14 พ.ค. 2568·3 นาที
ทำไมภาระงาน OLTP และ OLAP มักไม่ควรอยู่ในฐานข้อมูลเดียวกัน
เรียนรู้ว่าการผสมงานเชิงธุรกรรม (OLTP) กับงานวิเคราะห์ (OLAP) ในฐานข้อมูลเดียวกันทำให้แอปช้าลง เพิ่มค่าใช้จ่าย และซับซ้อนด้านปฏิบัติการอย่างไร — และควรทำอย่างไรแทน
เรียนรู้ว่าการผสมงานเชิงธุรกรรม (OLTP) กับงานวิเคราะห์ (OLAP) ในฐานข้อมูลเดียวกันทำให้แอปช้าลง เพิ่มค่าใช้จ่าย และซับซ้อนด้านปฏิบัติการอย่างไร — และควรทำอย่างไรแทน
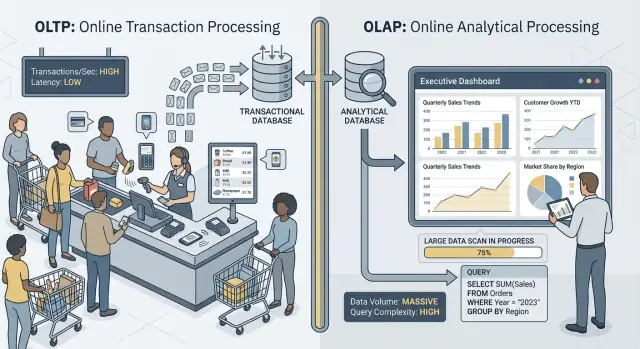
เมื่อคนพูดว่า “OLTP” และ “OLAP” พวกเขากำลังพูดถึงสองรูปแบบการใช้งานฐานข้อมูลที่ต่างกันมาก
OLTP (Online Transaction Processing) คือภาระงานเบื้องหลังการกระทำประจำวันที่ต้องเร็วและถูกต้องเสมอ คิดว่า: “บันทึกการเปลี่ยนแปลงตอนนี้เลย”
งาน OLTP ทั่วไปได้แก่ สร้างคำสั่งซื้อ อัพเดตสต็อก บันทึกการชำระเงิน หรือเปลี่ยนที่อยู่ลูกค้า งานพวกนี้มักเล็ก (ไม่กี่แถว) เกิดบ่อย และต้องตอบกลับภายในมิลลิวินาทีเพราะมีคนหรือระบบรอผล
OLAP (Online Analytical Processing) คือภาระงานที่ใช้เพื่อเข้าใจว่าเกิดอะไรขึ้นและทำไม คิดว่า: “สแกนข้อมูลจำนวนมากแล้วสรุป”
งาน OLAP ทั่วไป ได้แก่ แดชบอร์ด รายงานแนวโน้ม การวิเคราะห์โคฮอร์ต การพยากรณ์ และคำถามแบบ slice-and-dice เช่น: “รายได้เปลี่ยนแปลงอย่างไรตามภูมิภาคและหมวดสินค้าตลอด 18 เดือนที่ผ่านมา?” คิวรีเหล่านี้มักอ่านหลายแถว ทำการคำนวณรวมหนัก ๆ และอาจใช้เวลาวินาทีหรือเป็นนาทีโดยที่ผลลัพธ์ไม่ได้ถือว่า "ผิด" หากไม่เร็วนัก
แนวคิดหลักเรียบง่าย: OLTP ปรับแต่งเพื่อการเขียนที่เร็วและสม่ำเสมอ พร้อมการอ่านขนาดเล็ก ในขณะที่ OLAP ปรับแต่งเพื่อการอ่านจำนวนมากและการคำนวณซับซ้อน เพราะเป้าหมายต่างกัน การตั้งค่าฐานข้อมูล ดัชนี โครงร่างการเก็บข้อมูล และวิธีการสเกลมักต่างกันด้วย
หมายเหตุคำว่า: มักไม่ใช่ไม่เคย ทีมเล็กบางทีมอาจใช้ฐานข้อมูลเดียวกันได้ชั่วคราว โดยเฉพาะเมื่อปริมาณข้อมูลยังน้อยและมีกฎการเขียนคิวรีอย่างเข้มงวด ส่วนตอนหลังจะพูดถึงสิ่งที่จะพังก่อน รูปแบบการแยบ และวิธีย้ายการรายงานออกจาก production อย่างปลอดภัย
OLTP และ OLAP อาจ “ใช้ SQL” เหมือนกัน แต่ถูกปรับจูนเพื่อหน้าที่ต่างกัน—และนั่นสะท้อนในสิ่งที่แต่ละฝั่งถือว่าเป็นความสำเร็จ
ระบบ OLTP ขับเคลื่อนการทำงานประจำวัน: กระบวนการเช็คเอาท์ อัพเดตบัญชี การจอง เครื่องมือสนับสนุน เป้าหมายคือ:
ความสำเร็จมักวัดด้วยเมตริกความหน่วง เช่น p95/p99 อัตราความผิดพลาด และพฤติกรรมภายใต้ภาระพร้อมกันสูง
ระบบ OLAP ตอบคำถามเช่น “อะไรเปลี่ยนแปลงไตรมาสนี้?” หรือ “เซกเมนต์ไหนที่เลิกใช้งานหลังการปรับราคาหรือไม่?” คิวรีเหล่านี้มักจะ:
ความสำเร็จในฝั่งนี้ดูที่ ปริมาณคิวรีที่รองรับได้ เวลาในการได้คำตอบ (time-to-insight) และความสามารถรันคิวรีซับซ้อนได้โดยไม่ต้องปรับจูนทีละรายงาน
เมื่อคุณบังคับให้ทั้งสองภาระงานไปรันบนฐานข้อมูลเดียว คุณกำลังขอให้มันดีทั้งงานธุรกรรมขนาดเล็กที่มีปริมาณสูง และการสแกนขนาดใหญ่พร้อมการสำรวจ ข้อสรุปมักเป็นการประนีประนอม: OLTP มีความหน่วงที่ไม่คาดคิด, OLAP ถูกจำกัดเพื่อปกป้อง production, และทีมมักถกเถียงกันว่าคิวรีของใคร "อนุญาต". เป้าหมายต่างกันสมควรได้ตัวชี้วัดความสำเร็จที่ต่างกัน—และมักได้ระบบที่แยกจากกัน
เมื่อ OLTP (การทำธุรกรรมประจำ) และ OLAP (การรายงาน/วิเคราะห์) รันบนฐานข้อมูลเดียว พวกมันจะแย่งทรัพยากรร่วมกัน ผลลัพธ์ไม่ใช่แค่ "รายงานช้าขึ้น" แต่มักเป็นการเช็คเอาต์ช้าลง การล็อกอินติดขัด และปัญหาแอปที่ไม่คาดคิด
คิวรีเชิงวิเคราะห์มักรันนานและหนัก: join ข้ามตารางใหญ่ การคำนวณรวม การเรียง และการจัดกลุ่ม พวกมันสามารถครอบงำคอร์ CPU และหน่วยความจำสำหรับ hash join และ buffer การเรียง
ในขณะเดียวกัน คิวรีธุรกรรมมักเล็กแต่ไวต่อความหน่วง ถ้า CPU อิ่มหรือหน่วยความจำโดนกดดัน คิวรีสั้นเหล่านั้นจะต้องรอหลังคิวรีใหญ่ ถึงแม้ว่างานแต่ละรายการจะต้องการเวลาเพียงไม่กี่มิลลิวินาทีจริง ๆ
การวิเคราะห์มักทำให้เกิดการสแกนตารางใหญ่และอ่านเพจจำนวนมากแบบต่อเนื่อง OLTP ทำตรงข้าม: การอ่าน/เขียนแบบสุ่มเล็ก ๆ จำนวนมากพร้อมการเขียนดัชนีและล็อก
นำมารวมกัน ระบบเก็บข้อมูลต้องจัดการรูปแบบการเข้าถึงที่ไม่เข้ากัน แคชที่ช่วย OLTP อาจถูก "ชะล้าง" โดยการสแกนของ analytics และความหน่วงการเขียนอาจพุ่งเมื่อดิสก์ถูกใช้สำหรับสตรีมข้อมูลรายงาน
ผู้วิเคราะห์ไม่กี่คนรันคิวรีกว้าง ๆ อาจผูกการเชื่อมต่อไว้เป็นนาที ถ้าแอปใช้ pool ขนาดคงที่ คำขอจะเข้าแถวรอการเชื่อมต่อว่าง การต่อคิวนี้ทำให้ระบบที่ดูเหมือนสุขภาพดีรู้สึกพัง: ค่าเฉลี่ยความหน่วงอาจดูใช้ได้ แต่ความหน่วงชนหาง (p95/p99) กลับเจ็บปวด
จากมุมภายนอก จะเห็นเป็น timeout, กระบวนการเช็คเอาต์ช้า ผลการค้นหาล่าช้า และพฤติกรรมที่ผิดปกติ—มักปรากฏเฉพาะตอนที่มีการรายงานหรือปลายเดือน ทีมแอปเห็น error, ทีม analytics เห็นคิวรีช้า, แต่ปัญหาจริง ๆ คือการแย่งทรัพยากรใต้พื้นผิว
OLTP และ OLAP ไม่ได้แค่ "ใช้ฐานข้อมูลต่างกัน"—พวกมันให้รางวัลกับการออกแบบเชิงกายภาพที่ตรงกันข้าม เมื่อคุณพยายามรองรับทั้งสองในที่เดียว มักได้การประนีประนอมที่แพงแต่ยังไม่ดีพอ
ภาระงานเชิงธุรกรรมถูกครอบงำด้วยคิวรีสั้นที่เข้าถึงข้อมูลส่วนน้อย: ดึงคำสั่งซื้อหนึ่งรายการ อัพเดตแถวสต็อกหนึ่งแถว แสดงเหตุการณ์ล่าสุด 20 รายการของผู้ใช้หนึ่งคน
นั่นทำให้สคีม่า OLTP มุ่งไปที่ storage แบบแถวและดัชนีที่รองรับการค้นหาแบบจุดและช่วงสั้น (มักเป็น primary key, foreign key และดัชนีรองที่สำคัญไม่กี่ตัว) เป้าหมายคือความหน่วงต่ำที่คาดเดาได้ โดยเฉพาะสำหรับการเขียน
ภาระงานวิเคราะห์มักต้องอ่านหลายแถวและแค่บางคอลัมน์: “รายได้ตามสัปดาห์ตามภูมิภาค”, “อัตราแปลงตามแคมเปญ”, “สินค้าท็อปตามมาร์จิ้น”
ระบบ OLAP ได้ประโยชน์จาก storage แบบคอลัมน์ (อ่านเฉพาะคอลัมน์ที่ต้องการ), การพาร์ติชัน (เพื่อตัดข้อมูลเก่า/ไม่เกี่ยวข้อง) และการคำนวณรวมล่วงหน้า (materialized views, rollups, ตารางสรุป) เพื่อให้รายงานไม่ต้องคำนวณซ้ำ ๆ
การตอบสนองทั่วไปคือเพิ่มดัชนีจนทุกแดชบอร์ดเร็วขึ้น แต่ดัชนีทุกชิ้นเพิ่มต้นทุนการเขียน: insert, update, delete ต้องดูแลโครงสร้างมากขึ้น นอกจากนี้ยังเพิ่มพื้นที่เก็บข้อมูลและทำให้การบำรุงรักษาช้าลง เช่น vacuum, reindex, backup
ฐานข้อมูลเลือกรายการวางแผนคิวรีจากสถิติ—การประมาณจำนวนแถวที่ตรงกับตัวกรอง ความเลือกของดัชนี และการกระจายข้อมูล OLTP เปลี่ยนข้อมูลตลอดเวลา เมื่อการกระจายเปลี่ยน สถิติก็อาจคลาดเคลื่อน และ planner อาจเลือกแผนที่ดีเมื่อวานแต่ช้าในวันนี้
ผสมกับคิวรี OLAP หนัก ๆ ที่สแกนและ join ตารางใหญ่มากขึ้น ทำให้ความผันผวนเพิ่มขึ้น: "แผนที่ดีที่สุด" ยากจะทำนาย และการปรับจูนเพื่อภาระงานหนึ่งมักทำให้อีกภาระแย่ลง
แม้ว่าฐานข้อมูลของคุณจะ "รองรับการพร้อมกัน" การผสมระหว่างการรายงานหนักกับธุรกรรมสดสร้างความช้าละเอียดที่ยากจะคาดเดา—และยากอธิบายให้ลูกค้าที่มองเห็นเวลาเช็คเอาต์หมุนดู
คิวรีแบบ OLAP มักสแกนหลายแถว join หลายตาราง และรันเป็นวินาทีหรือเป็นนาที ในช่วงนั้นพวกมันอาจถือ lock (เช่น บนวัตถุสกีมา หรือเมื่อใช้ temp structures) และบ่อยครั้งจะ เพิ่มปัญหาการล็อกโดยอ้อม โดยการทำให้แถวจำนวนมากอยู่ "ในสถานะที่มีการใช้งาน"
แม้มี MVCC (multi-version concurrency control) ฐานข้อมูลยังต้องติดตามหลายเวอร์ชันของแถวเดียวกันเพื่อให้ผู้อ่านและผู้เขียนไม่บล็อกกัน ซึ่งช่วยได้ แต่ไม่ขจัดการแย่งทรัพยากร—โดยเฉพาะเมื่อคิวรีแตะตารางร้อนที่ธุรกรรมอัพเดตตลอดเวลา
MVCC หมายความว่าเวอร์ชันแถวเก่าจะคงอยู่จนกว่าฐานข้อมูลจะสามารถลบได้อย่างปลอดภัย รายงานที่รันนานอาจเปิด snapshot ยาว ซึ่งป้องกันการเก็บกวาดจากการคืนพื้นที่
นั่นส่งผลต่อ:
ผลคือการโดนสองต่อ: การรายงานทำให้ฐานข้อมูลทำงานหนักขึ้น และ ทำให้ระบบช้าลงเมื่อเวลาผ่านไป
เครื่องมือรายงานมักร้องขอ isolation สูงขึ้น (หรือเผลอรันใน transaction ยาว) การ isolation สูงขึ้นทำให้การรอ lock เพิ่มขึ้นและเพิ่มจำนวนเวอร์ชันที่ต้องจัดการ จากฝั่ง OLTP คุณจะเห็นเป็นการพุ่งของความหน่วง: คำสั่งส่วนใหญ่เขียนเร็ว แต่บางรายการดันหยุดนิ่งอย่างไม่คาดคิด
ปลายเดือน ฝ่ายการเงินรันคิวรี "รายได้ตามสินค้า" ที่สแกนคำสั่งซื้อและรายการสินค้าทั้งเดือน ขณะที่คิวรีรัน การเขียนคำสั่งซื้อใหม่ยังรับได้ แต่ vacuum ไม่สามารถเก็บกวาดเวอร์ชันเก่าได้ อินเด็กซ์สึกหรอ ฯลฯ API คำสั่งซื้อเริ่มเห็น timeout — ไม่ใช่เพราะระบบล่ม แต่เพราะการแย่งทรัพยากรและการเก็บกวาดผลักความหน่วงเกินขีดจำกัด
ระบบ OLTP อยู่รอดด้วยความสามารถในการคาดการณ์ การเช็คเอาต์ การอัพเดต หรือการทำงานสนับสนุนไม่ใช่ "โอเคส่วนใหญ่" ถ้ามันเร็ว 95% ของเวลา—ผู้ใช้จะสังเกตช่วงที่ช้าได้ OLAP มักเป็นแบบ bursty: คิวรีหนักไม่กี่ตัวอาจเงียบเป็นชั่วโมงแล้วพุ่งขึ้นและใช้ทรัพยากรมาก
การจราจรทางการวิเคราะห์มักมารวมกันรอบกิจวัตร:
ในขณะที่การจราจร OLTP มักสม่ำเสมอ เมื่อสองภาระงานแชร์ฐานข้อมูล spike ของ analytics จะกลายเป็นความหน่วงที่ไม่คาดคิดสำหรับธุรกรรม—timeout หน้าเว็บ ช้าการโหลด และ retry ที่เพิ่มภาระอีก
คุณลดความเสียหายได้ด้วยยุทธวิธีเช่นรันรายงานกลางคืน จำกัด concurrency ตั้ง statement timeouts หรือกำหนด query cost caps เหล่านี้เป็นเกราะป้องกันที่มีประโยชน์ โดยเฉพาะสำหรับ "การรายงานบน production"
แต่พวกมันไม่แก้ความตึงเครียดพื้นฐาน: คิวรี OLAP ออกแบบมาให้ใช้ทรัพยากรมากเพื่อให้คำตอบของคำถามใหญ่ ขณะที่ OLTP ต้องการเศษทรัพยากรเล็ก ๆ ตลอดวัน เดี๋ยวมีรีเฟรชแดชบอร์ดที่ไม่คาดคิดหรือคิวรี ad-hoc ผ่านมา ระบบร่วมก็จะเปิดเผยปัญหาอีกครั้ง
บนโครงสร้างพื้นฐานร่วม หนึ่งผู้ใช้หรือ job ทาง analytics ที่ "ดัง" สามารถผูก cache อิ่ม ใช้ disk จนเต็ม หรือกด scheduler ของ CPU—โดยไม่ได้ทำอะไรผิด OLTP กลายเป็นผู้ได้รับผลกระทบ และแย่ที่สุดคือความล้มเหลวจะดูเป็นแบบสุ่ม: ความหน่วงพุ่งขึ้นแทนที่จะเป็น error ที่ชัดเจน
การผสม OLTP และ OLAP ไม่ได้สร้างแค่ปัญหาประสิทธิภาพ—มันทำให้การปฏิบัติการประจำวันยากขึ้น ฐานข้อมูลกลายเป็นกล่องเดียวสำหรับทุกอย่าง และงานปฏิบัติการทุกชิ้นต้องรับความเสี่ยงของทั้งสองภาระงาน
ตารางวิเคราะห์มักโตทั้งกว้างและเร็ว (เก็บประวัติมากขึ้น คอลัมน์เพิ่มขึ้น สรุปหลายแบบ) ปริมาณนี้เปลี่ยนเรื่องการกู้คืนให้ยากขึ้น
แบ็คอัพเต็มใช้เวลานานขึ้น ใช้พื้นที่มากขึ้น และเพิ่มโอกาสที่จะพลาดหน้าต่างแบ็คอัพ การกู้คืนแย่กว่า: เมื่อคุณต้องคืนระบบเร็ว คุณกำลังคืนทั้งข้อมูลธุรกรรมที่แอปต้องการและชุดข้อมูลวิเคราะห์ขนาดใหญ่ที่ไม่จำเป็นต่อการเปิดธุรกิจอีกครั้ง การทดสอบการกู้คืนฉุกเฉินก็ใช้เวลานานขึ้น และทำให้น้อยครั้งลง—ตรงกันข้ามกับสิ่งที่คุณควรทำ
การเติบโตของธุรกรรมมักคาดเดาได้: ลูกค้ามากขึ้น คำสั่งซื้อเพิ่มขึ้น แถวเพิ่มขึ้น การเติบโตของการวิเคราะห์มักกระโดด: แดชบอร์ดใหม่ นโยบายการเก็บรักษาใหม่ หรือทีมตัดสินใจเก็บ "แค่ปีเดียว" ของกิจกรรมดิบ
เมื่อทั้งสองอยู่ด้วยกัน คุณตอบยากว่า:
ความไม่แน่นอนนี้นำไปสู่การ provision เกินความจำเป็น (จ่ายเพิ่มแต่ไม่ได้ใช้) หรือ provision น้อยไป (ล่มแบบเซอร์ไพรส์)
ในฐานข้อมูลร่วม คิวรี "บริสุทธิ์" หนึ่งชิ้นอาจกลายเป็นเหตุการณ์ คุณจะเพิ่มเกราะป้องกันเช่น statement timeouts โควต้าภาระงาน หน้าต่างการรายงานที่ตั้งเวลา หรือกฎการจัดการภาระงาน สิ่งเหล่านี้ช่วยได้แต่เปราะ: แอปกับนักวิเคราะห์แข่งขันกันในข้อจำกัดเดียว และการเปลี่ยนแปลงนโยบายสำหรับกลุ่มหนึ่งอาจทำให้อีกกลุ่มพัง
แอปมักต้องการสิทธิจำกัดเฉพาะงาน นักวิเคราะห์มักต้องการสิทธิอ่านกว้าง ๆ ข้ามหลายตารางเพื่อสำรวจและตรวจสอบ การรวมทั้งสองไว้ในฐานข้อมูลเดียวเพิ่มแรงกดดันให้ขยายสิทธิออกไป "เพื่อให้รายงานทำงานได้" ซึ่งเพิ่ม blast radius ของความผิดพลาดและขยายจำนวนคนที่เห็นข้อมูลที่ละเอียดอ่อน
พยายามรัน OLTP และ OLAP ในฐานข้อมูลเดียวมักดูเหมือนถูกกว่า—จนกว่าคุณจะเริ่มสเกล ปัญหาไม่ใช่แค่ประสิทธิภาพ แต่คือวิธีที่แต่ละภาระงานควรสเกลซึ่งผลักดันให้คุณต้องเลือกโครงสร้างพื้นฐานต่างกัน และการรวมกันบีบบังคับให้เกิดการประนีประนอมที่มีราคาแพง
ระบบธุรกรรมถูกจำกัดด้วยการเขียน: อัพเดตเล็ก ๆ จำนวนมาก ความหน่วงเข้มงวด และพีกที่ต้องรับได้ทันที การสเกล OLTP มักหมายถึงการสเกลแนวตั้ง (CPU ใหญ่ขึ้น ดิสก์เร็วขึ้น หน่วยความจำมากขึ้น) เพราะภาระงานที่เน้นเขียนไม่ค่อยขยายได้ง่าย
เมื่อถึงขีดจำกัดแนวตั้ง คุณต้องพิจารณา sharding หรือแพตเทิร์นการสเกลการเขียนอื่น ๆ ซึ่งเพิ่มภาระวิศวกรรมและมักต้องเปลี่ยนแอป
ภาระงานวิเคราะห์สเกลต่างกัน: การสแกนยาว การคำนวณรวมหนัก และ throughput การอ่านสูง ระบบ OLAP มักสเกลด้วยการเพิ่ม compute แบบกระจายและแยก compute จาก storage เพื่อให้เพิ่มพลังการคิวรีโดยไม่ต้องย้ายหรือทำสำเนาข้อมูล
ถ้า OLAP แชร์ฐานข้อมูล OLTP คุณไม่สามารถสเกลการวิเคราะห์แยกได้ คุณต้องสเกลทั้งฐานข้อมูล—แม้ว่าการทำธุรกรรมจะยังไหวก็ตาม
เพื่อให้ธุรกรรมเร็วขณะรันรายงาน ทีมมัก over-provision ฐานข้อมูล production: เพิ่ม CPU เผื่อไว้, storage ระดับพรีเมียม, และ instance ขนาดใหญ่ขึ้น "กันไว้ไงไม่ต้องคิด" นั่นหมายความว่าคุณจ่ายราคา OLTP เพื่อรองรับพฤติกรรม OLAP
การแยกระบบช่วยลดการ provision เกินความจำเป็น เพราะแต่ละระบบถูกปรับขนาดตามงาน: OLTP เพื่อการเขียนหน่วงต่ำที่คาดเดาได้, OLAP เพื่อการอ่านหนักเป็นครั้งคราว ผลคือมักถูกกว่าโดยรวม—แม้จะเป็น "สองระบบ"—เพราะคุณเลิกจ่ายสำหรับ capacity ระดับพรีเมียมเพื่อรันรายงานบน production
ทีมส่วนใหญ่แยก ภาระงานเชิงธุรกรรม (OLTP) ออกจาก ภาระงานวิเคราะห์ (OLAP) โดยเพิ่มระบบอ่านหรือระบบวิเคราะห์แยกต่างหาก แทนที่จะบังคับให้ฐานข้อมูลเดียวให้บริการทั้งคู่
ก้าวแรกที่พบบ่อยคือ read replica ของฐานข้อมูล OLTP ที่เครื่องมือ BI รันคิวรี
ข้อดี: เปลี่ยนแปลงแอปน้อย, SQL คุ้นเคย, ติดตั้งเร็ว
ข้อเสีย: ยังเป็นเอนจินและสกีม่าเดียวกัน รายงานหนักอาจอิ่ม CPU/I/O ของ replica; บางรายงานต้องการฟีเจอร์ที่ replica ไม่มี; และ replication lag ทำให้ตัวเลขอาจล้าหลังเป็นนาที (หรือมากกว่า) Lag ยังสร้างบทสนทนา "ทำไมไม่ตรงกับ production" ตอนเกิดเหตุ
เหมาะที่สุด: ทีมเล็ก ปริมาณข้อมูลพอประมาณ "เกือบเรียลไทม์" ดีแต่ไม่วิกฤต และคิวรีรายงานถูกควบคุม
OLTP ยังคงปรับแต่งเพื่อการเขียนและการอ่านจุด ในขณะที่การวิเคราะห์ย้ายไปยัง data warehouse (หรือ DB แบบคอลัมน์) ที่ออกแบบมาสำหรับการสแกน การบีบอัด และการคำนวณรวมขนาดใหญ่
ข้อดี: ประสิทธิภาพ OLTP ที่คาดเดาได้, แดชบอร์ดเร็วขึ้น, รองรับผู้วิเคราะห์พร้อมกันได้ดีขึ้น, และการจูนค่าใช้จ่ายชัดเจน
ข้อเสีย: คุณต้องดูแลระบบอีกชุดและต้องมี data model (มักเป็น star schema) ที่เป็นมิตรกับการวิเคราะห์
เหมาะที่สุด: ข้อมูลโตขึ้น หลายผู้มีส่วนได้ส่วนเสีย รายงานซับซ้อน หรือต้องการ latency ของ OLTP ต่ำมาก
แทนการทำ ETL แบบเป็นช่วง คุณสตรีมการเปลี่ยนแปลงด้วย CDC จาก log ของ OLTP ไปยัง warehouse (มักทำเป็น ELT)
ข้อดี: ข้อมูลสดขึ้นโดยมีภาระน้อยลงบน OLTP, การประมวลผล incremental ง่ายขึ้น, และ auditability ดีขึ้น
ข้อเสีย: มีชิ้นส่วนมากขึ้นและต้องจัดการการเปลี่ยนสกีมาอย่างระมัดระวัง
เหมาะที่สุด: ปริมาณใหญ่ ความต้องการ freshness สูง และทีมพร้อมสำหรับ pipeline
การย้ายข้อมูลจากฐานข้อมูลเชิงธุรกรรม (OLTP) ไปยังระบบวิเคราะห์ (OLAP) ไม่ใช่แค่ "คัดลอกตาราง" แต่เป็นการสร้าง pipeline ที่เชื่อถือได้และมีผลกระทบน้อย เป้าหมายคือให้ analytics ได้ข้อมูลที่ต้องการโดยไม่เสี่ยงต่อทราฟฟิค production
ETL (Extract, Transform, Load) คือการทำความสะอาดและปรับรูปรายการก่อนที่จะโหลดเข้า warehouse เหมาะเมื่อการคำนวณใน warehouse แพง หรือคุณต้องการควบคุมสิ่งที่จะเก็บอย่างเข้มงวด
ELT (Extract, Load, Transform) โหลดข้อมูลดิบก่อนแล้วแปลงภายใน warehouse มักตั้งค่าได้เร็วและเปลี่ยนแปลงง่าย: คุณเก็บประวัติแหล่งข้อมูลและปรับทรานส์ฟอร์มเมื่อความต้องการเปลี่ยน
กฎปฏิบัติ: ถ้าตรรกะธุรกิจเปลี่ยนบ่อย ELT ลดงานซ้ำ; ถ้าการกำกับดูแลต้องการข้อมูลที่คัดกรองแล้วอย่างเข้มงวด ETL อาจเหมาะกว่า
Change Data Capture (CDC) สตรีม insert/update/delete จาก OLTP (มักจาก log) ไปยังระบบวิเคราะห์ แทนการสแกนตารางใหญ่ซ้ำ ๆ CDC ให้คุณย้ายเฉพาะสิ่งที่เปลี่ยน
ประโยชน์:
ความสดเป็นการตัดสินใจเชิงธุรกิจพร้อมต้นทุนทางเทคนิค
กำหนด SLA ชัดเจน (เช่น: “ข้อมูลหน่วงไม่เกิน 15 นาที”) เพื่อให้ผู้มีส่วนได้ส่วนเสียเข้าใจความหมายของคำว่า "สด"
pipeline มักพังเงียบ ๆ—จนกว่าจะมีคนสังเกตตัวเลขไม่ตรง เพิ่มการตรวจแบบเบา ๆ สำหรับ:
การป้องกันเหล่านี้ทำให้ OLAP เชื่อถือได้ในขณะที่ปกป้อง OLTP
การเก็บ OLTP และ OLAP ไว้ด้วยกันไม่ใช่ "ผิดเสมอไป" มันอาจเป็นทางเลือกที่สมเหตุสมผลชั่วคราวเมื่อแอปเล็ก การวิเคราะห์เบา และคุณบังคับขอบเขตอย่างเข้มงวดเพื่อไม่ให้การวิเคราะห์มาทำให้การชำระเงินช้าหรือ timeout
แอปเล็กที่มีการวิเคราะห์เบาและจำกัดการรันคิวรี มักพออยู่ในฐานข้อมูลเดียวได้—โดยเฉพาะช่วงแรก จุดสำคัญคือต้องซื่อสัตย์กับความหมายของ "เบา": แดชบอร์ดไม่กี่ชิ้น จำนวนแถวพอประมาณ และเพดานเวลารันคิวรีชัดเจน
สำหรับชุดรายงานที่ซ้ำ ๆ และจำกัด materialized views หรือ summary tables ลดต้นทุนการวิเคราะห์ แทนการสแกนธุรกรรมดิบ คุณคำนวณสรุปเป็นรายวันหรือรายชั่วโมง ทำให้คิวรีส่วนใหญ่สั้นและคาดเดาได้
ถ้าผู้ใช้ยอมรับความล่าช้า หน้าต่างการรายงานนอกช่วงพีค ช่วยได้ ตั้งงานหนักตอนกลางคืนหรือช่วงที่คนใช้น้อย และพิจารณา role การรายงานที่มีสิทธิและข้อจำกัดทรัพยากรเข้มงวด
ถ้าคุณเห็น latency ธุรกรรมเพิ่มขึ้นเป็นประจำ เหตุการณ์ระหว่างการรันรายงาน การหมด connection pool หรือเรื่อง "คิวรีหนึ่งทำให้ production ล่ม" แปลว่าคุณพ้นโซนปลอดภัยแล้ว การแยกฐานข้อมูลหรืออย่างน้อยใช้ replica จะกลายเป็นเรื่องพื้นฐานในการดูแลระบบ ไม่ใช่แค่การปรับแต่ง
การย้ายการวิเคราะห์ออกจากฐานข้อมูล production เป็นเรื่องของการทำให้งานมองเห็นได้ ตั้งเป้า และย้ายทีละน้อย
เริ่มด้วยหลักฐาน ไม่ใช่สมมติ คัดรายการ:
รวมการวิเคราะห์ "ซ่อนอยู่": SQL ad-hoc จาก BI tools งานที่ตั้งเวลา และการส่งออก CSV
เขียนเป้าหมายที่คุณจะปรับแต่งเพื่อ:
นี่ช่วยหลีกเลี่ยงการถกเถียงว่า "ช้าไหม" กับ "โอเคไหม" และช่วยเลือกสถาปัตยกรรม
เลือกตัวเลือกง่ายสุดที่ตอบโจทย์:
ตั้งการมอนิเตอร์สำหรับ replica lag/pipeline delays เวลารันแดชบอร์ด และค่าใช้จ่าย warehouse เพิ่ม query budgets (timeouts, concurrency limits) และมี playbook ชัดเจน: ต้องทำอย่างไรเมื่อ freshness ลดลง โหลดพุ่ง หรือเมตริกสำคัญเบี้ยว
ถ้าคุณยังเริ่มเร็ว ความเสี่ยงใหญ่คือเผลอสร้างการวิเคราะห์เข้าไปในเส้นทางฐานข้อมูลเดียวกับธุรกรรมหลัก (เช่น คิวรีแดชบอร์ดที่กลายเป็น "สำคัญต่อ production") วิธีหลีกเลี่ยงคือออกแบบการแยกไว้แต่แรก—แม้จะเริ่มด้วย read replica ก็ตาม—และใส่มันในเช็คลิสต์สถาปัตยกรรม
แพลตฟอร์มอย่าง Koder.ai ช่วยได้ตรงนี้เพราะคุณสามารถจำลองฝั่ง OLTP (React app + Go services + PostgreSQL) และร่างขอบเขตการรายงาน/warehouse ในโหมด planning ก่อน deploy เมื่อผลิตภัณฑ์โตขึ้น คุณสามารถ export โค้ด ขยายสคีมา และเพิ่ม CDC/ELT โดยไม่ปล่อยให้ "รายงานบน production" กลายเป็นนิสัยถาวร
OLTP (Online Transaction Processing) รับผิดชอบการทำงานประจำวัน เช่น การสร้างคำสั่งซื้อ การอัพเดตสินค้าคงคลัง และการบันทึกการชำระเงิน โฟกัสที่ ความหน่วงต่ำ ความสามารถในการรองรับพร้อมกันสูง และ ความถูกต้องของข้อมูล.
OLAP (Online Analytical Processing) ตอบคำถามเชิงธุรกิจด้วยการสแกนและสรุปข้อมูลจำนวนมาก (แดชบอร์ด แนวโน้ม โคฮอร์ต) โดยให้ความสำคัญกับ throughput การวิเคราะห์ที่ยืดหยุ่น และการสรุปข้อมูล ไม่ได้เน้นการตอบกลับในระดับมิลลิวินาที.
เพราะภาระงานทั้งสองแย่งทรัพยากรชุดเดียวกัน:
ผลลัพธ์คือค่าสถิติหาง (p95/p99) ของการทำงานหลักไม่แน่นอนและช้าลงเป็นครั้งคราว.
โดยทั่วไปไม่ใช่ทางออกที่ดี การเพิ่มดัชนีเพื่อให้แดชบอร์ดเร็วขึ้นมักย้อนกลับได้เพราะ:
สำหรับงานวิเคราะห์ มักได้ผลดีกว่าจาก ในระบบที่ออกแบบมาสำหรับ OLAP.
MVCC ช่วยลดการบล็อกระหว่างผู้อ่านกับผู้เขียน แต่ไม่ได้แก้ปัญหาการทำงานร่วมกันอย่างสิ้นเชิง:
แม้ไม่มีการล็อกชัดเจนแล้ว การวิเคราะห์หนักๆ ก็ทำให้ระบบช้าลงตามเวลาได้.
คุณมักเห็นสัญญาณเช่น:
ถ้าระบบช้าหรือเกิดปัญหาแบบสุ่มในตอนรีเฟรชแดชบอร์ด แปลว่าเป็นสัญญาณชัดเจนว่าควรแยก.
Replica อ่านเป็นก้าวแรกที่พบบ่อย:
เหมาะเมื่อปริมาณข้อมูลไม่มากและการหน่วงเป็น "นาที" ยังยอมรับได้.
คลังข้อมูล (data warehouse) เหมาะเมื่อคุณต้องการ:
โดยปกติจำเป็นต้องมีโมเดลที่เหมาะกับการวิเคราะห์ (เช่น star/snowflake) และ pipeline สำหรับโหลดข้อมูล.
CDC (Change Data Capture) สตรีมการ insert/update/delete จากฐานข้อมูล OLTP (มักจาก log) ไปยังระบบวิเคราะห์.
ข้อดีคือ:
ข้อแลกเปลี่ยนคือเพิ่มความซับซ้อนของระบบและต้องจัดการการเปลี่ยนแปลงสกีมาอย่างระมัดระวัง.
เลือกตามความถี่ที่ตรรกะธุรกิจเปลี่ยนและสิ่งที่ต้องการเก็บ:
แนวปฏิบัติ: เริ่มด้วย ELT เพื่อความเร็ว แล้วเพิ่ม governance (tests, curated models) เมื่อเมตริกสำคัญนิ่งขึ้น.
ได้ — แบบชั่วคราวและในเงื่อนไขที่เข้มงวด หากคุณ:
แต่ถ้าการรายงานเริ่มทำให้ latency พุ่งหรือเกิดเหตุการณ์ต่อเนื่อง ก็ควรแยกระบบทันที.