03 พ.ย. 2568·3 นาที
Leslie Lamport และระบบกระจาย: เวลา ลำดับ ความถูกต้อง
เรียนรู้แนวคิดสำคัญของ Lamport ในระบบกระจาย—นาฬิกาเชิงตรรกะ การจัดลำดับ ฉันทามติ และความถูกต้อง—และเหตุใดแนวคิดเหล่านี้ยังชี้ทางให้โครงสร้างพื้นฐานสมัยใหม่
ทำไม Lamport ยังสำคัญกับระบบกระจายในปัจจุบัน
Leslie Lamport เป็นหนึ่งในนักวิจัยไม่กี่คนที่ผลงานเชิงทฤษฎีของเขาปรากฏทุกครั้งที่คุณส่งมอบระบบจริง ถ้าคุณเคยดูแลคลัสเตอร์ฐานข้อมูล คิวข้อความ เอนจินเวิร์กโฟลว์ หรือระบบใด ๆ ที่รีไทรคำขอและทนต่อความล้มเหลว คุณกำลังเผชิญปัญหาที่ Lamport ช่วยตั้งชื่อและแก้ไขไว้
สิ่งที่ทำให้แนวคิดของเขายืดหยุ่นคือมันไม่ผูกติดกับเทคโนโลยีเฉพาะ มันอธิบายความจริงที่ไม่สะดวกซึ่งปรากฏเมื่อเครื่องหลายเครื่องพยายามทำตัวเป็นระบบเดียว: นาฬิกาไม่ตรงกัน เครือข่ายหน่วงหรือทิ้งข้อความ และความล้มเหลวเป็นเรื่องปกติ ไม่ใช่เรื่องพิเศษ
สามประเด็นที่เราจะใช้ตลอดบทความนี้
เวลา: ในระบบกระจาย คำถามว่า “ตอนนี้กี่โมง” ไม่ใช่คำถามง่าย ๆ นาฬิกาทางกายภาพเพี้ยนได้ และลำดับเหตุการณ์ที่คุณเห็นอาจต่างจากอีกเครื่อง
การจัดลำดับ: เมื่อคุณไม่ไว้วางใจนาฬิกาเพียงหนึ่งเดียว คุณต้องหาวิธีอื่นที่จะพูดได้ว่าเหตุการณ์ใดเกิดก่อน—และเมื่อใดที่คุณต้องบังคับให้ทุกคนปฏิบัติตามลำดับเดียวกัน
ความถูกต้อง: “มันมักจะทำงาน” ไม่ใช่การออกแบบ Lamport ดันสนามให้ไปสู่คำจำกัดความที่ชัดเจน (safety vs. liveness) และสเปคที่คุณสามารถคิดวิเคราะห์ได้ ไม่ใช่แค่ทดสอบ
ควรคาดหวังอะไร (ไม่มีคณิตศาสตร์หนัก)
เราจะเน้นที่แนวคิดและสัญชาตญาณ: ปัญหา เครื่องมือขั้นต่ำที่ช่วยให้คิดชัดขึ้น และเครื่องมือเหล่านั้นหล่อหลอมการออกแบบเชิงปฏิบัติอย่างไร
แผนที่บทความนี้:
- ทำไมการไม่มีนาฬิกาเดียวทำให้ไม่มีเรื่องราวเหตุการณ์เดียว
- ว่าด้วยสาเหตุและความสัมพันธ์ “happened-before” ซึ่งนำไปสู่นาฬิกาเชิงตรรกะและ Lamport timestamps
- เมื่อ partial order ไม่พอและต้องการไทม์ไลน์เดียว
- consensus และ Paxos เกี่ยวข้องกับการตกลงลำดับอย่างไร
- ทำไม state machine replication ใช้งานได้เมื่อการจัดลำดับถูกแชร์
- พูดถึงความถูกต้องในสเปค—และเครื่องมืออย่าง TLA+ ช่วยอย่างไร
ปัญหาหลัก: ไม่มีนาฬิกาเดียว ไม่มีความเป็นจริงเดียว
ระบบถูกเรียกว่า “กระจาย” เมื่อประกอบด้วยเครื่องหลายเครื่องที่ประสานงานผ่านเครือข่ายเพื่อทำงานหนึ่งชิ้น ฟังดูง่ายจนกว่าคุณจะยอมรับสองข้อเท็จจริง: เครื่องสามารถล้มเหลวเป็นรายตัว (partial failures) และเครือข่ายสามารถหน่วง ทิ้ง ทำซ้ำ หรือลำดับข้อความผิดได้
ในโปรแกรมเดียวบนคอมพิวเตอร์หนึ่งเครื่อง คุณมักจะชี้ได้ว่า "อะไรเกิดก่อน" ในระบบกระจาย เครื่องต่าง ๆ อาจสังเกตลำดับเหตุการณ์ต่างกัน—และทั้งสองฝ่ายอาจถูกต้องตามมุมมองท้องถิ่นของตน
ทำไมคุณจึงไม่ควรไว้ใจนาฬิกาแบบรวมศูนย์
มันน่าดึงดูดที่จะแก้ปัญหาการประสานงานด้วยการประทับเวลาทุกอย่าง แต่ไม่มีนาฬิกาเดียวที่คุณวางใจได้ข้ามเครื่อง:
- นาฬิกาในฮาร์ดแวร์ของแต่ละเซิร์ฟเวอร์เพี้ยนในอัตราที่ต่างกัน
- การซิงค์นาฬิกา (เช่น NTP) เป็นเพียงความพยายามที่ดีที่สุด ไม่ใช่ข้อรับประกัน
- การทำงานแบบ virtualization, ภาระ CPU หรือการหยุดชั่วคราวอาจทำให้เวลาเด้งหรือหยุดชะงักได้
ดังนั้น “เหตุการณ์ A เกิดที่ 10:01:05.123” บนโฮสต์หนึ่งจึงเปรียบเทียบกับ “10:01:05.120” บนโฮสต์อื่นอย่างเชื่อถือไม่ได้
การหน่วงทำให้ความเป็นจริงสับสนได้อย่างไร
การหน่วงของเครือข่ายสามารถพลิกสิ่งที่คุณคิดว่าเห็นได้ เขียนคำสั่งอาจถูกส่งก่อนแต่มาถึงทีหลัง รีไทรอาจมาหลังคำขอเดิม ศูนย์ข้อมูลสองแห่งอาจประมวลผลคำขอ “เดียวกัน” ในลำดับตรงกันข้าม
นี่ทำให้การดีบักสับสนเป็นพิเศษ: log จากเครื่องต่าง ๆ อาจไม่ตรงกัน และการ “เรียงตาม timestamp” อาจสร้างเรื่องราวที่ไม่เคยเกิดขึ้นจริง
ผลลัพธ์เชิงปฏิบัติ
เมื่อคุณสมมติไทม์ไลน์เดียวที่ไม่มีอยู่จริง คุณจะเจอล้มเหลวที่จับต้องได้:
- ประมวลผลซ้ำสองครั้ง (การคิดเงินซ้ำหลังการรีไทร)
- ความไม่สอดคล้องกัน (ผู้ใช้สองคนอ้างว่าได้ไอเท็มชิ้นสุดท้ายสำเร็จทั้งคู่)
- ข้อมูลเหมือนหายไป (อัปเดตที่มาถึงช้ากว่าทับอัปเดตที่ใหม่กว่า)
ข้อสังเกตสำคัญของ Lamport เริ่มจากตรงนี้: ถ้าคุณแชร์เวลาไม่ได้ คุณต้องคิดเรื่อง ลำดับ ในแบบที่ต่างไป
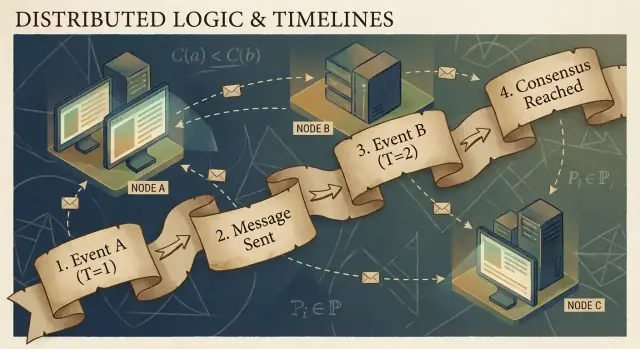
สาเหตุและความสัมพันธ์ happened-before
โปรแกรมกระจายประกอบด้วย เหตุการณ์: สิ่งที่เกิดขึ้นที่โหนดหนึ่ง ๆ (process, server, หรือ thread) เช่น “ได้รับคำขอ”, “เขียนแถว”, หรือ “ส่งข้อความ” ข้อความ เป็นตัวเชื่อมระหว่างโหนด: เหตุการณ์หนึ่งคือการ ส่ง อีกเหตุการณ์คือการ รับ
ข้อสังเกตสำคัญของ Lamport คือ ในระบบที่ไม่มีนาฬิการ่วม สิ่งที่เชื่อถือได้มากที่สุดที่คุณติดตามได้คือ สาเหตุเชิงเหตุผล (causality)—เหตุการณ์ใดอาจมีอิทธิพลต่อเหตุการณ์อื่น
ความสัมพันธ์ happened-before (→)
Lamport นิยามกฎง่าย ๆ เรียกว่า happened-before เขียนเป็น A → B (เหตุการณ์ A เกิดก่อน B):
- ลำดับภายในกระบวนการเดียวกัน: ถ้า A และ B เกิดบนเครื่อง/กระบวนการเดียวกัน และ A ถูกสังเกตว่าเกิดก่อนในกระบวนการนั้น ก็ให้ A → B
- ลำดับข้อความ: ถ้า A คือ “ส่งข้อความ m” และ B คือ “รับข้อความ m” ก็ให้ A → B
- สมบัติถ่ายทอด: ถ้า A → B และ B → C ก็ให้ A → C
ความสัมพันธ์นี้ให้คุณ partial order: มันบอกว่าคู่ของเหตุการณ์บางคู่มีลำดับแน่นอน แต่ไม่ใช่ทุกคู่
เรื่องเล่าจริง: ผู้ใช้ → คำขอ → DB → แคช
ผู้ใช้คลิก “ซื้อ” คลิกนั้นกระตุ้นคำขอไปยัง API server (เหตุการณ์ A) เซิร์ฟเวอร์เขียนแถวคำสั่งในฐานข้อมูล (เหตุการณ์ B) หลังการเขียนเสร็จ เซิร์ฟเวอร์เผยแพร่ข้อความ “order created” (เหตุการณ์ C) และบริการแคชได้รับแล้วอัปเดตแคช (เหตุการณ์ D)
ที่นี่ A → B → C → D แม้ว่าเวลาผนังจะเพี้ยน แต่โครงสร้างข้อความและโปรแกรมสร้างลิงก์เชิงสาเหตุจริง
“พร้อมกัน” หมายความว่าอะไรจริง ๆ
สองเหตุการณ์เป็น concurrent เมื่อไม่มีเหตุการณ์ใดเป็นสาเหตุของอีกเหตุการณ์: ไม่ (A → B) และไม่ (B → A). ความพร้อมกันไม่ได้หมายถึง “เกิดพร้อมกันในเวลาเดียวกัน” แต่มันหมายถึง “ไม่มีเส้นทางสาเหตุเชื่อมต่อกัน” นั่นเป็นเหตุผลที่บริการสองตัวอาจอ้างว่าทำก่อนและทั้งคู่ถูกต้อง เว้นแต่คุณจะเพิ่มกฎการจัดลำดับ
นาฬิกาเชิงตรรกะ: Lamport Timestamps แบบเข้าใจง่าย
ถ้าคุณเคยพยายามประกอบว่า "อะไรเกิดก่อน" ข้ามเครื่องหลายเครื่อง คุณจะเจอปัญหาพื้นฐาน: คอมพิวเตอร์ไม่ได้แชร์นาฬิกาที่ซิงค์สมบูรณ์ Lamport แนะนำทางแก้คือหยุดไล่ตามเวลาเชิงกายภาพที่สมบูรณ์แบบและติดตาม ลำดับ แทน
แนวคิด: ตัวนับแนบมากับแต่ละเหตุการณ์
Lamport timestamp คือหมายเลขที่คุณแนบไว้กับทุกเหตุการณ์ที่มีความหมายในกระบวนการหนึ่ง ๆ (instance ของบริการ โหนด thread—แล้วแต่คุณจะเลือก) คิดว่ามันเป็น “ตัวนับเหตุการณ์” ที่ให้วิธีที่สม่ำเสมอในการบอกว่า "เหตุการณ์นี้เกิดก่อนอีกเหตุการณ์นั้น" แม้ว่านาฬิกาผนังจะไม่น่าเชื่อถือ
สองกฎ (และมันง่ายจริง ๆ)
-
เพิ่มค่าท้องถิ่น: ก่อนที่คุณจะบันทึกเหตุการณ์ (เช่น “เขียน DB”, “ส่งคำขอ”, “เพิ่มเข้า log”) ให้เพิ่มตัวนับท้องถิ่นของคุณ
-
เมื่อรับ ให้เอา max + 1: เมื่อคุณรับข้อความที่รวม timestamp ของผู้ส่ง ให้ตั้งตัวนับของคุณเป็น:
max(local_counter, received_counter) + 1
แล้วประทับเหตุการณ์รับด้วยค่านั้น
กฎเหล่านี้ทำให้ timestamp เคารพสาเหตุ: ถ้าเหตุการณ์ A อาจมีอิทธิพลต่อ B (เพราะข้อมูลไหลผ่านข้อความ) ค่า timestamp ของ A จะน้อยกว่า B
Lamport timestamps บอกอะไรได้และไม่ได้บอกอะไร
มันบอกคุณเกี่ยวกับ การจัดลำดับเชิงสาเหตุ:
- ถ้า
TS(A) < TS(B)A อาจจะ เกิดก่อน B - ถ้า A เป็นสาเหตุของ B (โดยตรงหรือโดยอ้อม) ก็ แน่นอนว่า
TS(A) < TS(B)
มันบอกคุณไม่ได้เกี่ยวกับ เวลาเชิงกายภาพ:
- timestamp ที่ต่ำกว่าไม่ได้แปลว่า "เกิดก่อนเป็นวินาที"
- เหตุการณ์สองเหตุการณ์อาจ concurrent และยังได้ timestamp ต่างกันตามรูปแบบการส่งข้อความ
ดังนั้น Lamport timestamps ดีสำหรับการจัดลำดับ ไม่ใช่สำหรับการวัดความหน่วงหรือตอบว่า "เวลาเท่าไร"
ตัวอย่างเชิงปฏิบัติ: การจัดลำดับ log ข้ามบริการ
สมมติ Service A เรียก Service B และทั้งคู่เขียน audit log คุณต้องการมุมมอง log รวมที่รักษาสาเหตุและผล
- Service A เพิ่มตัวนับ บันทึก “เริ่มชำระเงิน” ส่งคำขอไป B พร้อม timestamp 42
- Service B รับคำขอที่มี 42 ตั้งตัวนับเป็น
max(local, 42) + 1สมมติเป็น 43 แล้วบันทึก “ตรวจสอบบัตรเรียบร้อย” - B ตอบกลับด้วย 44; A รับ อัปเดตเป็น 45 แล้วบันทึก “ชำระเงินเสร็จ”
เมื่อรวม log จากทั้งสองบริการ การเรียงตาม (lamport_timestamp, service_id) ให้ไทม์ไลน์ที่เสถียรและอธิบายได้ ตรงกับห่วงโซ่อิทธิพลจริง ๆ แม้นาฬิกาผนังจะเพี้ยนหรือเครือข่ายหน่วง
จาก Partial Order ไปสู่ Total Order: เมื่อคุณต้องการไทม์ไลน์เดียว
สาเหตุให้ partial order: มันให้ partial order: เหตุการณ์บางอย่างชัดเจนว่า "ก่อน" เหตุการณ์อื่น (เพราะข้อความหรือการขึ้นต่อกัน) แต่หลายเหตุการณ์ก็ concurrent ตามธรรมชาติ นั่นไม่ใช่ข้อบกพร่อง—มันคือรูปแบบธรรมชาติของความเป็นจริงในระบบกระจาย
Partial order: พอสำหรับคำถามหลายอย่าง
ถ้าคุณกำลังดีบักว่า "อะไรอาจมีอิทธิพลต่อสิ่งนี้" หรือบังคับกฎเช่น "การตอบต้องตามหลังคำขอ" partial order ก็เพียงพอแล้ว คุณแค่ต้องเคารพขอบ happened-before; เรื่องอื่น ๆ สามารถถือว่าเป็นอิสระได้
Total order: จำเป็นเมื่อระบบต้องเลือกเรื่องเดียว
ระบบบางอย่างอยู่ไม่ได้หากปล่อยให้ "ลำดับไหนก็ได้" พวกมันต้องการ ลำดับเดียว ของการดำเนินการ โดยเฉพาะสำหรับ:
- การเขียนไปยังอ็อบเจกต์ที่แชร์ (“ตั้งยอด”, “อัปเดตโปรไฟล์”, “ต่อท้ายลง log”)
- คำสั่งที่ต้องถูกประยุกต์ให้เหมือนกันทุกที่ (state machine replication)
- การแก้ปัญหาความขัดแย้งที่ “last write wins” ต้องมีความหมายเดียวกันบนทุกโหนด
ถ้าไม่มี total order รีพลิกาทั้งสองอาจทั้งคู่ถูกต้องท้องถิ่นแต่เกิดความคลาดเคลื่อนโดยรวม: หนึ่งทำ A แล้ว B อีกอันทำ B แล้ว A และได้ผลลัพธ์ต่างกัน
ทำอย่างไรถึงจะได้ไทม์ไลน์เดียว?
คุณต้องแนะนำกลไกที่ สร้าง ลำดับ:
- sequencer/leader ที่กำหนดตำแหน่งเพิ่มขึ้นเรื่อย ๆ ให้คำสั่งแต่ละคำสั่ง
- หรือ consensus (เช่น วิธีแบบ Paxos) เพื่อให้คลัสเตอร์ตกลงกันว่าเป็น entry ถัดไปของ log แม้ในสภาวะหน่วงและล้มเหลว
การแลกเปลี่ยนที่หลีกเลี่ยงไม่ได้
total order มีพลัง แต่ต้องจ่ายค่าบางอย่าง:
- ความหน่วง: คุณอาจต้องรอการประสานก่อน commit
- อัตราการประมวลผล: log ที่มีลำดับเดียวสามารถเป็นคอขวดได้
- ความพร้อมใช้งานเมื่อเกิดความล้มเหลว: หากคุณเข้าถึงโหนดที่เพียงพอเพื่อให้ตกลงกันไม่ได้ ความก้าวหน้าจะหยุดเพื่อรักษาความถูกต้อง
การเลือกการออกแบบสรุปได้ง่าย: เมื่อความถูกต้องต้องการเรื่องราวร่วม คุณต้องจ่ายค่า coordination เพื่อให้ได้มัน
Consensus: ตกลงในเงื่อนไขของความหน่วงและความล้มเหลว
รักษาการเป็นเจ้าของเต็มรูปแบบ
ส่งซอร์สโค้ดที่สร้างให้กับ repository ของคุณเมื่อการออกแบบลงตัวแล้ว
Consensus คือปัญหาที่ทำให้เครื่องหลายเครื่องตกลงกันในคำตัดสินเดียว—ค่าเดียวที่จะ commit ผู้นำคนเดียวที่ต้องตาม การกำหนดค่าหนึ่งชุดที่จะเปิดใช้—แม้ว่าแต่ละเครื่องจะเห็นเหตุการณ์ท้องถิ่นของตัวเองและข้อความที่มาถึงเท่านั้น
ฟังดูง่ายจนกว่าคุณจะจำได้ว่าสิ่งที่ระบบกระจายทำได้คืออะไร: ข้อความสามารถหน่วง ทำซ้ำ ลำดับผิด หรือล้มเหลวได้ เครื่องสามารถ crash แล้วรีสตาร์ท และคุณไม่ค่อยมีสัญญาณชัดเจนว่า “โหนดนี้ตายแน่นอน” Consensus เกี่ยวกับการทำให้การตกลงกันปลอดภัยภายใต้เงื่อนไขเหล่านี้
ทำไมการตกลงจึงยาก
ถ้าโหนดสองฝ่ายชั่วคราวติดต่อไม่ได้ (network partition) แต่ละฝั่งอาจพยายาม “เดินหน้าต่อ” ด้วยตัวเอง ถ้าทั้งสองตัดสินค่าต่างกัน คุณอาจได้พฤติกรรม split-brain: สองผู้นำ สองการกำหนดค่าต่างกัน หรือสองประวัติแข่งขันกัน
แม้ไม่เกิด partition ความหน่วงเองก็ทำให้เกิดปัญหาได้ พอเวลาที่โหนดได้ยินข้อเสนอ ข้อมูลอาจเปลี่ยนไปแล้ว โดยไม่มีนาฬิการ่วม คุณบอกไม่ได้ว่า “ข้อเสนอ A เกิดก่อนข้อเสนอ B” เพียงเพราะ A มี timestamp ก่อน—เวลาเชิงกายภาพไม่ใช่อำนาจอธิปไตยที่เชื่อถือได้ที่นี่
คุณเจอ consensus ที่ไหนในระบบจริง
คุณอาจไม่ได้เรียกมันว่า “consensus” ในชีวิตประจำวัน แต่คุณจะเจอในการทำงานโครงสร้างพื้นฐานทั่วไป:
- การเลือกผู้นำ (ใครเป็นหัวหน้าตอนนี้)
- log ที่ replicated (entry ถัดไปของประวัติร่วมคืออะไร)
- การเปลี่ยนการกำหนดค่า (ชุดโหนดใดที่มีสิทธิ์โหวต/commit)
ในแต่ละกรณี ระบบต้องการผลลัพธ์เดียวที่ทุกคนมาบรรจบกัน หรือตั้งกฎที่ป้องกันไม่ให้ผลลัพธ์ขัดแย้งถูกมองว่ายังคงใช้งานได้
Paxos ในฐานะคำตอบของ Lamport
Paxos ของ Lamport เป็นโซลูชันพื้นฐานสำหรับปัญหา “การตกลงอย่างปลอดภัย” แนวคิดสำคัญไม่ใช่ timeout วิเศษหรือผู้นำสมบูรณ์แบบ แต่มันคือชุดกฎที่รับประกันว่า จะมีเพียงค่าเดียวเท่านั้นที่สามารถถูกเลือกได้ แม้เมื่อข้อความล่าช้าและโหนดล้มเหลว
Paxos แยก safety (“ไม่เคยเลือกสองค่าต่างกัน”) ออกจาก progress (“ในที่สุดก็เลือกค่าใดค่าหนึ่งได้”) ทำให้มันเป็นแบบแผนที่ใช้ได้จริง: คุณสามารถปรับแต่งเพื่อประสิทธิภาพจริงในโลกจริงพร้อมรักษาคำรับประกันพื้นฐาน
Paxos แบบไม่ปวดหัว: สัญชาตญาณด้านความปลอดภัยหลัก
Paxos มีชื่อเสียงว่าอ่านยาก แต่สาเหตุส่วนหนึ่งมาจาก “Paxos” ไม่ใช่อัลกอริธึมแบบสั้น ๆ มันเป็นตระกูลของรูปแบบที่เกี่ยวข้องกันเพื่อให้กลุ่มตกลง แม้เมื่อข้อความล่าช้า ทำซ้ำ หรือเครื่องล้มเหลวชั่วคราว
ตัวละคร: proposers, acceptors, และ quorums
โมเดลคิดช่วยคือแยกคนที่เสนอออกจากคนที่ตรวจสอบ
- Proposers พยายามให้ค่าหนึ่งถูกเลือก (เช่น “entry ถัดไปของ log คือ X”)
- Acceptors โหวตต่อข้อเสนอ
- Quorum คือ “จำนวน acceptor ที่เพียงพอ” เพื่อก้าวหน้า—โดยทั่วไปคือเสียงข้างมาก
แนวคิดโครงสร้างที่สำคัญ: กลุ่มเสียงข้างมากสองกลุ่มทับซ้อนกันเสมอ การทับซ้อนนั่นแหละคือที่ที่ความปลอดภัยอยูj
เป้าหมายด้านความปลอดภัย: ห้ามตัดสินสองค่าแตกต่างกัน
ความปลอดภัยของ Paxos บอกง่าย ๆ: เมื่อตัดสินค่าแล้ว ระบบต้องไม่ตัดสินค่าต่างออกไป—ไม่มีการตัดสินสองค่าและเกิด split-brain
สัญชาตญาณที่สำคัญคือข้อเสนอมี หมายเลข (คิดว่าเป็น ID บัลลอต) Acceptors สัญญาว่าจะเพิกเฉยต่อข้อเสนอหมายเลขเก่าหลังจากที่เห็นข้อเสนอหมายเลขใหม่กว่า และเมื่อ proposer ลองด้วยหมายเลขใหม่ มันต้องถาม quorum ก่อนว่าเคยยอมรับอะไรไปแล้ว
เพราะ quorum ทับซ้อนกัน proposer ใหม่จะได้ยินจาก acceptor อย่างน้อยหนึ่งตัวที่ "จำ" ค่าที่เพิ่งถูกยอมรับก่อนไว้ กฎคือ: ถ้าใครใน quorum ยอมรับค่าใดไว้แล้ว คุณต้องเสนอค่านั้น (หรือค่าที่ใหม่ที่สุดในหมู่พวกเขา) ข้อจำกัดนี้ป้องกันไม่ให้สองค่าต่างกันถูกเลือก
ด้าน liveness แบบภาพรวม
liveness หมายถึงระบบในที่สุดก็ตัดสิน บางอย่าง ได้ภายใต้เงื่อนไขสมเหตุสมผล (เช่น ผู้นำคงที่ปรากฏ และเครือข่ายในที่สุดก็นำส่งข้อความ) Paxos ไม่สัญญาความเร็วในช่วงวุ่นวาย แต่มันสัญญาความถูกต้อง และความก้าวหน้าจะเกิดขึ้นเมื่อสถานการณ์นิ่งลง
State Machine Replication: ความถูกต้องผ่านการจัดลำดับร่วม
สร้างโปรโตไทป์ replicated log
โปรโตไทป์ API ของ replicated log พร้อม UI React และ backend Go + PostgreSQL
State machine replication (SMR) เป็นรูปแบบงานหนักเบื้องหลังระบบ "ความพร้อมใช้งานสูง" หลายระบบ: แทนที่จะให้เซิร์ฟเวอร์เดียวตัดสินใจ คุณรันรีพลิกาหลายตัวที่ประมวลผลลำดับคำสั่งเดียวกัน
แนวคิด replicated log
ศูนย์กลางคือ replicated log: รายการคำสั่งที่มีลำดับ เช่น “put key=K value=V” หรือ “โอน $10 จาก A ไป B” ลูกค้าจะไม่ส่งคำสั่งไปยังทุกรีพลิกาแล้วหวังดีที่สุด แต่ส่งคำสั่งไปยังกลุ่ม และระบบตกลง ลำดับเดียว ของคำสั่งเหล่านั้น จากนั้นรีพลิกาทุกตัวจะนำไปประยุกต์ใช้ท้องถิ่น
ทำไมการจัดลำดับถึงให้ความถูกต้อง
ถ้าทุกรีพลิกาเริ่มจากสถานะเริ่มต้นเดียวกันและประมวลผล คำสั่งชุดเดียวในลำดับเดียวกัน พวกมันจะจบใน สถานะเดียวกัน นั่นคือสัญชาตญาณด้านความปลอดภัยหลัก: คุณไม่ได้พยายามทำให้หลายเครื่อง "ซิงค์" โดยเวลา แต่คุณทำให้พวกมันเหมือนกันด้วยการกำหนดลำดับและพฤติกรรมกำหนดผลลัพธ์แน่นอน
นั่นคือเหตุผลที่ consensus (เช่น Paxos/Raft) มักจับคู่กับ SMR: consensus ตัดสิน entry ถัดไปของ log และ SMR แปลงการตัดสินนั้นเป็นสถานะที่สอดคล้องกันข้ามรีพลิกา
เห็นได้ในระบบจริง
- บริการประสานงาน (เช่น สำหรับการกำหนดค่าและการเลือกผู้นำ)
- ฐานข้อมูลที่มี write-ahead logs ที่ replicated
- ระบบข้อความที่ต้องการการจัดลำดับพาร์ติชันอย่างเข้มงวด
ข้อกังวลเชิงปฏิบัติที่วิศวกรต้องไม่มองข้าม
log โตไปเรื่อย ๆ ถ้าไม่จัดการ:
- Snapshots: จับสถานะปัจจุบันเป็นระยะ ๆ เพื่อให้โหนดใหม่ตามทันโดยไม่ต้องเล่นซ้ำประวัติทั้งหมด
- Log compaction: ทิ้ง entry เก่าอย่างปลอดภัยเมื่อถูกสะท้อนใน snapshot แล้วและไม่จำเป็นอีกต่อไป
- การเปลี่ยนสมาชิก: การเพิ่ม/เอารีพลิกาออกต้องถูกจัดลำดับด้วย มิฉะนั้นโหนดต่างกันอาจไม่เห็นด้วยว่าใคร "อยู่ในกลุ่ม" นำไปสู่ split-brain
SMR ไม่ใช่เวทมนตร์ มันเป็นวิธีวินัยที่เปลี่ยน "การตกลงเรื่องลำดับ" ให้เป็น "การตกลงเรื่องสถานะ"
ความถูกต้อง: Safety, Liveness และการเขียนสเปคให้ชัด
ระบบกระจายล้มเหลวในรูปแบบแปลก ๆ: ข้อความมาถึงช้า โหนดรีสตาร์ท นาฬิกาไม่ตรง และเครือข่ายแยกตัวกัน “ความถูกต้อง” ไม่ใช่ความรู้สึก—มันคือชุดสัญญาที่คุณต้องบอกออกมาอย่างชัดเจนแล้วตรวจสอบกับทุกสถานการณ์ รวมถึงความล้มเหลว
Safety vs. liveness (พร้อมตัวอย่างชัดเจน)
Safety หมายถึง “ไม่มีสิ่งไม่ดีเกิดขึ้นเลย” ตัวอย่าง: ใน key-value store ที่ replicated ห้าม commit ค่าต่างกันสองค่าใน index เดียวกัน อีกตัวอย่าง: บริการล็อกต้องไม่ให้ล็อกเดียวกันกับลูกค้าสองคนพร้อมกัน
Liveness หมายถึง “สิ่งที่ดีจะเกิดขึ้นในที่สุด” ตัวอย่าง: ถ้าเสียงข้างมากของรีพลิกาใช้งานได้และเครือข่ายในที่สุดส่งข้อความ คำขอเขียนจะเสร็จสิ้นในที่สุด คำขอขอล็อกจะได้คำตอบในที่สุด (ไม่รอเป็นนิรันดร์)
Safety เกี่ยวกับการป้องกันความขัดแย้ง; liveness เกี่ยวกับการหลีกเลี่ยงการหยุดนิ่งถาวร
Invariants: ข้อที่ไม่ต่อรอง
Invariant คือเงื่อนไขที่ต้องเป็นจริงเสมอในทุกสถานะที่เข้าถึงได้ เช่น:
- “แต่ละ index ของ log มีค่า commit ได้ไม่เกินหนึ่งค่า”
- “หมายเลขเทอมของผู้นำไม่เคยลดลง”
ถ้า invariant ถูกละเมิดในระหว่าง crash timeout retry หรือ partition แปลว่ามันไม่ได้ถูกบังคับจริง
ความหมายของ “การพิสูจน์” ที่นี่
การพิสูจน์คือการให้เหตุผลครอบคลุม ทุกการดำเนินการที่เป็นไปได้ ไม่ใช่แค่เส้นทางปกติ คุณต้องพิจารณาทุกกรณี: ข้อความสูญหาย ทำซ้ำ ลำดับผิด; โหนด crash แล้วรีสตาร์ท; ผู้นำแข่งขัน; ลูกค้ารีไทร
สเปคช่วยป้องกันพฤติกรรมที่คาดไม่ถึง
สเปคที่ชัดเจนกำหนดสถานะ การกระทำที่อนุญาต และคุณสมบัติที่ต้องรักษา นั่นป้องกันคำสั่งกำกับที่คลุมเครืออย่าง "ระบบควรสอดคล้อง" ทำให้เกิดความคาดหวังขัดแย้ง สเปคบังคับให้คุณระบุว่าเกิดอะไรในช่วง partition ความหมายของ "commit" คืออะไร และไคลเอนต์พึ่งพาอะไรได้—ก่อนที่การผลิตจะสอนบทเรียนยาก
จากทฤษฎีสู่ปฏิบัติ: การจำลองด้วย TLA+
หนึ่งในบทเรียนที่มีประโยชน์ที่สุดของ Lamport คือ คุณสามารถ (และมักจะควร) ออกแบบโพรโตคอลกระจายในระดับที่สูงกว่าระดับโค้ด ก่อนที่จะกังวลเรื่องเธรด RPC และลูปรีไทร คุณสามารถเขียนกฎพื้นฐานของระบบ: การกระทำที่อนุญาต สถานะที่เปลี่ยนได้ และสิ่งที่ต้องไม่เกิดขึ้น
TLA+ ใช้ทำอะไร
TLA+ เป็นภาษาสเปคและเครื่องมือตรวจสอบแบบ model-checking สำหรับบรรยายระบบขนานและกระจาย คุณเขียนแบบจำลองเรียบง่ายที่เหมือนคณิตศาสตร์ของระบบ—สถานะและการเปลี่ยนผ่าน—พร้อมคุณสมบัติที่คุณสนใจ (เช่น “มีผู้นำสูงสุดเพียงหนึ่งคน” หรือ “entry ที่ commit แล้วจะไม่หายไป”)
แล้ว model checker จะสำรวจการสลับลำดับ การหน่วงข้อความ และความล้มเหลวเพื่อค้นหา counterexample: ลำดับขั้นตอนที่เป็นรูปธรรมซึ่งทำให้คุณสมบัติพัง แทนที่จะถกเถียงเรื่องมุมขอบในการประชุม คุณจะได้ข้อโต้แย้งที่ปฏิบัติได้
บั๊กที่แบบจำลองจับได้
ลองพิจารณา "ขั้นตอน commit" ใน replicated log ในโค้ด มันง่ายที่จะหลุดให้สองโหนดมาร์ก entry ต่างกันว่า commit ที่ index เดียวกันภายใต้จังหวะที่หายาก
แบบจำลอง TLA+ สามารถเปิดเผยร่องรอยแบบนี้:
- Node A commit entry X ที่ index 10 หลังได้ quorum
- Node B (ข้อมูลเก่า) ก็รวม quorum และ commit entry Y ที่ index 10 ด้วย
นั่นคือการ commit ซ้ำ—การละเมิดความปลอดภัยที่อาจเกิดขึ้นเดือนละครั้งใน production แต่จะปรากฏเร็วภายใต้การค้นหาอย่างครบถ้วน แบบจำลองที่คล้ายกันมักจับการอัปเดตที่หาย การประยุกต์ซ้ำสองครั้ง หรือสถานการณ์ “ack แต่ไม่ทนทาน” ได้
เมื่อไหร่ที่ควรทำแบบจำลอง
TLA+ มีค่ายิ่งสำหรับตรรกะการประสานที่สำคัญ: การเลือกผู้นำ การเปลี่ยนสมาชิก โฟลว์แบบคล้าย consensus และโพรโตคอลที่การจัดลำดับและการจัดการความล้มเหลวมีปฏิสัมพันธ์กัน ถ้าบั๊กจะทำให้ข้อมูลเสียหายหรือจำเป็นต้องกู้คืนด้วยมือ แบบจำลองเล็ก ๆ มักถูกกว่าการดีบักทีหลัง
ถ้าคุณสร้างเครื่องมือภายในที่พึ่งพาแนวคิดเหล่านี้ เวิร์กโฟลว์ปฏิบัติคือเขียนสเปคสั้น ๆ (แม้ไม่เป็นทางการ) แล้ว implement ระบบและสร้างเทสต์จาก invariant ของสเปค แพลตฟอร์มอย่าง Koder.ai สามารถช่วยเร่งวงจร build-test: คุณอธิบายพฤติกรรมการจัดลำดับ/consensus ที่ต้องการเป็นภาษาธรรมดา สร้างสเกฟโฟลดสำหรับบริการ (frontend React, backend Go + PostgreSQL, หรือไคลเอนต์ Flutter) และเก็บเงื่อนไข "สิ่งที่ห้ามเกิด" ไว้ในขณะที่ปล่อยผลิตภัณฑ์
ข้อเสนอเชิงปฏิบัติสำหรับการสร้างและการปฏิบัติงานระบบที่เชื่อถือได้
สร้างเดโมการจัดลำดับ
เปลี่ยนแนวคิดการจัดลำดับของคุณให้เป็นบริการ Go ที่ทำงานได้และปรับปรุงจากการแชทอย่างเรียบง่าย
ของขวัญชิ้นใหญ่ของ Lamport สำหรับผู้ปฏิบัติคือกรอบความคิด: ถือว่าการจัดลำดับและเวลาเป็นข้อมูลที่คุณต้องสร้างแบบจำลอง ไม่ใช่สมมติฐานที่สืบทอดมาจากนาฬิกาผนัง กรอบความคิดนี้กลายเป็นชุดนิสัยที่นำไปใช้ได้ในงานประจำ
เปลี่ยนทฤษฎีให้เป็นการปฏิบัติทางวิศวกรรม
ถ้าข้อความอาจถูกหน่วง ทำซ้ำ หรือลำดับผิด ให้ออกแบบการโต้ตอบทุกอย่างให้ปลอดภัยภายใต้เงื่อนไขนั้น ๆ
- ทำให้เป็น idempotent โดยดีฟอลต์: ให้การทำซ้ำไม่มีอันตราย ใช้ idempotency key สำหรับการชำระเงิน การจัดสรร หรือการเขียนใด ๆ ที่อาจรีไทร
- รีไทรพร้อม deduplication: รีไทรจำเป็น แต่ถ้าไม่มี dedup จะเกิดการเขียนซ้ำ เก็บ ID คำขอและมาร์ก "ประมวลผลแล้ว"
- การส่งอย่างน้อยหนึ่งครั้ง + ผลลัพธ์แบบ exactly-once: ยอมรับว่าเครือข่ายอาจส่งซ้ำ ให้แน่ใจว่าการเปลี่ยนแปลงสถานะของคุณไม่เกิดซ้ำ
ระวังเรื่อง timeout และนาฬิกา
Timeout เป็นนโยบาย ไม่ใช่ข้อเท็จจริง Timeout บอกว่า "ฉันไม่ได้ยินในเวลาที่กำหนด" ไม่ใช่ "อีกฝ่ายไม่ได้ทำ" นี่คือผลสรุปสองประการ:
- อย่าถือ timeout เป็นความล้มเหลวเด็ดขาด ออกแบบกลไกชดเชยและเส้นทางไกล่เกลี่ย
- หลีกเลี่ยงการใช้เวลาท้องถิ่นในการจัดลำดับเหตุการณ์ข้ามโหนด ใช้หมายเลขลำดับ ตัวนับ monotonic หรือเมตาดาต้าเชิงสาเหตุ เช่น "อัปเดตนี้แทนที่เวอร์ชัน X"
การสังเกตการณ์ที่เคารพสาเหตุ
เครื่องมือดีบักที่ดีเข้ารหัสการจัดลำดับ ไม่ใช่แค่นำเสนอ timestamp
- Trace ID ทั่วถึง: ส่งต่อ correlation/trace ID ผ่านทุกฮ็อปและทุกบรรทัด log
- เบาะแสเชิงสาเหตุใน log: บันทึก ID ข้อความ, ID คำขอพาเรนต์, และ "สิ่งที่ฉันเชื่อว่าเป็นเวอร์ชันล่าสุด" เมื่อทำการตัดสินใจ
- การเล่นซ้ำที่กำหนดได้: บันทึกอินพุต (คำสั่ง) เพื่อให้คุณสามารถเล่นซ้ำและยืนยันว่าบั๊กเป็นเรื่องจังหวะหรือเรื่องตรรกะ
คำถามออกแบบที่ควรถามก่อนปล่อยฟีเจอร์กระจาย
ก่อนเพิ่มฟีเจอร์กระจาย ให้บังคับความชัดเจนด้วยคำถามเหล่านี้:
- จะเกิดอะไรถ้าคำขอเดียวกันถูกประมวลผลสองครั้ง?
- เราต้องการการจัดลำดับแบบไหน (ถ้ามี) และมันถูกบังคับที่ไหน?
- ความล้มเหลวแบบไหน "ปลอดภัย" (ไม่ทำให้สถานะเสีย) เทียบกับแบบไหน "ดัง" (เห็นโดยผู้ใช้) เทียบกับแบบไหน "เงียบ" (ความเสียหายซ่อนเร้น)?
- เส้นทางการกู้คืนหลัง outage บางส่วนหรือ network split คืออะไร?
- เราจะเก็บ log อะไรเพื่อเรียกคืนเรื่องราว happened-before ใน production?
คำถามเหล่านี้ไม่ต้องการปริญญาเอก—แค่ระเบียบวินัยที่จะถือการจัดลำดับและความถูกต้องเป็นข้อกำหนดของผลิตภัณฑ์ชั้นหนึ่ง
สรุปและขั้นตอนถัดไปที่แนะนำ
ของขวัญถาวรของ Lamport คือวิธีคิดเมื่อระบบไม่แชร์นาฬิกาและไม่ตกลงกันว่า "อะไรเกิดขึ้น" โดยอัตโนมัติ แทนที่จะวิ่งตามเวลาที่สมบูรณ์แบบ คุณติดตาม สาเหตุ (สิ่งใดอาจมีอิทธิพลต่อสิ่งใด), แสดงมันด้วย เวลาเชิงตรรกะ (Lamport timestamps) และ—เมื่อผลิตภัณฑ์ต้องการประวัติเดียว—สร้าง การตกลง (consensus) เพื่อให้รีพลิกาทุกตัวประยุกต์ชุดการตัดสินใจเดียวกัน
เส้นทางนี้นำไปสู่แนวคิดเชิงวิศวกรรมที่ปฏิบัติได้:
กำหนดสเปคก่อน แล้วจึงสร้าง
จดกฎที่คุณต้องการ: สิ่งที่ต้องไม่เกิด (safety) และสิ่งที่ต้องเกิดในที่สุด (liveness) แล้ว implement ตามสเปค และทดสอบระบบภายใต้การหน่วง partition รีไทร ข้อความซ้ำ และรีสตาร์ทโหนด หลาย ๆ "การล่มปริศนา" จริง ๆ แล้วคือการขาดบอกว่า "คำขออาจถูกประมวลผลสองครั้ง" หรือ "ผู้นำเปลี่ยนได้ตลอดเวลา"
เรียนรู้ต่อในขั้นตอนที่เน้น
ถ้าคุณอยากลงลึกโดยไม่จมกับความเป็นทางการ:
- อ่าน Lamport “Time, Clocks, and the Ordering of Events in a Distributed System” เพื่อทำความเข้าใจ happened-before
- อ่านย่อหน้า “Paxos Made Simple” เพื่อเข้าใจสัญชาตญาณด้านความปลอดภัย: เมื่อตัดสินค่าแล้ว ความคืบหน้าในอนาคตจะไม่ขัดแย้งกับมัน
- ดูการบรรยายแนะนำ TLA+ แล้วจำลองโพรโตคอลเล็ก ๆ (บริการล็อกหรือรีจิสเตอร์สองรีพลิกา) และตรวจสอบ
ลองทำแบบฝึกหัดหนึ่งอย่างแบบลงมือ
เลือกคอมโพเนนต์ที่คุณดูแลและเขียน "สัญญาความล้มเหลว" หน้ากระดาษ: คุณสมมติอะไรเกี่ยวกับเครือข่ายและ storage, การดำเนินการใดเป็น idempotent, และการรับประกันการจัดลำดับใดที่คุณให้
ถ้าต้องการทำแบบฝึกหัดนี้ให้เป็นรูปธรรมมากขึ้น สร้างบริการ "demo การจัดลำดับ": API รับคำสั่งไปต่อท้าย log, worker พื้นหลังนำไปประยุกต์, และมุมมองผู้ดูแลแสดงเมตาดาต้าสาเหตุและการรีไทร การทำแบบนี้บน Koder.ai สามารถเป็นวิธีรวดเร็วในการวนรอบ—โดยเฉพาะถ้าคุณต้องการ scaffolding เร็ว การโฮสต์ สแนปช็อต/ย้อนกลับสำหรับการทดลอง และการส่งออกซอร์สโค้ดเมื่อพร้อม
ถ้าทำดีแนวคิดเหล่านี้จะลดการล่มเพราะพฤติกรรมหลายอย่างจะไม่เป็นนัยอีกต่อไป มันยังทำให้การตีความง่ายขึ้น: คุณหยุดถกเถียงเรื่องเวลาและเริ่มพิสูจน์ว่าการจัดลำดับ การตกลง และความถูกต้องหมายถึงอะไรสำหรับระบบของคุณ