25 ก.ค. 2568·4 นาที
วิธีที่ LLM แปลงไอเดียภาษาอังกฤษง่ายๆ ให้เป็นแอปแบบ Full-Stack
LLM แปลงไอเดียภาษาอังกฤษธรรมดาให้เป็นแอปเว็บ มือถือ และแบ็กเอนด์: ข้อกำหนด, ฟลู UI, โมเดลข้อมูล, API, การทดสอบ และการดีพลอย
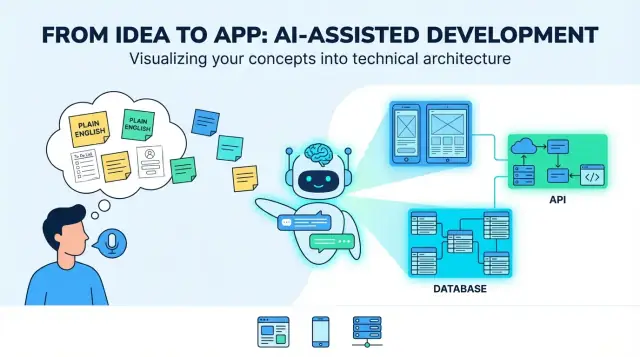
จากไอเดียสู่แอป: “การแปล” หมายความว่าอย่างไร
ไอเดียผลิตภัณฑ์แบบ "ภาษาอังกฤษธรรมดา" มักเริ่มจากความตั้งใจและความหวังผสมกัน: ใครใช้, แก้ปัญหาอะไร, และ ความสำเร็จหน้าตาเป็นอย่างไร อาจเป็นประโยคสั้นๆ ("แอปสำหรับจองคนพาเดินสุนัข"), เวิร์กโฟลว์หยาบๆ ("ลูกค้าขอ → ผู้ดูแลรับงาน → จ่ายเงิน"), และข้อจำเป็นบางอย่าง ("แจ้งเตือนผลัก, ให้คะแนน") นั่นพอให้คุยไอเดียได้—แต่ยังไม่พอให้สร้างอย่างสม่ำเสมอ
เมื่อคนพูดว่า LLM สามารถ “แปล” ไอเดียเป็นแอป ความหมายที่มีประโยชน์คือ: เปลี่ยนเป้าหมายที่คลุมเครือให้เป็นการตัดสินใจที่ชัดเจนและตรวจสอบได้ การ “แปล” ไม่ใช่แค่เขียนซ้ำ—แต่เป็นการเพิ่มโครงสร้างเพื่อตรวจทาน ท้าทาย และนำไปปฏิบัติได้
สิ่งที่ LLM สร้างได้ (อย่างรวดเร็ว)
LLM ทำได้ดีในการผลิตร่างแรกของบล็อกก่อสร้างหลัก:
- บทบาทผู้ใช้และเส้นทางหลัก (เช่น ลูกค้า, ผู้ให้บริการ, ผู้ดูแลระบบ)
- รายการฟีเจอร์และเกณฑ์ยอมรับ ("ผู้ใช้สามารถรีเซ็ตรหัสผ่านผ่านอีเมลได้")
- รายการหน้าจอและฟลู UI สำหรับเว็บและมือถือ
- สถาปัตยกรรมแนะนำ (แอปหน้าเครื่อง, บริการแบ็กเอนด์, การรวมระบบ)
- โมเดลข้อมูล (ตาราง/คอลเลกชัน, ความสัมพันธ์)
- โครงร่าง API (endpoints, รูปแบบ request/response)
ผลลัพธ์ทั่วไปมักเป็นแบบร่างสำหรับผลิตภัณฑ์แบบ full-stack: UI เว็บ (มักสำหรับผู้ดูแลหรือการใช้งานบนเดสก์ท็อป), UI มือถือ (สำหรับผู้ใช้ที่เคลื่อนที่), บริการแบ็กเอนด์ (auth, กฎธุรกิจ, การแจ้งเตือน), และที่จัดเก็บข้อมูล (ฐานข้อมูลและที่เก็บไฟล์/สื่อ)
สิ่งที่ยังต้องการการตัดสินใจจากมนุษย์
LLM ไม่สามารถเลือกการประนีประนอมของผลิตภัณฑ์ได้อย่างน่าเชื่อถือ เพราะคำตอบที่ถูกต้องขึ้นกับบริบทที่คุณอาจยังไม่ได้เขียนไว้:
- อะไรถือว่าเป็น “ความสำเร็จ” และตัวชี้วัดใดสำคัญ?
- ข้อจำกัดมีอะไรบ้าง (งบประมาณ, ระยะเวลา, การปฏิบัติตาม, เครื่องมือที่มีอยู่)?
- เคสขอบใดที่คุณ ใส่ใจ (และอันไหนเลื่อนได้)?
- เวอร์ชันที่เรียบง่ายที่สุดที่ผู้ใช้ยังรักคืออะไร?
ถือว่าโมเดลเป็นระบบที่เสนอ ตัวเลือก และ ค่าเริ่มต้น ไม่ใช่ความจริงสุดท้าย
ความเสี่ยงสำคัญที่ต้องระวัง
ความล้มเหลวที่พบได้บ่อยมีแบบแผน:
- ความกำกวม: คำว่า “เร็ว”, “ปลอดภัย”, หรือ “ง่าย” ต้องมีคำนิยาม
- ขาดเคสขอบ: ยกเลิก, รีไทร, โหมดออฟไลน์, คืนเงิน, เรคคอร์ดซ้ำ, การใช้งานไม่หวังดี
- ความมั่นใจเกินจริง: ผลลัพธ์อาจฟังดูแน่นอนแต่สมมติฐานอาจไม่แข็งแรง
เป้าหมายจริงของ “การแปล” คือทำให้สมมติฐานมองเห็นได้—เพื่อที่คุณจะได้ยืนยัน ปรับ หรือปฏิเสธก่อนที่มันจะกลายเป็นโค้ด
ขั้นตอนที่ 1: เคลียร์บรีฟผลิตภัณฑ์
ก่อนที่ LLM จะเปลี่ยน “สร้างแอปสำหรับ X” ให้เป็นหน้าจอ, API และโมเดลข้อมูล คุณต้องมีบรีฟผลิตภัณฑ์ที่เฉพาะพอให้ออกแบบได้ ขั้นตอนนี้คือการเปลี่ยนความตั้งใจที่คลุมเครือให้เป็นเป้าหมายร่วม
เริ่มจากปัญหาและวิธีวัดความสำเร็จ
เขียนปัญหาเป็น 1–2 ประโยค: ใครกำลังประสบปัญหา เรื่องอะไร และทำไมมันสำคัญ แล้วเพิ่มตัวชี้วัดความสำเร็จที่สังเกตได้
ตัวอย่าง: “ลดเวลาที่คลินิกใช้ในการนัดติดตามผล” ตัวชี้วัดอาจเป็นเวลาจัดตารางเฉลี่ย อัตราไม่มารายงาน หรือ % ของผู้ป่วยที่จองผ่านระบบบริการตนเอง
กำหนดผู้ใช้เป้าหมายและกรณีใช้งานหลัก
ระบุประเภทผู้ใช้หลัก (ไม่ใช่ทุกคนที่อาจแตะต้องระบบ) ให้แต่ละคนมีงานสำคัญที่สุดและสถานการณ์สั้นๆ
เทมเพลตที่เป็นประโยชน์: “ในฐานะ [บทบาท], ฉันต้องการ [ทำบางอย่าง] เพื่อ [ประโยชน์].” ตั้งเป้า 3–7 กรณีใช้งานหลักที่อธิบาย MVP
จับข้อจำกัดตั้งแต่ต้น (เพราะมันกำหนดทุกอย่าง)
ข้อจำกัดต่างๆ คือปัจจัยที่ทำให้ต้นแบบแตกต่างจากสินค้าที่พร้อมส่งมอบ รวมถึง:
- แพลตฟอร์ม: เว็บ, iOS, Android (และความต้องการออฟไลน์)
- ระยะเวลาและงบประมาณ: แลกเปลี่ยนอะไรได้บ้าง
- การปฏิบัติตาม/ความเป็นส่วนตัว: HIPAA, GDPR, ที่เก็บข้อมูลตามภูมิศาสตร์, บันทึกการตรวจสอบ
- การรวมระบบ: การชำระเงิน, ปฏิทิน, SSO, CRM, ผู้ให้บริการอีเมล/SMS
กำหนดคำว่า “เสร็จ”: MVP vs ภายหลัง
ระบุชัดเจนว่ามีอะไรบ้างในรีลีสแรกและอะไรเลื่อนไป กฎง่ายๆ: ฟีเจอร์ MVP ต้องรองรับกรณีใช้งานหลักแบบ end-to-end โดยไม่ต้องมีงานด้วยมือ
ถ้าต้องการ ให้จับสิ่งนี้เป็นบรีฟหน้าเดียวและเก็บไว้เป็น “แหล่งความจริง” สำหรับขั้นตอนถัดไป (ข้อกำหนด, ฟลู UI, และสถาปัตยกรรม)
ขั้นตอนที่ 2: แปลงภาษาอังกฤษธรรมดาเป็นข้อกำหนด
ไอเดียภาษาอังกฤษมักเป็นการผสมของเป้าหมาย (“ช่วยคนจองคลาส”), สมมติฐาน (“ผู้ใช้จะล็อกอิน”), และขอบเขตคลุมเครือ (“ทำให้เรียบง่าย”) LLM มีประโยชน์เพราะมันสามารถเปลี่ยนข้อมูลกระจัดกระจายให้เป็นข้อกำหนดที่คุณตรวจแก้และอนุมัติได้
เปลี่ยนข้อความเป็น user stories
เริ่มจากเขียนแต่ละประโยคเป็นเรื่องราวผู้ใช้ วิธีนี้บังคับให้ชัดเจนว่า ใคร ต้องการ อะไร และ ทำไม:
- ในฐานะผู้ใช้ใหม่, ฉันต้องการสมัครด้วยอีเมลหรือ Google เพื่อเริ่มได้เร็ว
- ในฐานะผู้ใช้กลับมา, ฉันต้องการเห็นการจองที่กำลังจะมาถึงเพื่อวางแผนสัปดาห์ของฉัน
ถ้าเรื่องราวไม่ได้ระบุประเภทผู้ใช้หรือประโยชน์ แปลว่าอาจยังคลุมเครือ
สร้างรายการฟีเจอร์และตั้งลำดับความสำคัญ
จัดกลุ่มเรื่องราวเป็นฟีเจอร์ แล้วติดป้ายว่า must-have หรือ nice-to-have ช่วยป้องกันการไหลของขอบเขตก่อนการออกแบบและวิศวกรรมจะเริ่ม
ตัวอย่าง: “แจ้งเตือน push” อาจเป็น nice-to-have ในขณะที่ “ยกเลิกการจอง” อาจเป็น must-have
เขียนเกณฑ์ยอมรับที่โมเดลตรวจสอบได้
เพิ่มกฎที่ทดสอบได้ภายใต้แต่ละเรื่องราว เกณฑ์ยอมรับที่ดีต้องชัดเจนและสังเกตได้:
- เมื่อกรอกอีเมลไม่ถูกต้อง แล้วส่งฟอร์ม ฉันเห็นข้อผิดพลาดแบบอินไลน์และไม่สร้างบัญชี
- เมื่อฉันยกเลิกภายใน 24 ชั่วโมง และยืนยันการยกเลิก ช่องของฉันจะถูกปล่อยและฉันได้รับข้อความยืนยัน
ระบุเคสขอบตั้งแต่ต้น
LLM มักเริ่มจากเส้นทางที่ราบรื่น ดังนั้นให้ร้องขอเคสขอบเช่น:
- โหมดออฟไลน์หรือเครือข่ายไม่ดี (คิวการกระทำ, พฤติกรรมรีไทร)
- ข้อมูลไม่ถูกต้อง (ฟิลด์ว่าง, ชนิดไฟล์ไม่รองรับ)
- การยกเลิกและการส่งซ้ำ (idempotency, ยืนยันการกระทำ)
ชุดข้อกำหนดนี้จะเป็นแหล่งความจริงที่คุณใช้ประเมินผลลัพธ์ถัดไป (ฟลู UI, API, และการทดสอบ)
ขั้นตอนที่ 3: ออกแบบฟลู UI สำหรับเว็บและมือถือ
ไอเดียภาษาอังกฤษจะกลายเป็นสิ่งที่สร้างได้เมื่อมันกลายเป็น การเดินทางผู้ใช้ และ หน้าจอที่เชื่อมด้วยการนำทางชัดเจน ที่ขั้นตอนนี้คุณยังไม่เลือกสี แต่กำหนดว่าผู้ใช้ทำอะไรได้ ในลำดับใด และความสำเร็จคืออะไร
เขียนแผนที่เส้นทางผู้ใช้หลัก
เริ่มจากรายการเส้นทางที่สำคัญ สำหรับสินค้าหลายตัว คุณสามารถจัดเป็น:
- การเริ่มต้นใช้งาน: สร้างบัญชี, ยืนยันอีเมล/โทรศัพท์, การตั้งค่าเริ่มต้น
- งานหลัก: งานหลักที่แอปช่วยให้ผู้ใช้ทำ (สร้าง, ค้นหา, จอง, ติดตาม, แชร์)
- การชำระเงิน: หน้าแสดงราคา, ชำระเงิน, ใบเสร็จ, การจัดการสมาชิก (ถ้าจำเป็น)
- การช่วยเหลือ: FAQ, ฟอร์มติดต่อ, รายงานปัญหา
- การตั้งค่า: โปรไฟล์, การแจ้งเตือน, การตั้งค่าความเป็นส่วนตัว, ออกจากระบบ, ลบบัญชี
โมเดลสามารถร่างฟลูเหล่านี้เป็นลำดับขั้นตอนได้ งานของคุณคือตรวจว่าสิ่งใดเป็นทางเลือก สิ่งใดจำเป็น และผู้ใช้สามารถออกแล้วกลับมาได้ที่ไหน
สร้างรายการหน้าจอ (เว็บ + มือถือ) พร้อมการนำทาง
ขอผลลัพธ์สองอย่าง: รายการหน้าจอ และ แผนผังการนำทาง
- เว็บมักใช้แถบด้านข้างหรือแถบท็อปที่มีตัวเลือกมากขึ้น
- มือถือมักใช้แท็บและสแต็กของหน้าจอ โดยมีตัวเลือกน้อยต่อมุมมอง
ผลลัพธ์ที่ดีจะตั้งชื่อหน้าจออย่างสม่ำเสมอ (เช่น “Order Details” vs “Order Detail”), กำหนดจุดเริ่มต้น และรวมสถานะหน้าเปล่า (ไม่มีผลลัพธ์, ไม่มีรายการบันทึก)
ฟอร์มและกฎการตรวจสอบ
แปลงข้อกำหนดเป็นฟิลด์ฟอร์มพร้อมกฎ: จำเป็น/ไม่จำเป็น, รูปแบบ, ขีดจำกัด, และข้อความผิดพลาดที่เป็นมิตร ตัวอย่าง: กฎรหัสผ่าน, รูปแบบที่อยู่การชำระเงิน, หรือ “วันที่ต้องเป็นอนาคต” ให้มั่นใจว่ามีการตรวจสอบทั้งแบบอินไลน์ (ขณะพิมพ์) และเมื่อส่ง
พื้นฐานการเข้าถึงที่ต้องใส่
รวมขนาดข้อความที่อ่านง่าย, ความคมชัดชัดเจน, รองรับคีย์บอร์ดเต็มรูปแบบบนเว็บ, และข้อความผิดพลาดที่อธิบายวิธีแก้ ไม่ใช่แค่ "ข้อมูลไม่ถูกต้อง" นอกจากนี้ให้แน่ใจว่าฟิลด์ฟอร์มแต่ละฟิลด์มีป้ายกำกับและลำดับโฟกัสสมเหตุผล
ขั้นตอนที่ 4: เสนอสถาปัตยกรรมแอป
“สถาปัตยกรรม” คือแผนผังของแอป: ส่วนไหนมีอยู่ แต่ละชิ้นรับผิดชอบอะไร และพวกมันคุยกันอย่างไร เมื่อ LLM เสนอสถาปัตยกรรม งานของคุณคือให้แน่ใจว่ามัน เรียบง่ายพอที่จะสร้างตอนนี้ และ ชัดพอที่จะพัฒนาต่อทีหลัง
เริ่มจากค่าเริ่มต้น: monolith หรือ modular?
สำหรับผลิตภัณฑ์ใหม่ส่วนใหญ่ แบ็กเอนด์แบบโมโนลิธ เป็นจุดเริ่มต้นที่เหมาะสม: โค้ดเบสเดียว, ดีพลอยเดียว, ฐานข้อมูลเดียว เร็วกว่าในการสร้าง ง่ายกว่าในการดีบัก และถูกกว่าในการใช้งาน
Modular monolith มักเป็นจุดลงตัว: ยังดีพลอยเป็นชิ้นเดียว แต่จัดเป็นโมดูล (Auth, Billing, Projects ฯลฯ) ด้วยขอบเขตที่ชัดเจน เลื่อนการแยกบริการจนกว่าจะมีแรงกดดันจริง เช่น ทราฟฟิกสูง ทีมที่ต้องดีพลอยแยก หรือส่วนที่ต้องสเกลต่างกัน
หาก LLM เสนอ “microservices” ทันที ขอเหตุผลสนับสนุนด้วยความต้องการที่เป็นรูปธรรม ไม่ใช่สมมติฐานในอนาคต
กำหนดคอมโพเนนต์หลัก (และทำให้มันเรียบๆ)
เค้าโครงสถาปัตยกรรมที่ดีจะระบุสิ่งจำเป็น:
- Auth & user management: สมัคร/ล็อกอิน, บทบาท, เซสชัน/โทเคน
- ชั้นกฎธุรกิจ: กฎของผลิตภัณฑ์ (ราคา, การอนุมัติ, ขีดจำกัด)
- การเข้าถึงข้อมูล: วิธีอ่าน/เขียนฐานข้อมูล
- งานแบ็กกราวด์: งานที่ทำเวลานาน (นำเข้า, สร้างรายงาน, งานตามตาราง)
- การแจ้งเตือน: อีเมล/push/in-app, เทมเพลต และการตั้งค่าการแจ้งเตือน
โมเดลควรกำหนดด้วยว่าชิ้นแต่ละชิ้นอยู่ที่ไหน (แบ็กเอนด์ vs มือถือ vs เว็บ) และอธิบายว่าคลไคลเอนต์ติดต่อกับแบ็กเอนด์อย่างไร (โดยทั่วไป REST หรือ GraphQL)
ระบุสมมติฐานเทคโนโลยีให้ชัด
สถาปัตยกรรมจะกำกวมจนกว่าจะล็อกพื้นฐาน: เฟรมเวิร์กแบ็กเอนด์, ฐานข้อมูล, โฮสติ้ง, และแนวทางมือถือ (native vs ข้ามแพลตฟอร์ม) ให้โมเดลเขียนสิ่งเหล่านี้เป็น “สมมติฐาน” เพื่อให้ทุกคนรู้ว่าสิ่งที่ออกแบบมาอิงกับอะไร
วางแผนสำหรับการสเกลโดยไม่โอเวอร์เอนจิเนียร์
แทนที่จะเขียนใหม่ใหญ่โต ให้ชอบทางเลือก “ทางหนี” เล็กๆ: แคชสำหรับการอ่านบ่อย, คิวสำหรับงานแบ็กกราวด์, และเซิร์ฟเวอร์แบบ stateless เพื่อให้เพิ่มอินสแตนซ์ได้ในอนาคต ข้อเสนอที่ดีที่สุดจะแสดงตัวเลือกเหล่านี้พร้อมกับทำให้ v1 เรียบง่าย
ขั้นตอนที่ 5: ทำโมเดลข้อมูล
สร้างจากบรีฟผลิตภัณฑ์
แปลงบรีฟภาษาอังกฤษธรรมดาของคุณเป็นโครงงานเว็บ, แบ็กเอนด์ และแอปมือถือในแชทเดียว
ไอเดียผลิตภัณฑ์เต็มไปด้วยคำนาม: “ผู้ใช้”, “โปรเจกต์”, “งาน”, “การชำระเงิน”, “ข้อความ” การทำโมเดลข้อมูลคือขั้นตอนที่ LLM เปลี่ยนคำนามเหล่านั้นให้เป็นภาพร่วมว่าระบบต้องเก็บอะไร และสิ่งต่างๆ เชื่อมโยงกันอย่างไร
แปลงคำนามเป็นเอนทิตีและความสัมพันธ์
เริ่มจากรายการเอนทิตีหลักและถามว่าอะไรเป็นของอะไร
ตัวอย่าง:
- User สร้างหลาย Project
- Project มีหลาย Task
- Task อาจมีหลาย Comment
จากนั้นกำหนดความสัมพันธ์และข้อจำกัด: งานสามารถมีอยู่โดยไม่มีโปรเจกต์ได้ไหม, คอมเมนต์แก้ไขได้ไหม, โปรเจกต์เก็บถาวรได้ไหม, และเมื่อโปรเจกต์ถูกลบงานจะเป็นอย่างไร
ร่างตาราง/คอลเลกชันและฟิลด์ที่สำคัญ
ต่อไป โมเดลจะเสนอสคีมาเบื้องต้น (SQL tables หรือ NoSQL collections) ทำให้เรียบง่ายและมุ่งที่การตัดสินใจที่มีผลต่อพฤติกรรม
ร่างทั่วไปอาจรวม:
- users: id, email, name, password_hash/identity_provider_id, created_at
- projects: id, owner_user_id, name, status, created_at
- project_members: project_id, user_id, role
- tasks: id, project_id, title, description, status, due_date, assignee_user_id
สำคัญ: จับฟิลด์สถานะ, timestamps, และข้อจำกัดที่ไม่ซ้ำตั้งแต่ต้น (เช่น email ไม่ซ้ำ) รายละเอียดเหล่านี้ขับฟิลเตอร์ UI, การแจ้งเตือน, และการรายงานต่อไป
ความเป็นเจ้าของ, สิทธิ์, และการแยก multi-tenant
แอปจริงมักต้องการกฎชัดเจนว่าใครเห็นอะไร LLM ควรทำให้ความเป็นเจ้าของชัดเจน (owner_user_id) และโมเดลการเข้าถึง (สมาชิก/บทบาท) สำหรับผลิตภัณฑ์ multi-tenant ให้เพิ่มเอนทิตี tenant/organization และผูก tenant_id กับทุกอย่างที่ต้องแยกกัน
และกำหนดด้วยว่าการบังคับสิทธิ์ทำอย่างไร: โดยบทบาท (admin/member/viewer), โดยความเป็นเจ้าของ, หรือทั้งสอง
การเก็บรักษา, การลบ, และบันทึก audit
สุดท้าย ตัดสินใจว่าสิ่งใดต้องบันทึกและสิ่งใดต้องลบ ตัวอย่าง:
- เหตุการณ์ audit: “สร้างงาน”, “เปลี่ยนสิทธิ์”, “ส่งออก”
- กฎการเก็บรักษา: ลบข้อมูลส่วนบุคคลตามคำขอ, เก็บใบแจ้งหนี้ X ปี
- ลบแบบ soft vs hard: เก็บระเบียนกู้คืนได้ หรือลบออกจริง
การเลือกระบบเหล่านี้ช่วยป้องกันปัญหาเมื่อเจอคำถามเรื่องการปฏิบัติตาม, ฝ่ายสนับสนุน, หรือการเรียกเก็บเงินในภายหลัง
ขั้นตอนที่ 6: สร้าง API แบ็กเอนด์
API แบ็กเอนด์คือที่คำสัญญาของแอปกลายเป็นการกระทำจริง: “บันทึกโปรไฟล์ของฉัน”, “แสดงคำสั่งของฉัน”, “ค้นหารายการ” ผลลัพธ์ที่ดีเริ่มจากการกระทำของผู้ใช้และเปลี่ยนเป็นชุด endpoints ชัดเจน
เริ่มจากการกระทำของผู้ใช้ → CRUD + การค้นหา
รายการสิ่งหลักที่ผู้ใช้โต้ตอบ (เช่น Projects, Tasks, Messages) สำหรับแต่ละอย่างให้กำหนดสิ่งที่ผู้ใช้ทำได้:
- Create: เพิ่มรายการใหม่
- Read: ดึงรายการหนึ่งหรือรายการทั้งหมด
- Update: เปลี่ยนฟิลด์
- Delete: ลบ/ปิดการใช้งาน
- Search/filter: ค้นหาตามคำหลัก, สถานะ, วันที่ ฯลฯ
สิ่งนี้มักแมปเป็น endpoints เช่น:
POST /api/v1/tasks(create)GET /api/v1/tasks?status=open&q=invoice(list/search)GET /api/v1/tasks/{taskId}(read)PATCH /api/v1/tasks/{taskId}(update)DELETE /api/v1/tasks/{taskId}(delete)
ตัวอย่าง request/response (ภาษาธรรมดา + JSON)
สร้างงาน: ผู้ใช้ส่ง title และ due date
POST /api/v1/tasks
{
"title": "Send invoice",
"dueDate": "2026-01-15"
}
การตอบกลับคืนเรคคอร์ดที่บันทึก (รวมฟิลด์ที่เซิร์ฟเวอร์สร้าง):
201 Created
{
"id": "tsk_123",
"title": "Send invoice",
"dueDate": "2026-01-15",
"status": "open",
"createdAt": "2025-12-26T10:00:00Z"
}
(หมายเหตุ: ไม่แปลเนื้อหาในกรอบโค้ดด้านบน)
การจัดการข้อผิดพลาดที่แอปมือถือรับได้
ให้โมเดลผลิตข้อผิดพลาดที่สม่ำเสมอ:
- 400 ข้อผิดพลาดการตรวจสอบ (พร้อมข้อความระดับฟิลด์)
- 401/403 ปัญหาการพิสูจน์ตัวตน/สิทธิ์
- 404 ไม่พบ
- 409 ความขัดแย้ง (ซ้ำ, อัปเดตล้าสมัย)
- 429 คำขอเกิน (บอกไคลเอนต์ว่า retry เมื่อไหร่)
- 500 ข้อผิดพลาดที่ไม่คาดคิด (ข้อความทั่วไป + request id)
สำหรับการ retry ให้ชอบ idempotency keys ใน POST และแนะแนวว่า “ลองอีกครั้งหลัง 5 วินาที” เป็นต้น
การจัดเวอร์ชันและความเข้ากันได้ย้อนหลัง
ไคลเอนต์มือถืออัปเดตช้า ใช้พาธฐานเวอร์ชัน (/api/v1/...) และหลีกเลี่ยงการเปลี่ยนแปลงที่ทำให้แตกหัก:
- เพิ่มฟิลด์ใหม่เป็น optional แทนการเปลี่ยน/ลบ
- เก็บฟิลด์เก่าไว้ในช่วงเวลาการเลิกใช้งาน
- อธิบายการเปลี่ยนแปลงใน changelog สั้นๆ (เช่น
GET /api/version)
ขั้นตอนที่ 7: ความปลอดภัยและความเป็นส่วนตัวเป็นค่าเริ่มต้น
จากไอเดียสู่ MVP
ร่างบทบาทผู้ใช้, เส้นทางการใช้งาน และเกณฑ์ยอมรับ แล้วสร้างเวอร์ชันแรกของแอปของคุณ
ความปลอดภัยไม่ใช่งาน "ทีหลัง" เมื่อ LLM แปลงไอเดียเป็นข้อกำหนด คุณต้องการค่าเริ่มต้นที่ปลอดภัยชัดเจน—เพื่อไม่ให้เวอร์ชันแรกถูกเปิดรับการโจมตีโดยไม่ตั้งใจ
การพิสูจน์ตัวตน: ผู้ใช้ยืนยันตัวเองอย่างไร
ขอให้โมเดลแนะนำวิธีล็อกอินหลักและสำรอง รวมทั้งกรณีเมื่อเกิดปัญหา (เข้าถึงไม่ได้, ล็อกอินที่น่าสงสัย) ตัวเลือกทั่วไปรวม:
- อีเมล + รหัสผ่าน (คุ้นเคย แต่ต้องจัดการรีเซ็ต, กฎความแข็งแรง, ความเสี่ยงจากการรั่วไหล)
- ลิงก์วิเศษ / โค้ดใช้ครั้งเดียว (ลดความเสี่ยงจากรหัสผ่าน แต่ต้องจัดส่งอีเมลได้มั่นคงและโทเคนหมดอายุสั้น)
- ล็อกอินโซเชียล (สมัครเร็ว แต่พึ่งพาบุคคลที่สามและต้องมีกฎการผูกบัญชี)
กำหนดการจัดการเซสชัน (access tokens สั้น, refresh tokens) และว่าจะรองรับการยืนยันหลายปัจจัยหรือไม่
การอนุญาต: ผู้ใช้ทำอะไรได้บ้าง
การพิสูจน์ตัวตนระบุผู้ใช้; การอนุญาตจำกัดการเข้าถึง แนะนำรูปแบบชัดเจนหนึ่งแบบ:
- บทบาท (เช่น Admin, Member, Viewer) สำหรับแอปง่ายๆ
- สิทธิ์ (fine-grained เช่น
project:edit,invoice:export) สำหรับผลิตภัณฑ์ยืดหยุ่น - การเข้าถึงระดับวัตถุ: ผู้ใช้สามารถอ่าน/เขียนรายการที่ตนเป็นเจ้าของหรือแชร์เฉพาะกับตนเท่านั้น
ผลลัพธ์ที่ดีรวมกฎตัวอย่างเช่น: “เฉพาะเจ้าของโปรเจกต์เท่านั้นที่ลบโปรเจกต์ได้; ผู้ร่วมงานแก้ไขได้; ผู้ดูได้คอมเมนต์”
การตรวจสอบความปลอดภัยที่ต้องการในแผน
ให้โมเดลระบุการป้องกันที่เป็นรูปธรรม ไม่ใช่คำสัญญาทั่วไป:
- การตรวจสอบและกำจัดอินพุต ในทุก endpoint (อย่าไว้ใจไคลเอนต์)
- การจำกัดอัตรา สำหรับล็อกอิน, คำขอ OTP/ลิงก์วิเศษ, และ endpoint ที่แพง
- การจัดการความลับ: เก็บ API keys นอกโค้ด, หมุน credentials, ห้าม log โทเคน
และขอรายการตรวจสอบภัยคุกคามพื้นฐาน: ป้องกัน CSRF/XSS, คุกกี้ปลอดภัย, อัปโหลดไฟล์ที่ปลอดภัยถ้ามี
ความเป็นส่วนตัวพื้นฐาน: เก็บเท่าที่จำเป็น อธิบายให้ชัด
ตั้งค่าเริ่มต้นให้เก็บข้อมูลน้อยที่สุด: แค่สิ่งที่ฟีเจอร์ต้องการ และเก็บในระยะเวลาสั้นที่สุด
ให้ LLM ร่างข้อความภาษาง่ายสำหรับ:
- ข้อมูลที่เก็บ (และเหตุผล)
- ระยะเวลาที่เก็บ
- วิธีที่ผู้ใช้ลบหรือส่งออกข้อมูล
ถ้าเพิ่มการวิเคราะห์ ให้บังคับ opt-out (หรือ opt-in ตามกฎหมาย) และทำเอกสารในการตั้งค่าและหน้านโยบายให้ชัด
ขั้นตอนที่ 8: กลยุทธ์การทดสอบที่โมเดลสร้างได้
LLM ที่ดีสามารถเปลี่ยนข้อกำหนดเป็นแผนการทดสอบที่ใช้ได้จริง—ถ้าคุณบังคับให้มันอิงเกณฑ์ยอมรับ ไม่ใช่คำพูดทั่วไป
แมปการทดสอบตรงไปยังเกณฑ์ยอมรับ
เริ่มโดยให้โมเดลข้อกำหนดและเกณฑ์ยอมรับ แล้วขอให้มันสร้างการทดสอบ ต่อเกณฑ์ ผลลัพธ์ที่ดีรวม:
- Unit tests สำหรับกฎธุรกิจ (เช่น การคำนวณราคา, การตรวจสอบ)
- Integration tests สำหรับพฤติกรรม API + DB (เช่น สร้างคำสั่งแล้วแถวใน DB ถูกต้อง)
- End-to-end tests สำหรับเส้นทางผู้ใช้สำคัญ (เช่น สมัคร → เริ่มต้น → ทำงานแรกให้เสร็จ)
ถ้าการทดสอบชี้กลับไปยังเกณฑ์เฉพาะไม่ได้ มันอาจเป็นเสียงรบกวน
ข้อมูลทดสอบและฟิกซ์เจอร์จากสถานการณ์จริง
LLM ยังสามารถเสนอ fixtures ที่สะท้อนการใช้จริง: ชื่อยุ่งๆ, ฟิลด์หาย, โซนเวลา, ข้อความยาว, เครือข่ายชักช้า, และเรคคอร์ดที่เกือบซ้ำ
ขอให้รวม:
- ชุดข้อมูล seed (เล็ก กลาง) ที่มีเคสขอบ
- factories/fixtures ที่ใช้ซ้ำได้สำหรับผู้ใช้, บทบาท, และเอนทิตีทั่วไป
- ชุดข้อมูล “golden path” ที่ใช้ใน E2E tests เพื่อความสม่ำเสมอ
เช็คลิสต์มือถือที่คนมักลืม
ให้โมเดลเพิ่มเช็คลิสต์เฉพาะมือถือ:
- โหมดออฟไลน์ (อ่านอย่างเดียว vs คิวการเขียน, การจัดการความขัดแย้ง)
- การเข้าออกพื้นหลัง/หน้า (กู้คืนสถานะ, คำขอที่ค้างอยู่)
- การขอสิทธิ์ (กล้อง, ตำแหน่ง, การแจ้งเตือน) และเส้นทางเมื่อถูกปฏิเสธ
ใช้ LLM สร้างการทดสอบ—และวิธีตรวจทาน
LLM ดีในการร่างโครงทดสอบเร็ว แต่คุณควรตรวจ:
- Assertions: ตรวจผลลัพธ์ ไม่ใช่รายละเอียดการดำเนินการ
- Coverage: มีเคสล้มเหลวรวมไหม (401/403, 422, timeouts)?
- ความเสี่ยงของการขึ้นๆ ลงๆ: รอเวลาที่เปลี่ยนไป, ขึ้นกับเครือข่าย, selectors ไม่เสถียร
ถือว่าโมเดลเป็นผู้เขียนเทสต์ฉับไว ไม่ใช่ผู้อนุมัติ QA สุดท้าย
ขั้นตอนที่ 9: ดีพลอย, ปล่อยรุ่น, และมอนิเตอร์
โมเดลอาจสร้างโค้ดมากมาย แต่ผู้ใช้จะได้ประโยชน์เมื่อมันถูกส่งอย่างปลอดภัยและคุณเห็นผลหลังปล่อย ขั้นตอนนี้คือการทำให้การปล่อยทำซ้ำได้: เดิมทีเดิมทุกครั้งและมีความประหลาดใจน้อยที่สุด
พื้นฐาน CI (อัตโนมัติอะไรบ้าง)
ตั้ง CI เบื้องต้นให้รันทุก pull request และเมื่อ merge ไปยัง main:
- Linting/formatting เพื่อตรวจความไม่สอดคล้องของโค้ด
- Automated tests (unit + จำนวนเล็กของ E2E “happy path”)
- ขั้นตอน build สำหรับแต่ละส่วน:
- สร้างเว็บแอป
- สร้างแอปมือถือ (Android/iOS)
- สร้าง/แพ็กแบ็กเอนด์
แม้ว่า LLM จะเขียนโค้ด CI จะบอกคุณว่าโค้ดยังทำงานหลังการเปลี่ยนแปลงหรือไม่
สภาพแวดล้อม: dev, staging, production
ใช้ 3 สภาพแวดล้อมที่มีจุดประสงค์ชัด:
- Dev: วนรอบเร็ว, ฐานข้อมูลท้องถิ่น, log debug
- Staging: การตั้งค่าใกล้เคียง production สำหรับการตรวจสอบสุดท้าย
- Production: ผู้ใช้จริง, การเข้าถึงเข้มงวด, ลดเสียง log
การตั้งค่าควรจัดการผ่าน environment variables และ secrets (ไม่ hard-code) กฎง่าย: ถ้าการเปลี่ยนค่านั้นต้องแก้โค้ด มันอาจตั้งค่าไม่ถูก
เค้าโครงการปรับใช้
สำหรับแอป full-stack ทั่วไป:
- โฮสต์แบ็กเอนด์: ดีพลอย container หรือบริการจัดการ แล้วรัน health checks
- การมิเกรตฐานข้อมูล: version migrations, รันอัตโนมัติระหว่าง deploy, และทำให้ย้อนกลับได้เมื่อเป็นไปได้
- ปล่อยมือถือ: เผยแพร่บิลด์ภายในก่อน (TestFlight / internal testing), แล้วค่อย rollout แบบเป็นขั้นตอนสู่ App Store/Play Store
มอนิเตอร์และเวิร์กโฟลว์ปัญหา
วางแผนให้มีสัญญาณ 3 อย่าง:
- Logs (เกิดอะไรขึ้น), metrics (เท่าไร), และ alerts (อะไรต้องทำตอนนี้)
- กฎ on-call เบาๆ: alerts ควร actionable ไม่ใช่ noisy
- ทางสำหรับผู้ใช้รายงานปัญหา (ลิงก์ในแอปหรือหน้า support) ส่งเข้าแถวการจัดลำดับความสำคัญที่มี severity, ขั้นตอนทำซ้ำ, และแผนการ rollback
นี่คือที่การพัฒนาโดยมี AI เข้าไปช่วยกลายเป็นการปฏิบัติการ: คุณไม่ได้แค่สร้างโค้ด คุณกำลังรันผลิตภัณฑ์จริง
ข้อผิดพลาดที่ LLM มักทำ (และแก้ยังไง)
ออกแบบ API ที่พร้อมส่งมอบ
เปลี่ยนการกระทำของผู้ใช้เป็น endpoints ที่ชัดเจน พร้อมข้อผิดพลาดและการจัดเวอร์ชันที่สม่ำเสมอ
LLM สามารถเปลี่ยนไอเดียคลุมเครือเป็นแผนที่ ดูเหมือน ครบถ้วน—แต่ภาษาสวยๆ อาจซ่อนช่องว่าง ความล้มเหลวที่พบบ่อยมีรูปแบบ และคุณสามารถป้องกันได้ด้วยนิสัยไม่กี่อย่างที่ทำซ้ำได้
ทำไมพรอมต์ล้มเหลว
ผลลัพธ์อ่อนมักมาจากสี่ปัญหา:
- ขาดบริบท: โมเดลไม่รู้ผู้ใช้ของคุณ, ข้อจำกัด (งบ, เวลา, ทักษะทีม), ข้อกำหนดการปฏิบัติตาม, หรือสิ่งที่มีอยู่แล้ว
- ข้อกำหนดขัดแย้ง: “ทำให้เรียบง่าย” บวกกับ “รองรับทุกเคสขอบ” ให้สเปคมั่ว
- สมมติฐานที่ซ่อนอยู่: โมเดลอาจสมมติว่าล็อกอินเป็นอีเมล/รหัสผ่าน, “เรียลไทม์” คือ WebSockets, หรือ “admin” หมายถึงสิทธิ์เต็มรูปแบบ
- ลำดับความสำคัญที่ไม่ชัด: หากไม่มีการแลกเปลี่ยน (ความเร็ว vs ต้นทุน vs คุณภาพ) คุณจะได้คำตอบทั่วไปที่ไม่พอดีกับบริบท
จะขอผลลัพธ์ที่ดีกับโมเดลอย่างไร
ให้โมเดลข้อมูลชัดเจน:
- ตัวอย่าง: “เหมือนการจองแบบ Calendly แต่สำหรับบริการนอกสถานที่” บวกกับ 2–3 เรื่องราวตัวอย่าง
- ข้อจำกัด: “ต้องใช้ Postgres, ปรับใช้บน AWS, รองรับ 10k MAU”
- บังคับให้เหตุผลปรากฏ: ให้มันรายการสมมติฐาน, คำถามที่เปิด, และทางเลือก: “โชว์การทำงาน: การตัดสินใจ + ทำไม”
เพิ่ม “นิยามของความเสร็จ” เพื่อลดการทำงานซ้ำ
ขอเช็คลิสต์ต่อผลลัพธ์แต่ละชิ้น ตัวอย่าง ข้อกำหนดไม่ถือว่า “เสร็จ” จนกว่าจะมีเกณฑ์ยอมรับ, สถานะข้อผิดพลาด, บทบาท/สิทธิ์, และตัวชี้วัดความสำเร็จที่วัดได้
เก็บแหล่งความจริงเดียว
ผลลัพธ์จาก LLM ครอบคลุมเมื่อสเปค, โน้ต API, และแนวคิดการออกแบบไม่กระจัดกระจาย รักษาเอกสารเดียวที่มี:
- สเปคผลิตภัณฑ์,
- สัญญา API (endpoints + schemas),
- และ โน้ตการออกแบบ (ฟลูหลักและเคสขอบ)
เมื่อคุณพรอมต์อีกครั้ง ให้วางช่วงย่อหน้าล่าสุดแล้วบอกว่า: “อัปเดต เฉพาะ ส่วน X และ Y; ให้ส่วนอื่นไม่เปลี่ยน” ถ้าคุณกำลังพัฒนาไปพร้อมกัน มันช่วยใช้เวิร์กโฟลว์ที่รองรับการวนซ้ำอย่างรวดเร็ว โดยไม่ สูญเสียการติดตาม เช่นโหมด “planning” ของ Koder.ai: คุณสามารถล็อกสเปค (สมมติฐาน, คำถามที่เปิด, เกณฑ์ยอมรับ), สร้างโครงเว็บ/มือถือ/แบ็กเอนด์จากแชทเดียวกัน, และพึ่งพา snapshot/rollback เมื่อต้องย้อนการเปลี่ยน แยกซอร์สโค้ดเป็นประโยชน์เมื่อต้องการให้สถาปัตยกรรมที่สร้างและรีโปของคุณสอดคล้องกัน
เดินผ่านตัวอย่างจริงและจุดที่มนุษย์ต้องตรวจ
นี่คือภาพรวมว่า “การแปลโดย LLM” อาจเป็นอย่างไรแบบ end-to-end—พร้อมจุดตรวจที่มนุษย์ควรชะลอและตัดสินใจจริง
ตัวอย่างสั้น: ไอเดีย → หน้าจอ, ข้อมูล, API
ไอเดียภาษาอังกฤษ: “ตลาดหาคนดูแลสัตว์เลี้ยงที่เจ้าของโพสต์คำขอ, ผู้ดูแลสมัคร, และเงินถูกปล่อยหลังงานเสร็จ”
LLM สามารถแปลงเป็นร่างแรกได้เช่น:
- หน้าจอ: สมัคร/ล็อกอิน, สร้างคำขอ, รายละเอียดคำขอ (พร้อมผู้สมัคร), สมัครงาน, แชทในแอป, เช็คเอาต์, งานเสร็จ, ให้คะแนน/รีวิว, ผู้ดูแลระบบ (ข้อพิพาท)
- โมเดลข้อมูล: Users (role: owner/sitter), PetProfiles, Requests (วันที่, สถานที่, สถานะ), Applications, Messages, Payments, Reviews
- API:
POST /requests,GET /requests/{id},POST /requests/{id}/apply,GET /requests/{id}/applications,POST /messages,POST /checkout/session,POST /jobs/{id}/complete,POST /reviews
นั่นมีประโยชน์—แต่ยังไม่ถือว่า “เสร็จ” มันเป็นข้อเสนอที่เป็นโครงสร้างที่ต้องตรวจ
จุดที่มนุษย์ต้องตรวจ (และทำไมสำคัญ)
การตัดสินใจด้านผลิตภัณฑ์: อะไรทำให้ “ใบสมัคร” ถูกต้อง? เจ้าของเชิญผู้ดูแลได้ไหม? คำขอถือว่า “เต็ม” เมื่อใด? กฎเหล่านี้มีผลต่อทุกหน้าจอและ API
การตรวจความปลอดภัย & ความเป็นส่วนตัว: ยืนยันการเข้าถึงตามบทบาท (เจ้าของอ่านแชทของเจ้าของคนอื่นไม่ได้), ป้องกันข้อมูลการชำระเงิน, และกำหนดนโยบายการเก็บข้อมูล (เช่น ลบแชทหลัง X เดือน) เพิ่มการควบคุมการใช้งานไม่ดี: rate limits, ป้องกันสแปม, audit logs
การแลกเปลี่ยนด้านประสิทธิภาพ: ตัดสินใจว่าสิ่งใดต้องเร็วและต้องสเกล (ค้นหา/กรองคำขอ, แชท) สิ่งนี้มีผลต่อการแคช, การแบ่งเพจ, ดัชนี และงานแบ็กกราวด์
วงจรการวนซ้ำ: ข้อเสนอแนะ → ข้อกำหนด → โค้ด
หลังพายล็อต ผู้ใช้อาจขอ “ทำซ้ำคำขอ” หรือ “ยกเลิกคืนเงินบางส่วน” นำสิ่งนั้นกลับมาเป็นข้อกำหนดอัปเดต สร้างหรือแพตช์ฟลูที่เกี่ยวข้อง แล้วรันเทสต์และการตรวจความปลอดภัยอีกครั้ง
ควรจัดเอกสารอะไรเพื่อความดูแลรักษา
บันทึก “เหตุผล” ไม่ใช่แค่ “สิ่งที่ทำ”: กฎธุรกิจสำคัญ, เมทริกซ์สิทธิ์, สัญญา API, รหัสข้อผิดพลาด, มิเกรชันฐานข้อมูล, และ runbook สั้นๆ สำหรับการปล่อยและการตอบเหตุฉุกเฉิน นี่คือสิ่งที่ทำให้โค้ดที่สร้างโดยเครื่องเข้าใจได้หลัง 6 เดือน
คำถามที่พบบ่อย
คำว่า “การแปล” หมายความว่าอย่างไร เมื่อคนพูดว่า LLM สามารถแปลไอเดียเป็นแอปได้?
ในบริบทนี้ “การแปล” หมายถึงการเปลี่ยนไอเดียที่ยังคลุมเครือให้เป็น การตัดสินใจที่ชัดเจนและตรวจสอบได้: บทบาทผู้ใช้, เส้นทางการใช้งาน, ข้อกำหนด, ข้อมูล, API และเกณฑ์ความสำเร็จ。
มันไม่ใช่แค่การเขียนซ้ำ—แต่เป็นการทำให้สมมติฐานปรากฏให้เห็นเพื่อที่คุณจะได้ยืนยันหรือปฏิเสธก่อนจะเริ่มสร้างจริง
ผมควรคาดหวังให้อะไรจาก LLM เมื่อสร้างผลิตภัณฑ์ใหม่?
ชิ้นงานร่างที่ใช้งานได้จริงมักจะรวมถึง:
- บทบาทผู้ใช้และเส้นทางหลัก
- รายการฟีเจอร์พร้อมลำดับความสำคัญ (ต้องมี vs อยากมี)
- เรื่องราวผู้ใช้พร้อมเกณฑ์ยอมรับ
- รายการหน้าจอ + แผนผังการนำทาง (เว็บและมือถือ)
- โมเดลข้อมูล (เอนทิตี, ความสัมพันธ์, ข้อจำกัด)
- โครงร่าง API (endpoints, schemas, ข้อผิดพลาด)
ถือเป็น แบบร่างแผนผัง ที่ควรตรวจทาน ไม่ใช่สเปคสุดท้าย
การตัดสินใจใดบ้างที่ยังต้องใช้คน แม้จะมีผลลัพธ์จาก LLM ที่ดี?
เพราะ LLM ไม่รู้บริบทจริงของคุณโดยอัตโนมัติ มนุษย์ยังต้องตัดสินใจเรื่องสำคัญ เช่น:
- ความหมายของ “ความสำเร็จ” (ตัวชี้วัด)
- ข้อจำกัดด้านงบประมาณ/ระยะเวลาและความเสี่ยงที่รับได้
- ขอบเคสใดควรแก้ตอนนี้หรือเลื่อนไปก่อน
- รูปแบบ MVP ที่เรียบง่ายแต่ผู้ใช้ยังรัก
ให้โมเดลเสนอทางเลือก แล้ว เลือกอย่างรอบคอบ
จะเขียนบรีฟผลิตภัณฑ์อย่างไรให้ LLM ใช้งานได้จริง?
ให้ข้อมูลที่เพียงพอเพื่อออกแบบ:
- คำอธิบายปัญหา 1 ประโยค + ตัวชี้วัดความสำเร็จ 2–3 รายการ
- 3–7 กรณีใช้งานหลักในรูปแบบ “ในฐานะ [บทบาท], ฉันต้องการ…”
- แพลตฟอร์มที่ต้องรองรับ (web/iOS/Android), ความต้องการออฟไลน์, และการเชื่อมต่อภายนอก
- ข้อกำกับด้านความเป็นส่วนตัว/การปฏิบัติตาม (เช่น HIPAA/GDPR)
- รายการที่เข้าใน MVP vs เลื่อนออก
ถ้าคนที่รับบรีฟของคุณแล้วไม่ตีความเหมือนกัน แปลว่าบรีฟยังไม่พร้อม
จะแปลงไอเดียภาษาอังกฤษเป็นข้อกำหนดโดยไม่ให้สเปคคลุมเครือได้อย่างไร?
แปลงเป้าหมายเป็น เรื่องราวผู้ใช้ + เกณฑ์ยอมรับ:
- รวมเรื่องราวผู้ใช้เป็นกลุ่มฟีเจอร์
- ติดป้ายลำดับความสำคัญ (must-have/nice-to-have)
- เขียนเกณฑ์ยอมรับแบบ "Given/When/Then"
- ระบุกรณีขอบอย่างชัดเจน (ยกเลิก, รีไทร, ซ้ำ, คืนเงิน)
ชุดนี้จะเป็น “แหล่งความจริง” สำหรับ UI, API และการทดสอบ
จะใช้ LLM กับการออกแบบ UI ให้ได้ผลโดยไม่ออกแบบสวยแต่ใช้งานไม่ได้อย่างไร?
ขอให้โมเดลส่งมอบ 2 อย่าง:
- รายการหน้าจอ (ทุกหน้าที่ต้องสร้าง)
- แผนผังการนำทาง (ผู้ใช้เคลื่อนที่ระหว่างหน้าต่างๆ อย่างไร)
แล้วยืนยันว่า:
- แต่ละเส้นทางหลักทำงานได้จริงจนจบ
ควรเริ่มด้วย monolith, modular monolith หรือ microservices?
เริ่มด้วยค่าเริ่มต้น: monolith หรือ modular monolith สำหรับผลิตภัณฑ์ v1 ส่วนใหญ่。
ถ้าโมเดลเสนอ microservices ทันที ให้ขอเหตุผลชัดเจน (เช่น ปริมาณทราฟฟิก, ความต้องการ deploy แยกของทีม, ส่วนที่ต้องสเกลต่างกัน) และยอมรับ ‘escape hatches’ แทน:
- คิวงานแบ็กกราวด์
- แคชสำหรับอ่านบ่อย
- แอปเซิร์ฟเวอร์แบบ stateless
ทำให้ v1 ง่ายต่อการส่งมอบและดีบัก
ควรมองหาอะไรในโมเดลข้อมูลที่สร้างโดย LLM เพื่อหลีกเลี่ยงการเขียนทับครั้งใหญ่ในภายหลัง?
ให้โมเดลระบุ:
- เอนทิตีและความสัมพันธ์ (อะไรอยู่ข้างในอะไร)
- ความเป็นเจ้าของและการเข้าถึง (owner_user_id, สมาชิก, บทบาท)
- ข้อจำกัด (email ต้องไม่ซ้ำ, ฟิลด์บังคับ, enums ของสถานะ)
- กฎการลบ (soft vs hard) และเหตุการณ์ audit
- การแยกหลายเทนแนนต์ (tenant/organization + tenant_id เมื่อจำเป็น)
การตัดสินใจเรื่องข้อมูลมีผลต่อฟิลเตอร์ UI, การแจ้งเตือน, รายงาน และความปลอดภัย
จะประเมินว่า API ที่ LLM สร้างใช้งานได้จริงในแอปอย่างไร?
ยืนยันความสม่ำเสมอและความเป็นมิตรกับมือถือ:
- พาธฐานเวอร์ชัน (เช่น
/api/v1/...) - CRUD + search/filter ชัดเจน
- รูปแบบ request/response ที่นิ่งพร้อมตัวอย่าง
- รูปแบบข้อผิดพลาดมาตรฐานสำหรับ 400/401/403/404/409/429/500
- Idempotency keys สำหรับ
POSTที่อาจถูก retry
หลีกเลี่ยงการเปลี่ยนแปลงที่ทำให้แตกหัก; เพิ่มฟิลด์เป็น optional และให้ช่วงเวลา deprecation
จะใช้ LLM ผลิตกลยุทธ์การทดสอบที่ไม่ใช่แค่คำพูดทั่วไปได้อย่างไร?
ให้โมเดลร่างแผนแล้วตรวจทานเทียบกับเกณฑ์ยอมรับ:
- Unit tests สำหรับกฎธุรกิจและสิทธิ์
- Integration tests สำหรับพฤติกรรม API + DB
- End-to-end tests สำหรับเส้นทางสำคัญ
- ตรวจสอบเฉพาะมือถือ (ออฟไลน์, backgrounding, คำขอสิทธิ์)
ขอข้อมูล fixtures จริง: โซนเวลา, ข้อความยาว, กรณีซ้ำใกล้เคียง, เครือข่ายไม่เสถียร
ถือว่าการทดสอบที่ LLM สร้างเป็นจุดเริ่มต้น ไม่ใช่ QA สุดท้าย