18 ส.ค. 2568·3 นาที
LLVM ของ Chris Lattner: เครื่องยนต์เงียบเบื้องหลังเครื่องมือสมัยใหม่
เรียนรู้ว่า LLVM ของ Chris Lattner กลายเป็นแพลตฟอร์มคอมไพเลอร์แบบโมดูลาร์ที่อยู่เบื้องหลังภาษาและเครื่องมือ—ช่วยเรื่องการปรับแต่ง การวินิจฉัยที่ดีขึ้น และการสร้างที่เร็วขึ้น
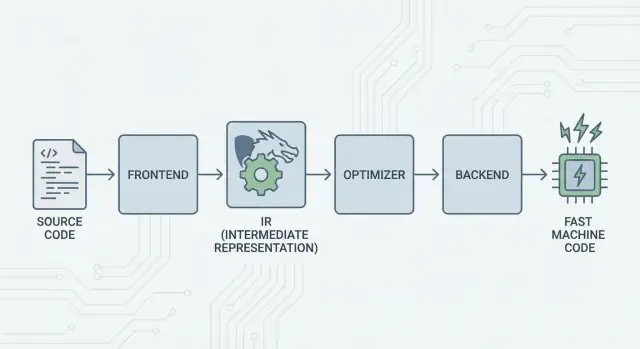
LLVM คืออะไร อธิบายแบบง่ายๆ
ควรคิดว่า LLVM เป็น “ห้องเครื่อง” ที่คอมไพเลอร์และเครื่องมือสำหรับนักพัฒนาหลายตัวใช้ร่วมกัน
เมื่อคุณเขียนโค้ดด้วยภาษาที่เป็นที่นิยม เช่น C, Swift หรือ Rust จะต้องมีสิ่งหนึ่งแปลโค้ดนั้นเป็นคำสั่งที่ CPU สามารถรันได้ คอมไพเลอร์แบบดั้งเดิมมักจะสร้างทุกส่วนของสายการแปลงนั้นขึ้นมาเองทั้งหมด LLVM เลือกแนวทางต่างออกไป: มันให้แกนกลางคุณภาพสูงที่นำกลับมาใช้ใหม่ได้ ซึ่งจัดการส่วนที่ยากและมีค่าใช้จ่ายสูง—การปรับแต่ง ประเมินวิเคราะห์ และการสร้างโค้ดเครื่องสำหรับโปรเซสเซอร์ต่างๆ
พื้นฐานร่วมสำหรับหลายภาษา
LLVM ไม่ใช่คอมไพเลอร์เดียวที่คุณมักจะ “ใช้งานโดยตรง” มันคือ โครงสร้างพื้นฐานคอมไพเลอร์: บล็อกก่อสร้างที่ทีมภาษาแต่ละทีมสามารถประกอบเป็นชุดเครื่องมือ ทีมหนึ่งมุ่งที่ไวยากรณ์ ความหมาย และฟีเจอร์ฝั่งผู้พัฒนา แล้วส่งงานหนักให้ LLVM ทำต่อ
พื้นฐานร่วมนี้เป็นเหตุผลสำคัญที่ภาษาใหม่ๆ สามารถส่งมอบ toolchain ที่รวดเร็วและปลอดภัยได้โดยไม่ต้องทำซ้ำงานคอมไพเลอร์ที่มีมายาวนาน
ทำไมมันสำคัญแม้คุณจะไม่ใช่คนทำคอมไพเลอร์
LLVM ปรากฏตัวในการใช้งานของนักพัฒนาในชีวิตประจำวัน:
- ความเร็ว: มันสามารถเปลี่ยนโค้ดระดับสูงให้เป็นโค้ดเครื่องที่มีประสิทธิภาพข้ามแพลตฟอร์มได้
- ข้อผิดพลาดและการดีบักที่ดีขึ้น: ระบบนิเวศรอบ LLVM ทำให้เกิดการวินิจฉัยที่ลึกขึ้นและเครื่องมือที่ดีกว่า
- มากกว่าแค่การคอมไพล์: การวิเคราะห์แบบสแตติก, sanitizers, การเก็บข้อมูล coverage และเครื่องมือช่วยนักพัฒนารายอื่นมักจะสร้างบนตัวแทนกลางและไลบรารีเดียวกัน
บทความนี้จะเป็น (และจะไม่เป็น)
นี่คือการพาทัวร์แนวคิดที่ Chris Lattner เริ่มต้น: โครงสร้างของ LLVM ทำงานอย่างไร ทำไมชั้นกลางจึงสำคัญ และมันช่วยให้เกิดการปรับแต่งและรองรับหลายแพลตฟอร์มได้อย่างไร มันไม่ใช่ตำราทางทฤษฎี—เราจะเน้นสัญชาตญาณและผลกระทบในโลกจริงแทนทฤษฎีอย่างเป็นทางการ
วิสัยทัศน์ดั้งเดิมของ Chris Lattner
Chris Lattner เป็นนักวิทยาการคอมพิวเตอร์และวิศวกร ที่ในฐานะนิสิตบัณฑิตในต้นยุค 2000 เริ่มสร้าง LLVM ขึ้นมาจากความเบื่อหน่ายเชิงปฏิบัติ: เทคโนโลยีคอมไพเลอร์ทรงพลังแต่ยากจะนำกลับมาใช้ใหม่ หากคุณต้องการภาษาใหม่ การปรับแต่งที่ดีกว่า หรือการรองรับ CPU ใหม่ คุณมักจะต้องปรับแต่งคอมไพเลอร์แบบรวมศูนย์ที่ส่วนต่างๆ พัวพันกันทุกการเปลี่ยนแปลง
ปัญหาที่เขาต้องการแก้
ในตอนนั้น คอมไพเลอร์หลายตัวถูกสร้างเหมือนเครื่องเดียวขนาดใหญ่: ส่วนที่เข้าใจภาษา ส่วนที่ปรับแต่ง และส่วนที่สร้างโค้ดเครื่องถูกร้อยเรียงเข้าด้วยกัน ทำให้ปรับเปลี่ยนยาก
เป้าหมายของ Lattner ไม่ใช่ “คอมไพเลอร์สำหรับภาษาเดียว” แต่เป็นพื้นฐานร่วมที่ขับเคลื่อนหลายภาษาและหลายเครื่องมือ—โดยไม่ให้ทุกคนต้องเขียนซ้ำชิ้นซับซ้อนเดิมๆ การเดิมพันคือถ้าคุณมาตรฐานตรงกลางของ pipeline ได้ ขอบด้านนอกจะนวัตกรรมได้เร็วขึ้น
ทำไม “โครงสร้างพื้นฐานแบบโมดูลาร์” จึงเป็นความคิดใหม่
การเปลี่ยนแปลงสำคัญคือการมองการคอมไพล์เป็นชุดบล็อกที่แยกจากกันได้และมีขอบเขตชัดเจน ในโลกโมดูลาร์:
- ทีมภาษาจะโฟกัสที่การพาร์สและฟีเจอร์ฝั่งผู้พัฒนา
- ทีมปรับแต่งสามารถปรับปรุงประสิทธิภาพเพียงครั้งเดียวและแชร์ได้กว้าง
- การรองรับฮาร์ดแวร์สามารถเพิ่มได้โดยไม่ต้องออกแบบใหม่ทั้งหมดในส่วนต้นทาง
การแยกแบบนี้ฟังดูชัดเจนตอนนี้ แต่กลับสวนทางกับรูปแบบการพัฒนาคอมไพเลอร์เชิงผลิตที่มีอยู่
เปิดซอร์ส ถูกออกแบบให้คนอื่นใช้งาน
LLVM ถูกปล่อยเป็นโอเพนซอร์สตั้งแต่ต้น ซึ่งสำคัญเพราะโครงสร้างพื้นฐานร่วมใช้ได้ก็ต่อเมื่อหลายทีมสามารถเชื่อถือ ตรวจสอบ และขยายมันได้ ตามเวลา มหาวิทยาลัย บริษัท และผู้ร่วมพัฒนาส่งเสริมโปรเจกต์โดยเพิ่ม targets แก้กรณีมุม ปรับปรุงประสิทธิภาพ และสร้างเครื่องมือใหม่ๆ รอบมัน
มุมมองชุมชนนี้ไม่ใช่แค่ความเอื้อเฟื้อ—มันเป็นส่วนหนึ่งของการออกแบบ: ทำให้แกนกลางมีประโยชน์กว้างๆ แล้วมันจะมีมูลค่าพอให้รักษาร่วมกัน
แนวคิดใหญ่: Frontends, แกนกลางร่วม, และ Backends
ไอเดียหลักของ LLVM ง่าย: แยกคอมไพเลอร์เป็นสามส่วนใหญ่เพื่อให้หลายภาษาใช้ความยากยากร่วมกันได้
1) Frontends: “โปรแกรมเมอร์ตั้งใจจะทำอะไร?”
Frontend เข้าใจภาษาโปรแกรมเฉพาะ มันอ่านซอร์สโค้ด ตรวจกฎ (ไวยากรณ์และชนิดข้อมูล) และแปลงเป็นตัวแทนที่มีโครงสร้าง
ประเด็นสำคัญ: frontend ไม่จำเป็นต้องรู้ทุกรายละเอียดของ CPU งานของมันคือแปลงแนวคิดภาษาต่างๆ—ฟังก์ชัน ลูป ตัวแปร—เป็นสิ่งที่สากลมากขึ้น
2) แกนกลางร่วม: แก้ปัญหา N×M
แบบดั้งเดิม การสร้างคอมไพเลอร์หมายถึงทำงานเดิมซ้ำหลายครั้ง:
- กับ N ภาษาระดับสูง และ M เป้าหมายชิป คุณจะมี N×M การผสมที่ต้องรองรับ
LLVM ลดตรงนี้เป็น:
- N frontends ที่แปลงเป็นรูปแบบร่วม
- M backends ที่แปลงจากรูปแบบร่วมไปเป็นโค้ดเครื่อง
“รูปแบบร่วม” นี้คือศูนย์กลางของ LLVM: pipeline ร่วมที่การปรับแต่งและการวิเคราะห์อาศัยอยู่ การปรับปรุงตรงกลาง (เช่น การเพิ่ม optimizer หรือข้อมูลดีบัก) จะเป็นประโยชน์กับ หลายภาษา พร้อมกัน แทนที่จะต้องทำซ้ำในทุกคอมไพเลอร์
3) Backends: “จะทำให้รันเร็วบน CPU นั้นได้อย่างไร?”
Backend รับตัวแทนร่วมแล้วผลิตเอาต์พุตที่เป็นเครื่องแบบเฉพาะ: คำสั่งสำหรับ x86, ARM ฯลฯ ที่นี่รายละเอียดอย่างรีจิสเตอร์ การเรียกฟังก์ชัน และการเลือกคำสั่งมีความสำคัญ
ภาพที่เข้าใจง่ายของ pipeline
คิดว่าการคอมไพล์เหมือนเส้นทางการเดินทาง:
- ซอร์สโค้ด เริ่มต้นในประเทศของภาษาเฉพาะ (frontend)
- ข้ามพรมแดนเข้าสู่ “ภาษากลาง” มาตรฐาน (แกนกลางของ LLVM และ passes)
- แล้วเดินทางด้วยระบบท้องถิ่นไปยังเมืองปลายทางเฉพาะ (backend สำหรับเครื่องเป้าหมายของคุณ)
ผลลัพธ์คือ toolchain แบบโมดูลาร์: ภาษาโฟกัสที่การแสดงความคิดให้ชัดเจน ขณะที่แกนกลางของ LLVM โฟกัสกับการทำให้ความคิดเหล่านั้นรันได้อย่างมีประสิทธิภาพข้ามแพลตฟอร์มต่างๆ
LLVM IR: ชั้นกลางที่ทำให้เกิดการนำกลับมาใช้ใหม่
LLVM IR (Intermediate Representation) คือ “ภาษากลาง” ระหว่างภาษาโปรแกรมและโค้ดเครื่องที่ CPU รัน
Frontend ของคอมไพเลอร์ (เช่น Clang สำหรับ C/C++) แปลงซอร์สโค้ดของคุณเป็นรูปแบบร่วมนี้ แล้ว optimizer และตัวสร้างโค้ดของ LLVM ทำงานกับ IR ไม่ใช่กับภาษาต้นฉบับ สุดท้าย backend แปลง IR เป็นคำสั่งสำหรับเป้าหมายเฉพาะ (x86, ARM ฯลฯ)
ภาษากลางระหว่างเครื่องมือและ CPU
คิดว่า LLVM IR เป็นสะพานออกแบบมาอย่างระมัดระวัง:
- ด้านบน: หลายภาษาต้นทางสามารถเชื่อมต่อได้ (C, C++, Rust, Swift, Julia ฯลฯ)
- ด้านล่าง: หลาย CPU สามารถเป็นเป้าหมาย
- ตรงกลาง: เครื่องมือวิเคราะห์และการปรับแต่งชุดเดียวกันนำกลับมาใช้ใหม่ได้
นี่คือเหตุผลที่คนมักเรียก LLVM ว่าเป็น “โครงสร้างพื้นฐานคอมไพเลอร์” มากกว่าเป็น “คอมไพเลอร์” เพียงตัวเดียว IR คือสัญญาร่วมที่ทำให้โครงสร้างพื้นฐานนั้นนำกลับมาใช้ได้
ทำไม IR ถึงช่วยประหยัดงานของทุกคน
เมื่อโค้ดอยู่ใน LLVM IR ส่วนใหญ่ของการปรับแต่งไม่จำเป็นต้องรู้อะไรมากว่ามันเริ่มจาก C++ template, Rust iterator หรือ Swift generic มันสนใจแนวคิดสากลเช่น:
- “ค่านี้เป็นค่าคงที่”
- “การคำนวณนี้ซ้ำ; เราใช้ผลลัพธ์ซ้ำได้ไหม?”
- “การโหลดหน่วยความจำนี้สามารถย้ายหรือลบได้อย่างปลอดภัยไหม?”
ดังนั้นทีมภาษาไม่ต้องสร้าง (และรักษา) optimizer ทั้งหมดเอง พวกเขาโฟกัสที่ frontend—การพาร์ส การตรวจชนิด กฎเฉพาะภาษา—แล้วส่งต่อให้ LLVM ทำงานหนักต่อ
มัน “หน้าตา” อย่างไรเชิงแนวคิด
LLVM IR ต่ำระดับพอที่จะจับกับโค้ดเครื่องได้อย่างชัดเจน แต่ก็มีโครงสร้างพอให้วิเคราะห์ได้ แนวคิดสร้างจากคำสั่งง่ายๆ (add, compare, load/store), การไหลควบคุมชัดเจน (branch) และค่าว่าชนิดชัดเจน—คล้ายๆ assembly ที่ออกแบบมาสำหรับคอมไพเลอร์ ไม่ใช่สิ่งที่คนมักจะเขียนโดยตรง
การปรับแต่งทำงานอย่างไร (ไม่ต้องคำนวณเชิงคณิต)
เมื่อคนได้ยินคำว่า “การปรับแต่งคอมไพเลอร์” มักคิดถึงทริคลึกลับ ใน LLVM ส่วนใหญ่การปรับแต่งเป็น การเขียนโปรแกรมซ้ำอย่างปลอดภัยและเป็นระบบ—การเปลี่ยนแปลงที่รักษาเจตนาของโปรแกรมไว้ แต่ทำให้มันเร็วขึ้น (หรือเล็กลง)
คิดว่ามันเหมือนการแก้ไข ไม่ใช่การประดิษฐ์
LLVM รับโค้ดของคุณ (ในรูปแบบ IR) แล้วนำการปรับปรุงเล็กๆ มาทำซ้ำๆ เหมือนการขัดเกลา:
- ลบงานที่ซ้ำกัน: ถ้าค่าถูกคำนวณสองครั้งและไม่มีอะไรเปลี่ยนระหว่างนั้น LLVM อาจคำนวณครั้งเดียวแล้วใช้ซ้ำ
- ทำให้ตรรกะที่ชัดเจนเรียบง่าย: นิพจน์คงที่สามารถถูกพับล่วงหน้า (เช่น เปลี่ยน
3 * 4เป็น12) ทำให้ CPU ทำงานน้อยลงตอนรัน - ปรับแต่งลูป: passes เกี่ยวกับลูปสามารถลดการตรวจซ้ำ ย้ายงานที่ไม่เปลี่ยนแปลงออกจากลูป หรือจดจำรูปแบบที่รันได้มีประสิทธิภาพกว่า
การเปลี่ยนเหล่านี้คำนึงถึงความปลอดภัยเป็นหลัก pass จะทำการ rewrite ก็ต่อเมื่อพิสูจน์ได้ว่าการเปลี่ยนจะไม่เปลี่ยนความหมายของโปรแกรม
ตัวอย่างที่เข้าใจได้
ถ้าโปรแกรมของคุณทำแนวคิดนี้:
- อ่านค่าการตั้งค่าซ้ำๆ ทุกการวนลูป
- ทำการคำนวณเดียวกันกับอินพุตเดียวกันหลายที่
- ตรวจเงื่อนไขที่ในบริบทใดบริบทหนึ่งเป็นจริง/เท็จเสมอ
…LLVM จะพยายามเปลี่ยนเป็น “ทำครั้งเดียว” “ใช้ผลซ้ำ” และ “ลบสาขาที่ตายแล้ว” มันไม่ใช่เวทมนตร์ แต่เป็นการจัดระเบียบ
การแลกเปลี่ยนจริง: เวลาแปลกับเวลาเรียกใช้งาน
การปรับแต่งไม่ได้ฟรี: การวิเคราะห์มากขึ้นและ passes มากขึ้นมักหมายถึง เวลาแปลที่ช้าลง แม้โปรแกรมสุดท้ายจะรันเร็วขึ้น นั่นคือเหตุผลที่ toolchains มีระดับเช่น “ปรับแต่งเล็กน้อย” กับ “ปรับแต่งอย่างมาก”
โปรไฟล์ช่วยเรื่องนี้ได้ ด้วย profile-guided optimization (PGO) คุณรันโปรแกรม เก็บข้อมูลการใช้งานจริง แล้วคอมไพล์ใหม่เพื่อให้ LLVM ใส่ใจเส้นทางที่สำคัญจริงๆ—ทำให้การแลกเปลี่ยนเป็นไปอย่างคาดเดาได้มากขึ้น
Backends: ถึงหลาย CPU โดยไม่ต้องเขียนซ้ำทุกอย่าง
สร้างจากการแชท
เปลี่ยนไอเดียให้กลายเป็นแอปที่ใช้งานได้ด้วยการแชทอย่างง่าย โดยไม่ต้องตั้งค่าเครื่องมือพัฒนา
คอมไพเลอร์มีงานสองอย่างที่ต่างกันมาก ก่อนอื่นต้องเข้าใจซอร์สโค้ด และที่สองต้องผลิตโค้ดเครื่องที่ CPU เฉพาะจะรัน Backends ของ LLVM มุ่งที่งานหลัง
Backend ทำอะไรจริงๆ
คิดว่า LLVM IR เป็น “สูตรสากล” ว่าโปรแกรมควรทำอะไร Backend แปลงสูตรนั้นเป็นคำสั่งจริงสำหรับตระกูลโปรเซสเซอร์เฉพาะ—x86-64 สำหรับเดสก์ท็อปและเซิร์ฟเวอร์ ARM64 สำหรับโทรศัพท์และโน้ตบุ๊กใหม่ หรือเป้าหมายเฉพาะอย่าง WebAssembly
โดย concrète backend รับผิดชอบ:
- การเลือกคำสั่ง: แม็ปปฏิบัติการ IR ไปเป็นคำสั่ง CPU จริง
- การจัดสรรรีจิสเตอร์: เลือกว่าค่าไหนอาศัยอยู่ในรีจิสเตอร์เร็วหรือในหน่วยความจำ
- การจัดลำดับ: จัดคำสั่งให้ CPU รันได้มีประสิทธิภาพ
- เอาต์พุตเป็น assembly/object: ออกโค้ดที่ linker และ OS เข้าใจ
ทำไมโครงสร้างพื้นฐานร่วมทำให้รองรับฮาร์ดแวร์ใหม่ง่ายขึ้น
หากไม่มีแกนกลางร่วม ทุกภาษาจะต้องทำซ้ำทั้งหมดนี้สำหรับทุก CPU ที่ต้องการรองรับ—งานมหาศาลและภาระการบำรุงรักษาต่อเนื่อง
LLVM พลิกสถานการณ์: frontends (เช่น Clang) ผลิต LLVM IR ครั้งเดียว และ backends จัดการ “ระยะสุดท้าย” ต่อเป้าหมาย การเพิ่มการรองรับ CPU ใหม่โดยทั่วไปหมายถึงเขียน backend ครั้งเดียว (หรือขยายอันที่มีอยู่) แทนที่จะเขียนใหม่ทุกคอมไพเลอร์
ความพกพาสำหรับทีมที่ส่งมอบบนหลายแพลตฟอร์ม
สำหรับโปรเจกต์ที่ต้องรันบน Windows/macOS/Linux บน x86 และ ARM หรือแม้แต่ในเบราว์เซอร์ โมเดล backend ของ LLVM คือข้อได้เปรียบเชิงปฏิบัติ คุณสามารถเก็บฐานโค้ดเดียวและ pipeline การสร้างหนึ่งชุด แล้วเป้าหมายโดยเลือก backend ต่างกัน (หรือ cross-compiling)
ความพกพานี้คือเหตุผลที่ LLVM ปรากฏอยู่ในทุกที่: มันไม่ใช่แค่เรื่องความเร็ว แต่เป็นการหลีกเลี่ยงงานคอมไพเลอร์เฉพาะแพลตฟอร์มซ้ำซ้อนที่ชะลอทีม
Clang: ที่นักพัฒนาหลายคนสัมผัส LLVM เป็นครั้งแรก
Clang คือ frontend สำหรับ C, C++ และ Objective-C ที่เชื่อมต่อกับ LLVM หาก LLVM เป็นเครื่องยนต์ร่วมที่ปรับแต่งและสร้างโค้ด เครื่องมือ Clang คือส่วนที่อ่านซอร์ส เข้าใจกฎของภาษา และแปลงสิ่งที่คุณเขียนเป็นรูปแบบที่ LLVM ทำงานได้
ทำไม Clang ได้รับความสนใจ
นักพัฒนาหลายคนไม่ค้นพบ LLVM ผ่านงานวิจัยคอมไพเลอร์ แต่เจอมันครั้งแรกเมื่อเปลี่ยนคอมไพเลอร์แล้วฟีดแบ็กดีขึ้นอย่างเห็นได้ชัด
การรายงานข้อผิดพลาดของ Clang เป็นที่เลื่องลือว่าอ่านง่ายและชัดเจน แทนที่จะเป็นข้อผิดพลาดคลุมเครือ มักชี้โทเค็นที่เกิดปัญหา แสดงบรรทัดที่เกี่ยวข้อง และอธิบายสิ่งที่คาดหวัง ซึ่งมีความหมายในงานประจำเพราะวงจร “คอมไพล์ แก้ไข ทำซ้ำ” จะน้อยลงของความหงุดหงิด
Clang ยังเปิดอินเทอร์เฟซที่สะอาดและมีเอกสาร (เช่น libclang และระบบเครื่องมือของ Clang) ทำให้ editors, IDE และเครื่องมืออื่นๆ บูรณาการความเข้าใจภาษาลึกได้โดยไม่ต้องเขียน parser C/C++ ขึ้นใหม่
มันแสดงผลในเวิร์กโฟลว์ประจำวันอย่างไร
เมื่อเครื่องมือสามารถพาร์สและวิเคราะห์โค้ดได้อย่างน่าเชื่อถือ คุณจะเริ่มได้ฟีเจอร์ที่รู้สึกเหมือนทำงานกับโปรแกรมที่มีโครงสร้าง ไม่ใช่แค่แก้ข้อความ:
- การนำทางโค้ดที่แม่นยำ (“go to definition,” “find references”) แม้ในโปรเจกต์ C++ ขนาดใหญ่ที่ใช้แมโครเยอะ
- รองรับการ refactor ที่เข้าใจสัญลักษณ์และสโคป ไม่ใช่แค่ search-and-replace
- คำแนะนำอินไลน์และการแก้ไขด่วนที่ขับเคลื่อนด้วยข้อมูลไวยากรณ์และชนิดจริง
นี่คือเหตุผลที่ Clang มักเป็นจุดสัมผัสแรกของ LLVM: มันคือที่มาของการปรับปรุงประสบการณ์นักพัฒนาในทางปฏิบัติ แม้คุณจะไม่คิดถึง LLVM IR หรือ backends ก็ตาม คุณก็ยังได้ประโยชน์เมื่อ autocomplete ใน editor ฉลาดขึ้น การตรวจแบบสแตติกแม่นกว่า และข้อผิดพลาดในการคอมไพล์แก้ไขได้ง่ายขึ้น
ทำไมหลายภาษาสมัยใหม่เลือกใช้ LLVM
LLVM ดึงดูดทีมภาษาด้วยเหตุผลง่ายๆ: มันให้คุณโฟกัสที่ ภาษา แทนที่จะเสียเวลาเป็นปีๆ สร้างคอมไพเลอร์ที่ปรับแต่งได้เต็มรูปแบบ
เร็วขึ้นสู่ตลาด
การสร้างภาษาใหม่ต้องทำการพาร์ส ตรวจชนิด รายงานข้อผิดพลาด จัดการแพ็กเกจ เอกสาร และชุมชน ถ้าคุณยังต้องสร้าง optimizer, ตัวสร้างโค้ด และการรองรับแพลตฟอร์มจากศูนย์ เวลาก็เลื่อนไป—บางครั้งนานเป็นปี
LLVM ให้แกนกลางที่พร้อมใช้: การจัดการรีจิสเตอร์ การเลือกคำสั่ง passes ปรับแต่งที่เติบโตแล้ว และ targets สำหรับ CPU ยอดนิยม ทีมสามารถเสียบ frontend ที่แปลงภาษาลงเป็น LLVM IR แล้วพึ่งพา pipeline ที่มีอยู่เพื่อสร้างโค้ดเนทีฟสำหรับ macOS, Linux และ Windows
ประสิทธิภาพสูงโดยไม่ต้อง “ฮีโร่”
optimizer และ backends ของ LLVM เป็นผลจากวิศวกรรมระยะยาวและการทดสอบจริงในโลก นั่นแปลว่าฐานประสิทธิภาพที่แข็งแรงสำหรับภาษาที่นำไปใช้—มักจะดีพอในช่วงเริ่มต้น และสามารถดีขึ้นได้เมื่อ LLVM ดีขึ้น
นี่คือเหตุผลที่หลายภาษาที่รู้จักใช้มัน:
- Swift ใช้ LLVM เพื่อสร้างไบนารีที่ปรับแต่งสูงบนแพลตฟอร์มของ Apple
- Rust พึ่งพา LLVM สำหรับการสร้างโค้ดและ targets หลายสถาปัตยกรรม
- Julia ใช้ LLVM เพื่อเปิดใช้งานโค้ดตัวเลขที่เร็ว รวมถึงการคอมไพล์ขณะรันสำหรับงานเฉพาะ
ไม่ใช่ทุกภาษาที่ต้องการ LLVM
การเลือก LLVM คือการแลกเปลี่ยน ไม่ใช่ข้อบังคับ บางภาษาให้ความสำคัญกับไบนารีขนาดเล็กมาก เวลาแปลที่เร็วมาก หรือการควบคุม toolchain ทั้งหมดอย่างเข้มงวด บางระบบมีคอมไพเลอร์เดิมอยู่แล้ว (เช่น ระบบที่ใช้ GCC) หรือต้องการ backend ที่เรียบง่ายกว่า
LLVM เป็นตัวเลือกที่นิยมนั่นเพราะมันเป็นค่าเริ่มต้นที่แข็งแกร่ง—ไม่ใช่ว่ามันเป็นหนทางเดียวที่ถูกต้อง
JIT และการคอมไพล์ขณะรัน: วงจรฟีดแบ็กที่เร็ว
เปลี่ยนการแชร์เป็นเครดิต
รับเครดิตเมื่อแชร์สิ่งที่คุณสร้างหรือชวนผู้อื่นลองใช้ Koder.ai
“Just-in-time” (JIT) คอมไพล์คือการคอมไพล์ในขณะที่รัน แทนที่จะคอมไพล์ทั้งหมดล่วงหน้า JIT รอจนส่วนของโค้ดนั้นจำเป็น แล้วคอมไพล์ส่วนที่ต้องใช้ในเวลานั้น—มักใช้ข้อมูลขณะรันจริง (เช่น ชนิดและขนาดของข้อมูล) เพื่อเลือกวิธีที่ดีกว่า
ทำไม JIT ถึงรู้สึกเร็ว
เพราะคุณไม่ต้องคอมไพล์ทุกอย่างล่วงหน้า ระบบ JIT มอบฟีดแบ็กเร็วสำหรับงานเชิงโต้ตอบ คุณเขียนหรือสร้างโค้ดสั้นๆ รันทันที และระบบคอมไพล์เฉพาะส่วนที่จำเป็นตอนนั้น ถ้าโค้ดชิ้นเดียวกันรันซ้ำ JIT สามารถแคชผลลัพธ์ที่คอมไพล์แล้วหรือคอมไพล์ซ้ำส่วนที่ “ร้อน” อย่างก้าวกระโดด
ที่ที่การคอมไพล์ขณะรันช่วยได้จริง
JIT เด่นเมื่องานไดนามิกหรือโต้ตอบ:
- REPLs และโน้ตบุ๊ก: ประเมินสคริปต์ทันทีขณะยังได้การรันที่ความเร็วเนทีฟสำหรับลูปหนักๆ
- ปลั๊กอินและส่วนเสริม: แอปโหลดโค้ดผู้ใช้ตอนรันและคอมไพล์ให้ตรงกับ CPU โฮสต์
- งานไดนามิก: เมื่ออินพุตหลากหลาย การโปรไฟล์ขณะรันช่วยชี้ว่าเส้นทางใดควรได้รับการปรับแต่ง
- การคำนวณทางวิทยาศาสตร์: เคอร์เนลที่สร้างขึ้นสำหรับขนาดเมทริกซ์หรือรูปแบบเฉพาะสามารถคอมไพล์เมื่อจำเป็น
บทบาทของ LLVM (ไม่ต้องโอเวอร์)
LLVM ไม่ได้ทำให้โปรแกรมทุกตัวเร็วขึ้นอัตโนมัติ และมันไม่ใช่ JIT สมบูรณ์แบบในตัวเอง แต่มันมอบ ชุดเครื่องมือ: IR ที่นิยามชัดเจน ชุด passes ปรับแต่ง และการสร้างโค้ดสำหรับหลาย CPU โปรเจกต์สามารถสร้างเอนจิน JIT บนบล็อกก่อสร้างเหล่านี้ โดยเลือกการแลกเปลี่ยนระหว่างเวลาเริ่มต้น ประสิทธิภาพสูงสุด และความซับซ้อน
ประสิทธิภาพ ความคาดเดาได้ และการแลกเปลี่ยนในโลกจริง
toolchain ที่ใช้ LLVM สามารถผลิตโค้ดที่เร็วมาก—แต่ “เร็ว” ไม่ใช่คุณสมบัติเดี่ยวที่คงที่ มันขึ้นกับรุ่นคอมไพเลอร์เป้าหมาย CPU การตั้งค่า optimization และแม้แต่สิ่งที่คุณบอกคอมไพเลอร์ให้สมมติเกี่ยวกับโปรแกรม
ทำไม “ซอร์สเดียว ผลลัพธ์ต่างกัน” เกิดขึ้น
คอมไพเลอร์สองตัวสามารถอ่านซอร์สเดียวกันแต่ผลิตโค้ดเครื่องต่างกันได้อย่างมีนัยสำคัญ ส่วนหนึ่งเป็นความตั้งใจ: แต่ละคอมไพเลอร์มีชุด passes, เฮียริสติก และการตั้งค่าดีฟอลต์ต่างกัน แม้แต่ใน LLVM เอง Clang 15 และ Clang 18 อาจตัดสินใจ inline ต่างกัน vectorize ลูปต่างกัน หรือจัดลำดับคำสั่งต่างกัน
นอกจากนี้อาจเกิดจาก undefined behavior หรือ unspecified behavior ในภาษานั้นๆ หากโปรแกรมของคุณเผลอพึ่งพาสิ่งที่มาตรฐานไม่ได้รับประกัน (เช่น overflow ของ signed ใน C) คอมไพเลอร์ต่างกันหรือธงต่างกันอาจ “ปรับแต่ง” ในทางที่เปลี่ยนผลลัพธ์ได้
การกำหนดผล ต้นแบบ debug และ release
ผู้คนมักคาดหวังว่าการคอมไพล์จะนิ่ง: อินพุตเหมือนกัน ผลลัพธ์เหมือนกัน ในทางปฏิบัติ คุณจะเข้าใกล้แต่ไม่เสมอไป ตรอกทางสร้าง เวลาในไฟล์ ลำดับการลิงก์ ข้อมูลที่ได้จากโปรไฟล์ และการเลือก LTO ล้วนส่งผลต่อชิ้นงานสุดท้าย
ความแตกต่างที่ใหญ่และมีประโยชน์จริงคือ debug vs release Debug builds มักปิดการปรับแต่งมากเพื่อรักษาการดีบักแบบทีละขั้นและ stack trace ที่อ่านได้ Release builds เปิดการเปลี่ยนแปลงเชิงรุกที่อาจจัดเรียงโค้ด inline ฟังก์ชัน และลบตัวแปร—ดีสำหรับประสิทธิภาพ แต่ยากต่อการดีบัก
คำแนะนำเชิงปฏิบัติ: วัดผล อย่าเดา
มองประสิทธิภาพเป็นปัญหาการวัด:
- ทำ benchmark บนฮาร์ดแวร์และชุดข้อมูลที่เป็นตัวแทน
- อุ่น cache และรันหลายรอบ
- เปรียบเทียบบิลด์ด้วยธงที่ชัดเจน (เช่น เปลี่ยน
-O2กับ-O3, เปิด/ปิด LTO, หรือเลือก target ด้วย-march)
การเปลี่ยนธงเล็กๆ อาจเปลี่ยนประสิทธิภาพได้ทั้งสองทาง กรรมวิธีที่ปลอดภัยคือ: ตั้งสมมติฐาน วัดมัน แล้วเก็บ benchmark ใกล้เคียงกับสิ่งที่ผู้ใช้ของคุณรันจริง
เครื่องมือที่มากกว่าแค่การคอมไพล์: การวิเคราะห์ การดีบัก และความปลอดภัย
กู้คืนได้อย่างรวดเร็ว
ยกเลิกการเปลี่ยนแปลงที่ไม่ดีได้อย่างรวดเร็วและเดินหน้าต่อโดยไม่สูญเสียโมเมนตัม
LLVM มักถูกอธิบายว่าเป็นชุดเครื่องมือคอมไพเลอร์ แต่หลายคนรู้สึกถึงผลกระทบผ่านเครื่องมือที่อยู่ รอบๆ การคอมไพล์: ตัววิเคราะห์ debugger และการตรวจความปลอดภัยที่สามารถเปิดใช้ในระหว่างการสร้างและทดสอบ
การวิเคราะห์และการเสริมเป็น “แอดออน”
เพราะ LLVM เปิดเผย IR และ pipeline ของ passes อย่างชัดเจน จึงเป็นเรื่องธรรมชาติที่จะสร้างขั้นตอนเพิ่มเติมที่ตรวจหรือเขียนโค้ดใหม่เพื่อจุดประสงค์อื่นนอกเหนือจากความเร็ว ขั้นตอนหนึ่งอาจแทรกตัวนับสำหรับ profiling ทำเครื่องหมายการทำงานหน่วยความจำที่น่าสงสัย หรือเก็บข้อมูล coverage
จุดสำคัญคือฟีเจอร์เหล่านี้สามารถผนวกได้โดยไม่ต้องให้แต่ละทีมภาษาเขียนระบบพื้นฐานซ้ำ
Sanitizers: จับบั๊กใกล้ต้นทาง
Clang และ LLVM ทำให้ sanitizers ได้รับความนิยม—ชุดเครื่องมือรันไทม์ที่ใส่โค้ดเพิ่มเติมเพื่อตรวจจับบั๊กทั่วไปในการทดสอบ เช่น การเข้าถึงหน่วยความจำเกินขอบ ใช้หลัง free, data races และรูปแบบ undefined behavior พวกมันไม่ใช่โล่ป้องกันวิเศษ และมักชะลอโปรแกรม ดังนั้นจึงใช้ใน CI และการทดสอบก่อนปล่อยมากกว่า แต่เมื่อมันจับได้ มักชี้ตำแหน่งต้นทางอย่างชัดเจนและอธิบายได้ ซึ่งทีมต้องการเมื่อไล่บั๊กที่เกิดเป็นครั้งคราว
การวินิจฉัยที่ดีขึ้น = การเริ่มต้นที่เร็วขึ้น
คุณภาพของเครื่องมือยังหมายถึงการสื่อสาร ข้อเตือนที่ชัดเจน ข้อความผิดพลาดที่ปฏิบัติได้ และข้อมูลดีบักที่สม่ำเสมอลดปัจจัยความลึกลับสำหรับผู้มาใหม่ เมื่อ toolchain อธิบาย สิ่งที่เกิดขึ้น และ จะแก้อย่างไร นักพัฒนาจะเสียเวลาน้อยลงกับการจำกฎคอมไพเลอร์และใช้เวลาเรียนรู้โค้ดเบส
LLVM ไม่ได้รับประกันการวินิจฉัยหรือความปลอดภัยที่สมบูรณ์ด้วยตัวมันเอง แต่มันให้พื้นฐานร่วมที่ทำให้การสร้างเครื่องมือฝั่งผู้พัฒนาทำได้จริง รักษาได้ และแชร์ได้ข้ามโปรเจกต์
ควรใช้ LLVM เมื่อไร (และเมื่อใดไม่ควร)
ควรคิดว่า LLVM เป็น “ชุดเครื่องมือสร้างคอมไพเลอร์และเครื่องมือ” ความยืดหยุ่นนี้คือเหตุผลที่มันขับเคลื่อน toolchain สมัยใหม่มากมาย—แต่มันก็ไม่ใช่คำตอบที่เหมาะกับทุกโปรเจกต์
เมื่อ LLVM เหมาะ
LLVM เหมาะเมื่อคุณต้องการนำวิศวกรรมคอมไพเลอร์ชั้นสูงกลับมาใช้ใหม่โดยไม่เขียนใหม่
ถ้าคุณสร้าง ภาษาโปรแกรมใหม่ LLVM ให้ pipeline การปรับแต่งที่พิสูจน์แล้ว การสร้างโค้ดบนหลาย CPU และหนทางสู่ข้อมูลดีบักที่ดี
ถ้าคุณส่ง แอปแบบข้ามแพลตฟอร์ม ระบบ backend ของ LLVM ลดงานที่ต้องทำเพื่อรองรับสถาปัตยกรรมต่างๆ คุณโฟกัสที่ภาษาและตรรกะผลิตภัณฑ์ แทนการเขียนตัวสร้างโค้ดแยก
ถ้าจุดมุ่งหมายของคุณคือ เครื่องมือสำหรับนักพัฒนา—linters, การวิเคราะห์แบบสแตติก, การนำทางโค้ด—LLVM และระบบนิเวศรอบมันเป็นพื้นฐานที่แข็งแรงเพราะคอมไพเลอร์เข้าใจโครงสร้างและชนิดของโค้ดแล้ว
เมื่อมันอาจเกินความจำเป็น
LLVM อาจหนักเกินไปถ้าคุณทำงานบน ระบบฝังตัวขนาดเล็ก ที่ขนาดบิลด์ หน่วยความจำ และเวลาแปลถูกจำกัดอย่างเข้มงวด
มันอาจไม่เหมาะสำหรับ พายป์ไลน์เฉพาะมาก ที่คุณไม่ต้องการการปรับแต่งทั่วไป หรือภาษาของคุณใกล้เคียง DSL ที่ตรงไปตรงมาและสามารถแปลงเป็นโค้ดเครื่องได้โดยตรง
เช็คลิสต์ง่ายๆ
ถามตัวเองสามคำถาม:
- เราจำเป็นต้องรองรับ หลายแพลตฟอร์ม/CPU ทั้งตอนนี้หรือเร็วๆ นี้ไหม?
- เราได้ประโยชน์จาก การปรับแต่งและข้อมูลดีบักที่มีอยู่ แทนการสร้างเองไหม?
- เราต้องการเส้นทางในระบบนิเวศ (เครื่องมือ บูรณาการ คนฝึกหัด) มากกว่าคอมไพเลอร์ที่เล็กและเฉพาะไหม?
ถ้าคุณตอบ “ใช่” กับมากกว่าหนึ่งข้อ LLVM มักเป็นเดิมพันที่ใช้งานได้จริง ถ้าคุณต้องการแค่คอมไพเลอร์เล็กๆ ที่แก้ปัญหาแคบๆ วิธีที่เบากว่าอาจชนะ
ข้อสังเกตเชิงปฏิบัติสำหรับทีมผลิตภัณฑ์: รับประโยชน์จาก LLVM โดยไม่ต้องเป็นผู้เชี่ยวชาญคอมไพเลอร์
ทีมส่วนใหญ่ไม่ต้องการ “นำ LLVM มาใช้” เป็นโปรเจกต์ใหญ่ พวกเขาต้องการผลลัพธ์: การสร้างข้ามแพลตฟอร์ม ไบนารีที่เร็ว ข้อวินิจฉัยที่ดี และเครื่องมือที่เชื่อถือได้
นั่นเป็นเหตุผลที่แพลตฟอร์มอย่าง Koder.ai น่าสนใจในบริบทนี้ หากเวิร์กโฟลว์ของคุณถูกขับเคลื่อนมากขึ้นด้วยออโตเมชันระดับสูง (การวางแผน สร้างโครงร่าง รันลูปอย่างรวดเร็ว) คุณยังได้ประโยชน์จาก LLVM ทางอ้อมผ่าน toolchains ที่อยู่เบื้องหลัง—ไม่ว่าคุณจะสร้างเว็บ React, แบ็กเอนด์ Go กับ PostgreSQL หรือไคลเอนต์ Flutter โมบาย Koder.ai ที่ขับเคลื่อนด้วยแชทมุ่งเน้นที่การส่งมอบสินค้าเร็วขึ้น ขณะที่โครงสร้างพื้นฐานคอมไพเลอร์สมัยใหม่ (LLVM/Clang และเพื่อน เมื่อใช้ได้) ยังคงทำงานที่ไม่หวือหวาเรื่องการปรับแต่ง การวินิจฉัย และความพกพาอยู่เบื้องหลัง