23 ธ.ค. 2568·2 นาที
งบข้อผิดพลาดสำหรับทีมเล็ก: SLO ที่เป็นจริงและพิธีกรรมสั้นๆ
เรียนรู้การใช้งบข้อผิดพลาดสำหรับทีมเล็ก: ตั้ง SLO ที่เป็นจริงสำหรับผลิตภัณฑ์เริ่มต้น ตัดสินใจว่าเหตุการณ์ไหนสำคัญ และทำพิธีสั้นรายสัปดาห์เพื่อความน่าเชื่อถือ
เรียนรู้การใช้งบข้อผิดพลาดสำหรับทีมเล็ก: ตั้ง SLO ที่เป็นจริงสำหรับผลิตภัณฑ์เริ่มต้น ตัดสินใจว่าเหตุการณ์ไหนสำคัญ และทำพิธีสั้นรายสัปดาห์เพื่อความน่าเชื่อถือ
ทีมเล็กส่งงานเร็วเพราะต้องทำ ความเสี่ยงมักไม่ใช่การล่มครั้งใหญ่ครั้งเดียว แต่เป็นความล้มเหลวเล็ก ๆ ที่เกิดซ้ำ: ฟอร์มสมัครไม่เสถียร, การชำระเงินบางครั้งล้มเหลว, หรือการ deploy ที่บางครั้งทำให้หน้าจอหนึ่งเสีย แต่ละเหตุการณ์ขโมยเวลาหลายชั่วโมง ทำลายความเชื่อถือ และเปลี่ยนการปล่อยเป็นการเสี่ยงคว่ำหัวเหรียญ
งบข้อผิดพลาดให้ทีมเล็กวิธีง่าย ๆ ในการเคลื่อนไหวไวโดยไม่ต้องทำเป็นว่าความน่าเชื่อถือจะ “เกิดขึ้นเอง”
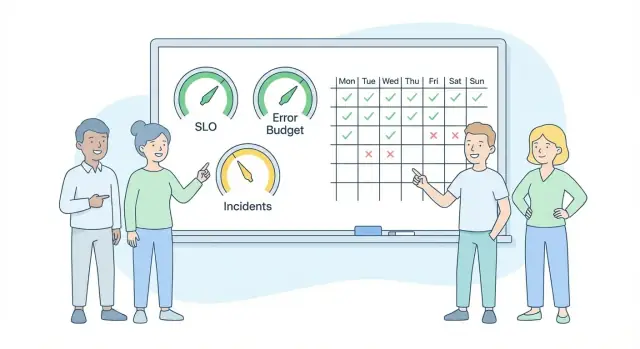
SLO (service level objective) คือคำมั่นชัดเจนเกี่ยวกับประสบการณ์ผู้ใช้ แสดงเป็นตัวเลขในช่วงเวลา ตัวอย่าง: “การชำระเงินสำเร็จอย่างน้อย 99.5% ในช่วง 7 วันที่ผ่านมา” งบข้อผิดพลาดคือปริมาณ "ไม่ดี" ที่อนุญาตภายในคำมั่นนั้น ถ้า SLO คือ 99.5% งบสัปดาห์คือ 0.5% ของการชำระเงินที่ล้มเหลว
นี่ไม่ใช่เรื่องความสมบูรณ์แบบหรือการโอ้อวดความพร้อมใช้งาน มันไม่ใช่กระบวนการหนักหนา ประชุมไม่รู้จบ หรือตารางคำนวณที่ไม่มีใครอัปเดต มันคือวิธีตกลงกันว่า “พอใช้ได้” คืออะไร สังเกตว่าเมื่อไหร่เรากำลังเอนเอียง และตัดสินใจอย่างสงบว่าจะทำอย่างไรต่อไป
เริ่มเล็ก: เลือก 1–3 SLO ที่มองเห็นจากผู้ใช้ เชื่อมกับเส้นทางสำคัญ วัดด้วยสัญญาณที่คุณมีอยู่แล้ว (ข้อผิดพลาด, ความหน่วง, การชำระเงินล้มเหลว) และทำการทบทวนสั้น ๆ รายสัปดาห์ ดูการเผางบและเลือกงานติดตามหนึ่งอย่าง เวลาฝึกเป็นสิ่งสำคัญกว่าชุดเครื่องมือ
คิดความน่าเชื่อถือเหมือนแผนการกินอาหาร คุณไม่ต้องการวันที่สมบูรณ์แบบ คุณต้องการเป้าหมาย วิธีวัด และการเผื่อให้ชีวิตจริง
SLI (service level indicator) คือค่าที่คุณดู เช่น “% คำขอที่สำเร็จ” หรือ “p95 โหลดหน้าไม่เกิน 2 วินาที” SLO คือเป้าหมายของค่านั้น เช่น “99.9% ของคำขอสำเร็จ” งบข้อผิดพลาดคือปริมาณที่คุณพลาด SLO แล้วยังถือว่าอยู่ในเส้นทาง
ตัวอย่าง: ถ้า SLO คือ 99.9% availability งบคือ downtime 0.1% ในหนึ่งสัปดาห์ (10,080 นาที) 0.1% ประมาณ 10 นาที นั่นไม่ใช่คำแนะนำให้พยายามใช้ 10 นาที แต่มันหมายความว่าเมื่อคุณใช้มัน คุณกำลังแลกความน่าเชื่อถือกับความเร็ว การทดลอง หรือการทำฟีเจอร์
คุณค่าคือ: มันเปลี่ยนความน่าเชื่อถือเป็นเครื่องมือตัดสินใจ ไม่ใช่งานรายงาน หากคุณเผางบส่วนใหญ่ภายในวันพุธ ให้หยุดการเปลี่ยนแปลงเสี่ยง ๆ แล้วแก้สิ่งที่พัง ถ้าคุณแทบไม่ใช้เลย ก็ส่งงานได้มั่นใจขึ้น
ไม่ใช่ทุกอย่างต้องการ SLO เดียวกัน แอปสาธารณะอาจต้อง 99.9% เครื่องมือภายในมักคลายบังคับได้เพราะคนสังเกตเห็นน้อยกว่าและผลกระทบเล็กกว่า
อย่าเริ่มจากวัดทุกอย่าง เริ่มจากปกป้องช่วงเวลาที่ผู้ใช้ตัดสินว่าผลิตภัณฑ์ของคุณใช้ได้หรือไม่
เลือก 1–3 เส้นทางผู้ใช้ที่พาไปสู่ความเชื่อถือมากที่สุด หากเส้นทางเหล่านี้มั่นคง ปัญหาอื่น ๆ จะรู้สึกเล็กลง ตัวอย่างที่ดีคือการสัมผัสครั้งแรก (สมัครหรือเข้าสู่ระบบ), ช่วงเวลาจ่ายเงิน (checkout หรืออัปเกรด), และการกระทำหลัก (publish, create, send, upload หรือเรียก API สำคัญ)
เขียนความหมายของ “สำเร็จ” เป็นภาษาง่าย ๆ หลีกเลี่ยงคำศัพท์ทางเทคนิคเช่น “200 OK” เว้นแต่ผู้ใช้ของคุณเป็นนักพัฒนา
ตัวอย่างให้ปรับใช้ได้:
เลือกหน้าต่างการวัดให้ตรงกับความถี่การเปลี่ยนแปลงของคุณ หน้าต่าง 7 วันเหมาะเมื่อคุณปล่อยทุกวันและต้องการฟีดแบ็กเร็ว หน้าต่าง 28 วันเหมาะกว่าเมื่อการปล่อยไม่บ่อยหรือข้อมูลมีสัญญาณรบกวน
ผลิตภัณฑ์เริ่มต้นมีข้อจำกัด: ทราฟฟิคต่ำ (deploy ผิดครั้งเดียวเบี่ยงสถิติ), โฟลว์เปลี่ยนเร็ว, และเทเลเมทรีบางครั้งบางตา ไม่เป็นไร เริ่มจากการนับง่าย ๆ (พยายามเทียบกับความสำเร็จ) ปรับคำนิยามเมื่อเส้นทางหยุดเปลี่ยน
เริ่มจากสิ่งที่คุณส่งวันนี้ ไม่ใช่สิ่งที่คุณอยากมี ช่วงสัปดาห์หรือสองสัปดาห์ จับ baseline สำหรับแต่ละเส้นทางสำคัญ: สำเร็จบ่อยแค่ไหน และล้มเหลวบ่อยแค่ไหน ใช้ทราฟฟิคจริงถ้ามี ถ้าไม่มี ให้ใช้การทดสอบของคุณเอง บวกตั๋วสนับสนุนและล็อก คุณกำลังสร้างภาพคร่าว ๆ ของ “ปกติ”
SLO แรกควรเป็นสิ่งที่คุณทำได้ในส่วนใหญ่ของสัปดาห์ในขณะยังส่งงานได้ หาก baseline เป็น 98.5% อย่าตั้ง 99.9% แล้วหวัง ให้ตั้ง 98% หรือ 98.5% แล้วค่อยเข้มขึ้นทีหลัง
ความหน่วงน่าดึงดูดแต่บางครั้งทำให้ไขว้เขวในช่วงแรก หลายทีมได้ประโยชน์มากกว่าจาก SLO แบบอัตราความสำเร็จก่อน (คำขอเสร็จโดยไม่มีข้อผิดพลาด) ค่อยเพิ่มเรื่อง latency เมื่อผู้ใช้รู้สึกและข้อมูลนิ่งพอ
รูปแบบที่ช่วยคือบรรทัดเดียวต่อเส้นทาง: ใคร, อะไร, เป้าหมาย, และหน้าต่างเวลา
ยืดหน้าต่างสำหรับช่วงเวลาที่เกี่ยวกับเงินและความไว้วางใจ (บิลลิ่ง, การยืนยันตัวตน) และสั้นกว่าสำหรับโฟลว์ประจำวัน เมื่อคุณทำ SLO ได้ง่าย ให้เพิ่มขึ้นทีละน้อย
ทีมเล็กเสียเวลาความน่าเชื่อถือมากเมื่อทุกสะดุดกลายเป็นเตือนฉุกเฉิน เป้าหมายง่าย ๆ คือ: ความเจ็บปวดที่ผู้ใช้เห็นจะใช้จากงบ; ทุกอย่างอื่นจัดการเป็นงานปกติ
ชุดเหตุการณ์เล็ก ๆ ก็เพียงพอ: ล่มทั้งระบบ, ล่มบางส่วน (โฟลว์สำคัญเสีย), ประสิทธิภาพลดลง (ยังใช้งานได้แต่ช้า), deploy ผิดพลาด, และปัญหาข้อมูล (ผิด/ขาด/ซ้ำ)
เก็บมาตราชั้นเดียวและใช้ทุกครั้ง
ตัดสินใจว่าอะไรนับเข้ากับงบ ให้มองความล้มเหลวที่ผู้ใช้เห็นเป็นการใช้: สมัครหรือชำระเงินพัง, timeout ที่ผู้ใช้รู้สึก, spike ของ 5xx ที่หยุดเส้นทาง การบำรุงรักษาที่วางแผนไว้ไม่ควรนับถ้าคุณแจ้งล่วงหน้าและแอปทำงานตามคาดในช่วงนั้น
กฎข้อเดียวช่วยยุติการโต้วาที: ถ้าผู้ใช้ภายนอกจริง ๆ จะสังเกตและไม่สามารถทำเส้นทางที่ปกป้องได้ มันถือเป็นการใช้งบ มิฉะนั้นไม่ใช่
กฎนี้ครอบคลุมกรณีเทาๆ เช่น: บริการภายนอกเจ๊งนับเฉพาะเมื่อมันทำให้เส้นทางผู้ใช้เสีย, ชั่วโมงทราฟฟิคต่ำยังนับถ้าผู้ใช้ได้รับผลกระทบ, และผู้ทดสอบภายในไม่ต้องนับถ้า dogfooding ไม่ใช่การใช้งานหลัก
เป้าหมายไม่ใช่การวัดที่สมบูรณ์แบบ แต่เป็นสัญญาณร่วมที่ทำซ้ำได้ บอกเมื่อความน่าเชื่อถือกำลังมีราคาสูง
สำหรับแต่ละ SLO เลือกแหล่งความจริงแหล่งเดียวแล้วยึดติด: dashboard มอนิเตอร์, log แอป, synthetic check ที่เรียก endpoint หนึ่ง, หรือเมตริกเดียวเช่น successful checkouts ต่อ นาที ถ้าคุณเปลี่ยนวิธีวัด ให้จดวันที่และถือเป็นการรีเซ็ตเพื่อไม่ให้เปรียบเทียบแอปเปิลกับส้ม
เตือนควรสะท้อนการเผางบ ไม่ใช่ทุกสะดุดชั่วคราว พุ่งชั่วคราวอาจน่ารำคาญ แต่ไม่ควรปลุกใครถ้ามันแทบไม่แตะงบเดือน รูปแบบง่ายๆ ที่ใช้ได้คือ: เตือนเมื่อ “เผาเร็ว” (คาดว่าจะเผางบเดือนในหนึ่งวัน) และเตือนเบา ๆ เมื่อ “เผาช้า” (คาดว่าจะเผาในหนึ่งสัปดาห์)
เก็บบันทึกความน่าเชื่อถือเล็ก ๆ เพื่อไม่ต้องพึ่งความจำ บรรทัดเดียวต่อเหตุการณ์พอ: วันที่และระยะเวลา, ผลกระทบต่อผู้ใช้, สาเหตุที่คาด, สิ่งที่เปลี่ยน, และผู้รับผิดชอบติดตามพร้อมวันครบกำหนด
ตัวอย่าง: ทีมสองคนทำ API ใหม่สำหรับแอปมือถือ SLO ของพวกเขาคือ “99.5% ของคำขอสำเร็จ” วัดจากตัวนับตัวเดียว การ deploy ผิดทำให้อัตราสำเร็จเหลือ 97% เป็นเวลา 20 นาที เตือน fast-burn ทำงาน พวกเขาย้อนกลับ และงานติดตามคือ “เพิ่ม canary check ก่อน deploy”
คุณไม่ต้องการกระบวนการใหญ่ คุณต้องการนิสัยเล็ก ๆ ที่ทำให้ความน่าเชื่อถือเห็นได้โดยไม่แย่งเวลาสร้างงาน การตรวจเช็ก 20 นาทีทำงานเพราะมันเปลี่ยนทุกอย่างให้เป็นคำถามเดียว: เรากำลังใช้ความน่าเชื่อถือเร็วกว่าที่วางแผนไหม?
ใช้เวลาบนปฏิทินเดิมทุกสัปดาห์ เก็บโน้ตร่วมที่คุณต่อท้าย (อย่าเขียนทับ) ความสม่ำเสมอชนะรายละเอียด
วาระง่าย ๆ:
ระหว่างงานติดตามและข้อผูกมัด ให้ตัดสินใจเกี่ยวกับกฎการปล่อยของสัปดาห์และทำให้มันน่าเบื่อ:
ถ้าโฟลว์สมัครมีสองครั้งที่ล่มสั้น ๆ และเผางบส่วนใหญ่ คุณอาจ freeze การเปลี่ยนแปลงเกี่ยวกับการสมัครเท่านั้น ในขณะที่ยังส่งงานอื่นได้
งบข้อผิดพลาดมีค่ายิ่งเมื่อมันเปลี่ยนสิ่งที่คุณทำสัปดาห์หน้า จุดประสงค์ไม่ใช่ uptime สมบูรณ์ แต่เพื่อวิธีชัดเจนในการตัดสินใจ: เราจะส่งฟีเจอร์ หรือจ่ายหนี้ความน่าเชื่อถือ?
นโยบายที่พูดออกมาง่าย:
นั่นไม่ใช่การลงโทษ แต่เป็นการแลกเปลี่ยนสาธารณะเพื่อไม่ให้ผู้ใช้จ่ายผลในภายหลัง
เมื่อคุณชะลอ ให้หลีกเลี่ยงงานคลุมเครือเช่น “ปรับความเสถียร” ให้เลือกการเปลี่ยนแปลงที่จะเปลี่ยนผลลัพธ์ครั้งต่อไป: เพิ่ม guardrail (timeout, validation, rate limits), ปรับปรุงเทสต์ที่ควรจับบั๊กนี้, ทำให้ rollback ง่าย, แก้แหล่งข้อผิดพลาดอันดับหนึ่ง, หรือเพิ่มเตือนที่เชื่อมกับเส้นทางผู้ใช้หนึ่งอย่าง
แยกการรายงานออกจากการตำหนิ ให้รางวัลกับการเขียนรายงานเหตุการณ์เร็ว แม้รายละเอียดยุ่งเหยิง เหตุการณ์ที่แย่จริงคือรายงานที่มาช้าเมื่อไม่มีใครจำได้ว่าเปลี่ยนอะไร
กับดักที่พบบ่อยคือการตั้ง SLO ระดับทองตั้งแต่วันแรก (99.99% ฟังดูดี) แล้วค่อยเงียบ ๆ ละเลยเมื่อความเป็นจริงมาเยือน SLO เริ่มต้นควรทำได้ด้วยคนและเครื่องมือที่คุณมี มิฉะนั้นมันจะกลายเป็นเสียงในพื้นหลัง
ความผิดพลาดอีกอย่างคือการวัดสิ่งที่ผิด ทีมดูกราฟหลายบริการกับฐานข้อมูล แต่พลาดเส้นทางที่ผู้ใช้รู้สึกจริง ๆ: สมัคร, ชำระเงิน, หรือ “บันทึกการเปลี่ยนแปลง” ถ้าคุณอธิบาย SLO ได้ไม่ถึงหนึ่งประโยคจากมุมมองผู้ใช้ มันอาจจะเป็นสิ่งภายในมากเกินไป
ความเหนื่อยหน่ายจากการเตือนทำให้คนเดียวที่แก้ production หมดไฟ ถ้าทุก spike เล็ก ๆ โทรปลุกคนนึง บริการโทรปลุกกลายเป็น “ปกติ” และไฟจริงจะถูกพลาด ให้ page เมื่อมีผลต่อผู้ใช้ เส้นทางอื่นส่งไปเช็คเป็นรายวัน
กับดักเงียบ ๆ อีกอย่างคือการนับไม่สม่ำเสมอ สัปดาห์หนึ่งนับ slowdown 2 นาทีเป็น incident สัปดาห์หน้าไม่ นั่นทำให้งบกลายเป็นการถกเถียงแทนที่จะเป็นสัญญาณ จดกฎครั้งเดียวแล้วใช้ให้สม่ำเสมอ
แนวป้องกันที่ช่วย:
ถ้า deploy ทำให้ล็อกอินพัง 3 นาที ให้นับทุกครั้ง แม้จะแก้เร็ว ความสม่ำเสมอคือสิ่งที่ทำให้งบมีประโยชน์
ตั้งจับเวลา 10 นาที เปิดเอกสารร่วม แล้วตอบห้าข้อนี้:
ถ้าคุณวัดอะไรไม่ได้ตอนนี้ ให้เริ่มจากพร็อกซีที่เห็นได้เร็ว: การชำระเงินล้มเหลว, ข้อผิดพลาด 500, หรือตั๋วสนับสนุนที่ติดแท็ก “checkout” แทนพร็อกซีเมื่อการติดตามดีกว่า
ตัวอย่าง: ทีมสองคนเห็นข้อความ “ลืมรหัสไม่ได้รีเซ็ต” สามครั้งในสัปดาห์ หากการรีเซ็ตรหัสเป็นเส้นทางที่ปกป้องได้ นั่นคือ incident พวกเขาเขียนบันทึกสั้น ๆ (เกิดอะไรขึ้น กี่คน ทำอะไร) และเลือกงานติดตามหนึ่งอย่าง: เพิ่มเตือนการรีเซ็ตรหัสหรือลองเพิ่ม retry
Maya และ Jon จัดการสตาร์ทอัพสองคนและปล่อยทุกวันศุกร์ พวกเขาเคลื่อนไหวเร็ว แต่ผู้ใช้จ่ายคนแรก ๆ ให้ความสำคัญกับเรื่องเดียว: สามารถสร้างโปรเจ็กต์และเชิญเพื่อนร่วมงานโดยไม่พังไหม?
สัปดาห์ที่แล้วพวกเขามี outage จริงหนึ่งครั้ง: “สร้างโปรเจ็กต์” ล้มหลัง migration ผิดเป็นเวลา 22 นาที พวกเขายังมีช่วงช้าสามครั้งที่หน้าหมุน 8–12 วินาที ผู้ใช้บ่น แต่ทีมถกเถียงว่า slowdown นับเป็น "ล่ม" ไหม
พวกเขาเลือกเส้นทางเดียวและทำให้วัดได้:
วันจันทร์พวกเขาทำพิธี 20 นาที เวลาเดียว โน้ตร่วมกัน ตอบสี่คำถาม: เกิดอะไร ขนาดการเผางบเท่าไหร่ สิ่งที่เกิดขึ้นซ้ำ และการเปลี่ยนแปลงเดียวที่จะป้องกันไม่ให้ซ้ำ
การแลกเปลี่ยนชัดเจน: outage และช่วงช้าพาให้งบแทบหมด งาน “ฟีเจอร์ใหญ่หนึ่งชิ้น” สัปดาห์หน้าเปลี่ยนเป็น “เพิ่ม index ฐานข้อมูล ทำให้ migration ปลอดภัยขึ้น และเพิ่มเตือน create-project failures”
ผลลัพธ์ไม่ใช่ความน่าเชื่อถือที่สมบูรณ์แบบ แต่เป็นปัญหาที่เกิดซ้ำน้อยลง การตัดสินใจชัดขึ้น และการแก้ไขดึกคือน้อยลง เพราะพวกเขาตกลงกันล่วงหน้าว่า "แย่พอ" คืออะไร
เลือกเส้นทางผู้ใช้หนึ่งเส้นแล้วตั้งคำมั่นเรื่องความน่าเชื่อถือง่าย ๆ บนมัน งบข้อผิดพลาดทำงานได้ดีที่สุดเมื่อมันน่าเบื่อและทำซ้ำได้ ไม่ใช่สมบูรณ์แบบ
เริ่มด้วย SLO หนึ่งและพิธีสั้น ๆ รายสัปดาห์ ถ้ายังง่ายหลังหนึ่งเดือน ให้เพิ่ม SLO ที่สอง ถ้ามันหนักเกินไป ให้ย่อมัน
เก็บคณิตศาสตร์ให้เรียบง่าย (รายสัปดาห์หรือรายเดือน) ตั้งเป้าให้เป็นจริงสำหรับสถานะปัจจุบันของคุณ เขียนโน้ตความน่าเชื่อถือหนึ่งหน้า ที่ตอบ: SLO และวิธีวัด, อะไรนับเป็น incident, ใครรับผิดชอบสัปดาห์นี้, เมื่อใดที่ตรวจเช็ก และทำอย่างไรโดยปริยายเมื่องบเผาเร็วเกินไป
ถ้าคุณสร้างบนแพลตฟอร์มอย่าง Koder.ai (Koder.ai) มันช่วยให้จับคู่การวนซ้ำเร็วกับนิสัยความปลอดภัยได้ดี โดยเฉพาะ snapshot และการ rollback เพื่อให้ "ย้อนกลับสู่สถานะที่ดีล่าสุด" เป็นการกระทำปกติและฝึกฝนได้
เก็บวงจรให้กระชับ: SLO หนึ่ง โน้ตหนึ่ง การตรวจเช็กสั้นหนึ่งครั้งต่อสัปดาห์ เป้าหมายไม่ใช่การกำจัดเหตุการณ์ แต่เป็นการสังเกตตั้งแต่ต้น ตัดสินใจอย่างสงบ และปกป้องไม่กี่อย่างที่ผู้ใช้สัมผัสจริง
SLO คือคำมั่นสัญญาด้านความน่าเชื่อถือเกี่ยวกับประสบการณ์ผู้ใช้ วัดเป็นช่วงเวลา (เช่น 7 หรือ 30 วัน)
ตัวอย่าง: “99.5% ของการชำระเงินสำเร็จใน 7 วันที่ผ่านมา”
งบข้อผิดพลาดคือปริมาณ “สิ่งไม่ดี” ที่อนุญาตให้เกิดขึ้นภายใน SLO ของคุณ
ถ้า SLO ของคุณคือความสำเร็จ 99.5% งบคือความล้มเหลว 0.5% ในหน้าต่างเวลานั้น เมื่อคุณใช้งบเร็วเกินไป คุณจะชะลอการเปลี่ยนแปลงเสี่ยงและแก้สาเหตุ
เริ่มจาก 1–3 เส้นทางการใช้งานที่ผู้ใช้สังเกตได้ทันที:
ถ้าพวกนี้ใช้งานได้ดี ปัญหาอื่นๆ จะดูเล็กลงและจัดลำดับได้ง่ายขึ้น
ตั้ง SLO ที่เป็นจริงได้ในสภาพปัจจุบันของคุณ
ถ้าตอนนี้ 98.5% ให้เริ่มที่ 98–98.5% ดีกว่าประกาศ 99.9% แล้วปล่อยให้เป็นเสียงในพื้นหลัง
ใช้การนับง่ายๆ: พยายามเทียบกับความสำเร็จ (attempts vs successes)
แหล่งข้อมูลเริ่มต้นที่ดี:
อย่ารอการสังเกตที่สมบูรณ์แบบ เริ่มจากตัวแทนที่เชื่อถือได้แล้วปรับปรุงทีหลัง
นับถ้า/เมื่อผู้ใช้ภายนอกจะสังเกตเห็นและไม่สามารถจบเส้นทางที่ปกป้องได้
ตัวอย่างที่ควรนับเข้ากับงบ:
อย่าให้งานภายในเท่านั้นนับเว้นแต่การใช้งานภายในคือการใช้งานหลักของผลิตภัณฑ์
กฎง่ายๆ: แจ้งเตือนตามการเผาผลาญงบ ไม่ใช่ทุกการสะดุดเล็กๆ
รูปแบบที่มีประโยชน์สองแบบ:
วิธีนี้ลดความเหนื่อยหน่ายจากการถูก page บ่อยๆ และโฟกัสที่ปัญหาที่จะเปลี่ยนสิ่งที่คุณปล่อยในสัปดาห์หน้า
ทำให้สั้น 20 นาที เวลาเดียวกัน โน้ตร่วมกัน:
ปิดด้วยโหมดการปล่อยสำหรับสัปดาห์: Normal, Cautious, หรือ Freeze (เฉพาะบริเวณนั้น)
ใช้กฎเป็นค่าเริ่มต้นที่พูดออกมาได้ง่าย:
เป้าหมายคือการแลกเปลี่ยนที่สงบ ไม่ใช่การลงโทษ
ไม่กี่แนวปฏิบัติช่วยให้ส่งงานเร็วและปลอดภัย:
ถ้าคุณสร้างบนแพลตฟอร์มอย่าง Koder.ai ให้ทำให้การ “ย้อนกลับสู่สถานะที่ดีล่าสุด” เป็นการกระทำปกติ และมองการย้อนกลับซ้ำๆ เป็นสัญญาณให้ลงทุนในเทสต์หรือการตรวจสอบก่อนปล่อย