30 ส.ค. 2568·3 นาที
แบบจำลองความคิดง่าย ๆ ว่า AI คิดอย่างไรเมื่อสร้างแอป
แบบจำลองความคิดที่ชัดเจนสำหรับการที่ AI สร้างโค้ดและตัดสินใจในแอป—โทเค็น บริบท เครื่องมือ และการทดสอบ—พร้อมขีดจำกัดและเคล็ดลับการพรอมต์เชิงปฏิบัติ
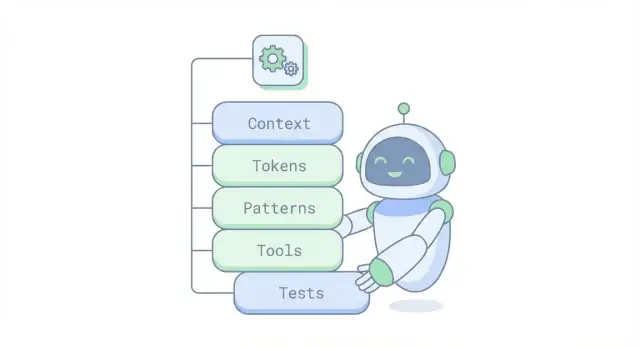
แบบจำลองความคิดที่ชัดเจนสำหรับการที่ AI สร้างโค้ดและตัดสินใจในแอป—โทเค็น บริบท เครื่องมือ และการทดสอบ—พร้อมขีดจำกัดและเคล็ดลับการพรอมต์เชิงปฏิบัติ
เมื่อคนพูดว่า “AI คิด” พวกเขามักหมายถึงบางอย่างประมาณว่า: มันเข้าใจคำถามของคุณ ให้เหตุผล แล้วตัดสินใจตอบ
สำหรับ AI สมัยใหม่ที่ใช้ข้อความ (LLM) แบบจำลองทางความคิดที่มีประโยชน์กว่าคือแบบที่เรียบง่ายกว่า: โมเดลทำนายว่า ข้อความอะไรควรจะมาต่อไป
ฟังดูธรรมดา—จนกว่าคุณจะเห็นว่าการทำนาย “ข้อความถัดไป” ไปได้ไกลแค่ไหน หากโมเดลเรียนรู้รูปแบบจากการฝึกพอ เพียงแค่ทำนายคำถัดไป (และคำถัดไป) ก็สามารถสร้างคำอธิบาย แผน โค้ด สรุป และแม้แต่ข้อมูลเชิงโครงสร้างที่แอปของคุณใช้ได้
คุณไม่จำเป็นต้องเรียนรู้คณิตศาสตร์พื้นฐานทั้งหมดเพื่อสร้างฟีเจอร์ AI ที่ดี สิ่งที่คุณต้องการคือวิธีปฏิบัติที่คาดพฤติกรรมได้ดี:
บทความนี้คือแบบจำลองประเภทนั้น: ไม่ใช่การโฆษณาเกินจริง ไม่ใช่งานวิชาการเชิงลึก—แค่แนวคิดที่จะช่วยให้คุณออกแบบประสบการณ์ผลิตภัณฑ์ที่เชื่อถือได้
สำหรับผู้สร้างแอป การ “คิด” ของโมเดลคือข้อความที่มันสร้างขึ้นเพื่อตอบอินพุตที่คุณให้มา (พรอมต์ ข้อความของผู้ใช้ กฎระบบ และเนื้อหาที่ดึงมา) โมเดลไม่ได้ตรวจสอบข้อเท็จจริงโดยอัตโนมัติ ไม่ได้ท่องเว็บ และไม่ได้ “รู้” ว่าฐานข้อมูลของคุณมีอะไร เว้นแต่คุณจะส่งข้อมูลนั้นเข้าไป
ตั้งความคาดหวังให้เหมาะสม: LLM มีประโยชน์มากในการร่าง แปลง เอกสารจำแนก และสร้างเอาต์พุตที่เหมือนโค้ด แต่มันไม่ใช่เครื่องยนต์แห่งความจริงวิเศษ
เราจะแยกแบบจำลองความคิดเป็นส่วนต่าง ๆ ดังนี้:
ด้วยแนวคิดเหล่านี้ คุณจะออกแบบพรอมต์ UI และกลไกป้องกันเพื่อให้ฟีเจอร์ AI รู้สึกสม่ำเสมอและเชื่อถือได้
เมื่อคนพูดว่า AI “คิด” มักนึกภาพว่าเหมือนการให้เหตุผลแบบคน แต่แบบจำลองที่มีประโยชน์กว่าและเรียบง่ายกว่าคือ: มันทำ autocomplete อย่างรวดเร็วทีละชิ้น
โทเค็น คือชิ้นส่วนของข้อความที่โมเดลทำงานด้วย บางครั้งเป็นคำเต็ม ("apple"), บางครั้งเป็นส่วนของคำ ("app" + "le"), บางครั้งเป็นเครื่องหมายวรรคตอน หรือแม้แต่ช่องว่าง การแบ่งชิ้นขึ้นกับ tokenizer ของโมเดล แต่ข้อสรุปคือ: โมเดลไม่ได้ประมวลผลเป็นประโยคสวยงาม มันประมวลผลเป็นโทเค็น
วงลูปหลักของโมเดลคือ:
แค่นั้นเอง ทุกย่อหน้า รายการหัวข้อ และลำดับเหตุผลที่คุณเห็น ถูกสร้างจากการทำนายโทเค็นถัดไปซ้ำๆ
เพราะโมเดลเห็นข้อความจำนวนมหาศาลในการฝึก มันเรียนรู้รูปแบบเช่น วิธีการอธิบาย วิธีเขียนอีเมลสุภาพ หรือวิธีอธิบายการแก้บั๊ก เมื่อคุณถาม มันจะสร้างคำตอบที่ ตรงกับรูปแบบ ที่เรียนรู้และสอดคล้องกับบริบทที่ให้มา
นี่คือเหตุผลที่มันอาจฟังดูมั่นใจและสอดคล้องแม้จะผิด: มันกำลังปรับเพื่อให้ข้อความต่อไปเหมาะสม ไม่ใช่เพื่อตรวจสอบความเป็นจริง
โค้ดไม่พิเศษสำหรับโมเดล JavaScript, SQL, JSON และข้อความแสดงความผิดพลาดก็เป็นลำดับของโทเค็น โมเดลสามารถสร้างโค้ดที่เป็นประโยชน์ได้เพราะมันเรียนรู้รูปแบบการเขียนโค้ด ไม่ใช่เพราะมัน “เข้าใจ” แอปของคุณเหมือนวิศวกรในทีมคุณ
เมื่อคนถามว่า “โมเดลได้คำตอบมาจากไหน?” โมเดลเรียนรู้ รูปแบบ จากตัวอย่างจำนวนมาก แล้วนำรูปแบบเหล่านั้นมารวมกันเพื่อทำนายข้อความถัดไป
ในการฝึก โมเดลถูกโชว์ข้อความจำนวนมาก (หนังสือ บทความ โค้ด เอกสาร ถามตอบ ฯลฯ) มันฝึกงานเดิมๆ: ให้ข้อความบางส่วนแล้วทำนายโทเค็นถัดไป เมื่อทำนายผิด กระบวนการฝึกจะปรับพารามิเตอร์ภายในให้ทำนายดีขึ้นในครั้งต่อไป
เวลาผ่านไป การปรับเหล่านั้นสะสมจนโมเดลเริ่มเก็บความสัมพันธ์เช่น:
เพราะมันเรียนรู้สถิติทั่วไป ไม่ใช่สคริปต์ตายตัว มันสามารถผสมรูปแบบในรูปแบบใหม่ได้ หากเคยเห็นตัวอย่างการ “อธิบายแนวคิด” หลายแบบ และตัวอย่าง “สถานการณ์แอปของคุณ” หลายแบบ มันมักจะรวมกันเป็นคำตอบที่เหมาะสม
นี่คือเหตุผลที่ LLM สามารถเขียนอีเมลต้อนรับสำหรับสินค้านิช หรือปรับคำอธิบายการผสาน API ให้เข้ากับสแตกเฉพาะได้ มันไม่ได้ดึงย่อหน้าที่เก็บไว้ แต่มันสร้างลำดับใหม่ที่ตรงกับรูปแบบที่เรียนรู้
แม้ข้อมูลฝึกบางส่วนจะมีข้อเท็จจริงเฉพาะ คุณไม่ควรถือว่าโมเดลสามารถ "ค้นหา" ข้อมูลนั้นได้อย่างเชื่อถือได้ การฝึกไม่ทำงานเหมือนการทำดัชนีฐานความรู้ มันใกล้เคียงกับการบีบอัด: ตัวอย่างจำนวนมากถูกกลั่นเป็นน้ำหนักที่มีผลต่อการทำนายในอนาคต
นั่นหมายความว่าโมเดลอาจพูดด้วยความมั่นใจเกี่ยวกับรายละเอียดที่มัน เดา โดยอิงจากสิ่งที่มักปรากฏในบริบทที่คล้ายกัน
การเรียนรู้รูปแบบทรงพลังสำหรับการสร้างข้อความที่ลื่นไหลและเกี่ยวข้อง แต่ความลื่นไหลไม่เท่ากับความจริง โมเดลอาจ:
ข้อสรุปสำหรับผู้สร้างแอป: คำตอบของ LLM มักมาจากรูปแบบที่เรียนรู้ ไม่ใช่ข้อเท็จจริงที่ตรวจสอบ หากความถูกต้องสำคัญ คุณควรยึดผลลัพธ์เข้ากับข้อมูลของคุณเองและมีการตรวจสอบ (จะกล่าวต่อในส่วนถัดไป)
เมื่อ LLM เขียนคำตอบ มันไม่ได้ดึง "ประโยคที่ถูกต้อง" เดียวจากฐานข้อมูล แต่ในแต่ละขั้นตอนจะทำนาย ช่วง ของโทเค็นถัดไปที่เป็นไปได้ แต่ละตัวมีความน่าจะเป็น
ถ้าโมเดลเลือกโทเค็นที่น่าจะเป็นที่สุดเสมอ ผลลัพธ์จะคงที่มาก—แต่ก็มักจะจำเจและแข็งทื่อ ระบบส่วนใหญ่จึง สุ่มตัวอย่าง จากการแจกแจง ซึ่งนำมาซึ่งความสุ่มที่ควบคุมได้
การตั้งค่าสองอย่างที่ใช้บ่อยส่งผลต่อความหลากหลายของเอาต์พุต:
ถ้าคุณสร้างแอป การตั้งค่านี้ไม่ใช่แค่เรื่องความคิดสร้างสรรค์ แต่เป็นการเลือกระหว่าง:
เพราะโมเดลถูกปรับเพื่อให้ข้อความเป็นไปได้สูง มันจึงอาจสร้างประโยคที่ฟังดูแน่นอนได้—แม้เนื้อหาจะไม่ถูกต้องก็ตาม ความมั่นใจในถ้อยคำไม่ใช่หลักฐาน นี่คือเหตุผลที่แอปมักต้องมีการยึดผลลัพธ์เข้ากับข้อมูลจริง (retrieval) หรือขั้นตอนการยืนยัน
ถาม LLM: “เขียนฟังก์ชัน JavaScript เพื่อเอาค่าซ้ำออกจากอาร์เรย์” คุณอาจได้ตัวอย่างต่าง ๆ ที่ถูกต้องทั้งหมด:
// Option A: concise
const unique = (arr) => [...new Set(arr)];
// Option B: explicit
function unique(arr) {
return arr.filter((x, i) => arr.indexOf(x) === i);
}
การตั้งค่าการสุ่มต่างกันทำให้สไตล์ต่างกัน (กระชับ vs อธิบายชัดเจน) ข้อแลกเปลี่ยนต่างกัน (ความเร็ว การอ่าน) และพฤติกรรมขอบเขตที่แตกต่างกัน ทั้งหมดนี้เกิดขึ้นโดยโมเดลไม่ได้ “เปลี่ยนใจ” แต่มันเลือกจากความต่อเนื่องที่มีความน่าจะเป็นสูงหลายแบบ
เมื่อคนพูดว่าโมเดล “จำ” บทสนทนาของคุณ จริง ๆ แล้วมันมี บริบท: ข้อความที่มันสามารถ "เห็น" ตอนนี้—ข้อความล่าสุด คำสั่งระบบ และส่วนของบทสนทนาก่อนหน้าที่ยังอยู่ในหน้าต่าง
หน้าต่างบริบท คือขีดจำกัดคงที่บนปริมาณข้อความที่โมเดลพิจารณาได้พร้อมกัน เมื่อบทสนทนายาวขึ้น ส่วนเก่าจะหลุดออกจากหน้าต่างและหายไปจากมุมมองของโมเดล
นั่นคือสาเหตุที่คุณอาจเห็นพฤติกรรมเช่น:
ถ้าคุณใส่ข้อความเพิ่มเรื่อย ๆ คุณกำลังแข่งขันเพื่อพื้นที่จำกัด ข้อจำกัดสำคัญถูกแทนที่ด้วยข้อความล่าสุด หากไม่มีสรุป โมเดลต้องอนุมานว่าสิ่งที่สำคัญจากสิ่งที่ยังมองเห็น—ดังนั้นมันจึงอาจฟังดูมั่นใจในขณะที่เงียบ ๆ หลุดรายละเอียดสำคัญไป
การแก้จริงจังคือการ สรุปเป็นระยะ: ย่อเป้าหมาย การตัดสินใจ และข้อจำกัดในบล็อกสั้น ๆ แล้วต่อยอด ในแอป มักทำเป็น “สรุปบทสนทนาอัตโนมัติ” ที่ถูกฉีดกลับเข้าไปในพรอมต์
โมเดลมักปฏิบัติตามคำสั่งที่ ใกล้กับเอาต์พุต ที่จะสร้าง ดังนั้นถ้าคุณมีข้อกำหนดที่ต้องปฏิบัติตาม ให้วางไว้ท้ายพรอมต์—ก่อนคำว่า “ตอนนี้ให้สร้างคำตอบ”
ถ้าสร้างแอป ให้ถือเรื่องนี้เหมือนการออกแบบอินเทอร์เฟซ: ตัดสินใจว่าอะไรต้องอยู่ในบริบท และตรวจสอบให้แน่ใจว่ามันถูกใส่เสมอ—โดยการตัดประวัติที่ไม่สำคัญหรือเพิ่มสรุปที่กระชับ สำหรับแนวทางการจัดโครงสร้างพรอมต์เพิ่มเติม ดู /blog/prompting-as-interface-design
LLM ดีมากในการสร้างข้อความที่ ฟังดู เหมือนคำตอบจากนักพัฒนาที่มีความสามารถ แต่ “ฟังดูถูก” ไม่เท่ากับ “ถูกต้อง” โมเดลทำนายโทเค็น ไม่ได้ตรวจสอบเอาต์พุตกับโค้ดของคุณ ไลบรารี หรือโลกจริง เว้นแต่คุณจะเชื่อมต่อเครื่องมือที่ทำเช่นนั้น
ถ้าโมเดลแนะนำการแก้ไข รีแฟคเตอร์ หรือฟังก์ชันใหม่ มันก็ยังเป็นแค่ข้อความ มันไม่ได้รันแอปของคุณ นำเข้าแพ็กเกจ เรียก API หรือคอมไพล์โปรเจกต์ เว้นแต่คุณจะเชื่อมต่อกับเครื่องมือที่ทำงานเหล่านั้น (เช่น test runner, linter, build step)
นี่คือตัวเปรียบเทียบสำคัญ:
เมื่อ AI ทำผิด มักเกิดในรูปแบบที่คาดเดาได้:
ข้อผิดพลาดเหล่านี้สังเกตยากเพราะคำอธิบายรอบ ๆ มักสอดคล้อง
ปฏิบัติกับเอาต์พุตของ AI เหมือนร่างที่เร็วจากเพื่อนร่วมทีมที่ไม่ได้รันโปรเจกต์ ทว่าสิ่งที่ขึ้นความมั่นใจจริง ๆ คือหลังจากที่คุณ:
ถ้าเทสต์ไม่ผ่าน ให้ถือว่าคำตอบของโมเดลเป็นจุดเริ่มต้น ไม่ใช่การแก้ไขสุดท้าย
โมเดลภาษาเก่งในการเสนอสิ่งที่ น่าจะ ทำงานได้ แต่ถ้ามันยังเป็นแค่ข้อความ เครื่องมือคือสิ่งที่จะทำให้แอปที่ขับเคลื่อนด้วย AI เปลี่ยนข้อเสนอเป็นการกระทำที่ได้รับการยืนยัน: รันโค้ด คิวรีฐานข้อมูล ดึงเอกสาร หรือเรียก API ภายนอก
ในเวิร์กโฟลว์การสร้างแอป เครื่องมือส่วนใหญ่มีลักษณะเป็น:
สิ่งสำคัญคือ โมเดลไม่ต้องเดาอีกต่อไป—มันสามารถตรวจสอบได้
แบบจำลองจิตใจที่เป็นประโยชน์คือ:
นี่คือวิธีลดการเดา หาก linter รายงาน unused imports โมเดลจะอัปเดตโค้ด หากยูนิตเทสต์ล้ม โมเดลจะแก้จนกว่าเทสต์จะผ่าน (หรืออธิบายว่าแก้ไม่ได้)
eslint/ruff/prettier เพื่อตรวจจับปัญหาเครื่องมือทรงพลังและอันตราย ปฏิบัติตามหลัก least privilege:
เครื่องมือไม่ทำให้โมเดล "ฉลาดขึ้น" แต่ทำให้ AI ในแอปของคุณ มีหลักฐานมากขึ้น — เพราะมันสามารถยืนยัน ไม่ใช่แค่เล่า
โมเดลภาษาเก่งในการเขียน สรุป และให้เหตุผลบนข้อความที่มัน "เห็น" แต่ไม่ได้รู้การเปลี่ยนแปลงผลิตภัณฑ์ล่าสุด นโยบายบริษัท หรือรายละเอียดบัญชีลูกค้า RAG แก้ปัญหานี้ได้ง่าย: ดึงข้อเท็จจริงที่เกี่ยวข้องก่อน แล้วให้โมเดลเขียนโดยใช้ข้อมูลนั้น
คิดว่า RAG เป็น “AI แบบเปิดหนังสือ” แทนที่จะถามโมเดลจากหน่วยความจำ แอปของคุณจะดึงชุดย่อหน้าที่เกี่ยวข้องจากแหล่งที่เชื่อถือได้แล้วใส่เข้าไปในพรอมต์ โมเดลจะตอบโดยยึดจากเนื้อหาที่ให้มา
RAG เหมาะเป็นค่าดีฟอลต์เมื่อความถูกต้องขึ้นกับข้อมูลนอกโมเดล:
ถ้าคุณต้องการคำตอบที่ถูกต้องตามธุรกิจ RAG มักดีกว่าการหวังว่าโมเดลจะเดาถูก
RAG ดีแค่การดึง ถ้าก้าวค้นคืนข้อความที่ล้าสมัย ไม่เกี่ยวข้อง หรือไม่ครบ โมเดลอาจสร้างคำตอบผิดที่ “ยั้งจากแหล่งที่ผิด” ในทางปฏิบัติ การพัฒนาคุณภาพการค้นหา (การแบ่งชิ้น ข้อมูลเมตา ความสด และการจัดลำดับ) มักเพิ่มความถูกต้องได้มากกว่าการปรับพรอมต์
“เอเยนต์” คือ LLM ที่รันเป็นลูป: มันวางแผน ทำขั้นตอน ดูผล แล้วตัดสินใจต่อ แทนที่จะตอบครั้งเดียว มันวนจนกว่าจะบรรลุเป้าหมาย
แบบจำลองที่เป็นประโยชน์คือ:
Plan → Do → Check → Revise
ลูปนี้แปลงพรอมต์เดียวให้กลายเป็นเวิร์กโฟลว์ขนาดเล็ก นี่คือสาเหตุที่เอเยนต์อาจดู “เป็นอิสระ” มากกว่าการแชท: โมเดลไม่ได้แค่สร้างข้อความ มันเลือกการกระทำและจัดลำดับ
เอเยนต์ต้องการกฎชัดเจนเมื่อหยุด เงื่อนไขหยุดทั่วไปได้แก่:
กรอบป้องกันคือข้อจำกัดที่ทำให้ลูปปลอดภัยและคาดเดาได้: เครื่องมือที่อนุญาต แหล่งข้อมูลที่อนุญาต ขั้นตอนการยืนยัน (human-in-the-loop) และรูปแบบเอาต์พุต
เพราะเอเยนต์มักจะเสนอว่า “อีกสักขั้น” อยู่เสมอ คุณต้องออกแบบรับมือความล้มเหลว หากไม่มี งบประมาณ เวลา และขีดจำกัดขั้นตอน เอเยนต์อาจวนซ้ำเป็นการกระทำซ้ำ ๆ หรือเรียกเก็บค่าใช้จ่ายโดยไม่จำเป็น
ค่าดีฟอลต์ที่เป็นประโยชน์: จำกัดการวนรอบ บันทึกทุกการกระทำ ให้ผลลัพธ์จากเครื่องมือต้องได้รับการตรวจสอบ และล้มอย่างสุภาพด้วยคำตอบบางส่วนพร้อมสิ่งที่ลองแล้ว นั่นมักดีกว่าการปล่อยให้เอเยนต์วนไม่รู้จบ
ถ้าคุณสร้างด้วยแพลตฟอร์มโค้ดที่มี vibe แบบ Koder.ai แบบจำลอง "เอเยนต์ + เครื่องมือ" นี้มีประโยชน์เป็นพิเศษ คุณไม่ได้แค่แชทเพื่อขอคำแนะนำ—คุณกำลังใช้เวิร์กโฟลว์ที่ผู้ช่วยสามารถช่วยวางแผน สร้างส่วนประกอบ React/Go/PostgreSQL หรือ Flutter และวนซ้ำพร้อมเช็คลอย์พอยต์ (เช่น สแนปช็อตและการย้อนกลับ) ทำให้คุณเคลื่อนที่เร็วโดยไม่เสียการควบคุมการเปลี่ยนแปลง
เมื่อคุณเอา LLM ไปขับฟีเจอร์ในแอป พรอมต์ของคุณไม่ใช่ “แค่ข้อความ” อีกต่อไป มันคือสัญญาอินเทอร์เฟซระหว่างผลิตภัณฑ์และโมเดล: โมเดลควรทำอะไร อะไรที่อนุญาต และมันต้องตอบอย่างไรเพื่อให้โค้ดของคุณนำไปใช้ได้อย่างเชื่อถือได้
แนวคิดที่เป็นประโยชน์คือมองพรอมต์เหมือนฟอร์ม UI ฟอร์มที่ดีลดความกำกวม จำกัดตัวเลือก และทำให้การกระทำถัดไปชัดเจน พรอมต์ที่ดีทำเช่นเดียวกัน
ก่อนปล่อยพรอมต์ให้แน่ใจว่าระบุชัดเจน:
โมเดลปฏิบัติตามรูปแบบ หนทางที่ดีคือใส่ตัวอย่างอินพุตและเอาต์พุตที่ดี (โดยเฉพาะเมื่อต้องมีกรณีขอบ) แม้ตัวอย่างเดียวก็ช่วยลดการโต้ตอบและป้องกันไม่ให้โมเดลคิดรูปแบบที่ UI ไม่รองรับ
ถ้ามีระบบอื่นอ่านผล ให้ขอ JSON ตาราง หรือบูลเล็ตที่เข้มงวด
You are a helpful assistant.
Task: {goal}
Inputs: {inputs}
Constraints:
- {constraints}
Output format (JSON):
{
"result": "string",
"confidence": "low|medium|high",
"warnings": ["string"],
"next_steps": ["string"]
}
นี่เปลี่ยน “การพรอมต์” ให้เป็นการออกแบบอินเทอร์เฟซที่คาดเดาได้
เพิ่มกฎชัด ๆ เช่น: "ถ้าข้อกำหนดสำคัญขาดหาย ให้ถามคำถามชี้แจงก่อนตอบ"
บรรทัดเดียวนี้ช่วยป้องกันเอาต์พุตที่ดูมั่นใจแต่ผิด—เพราะโมเดลได้รับอนุญาต (และคาดหวัง) ให้หยุดและขอข้อมูลแทนการเดา
ในทางปฏิบัติ พรอมต์ที่เชื่อถือได้ที่สุดมักตรงกับกระบวนการสร้างและปรับใช้ของคุณ เช่น ถ้าแพลตฟอร์มของคุณรองรับการวางแผนก่อน สร้างการเปลี่ยนแปลง แล้วส่งออกซอร์สโค้ดหรือปรับใช้ คุณสามารถสะท้อนนั้นในสัญญาพรอมต์ (plan → produce diff/steps → confirm → apply) โหมด "planning" ของ Koder.ai เป็นตัวอย่างที่ดีของการทำให้กระบวนการเป็นเฟสชัดเจน เพื่อลดการเลื่อนและช่วยทีมทบทวนก่อนปล่อย
ความเชื่อถือไม่เกิดจากโมเดลที่ "ฟังดูมั่นใจ" แต่เกิดจากการปฏิบัติกับเอาต์พุตเหมือน dependency อีกตัวหนึ่งในผลิตภัณฑ์: วัดผล ติดตาม และจำกัด
เริ่มจากชุดงานจริงจำนวนน้อยที่แอปต้องทำให้ดี แล้วแปลงเป็นการตรวจสอบซ้ำได้:
แทนที่จะถามว่า “ดีไหม” ให้ติดตามว่า “ผ่านบ่อยแค่ไหน” เมตริกที่ใช้ได้แก่:
เมื่อเกิดข้อผิดพลาด คุณควรสามารถเล่นซ้ำได้ บันทึก (พร้อมการกลบข้อมูลที่เหมาะสม):
นี่ทำให้ดีบักเป็นไปได้จริงและช่วยให้ตอบคำถามว่า “โมเดลเปลี่ยนไป หรือข้อมูล/เครื่องมือเราเปลี่ยน?”
การตั้งค่าพื้นฐานช่วยป้องกันเหตุการณ์ทั่วไป:
โดยทั่วไปหมายความว่าโมเดลสามารถสร้างข้อความที่สอดคล้องและมีจุดมุ่งหมาย ซึ่งดูเหมือนการเข้าใจและให้เหตุผล ในทางปฏิบัติ LLM ทำการทำนายโทเค็นถัดไป: มันสร้างการต่อข้อความที่มีความน่าจะเป็นสูงที่สุด โดยอิงจากพรอมต์ คำสั่งระบบ และบริบทที่ให้มา
สำหรับผู้สร้างแอป ข้อสรุปที่เป็นประโยชน์คือ “การคิด” คือพฤติกรรมเอาต์พุตที่คุณสามารถกำหนดและจำกัดได้ — ไม่ใช่การรับประกันความจริงภายในตัวโมเดล
โทเค็นคือชิ้นส่วนของข้อความที่โมเดลประมวลผลและสร้างขึ้น (อาจเป็นคำเต็ม ส่วนของคำ เครื่องหมายวรรคตอน หรือเว้นวรรค) เนื่องจากโมเดลทำงานบนโทเค็น ไม่ใช่ “ประโยค” ดังนั้น ค่าใช้จ่าย ข้อจำกัด และการตัดทอนจะวัดเป็นโทเค็น
ในเชิงปฏิบัติ:
เพราะการสร้างเป็นแบบมีความน่าจะเป็น ในแต่ละขั้นตอนโมเดลจะให้ความน่าจะเป็นกับตัวเลือกของโทเค็นถัดไปหลายตัว และระบบส่วนใหญ่ สุ่มตัวอย่าง จากการแจกแจงนั้นแทนที่จะเลือกตัวเลือกสูงสุดเสมอ
เพื่อให้ผลลัพธ์ซ้ำได้มากขึ้น:
LLM ถูกออกแบบให้สร้างข้อความที่เป็นไปได้มากที่สุด ไม่ใช่ตรวจสอบข้อเท็จจริง จึงอาจพูดด้วยน้ำเสียงมั่นใจแม้ข้อเสนอแนะจะเป็นการเดา
ในการออกแบบผลิตภัณฑ์ ให้ถือว่าความคล่องแคล่วคือ “งานเขียนที่ดี” ไม่ใช่ “ความถูกต้อง” และเพิ่มการตรวจสอบ (retrieval, tools, tests, approvals) เมื่อความถูกต้องมีความสำคัญ
context window คือปริมาณข้อความสูงสุดที่โมเดลสามารถพิจารณาได้ในครั้งเดียว (คำสั่งระบบ ประวัติบทสนทนา ข้อความที่ดึงมา ฯลฯ) เมื่อเธรดยาวเกินไป ข้อความเก่าจะหลุดออกจากหน้าต่างบริบทและโมเดลจะมองไม่เห็น
แนวทางแก้:
ไม่โดยอัตโนมัติ ค่าเริ่มต้นคือโมเดลไม่ได้ท่องเว็บ ไม่ได้อ่านฐานข้อมูลของคุณ และไม่ได้รันโค้ด มันเข้าถึงได้เฉพาะสิ่งที่คุณใส่ในพรอมต์และเครื่องมือที่เชื่อมต่อไว้เท่านั้น
หากคำตอบขึ้นกับข้อมูลภายในหรือข้อมูลล่าสุด ให้ส่งข้อมูลเหล่านั้นผ่าน retrieval (RAG) หรือการเรียกใช้เครื่องมือ แทนการ “ถามให้มากขึ้น”
เมื่อคุณต้องการผลลัพธ์ที่ได้รับการยืนยันหรือการกระทำจริง ให้ใช้เครื่องมือ ตัวอย่างทั่วไป:
รูปแบบที่ดีคือ propose → check → adjust ที่โมเดลจะวนปรับตามผลลัพธ์จากเครื่องมือ
RAG (Retrieval-Augmented Generation) คือ “AI แบบเปิดหนังสือ”: แอปของคุณดึงข้อความที่เกี่ยวข้องจากแหล่งเชื่อถือได้ (เอกสาร ตั๋ว นโยบาย) แล้วใส่เข้าไปในพรอมต์เพื่อให้โมเดลตอบโดยยึดจากข้อมูลเหล่านั้น
ใช้ RAG เมื่อ:
ความเสี่ยงหลักคือการดึงข้อมูลผิดหรือเก่า—การปรับปรุงการค้นหา การแบ่งชิ้น และความสดใหม่มักช่วยได้มากกว่าการปรับพรอมต์
เอเยนต์คือ LLM ที่ทำงานเป็นวงจรหลายขั้นตอน: มันวางแผน ทำงาน ตรวจสอบผล แล้วปรับแผนต่อ ซึ่งเหมาะกับเวิร์กโฟลว์เช่น “ค้นหาข้อมูล → ร่าง → ตรวจสอบ → ส่ง”
เพื่อให้ปลอดภัย:
ปฏิบัติต่อพรอมต์เสมือนสัญญาระหว่างผลิตภัณฑ์และโมเดล: ระบุเป้าหมาย ข้อมูลนำเข้า ข้อจำกัด และรูปแบบเอาต์พุตให้ชัดเจนเพื่อให้แอปของคุณใช้งานผลลัพธ์ได้อย่างเชื่อถือได้
การสร้างความเชื่อถือเชิงปฏิบัติ: