอจากผู้อื่นแค่ไหน\n
- ระบุโหมดความล้มเหลวก่อนเส้นทางสุข ได้แก่: timeouts (คุณไม่รู้ว่าทำงานหรือไม่), requests ซ้ำ, ความสำเร็จบางส่วน (ขั้นตอนหนึ่งเกิดขึ้น ขั้นตอนถัดไปไม่เกิด), และอีเวนต์ที่มาผิดลำดับ\n
- เลือกกลยุทธ์ idempotency สำหรับแต่ละ input สำหรับ API แบบ synchronous มักเป็น idempotency key + ผลลัพธ์ที่เก็บไว้ สำหรับข้อความ/อีเวนต์ มักเป็น message ID ที่ไม่ซ้ำและระเบียน "ฉันประมวลผลอันนี้แล้วไหม?"\n
- เก็บเจตนาไว้ก่อน แล้วค่อยทำงาน เก็บสิ่งที่ทนทานเช่น
PaymentAttempt: pendingหรือShipmentRequest: queuedก่อน เรียก external แล้วค่อยบันทึกผล คืนค่า reference ID คงที่เพื่อให้การ retry ชี้ไปยังเจตนาเดิมแทนการสร้างอันใหม่\n - สร้างการคืนสถานะและทางซ่อม และทำให้มองเห็นได้ การคืนสถานะอาจเป็นงานที่สแกนรายการ "ค้างนาน" แล้วตรวจสอบสถานะภายนอกอีกครั้ง ทางซ่อมอาจเป็น action ของแอดมินอย่าง "retry", "cancel", หรือ "mark resolved" พร้อมโน้ต audit เพิ่ม observability เบื้องต้น: correlation IDs, ฟิลด์สถานะชัดเจน และตัวนับบางอย่าง (pending, retries, failures)
ตัวอย่าง: ถ้า checkout timeout ทันทีหลังจากเรียก provider เก็บความพยายามไว้ คืน attempt ID ให้ผู้ใช้ และให้ผู้ใช้ retry ด้วยเดิม idempotency key ต่อมา reconciliation ยืนยันว่า provider เรียกเก็บหรือไม่และอัปเดต attempt โดยไม่ทำให้เกิดการชาร์จซ้ำ
สถานการณ์ตัวอย่าง: flow คำสั่งซื้อกับ retry และ callback ล่าช้า
ลูกค้ากด "สั่งซื้อ" เซิร์ฟเวอร์ของคุณส่งคำขอชำระเงินไปยัง provider แต่เครือข่ายไม่เสถียร ผู้ให้บริการมีความจริงของตัวเอง และฐานข้อมูลของคุณมีของคุณ พวกมันจะเบี้ยวถ้าไม่ได้ออกแบบ
สิ่งที่เกิดขึ้นภายนอก (เหตุการณ์ที่คุณไม่ควบคุม)
จากมุมมองของคุณ ภายนอกคือสตรีมของข้อความที่อาจมาช้า มาซ้ำ หรือหายไป:\n
- "ส่งคำสั่งซื้อ" ถึง API ของคุณ\n- คำขอชำระเงินของคุณไปยัง provider\n- provider ส่งเว็บฮุคว่า "authorized"\n- provider retry เว็บฮุคและส่ง callback เดิมอีกครั้ง\n- ไคลเอนต์ timeout และ retry "สั่งซื้อ"
ไม่มีขั้นตอนไหนรับประกัน "exactly once" พวกมันรับประกันได้เพียง "maybe"
สิ่งที่คุณเก็บไว้ภายใน (ระเบียนที่คุณควบคุม)
ภายในขอบเขต ให้เก็บข้อเท็จจริงที่ทนทานและข้อมูลขั้นต่ำที่เชื่อมอีเวนต์ภายนอกกับข้อเท็จจริงนั้น
เมื่อผู้ใช้สั่งซื้อครั้งแรก ให้สร้างระเบียน order ในสถานะชัดเจนเช่น pending_payment และสร้าง payment_attempt พร้อม reference ของ provider และ idempotency_key ผูกกับการกระทำของลูกค้า
ถ้าไคลเอนต์ timeout และ retry API ของคุณไม่ควรสร้างคำสั่งซื้อที่สอง แต่น่าจะมองหา idempotency_key และคืน order_id เดิมพร้อมสถานะปัจจุบัน การตัดสินใจเดียวนี้ป้องกันการซ้ำเมื่อเครือข่ายล้มเหลว
ตอนนี้เว็บฮุคมาสองครั้ง callback แรกอัปเดต payment_attempt เป็น authorized และเลื่อนคำสั่งซื้อเป็น paid callback ที่สองเข้ามาที่ handler เดิม แต่คุณตรวจพบว่าประมวลผลอีเวนต์ provider นี้แล้ว (โดยเก็บ provider event ID หรือเช็คสถานะปัจจุบัน) และไม่ทำอะไรเพิ่มเติม แต่ยังตอบ 200 OK ได้ เพราะผลลัพธ์นั้นจริงอยู่แล้ว
สุดท้าย reconciliation จัดการกรณียุ่งเหยิง หากคำสั่งซื้อยัง pending_payment หลังจากหน่วงเวลา งานแบ็กกราวด์จะ query provider โดยใช้ reference ที่เก็บไว้ ถ้า provider บอก "authorized" แต่คุณพลาดเว็บฮุค คุณอัปเดตระเบียน ถ้า provider บอก "failed" แต่คุณมาร์กเป็น paid คุณจะมาร์กเพื่อตรวจสอบหรือกระตุ้นการชดเชยเช่นคืนเงิน
ข้อผิดพลาดทั่วไปที่ทำให้เกิดการซ้ำและสถานะค้าง
เป็นเจ้าของโค้ดที่สร้างขึ้น
ควบคุมเต็มที่ด้วยการส่งออกซอร์สโค้ดเมื่อพร้อมย้ายหรือขยาย
ระเบียนซ้ำและ workflow ติดค้างส่วนใหญ่เกิดจากการสับสนระหว่างสิ่งที่เกิดขึ้นภายนอก (คำขอมาถึง, ข้อความรับได้) กับสิ่งที่คุณ commit อย่างปลอดภัยภายในระบบ
ความล้มเหลวคลาสสิก: ไคลเอนต์ส่ง "สั่งซื้อ" เซิร์ฟเวอร์เริ่มทำงาน เครือข่ายขาด ไคลเอนต์ retry ถ้าคุณถือว่าแต่ละ retry คือความจริงใหม่ คุณจะได้ค่าธรรมเนียมซ้ำ คำสั่งซื้อซ้ำ หรืออีเมลหลายฉบับ
สาเหตุที่พบบ่อย:\n
- เชื่อข้อความขาเข้าก่อนเวลา: ส่งอีเมลหรือบันทึก "คำสั่งซื้อสร้างแล้ว" ก่อน commit ลงฐานข้อมูลอย่างทนทาน\n- การ retry สร้างแถวใหม่: สร้าง order ID ใหม่ทุกครั้งแทนแม็ป retry ให้เป็นผลลัพธ์เดียว\n- สมมติ "exactly once": คิวและ callback ไม่รับประกันแบบนั้น การซ้ำ หน่วง และการมาผิดลำดับเกิดขึ้นเสมอ\n- ไม่มีตัวระบุคงที่: ถ้าตอบไม่ได้ว่า "เคยเห็นเจตนานี้ไหม" คุณป้องกันการซ้ำไม่ได้\n- มีแต่ success/failure ไม่มีสถานะกลาง: ถ้าไม่มีสถานะ pending/timeouts จะกลายเป็นปริศนาและผู้ใช้กดซ้ำ
ปัญหาใหญ่คือ: ไม่มี audit trail ถ้าคุณเขียนทับฟิลด์และเก็บแค่สถานะล่าสุด คุณจะสูญเสียหลักฐานที่ต้องใช้ในการคืนสถานะภายหลัง
ตรวจสอบความสมเหตุสมผลง่าย ๆ: "ถ้าฉันรัน handler นี้สองครั้ง จะได้ผลเหมือนเดิมไหม?" ถ้าคำตอบคือไม่ การซ้ำไม่ใช่ edge case หายาก แต่มันเกิดขึ้นแน่นอน
เช็คลิสต์ด่วนและขั้นตอนถัดไปเชิงปฏิบัติ
ถ้าจำได้อย่างหนึ่ง: แอปของคุณต้องถูกต้องแม้ข้อความมาถึงช้า มาซ้ำ หรือไม่มาถึงเลย\n ใช้เช็คลิสต์นี้เพื่อหาจุดอ่อนก่อนมันเปลี่ยนเป็นระเบียนซ้ำ การอัปเดตหายไป หรือ workflow ติดค้าง:\n
- ระบุแหล่งความจริงชัดเจน: สำหรับแต่ละ workflow ชี้ได้ว่าจุดไหนคือ "ความจริง" (มักเป็นฐานข้อมูลของคุณ)\n- ทุกการเขียน retry ได้อย่างปลอดภัย: คำสั่ง/API แต่ละอันมี idempotency key หรือ natural unique key\n- มี ID คงที่และ correlation ID ตลอดกระบวนการ: ติดตามการกระทำธุรกิจเดียวข้ามล็อก ทะเบียน และ callback\n- การคืนสถานะรันอัตโนมัติ: เปรียบเทียบ "สิ่งที่เราคิด" กับ "สิ่งที่เกิดขึ้น" เป็นประจำและซ่อมแซมหรือแจ้งเตือนชัดเจน\n- การย้อนสถานะไม่ทำให้ข้อมูลเสียหาย: การเปลี่ยนสถานะเก็บ audit และเข้ากันได้กับเวอร์ชันต่าง ๆ
ถ้าตอบคำถามใดไม่ได้ทันที นั่นเป็นสัญญาณว่าขอบเขตไม่ชัดหรือการเปลี่ยนสถานะขาด
ขั้นตอนปฏิบัติถัดไป:\n
- วาดขอบเขตและสถานะก่อน พิจารณาชุดสถานะเล็ก ๆ ต่อ workflow (เช่น: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed)\n
- เพิ่ม idempotency ในที่สำคัญที่สุด เริ่มจากการเขียนที่มีความเสี่ยงสูง: สร้างคำสั่งซื้อ เก็บเงิน ออกคืนเงิน เก็บ idempotency keys ใน PostgreSQL กับข้อจำกัด unique เพื่อปฏิเสธการซ้ำอย่างปลอดภัย\n
- มอง reconciliation เป็นฟีเจอร์ปกติ ตั้งงานที่ค้นหา "ค้างนานเกิน" ตรวจสอบระบบภายนอกอีกครั้ง และซ่อมสถานะในเครื่อง\n
- วนซ้ำอย่างปลอดภัย ปรับ transitions และกฎ retry แล้วทดสอบโดยการส่งคำขอเดิมซ้ำและประมวลผลอีเวนต์เดิมอีกครั้ง
ถ้าคุณกำลังสร้างอย่างรวดเร็วบนแพลตฟอร์มที่ขับเคลื่อนด้วยแชทอย่าง Koder.ai (koder.ai) ก็คุ้มค่าที่จะฝังกฎเหล่านี้ไว้ในบริการที่สร้างขึ้นตั้งแต่ต้น: ความเร็วมาจากการอัตโนมัติ แต่ความน่าเชื่อถือมาจากขอบเขตชัดเจน ตัวจัดการ idempotent และการคืนสถานะ
คำถามที่พบบ่อย
What does “data on the outside vs inside” mean in simple terms?
"ภายนอก" คือทุกอย่างที่คุณไม่ได้ควบคุม: เบราว์เซอร์ เครือข่ายมือถือ คิว เว็บฮุคจากบุคคลที่สาม การ retry และ timeout สมมติว่าข้อความอาจถูกหน่วง ซ้ำ หาย หรือมาถึงไม่เรียงลำดับ\n\n"ภายใน" คือสิ่งที่คุณควบคุม: สถานะที่เก็บไว้ กฎธุรกิจ และข้อเท็จจริงที่คุณสามารถพิสูจน์ได้ภายหลัง (โดยทั่วไปคือข้อมูลในฐานข้อมูลของคุณ)
Why can’t I trust incoming requests or webhooks to happen exactly once?
เพราะเครือข่ายไม่ได้บอกความจริงเสมอไป\n\nการที่ไคลเอนต์ timeout ไม่ได้แปลว่าเซิร์ฟเวอร์ไม่ได้ประมวลผลคำขอนั้น เว็บฮุคที่มาสองครั้งไม่ได้หมายความว่าผู้ให้บริการทำการกระทำนั้นสองครั้ง หากคุณถือว่าทุกข้อความเป็น "ความจริงใหม่" คุณจะสร้างคำสั่งซื้อซ้ำ เก็บเงินสองครั้ง และเกิด workflow ติดค้าง
Where should I draw the “boundary” in a typical app?
ขอบเขตชัดเจนคือจุดที่ข้อความที่ไม่เชื่อถือได้กลายเป็นข้อเท็จจริงที่ทนทาน\n\nขอบเขตทั่วไปได้แก่:\n\n- Endpoint API ที่ commit ข้อมูลลงฐานข้อมูลของคุณ\n- ตัวบริโภคคิวที่เปลี่ยนอีเวนต์เป็นการเปลี่ยนแปลงสถานะที่บันทึกไว้\n- ตัวจัดการ callback ที่บันทึกสิ่งที่ผู้ให้บริการอ้างว่าเกิดขึ้น\n\nเมื่อข้อมูลข้ามขอบเขตแล้ว ให้บังคับใช้ invariant ภายใน (เช่น "คำสั่งซื้อจ่ายได้ครั้งเดียว")
How do I stop double charges when users retry “Pay”?
ใช้ idempotency แนวคิดคือ: ความตั้งใจเดียวกันควรให้ผลลัพธ์เดียวกันแม้ส่งหลายครั้ง\n\nรูปแบบปฏิบัติ:\n\n- ไคลเอนต์ส่ง idempotency key ต่อการกระทำ\n- เซิร์ฟเวอร์บันทึกคีย์และผลลัพธ์สุดท้ายใน storage ที่ทนทาน\n- เมื่อเกิดซ้ำ ให้คืน resource ID/สถานะเดียวกับครั้งแรก
Where do I store idempotency records, and how long should I keep them?
อย่าเก็บไว้แค่ในหน่วยความจำ เก็บไว้ในขอบเขตของคุณ (เช่น PostgreSQL) เพื่อให้การรีสตาร์ทไม่ทำให้การป้องกันหายไป\n\nกฎการเก็บโดยประมาณ:\n\n- การกระทำความเสี่ยงต่ำ: นาทีนับถึงชั่วโมง\n- การกระทำค่าใช้จ่ายสูง (การชำระเงิน การคืนเงิน การจัดส่ง อีเมล): ควรเป็นวันหรือมากกว่า\n\nเก็บไว้นานพอที่จะครอบคลุมการ retry และ callback ที่ล่าช้าได้
What states should I add to avoid “we're not sure” bugs?
ใช้สถานะที่ยอมรับความไม่แน่นอนได้\n\nชุดสถานะที่เป็นประโยชน์:\n\n- pending_* (ยอมรับความตั้งใจแล้วแต่ยังไม่ทราบผล)\n- succeeded / failed (บันทึกผลสุดท้ายแล้ว)\n- needs_review (พบความไม่ตรงกัน ต้องการมนุษย์หรืองานพิเศษ)\n\nวิธีนี้ช่วยให้ไม่ต้องเดาเมื่อเกิด timeout และทำให้ reconciliation ง่ายขึ้น
Why are distributed transactions usually a trap for app workflows?
เพราะคุณไม่สามารถ commit แบบอะตอมข้ามหลายระบบที่เชื่อมต่อเครือข่ายได้เสมอ\n\nถ้าทำเป็นลำดับ synchronous ทั้งหมด เช่น บันทึกคำสั่งซื้อ → เก็บเงิน → สำรองสต็อก แล้วขั้นตอนที่ 2 timeout คุณจะไม่รู้ว่าควร retry หรือไม่ การ retry อาจทำให้เกิดการซ้ำ; ไม่ retry อาจทำให้งานไม่เสร็จ\n\nออกแบบให้ยอมรับความสำเร็จบางส่วน: บันทึกความตั้งใจก่อน ทำงานภายนอก แล้วบันทึกผล
What is the outbox/inbox pattern, and when should I use it?
outbox/inbox ช่วยให้การส่งข้อความข้ามระบบเชื่อถือได้โดยไม่ต้องทำเป็นว่าเครือข่ายสมบูรณ์\n\n- Outbox: ในทรานแซคชันเดียวกับการเปลี่ยนแปลงสถานะ ให้เขียนแถวที่เป็นข้อความที่ต้องการส่ง\n- worker อ่าน outbox แล้วส่งข้อความ\n- Inbox (ด้านรับ): เก็บ ID ของข้อความที่ประมวลผลแล้วเพื่อให้การส่งซ้ำไม่สร้างผลข้างเคียงซ้ำ
What is reconciliation, and what’s a simple way to implement it?
Reconciliation คือวิธีคืนสถานะเมื่อข้อมูลของคุณไม่ตรงกับระบบภายนอก\n\nค่าเริ่มต้นที่ดี:\n\n- งานที่กำหนดเวลาตรวจสอบรายการ "ค้างนานเกินไป"\n- ขั้นตอนเปรียบเทียบ (สถานะของเรา vs สถานะผู้ให้บริการ)\n- การซ่อมแซม: retry, ยกเลิก, คืนเงิน หรือตั้ง needs_review\n\nสำหรับการชำระเงิน การจัดส่ง หรือการสมัครที่มีเว็บฮุค การทำ reconciliation ไม่ใช่เรื่องเลือกได้
Does this still matter if I’m building quickly with a platform like Koder.ai?
ใช่ ความเร็วไม่ได้ทำให้ความล้มเหลวของเครือข่ายหายไป\n\nถ้าสร้างบริการด้วย Koder.ai ให้ฝังค่าเริ่มต้นเหล่านี้ตั้งแต่ต้น:\n\n- ขอบเขตชัดเจน (เมื่อใดความตั้งใจกลายเป็น durable)\n- ตัวจัดการที่ idempotent สำหรับการสร้าง/การตัดเงิน/คืนเงิน\n- Correlation IDs เก็บพร้อมข้อมูลอ้างอิงภายนอก\n- งาน reconciliation สำหรับรายการค้าง\n\nเมื่อทำเช่นนี้ การ retry และ callback ซ้ำจะเป็นเรื่องปกติ แทนที่จะเป็นเรื่องหน้าเสีย