10 ส.ค. 2568·3 นาที
LLM จัดการกฎธุรกิจและการตัดสินใจในเวิร์กโฟลว์อย่างไร
เรียนรู้ว่า LLM แปลความกฎธุรกิจ ติดตามสถานะเวิร์กโฟลว์ และยืนยันการตัดสินใจด้วย prompt เครื่องมือ การทดสอบ และการทบทวนโดยมนุษย์—ไม่ใช่แค่โค้ด
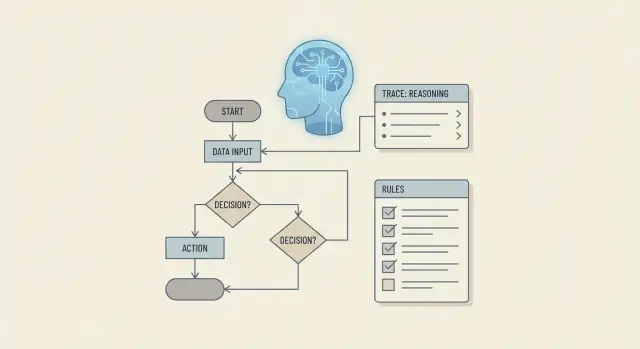
ทำไมการให้เหตุผลตามกฎธุรกิจจึงมากกว่าแค่การสร้างโค้ด
เมื่อมีคนถามว่า LLM สามารถ “ให้เหตุผลเกี่ยวกับกฎธุรกิจ” ได้ไหม พวกเขามักหมายถึงสิ่งที่ยากกว่าการเขียน if/else ธรรมดา การให้เหตุผลตามกฎธุรกิจคือความสามารถในการปฏิบัติตามนโยบายอย่างสม่ำเสมอ อธิบายการตัดสินใจ จัดการข้อยกเว้น และยังคงสอดคล้องกับขั้นตอนของเวิร์กโฟลว์—โดยเฉพาะเมื่อข้อมูลนำเข้าไม่สมบูรณ์ สกปรก หรือเปลี่ยนแปลง
การให้เหตุผลกับการสร้างโค้ด
การสร้างโค้ดส่วนใหญ่คือการผลิตไวยากรณ์ที่ถูกต้องในภาษาที่ต้องการ แต่การให้เหตุผลตามกฎคือการรักษาเจตนารมณ์
โมเดลอาจสร้างโค้ดที่ถูกต้องตามไวยากรณ์แต่ยังให้ผลลัพธ์ทางธุรกิจผิดพลาดได้ เพราะว่า:
- ข้อความนโยบายคลุมเครือ (เช่น “ลูกค้าล่าสุด”, “ความเสี่ยงสูง”, “เอกสารที่อนุมัติแล้ว”)
- กฎขัดแย้งกันและไม่ชัดเจนว่าอันไหนมีลำดับความสำคัญ
- กรณีมุมที่ไม่ได้ระบุ (การคืนเงินบางส่วน ซ้ำซ้อน วันหยุด/สุดสัปดาห์)
- สถานะของเวิร์กโฟลว์เปลี่ยนว่าควรทำอะไรต่อไป (การรับเข้ากับการตรวจทานกับการอนุมัติขั้นสุดท้าย)
กล่าวคือ ความถูกต้องไม่ได้หมายถึง “คอมไพล์ได้ไหม?” แต่คือ “ตรงกับการตัดสินใจของธุรกิจในทุกครั้งหรือไม่ และเราพิสูจน์ได้หรือเปล่า?”
ควรคาดหวังอะไรจาก LLM
LLM สามารถช่วยแปลงนโยบายเป็นกฎที่มีโครงสร้าง แนะนำเส้นทางการตัดสินใจ และร่างคำอธิบายสำหรับมนุษย์ แต่พวกมันไม่ได้รู้โดยอัตโนมัติว่ากฎใดมีอำนาจสูงสุด แหล่งข้อมูลใดเชื่อถือได้ หรือกรณีตอนนี้อยู่ในขั้นตอนไหน หากไม่มีข้อจำกัด พวกมันอาจเลือกคำตอบที่ฟังดูเป็นไปได้แทนคำตอบที่ถูกควบคุม
ดังนั้นเป้าหมายไม่ใช่ "ปล่อยให้โมเดลตัดสิน" แต่คือให้โครงสร้างและการตรวจสอบเพื่อให้ช่วยได้อย่างเชื่อถือได้
สิ่งที่โพสต์ส่วนที่เหลือจะทำ
แนวทางเชิงปฏิบัติจะเป็นเหมือน pipeline:
- แปลงข้อความนโยบายเป็นตัวแทนกฎที่ใช้ได้
- ติดตามสถานะเวิร์กโฟลว์เพื่อให้การตัดสินใจสอดคล้องข้ามขั้นตอน
- ใช้รูปแบบ prompt เพื่อบังคับลำดับความสำคัญ ข้อยกเว้น และคำอธิบาย
- ยึดการตัดสินใจด้วยเครื่องมือและการดึงข้อมูล (ใช้เฉพาะข้อมูลที่อนุญาตเท่านั้น)
- จำกัดผลลัพธ์ด้วยสคีมาเพื่อลดความคลุมเครือ
- ตรวจสอบ ทดสอบ และมอนิเตอร์เพื่อจับข้อผิดพลาดก่อนปล่อยใช้งาน
นั่นแหละความต่างระหว่างสเนปิปต์โค้ดฉลาด ๆ กับระบบที่รองรับการตัดสินใจทางธุรกิจจริง
กฎธุรกิจและเวิร์กโฟลว์: ทบทวนสั้น ๆ เป็นภาษาเรียบง่าย
ก่อนจะพูดถึงว่า LLM "ให้เหตุผล" อย่างไร มีประโยชน์ถ้าแยกสองอย่างที่ทีมมักมัดรวมกัน: กฎธุรกิจ และ เวิร์กโฟลว์
กฎธุรกิจคืออะไร?
กฎธุรกิจ คือข้อความการตัดสินใจที่องค์กรต้องการให้บังคับใช้อย่างสม่ำเสมอ ปรากฏในรูปแบบนโยบายและตรรกะ เช่น:
- ความมีสิทธิ์: ใครมีสิทธิ์ได้รับสิทธิ ประเภทแผน หรือฟีเจอร์
- การตั้งราคา: ส่วนลดใดบ้างที่ใช้ได้และเมื่อไร
- การอนุมัติ: เมื่อใดต้องให้ผู้จัดการตรวจทาน
- การปฏิบัติตาม: อะไรต้องถูกบันทึก ลบข้อมูล หรือบล็อก
กฎมักมีรูปแบบ “IF X, THEN Y” (บางครั้งมีข้อยกเว้น) และควรให้ผลลัพธ์ชัดเจน: อนุมัติ/ปฏิเสธ, ราคา A/ราคา B, ขอข้อมูลเพิ่ม เป็นต้น
เวิร์กโฟลว์คืออะไร?
เวิร์กโฟลว์ คือกระบวนการที่ย้ายงานจากเริ่มจนเสร็จ มันเกี่ยวกับ จะเกิดอะไรขึ้นต่อไป มากกว่าจะตัดสินว่า อะไรอนุญาต เวิร์กโฟลว์มักมี:
- สถานะ: submitted → under review → approved/denied → completed
- ขั้นตอนและการส่งต่อ: ฝ่ายสนับสนุน → การเงิน → ลูกค้า
- เหตุการณ์ตามเวลา: เตือนเวลา, SLA, ยกเลิกอัตโนมัติหลัง 14 วัน
- เอกสารประกอบ: แบบฟอร์ม ไฟล์แนบ รหัสเหตุผล หมายเหตุการตรวจสอบ
ตัวอย่างเล็ก ๆ: คำขอคืนเงิน
ลองนึกภาพคำขอคืนเงิน
ตัวอย่างกฎ: “คืนเงินได้ภายใน 30 วันหลังซื้อ ข้อยกเว้น: ดาวน์โหลดดิจิทัลไม่สามารถคืนได้หลังจากเข้าถึงแล้ว ข้อยกเว้น: กรณี chargeback ต้องยกระดับ”
ตัวอย่างเวิร์กโฟลว์:
- ลูกค้าส่งคำขอ (สถานะ: submitted)
- ระบบตรวจวันที่ซื้อและประเภทสินค้า (สถานะ: under review)
- หากมีสิทธิ์ ให้คืนเงินและแจ้งลูกค้า (สถานะ: completed)
- หากเป็น chargeback ส่งไปยังการเงินเพื่อตรวจสอบ (สถานะ: escalated)
ทำไมกฎถึงยากกว่าที่คิด
กฎซับซ้อนเมื่อต้อง ขัดแย้ง กัน (“ลูกค้า VIP ได้คืนเสมอ” กับ “ดาวน์โหลดดิจิทัลไม่คืน”) พึ่งพา บริบทที่หายไป (ดาวน์โหลดเข้าถึงแล้วไหม?) หรือซ่อน กรณีมุม (แพ็กเกจ, คืนบางส่วน, กฎหมายพื้นที่) เวิร์กโฟลว์เพิ่มอีกชั้น: การตัดสินใจต้องสอดคล้องกับสถานะปัจจุบัน การกระทำก่อนหน้า และกำหนดเวลา
LLM "ให้เหตุผล" อย่างไร: การจับคู่รูปแบบพร้อมโครงสร้างที่ช่วยได้
LLM ไม่ได้ "เข้าใจ" กฎธุรกิจเหมือนมนุษย์ มันสร้างคำถัดไปที่มีความน่าจะเป็นสูงสุดจากข้อมูลที่เรียนรู้มามาก นั่นคือเหตุผลที่ LLM ฟังดูมีเหตุผลแม้กำลังเดา—หรือเติมรายละเอียดที่หายไปโดยไม่ได้รับข้อมูล
ข้อจำกัดนี้มีผลกับเวิร์กโฟลว์และตรรกะการตัดสินใจ โมเดลอาจใช้กฎที่ "ฟังดูถูก" (เช่น “พนักงานต้องได้รับการอนุมัติจากผู้จัดการเสมอ”) แม้นโยบายจริงจะมีข้อยกเว้น (เช่น “เฉพาะมากกว่า $500” หรือ “เฉพาะผู้รับจ้าง”) นี่คือโหมดความล้มเหลวที่พบบ่อย: แน่นใจแต่ผิด
ทำไมยังมีประโยชน์สำหรับกฎธุรกิจ
แม้ไม่มี "ความเข้าใจ" จริง LLM ก็ช่วยได้เมื่อคุณใช้งานมันเป็นผู้ช่วยที่มีโครงสร้าง:
- สรุป นโยบายยาว ๆ ให้ชัดเจนสำหรับการทบทวน
- แม็ป ข้อความที่ไม่เป็นระเบียบเป็นฟิลด์ที่สอดคล้องกัน (ใคร อะไร ขีดจำกัด ข้อยกเว้น วันมีผล)
- ตรวจสอบ การตัดสินใจที่เสนอเทียบกับกฎที่ระบุ ("ข้อใดสนับสนุนสิ่งนี้?")
กุญแจคือการวางโมเดลในตำแหน่งที่มันไม่สามารถออกนอกเส้นทางได้ง่าย
จำกัดโมเดลเพื่อไม่ให้มันไหลเลื่อน
วิธีปฏิบัติทั่วไปคือ ผลลัพธ์แบบจำกัด: บังคับให้ LLM ตอบในสคีมหรือเทมเพลตคงที่ (เช่น JSON กับฟิลด์เฉพาะ หรือตารางที่มีคอลัมน์บังคับ) เมื่อโมเดลต้องเติม rule_id, conditions, exceptions, และ decision จะง่ายขึ้นที่จะเห็นช่องว่างและตรวจสอบอัตโนมัติ
ฟอร์แมตจำกัดยังชัดเจนเมื่อโมเดลไม่รู้คำตอบ หากฟิลด์ที่ต้องการหายไป คุณสามารถบังคับคำถามติดตามแทนการยอมรับคำตอบไม่แน่ใจ
คติ: LLM "ให้เหตุผล" เป็นการสร้างรูปแบบตามแบบแผนที่มีโครงสร้าง—มีประโยชน์ในการจัดระเบียบและตรวจตรากฎ แต่เสี่ยงหากถือว่าเป็นผู้ตัดสินที่ไม่ผิดพลาด
แปลงข้อความนโยบายที่ไม่เป็นระเบียบเป็นตัวแทนกฎที่ใช้ได้
เอกสารนโยบายเขียนสำหรับมนุษย์: ผสมเป้าหมาย ข้อยกเว้น และ "สามัญสำนึก" ในย่อหน้าเดียว LLM สามารถสรุปข้อความนั้นได้ แต่จะทำตามกฎได้แน่นอนขึ้นเมื่อคุณแปลงนโยบายเป็นอินพุตที่ชัดเจนและทดสอบได้
กฎที่ "ใช้ได้" หน้าตาเป็นอย่างไร
ตัวแทนกฎที่ดีมีสองคุณสมบัติ: ไม่มีความคลุมเครือ และตรวจสอบได้
เขียนกฎเป็นประโยคที่คุณทดสอบได้:
- IF/THEN สำหรับการตัดสินใจ (ความมีสิทธิ์ การส่งต่อ การอนุมัติ)
- MUST / MUST NOT สำหรับข้อจำกัดที่เข้มงวด
- MAY สำหรับตัวเลือกที่อนุญาต (มักต้องมีตัวตัดสินใจเมื่อไม่แน่ชัด)
กฎสามารถให้โมเดลในหลายรูปแบบ:
- หัวข้อแบบย่อเป็นภาษาธรรมดา (เร็วสุด ยังคงมีโครงสร้าง)
- ตาราง (ดีสำหรับนโยบายที่อิงเกณฑ์)
- YAML/JSON (ดีที่สุดเมื่อคุณต้องการผลลัพธ์ที่จำกัดและการตรวจสอบอัตโนมัติ)
จัดการความขัดแย้งและลำดับความสำคัญ
นโยบายจริงมักขัดแย้งกัน เมื่อสองกฎไม่ตรงกัน โมเดลต้องการสกีมาลำดับความสำคัญ วิธีปฏิบัติที่ใช้บ่อย:
- เฉพาะเจาะจงชนะทั่วไป (ข้อยกเว้นทับค่าเริ่มต้น)
- ผู้มีอำนาจสูงกว่าจะชนะ (กฎหมาย/คอมไพลอแนนซ์เหนือความชอบส่วนทีม)
- ล่าสุดชนะ (เวอร์ชันใหม่กว่าแทนที่เวอร์ชันเก่า)
- หมายเลขลำดับความสำคัญชัดเจน (เช่น
priority: 100)
ระบุวิธีแก้ความขัดแย้งโดยตรง หรือเข้ารหัสมัน (เช่น priority: 100) มิฉะนั้น LLM อาจ "เฉลี่ย" กฎ
ตัวอย่าง: แปลงย่อหน้าหนึ่งเป็นรายการกฎ
ต้นฉบับ:
“Refunds are available within 30 days for annual plans. Monthly plans are non-refundable after 7 days. If the account shows fraud or excessive chargebacks, do not issue a refund. Enterprise customers need Finance approval for refunds over $5,000.”
กฎที่มีโครงสร้าง (YAML):
rules:
- id: R1
statement: "IF plan_type = annual AND days_since_purchase <= 30 THEN refund MAY be issued"
priority: 10
- id: R2
statement: "IF plan_type = monthly AND days_since_purchase > 7 THEN refund MUST NOT be issued"
priority: 20
- id: R3
statement: "IF fraud_flag = true OR chargeback_rate = excessive THEN refund MUST NOT be issued"
priority: 100
- id: R4
statement: "IF customer_tier = enterprise AND refund_amount > 5000 THEN finance_approval MUST be obtained"
priority: 50
conflict_resolution: "Higher priority wins; MUST NOT overrides MAY"
ตอนนี้โมเดลจะไม่เดาว่าสิ่งใดสำคัญ—มันจะใช้ชุดกฎที่คุณสามารถตรวจทาน ทดสอบ และจัดเวอร์ชันได้
ติดตามสถานะเวิร์กโฟลว์เพื่อให้โมเดลคงความสอดคล้อง
เวิร์กโฟลว์ไม่ใช่แค่ชุดกฎ แต่มันคือชุดเหตุการณ์ที่ขั้นก่อนหน้าจะเปลี่ยนสิ่งที่ควรเกิดขึ้นต่อไป ความจำนี้คือ สถานะ: ข้อเท็จจริงปัจจุบันเกี่ยวกับเคส (ใครส่งอะไรไปแล้ว อะไรอนุมัติแล้ว อะไรรอ และมีเดดไลน์ใด) หากคุณไม่ติดตามสถานะอย่างชัดเจน เวิร์กโฟลว์จะพังในแบบที่คาดได้—การอนุมัติซ้ำ ข้ามการตรวจสอบที่จำเป็น พลิกการตัดสินใจ หรือใช้กฎผิดเพราะโมเดลเดาไม่ได้ว่าเกิดอะไรไปแล้ว
สถานะหมายถึงอะไรในภาษาง่าย ๆ
คิดว่าสถานะเป็นสกอร์บอร์ดของเวิร์กโฟลว์ มันตอบว่า: ตอนนี้เราอยู่ตรงไหน? ทำอะไรไปแล้ว? อนุญาตอะไรต่อไป? สำหรับ LLM การมีสรุปสถานะที่ชัดเจนป้องกันไม่ให้มันพิจารณาขั้นตอนก่อนหน้าใหม่หรือเดาสิ่งที่เกิดขึ้น
วิธีส่งสถานะให้โมเดล
เมื่อคุณเรียกโมเดล ให้รวม payload สรุปสถานะที่กะทัดรัดพร้อมคำขอของผู้ใช้ ฟิลด์ที่มีประโยชน์ได้แก่:
- ชื่อและสถานะของขั้นตอน (เช่น
manager_review: approved,finance_review: pending) - รหัสประจำตัวที่คงที่ (request ID, employee ID) เพื่อไม่ให้โมเดลสับเปลี่ยนเคส
- ป้ายเวลา (submitted at, last updated) เพื่อแก้ปัญหา "ล่าสุดชนะ"
- แฟล็ก (ข้อยกเว้นนโยบาย เอกสารถูกขาด ข้อกำหนดการยกระดับ)
หลีกเลี่ยงการใส่ข้อความประวัติศาสตร์ทั้งหมด ให้ใส่เฉพาะสถานะปัจจุบันกับร่องรอยการตรวจสอบสั้น ๆ ของการเปลี่ยนแปลงสำคัญ
เก็บแหล่งข้อมูลเดียวของความจริง
ปฏิบัติเช่นเอนจินเวิร์กโฟลว์ (ฐานข้อมูล ระบบตั๋ว หรือ orchestrator) เป็น แหล่งข้อมูลเดียวของความจริง ให้ LLM อ่าน สถานะจากระบบนั้นและเสนอการกระทำถัดไป แต่ระบบเป็นฝ่ายบันทึกการเปลี่ยนแปลง นี่ช่วยลด "state drift" ที่เรื่องเล่าในโมเดลแตกต่างจากความเป็นจริง
ตัวอย่าง: สแนปช็อตสถานะการอนุมัติ
{
"request_id": "TRV-10482",
"workflow": "travel_reimbursement_v3",
"current_step": "finance_review",
"step_status": {
"submission": "complete",
"manager_review": "approved",
"finance_review": "pending",
"payment": "not_started"
},
"actors": {
"employee_id": "E-2291",
"manager_id": "M-104",
"finance_queue": "FIN-AP"
},
"amount": 842.15,
"currency": "USD",
"submitted_at": "2025-12-12T14:03:22Z",
"last_state_update": "2025-12-13T09:18:05Z",
"flags": {
"receipt_missing": false,
"policy_exception_requested": true,
"needs_escalation": false
}
}
ด้วยสแนปช็อตแบบนี้ โมเดลจะคงความสอดคล้อง: มันจะไม่ขออนุมัติผู้จัดการซ้ำ มันจะมุ่งไปที่การตรวจสอบทางการเงิน และอธิบายการตัดสินใจตามแฟล็กและขั้นตอนปัจจุบัน
รูปแบบ prompt ที่ช่วยให้การปฏิบัติตามกฎและการตัดสินใจดีขึ้น
ปรับใช้และวนปรับได้อย่างเร็ว
ปล่อยผู้ช่วยเวิร์กโฟลว์ของคุณพร้อมการปรับใช้และโฮสติ้งในที่เดียว
Prompt ที่ดีไม่ได้แค่ถามคำตอบ—มันกำหนดความคาดหวังว่าโมเดลควรใช้กฎอย่างไรและควรรายงานผลอย่างไร เป้าหมายคือการตัดสินใจที่ทำซ้ำได้ ไม่ใช่ถ้อยคำมีไหวพริบ
1) Role prompting: มอบหน้าที่ชัดเจน ไม่ใช่แค่บรรยากาศ
ให้โมเดลรับบทบาทที่ผูกกับกระบวนการของคุณ หน้าที่ 3 แบบที่ใช้ดีร่วมกันได้แก่:
- นักวิเคราะห์นโยบาย: แปลข้อความกฎและแม็ปไปยังเคสปัจจุบัน
- ผู้ตรวจสอบ: ตรวจการตัดสินใจเทียบกับข้อกำหนดและชี้ช่องข้อมูลขาด
- เอเยนต์: กระทำการถัดไปในเวิร์กโฟลว์ (สร้างตั๋ว ร่างอีเมล ตั้งสถานะ)
คุณสามารถรันตามลำดับเหล่านี้ ("analyst → validator → agent") หรือขอผลลัพธ์ทั้งสามในคำตอบที่มีโครงสร้างเดียว
2) คำสั่งทีละขั้นตอน (โดยไม่ขอ reasoning ที่ซ่อนอยู่)
แทนที่จะขอ “chain-of-thought” ให้กำหนดขั้นตอนและเอกสารที่มองเห็นได้:
- ระบุข้อกฎที่เกี่ยวข้อง
- ดึงอินพุตที่จำเป็นจากเคส
- ใช้กฎตามลำดับความสำคัญ
- ผลิตการตัดสินใจและขั้นตอนถัดไป
นี่ทำให้โมเดลเป็นระเบียบและมุ่งเน้นที่ผลลัพธ์: กฎที่ใช้และผลลัพธ์
3) ขอเหตุผลแบบมีโครงสร้าง: rule IDs + หลักฐาน
คำอธิบายอิสระมักเบี่ยงเบน ให้บังคับเหตุผลสั้น ๆ ที่ชี้ไปยังแหล่ง:
- Rule IDs ที่ใช้ (เช่น R-12, R-18)
- หลักฐาน (ย่อหน้าที่อ้างจากเท็กซ์นโยบายและฟิลด์เคสเฉพาะ)
- สมมติฐาน (เมื่ออินพุตหาย)
นี่ช่วยให้การทบทวนเร็วขึ้นและดีบักเมื่อมีข้อขัดแย้ง
4) รูปแบบเช็คลิสต์: อินพุต, การตัดสินใจ, ข้อยกเว้น, ขั้นตอนถัดไป
ใช้เทมเพลตคงที่ทุกครั้ง:
- Inputs received: …
- Inputs missing: …
- Decision: approve/deny/needs-review
- Rule references: [R-…]
- Exceptions considered: …
- Next workflow step: update status / request info / escalate
เทมเพลตนี้ลดความคลุมเครือและกระตุ้นให้โมเดลแสดงช่องว่างก่อนที่จะตัดสินใจผิดพลาด
ใช้เครื่องมือและการดึงข้อมูลเพื่อยึดการตัดสินใจกับข้อมูลจริง
LLM อาจร่างคำตอบที่โน้มน้าวได้แม้ขาดข้อเท็จจริง นั่นมีประโยชน์สำหรับร่าง แต่เสี่ยงสำหรับการตัดสินใจตามกฎ หากโมเดลต้อง เดา สถานะบัญชี ระดับลูกค้า อัตราภาษีภูมิภาค หรือว่าขีดจำกัดถูกใช้ไปแล้ว คุณจะได้ข้อผิดพลาดที่ดูมั่นใจ
เครื่องมือแก้ปัญหานั้นด้วยการเปลี่ยน “การให้เหตุผล” เป็นกระบวนการสองขั้นตอน: ดึงหลักฐานก่อน ตัดสินทีหลัง
เครื่องมือทั่วไปที่ทำให้โมเดลตรงไปตรงมามากขึ้น
ในระบบที่มีกฎและเวิร์กโฟลว์หนัก เครื่องมือไม่กี่อย่างทำงานได้มาก:
- ค้นหาในฐานข้อมูล (โปรไฟล์ลูกค้า สถานะบัญชี สิทธิ์ ยอดการใช้งาน)
- ที่เก็บนโยบาย/กฎ (ข้อความกฎที่อนุมัติ เวอร์ชัน คู่มือ ข้อยกเว้น)
- เครื่องคิดเลข (ค่าธรรมเนียม การคำนวณสัดส่วน ภาษี หน้าต่างเวลา ขีดจำกัด)
- API ตั๋ว/เวิร์กโฟลว์ (เคสเปิด ตัวจับเวลา SLA การอนุมัติ การบันทึกขั้นตอน)
จุดสำคัญคือโมเดลไม่ได้ "คิดขึ้น" ข้อเท็จจริงเชิงปฏิบัติ มันขอข้อมูลเหล่านั้น
การดึง: นำเฉพาะกฎที่เกี่ยวข้องมาใช้
แม้ว่าคุณจะเก็บนโยบายทั้งหมดไว้ในที่เดียว คุณไม่อยากใส่ทั้งหมดเข้าไปใน prompt เสมอไป การดึงเลือกเฉพาะย่อหน้าที่เกี่ยวข้องกับเคสปัจจุบัน เช่น:
- นโยบายการยกเลิกสำหรับแผนของลูกค้า
- ข้อบังคับภูมิภาคตามประเทศ/รัฐ
- ข้อยกเว้นที่ใช้เมื่อตรวจพบ chargeback
นี่ลดการขัดแย้งและทำให้โมเดลไม่ตามกฎเก่าที่ปรากฏในคอนเท็กซ์ก่อนหน้า
เปลี่ยนผลลัพธ์จากเครื่องมือให้เป็นหลักฐานประกอบการตัดสิน
รูปแบบที่เชื่อถือได้คือการถือผลลัพธ์ของเครื่องมือเป็น หลักฐาน ที่โมเดลต้องอ้างอิงในการตัดสิน เช่น:
- เครื่องมือ:
get_account(account_id)→status="past_due",plan="Business",usage_this_month=12000 - เครื่องมือ:
retrieve_policies(query="overage fee Business plan")→ คืนกฎ: “Overage fee applies above 10,000 units at $0.02/unit.” - เครื่องมือ:
calculate_overage(usage=12000, threshold=10000, rate=0.02)→$40.00
ตอนนี้การตัดสินใจไม่ใช่การเดา: มันเป็นข้อสรุปที่ยึดกับอินพุตเฉพาะ ("past_due", "12,000 units", "$0.02/unit") หากตรวจสอบผลลัพธ์ในภายหลัง คุณจะเห็นได้ชัดว่าข้อเท็จจริงใดและเวอร์ชันกฎใดถูกใช้—และแก้ไขส่วนที่ถูกต้องเมื่อมีการเปลี่ยนแปลง
ผลลัพธ์จำกัด: สคีมาที่ลดความคลุมเครือ
ออกแบบโฟลว์ก่อน
ใช้โหมดวางแผนเพื่อแม็ปสถานะ ค่าความสำคัญ และเส้นทางการยกระดับก่อนลงมือทำ
ข้อความอิสระยืดหยุ่น แต่เป็นวิธีที่ง่ายที่สุดที่จะทำให้เวิร์กโฟลว์พัง โมเดลอาจให้คำตอบที่ "สมเหตุสมผล" แต่ไม่สามารถอัตโนมัติได้ ("ดูโอเคสำหรับฉัน") หรือไม่สอดคล้องข้ามขั้นตอน ("approve" vs. "approved") ผลลัพธ์แบบจำกัดแก้ปัญหานั้นด้วยการบังคับให้การตัดสินใจอยู่ในรูปแบบที่คาดเดาได้
คืนการตัดสินใจเป็น JSON
รูปแบบปฏิบัติได้คือให้โมเดลตอบเป็นออบเจ็กต์ JSON เดียวที่ระบบของคุณสามารถแยกและส่งต่อได้:
{
"decision": "needs_review",
"reasons": [
"Applicant provided proof of income, but the document is expired"
],
"next_action": "request_updated_document",
"missing_info": [
"Income statement dated within the last 90 days"
],
"assumptions": [
"Applicant name matches across documents"
]
}
โครงสร้างนี้ทำให้ผลลัพธ์มีประโยชน์แม้เมื่อตัวโมเดลยังตัดสินใจไม่ได้ missing_info และ assumptions เปลี่ยนความไม่แน่นอนให้เป็นการติดตามที่ปฏิบัติได้ แทนการเดาเงียบ ๆ
ใช้ enumeration เพื่อลดผลลัพธ์ที่แตกต่างกัน
เพื่อลดความแปรปรวน กำหนดค่าที่อนุญาต (enums) สำหรับฟิลด์สำคัญ เช่น:
decision:approved|denied|needs_reviewnext_action:approve_case|deny_case|request_more_info|escalate_to_human
ด้วย enums ระบบ downstream ไม่ต้องตีความคำพ้อง ความหมาย หรือเครื่องหมายวรรคตอน พวกมันแยกกิ่งด้วยค่าที่รู้จัก
ทำไมสคีมาทำให้เวิร์กโฟลว์ปลอดภัยขึ้น
สคีมาเปรียบเหมือนราวกันตก พวกมัน:
- ป้องกัน "คำตอบไม่สมบูรณ์" โดยต้องมีฟิลด์ที่บังคับ
- ทำให้ง่ายขึ้นในการตรวจสอบเหตุผลว่าทำไมการตัดสินใจเกิดขึ้น (ผ่าน
reasons) - ทำให้การอัตโนมัติเชื่อถือได้: คิว การแจ้งเตือน และการสร้างงานสามารถทริกเกอร์โดยตรงจาก
decisionและnext_action - สนับสนุนการตรวจสอบความถูกต้อง: คุณสามารถปฏิเสธผลลัพธ์ที่ไม่ตรงกับสคีมาและขอให้โมเดลลองใหม่
ผลลัพธ์คือความคลุมเครือน้อยลง ข้อผิดพลาดมุมที่ลดลง และการตัดสินใจที่เดินผ่านเวิร์กโฟลว์อย่างสม่ำเสมอ
ยุทธศาสตร์การตรวจสอบ: จับข้อผิดพลาดก่อนปล่อย
แม้ prompt จะดี โมเดลก็อาจ "ฟังดูถูก" ในขณะที่ละเมิดกฎ ข้ามขั้นตอนที่จำเป็น หรือคิดตัวเลขขึ้นมา การตรวจสอบเป็นตาข่ายนิรภัยที่เปลี่ยนคำตอบที่น่าจะเป็นไปได้ให้เป็นการตัดสินที่เชื่อถือได้
การตรวจสอบเบื้องต้น: ตรวจอินพุตก่อนให้เหตุผล
เริ่มจากยืนยันว่ามีข้อมูลขั้นต่ำที่ต้องใช้ในการประยุกต์กฎ การตรวจสอบเบื้องต้นควรทำก่อนที่โมเดลจะตัดสินใจ
การตรวจสอบทั่วไปรวมฟิลด์ที่จำเป็น (ประเภทลูกค้า ยอดคำสั่ง ภูมิภาค) รูปแบบพื้นฐาน (วันที่ ไอดี สกุลเงิน) และช่วงที่อนุญาต (จำนวนไม่ลบ ร้อยละไม่เกิน 100%) หากล้มเหลว ให้คืนข้อผิดพลาดที่ชัดเจนและปฏิบัติได้ ("ขาด 'region'; ไม่สามารถเลือกชุดกฎภาษีได้") แทนการให้โมเดลเดา
การตรวจสอบหลัง: ตรวจผลลัพธ์เทียบกับกฎ
หลังโมเดลผลิตผล ให้ตรวจว่าผลสอดคล้องกับชุดกฎของคุณ
มุ่งเน้นที่:
- ครอบคลุมกฎ: การตัดสินใจอ้างถึงหรือแม็ปกับกฎที่ใช้หรือไม่ หรือข้ามนโยบายบังคับหรือเปล่า
- การตรวจความขัดแย้ง: ผลลัพธ์ขัดกับอินพุตที่ระบุหรือไม่ (เช่น "approved" ขณะที่มีเงื่อนไขบล็อกแบบ MUST NOT)
- กรณีขอบเขต: ทดสอบเกณฑ์ เช่น (Exactly $10,000), สถานะว่าง ("no prior violations"), และกรณีเกินพอ
การตรวจสอบรอบสอง: ขั้นตอนรีวิวโดยเจตนา
เพิ่ม "รอบสอง" ที่ประเมินคำตอบครั้งแรกอีกครั้ง นี่อาจเป็นการเรียกโมเดลอีกครั้งหรือตรวจสอบด้วย prompt แบบ validator ที่เน้นการตรวจความสอดคล้อง ไม่ใช่ความสร้างสรรค์
รูปแบบง่าย ๆ: รอบแรกผลิตการตัดสินใจ + เหตุผล; รอบสองคืน valid หรือรายการโครงสร้างของความล้มเหลว (ฟิลด์หาย ข้อจำกัดถูกละเมิด การตีความกฎไม่ชัด)
การบันทึก: ทำให้การตัดสินใจตรวจสอบได้
สำหรับการตัดสินใจทุกครั้ง ให้บันทึกอินพุตที่ใช้ เวอร์ชันกฎ/นโยบาย และผลการตรวจสอบ (รวมรอบสอง) เมื่อเกิดปัญหา จะช่วยให้คุณจำลองสภาวะเดิม แก้แม็ปกฎ และยืนยันการแก้ไขได้—โดยไม่ต้องเดาว่าโมเดล "คงหมายความว่า" อะไร
การทดสอบและมอนิเตอริงเพื่อความเชื่อถือได้ของกฎและเวิร์กโฟลว์
การทดสอบฟีเจอร์ที่ใช้ LLM กับกฎและเวิร์กโฟลว์ไม่ใช่แค่ "มันสร้างอะไรไหม?" แต่คือ "มันตัดสินใจเหมือนมนุษย์ที่รอบคอบในเหตุผลที่ถูกต้องเสมอไหม?" ข้อดีคือคุณสามารถทดสอบด้วยวินัยเดียวกับตรรกะการตัดสินใจแบบเดิม
ยูนิตเทสต์สำหรับกฎธุรกิจ (เช็กเล็ก ๆ ที่คาดการณ์ได้)
มองแต่ละกฎเหมือนฟังก์ชัน: ให้ค่าเข้าแล้วควรคืนผลลัพธ์ที่คาด
ตัวอย่าง หากมีกฎคืนเงินว่า “คืนเงินได้ภายใน 30 วันสำหรับสินค้าที่ไม่ได้เปิด” ให้กรณีทดสอบ:
- อายุคำสั่ง = 10 วัน, unopened = true → approve
- อายุคำสั่ง = 10 วัน, unopened = false → deny
- อายุคำสั่ง = 45 วัน, unopened = true → deny
- กรณีขอบ: exactly 30 days, ขาดฟิลด์ "unopened", สัญญาณขัดแย้ง
ยูนิตเทสต์เหล่านี้จับข้อผิดพลาด off-by-one ฟิลด์หาย และพฤติกรรม "ช่วยเติม" ของโมเดล
เทสต์สถานการณ์สำหรับเวิร์กโฟลว์ (เส้นทางหลายขั้นตอน มีเวลา)
เวิร์กโฟลว์พังเมื่อสถานะไม่สอดคล้องข้ามขั้นตอน เทสต์สถานการณ์จำลองเส้นทางจริง:
- การทดสอบเส้นทาง: ส่งคำขอ → ขอเอกสาร → ได้เอกสาร → ตัดสินใจ
- ขอบตามเวลา: "หากไม่มีตอบใน 7 วัน ส่งเตือน" "หากผ่าน 30 วัน ปิดเคส"
- การแยกสาขา: ลูกค้าทวงสิทธิ์, ขอข้อยกเว้นนโยบาย, ตรวจพบเคสซ้ำ
เป้าหมายคือยืนยันว่าโมเดลเคารพสถานะปัจจุบันและทำการเปลี่ยนแปลงที่อนุญาตเท่านั้น
สร้าง "gold set" ของเคสที่ทราบผลดี
สร้างชุดข้อมูลคิวเรตจากตัวอย่างจริงที่ทำให้เป็นนิรนาม พร้อมผลลัพธ์ที่ตกลงกัน (และเหตุผลสั้น ๆ) เก็บเวอร์ชันไว้ และทบทวนเมื่อกฎเปลี่ยน ชุด gold เล็ก ๆ (แม้ 100–500 เคส) ก็ทรงพลังเพราะสะท้อนความเป็นจริงที่ยุ่งเหยิง—ข้อมูลหาย คำพูดแปลก ๆ การตัดสินใจขอบ
มอนิเตอริงในโปรดักชัน (จับการ drift ก่อนลูกค้าเห็น)
ติดตามการแจกแจงการตัดสินใจและสัญญาณคุณภาพเมื่อเวลาผ่านไป:
- Drift: อัตราอนุมัติ/ปฏิเสธเปลี่ยนโดยไม่มีการอัปเดตนโยบาย
- การพุ่งใน
needs_reviewหรือการส่งต่อหามนุษย์ (มักเป็นปัญหา prompt, retrieval, หรือ upstream data) - คลัสเตอร์ข้อผิดพลาดตามผลิตภัณฑ์ ภูมิภาค หรือหมวดนโยบาย
จับการมอนิเตอริงกับการย้อนกลับที่ปลอดภัย: เก็บ prompt/แพ็กกฎก่อนหน้า เปิดฟีเจอร์ทีละน้อย ใช้ feature flag และพร้อมย้อนกลับเมื่อเมตริกถดถอย สำหรับ playbook การดำเนินงานและการปล่อยดู /blog/validation-strategies
Koder.ai อยู่ใน pipeline นี้อย่างไร
ย้อนกลับอย่างมั่นใจ
ปกป้องการปล่อยด้วย snapshot และย้อนกลับเมื่อกฎหรือ prompt เปลี่ยน
ถ้าคุณจะนำแนวทางข้างต้นไปใช้ ส่วนใหญ่คุณจะสร้างระบบรอบ ๆ โมเดล: ที่เก็บสถานะ การเรียกเครื่องมือ การดึงข้อมูล การตรวจสคีมา และตัวจัดการเวิร์กโฟลว์ Koder.ai เป็นวิธีปฏิบัติที่ช่วยให้ prototype และส่งมอบผู้ช่วยแบบมีเวิร์กโฟลว์ได้เร็วขึ้น: คุณสามารถอธิบายเวิร์กโฟลว์ในแชท สร้างเว็บแอป (React) พร้อมบริการแบ็กเอนด์ (Go กับ PostgreSQL) และวนปรับอย่างปลอดภัยด้วยสแนปช็อตและการย้อนกลับ
สิ่งนี้สำคัญเพราะ "ราวกันตก" มักอยู่ในแอปมากกว่าใน prompt:
- โหมดวางแผน ช่วยออกแบบโฟลว์ (สถานะ การเปลี่ยนแปลงที่อนุญาต เส้นทางยกระดับ) ก่อนดำเนินการ
- การบังคับสคีมา สามารถใช้บังคับที่ API boundary ทำให้คุณรับเฉพาะการตัดสินใจที่ parse ได้
- ฮุคเครื่องมือ (อ่าน DB, ดึงนโยบาย, เครื่องคิดเลข, อัปเดตตั๋ว) สามารถทำเป็น endpoint ชัดเจน ทำให้ "ดึงหลักฐานก่อน ตัดสินทีหลัง" เป็นค่าตั้งต้น
- การส่งออกซอร์สโค้ด ช่วยให้คุณไม่ถูกล็อคเมื่อโปรโตไทป์กลายเป็นงานจริง
ขีดจำกัด การใช้งานอย่างปลอดภัย และเมื่อใดควรให้มนุษย์เข้ามา
LLM ทำงานได้ค่อนข้างดีสำหรับนโยบายทั่วไป แต่ไม่ใช่เครื่องยนต์กฎเชิงกำหนด จงมองพวกมันเป็นผู้ช่วยการตัดสินใจที่ต้องมีราวกันตก ไม่ใช่อำนาจสุดท้าย
จุดที่ LLM มักล้มเหลว
ความล้มเหลวสามแบบปรากฏซ้ำ ๆ ในเวิร์กโฟลว์ที่มีกฎ:
- ข้อยกเว้นหายากและกรณีมุม: ถ้าข้อยกเว้นเกิดปีละครั้ง มันอาจไม่ค่อยอยู่ในข้อมูลฝึกและง่ายต่อการพลาด เว้นแต่จะส่งใน prompt หรือดึงมาจากเอกสารนโยบาย
- คอนเท็กซ์ยาวและข้อจำกัดที่ "ฝัง" กัน: เมื่อรายละเอียดสำคัญกระจายอยู่หลายหน้า โมเดลอาจให้น้ำหนักกับข้อความล่าสุดหรือเด่นสุดมากเกินไปและละเลยข้อจำกัดก่อนหน้า
- ความแม่นยำเชิงตัวเลขและการคำนวณเข้มงวด: รวมถึงยอดรวม การคำนวณสัดส่วน เกณฑ์ และการปัด ตัวเลขอาจผิด ให้ใช้เครื่องมือคำนวณและบังคับให้โมเดลอ้างตัวเลขที่ใช้
เมื่อใดควรบังคับให้มีการตรวจโดยมนุษย์
เพิ่มการรีวิวโดยมนุษย์เมื่อ:
- ผลลัพธ์มี ความเสี่ยงสูง (การเคลื่อนไหวเงิน ปฏิบัติตาม กฎหมาย ความปลอดภัย ข้อผูกมัดทางกฎหมาย เครดิตลูกค้า)
- โมเดลส่งสัญญาณ ความไม่มั่นใจ (ขอให้เดาข้อมูลที่หาย ถามหาแหล่งอ้างอิงไม่ได้ หรือให้เหตุผลขัดแย้ง)
- เคส ใหม่ (ผลิตภัณฑ์ใหม่ ภูมิภาคใหม่ นโยบายเพิ่งเปลี่ยน) หรือมีความอ่อนไหวเป็นพิเศษ
เส้นทางการยกระดับที่ทำให้เรื่องเดินต่อ
แทนที่จะปล่อยให้โมเดล "คิดขึ้น" ให้กำหนดขั้นตอนต่อไปชัด:
- ถามคำถามชี้แจง (วันที่หาย ระดับลูกค้า ภูมิภาค สถานะการอนุมัติ)
- ส่งต่อให้เอเยนต์ พร้อมข้อเท็จจริงสกัด ข้อเสนอการตัดสินใจ และการอ้างอิง
- สร้างตั๋ว เมื่อกฎคลุมเครือหรือขัดแย้ง เพื่อให้แก้ที่ต้นทาง (และถูกดึงอัตโนมัติภายหลัง)
กรอบการนำไปใช้แบบง่าย
ใช้ LLM ในเวิร์กโฟลว์ที่มีนโยบายหนักเมื่อคุณตอบ "ใช่" ต่อคำถามส่วนใหญ่เหล่านี้:
- เราสามารถ ยึด การตัดสินใจกับข้อความนโยบายที่อนุมัติหรือข้อมูลระบบได้หรือไม่?
- เราสามารถ จำกัดผลลัพธ์ (สคีมา, การกระทำที่อนุญาต, การอ้างอิงที่จำเป็น) ได้หรือไม่?
- เราสามารถ ตรวจสอบ (เช็ค, เกณฑ์, ยูนิตเทสต์, การสุ่มตัวอย่าง) ก่อนดำเนินการได้หรือไม่?
- เรามี เส้นทางยกระดับมนุษย์ สำหรับเคสเสี่ยงหรือไม่แน่นอนหรือไม่?
หากไม่ ให้เก็บ LLM ไว้ในบทบาทร่าง/ผู้ช่วยจนกว่าจะมีการควบคุมเหล่านั้น