19 เม.ย. 2568·3 นาที
ความชัดเจนของ Kelsey Hightower ในโลกคลาวด์เนทีฟ: อธิบาย Kubernetes
สไตล์การสอนที่ชัดเจนของ Kelsey Hightower ช่วยให้ทีมเข้าใจ Kubernetes และแนวคิดการปฏิบัติการ สร้างความมั่นใจ ภาษาเดียวกันในทีม และเร่งการนำไปใช้ในวงกว้าง
สไตล์การสอนที่ชัดเจนของ Kelsey Hightower ช่วยให้ทีมเข้าใจ Kubernetes และแนวคิดการปฏิบัติการ สร้างความมั่นใจ ภาษาเดียวกันในทีม และเร่งการนำไปใช้ในวงกว้าง
เครื่องมือคลาวด์เนทีฟสัญญาว่าจะมอบความเร็วและความยืดหยุ่น แต่ก็เพิ่มคำศัพท์ใหม่ ชิ้นส่วนที่เคลื่อนไหวได้ใหม่ และวิธีคิดใหม่เกี่ยวกับการปฏิบัติการ เมื่อการอธิบายไม่ชัดเจน การนำไปใช้ก็ช้าลงด้วยเหตุผลง่ายๆ: ผู้คนเชื่อมโยงเครื่องมือกับปัญหาจริงของพวกเขาไม่ได้ ทีมลังเล ผู้นำเลื่อนการตัดสินใจ และการทดลองระยะแรกกลายเป็นพิลอตที่ทำไม่เสร็จ
ความชัดเจนเปลี่ยนพลวัตนั้น คำอธิบายที่ชัดเจนเปลี่ยนคำว่า “อธิบาย Kubernetes” จากวาทกรรมการตลาดเป็นความเข้าใจร่วมกัน: Kubernetes ทำอะไร ไม่ทำอะไร และทีมของคุณต้องรับผิดชอบอะไรในแต่ละวัน เมื่อแบบจำลองในหัวนั้นอยู่แล้ว การสนทนาจะเป็นรูปธรรม—เกี่ยวกับงานที่จะรัน ความน่าเชื่อถือ การสเกล ความปลอดภัย และนิสัยการปฏิบัติที่จำเป็นเพื่อรันระบบโปรดักชัน
เมื่อแนวคิดถูกอธิบายด้วยภาษาง่ายๆ ทีมจะ:
กล่าวคือ การสื่อสารไม่ใช่สิ่งที่มีไว้เสริม; มันเป็นส่วนหนึ่งของแผนการนำไปใช้
บทความนี้มุ่งเน้นที่สไตล์การสอนของ Kelsey Hightower ว่าทำให้แนวคิดหลักของ DevOps และพื้นฐานของ Kubernetes ดูเข้าถึงได้อย่างไร—และวิธีที่แนวทางนั้นส่งผลต่อการนำ cloud-native ไปใช้โดยรวม คุณจะได้บทเรียนที่นำไปใช้ในองค์กรของคุณได้จริง:
เป้าหมายไม่ใช่การถกเถียงเรื่องเครื่องมือ แต่คือการแสดงให้เห็นว่าการสื่อสารที่ชัดเจน—ซ้ำแล้วซ้ำเล่า แบ่งปัน และพัฒนาในชุมชน—สามารถพาอุตสาหกรรมจากความสงสัยไปสู่การใช้งานอย่างมั่นใจ
Kelsey Hightower เป็นผู้สอน Kubernetes ที่เป็นที่รู้จักและเป็นเสียงสำคัญในชุมชน งานของเขาช่วยให้หลายทีมเข้าใจสิ่งที่การออร์เคสตราเตชันคอนเทนเนอร์หมายถึง—โดยเฉพาะส่วนการปฏิบัติการที่ผู้คนมักเรียนรู้ด้วยวิธีที่เจ็บปวด
เขาปรากฏตัวในบทบาทที่เป็นประโยชน์และเปิดเผย: การพูดในงานอุตสาหกรรม เผยแพร่บทเรียนและการพูด และมีส่วนร่วมในชุมชน cloud-native ที่ผู้ปฏิบัติแลกเปลี่ยนรูปแบบ ข้อผิดพลาด และวิธีแก้ แทนที่จะนำเสนอบทบาท Kubernetes เป็นสินค้าวิเศษ ผลงานของเขามักมองมันเป็นระบบที่คุณต้องปฏิบัติการ—ซึ่งมีชิ้นส่วนที่เคลื่อนไหว ข้อแลกเปลี่ยน และรูปแบบความล้มเหลวจริง
สิ่งที่โดดเด่นคือความเห็นอกเห็นใจต่อผู้ที่ต้องรับผิดชอบเมื่อมีสิ่งผิดพลาด: วิศวกร on-call ทีมแพลตฟอร์ม SRE และนักพัฒนาที่พยายามส่งงานพร้อมกับเรียนรู้โครงสร้างพื้นฐานใหม่
ความเห็นอกเห็นใจนั้นปรากฏในวิธีที่เขาอธิบาย:
ยังเห็นได้จากวิธีที่เขาพูดกับผู้เริ่มต้นโดยไม่ทำให้รู้สึกถูกดูถูก น้ำเสียงมักตรงไปตรงมา มีพื้นฐาน และระมัดระวังคำกล่าว — มากกว่า “นี่คือวิธีที่ดีที่สุดหนึ่งเดียว” เป็น “นี่คือสิ่งที่จะเกิดขึ้นใต้ฝากระโปรง”
คุณไม่จำเป็นต้องยกใครเป็นมาสคอตเพื่อเห็นผลกระทบ หลักฐานอยู่ในเนื้อหาเอง: การพูดที่ถูกอ้างอิงอย่างกว้าง แหล่งเรียนรู้เชิงปฏิบัติ และคำอธิบายที่ถูกนำไปใช้ซ้ำโดยผู้สอนคนอื่นและทีมแพลตฟอร์มภายใน เมื่อคนพูดว่าเขา “ในที่สุดก็เข้าใจ” แนวคิดเช่น control planes ใบรับรอง หรือการบูตสตาร์ทคลัสเตอร์ มักเพราะมีคนอธิบายอย่างชัดเจน—และคำอธิบายเหล่านั้นหลายครั้งสืบย้อนกลับไปที่สไตล์การสอนของเขา
ถ้าการนำ Kubernetes ไปใช้เป็นปัญหาด้านการสื่อสาร อิทธิพลของเขาเตือนใจว่าการสอนที่ชัดเจนก็เป็นโครงสร้างพื้นฐานชนิดหนึ่งเช่นกัน
ก่อนที่ Kubernetes จะกลายเป็นคำตอบเริ่มต้นสำหรับ “เราจะรันคอนเทนเนอร์ในโปรดักชันอย่างไร?” มันมักให้ความรู้สึกเป็นกำแพงหนาทึบของคำศัพท์และสมมติฐานใหม่ แม้ทีมที่คุ้นเคยกับ Linux CI/CD และบริการคลาวด์แล้วก็ยังพบว่าต้องตั้งคำถามพื้นฐาน—แล้วรู้สึกว่าตัวเอง “ไม่ควรถาม”
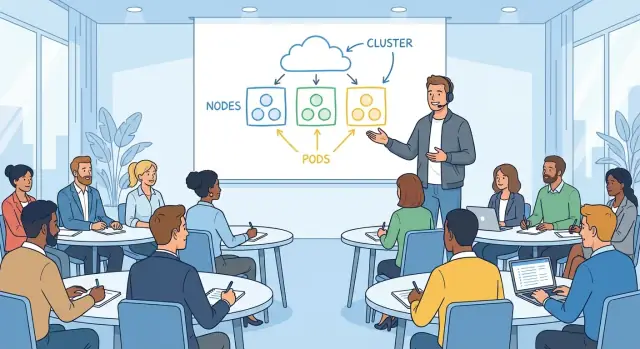
Kubernetes นำวิธีคิดใหม่เกี่ยวกับแอปพลิเคชันมาแทนคำเก่า แทนที่จะคิดว่า “เซิร์ฟเวอร์ตัวหนึ่งรันแอปของฉัน” คุณจะเห็น pods, deployments, services, ingresses, controllers, และ clusters แต่ละคำฟังดูเรียบง่ายเมื่อแยกกัน แต่วิธีการเชื่อมโยงกันต่างหากที่ทำให้ความหมายชัด
จุดที่ติดค้างทั่วไปคือความไม่ตรงกันของแบบจำลองทางความคิด:
นี่ไม่ใช่แค่การเรียนรู้เครื่องมือ แต่เป็นการเรียนรู้ระบบที่ถือว่าโครงสร้างพื้นฐานเป็นสิ่งที่ไหลได้
เดโมแรกอาจโชว์การสเกลคอนเทนเนอร์อย่างราบรื่น ความกังวลเริ่มต้นขึ้นเมื่อคนจินตนาการคำถามการปฏิบัติการจริง:
หลายทีมไม่ได้กลัว YAML แต่กลัวความซับซ้อนที่ซ่อนอยู่ ที่ความผิดพลาดอาจเงียบจนไม่รู้ตัวจนเกิดเหตุ
Kubernetes มักถูกนำเสนอเป็นแพลตฟอร์มเรียบร้อยที่คุณ “แค่ดีพลอย” แต่ในทางปฏิบัติ การไปถึงประสบการณ์นั้นต้องการการตัดสินใจ: เครือข่าย ที่จัดเก็บ ตัวตน นโยบาย การมอนิเตอริง การล็อก และยุทธศาสตร์การอัพเกรด
ช่องว่างนี้สร้างความหงุดหงิด ผู้คนไม่ได้ปฏิเสธ Kubernetes เอง แต่ตอบโต้กับความยากที่จะเชื่อมคำสัญญา (“เรียบง่าย พกพา ซ่อมตัวเอง”) กับขั้นตอนที่ต้องทำเพื่อให้มันเป็นจริงในสภาพแวดล้อมของพวกเขา
Kelsey Hightower สอนเหมือนคนที่เคยรับหน้าที่ on-call เคยมีการดีพลอยที่พลิกผัน และยังต้องส่งงานเพิ่มในวันถัดไป เป้าหมายไม่ใช่การโชว์คำศัพท์ แต่คือการช่วยคุณสร้างแบบจำลองในหัวที่ใช้ได้ตอนตีสองเมื่อ pager ดัง
นิสัยสำคัญคือการนิยามคำศัพท์ในขณะที่มันมีความหมาย แทนที่จะยัดพจนานุกรม Kubernetes ยาวๆ ขึ้นต้น เขาอธิบายแนวคิดตามบริบท: ว่า Pod คืออะไรในขณะที่อธิบายว่าทำไมต้องรวมคอนเทนเนอร์ หรือว่า Service ทำหน้าที่อย่างไรเมื่อคำถามคือ “คำร้องขอจะหาทางไปยังแอปของฉันอย่างไร?”
แนวทางนี้ลดความรู้สึก "ตามไม่ทัน" ที่วิศวกรหลายคนมี คุณไม่ต้องท่องพจนานุกรม; คุณเรียนรู้โดยตามปัญหาไปสู่ทางแก้
คำอธิบายของเขามักเริ่มจากสิ่งที่จับต้องได้:
คำถามเหล่านำไปสู่ primitives ของ Kubernetes โดยธรรมชาติ แต่ถูกยึดโยงกับสถานการณ์ที่วิศวกรคุ้นเคย ผังภาพยังช่วยได้ แต่ตัวอย่างที่จับต้องได้ทำงานหนักกว่า
สำคัญที่สุดคือการสอนครอบคลุมส่วนที่ไม่หวือหวา: การอัพเกรด เหตุการณ์ และการแลกเปลี่ยน มันไม่ใช่ "Kubernetes ทำให้ทุกอย่างง่าย" แต่คือ "Kubernetes ให้กลไกแก่คุณ—ตอนนี้คุณต้องปฏิบัติการมัน"
นั่นหมายถึงการยอมรับข้อจำกัด:
นี่คือเหตุผลที่เนื้อหาของเขาตอบโจทย์วิศวกรที่ทำงานจริง: มันถือ production เป็นห้องเรียน และความชัดเจนเป็นรูปแบบหนึ่งของความเคารพ
“Kubernetes the Hard Way” น่าจดจำไม่ใช่เพราะยากเพื่อให้ยาก แต่เพราะมันให้คุณสัมผัสชิ้นส่วนที่บทเรียนอื่นมักซ่อน แทนที่จะคลิกผ่านวิซาร์ดของบริการที่จัดการ คุณประกอบคลัสเตอร์ทีละชิ้น การเรียนรู้ด้วยการลงมือทำเปลี่ยนโครงสร้างพื้นฐานจากกล่องดำเป็นระบบที่คุณพิจารณาเหตุผลได้
ขั้นตอนมีให้คุณสร้างบล็อกก่อสร้างด้วยตัวเอง: ใบรับรอง kubeconfigs คอมโพเนนต์ control plane เครือข่าย และการตั้งค่าโหนด worker แม้คุณจะไม่คิดจะรัน Kubernetes แบบนี้ในโปรดักชัน การฝึกจะสอนว่าคอมโพเนนต์แต่ละตัวมีหน้าที่อะไรและจะเกิดอะไรขึ้นเมื่อมันกำหนดค่าผิด
คุณไม่ได้แค่ได้ยินว่า “etcd สำคัญ”—คุณเห็นว่าทำไมมันสำคัญ เก็บอะไร และจะเกิดอะไรขึ้นถ้ามันใช้การไม่ได้ คุณไม่ได้ท่องว่า “API server คือประตูหน้า”—คุณตั้งค่ามันและเข้าใจว่ากุญแจไหนที่มันตรวจก่อนจะอนุญาตคำขอ
หลายทีมกังวลกับการนำ Kubernetes มาใช้เพราะบอกไม่ได้ว่าใต้ฝากระโปรงเกิดอะไรขึ้น การสร้างจากพื้นฐานพลิกความรู้สึกนั้น เมื่อคุณเข้าใจโซ่แห่งความไว้วางใจ (certs) แหล่งความจริง (etcd) และแนวคิด control loop (controllers คอยปรับความต่างระหว่างสถานะที่ต้องการและที่เป็นจริง) ระบบจะดูไม่ลึกลับอีกต่อไป
ความไว้วางใจนี้มีประโยชน์ในทางปฏิบัติ: ช่วยให้คุณประเมินฟีเจอร์ของผู้ให้บริการ แปลเหตุการณ์ และเลือกค่าพื้นฐานที่สมเหตุสมผล คุณสามารถพูดว่า “เราเข้าใจสิ่งที่บริการจัดการกำลังละทิ้งให้เรา” แทนการหวังว่ามันจะถูกต้อง
การเดินทางที่ดีจะแบ่ง “Kubernetes” ออกเป็นขั้นเล็กๆ ที่ทดสอบได้ แต่ละขั้นมีผลลัพธ์ที่คาดหวังชัดเจน—เซอร์วิสเริ่มทำงาน ตรวจเช็กผ่าน สุขภาพผ่าน โหนดเข้าร่วม ความคืบหน้าวัดได้และความผิดพลาดถูกจำกัด
โครงสร้างแบบนี้ลดความวิตกกังวล: ความซับซ้อนกลายเป็นชุดของการตัดสินใจที่เข้าใจได้ ไม่ใช่การกระโดดครั้งเดียวสู่ความไม่รู้
ความสับสนใน Kubernetes ส่วนใหญ่เกิดจากการมองมันเป็นกองฟีเจอร์ แทนคำสัญญาง่ายๆ: คุณบอกว่าต้องการอะไร แล้วระบบจะพยายามให้ความเป็นจริงตรงกับสิ่งที่คุณขอ
“Desired state” คือทีมของคุณเขียนผลลัพธ์ที่คาดหวัง: ให้รันสามสำเนาของแอปนี้ เผยแพร่บนที่อยู่ที่คงที่ จำกัดการใช้ CPU มันไม่ใช่รูทีนทีละขั้น ความแตกต่างนี้สำคัญเพราะมันสะท้อนงานปฏิบัติการประจำวัน แทนที่จะพูดว่า “SSH ไปเซิร์ฟเวอร์ A เริ่มโปรเซส คัดลอกคอนฟิก” คุณประกาศเป้าหมายและปล่อยให้แพลตฟอร์มจัดการขั้นตอนซ้ำๆ
Reconciliation คือวงจรตรวจสอบและแก้ไขอย่างต่อเนื่อง Kubernetes เปรียบเทียบสิ่งที่รันอยู่ตอนนี้กับสิ่งที่คุณขอ และถ้ามีสิ่งใดคลาดเคลื่อน—แอปล้ม โหนดหาย คอนฟิกเปลี่ยน—มันจะลงมือแก้
พูดง่ายๆ: มันเหมือนวิศวกร on-call ที่ไม่หลับ คอยปรับมาตรฐานที่ตกลงกันไว้ตลอดเวลา
นี่คือที่ที่การแยก แนวคิด ออกจาก รายละเอียดการใช้งาน ช่วยได้ แนวคิดคือ “ระบบแก้ความคลาดเคลื่อน” การใช้งานอาจใช้ controllers, replica sets หรือยุทธศาสตร์ rollout—แต่คุณเรียนรายละเอียดเหล่านั้นทีหลังโดยไม่เสียแก่น
Scheduling ตอบคำถามเชิงปฏิบัติที่ผู้ปฏิบัติการคุ้นเคย: งานนี้ควรรันบนเครื่องไหน? Kubernetes ดูความจุที่มี เงื่อนไข และนโยบาย แล้ววางงานบนโหนด
การเชื่อม primitives กับหน้าที่คุ้นเคยทำให้มันคลิก:
เมื่อคุณมอง Kubernetes ว่าเป็น “ประกาศ, ปรับความต่าง, จัดวาง” สิ่งที่เหลือก็เป็นคำศัพท์—มีประโยชน์ แต่ไม่ลึกลับอีกต่อไป
การพูดเรื่องปฏิบัติการอาจฟังเหมือนภาษาลับ: SLIs, error budgets, “blast radius”, “capacity planning” เมื่อคนรู้สึกถูกกีดกัน พวกเขาจะพยักหน้าไปหรือหลีกเลี่ยงหัวข้อนั้น—ทั้งสองผลลัพธ์นำไปสู่ระบบที่เปราะบาง
สไตล์ของ Kelsey ทำให้การปฏิบัติการเป็นวิศวกรรมธรรมดา: ชุดคำถามปฏิบัติที่ฝึกได้ แม้คุณจะเป็นมือใหม่
แทนที่จะมองการปฏิบัติการเป็น “แนวปฏิบัติที่ดีที่สุด” ให้แปลเป็นสิ่งที่บริการของคุณต้องทำเมื่อตกอยู่ภายใต้แรงกดดัน
ความน่าเชื่อถือกลายเป็น: อะไรพังเป็นอย่างแรก และเราจะสังเกตได้อย่างไร? ความจุกลายเป็น: เกิดอะไรขึ้นเมื่อทราฟฟิกพุ่งในเช้าวันจันทร์? โหมดความล้มเหลวกลายเป็น: พึ่งพิงตัวไหนจะหลอกเรา หน่วงเวลา หรือคืนข้อมูลบางส่วน? การสังเกตได้กลายเป็น: ถ้าลูกค้าบ่น เราสามารถตอบว่า “อะไรเปลี่ยน” ได้ในห้านาทีไหม?
เมื่อแนวคิด ops ถูกถ้อยเป็นแบบนี้ มันหยุดฟังดูเหมือนเรื่องที่ต้องท่อง และเริ่มฟังเหมือนสามัญสำนึก
คำอธิบายที่ดีไม่อ้างว่ามีทางเดียวที่ถูก—แต่แสดงต้นทุนของแต่ละทางเลือก
ความเรียบง่าย vs การควบคุม: บริการที่จัดการลดงานเบา แต่จำกัดการปรับจูนระดับล่าง
ความเร็ว vs ความปลอดภัย: ปล่อยเร็วอาจลดการตรวจสอบวันนี้ แต่เพิ่มโอกาสต้องดีบักโปรดักชันพรุ่งนี้
การตั้งชื่อการแลกเปลี่ยนอย่างชัดเจนทำให้ทีมโต้แย้งกันอย่างสร้างสรรค์โดยไม่ดูถูกกันว่า "ไม่เข้าใจ"
การปฏิบัติการเรียนรู้ได้จากเหตุการณ์จริงและเกือบพลาด ไม่ใช่การท่องศัพท์ วัฒนธรรม ops ที่ดีถือว่าการตั้งคำถามเป็นงาน ไม่ใช่ความอ่อนแอ
นิสัยปฏิบัติ: หลังเหตุการณ์หรือสัญญาณที่น่าตกใจ จดสามข้อ—สิ่งที่คาดว่าเกิด สิ่งที่เกิดจริง และสัญญาณที่จะเตือนก่อนหน้านั้น สิ่งเล็กๆ นี้เปลี่ยนความสับสนให้เป็น runbook ที่ดีขึ้น dashboard ชัด และ on-call ที่ใจเย็นขึ้น
ถ้าคุณอยากให้มุมมองนี้แพร่หลาย สอนมันด้วยคำง่ายๆ การแลกเปลี่ยนตรงไปตรงมา และการอนุญาตให้เรียนรู้ต่อหน้าผู้อื่น
คำอธิบายที่ชัดเจนไม่ได้ช่วยคนเดียวเท่านั้น มันเดินทาง เมื่อผู้บรรยายหรือผู้เขียนทำให้ Kubernetes ดูเป็นรูปธรรม—ชี้ว่าชิ้นส่วนแต่ละชิ้นทำอะไร ทำไมมี และจะล้มในชีวิตจริงอย่างไร—ความคิดเหล่านั้นจะถูกทวนซ้ำในคุยทางเดิน คัดลอกใส่เอกสารภายใน และสอนซ้ำที่มิตติ้ง
Kubernetes มีคำศัพท์มากที่ฟังดูคุ้นแต่มีความหมายเฉพาะ: cluster, node, control plane, pod, service, deployment เมื่อคำอธิบายชัด ทีมจะหยุดคุยกันคนละเรื่อง
ตัวอย่างที่เห็นได้:
การสอดคล้องนี้เร่งการดีบัก การวางแผน และการเริ่มงานเพราะคนเสียเวลาน้อยลงกับการแปลความ
วิศวกรหลายคนหลีกเลี่ยง Kubernetes ตอนแรกไม่ใช่เพราะเรียนไม่ได้ แต่เพราะมันเหมือนกล่องดำ การสอนที่ชัดเจนแทนที่ความลึกลับด้วยแบบจำลองในหัว: “นี่คือสิ่งที่คุยกับอะไร นี่คือที่เก็บสถานะ นี่คือทางที่ทราฟฟิกถูกนำทาง”
เมื่อแบบจำลองนั้นชัดทดลองจะปลอดภัยขึ้น ผู้คนยินดีที่จะ:
เมื่อคำอธิบายจับใจ ชุมชนจะทวนซ้ำ ผังหรืออุปมาเรียบง่ายกลายเป็นวิธีมาตรฐานสอน และมีอิทธิพลต่อ:
เมื่อเวลาผ่านไป ความชัดเจนกลายเป็นวัฒนธรรม: ชุมชนไม่ได้แค่เรียน Kubernetes แต่เรียนรู้การพูดถึงการปฏิบัติการมัน
การสื่อสารที่ชัดเจนไม่เพียงทำให้ Kubernetes เรียนรู้ได้ง่ายขึ้น—มันเปลี่ยนวิธีที่องค์กรตัดสินใจรับเอามัน เมื่อระบบซับซ้อนถูกอธิบายด้วยภาษาง่าย ความเสี่ยงที่รับรู้ลดลง และทีมสามารถพูดถึงผลลัพธ์แทนศัพท์ได้
ผู้บริหารและผู้นำ IT ส่วนใหญ่ไม่ต้องการรายละเอียดการใช้งานทั้งหมด แต่ต้องการเรื่องราวที่เชื่อถือได้เกี่ยวกับการแลกเปลี่ยน การอธิบายตรงไปตรงมาว่า Kubernetes คืออะไร (และไม่ใช่) ช่วยทำให้การสนทนาเรื่อง:
เมื่อ Kubernetes ถูกนำเสนอเป็นชุดบล็อกที่เข้าใจได้ การพูดเรื่องงบประมาณและเวลาเป็นเรื่องที่มีเหตุผลมากขึ้น ทำให้รันพิลอตและวัดผลได้ง่ายขึ้น
การนำไปใช้ในอุตสาหกรรมไม่ได้แพร่ผ่านสไลด์ขายของเท่านั้น แต่มันแพร่ผ่านการสอน การพูดที่มีสัญญาณสูง เดโม และคู่มือเชิงปฏิบัติที่สร้างคำศัพท์ร่วมข้ามบริษัทและบทบาทงาน
การศึกษานี้มักแปลเป็นตัวเร่งสามอย่าง:
เมื่อทีมอธิบายแนวคิดอย่าง desired state controllers และยุทธศาสตร์ rollout ได้ Kubernetes ก็ถูกหยิบขึ้นมาพูดคุย—และดังนั้นก็ถูกนำไปใช้
แม้คำอธิบายยอดเยี่ยมก็ทดแทนการเปลี่ยนแปลงองค์กรไม่ได้ การนำ Kubernetes ไปใช้งานยังต้องการ:
การสื่อสารทำให้ Kubernetes เข้าถึงได้ ความสำเร็จในการนำไปใช้ยังต้องการความมุ่งมั่น การฝึกฝน และแรงจูงใจที่สอดคล้องกัน
การนำ Kubernetes มักล้มเหลวด้วยเหตุผลธรรมดา: คนทำนายการปฏิบัติการหลังวันแรกไม่ได้ ไม่รู้จะเรียนอะไรเป็นอันดับแรก และเอกสารสมมติว่าทุกคนพูดภาษา “cluster” เหมือนกัน วิธีแก้เชิงปฏิบัติคือถือความชัดเจนเป็นส่วนหนึ่งของแผนการนำไปใช้—ไม่ใช่เรื่องที่มาคิดทีหลัง
ทีมส่วนใหญ่ผสมรวม “วิธีใช้ Kubernetes” กับ “วิธีปฏิบัติการ Kubernetes” แยกการฝึกเป็นสองเส้นทางชัดเจน:
วางการแยกนี้ไว้บนสุดของเอกสารเพื่อพนักงานใหม่จะไม่เผลอเริ่มจากที่ลึกเกินไป
เดโมควรเริ่มด้วยระบบเล็กที่สุดที่ทำงานได้ และเพิ่มความซับซ้อนเมื่อจำเป็นเพื่อไขคำถามจริง เริ่มด้วย Deployment และ Service หนึ่งรายการ แล้วเพิ่มคอนฟิก health checks และ autoscaling เมื่อพื้นฐานเสถียรแล้วค่อยแนะนำ ingress controllers service mesh หรือ custom operators เป้าหมายคือให้ผู้คนเชื่อมสาเหตุและผล ไม่ใช่ท่อง YAML
Runbook ที่เป็นเช็คลิสต์ล้วนจะกลายเป็นการปฏิบัติแบบ cargo-cult แต่ละขั้นสำคัญควรมีเหตุผลหนึ่งประโยค: มันแก้อาการอะไร ผลลัพธ์ที่สำเร็จเป็นอย่างไร และอะไรอาจเกิดขึ้นผิดพลาด
ตัวอย่าง: “การรีสตาร์ทพ็อดเคลียร์ connection pool ที่ค้าง; หากเกิดซ้ำภายใน 10 นาที ให้เช็ก latency ของ downstream และเหตุการณ์ HPA” ประโยค “ทำไม” นั้นช่วยให้คนสามารถดัดแปลงเมื่อเหตุการณ์ไม่ตรงกับสคริปต์
คุณจะรู้ว่าการฝึก Kubernetes ได้ผลเมื่อ:
ติดตามผลลัพธ์เหล่านี้แล้วปรับเอกสารและเวิร์คชอปของคุณ ความชัดเจนเป็นผลลัพธ์—ปฏิบัติต่อมันเป็นงานหนึ่งงาน
วิธีหนึ่งที่มักถูกมองข้ามเพื่อให้แนวคิดแพลตฟอร์ม “ติด” คือให้ทีมทดลองกับบริการที่สมจริงก่อนแตะสภาพแวดล้อมสำคัญ นั่นอาจหมายถึงการสร้างแอปอ้างอิงภายในเล็กๆ (API + UI + ฐานข้อมูล) แล้วใช้เป็นตัวอย่างสม่ำเสมอในเอกสาร เดโม และการซ้อมแก้ปัญหา
แพลตฟอร์มอย่าง Koder.ai ช่วยตรงนี้เพราะคุณสามารถสร้างเว็บแอป backend และโมเดลข้อมูลจากสเปคที่ขับเคลื่อนด้วยแชท แล้ววนปรับในโหมดวางแผนก่อนใครจะกังวลเรื่อง YAML ที่สมบูรณ์ จุดประสงค์ไม่ใช่แทนการเรียนรู้ Kubernetes แต่เพื่อย่นระยะเวลาจาก ไอเดีย → บริการที่รันได้ เพื่อให้การฝึกสอนมุ่งไปที่แบบจำลองการปฏิบัติการ (desired state, rollouts, observability, การเปลี่ยนแปลงที่ปลอดภัย)
วิธีที่เร็วที่สุดในการทำให้ “แพลตฟอร์ม” ใช้งานได้ในบริษัทคือทำให้มันเข้าใจได้ คุณไม่ต้องการให้วิศวกรทุกคนเป็นผู้เชี่ยวชาญ Kubernetes แต่คุณต้องการคำศัพท์ร่วมและความมั่นใจในการดีบักปัญหาพื้นฐานโดยไม่ตระหนก
นิยาม: เริ่มด้วยประโยคชัดๆ หนึ่งประโยค ตัวอย่าง: “Service คือที่อยู่ที่เสถียรสำหรับชุด Pods ที่เปลี่ยนแปลงได้” หลีกเลี่ยงการยัดนิยามห้าข้อพร้อมกัน
แสดง: สาธิตแนวคิดด้วยตัวอย่างเล็กที่สุดที่เป็นไปได้ ไฟล์ YAML หนึ่งไฟล์ คำสั่งหนึ่งคำสั่ง ผลลัพธ์ที่คาดหวังหนึ่งอย่าง ถ้าไม่สามารถแสดงได้เร็วๆ แสดงว่าสโคปใหญ่เกินไป
ฝึก: ให้ภารกิจสั้นๆ ที่คนทำได้เอง (แม้ในแซนด์บ็อกซ์) “สเกล Deployment นี้และดูว่า Service endpoint เป็นอย่างไร” การเรียนรู้จะติดเมื่อลงมือ
แก้ปัญหา: จบด้วยการทำให้มันพังโดยเจตนาและเดินผ่านวิธีคิด “คุณจะตรวจอะไรเป็นอันดับแรก: events, logs, endpoints หรือ network policy?” ที่นี่คือที่ความมั่นใจเชิงปฏิบัติการเติบโต
อุปมามีประโยชน์เพื่อปูทิศทาง แต่ไม่ใช่เพื่อความแม่นยำ “Pods เหมือนวัว ไม่ใช่สัตว์เลี้ยง” อธิบายการทดแทนได้ดี แต่ก็อาจซ่อนรายละเอียดสำคัญ (workloads ที่มีสถานะ persistent volumes disruption budgets)
กฎง่ายๆ: ใช้อุปมาเพื่อแนะนำแนวคิด แล้วเปลี่ยนกลับไปใช้คำจริงเร็วๆ พูดว่า “มันเหมือน X ในแง่หนึ่ง; นี่คือที่มันหยุดเหมือนไม่เหมือน X” ประโยคเดียวช่วยป้องกันความเข้าใจผิดที่มีค่าใช้จ่ายสูงในภายหลัง
ก่อนนำเสนอ ยืนยันสี่อย่าง:
ความสม่ำเสมอชนะการฝึกเรียนครั้งใหญ่เป็นครั้งคราว ลองพิธีกรรมเบาๆ:
เมื่อการสอนกลายเป็นเรื่องปกติ การนำไปใช้จะใจเย็นขึ้น—และแพลตฟอร์มของคุณจะเลิกเป็นกล่องดำ
สแตกคลาวด์เนทีฟเพิ่มองค์ประกอบใหม่ (เช่น pods, services, control planes) และความรับผิดชอบด้านการปฏิบัติการใหม่ (การอัพเกรด ตัวตน เครือข่าย) เมื่อทีมไม่มีแบบจำลองทางความคิดที่ชัดเจน การตัดสินใจจะชะงักและการทดลองต้นแบบมักไม่เสร็จเพราะคนเชื่อมต่อเครื่องมือกับความเสี่ยงและเวิร์กโฟลว์จริงๆ ไม่ได้
เพราะภาษาธรรมดาทำให้การแลกเปลี่ยนและข้อกำหนดชัดเจนตั้งแต่แรก:
เขาเป็นผู้ที่ได้รับฟังอย่างกว้างขวางเพราะมักอธิบาย Kubernetes ในมุมมองที่สามารถปฏิบัติได้ ไม่ใช่เป็นสินทรัพย์วิเศษ การสอนของเขาเน้นสิ่งที่จะพัง สิ่งที่คุณต้องรับผิดชอบ และวิธีคิดเกี่ยวกับ control plane เครือข่าย และความปลอดภัย—หัวข้อที่ทีมมักเรียนรู้ตอนเกิดเหตุหากไม่ได้สอนล่วงหน้า
ความสับสนในช่วงแรกมักมาจากการเปลี่ยนแบบจำลองทางความคิด:
เมื่อทีมยอมรับว่า "โครงสร้างพื้นฐานมีความเป็นของไหล" คำศัพท์ก็จะจัดวางได้ง่ายขึ้น
เป็นช่องว่างระหว่างการสาธิตกับความเป็นจริงในโปรดักชัน การเดโมมักแสดง "deploy and scale" แต่การใช้งานจริงบังคับให้ต้องตัดสินใจเรื่อง:
ถ้าไม่มีบริบทเหล่านี้ Kubernetes จะดูเหมือนคำสัญญาที่ไม่มีแผนที่
มันสอนพื้นฐานโดยให้คุณประกอบคลัสเตอร์ทีละชิ้น (ใบรับรอง kubeconfigs คอมโพเนนต์ control plane เครือข่าย และการตั้งค่า worker) แม้คุณจะไม่ตั้งใจจะรันแบบนี้ในโปรดักชัน การทำแบบ "hard way" หนึ่งครั้งจะช่วยให้คุณเข้าใจสิ่งที่บริการจัดการกำลังซ่อนและจุดที่การกำหนดค่าผิดพลาดมักเกิดขึ้น
มันหมายถึงที่ทีมบอกผลลัพธ์ที่ต้องการ ไม่ใช่ขั้นตอนทีละอย่าง เช่น:
Kubernetes จะทำงานอย่างต่อเนื่องเพื่อให้ความเป็นจริงสอดคล้องกับคำอธิบายเหล่านั้น แม้พ็อดจะล้มหรือโหนดหายไป
Reconciliation คือวงจรตรวจสอบและแก้ไขอย่างต่อเนื่อง: Kubernetes เปรียบเทียบสิ่งที่คุณร้องขอกับสิ่งที่กำลังรันอยู่จริง แล้วดำเนินการเพื่อปิดช่องว่าง
เชิงปฏิบัติ: นี่คือเหตุผลที่พ็อดที่ล้มจะกลับมา หรือการตั้งค่าสเกลยังคงบังคับใช้เมื่อระบบเปลี่ยนแปลงด้านล่าง
นิยามพวกนี้ให้เป็นคำถามในชีวิตจริงที่เกี่ยวกับแรงกดดัน:
แบบนี้ทำให้องค์ประกอบการปฏิบัติการไม่ฟังดูเป็นศัพท์แสง แต่กลายเป็นการตัดสินใจวิศวกรรมธรรมดา
แยกเส้นทางการเรียนรู้เป็นสองสายชัดเจน:
จากนั้นวัดผลการเรียนรู้โดยผลลัพธ์ (การไตร่ตรองเหตุการณ์เร็วขึ้น คำถามซ้ำๆ ลดลง) ไม่ใช่แค่การเข้าร่วมการอบรม
ใช้ตัวอย่างที่จับต้องได้มากกว่าการอธิบายเชิงผลิตภัณฑ์ เริ่มจากระบบเล็กที่สุดที่ใช้งานได้ แล้วเพิ่มความซับซ้อนเฉพาะเมื่อจำเป็น ให้ผู้คนเชื่อมโยงสาเหตุและผลลัพธ์ แทนที่จะท่อง YAML
ตัวอย่างหนึ่ง: แพลตฟอร์มอย่าง Koder.ai ช่วยสร้างแอปเว็บ ทำ backend และโมเดลข้อมูลจากสเปคที่ขับเคลื่อนด้วยแชท ทำให้คุณวนจากไอเดียเป็นเซอร์วิสที่รันได้เร็วขึ้น เพื่อให้การฝึกสอนเน้นที่แบบจำลองทางปฏิบัติการ (desired state, rollouts, observability และการเปลี่ยนแปลงที่ปลอดภัย)