สิ่งที่การค้นหาทางฝั่งเซิร์ฟเวอร์แบบทันทีควรให้ได้
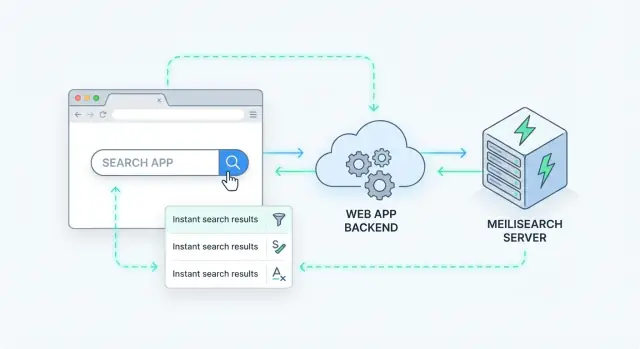
การค้นหาทางฝั่งเซิร์ฟเวอร์หมายความว่าคำค้นถูกรันบนเซิร์ฟเวอร์ของคุณ (หรือบริการค้นหาเฉพาะ) ไม่ใช่ในเบราว์เซอร์ แอปของคุณส่งคำขอค้นหา เซิร์ฟเวอร์รันคำค้นบนดัชนี แล้วส่งผลลัพธ์ที่จัดลำดับกลับมา
เรื่องนี้สำคัญเมื่อชุดข้อมูลของคุณใหญ่เกินกว่าจะส่งไปยังไคลเอนต์ทั้งหมด เมื่อคุณต้องการความสม่ำเสมอของความเกี่ยวข้องข้ามแพลตฟอร์ม หรือเมื่อการควบคุมการเข้าถึงเป็นสิ่งที่ไม่สามารถต่อรองได้ (เช่น เครื่องมือภายในที่ผู้ใช้ควรเห็นเฉพาะสิ่งที่อนุญาต) นอกจากนี้ยังเป็นตัวเลือกเริ่มต้นเมื่อคุณต้องการการเก็บสถิติ การล็อก และประสิทธิภาพที่คาดการณ์ได้
สิ่งที่ผู้ใช้คาดหวัง (และสังเกตได้ทันที)
ผู้คนไม่ได้คิดถึงเอนจินการค้นหา พวกเขาตัดสินจากประสบการณ์ การไหลของการค้นหาแบบ “ทันที” ที่ดีมักหมายถึง:
- ฟีดแบ็กเร็ว: ผลลัพธ์อัปเดตอย่างรวดเร็วขณะพิมพ์ โดยไม่มีความหน่วงที่น่าเกร็ง
- การพิมพ์ผิดไม่ทำให้ค้นหาไม่ได้: การสะกดผิด การสลับตัวอักษร หรือคำที่ไม่สมบูรณ์ยังหาไอเท็มที่ถูกต้องได้
- การควบคุมที่ใช้ได้จริง: ตัวกรอง (หมวดหมู่ สถานะ ช่วงราคา), การเรียงลำดับ (ใหม่สุด ถูกสุด), และฟาซิท (จำนวนต่อฟิลเตอร์) รู้สึกเป็นธรรมชาติ
- การเรียงลำดับที่เกี่ยวข้อง: ผลลัพธ์ “ดีที่สุด” ปรากฏขึ้นก่อน ไม่ใช่แค่รายการที่ใหม่ที่สุดหรืออัดคีย์เวิร์ดมากที่สุด
ถ้าขาดสิ่งใดสิ่งหนึ่ง ผู้ใช้มักพยายามคำค้นต่าง ๆ เลื่อนมากขึ้น หรือยอมแพ้การค้นหาไปเลย
ไกด์นี้จะช่วยอะไรคุณ
บทความนี้เป็นการเดินผ่านเชิงปฏิบัติสำหรับการสร้างประสบการณ์นั้นด้วย Meilisearch เราจะครอบคลุมการติดตั้งอย่างปลอดภัย วิธีจัดโครงสร้างและซิงก์ข้อมูลที่ทำดัชนี วิธีปรับความเกี่ยวข้องและกฎการจัดลำดับ วิธีเพิ่มตัวกรอง/การเรียง/ฟาซิท และการคิดเรื่องความปลอดภัยและการสเกลเพื่อให้การค้นหายังคงเร็วเมื่อแอปของคุณเติบโต
จุดที่การค้นหาทางฝั่งเซิร์ฟเวอร์โดดเด่น
Meilisearch เหมาะอย่างยิ่งสำหรับ:
- เอกสารและฐานความรู้ (ค้นหาหน้าต่าง ๆ ได้เร็ว ทนต่อการพิมพ์ผิด)
- แค็ตตาล็อกสินค้าและมาร์เก็ตเพลส (ตัวกรองและการเรียงลำดับจำเป็น)
- เครื่องมือภายใน (การค้นหาที่รับรู้สิทธิ์การเข้าถึง)
- ไซต์เนื้อหา (ค้นหาบทความ คู่มือ คำถามที่พบบ่อย)
เป้าหมายตลอดคือ: ผลลัพธ์ที่รู้สึกทันที ถูกต้อง และเชื่อถือได้—โดยไม่ทำให้การค้นหาเป็นโปรเจกต์วิศวกรรมขนาดใหญ่
ภาพรวม Meilisearch แบบเข้าใจง่าย
Meilisearch คือเอนจินการค้นหาที่คุณรันคู่กับแอปของคุณ คุณส่งเอกสาร (เช่น สินค้า บทความ ผู้ใช้ หรือบัตรสนับสนุน) และมันสร้างดัชนีที่ปรับแต่งมาเพื่อการค้นหาที่รวดเร็ว backend ของคุณ (หรือ frontend) จะสอบถาม Meilisearch ผ่าน HTTP API แบบเรียบง่ายแล้วได้รับผลลัพธ์ที่จัดลำดับภายในมิลลิวินาที
สิ่งที่คุณจะได้ทันที
Meilisearch มุ่งเน้นที่คุณสมบัติที่ผู้ใช้คาดหวังจากการค้นหาร่วมสมัย:
- ทนต่อการพิมพ์ผิด เช่น “iphnoe” ยังคงหาคำว่า “iPhone” ได้
- การควบคุมความเกี่ยวข้อง (กฎการจัดลำดับ) เพื่อให้คุณกำหนดความหมายของ “ผลลัพธ์ที่ตรงที่สุด” ตามธุรกิจของคุณ
- ตัวกรอง การเรียงลำดับ และฟาซิท เพื่อให้ผู้ใช้จำกัดผลลัพธ์ตามแอตทริบิวต์ เช่น หมวดหมู่ ช่วงราคา ความพร้อมจำหน่าย หรือแท็ก
ออกแบบมาให้รู้สึกตอบสนองและยืดหยุ่น แม้คำค้นจะสั้น ผิดเล็กน้อย หรือกำกวม
สิ่งที่ Meilisearch ไม่ใช่
Meilisearch ไม่ใช่ตัวแทนฐานข้อมูลหลักของคุณ ฐานข้อมูลของคุณยังเป็นแหล่งความจริงสำหรับการเขียน ธุรกรรม และข้อจำกัด Meilisearch เก็บสำเนาของฟิลด์ที่คุณเลือกให้ค้นหา กรอง หรือแสดงได้
โมเดลคิดที่ดีคือ: ฐานข้อมูลเพื่อเก็บและอัปเดตข้อมูล, Meilisearch เพื่อค้นหาอย่างรวดเร็ว
ความคาดหวังด้านประสิทธิภาพ (สิ่งที่มีผลต่อความเร็ว)
Meilisearch สามารถเร็วมาก แต่ผลลัพธ์ขึ้นกับปัจจัยบางอย่าง:
- ขนาดและรูปแบบข้อมูล (จำนวนเอกสาร จำนวนฟิลด์ และปริมาณข้อความที่คุณทำดัชนี)
- ฮาร์ดแวร์ (CPU, RAM, ดิสก์)
- การตั้งค่า (ฟิลด์ไหนเป็น searchable/filterable/sortable และความถี่ในการ reindex)
สำหรับชุดข้อมูลขนาดเล็กถึงกลาง คุณมักรันบนเครื่องเดียวได้ เมื่อดัชนีใหญ่ขึ้น คุณจะต้องคิดอย่างรอบคอบเกี่ยวกับสิ่งที่ทำดัชนีและวิธีซิงก์—ซึ่งเราจะพูดถึงในส่วนถัดไป
วางแผนดัชนีและโมเดลข้อมูลของคุณ
ก่อนติดตั้ง ตัดสินใจว่าคุณจะค้นหาอะไรจริง ๆ Meilisearch จะรู้สึก “ทันที” ก็ต่อเมื่อดัชนีและเอกสารสอดคล้องกับวิธีที่ผู้คนเรียกดูแอปของคุณ
แม็พเอนทิตีไปยังดัชนี
เริ่มจากการระบุเอนทิตีที่ต้องการค้นหา—โดยปกติคือ products, articles, users, help docs, locations เป็นต้น ในหลายแอป วิธีที่ชัดเจนคือ หนึ่งดัชนีต่อประเภทเอนทิตี (เช่น products, articles) เพราะจะทำให้กฎการจัดลำดับและตัวกรองคาดการณ์ได้
ถ้าประสบการณ์ผู้ใช้ค้นหาข้ามหลายประเภทในช่องเดียว (“ค้นหาทุกอย่าง”) คุณยังสามารถเก็บดัชนีแยกกันแล้วรวมผลใน backend หรือสร้างดัชนี "global" เฉพาะภายหลัง อย่าบังคับทุกอย่างเข้าไปในดัชนีเดียวถ้าฟิลด์และตัวกรองไม่สอดคล้องกันจริงๆ
เลือก primary key และรูปแบบเอกสาร
แต่ละเอกสารต้องมีตัวระบุที่เสถียร (primary key) เลือกสิ่งที่:\n
- ไม่เปลี่ยนแปลง (หรือเปลี่ยนแปลงน้อยมาก)\n- ไม่ซ้ำกันในดัชนี\n- มีอยู่แล้วในฐานข้อมูลของคุณ (เช่น
id, sku, slug)\n
สำหรับรูปร่างเอกสาร แนะนำให้ใช้ ฟิลด์แบบแบน เมื่อเป็นไปได้ โครงสร้างแบนง่ายต่อการกรองและเรียงลำดับ ฟิลด์ซ้อนเป็นอ็อบเจกต์ก็รับได้เมื่อเป็นกลุ่มที่แน่นและไม่เปลี่ยนแปลงมาก (เช่น author object) แต่หลีกเลี่ยงการซ้อนลึกที่สะท้อนสกีมาเชิงสัมพันธ์ทั้งชุด—เอกสารสำหรับการค้นหาควรถูกออกแบบให้ อ่านได้เร็ว ไม่ใช่เหมือนฐานข้อมูล
จำแนกฟิลด์: searchable, filterable, displayed
วิธีปฏิบัติที่ใช้ได้คือแท็กแต่ละฟิลด์ด้วยบทบาท:\n
- Searchable: ข้อความที่ผู้ใช้พิมพ์ (title, name, description)\n- Filterable: แอตทริบิวต์ที่ใช้จำกัดผล (category, price range, status, tags)\n- Displayed: สิ่งที่ส่งกลับไปยัง UI (title, thumbnail URL, short snippet)\n
วิธีนี้ป้องกันข้อผิดพลาดทั่วไป: ทำดัชนีฟิลด์ “กันไว้ก่อน” แล้วสงสัยทีหลังว่าทำไมผลลัพธ์จึงมีเสียงรบกวนหรือการกรองช้าลง
วางแผนเนื้อหาหลายภาษา
“ภาษา” อาจหมายถึงหลายสิ่งในข้อมูลของคุณ:\n
- ภาษาของเอกสาร (
lang: "en")\n- โลเคลของผู้ใช้ (ภาษา UI)\n- ฟิลด์ผสมหลายภาษา (ชื่อสินค้าที่เก็บหลายภาษา)\n
ตัดสินใจตั้งแต่ต้นว่าคุณจะใช้ ดัชนีแยกตามภาษา (เรียบง่ายและคาดการณ์ได้) หรือ ดัชนีเดียวที่มีฟิลด์ภาษา (ดัชนีน้อยลง แต่ต้องมีตรรกะมากขึ้น) คำตอบขึ้นกับว่าผู้ใช้ค้นหาภายในภาษาหนึ่งในแต่ละครั้งหรือไม่ และคุณเก็บการแปลอย่างไร
การติดตั้งและรัน Meilisearch อย่างปลอดภัย
การรัน Meilisearch ตรงไปตรงมา แต่ “ปลอดภัยโดยดีฟอลต์” ต้องมีการตัดสินใจบางอย่าง: จะ deploy ที่ไหน จะเก็บข้อมูลอย่างไร และจัดการ master key อย่างไร
ตัวเลือกการปรับใช้ (เลือกสิ่งที่ทีมของคุณสามารถดูแลได้)
- Docker (ใช้บ่อยที่สุด): เริ่มเร็ว อัปเกรดง่าย สม่ำเสมอข้ามสภาพแวดล้อม จับคู่กับ persistent volume
- VM หรือ bare metal: เหมาะเมื่อคุณมี pipeline การปรับใช้ Linux มาตรฐาน (systemd, การหมุนล็อก, สำรองข้อมูล)
- โฮสติ้งแบบบริหารจัดการ: ถ้าทีมไม่ต้องการดูแลเซิร์ฟเวอร์ ให้หา provider ที่มี Meilisearch แบบบริการ หรือแพลตฟอร์มที่ให้เป็น add-on คุณจะแลกความยืดหยุ่นกับการดำเนินงานที่ง่ายขึ้น
เบื้องต้นของสภาพแวดล้อม: การจัดเก็บ หน่วยความจำ สำรองข้อมูล และการมอนิเตอร์
การจัดเก็บ: Meilisearch เขียนดัชนีลงดิสก์ วางไดเรกทอรีข้อมูลบน storage ที่เชื่อถือได้และถาวร (ไม่ใช่ storage ของคอนเทนเนอร์ที่หายได้) วางแผนความจุสำหรับการเติบโต: ดัชนีอาจขยายเร็วเมื่อมีฟิลด์ข้อความขนาดใหญ่และแอตทริบิวต์มาก
หน่วยความจำ: จัดสรร RAM เพียงพอให้การค้นหาตอบสนองภายใต้โหลด ถ้าพบการสว็อป ประสิทธิภาพจะเสีย
สำรองข้อมูล: สำรองไดเรกทอรีข้อมูลของ Meilisearch (หรือใช้ snapshot ที่ชั้น storage) ทดสอบการกู้คืนอย่างน้อยหนึ่งครั้ง; การสำรองที่กู้คืนไม่ได้ก็แค่ไฟล์
มอนิเตอร์: ติดตาม CPU, RAM, การใช้ดิสก์ และ I/O ดิสก์ นอกจากนี้มอนิเตอร์สถานะ process และบันทึกข้อผิดพลาด อย่างน้อยตั้งการแจ้งเตือนเมื่อบริการหยุดหรือพื้นที่ดิสก์ใกล้หมด
ตั้งค่าและจัดเก็บ master key อย่างปลอดภัย
ให้รัน Meilisearch พร้อม master key เสมอในสภาพแวดล้อมที่ไม่ใช่การพัฒนาเกือบจะทุกรณี เก็บคีย์ใน secret manager หรือระบบจัดเก็บ env ที่เข้ารหัส (ไม่ใส่ใน Git, ไม่เก็บ .env แบบ plain-text ที่ commit เข้า repo)
ตัวอย่าง (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
นอกจากนี้พิจารณากฎเครือข่าย: ผูกที่อินเทอร์เฟซส่วนตัวหรือจำกัดการเข้าถึงเข้าโดยให้เฉพาะ backend ของคุณเท่านั้นที่สามารถเข้าถึง Meilisearch ได้
เช็คลิสต์เริ่มต้น
curl -s http://localhost:7700/version
การทำดัชนีเอกสารและรักษาความสอดคล้อง
Go from local to live
Deploy and host your app, then iterate on relevance without risky manual changes.
การทำดัชนีใน Meilisearch เป็นแบบอะซิงโครนัส: คุณส่งเอกสาร Meilisearch จะคิวงานและก็ต่อเมื่อ task นั้นสำเร็จเอกสารจึงค้นหาได้ ปฏิบัติกับการทำดัชนีเหมือนระบบงาน ไม่ใช่คำขอเดี่ยว
โฟลว์การทำดัชนีง่าย ๆ (add → wait → verify)
- เพิ่มเอกสาร (ตรวจว่าทุกเอกสารมี id ที่เสถียร โดยปกติคือ
id)
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
- รอ task การตอบ API จะมี
taskUid ตรวจสอบจนกว่าจะเป็น succeeded (หรือ failed)
curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- ยืนยันจำนวนและการค้นหาพื้นฐาน ยืนยันว่าดัชนีมีจำนวนเอกสารตามคาดและการค้นหาแบบพื้นฐานให้ผล
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
ถ้าจำนวนไม่ตรง อย่าเดา—ตรวจรายละเอียดข้อผิดพลาดของ task ก่อน
การแบตช์ที่ไม่สร้างความประหลาดใจในภายหลัง
การแบตช์คือการทำให้ task คาดเดาได้และกู้คืนได้
- เริ่มจาก 1,000–10,000 เอกสารต่อแบตช์ หรือกำหนดขนาด payload (หลายแอปสบายกับ 5–15 MB ต่อคำขอ)
- ชอบ หลายแบตช์ขนาดเล็ก มากกว่าการอัปโหลดครั้งใหญ่เดียว; retry และระบุข้อมูลที่ผิดพลาดจะง่ายกว่า
- ถ้ามีการเปลี่ยนบ่อย ให้ทำดัชนีอย่างต่อเนื่องเป็นแบตช์ (เช่น ทุกนาที) แทนการสร้างใหม่ทั้งหมด
อัปเดต vs reindex ทั้งหมด
addDocuments ทำงานเหมือน upsert: เอกสารที่มี primary key เดิมจะถูกอัปเดต เอกสารใหม่จะถูกแทรก ใช้สำหรับการอัปเดตปกติ
ทำ reindex ทั้งหมด เมื่อ:
- รูปร่างเอกสารเปลี่ยนแปลงอย่างมาก,
- ต้องคำนวณฟิลด์ที่ได้มาซ้ำ,
- การซิงก์มีความคลาดเคลื่อนและต้องการรีเซ็ตสะอาด
สำหรับการลบ ให้เรียก deleteDocument(s) โดยตรง มิฉะนั้นระเบียนเก่าอาจคงอยู่
Idempotency: การ retry ที่ปลอดภัยเมื่อ job ล้มเหลว
การทำดัชนีควร retry ได้ กุญแจคือ id เอกสารที่เสถียร
- ถ้าแบตช์หมดเวลาหรือ time out คุณสามารถส่งซ้ำได้: upsert + id เสถียรจะไม่สร้างซ้ำ
- เก็บ
taskUid ที่ส่งกลับควบคู่กับ id งานของคุณ และ retry ตามสถานะ task
- ถ้าใช้คิว ให้ worker เป็นแบบ “at-least-once” ที่ปลอดภัย: การซ้ำซ้อนไม่ก่อให้เกิดปัญหา
ข้อมูลตัวอย่างสำหรับทดสอบก่อนขึ้นจริง
ก่อนข้อมูลจริง ให้ทำดัชนีชุดข้อมูลเล็ก (200–500 รายการ) ที่มีฟิลด์เหมือนจริง ตัวอย่าง: ชุด products ที่มี id, name, description, category, brand, price, inStock, createdAt เพียงพอที่จะยืนยันโฟลว์ task จำนวน และพฤติกรรมอัปเดต/ลบ—โดยไม่ต้องรอการนำเข้าขนาดใหญ่
ความเกี่ยวข้องและกฎการจัดลำดับที่คุณปรับแต่งได้
“ความเกี่ยวข้อง” ก็คือ: อะไรแสดงขึ้นก่อน และเพราะเหตุใด Meilisearch ทำให้สิ่งนี้ปรับได้โดยไม่ต้องให้คุณสร้างระบบสกอร์เอง
เริ่มจากฟิลด์ที่ถูกต้อง
การตั้งค่าสองอย่างกำหนดสิ่งที่ Meilisearch สามารถทำกับเนื้อหาของคุณ:
searchableAttributes: ฟิลด์ที่ Meilisearch จะค้นหาเมื่อลูกค้าพิมพ์คำค้น (เช่น: title, summary, tags) ลำดับมีความหมาย: ฟิลด์ที่อยู่ก่อนจะสำคัญกว่าdisplayedAttributes: ฟิลด์ที่ส่งกลับมาในคำตอบ สำคัญเรื่องความเป็นส่วนตัวและขนาด payload—ถ้าฟิลด์ไม่อยู่ในนี้ จะไม่ถูกส่งกลับ
แนวปฏิบัติพื้นฐานคือทำให้ฟิลด์ที่มีสัญญาณสูงไม่กี่ฟิลด์สามารถค้นหาได้ (title, ข้อความสำคัญ) และเก็บ displayed fields ไว้เฉพาะที่ UI ต้องการ
กฎการจัดลำดับมีผลต่อการเรียงผลอย่างไร
Meilisearch จัดเรียงเอกสารที่ตรงกันโดยใช้ ranking rules—เป็นท่อของตัว “ตัดสินเมื่อเสมอกัน” แนวคิดคือมันจะชอบ:
- ผลลัพธ์ที่ตรงกับคำค้นได้ดี (รวมถึงการทนต่อการพิมพ์ผิด), แล้ว
- ผลลัพธ์ที่การตรงกันแข็งแรงกว่า (คำใกล้กันกว่า ตรงในแอตทริบิวต์ที่สำคัญกว่า), แล้ว
- ผลลัพธ์ที่สอดคล้องกับตรรกะธุรกิจของคุณ (การเรียงแบบกำหนดเองเช่น ความใหม่ หรือความนิยม)
คุณไม่ต้องจำรายละเอียดทั้งหมดเพื่อปรับแต่งอย่างมีประสิทธิภาพ; คุณแค่เลือก ฟิลด์ไหนสำคัญ และ เมื่อใดควรใช้การเรียงแบบกำหนดเอง
เป้าหมายการปรับแต่งทั่วไป (พร้อมตัวอย่าง)
เป้าหมาย: “การตรงกับ title ควรชนะ” ให้ title อยู่ก่อน:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
เป้าหมาย: “เนื้อหาใหม่ควรอยู่ก่อน” เพิ่มกฎการเรียงและเรียงที่เวลาคำขอ (หรือกำหนด ranking แบบกำหนดเอง):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
แล้วเรียก:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
เป้าหมาย: “โปรโมตสินค้ายอดนิยม” ทำให้ popularity เป็น sortable แล้วเรียงตามเมื่อเหมาะสม
ประเมินการเปลี่ยนแปลงด้วยการทดสอบก่อน/หลังแบบง่าย
เลือก 5–10 คำค้นจริงที่ผู้ใช้พิมพ์ บันทึกผลลัพธ์อันดับต้นก่อนเปลี่ยน จากนั้นเปรียบเทียบหลังการเปลี่ยน
ตัวอย่าง:
- ก่อน: คำค้น
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- หลัง (title-first + exactness): คำค้น
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
ถ้าผลหลังตรงกับความตั้งใจของผู้ใช้มากกว่า ให้เก็บการตั้งค่านั้น ถ้าทำให้กรณีพิเศษแย่ลง ให้ปรับทีละอย่าง (ลำดับแอตทริบิวต์ แล้วกฎการเรียง) เพื่อจะได้รู้ว่าการปรับใดทำให้ดีขึ้น
ตัวกรอง การเรียง และฟาซิทสำหรับการค้นหาในโลกจริง
ช่องค้นหาที่ดีไม่ใช่แค่ “พิมพ์คำแล้วได้ผล” ผู้ใช้ยังต้องการจำกัดผล (“เฉพาะสินค้าที่พร้อมจำหน่าย”) และเรียงลำดับ (“ถูกที่สุดก่อน”) ใน Meilisearch ทำได้ด้วย filters, sorting, และ facets
ตัวกรองและฟาซิท (แนวคิดเดียวกัน แต่ UI ต่างกัน)
Filter คือกฎที่ใช้กับชุดผลลัพธ์ Facet คือสิ่งที่แสดงใน UI เพื่อช่วยผู้ใช้สร้างกฎเหล่านั้น (มักเป็นกล่องเช็กหรือจำนวน)
ตัวอย่างที่ไม่เชิงเทคนิค:
- Category: “Shoes”, “Jackets”, “Accessories”
- Price: “Under $50”, “$50–$100”
- Status: “In stock”, “Backorder”, “Archived”
ผู้ใช้อาจค้นหา “running” แล้วกรองเป็น category = Shoes และ status = in_stock ฟาซิทจะแสดงจำนวนเช่น “Shoes (128)” และ “Jackets (42)” เพื่อให้ผู้ใช้เห็นว่ามีอะไรบ้าง
กำหนดฟิลด์ที่เป็น filterable และ sortable (มิฉะนั้นจะไม่ทำงาน)
Meilisearch ต้องให้คุณเปิดใช้งานฟิลด์ที่ใช้สำหรับการกรองและการเรียง
- ทำเครื่องหมายฟิลด์เป็น filterable เมื่อคุณจะใช้พวกมันในตัวกรอง:
category, status, brand, price, created_at, tenant_id
- ทำเครื่องหมายฟิลด์เป็น sortable เมื่อคุณจะเรียงผลตามมัน:
price, rating, created_at, popularity
เก็บรายการนี้ให้กระชับ การทำทุกอย่างเป็น filterable/sortable จะเพิ่มขนาดดัชนีและช้าในการอัปเดต
การแบ่งหน้าและข้อจำกัดเพื่อให้การค้นหายังคงเร็ว
แม้จะมีการแมตช์ 50,000 รายการ ผู้ใช้เห็นแค่หน้าแรก ใช้หน้าขนาดเล็ก (บ่อยครั้ง 20–50 ผลลัพธ์) ตั้ง limit ที่สมเหตุสมผล และแบ่งหน้าด้วย offset (หรือคุณสมบัติการแบ่งหน้าที่ใหม่กว่า) นอกจากนี้กำหนดความลึกหน้าสูงสุดในแอปของคุณเพื่อป้องกันคำขอที่แพงเกินไป เช่น “หน้า 400”
พหุพจน์คำพ้องความหมายและ stop words (เลือกใช้ระมัดระวัง)
- Synonyms ช่วยเมื่อคำต่างกันแต่ความหมายเหมือนกัน (เช่น “hoodie” ↔ “sweatshirt”) เพิ่มทีละน้อยและตรวจสอบวิเคราะห์การค้นหา—synonym มากเกินไปอาจให้ผลที่น่าประหลาดใจ
- Stop words เอาคำทั่วไปออก (“the”, “and”) ช่วยลดเสียงรบกวน แต่ก็อาจทำให้การค้นหาชื่อเฉพาะเสียหาย (“The Who”, “A Team”) ปรับ stop words เมื่อมีปัญชัดเจนเท่านั้น
การรวม Meilisearch เข้ากับ backend ของแอปคุณ
Tune relevance with confidence
Test ranking tweaks and roll back quickly with snapshots and rollback.
วิธีที่ชัดเจนในการเพิ่มการค้นหาทางฝั่งเซิร์ฟเวอร์คือปฏิบัติต่อ Meilisearch เป็นบริการข้อมูลเฉพาะด้านอยู่หลัง API ของคุณ แอปของคุณรับคำขอค้นหา เรียก Meilisearch แล้วส่งผลลัพธ์ที่คัดกรองกลับไปยังไคลเอนต์
รูปแบบ backend ง่าย ๆ
ทีมส่วนใหญ่จะใช้โฟลว์แบบนี้:
- ไคลเอนต์เรียก endpoint ของคุณ (เช่น
GET /api/search?q=wireless+headphones&limit=20).
- Backend ตรวจสอบอินพุต ใช้กฎธุรกิจ และตัดสินใจว่าควรสอบถามดัชนีใด
- Backend เรียก Search API ของ Meilisearch ด้วยคำค้นพร้อมตัวกรอง/การเรียง
- Backend ประมวลผลผลลัพธ์ (ซ่อนฟิลด์ส่วนตัว ผสานกับข้อมูล DB ประยุกต์กฎสิทธิ์)
- Backend ส่งรูปแบบผลลัพธ์ที่เสถียรกลับให้ไคลเอนต์
รูปแบบนี้ทำให้ Meilisearch แทนที่ได้ง่ายและป้องกันโค้ด frontend พึ่งพาโครงสร้างดัชนีโดยตรง
ถ้าคุณกำลังสร้างแอปใหม่ (หรือสร้างเครื่องมือภายในใหม่) และต้องการรูปแบบนี้เร็ว ๆ แพลตฟอร์มสร้างโค้ดอย่าง Koder.ai สามารถช่วย scaffold โฟลว์เต็ม—React UI, Go backend, และ PostgreSQL—แล้วรวม Meilisearch อยู่หลัง endpoint เดียว /api/search เพื่อให้ไคลเอนต์เรียบง่ายและสิทธิ์การเข้าถึงอยู่ฝั่งเซิร์ฟเวอร์
การสอบถามจาก frontend vs backend (และเหตุผลที่ backend ปลอดภัยกว่า)
Meilisearch รองรับการสอบถามจากฝั่งไคลเอนต์ แต่การสอบถามจาก backend มักปลอดภัยกว่าเพราะ:
- ความลับยังคงเป็นส่วนตัว: คุณไม่เสี่ยงเปิดเผยคีย์ที่มีสิทธิพิเศษ
- การอนุญาตสอดคล้องกัน: backend สามารถบังคับสิทธิ์ว่า "ผู้ใช้คนนี้ควรเห็นอะไร" ก่อนส่งผลลัพธ์
- คุณควบคุมความซับซ้อนของคำค้นได้: จำกัดตัวกรอง ตัวเลือกการเรียง และการแบ่งหน้าเพื่อปกป้องประสิทธิภาพ
การสอบถามจาก frontend ยังใช้ได้สำหรับข้อมูลสาธารณะที่ใช้คีย์จำกัด แต่ถ้ามีกฎการมองเห็นเฉพาะผู้ใช้ ให้ส่งผ่านเซิร์ฟเวอร์
แคชคำค้นยอดนิยมโดยไม่ทำลายความเกี่ยวข้อง
การจราจรการค้นหามักซ้ำกัน (“iphone case”, “return policy”) เพิ่มการแคชที่เลเยอร์ API ของคุณ:
- แคชผลลัพธ์เต็มชั่วระยะสั้น (เช่น 10–60 วินาที) สำหรับการเข้าชมโดยไม่ระบุผู้ใช้
- ทำคีย์แคชให้เป็นมาตรฐาน (ตัดช่องว่าง เล็กตัว รวมตัวกรอง/การเรียง)
- ล้างแคชอย่างระมัดระวัง: สำหรับดัชนีที่เปลี่ยนเร็ว ให้ใช้ TTL สั้นแทนการพยายาม purge อย่างรุนแรง
การจำกัดอัตราและควบคุมการละเมิด
ปฏิบัติต่อการค้นหาเป็น endpoint ที่เปิดสาธารณะ:
- ตั้ง rate limit ต่อ IP หรือ ต่อผู้ใช้
- กำหนด
limit สูงสุด และความยาวคำค้นสูงสุด
- พิจารณาการบล็อกแบบอ่อนของบอทที่ชัดเจน ในขณะที่ยังอนุญาตผู้ใช้จริง
พื้นฐานความปลอดภัย: คีย์ การควบคุมการเข้าถึง และมัลติ-เทนานซี
Meilisearch มักถูกวางไว้ "ข้างหลัง" แอปของคุณเพราะมันสามารถส่งข้อมูลธุรกิจที่ละเอียดอ่อนได้อย่างเร็ว ปฏิบัติเหมือนฐานข้อมูล: ล็อกมันไว้ และเปิดเผยเฉพาะสิ่งที่ผู้เรียกควรเห็น
API keys: master vs scoped (หลักการ least privilege)
Meilisearch มี master key ที่ทำได้ทุกอย่าง: สร้าง/ลบดัชนี อัปเดตการตั้งค่า และอ่าน/เขียนเอกสาร เก็บไว้เฉพาะฝั่งเซิร์ฟเวอร์
สำหรับแอป ให้สร้าง API keys ที่สิทธิจำกัดและจำกัดดัชนี ตัวอย่างที่พบบ่อย:
- งานแบ็กกราวด์: คีย์ที่เขียนเอกสารและอัปเดตการตั้งค่าได้ แต่จำกัดเฉพาะดัชนีที่กำหนด
- App server: คีย์อ่านอย่างเดียวสำหรับการค้นหา
- Client (ถ้าจำเป็น): คีย์ค้นหาแบบจำกัดมากพร้อมตัวกรองเข้มงวด
หลัก least privilege หมายความว่าถ้าคีย์รั่ว จะไม่สามารถลบข้อมูลหรืออ่านดัชนีที่ไม่เกี่ยวข้องได้
มัลติ-เทนานซี: ดัชนีแยกหรือกรองด้วย tenantId
ถ้าคุณให้บริการหลายลูกค้า (เทนแนนท์) มีสองทางเลือกหลัก:
1) หนึ่งดัชนีต่อเทนแนนท์.
ง่ายในการคิดและลดความเสี่ยงการเข้าถึงข้ามเทนแนนท์ ข้อเสีย: มีดัชนีมากขึ้นให้จัดการ และต้องอัปเดตการตั้งค่าอย่างสม่ำเสมอ
2) ดัชนีรวม + ตัวกรอง tenantId.
เก็บฟิลด์ tenantId ในเอกสารทุกชิ้นและบังคับตัวกรองเช่น tenantId = "t_123" สำหรับทุกการค้นหา สามารถสเกลได้ดี แต่ต้องแน่ใจว่าทุกคำขอใช้ตัวกรองเสมอ (ควรใช้คีย์ที่ถูกจำกัดเพื่อไม่ให้ผู้เรียกลบตัวกรองได้)
ป้องกันการรั่วไหลของข้อมูล: ควบคุมสิ่งที่ส่งคืนได้
แม้การค้นหาถูกต้อง ผลลัพธ์อาจรั่วฟิลด์ที่คุณไม่ต้องการแสดง (อีเมล โน้ตภายใน ราคาต้นทุน) กำหนดว่าอะไรดึงกลับได้:
- จำกัด displayed/retrievable attributes เป็น allowlist ที่ปลอดภัย
- เก็บฟิลด์ที่ละเอียดอ่อนในดัชนีเฉพาะเมื่อจำเป็นเท่านั้น และหลีกเลี่ยงการส่งกลับ
ทำเทสต์ "กรณีแย่สุด" อย่างรวดเร็ว: ค้นหาคำธรรมดาและยืนยันว่าไม่มีฟิลด์ส่วนตัวปรากฏ
ความปลอดภัยเชิงปฏิบัติการพื้นฐาน
- จำกัดการเข้าถึงเครือข่าย: ผูกกับ localhost หรือเครือข่ายส่วนตัว และอนุญาตการเข้าเฉพาะจากเซิร์ฟเวอร์แอปของคุณ
- วาง Meilisearch ไว้หลัง reverse proxy หากต้องการ TLS และ rate limiting
- เก็บคีย์ใน secrets manager (ไม่เก็บใน source control หรือ bundle ฝั่ง frontend) และหมุนคีย์เป็นระยะ
ถ้าไม่แน่ใจว่าคีย์ควรอยู่ฝั่งไคลเอนต์หรือไม่ ให้สมมติว่า "ไม่" และเก็บการค้นหาฝั่งเซิร์ฟเวอร์
ประสิทธิภาพและการสเกลโดยไม่ต้องเดา
Bring search to mobile
Generate a Flutter client that calls your backend search endpoint consistently.
Meilisearch เร็วเมื่อคุณคำนึงถึงสองงาน: การทำดัชนี (การเขียน) และ คำค้น (การอ่าน) ปัญหาช้าโดยส่วนใหญ่เกิดจากงานทั้งสองแข่งกันใช้ CPU, RAM, หรือดิสก์
จุดคอขวดที่มักเกิด
โหลดการทำดัชนี อาจพุ่งเมื่อคุณนำเข้าชุดใหญ่ อัปเดตบ่อย หรือเพิ่มฟิลด์ searchable มาก การทำดัชนีเป็นงานพื้นหลัง แต่ยังบริโภค CPU และแบนด์วิดท์ดิสก์ ถ้าคิวงานเพิ่ม การค้นหาอาจเริ่มช้าลงแม้ปริมาณคำค้นไม่เปลี่ยน
โหลดคำค้น โตตามทราฟฟิก แต่ฟีเจอร์ต่าง ๆ ก็เพิ่มงานต่อคำขอ: ตัวกรองมากขึ้น ฟาซิทมากขึ้น ชุดผลลัพธ์ใหญ่ขึ้น และการทนต่อการพิมพ์ผิดที่ละเอียดขึ้น ล้วนเพิ่มงานต่อคำขอ
ดิสก์ I/O เป็นผู้ร้ายเงียบ ดิสก์ช้า (หรือเพื่อนร่วมห้อง noisy neighbors บน shared volume) อาจเปลี่ยน "ทันที" ให้เป็น "ในที่สุด" NVMe/SSD เป็นฐานมาตรฐานสำหรับ production
ขั้นตอนการสเกลเชิงปฏิบัติ
เริ่มจากการกำหนดขนาดอย่างง่าย: ให้ Meilisearch RAM เพียงพอเพื่อให้ดัชนีอยู่ในหน่วยความจำและ CPU เพียงพอเพื่อรับ QPS สูงสุด จากนั้นแยกความกังวล:
- ถ้าการทำดัชนีรบกวนการอ่าน ให้วางแผนนำเข้าชุดใหญ่ในช่วงนอกชั่วโมงทำการ และชอบแบตช์ใหญ่กว่าหลายอัปเดตเล็ก
- เพิ่ม replicas เพื่อความพร้อมใช้งานสูงและความจุการอ่าน (แอปของคุณสามารถโหลดบาลานซ์คำค้นข้าม replicas)
- Sharding: Meilisearch ไม่มีการกระจายแบบอัตโนมัติ หากโตเกิน node เดียว คุณสามารถพาร์ทิชันข้อมูลในระดับแอป (เช่น แยกตามเทนแนนท์ ภูมิภาค หรือช่วงเวลา) เป็นหลายดัชนีหรือคลัสเตอร์
สิ่งที่ควรมอนิเตอร์ (เพื่อไม่ต้องเดา)
ติดตามชุดสัญญาณเล็ก ๆ:
- Latency การค้นหา (p50/p95) และ throughput
- ความยาวคิว task / เวลาในการประมวลผล task (คิวขึ้นแปลว่าการทำดัชนีตามไม่ทัน)
- CPU, RAM, การใช้ดิสก์ และ disk I/O wait
- อัตราข้อผิดพลาด (timeouts, 4xx/5xx, task ล้มเหลว)
การสำรองและแผนการอัปเกรด
การสำรองควรเป็นกิจวัตร ใช้ฟีเจอร์ snapshot ของ Meilisearch เป็นตารางเวลา เก็บ snapshot นอกระบบ และทดสอบการกู้คืนเป็นระยะ สำหรับการอัปเกรด อ่าน release notes ทดสอบใน non-prod และวางแผนเวลาสำหรับการ reindex ถ้าการเปลี่ยนเวอร์ชันมีผลต่อพฤติกรรมการทำดัชนี
ถ้าคุณใช้ snapshot ของสภาพแวดล้อมและ rollback ในแพลตฟอร์มแอปของคุณ ให้สอดคล้องการเปิดใช้ search กับวินัยเดียวกัน: snapshot ก่อนเปลี่ยน ยืนยัน health checks และมีทางกลับสู่สถานะที่ใช้งานได้เร็ว
แก้ปัญหาและเช็คลิสต์การเปิดตัวแบบปฏิบัติ
แม้จะรวมได้เรียบร้อย ปัญหาการค้นหามักตกอยู่ในไม่กี่กลุ่มที่ซ้ำได้ ข่าวดีก็คือ Meilisearch ให้การมองเห็นเพียงพอ (tasks, logs, การตั้งค่าที่กำหนดได้) เพื่อดีบักอย่างรวดเร็ว—ถ้าคุณทำอย่างเป็นระบบ
ปัญหาทั่วไป (และมักหมายถึงอะไร)
- "ตัวกรองของฉันไม่ทำงาน": ฟิลด์ไม่ได้เพิ่มเข้าไปใน
filterableAttributes, หรือเอกสารเก็บค่าในรูปแบบที่ไม่คาดคิด (string vs array vs nested object)
- "ผลลัพธ์จัดลำดับแปลก": ranking rules, synonyms, stop words หรือขาดการตั้งค่า
sortableAttributes/rankingRules ทำให้รายการผิดขึ้นมา
- "การค้นหาแสดงข้อมูลเก่า": task การทำดัชนียังประมวลผลอยู่ คุณเขียนไปยังดัชนีอื่นที่ต่างจากที่อ่าน หรือ pipeline ซิงก์ของคุณหลุดการอัปเดต/ลบ
เวิร์กโฟลว์การดีบักที่ยังเป็นระเบียบ
เริ่มจากการตรวจว่า Meilisearch รับการเปลี่ยนแปลงล่าสุดของคุณแล้วหรือไม่
- ตรวจสอบสถานะ task: การเปลี่ยนการตั้งค่าและการอัปเดตเอกสารแต่ละครั้งสร้าง async task ถ้า task ล้มเหลว ให้แก้ก่อน (payload ผิด ชนิดฟิลด์ผิด เอกสารใหญ่เกิน)
- ใช้ logs โดยมีคำถามเดียวในใจ: “เซิร์ฟเวอร์รับคำขอของฉันหรือไม่?” แล้ว “จบการประมวลผลหรือยัง?” หลีกเลี่ยงการสแกนทุกอย่างพร้อมกัน
- สร้างคำค้นที่ทำซ้ำได้ขั้นต่ำ:\n - เลือก หนึ่ง ดัชนี.\n - ใช้คำค้นที่ให้ชุดผลเล็กและคงที่.\n - เพิ่มข้อจำกัดทีละอย่าง:
filter, แล้ว sort, แล้ว facets.
ถ้าอธิบายผลลัพธ์ไม่ได้ ให้ชะลอการตั้งค่ากลับชั่วคราว: เอา synonyms ออก ลดการปรับแต่ง ranking แล้วทดสอบกับชุดข้อมูลเล็ก ๆ ปัญหาความเกี่ยวข้องซับซ้อนจะเห็นง่ายกว่าบน 50 เอกสารมากกว่า 5 ล้าน
ยุทธศาสตร์การเปิดตัว: ลดขอบเขตความเสียหาย
- ทดสอบดัชนีก่อน: สร้าง
your_index_v2 ขนานไปกับตัวเก่า ตั้งค่าการตั้งค่า แล้วเล่นซ้ำตัวอย่างคำค้นจาก production
- Canary rollout: เส้นทางทราฟฟิกค้นหาส่วนน้อยไปยังดัชนีหรือการตั้งค่าใหม่ เปรียบเทียบอัตราการคลิกและอัตรา "ไม่มีผลลัพธ์"
- พฤติกรรม fallback: ตัดสินใจว่าผู้ใช้เห็นอะไรเมื่อการค้นช้าหรือไม่พร้อม—ผลลัพธ์จากแคช คำค้นง่าย ๆ หรือข้อความเชิญให้ลองใหม่ อย่าให้การค้นหาล้มเหลวจนทำให้หน้าทั้งหน้าพัง
เช็คลิสต์ขั้นตอนต่อไป
- ยืนยันว่า
filterableAttributes และ sortableAttributes ตรงกับความต้องการ UI
- ยืนยันว่า task การทำดัชนีสำเร็จหลังการปรับใช้แต่ละครั้ง
- เพิ่มมอนิเตอร์ "search health" เล็ก ๆ (latency + task failures)
- ฝึก rollback: สลับทราฟฟิกกลับไปยังดัชนีก่อนหน้า
Related guides: search reliability, indexing patterns, and production rollout tips.