30 ส.ค. 2568·3 นาที
Nginx กับ HAProxy: เลือก Reverse Proxy ที่เหมาะสม
เปรียบเทียบ Nginx และ HAProxy ในฐานะ reverse proxy: ประสิทธิภาพ, การโหลดบาลานซ์, TLS, การสังเกตการณ์, ความปลอดภัย และรูปแบบการตั้งค่าที่นิยมเพื่อเลือกสิ่งที่เหมาะสมที่สุด
เปรียบเทียบ Nginx และ HAProxy ในฐานะ reverse proxy: ประสิทธิภาพ, การโหลดบาลานซ์, TLS, การสังเกตการณ์, ความปลอดภัย และรูปแบบการตั้งค่าที่นิยมเพื่อเลือกสิ่งที่เหมาะสมที่สุด
Reverse proxy คือเซิร์ฟเวอร์ที่อยู่ หน้าบ้าน ของแอปของคุณ รับคำขอจากไคลเอนต์ก่อน แล้วส่งต่อแต่ละคำขอไปยังบริการ backend ที่ถูกต้อง (เซิร์ฟเวอร์แอปของคุณ) จากนั้นส่งผลลัพธ์กลับให้ไคลเอนต์ ผู้ใช้คุยกับพร็อกซี; พร็อกซีคุยกับแอปของคุณ
Forward proxy ทำงานตรงข้าม: มันนั่งอยู่หน้าลูกค้า (เช่น ในเครือข่ายองค์กร) และส่งคำขอออกไปยังอินเทอร์เน็ต จุดประสงค์หลักคือการควบคุม กรอง หรือลบตัวตนของทราฟิกจากฝั่งลูกค้า
Load balancer มักถูกใช้งานเป็น reverse proxy แต่มีจุดมุ่งหมายเฉพาะคือ: กระจายทราฟิกไปยังอินสแตนซ์ backend หลายตัว ผลิตภัณฑ์หลายอย่าง (รวม Nginx และ HAProxy) ทั้งทำ reverse proxy และ load balancing จึงมักใช้สับสนกันได้
การนำไปใช้งานส่วนใหญ่เริ่มจากเหตุผลเหล่านี้อย่างน้อยหนึ่งข้อ:
/api ไปยังบริการ API, / ไปยังเว็บแอป)Reverse proxy มักยืนหน้า เว็บไซต์, API, และ ไมโครเซอร์วิสส์ — ทั้งที่ขอบเครือข่าย (สาธารณะ) หรือภายในระหว่างบริการ ในสแต็กสมัยใหม่ พวกมันยังถูกใช้เป็นส่วนประกอบของ ingress gateway, blue/green deploys, และการตั้งค่า high-availability
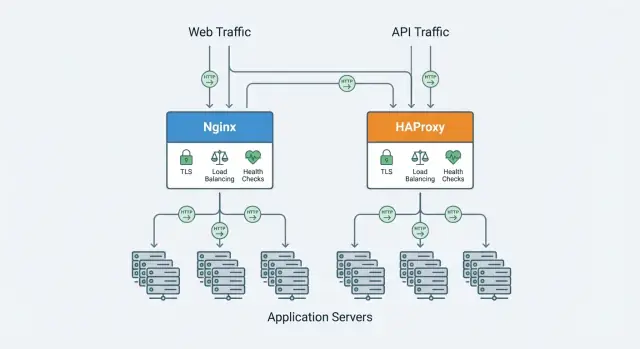
Nginx และ HAProxy ทับซ้อนกัน แต่ต่างกันในรายละเอียด ต่อไปนี้เราจะเปรียบเทียบปัจจัยการตัดสินใจ เช่น ประสิทธิภาพเมื่อมีการเชื่อมต่อจำนวนมาก, load balancing และ health checks, การรองรับโปรโตคอล (HTTP/2, TCP), ฟีเจอร์ TLS, การสังเกตการณ์ (observability), และ การตั้งค่าและปฏิบัติการประจำวัน
Nginx ถูกใช้แพร่หลายทั้งเป็น เว็บเซิร์ฟเวอร์ และ reverse proxy หลายทีมเริ่มด้วยมันเพื่อให้บริการเว็บไซต์สาธารณะ แล้วขยายบทบาทไปอยู่หน้าบริการแอป — จัดการ TLS, กำหนดเส้นทางทราฟิก, และบรรเทาช่วงพีค
Nginx เหมาะเมื่อทราฟิกของคุณเป็น HTTP(S) เป็นหลัก และคุณต้องการ “ประตูหน้า” เดียวที่ทำได้หลากหลาย มันเด่นในการ:
X-Forwarded-For, header ด้านความปลอดภัย)เพราะมันทั้งให้บริการเนื้อหาและพร็อกซีไปยังแอป Nginx จึงเป็นตัวเลือกทั่วไปสำหรับการตั้งค่าเล็กถึงกลางที่ต้องการชิ้นส่วนน้อยลง
ความสามารถยอดนิยมรวมถึง:
Nginx มักถูกเลือกเมื่อคุณต้องการจุดเข้าหนึ่งเดียวสำหรับ:
ถ้าความสำคัญของคุณคือการจัดการ HTTP อย่างครบถ้วนและคุณชอบแนวคิดในการรวมการให้บริการเว็บกับ reverse proxy Nginx มักเป็นค่าเริ่มต้นที่ดี
HAProxy (High Availability Proxy) มักใช้เป็น reverse proxy และ load balancer ที่อยู่หน้าบริการแอป มันรับทราฟิกเข้ามา ใช้กฎ routing/ทราฟิก แล้วส่งคำขอไปยัง backend ที่ healthy — มักทำให้เวลาตอบกลับคงที่แม้ภายใต้ concurrency หนัก
ทีมมักติดตั้ง HAProxy เพื่อ จัดการทราฟิก: กระจายการร้องขอไปยังเซิร์ฟเวอร์หลายเครื่อง ทำให้บริการยังใช้งานได้เมื่อล้มเหลว และบรรเทาช่วงพีค มันเป็นตัวเลือกบ่อยที่ขอบ (north–south) และภายใน (east–west) โดยเฉพาะเมื่อต้องการพฤติกรรมที่คาดเดาได้และการควบคุมการเชื่อมต่อ
HAProxy เด่นเรื่องการจัดการการเชื่อมต่อพร้อมกันจำนวนมาก สิ่งนี้สำคัญเมื่อคุณมีไคลเอนต์จำนวนมากเชื่อมต่อพร้อมกัน (API ที่มีคนใช้เยอะ การเชื่อมต่อยาว เช่น chat) และต้องการให้พร็อกซีตอบสนองได้
ความสามารถในการโหลดบาลานซ์เป็นเหตุผลหลักที่คนเลือก มันรองรับอัลกอริทึมและกลยุทธ์การ routing ที่หลากหลาย ช่วยให้คุณ:
Health checks เป็นอีกจุดแข็ง HAProxy สามารถตรวจสอบ backend แบบ active ได้และนำอินสแตนซ์ที่ไม่ดีออกจากวงจรโดยอัตโนมัติ แล้วใส่กลับเมื่อมันฟื้น คืนค่าเป็นเวลาที่ลด downtime และป้องกันการ deploy ที่ “ครึ่งเสีย” มีผลกระทบต่อผู้ใช้ทั้งหมด
HAProxy สามารถทำงานที่ Layer 4 (TCP) และ Layer 7 (HTTP)
ความแตกต่างเชิงปฏิบัติ: L4 โดยทั่วไปเรียบง่ายและเร็วสำหรับการส่งผ่าน TCP ในขณะที่ L7 ให้การ routing และตรรกะคำขอที่ทรงพลังเมื่อคุณต้องการ
HAProxy มักถูกเลือกเมื่อเป้าหมายหลักคือ โหลดบาลานซ์ที่เชื่อถือได้และประสิทธิภาพสูงพร้อมการตรวจสุขภาพที่แน่นอน — เช่น การกระจายทราฟิก API ข้ามหลายเซิร์ฟเวอร์, จัดการ failover ระหว่าง availability zone, หรือทำหน้าที่หน้าเซอร์วิสที่ปริมาณการเชื่อมต่อและพฤติกรรมทราฟิกมีความสำคัญมากกว่าฟีเจอร์เว็บเซิร์ฟเวอร์ขั้นสูง
การเปรียบเทียบประสิทธิภาพมักผิดพลาดเพราะมองตัวเลขเดียว (เช่น “max RPS”) แล้วละเลยสิ่งที่ผู้ใช้รู้สึก
พร็อกซีอาจเพิ่ม throughput แต่ทำให้ tail latency แย่ขึ้นถ้ามันต่อคิวงานมากเกินไปภายใต้ภาระ
คิดถึง “รูปทรง” ของแอปของคุณ:
ถ้าคุณ benchmark ด้วยรูปแบบหนึ่งแต่ deploy อีกแบบ ผลลัพธ์จะไม่สามารถถ่ายโอนได้
Buffering สามารถ ช่วย เมื่อไคลเอนต์ช้าหรือมีบัสต์ เพราะพร็อกซีอ่านคำขอ/ตอบทั้งหมดแล้วป้อนให้แอปอย่างสม่ำเสมอ
Buffering สามารถ ทำร้าย เมื่อแอปของคุณต้องการสตรีม (SSE, ดาวน์โหลดใหญ่, API เรียลไทม์) เพราะการบัฟเฟอร์เพิ่มแรงกดดันหน่วยความจำและอาจเพิ่ม tail latency
วัดมากกว่า “max RPS”:
ถ้า p95 เพิ่มขึ้นอย่างรวดเร็วก่อนเกิดข้อผิดพลาด คุณกำลังเห็นสัญญาณเตือนว่าใกล้เต็ม ไม่ใช่ “พื้นที่เหลือฟรี”
ทั้ง Nginx และ HAProxy สามารถอยู่หน้าหลายอินสแตนซ์แอปและกระจายทราฟิก แต่ต่างกันในเชิงลึกของฟีเจอร์ที่มากับตัว
Round-robin เป็นค่าเริ่มต้นที่ “พอใช้ได้” เมื่อ backend คล้ายกัน มันเรียบง่าย คาดเดาได้ และเหมาะกับแอป stateless
Least connections มีประโยชน์เมื่อคำขอมีระยะเวลาต่างกัน (ดาวน์โหลด, การเรียก API ยาว, การเชื่อมต่อยาว) มันช่วยกันไม่ให้เซิร์ฟเวอร์ช้าถูกโจมตีด้วยโหลดเพราะจะให้ความสำคัญกับ backend ที่มีคำขอ active น้อยกว่า
Weighted balancing (round-robin แบบมีน้ำหนัก หรือ weighted least connections) เหมาะเมื่อเซิร์ฟเวอร์ไม่เหมือนกัน — ผสม node เก่า/ใหม่ ขนาดอินสแตนซ์ต่างกัน หรือต้องการย้ายทราฟิกทีละน้อย
โดยทั่วไป HAProxy ให้ตัวเลือกอัลกอริทึมมากกว่าและการควบคุมละเอียดกว่า ที่ Layer 4/7 ขณะที่ Nginx ครอบคลุมกรณีทั่วไปอย่างชัดเจน (และสามารถขยายได้ขึ้นกับ edition/module)
Stickiness ทำให้ผู้ใช้ยังคงถูกส่งไปยัง backend เดิมข้ามคำขอ
ใช้ stickiness เฉพาะเมื่อจำเป็นเท่านั้น (เช่น session ฝั่งเซิร์ฟเวอร์แบบเก่า) บริการ stateless มักสเกลและกู้คืนได้ดีกว่า
Active health checks ตรวจสอบ backend เป็นระยะ (endpoint HTTP, การเชื่อมต่อ TCP, สถานะที่คาดหวัง) พวกมันจับความล้มเหลวแม้เมื่อทราฟิกต่ำ
Passive health checks ตอบสนองต่อทราฟิกจริง: timeout, error connection, หรือตอบกลับไม่ดีจะทำให้เครื่องถูกมาร์คว่าไม่ดี พวกมันเบา แต่ตรวจจับปัญหาได้นานกว่า
HAProxy เป็นที่รู้จักเรื่อง การควบคุม health-check และ failure-handling ที่ละเอียด (thresholds, rise/fall counts, การตรวจสอบแบบละเอียด) Nginx ก็รองรับการตรวจสอบที่แข็งแรงเช่นกัน ขึ้นกับการคอมไพล์และ edition
สำหรับ rolling deploys ควรมองหา:
ไม่ว่าจะเลือกอะไร ให้จับคู่ draining กับ timeout สั้นชัดเจนและ endpoint “ready/unready” เพื่อให้ทราฟิกย้ายอย่างราบรื่นระหว่างการ deploy
Reverse proxy อยู่ที่ขอบระบบ ดังนั้นการเลือกโปรโตคอลและ TLS ส่งผลต่อทุกอย่างตั้งแต่ประสิทธิภาพเบราว์เซอร์ถึงวิธีที่บริการสื่อสารกัน
ทั้ง Nginx และ HAProxy สามารถ “terminate” TLS: รับการเชื่อมต่อเข้ารหัสจากลูกค้า ถอดรหัส แล้วส่งคำขอไปยังแอปเป็น HTTP หรือเข้ารหัสใหม่เป็น TLS
ความจริงในทางปฏิบัติคือการจัดการใบรับรอง คุณต้องมีแผนสำหรับ:
Nginx มักถูกเลือกเมื่อต้องการยุติ TLS พร้อมฟีเจอร์เว็บเซิร์ฟเวอร์ (ไฟล์สแตติก, รีไดเรกต์) HAProxy มักถูกเลือกเมื่อ TLS เป็นส่วนหนึ่งของชั้นการจัดการทราฟิก (โหลดบาลานซ์และการจัดการการเชื่อมต่อ)
HTTP/2 ช่วยลดเวลาโหลดเพจโดย multiplexing คำขอหลายรายการผ่านการเชื่อมต่อเดียว ทั้งสองเครื่องมือรองรับ HTTP/2 ฝั่งลูกค้า
ข้อพิจารณาหลัก:
ถ้าคุณต้องการ route ทราฟิกที่ไม่ใช่ HTTP (ฐานข้อมูล, SMTP, Redis, โปรโตคอลกำหนดเอง) คุณต้องการการพร็อกซี TCP มากกว่าการ routing HTTP HAProxy ถูกใช้กันแพร่หลายสำหรับ TCP load balancing ที่มีประสิทธิภาพสูงและการควบคุมการเชื่อมต่อที่ละเอียด Nginx ก็สามารถพร็อกซี TCP ได้เช่นกัน (ผ่านความสามารถ stream) ซึ่งเพียงพอสำหรับการตั้งค่า pass-through แบบตรงไปตรงมาบางอย่าง
mTLS ยืนยันทั้งสองฝ่าย: ไคลเอนต์ต้องแสดงใบรับรอง ไม่ใช่แค่เซิร์ฟเวอร์ เหมาะกับการสื่อสารระหว่างบริการ การผสานกับพันธมิตร หรือการออกแบบ zero-trust ทั้งสองพร็อกซีสามารถบังคับการตรวจสอบใบรับรองของไคลเอนต์ที่ขอบ และหลายทีมยังใช้ mTLS ภายในระหว่างพร็อกซีและ upstream เพื่อย่นระยะความไว้ใจของเครือข่าย
พร็อกซีอยู่ตรงกลางทุกคำขอ จึงมักเป็นที่ดีที่สุดในการตอบคำถามว่า “เกิดอะไรขึ้น?” การสังเกตการณ์ที่ดีหมายถึงล็อกที่สม่ำเสมอ เมตริกสัญญาณชัดเจนไม่กี่ชนิด และวิธีการซ้ำได้ในการดีบัก timeouts และข้อผิดพลาด gateway
อย่างน้อย ควรเปิดใช้งาน access logs และ error logs ในการผลิต สำหรับ access logs ให้รวมเวลาตอบ upstream เพื่อบอกได้ว่าส่วนช้าเกิดจากพร็อกซีหรือแอป
ใน Nginx ฟิลด์ทั่วไปคือเวลาคำขอและเวลา upstream (เช่น $request_time, $upstream_response_time, $upstream_status) ใน HAProxy ให้เปิด HTTP log mode และจับฟิลด์เวลา (queue/connect/response times) เพื่อแยกระหว่าง “รอคิวช่อง backend” กับ “backend ช้า”
เก็บล็อกในรูปแบบมีโครงสร้าง (JSON ถ้าเป็นไปได้) และเพิ่ม request ID (จาก header เข้ามาหรือสร้างใหม่) เพื่อเชื่อมล็อกพร็อกซีและแอปเข้าด้วยกัน
ไม่ว่าจะ scrape Prometheus หรือส่งเมตริกที่อื่น ให้ส่งชุดเดียวกัน:
Nginx มักใช้ stub status endpoint หรือตัวส่งออก Prometheus; HAProxy มี stats endpoint ในตัวที่ exporter หลายตัวอ่านได้
เปิดเผย /health (process ทำงาน) และ /ready (เข้าถึง dependency ได้) ใช้ทั้งสองใน automation: health checks ของ load balancer, การ deploy, และการ auto-scaling
เมื่อตรวจสอบ ให้เทียบเวลาของพร็อกซี (queue/connect) กับเวลา upstream ถ้า queue/connect สูง ให้เพิ่มความสามารถหรือปรับ load balancing; ถ้าเวลา upstream สูง ให้มุ่งแก้ที่แอปหรือฐานข้อมูล
การรันพร็อกซีไม่ใช่แค่เรื่อง throughput สูงสุด แต่ยังเกี่ยวกับทีมของคุณสามารถทำการเปลี่ยนแปลงอย่างปลอดภัยได้เร็วแค่ไหน ไม่ว่าจะตอน 14:00 หรือ 02:00
คอนฟิก Nginx เป็นแบบ directive และมีลำดับชั้น อ่านเหมือน “บล็อกซ้อนบล็อก” (http → server → location) ซึ่งหลายคนพบว่าง่ายเมื่อต้องคิดเป็นไซต์และเส้นทาง
คอนฟิก HAProxy เป็นแนว “pipeline”: นิยาม frontends (สิ่งที่รับ), backends (ส่งไปที่ไหน), แล้วผูกกฎ (ACLs) เพื่อเชื่อมทั้งสอง มันอาจรู้สึกชัดเจนและคาดเดาได้เมื่อเข้าใจโมเดล โดยเฉพาะสำหรับตรรกะการ routing
Nginx มักรีโหลดคอนฟิกโดยเริ่ม worker ใหม่และ drain worker เก่าอย่างนุ่มนวล เหมาะกับการอัปเดตเส้นทางและการต่ออายุใบรับรองบ่อยๆ
HAProxy ก็สามารถรีโหลดแบบ seamless ได้ แต่ทีมมักปฏิบัติต่อมันเหมือน “อุปกรณ์”: ควบคุมการเปลี่ยนแปลงเข้มงวด เวอร์ชันคอนฟิกชัดเจน และประสานงานการรีโหลดอย่างระมัดระวัง
ทั้งสองรองรับการทดสอบคอนฟิกก่อนรีโหลด (จำเป็นสำหรับ CI/CD) ในทางปฏิบัติ คุณมักจะทำให้คอนฟิก DRY โดยการสร้างมัน:
นิสัยการปฏิบัติที่สำคัญ: จัดการคอนฟิกพร็อกซีเป็นโค้ด — รีวิว ทดสอบ และปรับใช้เหมือนการเปลี่ยนแปลงของแอป
เมื่อจำนวนบริการเพิ่มขึ้น ปัญหาที่แท้จริงคือการแพร่ของใบรับรองและการกำหนดเส้นทาง วางแผนสำหรับ:
ถ้าคาดว่าจะมีหลายร้อยโฮสต์ ให้พิจารณาเซ็นทรัลไลส์แพตเทิร์นและสร้างคอนฟิกจากเมตาดาต้าบริการ แทนการแก้ไขไฟล์ด้วยมือ
ถ้าคุณกำลังสร้างและ iterate หลายบริการ พร็อกซีเป็นเพียงส่วนหนึ่งของพายพาธการส่งมอบ — คุณยังต้องการโครงสร้างแอปที่ทำซ้ำได้ ความสอดคล้องของสภาพแวดล้อม และการโรลเอาท์ที่ปลอดภัย
Koder.ai ช่วยทีมให้เร็วขึ้นจาก “ไอเดีย” ไปสู่บริการที่รันได้ โดยสร้าง React เว็บแอป, backend Go + PostgreSQL, และแอปมือถือ Flutter ผ่านเวิร์กโฟลว์แบบแชท พร้อมรองรับ การส่งออกซอร์สโค้ด, การปรับใช้/โฮสติ้ง, โดเมนที่กำหนดเอง, และ snapshot พร้อม rollback ในทางปฏิบัติ นั่นหมายความว่าคุณสามารถโปรโตไทป์ API + เว็บ frontend, ปรับใช้มัน แล้วตัดสินใจว่าจะใช้ Nginx หรือ HAProxy เป็นประตูหน้าตามรูปแบบทราฟิกจริง แทนการเดา
พร็อกซีย้อนกลับนั่งอยู่หน้าระบบของคุณ: ลูกค้าติดต่อกับพร็อกซี แล้วพร็อกซีจะส่งคำขอไปยังบริการ backend ที่ถูกต้องและส่งผลลัพธ์กลับให้ลูกค้า
พร็อกซีไปข้างหน้า (forward proxy) นั่งอยู่หน้าลูกค้าและควบคุมการเข้าถึงอินเทอร์เน็ตของพวกเขา (พบบ่อยในเครือข่ายองค์กร)
ตัวโหลดบาลานเซอร์เน้นที่การแจกจ่ายทราฟิกไปยังอินสแตนซ์ backend หลายตัว หลายตัวโหลดบาลานเซอร์ถูกใช้งานเป็นพร็อกซีย้อนกลับ จึงทำให้คำสองคำนี้ทับซ้อนกันได้
ในทางปฏิบัติ คุณมักจะใช้เครื่องมือหนึ่งตัว (เช่น Nginx หรือ HAProxy) เพื่อทำทั้งสองอย่าง: ทำหน้าที่เป็นพร็อกซีย้อนกลับและเป็นโหลดบาลานเซอร์
วางพร็อกซีที่จุดควบคุมเดียวที่คุณต้องการ:
หลักการคืออย่าให้ไคลเอนต์เข้าถึง backend โดยตรง เพื่อให้พร็อกซีเป็นจุดควบคุมสำหรับนโยบายและการมองเห็น
การยุติ TLS หมายถึงพร็อกซีจัดการ HTTPS: ยอมรับการเชื่อมต่อที่เข้ารหัสจากลูกค้า ถอดรหัส แล้วส่งทราฟิกไปยัง upstream เป็น HTTP หรือเข้ารหัสใหม่เป็น TLS
ทางปฏิบัติ คุณต้องวางแผนเรื่อง:
เลือก Nginx เมื่อพร็อกซีของคุณเป็น “ประตูหน้า” ของเว็บ:
เลือก HAProxy เมื่อการจัดการทราฟิกและความคาดเดาได้ภายใต้ภาระเป็นสิ่งสำคัญ:
ใช้ round-robin เมื่อ backend คล้ายกันและค่าใช้จ่ายต่อคำขอใกล้เคียงกัน
ใช้ least-connections เมื่อระยะเวลาของคำขอแตกต่างกัน (ดาวน์โหลด ไคลเอนต์ยาว) เพื่อไม่ให้เครื่องช้าโดนโหลดหนัก
ใช้ weighted เมื่อ backend แตกต่างกัน (ขนาดอินสแตนซ์ต่างกัน หรือย้ายทีละน้อย) เพื่อกระจายทราฟิกตามน้ำหนักที่ตั้ง
การยึดเซสชัน (stickiness) ทำให้ผู้ใช้ถูกส่งไปยัง backend เดิมในหลายคำขอ
ถ้าเป็นไปได้ หลีกเลี่ยง stickiness: บริการแบบ stateless มักสเกลและกู้คืนได้ดีกว่า
การบัฟเฟอร์ช่วยได้เมื่อไคลเอนต์ช้าหรือเกิดบัสต์ เพราะพร็อกซีอ่านคำขอ/ตอบให้ครบแล้วส่งต่อให้แอปอย่างสม่ำเสมอ
มันจะเป็นปัญหาเมื่อคุณต้องการพฤติกรรมแบบ streaming (SSE, WebSockets, การดาวน์โหลดใหญ่) เพราะการบัฟเฟอร์เพิ่มแรงกดดันหน่วยความจำและอาจทำให้ tail latency แย่ลง
ถ้าแอปของคุณเน้นสตรีม ควรทดสอบและจูนการบัฟเฟอร์อย่างชัดเจน
เริ่มจากการแยกระยะเวลารอของพร็อกซีออกจากการตอบของ backend โดยใช้ล็อกและเมตริก
ความหมายทั่วไป:
สัญญาณที่ใช้งานได้: เวลาคิว/การเชื่อมต่อ (proxy) เทียบกับเวลาตอบ upstream
แก้ไขโดยปรับ timeout, เพิ่มความสามารถของ backend, หรือตั้งค่า health checks/readiness ให้ถูกต้อง