07 ส.ค. 2568·1 นาที
Noam Shazeer และสถาปัตยกรรม Transformer เบื้องหลัง LLMs
เข้าใจบทบาทของ Noam Shazeer ต่อสถาปัตยกรรม Transformer: self-attention, multi-head attention และเหตุผลที่การออกแบบนี้กลายเป็นรากฐานของ LLMs สมัยใหม่
เข้าใจบทบาทของ Noam Shazeer ต่อสถาปัตยกรรม Transformer: self-attention, multi-head attention และเหตุผลที่การออกแบบนี้กลายเป็นรากฐานของ LLMs สมัยใหม่
Transformer คือวิธีช่วยให้คอมพิวเตอร์เข้าใจลำดับข้อมูล—สิ่งที่ลำดับและบริบทมีความหมาย เช่น ประโยค โค้ด หรือชุดคำค้นหา แทนที่จะอ่านทีละโทเค็นแล้วพยายามพกความจำที่เปราะบางไปข้างหน้า Transformers มองไปทั่วทั้งลำดับและตัดสินใจว่าจะให้ความสนใจกับอะไรเมื่อแปลความแต่ละส่วน
การเปลี่ยนมุมมองง่าย ๆ นี้กลับกลายเป็นเรื่องใหญ่ เพราะเป็นเหตุผลหลักที่ทำให้โมเดลภาษาใหญ่ (LLMs) สมัยใหม่สามารถรักษาบริบท ปฏิบัติตามคำสั่ง เขียนย่อหน้าที่สอดคล้อง และสร้างโค้ดที่อ้างถึงฟังก์ชันหรือตัวแปรก่อนหน้านี้ได้
หากคุณเคยใช้แชทบอท ฟีเจอร์ "สรุปข้อความ" การค้นหาเชิงความหมาย หรือผู้ช่วยเขียนโค้ด คุณได้โต้ตอบกับระบบที่ใช้ Transformer แบบฐานเดียวกันแล้ว แบบแปลนนี้รองรับ:
เราจะแยกส่วนสำคัญ—self-attention, multi-head attention, positional encoding และบล็อก Transformer พื้นฐาน—และอธิบายว่าทำไมการออกแบบนี้ถึงสเกลได้ดีเมื่อโมเดลขยายใหญ่ขึ้น
เรายังจะกล่าวถึงรูปแบบสมัยใหม่ที่รักษาแนวคิดหลักไว้ แต่ปรับจูนเพื่อความเร็ว ต้นทุน หรือหน้าต่างบริบทที่ยาวขึ้น
นี่เป็นทัวร์ระดับสูงพร้อมคำอธิบายเป็นภาษาธรรมดาและคณิตศาสตร์น้อยที่สุด เป้าหมายคือสร้างสัญชาตญาณ: ส่วนต่าง ๆ ทำงานอย่างไร ทำไมมันทำงานร่วมกัน และสิ่งนั้นแปลเป็นความสามารถของผลิตภัณฑ์อย่างไร
Noam Shazeer เป็นนักวิจัยและวิศวกร AI ที่เป็นที่รู้จักในฐานะผู้เขียนร่วมของบทความปี 2017 "Attention Is All You Need." บทความนั้นได้แนะนำสถาปัตยกรรม Transformer ซึ่งต่อมากลายเป็นพื้นฐานของ LLMs สมัยใหม่ งานของ Shazeer อยู่ในบริบทของความพยายามเป็นทีม: Transformer ถูกสร้างขึ้นโดยกลุ่มนักวิจัยที่ Google และควรให้เครดิตในลักษณะนั้น
ก่อน Transformer ระบบ NLP หลายตัวพึ่งพาโมเดลลำดับเช่น recurrent models ที่ประมวลผลข้อความทีละก้าว ข้อเสนอ Transformer แสดงให้เห็นว่าสามารถโมเดลลำดับได้อย่างมีประสิทธิภาพโดยไม่ต้องมี recurrence โดยใช้ attention เป็นกลไกหลักในการผสมข้อมูลข้ามประโยค
การเปลี่ยนแปลงนี้สำคัญเพราะทำให้การเทรนขนานได้ง่ายขึ้น (คุณสามารถประมวลผลหลายโทเค็นพร้อมกัน) และเปิดทางให้การสเกลโมเดลและชุดข้อมูลในแบบที่เร็วขึ้นและใช้งานได้จริงในผลิตภัณฑ์
ผลงานของ Shazeer—ควบคู่กับผู้เขียนคนอื่น ๆ—ไม่ได้หยุดอยู่แค่เกณฑ์เชิงวิชาการ Transformer กลายเป็นโมดูลที่นำกลับมาใช้ใหม่ได้ที่ทีมงานสามารถปรับแต่ง: เปลี่ยนชิ้นส่วน ปรับขนาด ปรับแต่งงานสำหรับงานต่าง ๆ และต่อมาฝึกล่วงหน้าในสเกลใหญ่
นี่คือวิธีที่หลาย ๆ เบรกทรูเดินทาง: บทความเสนอสูตรที่ชัดเจนทั่วไป; วิศวกรปรับแต่ง; บริษัทนำไปปฏิบัติ; และในที่สุดมันกลายเป็นตัวเลือกเริ่มต้นสำหรับการสร้างฟีเจอร์ด้านภาษา
ถูกต้องที่จะกล่าวว่า Shazeer เป็นผู้ร่วมมีส่วนสำคัญและเป็นผู้เขียนร่วมของบทความ Transformer แต่ไม่ถูกต้องที่จะกล่าวว่าเขาเป็นผู้ประดิษฐ์คนเดียว ผลกระทบมาจากการออกแบบโดยรวมของทีม—และจากการปรับปรุงต่อ ๆ มาโดยชุมชนและอุตสาหกรรมที่สร้างขึ้นบนสูตรเดิมนั้น
ก่อน Transformers ปัญหาลำดับส่วนใหญ่ (การแปลภาษา การพูด การสร้างข้อความ) ถูกครอบงำโดย Recurrent Neural Networks (RNNs) และต่อมาก็เป็น LSTMs (Long Short-Term Memory networks) ไอเดียหลักคืออ่านข้อความ ทีละโทเค็น เก็บ “ความจำ” แบบกำลังทำงาน (hidden state) และใช้สภาวะนั้นทำนายสิ่งที่จะเกิดขึ้นถัดไป
RNN ประมวลผลประโยคเหมือนโซ่ แต่ละก้าวอัปเดต hidden state โดยอิงจากคำปัจจุบันและ hidden state ก่อนหน้า LSTMs ปรับปรุงจุดนี้โดยเพิ่มเกตที่ตัดสินใจว่าจะเก็บ ลืม หรือส่งออกอะไร—ทำให้รักษาสัญญาณที่เป็นประโยชน์ได้นานขึ้น
ในทางปฏิบัติ ความจำแบบลำดับมีคอขวด: ข้อมูลจำนวนมากต้องถูกบีบผ่านสถานะเดียวเมื่อลำดับยาวขึ้น แม้กับ LSTMs สัญญาณจากคำที่อยู่ไกลอาจจางหายหรือถูกเขียนทับ
สิ่งนี้ทำให้ความสัมพันธ์บางอย่างเรียนรู้ได้ยาก เช่น การเชื่อมคำสรรพนามกับคำนามที่ถูกต้องหลายคำก่อนหน้า หรือการติดตามหัวข้อข้ามหลายประโยค
RNNs และ LSTMs ยัง ช้าในการเทรน เพราะไม่สามารถขนานได้เต็มที่ตามเวลา คุณสามารถแบทช์ข้ามประโยคต่าง ๆ แต่ภายในประโยคหนึ่ง ก้าวที่ 50 ขึ้นกับก้าวที่ 49 ซึ่งขึ้นกับก้าวที่ 48 เป็นต้น
การคำนวณทีละขั้นตอนนี้กลายเป็นข้อจำกัดเมื่อคุณต้องการโมเดลใหญ่ขึ้น ข้อมูลมากขึ้น และการทดลองที่เร็วขึ้น
นักวิจัยต้องการออกแบบที่สามารถเชื่อมคำต่าง ๆ เข้าด้วยกัน โดยไม่ต้องเดินจากซ้ายไปขวาอย่างเคร่งครัดระหว่างการเทรน—วิธีที่จะโมเดลความสัมพันธ์ระยะไกลโดยตรงและใช้ประโยชน์จากฮาร์ดแวร์สมัยใหม่ได้ดีขึ้น ความกดดันนี้เป็นเวทีให้กับแนวทาง attention-first ที่แนะนำใน Attention Is All You Need
Attention คือวิธีที่โมเดลถามว่า: "คำอื่นคำไหนฉันควรดูตอนนี้เพื่อเข้าใจคำนี้?" แทนที่จะอ่านประโยคจากซ้ายไปขวาอย่างเข้มงวดและหวังว่าความจำจะพอเก็บ Attention ให้โมเดลสามารถมองจุดที่เกี่ยวข้องในประโยคเมื่อมันต้องการได้
โมเดลค่อย ๆ ทำงานเหมือนเสิร์ชเอ็นจินเล็ก ๆ ภายในประโยค
โมเดลจึงสร้าง query สำหรับตำแหน่งปัจจุบัน เทียบกับ keys ของทุกตำแหน่ง แล้วดึงการผสมของ values
การเปรียบเทียบเหล่านั้นให้ คะแนนความเกี่ยวข้อง: สัญญาณคร่าว ๆ ว่า "เกี่ยวข้องแค่ไหน" โมเดลเปลี่ยนคะแนนเหล่านี้เป็น น้ำหนัก attention ซึ่งเป็นสัดส่วนที่รวมกันได้ 1
ถ้าคำใดคำหนึ่งเกี่ยวข้องมาก มันจะได้รับสัดส่วนความสนใจมากขึ้น หากหลายคำสำคัญ attention สามารถกระจายไปยังหลายคำได้
ให้ตัวอย่าง: “Maria told Jenna that she would call later.”
เพื่อแปลความ she โมเดลควรมองย้อนกลับไปหาผู้สมัครเช่น “Maria” และ “Jenna” Attention จะให้ค่าน้ำหนักสูงขึ้นกับชื่อที่เข้ากับบริบทที่สุด
หรือพิจารณา: “The keys to the cabinet are missing.” Attention ช่วยเชื่อมคำว่า “are” กับ “keys” (ประธานจริง) ไม่ใช่ “cabinet” แม้ว่า “cabinet” จะอยู่ใกล้กว่า นั่นคือประโยชน์หลัก: attention เชื่อมความหมายข้ามระยะทางตามความจำเป็น
Self-attention คือไอเดียที่ว่าแต่ละโทเค็นในลำดับสามารถมองดูโทเค็นอื่นในลำดับเดียวกันเพื่อกำหนดว่าสิ่งใดสำคัญในตอนนั้น แทนที่จะประมวลผลคำจากซ้ายไปขวา (เหมือนโมเดลลำดับเก่า) Transformer ให้แต่ละโทเค็นรวบรวมเบาะแสจากทุกที่ในอินพุต
จินตนาการประโยค: “I poured the water into the cup because it was empty.” คำว่า “it” ควรเชื่อมโยงกับ “cup” ไม่ใช่ “water” ด้วย self-attention โทเค็นสำหรับ “it” จะให้ความสำคัญมากขึ้นกับโทเค็นที่ช่วยคลี่คลายความหมาย (“cup”, “empty”) และให้ความสำคัญน้อยกับคำที่ไม่เกี่ยวข้อง
หลัง self-attention แต่ละโทเค็นจะไม่ใช่แค่ตัวมันเองอีกต่อไป แต่มันกลายเป็นเวอร์ชันที่รับรู้บริบท—การผสมถ่วงน้ำหนักของข้อมูลจากโทเค็นอื่น ๆ คุณสามารถคิดได้ว่าแต่ละโทเค็นสร้างสรุปเฉพาะบุคคลของทั้งประโยค ปรับให้เข้ากับสิ่งที่โทเค็นนั้นต้องการ
ในทางปฏิบัติ นั่นหมายถึงการแทนค่าของ “cup” สามารถพกสัญญาณจาก “poured”, “water” และ “empty” ขณะที่ “empty” ก็สามารถดึงข้อมูลที่มันบรรยายได้
เพราะแต่ละโทเค็นสามารถคำนวณ attention ของตัวเองเหนือทั้งลำดับพร้อมกัน การเทรนไม่ต้องรอให้โทเค็นก่อนหน้าถูกประมวลผลทีละก้าว การประมวลผลแบบขนานนี้เป็นเหตุผลสำคัญที่ Transformers เทรนได้มีประสิทธิภาพในชุดข้อมูลขนาดใหญ่และสเกลขึ้นสู่โมเดลขนาดใหญ่
Self-attention ทำให้เชื่อมส่วนที่อยู่ไกลของข้อความได้ง่ายขึ้น โทเค็นสามารถมุ่งตรงไปยังคำที่เกี่ยวข้องซึ่งอยู่ไกล โดยไม่ต้องส่งข้อมูลผ่านโซ่ขั้นกลางยาว ๆ
เส้นทางตรงนี้ช่วยงานเช่น coreference ("she", "it", "they"), การติดตามหัวข้อข้ามย่อหน้า และการจัดการคำสั่งที่พึ่งพารายละเอียดก่อนหน้า
Attention เดี่ยวทรงพลัง แต่ยังเหมือนการดูการสนทนาเพียงมุมกล้องมุมเดียว ประโยคมักมีความสัมพันธ์หลายแบบพร้อมกัน: ใครทำอะไร อะไรที่ "it" อ้างถึง คำไหนตั้งโทน และหัวข้อโดยรวมคืออะไร
เมื่อคุณอ่าน “The trophy didn’t fit in the suitcase because it was too small,” คุณอาจต้องติดตามเบาะแสหลายอย่างพร้อมกัน (ไวยากรณ์ ความหมาย และบริบทโลกจริง) หัว attention เดียวอาจจับคำนามที่ใกล้ที่สุด ขณะที่อีกหัวอาจใช้วลีคำกริยาเพื่อตัดสินว่า "it" อ้างถึงอะไร
Multi-head attention รันการคำนวณ attention หลายชุดพร้อมกัน แต่ละ "หัว" ถูกกระตุ้นให้มองประโยคผ่านเลนส์ที่ต่างกัน—มักอธิบายว่าเป็น subspaces ต่างกัน ในทางปฏิบัติ หัวต่าง ๆ สามารถเชี่ยวชาญรูปแบบต่าง ๆ เช่น:
หลังจากแต่ละหัวให้ข้อมูลเชิงลึกของตัวเอง โมเดลไม่ได้เลือกแค่หัวเดียว มัน concatenate เอาผลลัพธ์ของหัวทั้งหมด (วางซ้อนกันแนวนอน) แล้ว project กลับสู่พื้นที่ทำงานหลักของโมเดลด้วยเลเยอร์เชิงเส้นที่เรียนได้
คิดว่าเหมือนการรวมบันทึกย่อหลายฉบับเป็นสรุปเดียวที่ชั้นถัดไปใช้ ผลลัพธ์คือการแทนค่าที่จับความสัมพันธ์หลายแบบพร้อมกัน—หนึ่งในเหตุผลที่ Transformers ทำงานได้ดีเมื่อสเกลขึ้น
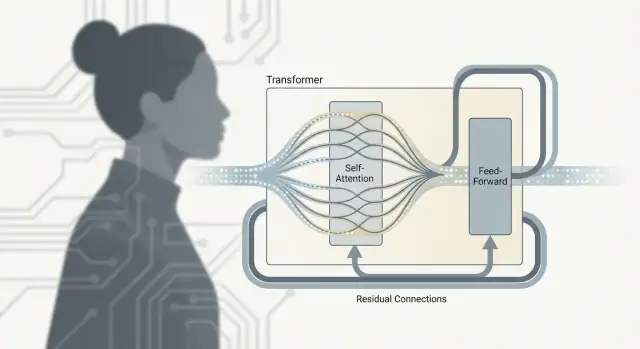
Transformer คือสถาปัตยกรรมเครือข่ายประสาทสำหรับข้อมูลแบบลำดับที่ใช้ self-attention เพื่อให้แต่ละโทเค็นเชื่อมความสัมพันธ์กับโทเค็นอื่น ๆ ภายในอินพุตเดียวกันได้
แทนที่จะสะสมข้อมูลทีละก้าว (แบบ RNNs/LSTMs) มันสร้างบริบทโดยการตัดสินใจว่า ควรให้ความสำคัญกับอะไร ทั่วทั้งลำดับ ซึ่งช่วยให้เข้าใจความสัมพันธ์ระยะไกลได้ดีขึ้นและทำให้การเทรนสามารถขนานกันได้ง่ายขึ้น
RNNs และ LSTMs ประมวลผลข้อความ ทีละโทเค็น ทำให้การเทรนยากต่อการขนานและสร้างคอขวดสำหรับความสัมพันธ์ระยะไกล
Transformers ใช้ attention เพื่อเชื่อมโทเค็นที่อยู่ไกลกันโดยตรง และสามารถคำนวณการปฏิสัมพันธ์ระหว่างโทเค็นหลายคู่พร้อมกันในช่วงการเทรน—ทำให้สามารถสเกลได้เร็วขึ้นด้วยข้อมูลและการคำนวณที่มากขึ้น
Attention คือกลไกที่ตอบคำถาม: "โทเค็นอื่น ๆ ตัวไหนสำคัญที่สุดสำหรับการเข้าใจโทเค็นนี้ตอนนี้?"
คิดว่ามันเหมือนการดึงข้อมูลภายในประโยค:
ผลลัพธ์คือการผสมถ่วงน้ำหนักของโทเค็นที่เกี่ยวข้อง ให้แต่ละตำแหน่งมีการแทนค่าที่รับรู้บริบท
Self-attention หมายความว่าโทเค็นภายในลำดับหันไปให้ความสนใจกับ โทเค็นอื่น ๆ ในลำดับเดียวกัน
นี่คือเครื่องมือหลักที่ช่วยให้โมเดลแก้ปัญหาเช่น coreference (เช่น "it" อ้างถึงอะไร), ความสัมพันธ์ประธาน–กิริยาข้ามประโยค และพึ่งพาที่อยู่ไกลในข้อความ—โดยไม่ต้องส่งทุกอย่างผ่าน “ความจำ” แบบลำดับเดียว
Multi-head attention รันการคำนวณ attention หลายตัวพร้อมกัน และแต่ละหัวสามารถเชี่ยวชาญรูปแบบที่ต่างกันได้
ในทางปฏิบัติ หัวต่าง ๆ มักให้ความสนใจในความสัมพันธ์ที่ต่างกัน (ไวยากรณ์, การเชื่อมโยงระยะไกล, การแก้คำสรรพนาม, สัญญาณหัวข้อ) แล้วโมเดลรวมมุมมองเหล่านี้เข้าด้วยกันเพื่อให้สามารถแทนโครงสร้างหลายแบบพร้อมกันได้
Self-attention เพียงอย่างเดียวไม่ได้รู้ลำดับของคำ—ถ้าสลับคำ โมเดลธรรมดาอาจมองว่าเป็นไปได้เท่าเทียม
Positional encodings แทรกสัญญาณตำแหน่งลงใน embedding ของโทเค็นเพื่อให้โมเดลเรียนรู้รูปแบบเช่น "คำที่ตามหลัง not มีความสำคัญ" หรือโครงสร้างประธานก่อนกริยา
ตัวเลือกทั่วไปได้แก่ sinusoidal (แบบคงที่), learned absolute positions, และวิธี relative/rotary
บล็อก Transformer ส่วนใหญ่รวม:
การซ้อนบล็อกหลาย ๆ ชั้นจึงให้ความลึกที่ช่วยให้เกิดฟีเจอร์ที่ซับซ้อนและพฤติกรรมที่แข็งแรงเมื่อสเกลขึ้น
ต้นฉบับใน Attention Is All You Need เป็นสถาปัตยกรรม encoder–decoder:
LLMs สมัยใหม่ส่วนใหญ่เป็น ฝึกให้ทำนายโทเค็นถัดไปโดยใช้ ซึ่งสอดคล้องกับการสร้างข้อความจากซ้ายไปขวาและสเกลได้ดีบนคอร์ปัสขนาดใหญ่
Noam Shazeer เป็น ผู้เขียนร่วม ในบทความปี 2017 "Attention Is All You Need" ซึ่งแนะนำสถาปัตยกรรม Transformer
ถูกต้องที่จะกล่าวว่าเขาเป็นผู้ร่วมมีส่วนสำคัญ แต่สถาปัตยกรรมนี้ถูกพัฒนาขึ้นโดย ทีม ที่ Google ผลกระทบที่แท้จริงยังมาจากการปรับปรุงและงานติดตามผลที่ชุมชนและอุตสาหกรรมสร้างขึ้นต่อจากแนวคิดต้นฉบับ
สำหรับอินพุตยาว ๆ self-attention แบบมาตรฐานมีค่าใช้จ่ายสูง เพราะการเปรียบเทียบโตขึ้นโดยประมาณตามกำลังสองของความยาวลำดับ ซึ่งส่งผลต่อหน่วยความจำและการคำนวณ
แนวทางปฏิบัติที่ทีมสามารถใช้ได้รวมถึง: